
Global Polarimetric Synthetic Aperture Radar Image Segmentation with Data Augmentation and Hybrid Architecture Model


Abstract
1. Introduction
- (1)
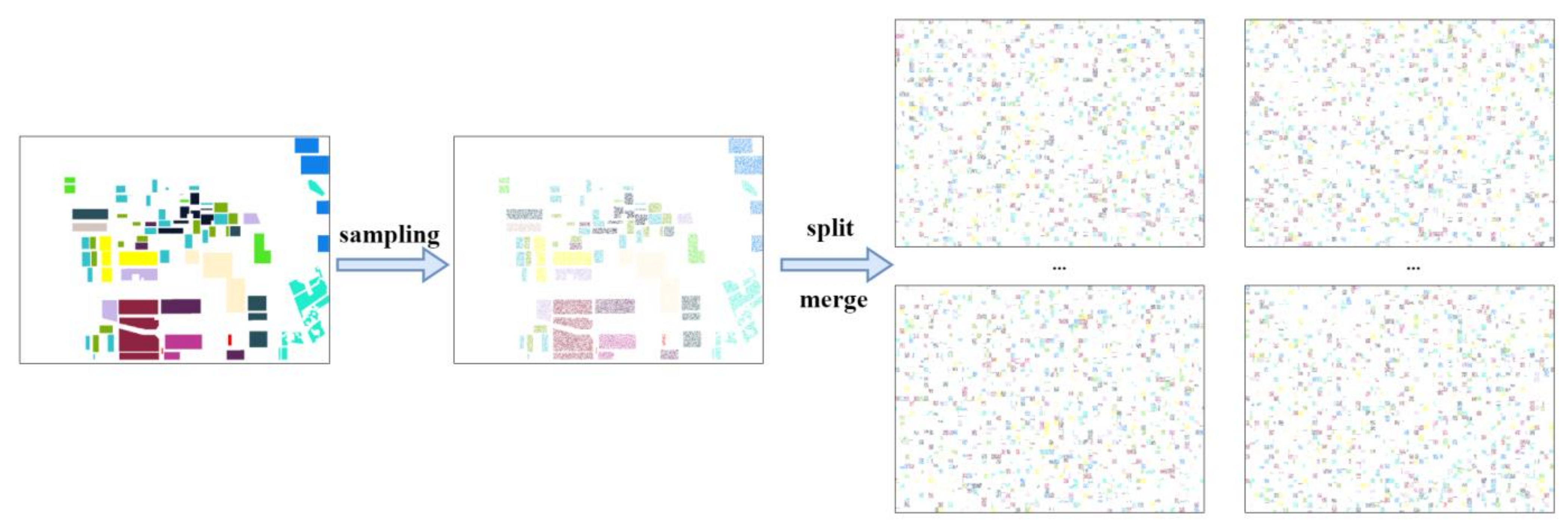
- A data augmentation technique is introduced, aiming at significantly improving the utilization of labeled data while mitigating spatial information interference. Based on this data augmentation technique, we improved the input format without the need to construct patches or perform cut and merge operations on label data. This ensures the model can adapt to images of any size and swiftly conduct global inference.
- (2)
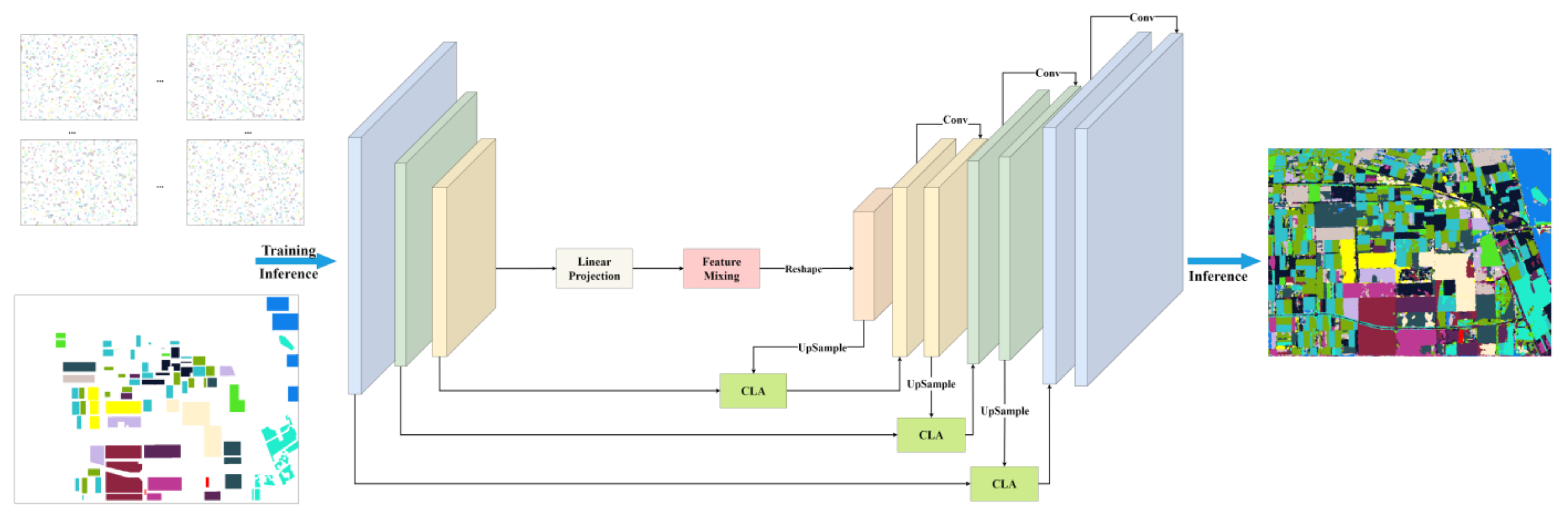
- A hybrid architecture of CNN and MLP is proposed to classify PolSAR images. The architecture accepts arbitrary-size input images. Then, the output is the extracted feature at different levels.
- (3)
- To further improve the performance, a cross-layer attention module is used to establish the relationship between different neural network layers, and the feature information is passed from the shallow layer to the deep layer. This information transfer helps capture dependencies over long distances, improving the model’s understanding of the data.
- (4)
- Three extensively recognized datasets are utilized for evaluating the efficacy of the proposed approach, and the experimental results unequivocally demonstrate its superior performance and classification accuracy when compared to contemporary other methods.
2. Related Works
2.1. Segmentation Model
2.2. Attention Mechanism
2.3. Hybrid Model
3. Proposed Methods
3.1. PolSAR Data Augmentation Method
3.2. Model
- (1)
- Shallow Feature Extraction: The whole PolSAR image is fed into the CNN network to extract preliminary features. The shallow features of PolSAR images at the i-th level are expressed as .
- (2)
- Deep Feature Extraction: To improve the perception of small targets, the final output of the shallow feature extraction module is forwarded to the Feature-Mixing (FM) blocks to obtain . Through the stacking of multiple Feature-Mixing layers, is highly integrated with both high-level abstract features and generalization features, aiding the model in better comprehending the content within images, enhancing segmentation performance for complex scenes and objects, reducing sensitivity to noise and variations, and delivering more semantically rich segmentation results.
- (3)
- Feature Fusion: High-level features provide abstract semantic information, while low-level features contain the details and basic structure of the image. Fusing these two types of information provides a more comprehensive understanding of the image and enhances the robustness of the model. To achieve enhanced utilization efficiency, is successively fused with the layers of through cross-layer attention (CLA) to obtain the multiscale high–low joint map.
3.2.1. Input of Model
3.2.2. Feature Extractor
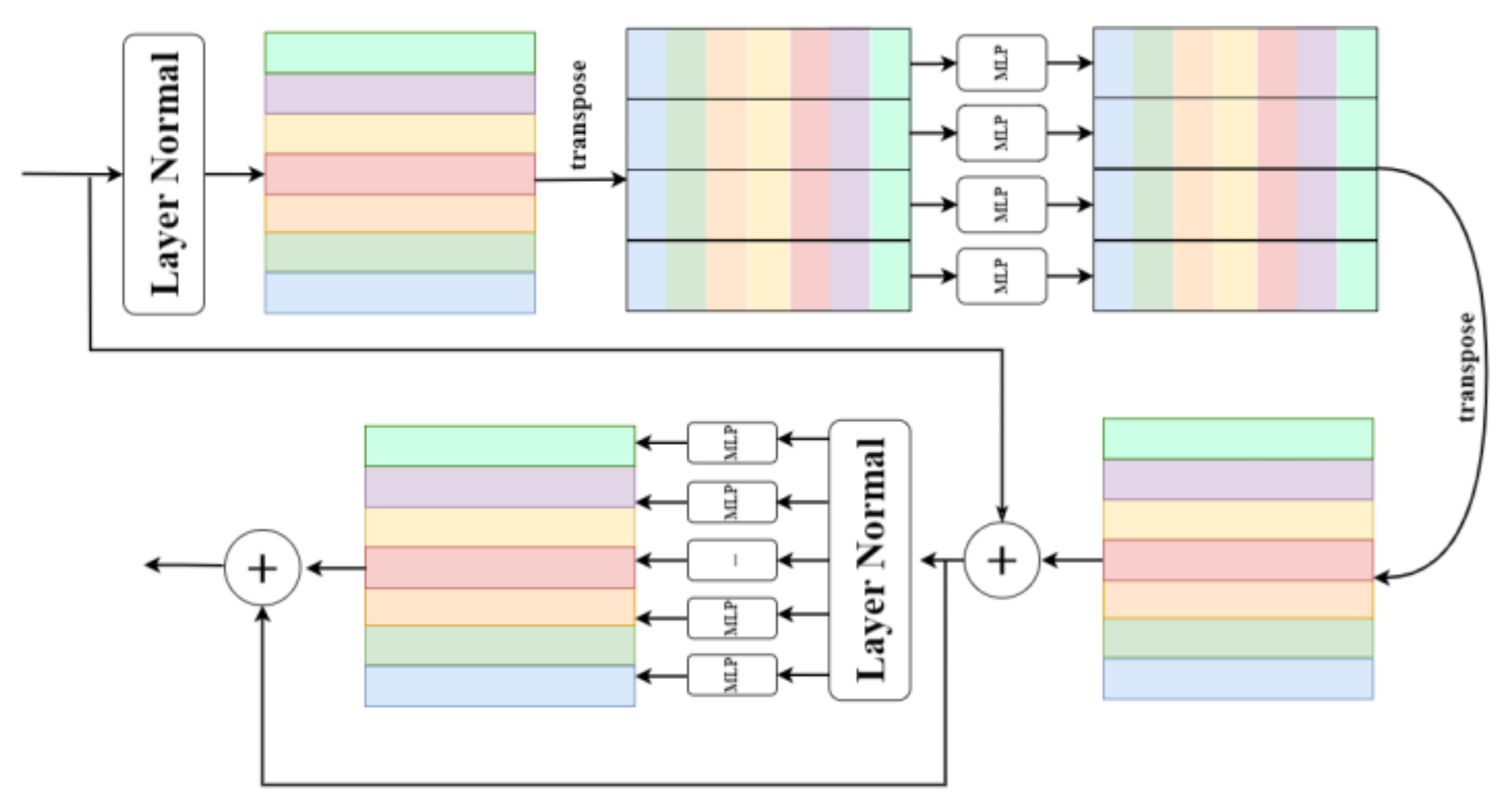
3.2.3. Cross-Layer Attention
3.2.4. Loss Function
4. Experiments and Results
4.1. Dataset
- (1)
- Flevoland I, AIRSAR, L-Band
- (2)
- Flevoland II, AIRSAR, L-Band
- (3)
- Oberpfaffenhofen, ESAR, L-Band
4.2. Analysis Criteria of Performance
4.3. Parameters of Experiment
4.4. Experiments Result
5. Analysis
5.1. Ablation Experiments
5.2. Impact of Augmentation of Data
5.3. Impact of Shape of Blocks
5.4. Impact of Sampling Ratio
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Parikh, H.; Patel, S.; Patel, V. Classification of SAR and PolSAR images using deep learning: A review. Int. J. Image Data Fusion 2020, 11, 1–32. [Google Scholar] [CrossRef]
- Sato, M.; Chen, S.W.; Satake, M. Polarimetric SAR Analysis of Tsunami Damage Following the March 11, 2011 East Japan Earthquake. Proc. IEEE 2012, 100, 2861–2875. [Google Scholar] [CrossRef]
- Chen, S.W.; Sato, M. Tsunami Damage Investigation of Built-Up Areas Using Multitemporal Spaceborne Full Polarimetric SAR Images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 1985–1997. [Google Scholar] [CrossRef]
- Chen, S.W.; Wang, X.S.; Sato, M. Urban Damage Level Mapping Based on Scattering Mechanism Investigation Using Fully Polarimetric SAR Data for the 3.11 East Japan Earthquake. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6919–6929. [Google Scholar] [CrossRef]
- Datcu, M.; Huang, Z.; Anghel, A.; Zhao, J.; Cacoveanu, R. Explainable, Physics-Aware, Trustworthy Artificial Intelligence: A paradigm shift for synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2023, 11, 8–25. [Google Scholar] [CrossRef]
- Cloude, S.R.; Pottier, E. An entropy based classification scheme for land applications of polarimetric SAR. IEEE Trans. Geosci. Remote Sens. 1997, 35, 68–78. [Google Scholar] [CrossRef]
- Freeman, A.; Durden, S.L. A three-component scattering model for polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1998, 36, 963–973. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Moriyama, T.; Ishido, M.; Yamada, H. Four-component scattering model for polarimetric SAR image decomposition. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1699–1706. [Google Scholar] [CrossRef]
- Lee, J.S.; Grunes, M.R.; Ainsworth, T.L.; Du, L.J.; Schuler, D.L.; Cloude, S.R. Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2249–2258. [Google Scholar] [CrossRef]
- Lee, J.S.; Schuler, D.L.; Lang, R.H.; Ranson, K.J. K-distribution for multi-look processed polarimetric SAR imagery. In Proceedings of the International Geoscience and Remote Sensing Symposium on Surface and Atmospheric Remote Sensing—Technologies, Data Analysis and Interpretation (IGARSS 94), Pasadena, CA, USA, 8–12 August 1992; pp. 2179–2181. [Google Scholar]
- Doulgeris, A.P. An Automatic U-Distribution and Markov Random Field Segmentation Algorithm for PolSAR Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1819–1827. [Google Scholar] [CrossRef]
- Doulgeris, A.P.; Anfinsen, S.N.; Eltoft, T. Automated Non-Gaussian Clustering of Polarimetric Synthetic Aperture Radar Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3665–3676. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.P.; Xu, F.; Jin, Y.Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Liu, F.; Jiao, L.C.; Hou, B.; Yang, S.Y. POL-SAR Image Classification Based on Wishart DBN and Local Spatial Information. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3292–3308. [Google Scholar] [CrossRef]
- Xie, W.; Jiao, L.C.; Hou, B.; Ma, W.P.; Zhao, J.; Zhang, S.Y.; Liu, F. POLSAR Image Classification via Wishart-AE Model or Wishart-CAE Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3604–3615. [Google Scholar] [CrossRef]
- Wang, J.L.; Hou, B.; Jiao, L.C.; Wang, S. POL-SAR Image Classification Based on Modified Stacked Autoencoder Network and Data Distribution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1678–1695. [Google Scholar] [CrossRef]
- Li, Y.Y.; Xing, R.T.; Jiao, L.C.; Chen, Y.Q.; Chai, Y.T.; Marturi, N.; Shang, R.H. Semi-Supervised PolSAR Image Classification Based on Self-Training and Superpixels. Remote Sens. 2019, 11, 1933. [Google Scholar] [CrossRef]
- Bi, H.X.; Sun, J.; Xu, Z.B. A Graph-Based Semisupervised Deep Learning Model for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2116–2132. [Google Scholar] [CrossRef]
- Fukuda, S.; Katagiri, R.; Hirosawa, H. Unsupervised approach for polarimetric SAR image classification using support vector machines. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2002)/24th Canadian Symposium on Remote Sensing, Toronto, ON, Canada, 24–28 June 2002; pp. 2599–2601. [Google Scholar]
- Kong, J.A.; Swartz, A.A.; Yueh, H.A.; Novak, L.M.; Shin, R.T. Identification of terrain cover using the optimum polarimetric classifier. J. Electromagn. Waves Appl. 1988, 2, 171–194. [Google Scholar]
- He, C.; Li, S.; Liao, Z.X.; Liao, M.S. Texture Classification of PolSAR Data Based on Sparse Coding of Wavelet Polarization Textons. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4576–4590. [Google Scholar] [CrossRef]
- Masjedi, A.; Zoej, M.J.V.; Maghsoudi, Y. Classification of Polarimetric SAR Images Based on Modeling Contextual Information and Using Texture Features. IEEE Trans. Geosci. Remote Sens. 2016, 54, 932–943. [Google Scholar] [CrossRef]
- Hong, D.F.; Yokoya, N.; Chanussot, J.; Zhu, X.X. CoSpace: Common Subspace Learning From Hyperspectral-Multispectral Correspondences. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4349–4359. [Google Scholar] [CrossRef]
- Zhang, L.; Ma, W.P.; Zhang, D. Stacked Sparse Autoencoder in PolSAR Data Classification Using Local Spatial Information. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1359–1363. [Google Scholar] [CrossRef]
- Jiao, L.C.; Liu, F. Wishart Deep Stacking Network for Fast POLSAR Image Classification. IEEE Trans. Image Process. 2016, 25, 3273–3286. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.Q.; Jiao, L.C.; Li, Y.Y.; Li, L.L.; Zhang, D.; Ren, B.; Marturi, N. A Novel Semicoupled Projective Dictionary Pair Learning Method for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2407–2418. [Google Scholar] [CrossRef]
- Fukuda, S.; Hirosawa, H. Polarimetric SAR image classification using support vector machines. IEICE Trans. Electron. 2001, E84C, 1939–1945. [Google Scholar]
- Jamali, A.; Roy, S.K.; Bhattacharya, A.; Ghamisi, P. Local Window Attention Transformer for Polarimetric SAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 4004205. [Google Scholar] [CrossRef]
- Chen, S.-W.; Tao, C.-S. PolSAR image classification using polarimetric-feature-driven deep convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Ni, J.; Xiang, D.; Lin, Z.; López-Martínez, C.; Hu, W.; Zhang, F. DNN-based PolSAR image classification on noisy labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3697–3713. [Google Scholar] [CrossRef]
- Li, L.; Ma, L.; Jiao, L.; Liu, F.; Sun, Q.; Zhao, J. Complex contourlet-CNN for polarimetric SAR image classification. Pattern Recognit. 2020, 100, 107110. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, G.; Dai, Q.; Xue, B.; Wang, P. Hybrid Attention-Based Encoder–Decoder Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2023, 15, 526. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mandianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, J.; Feng, L.; Li, S.; Yang, W.; Guo, D. A Refined Pyramid Scene Parsing Network for Polarimetric SAR Image Semantic Segmentation in Agricultural Areas. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4014805. [Google Scholar] [CrossRef]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.H.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zheng, S.X.; Lu, J.C.; Zhao, H.S.; Zhu, X.T.; Luo, Z.K.; Wang, Y.B.; Fu, Y.W.; Feng, J.F.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6877–6886. [Google Scholar]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4291–4308. [Google Scholar] [CrossRef]
- Cho, K.; Courville, A.; Bengio, Y. Describing multimedia content using attention-based encoder-decoder networks. IEEE Trans. Multimed. 2015, 17, 1875–1886. [Google Scholar] [CrossRef]
- Wang, F.; Tax, D. Survey on the attention based RNN model and its applications in computer vision. arXiv 2016, arXiv:1601.06823. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J.; IEEE. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | PB | DS | DA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Size | Training Ratio | Validation Ratio | Size | Training Plots | Validation Plots | Size | Training Plots | Validation Plots | |
| Flevoland I | 8 × 8 | 70% | 30% | 32 × 32 | 880 | 376 | 750 × 1024 | 70 | 30 |
| Flevoland II | 8 × 8 | 70% | 30% | 32 × 32 | 1081 | 462 | 1024 × 1024 | 70 | 30 |
| Oberpfaffenhofen | 8 × 8 | 70% | 30% | 32 × 32 | 2565 | 1099 | 1300 × 1024 | 70 | 30 |
| Class | SVM- PB | CNN- PB | U-Net- DS | SETR- DS | U-Net- DA | SETR- DA | Ours- DA |
|---|---|---|---|---|---|---|---|
| Stem beans | 98.52 | 99.03 | 99.79 | 99.66 | 98.44 | 97.13 | 99.42 |
| Peas | 96.61 | 98.57 | 99.05 | 99.37 | 97.81 | 96.02 | 99.07 |
| Forest | 93.71 | 99.51 | 98.12 | 98.67 | 98.06 | 97.31 | 99.18 |
| Lucerne | 95.79 | 86.67 | 99.18 | 99.12 | 95.56 | 96.52 | 98.71 |
| Wheat 2 | 93.30 | 92.38 | 98.32 | 97.91 | 97.49 | 97.79 | 99.12 |
| Beet | 98.20 | 99.05 | 99.72 | 98.64 | 96.38 | 93.05 | 99.06 |
| Potato | 94.28 | 97.62 | 97.9 | 98.15 | 97.93 | 94.63 | 99.41 |
| Bare soil | 55.1 | 100 | 97.93 | 39.05 | 67.78 | 98.62 | 98.51 |
| Grass | 81.96 | 97.14 | 94.28 | 80.34 | 89.93 | 94.34 | 98.19 |
| Rapeseed | 81.66 | 86.67 | 99.05 | 74.01 | 96.20 | 97.29 | 98.12 |
| Barley | 95.15 | 90.48 | 98.08 | 100.0 | 91.72 | 97.21 | 98.38 |
| Wheat 1 | 80.88 | 100 | 85.53 | 93.38 | 93.83 | 96.81 | 98.01 |
| Wheat 3 | 96.49 | 99.53 | 99.39 | 99.94 | 98.02 | 97.52 | 99.09 |
| Water | 99.69 | 80.11 | 68.78 | 91.02 | 98.28 | 98.06 | 99.34 |
| Building | 95.59 | 99.52 | 88.22 | 0.0 | 82.07 | 93.91 | 96.71 |
| OA | 92.41 | 95.24 | 94.68 | 93.11 | 96.05 | 98.29 | 98.90 |
| AA | 90.46 | 95.09 | 94.89 | 84.62 | 93.30 | 98.12 | 98.69 |
| mIoU | 84.84 | 91.01 | 89.10 | 78.92 | 89.52 | 96.41 | 97.52 |
| mDice | 90.76 | 95.17 | 93.39 | 84.38 | 94.25 | 98.17 | 98.74 |
| Kappa | 0.9134 | 0.9357 | 0.9465 | 0.9209 | 0.9567 | 0.9826 | 0.9879 |
| Class | SVM- PB | CNN- PB | U-Net- DS | SETR- DS | U-Net- DA | SETR- DA | Ours- DA |
|---|---|---|---|---|---|---|---|
| Potato | 99.70 | 99.52 | 99.39 | 99.46 | 99.86 | 99.10 | 99.72 |
| Fruit | 99.98 | 100.0 | 99.04 | 92.63 | 96.99 | 99.58 | 99.49 |
| Oats | 88.89 | 100.0 | 97.67 | 88.94 | 95.06 | 99.54 | 97.52 |
| Beet | 97.62 | 94.25 | 98.28 | 99.48 | 99.50 | 97.94 | 99.51 |
| Barley | 99.58 | 97.61 | 99.63 | 99.41 | 99.76 | 98.73 | 99.68 |
| Onions | 31.93 | 90.47 | 86.13 | 67.43 | 85.92 | 97.69 | 97.26 |
| Wheat | 99.76 | 96.67 | 99.85 | 99.95 | 99.76 | 98.67 | 99.67 |
| Beans | 94.05 | 92.38 | 100.0 | 100.0 | 90.33 | 93.51 | 97.84 |
| Peas | 99.93 | 100 | 99.75 | 86.57 | 97.47 | 97.94 | 98.97 |
| Maize | 79.21 | 98.10 | 1.57 | 0.00 | 93.10 | 95.95 | 97.56 |
| Flax | 98.50 | 94.76 | 99.95 | 79.5 | 99.17 | 98.93 | 99.30 |
| Rapeseed | 99.31 | 99.53 | 99.80 | 99.9 | 99.84 | 98.38 | 99.73 |
| Grass | 93.88 | 97.71 | 98.15 | 94.86 | 98.03 | 97.75 | 98.71 |
| Lucerne | 93.91 | 96.67 | 97.76 | 94.70 | 97.72 | 99.12 | 98.71 |
| OA | 97.69 | 96.80 | 98.16 | 96.67 | 99.12 | 99.21 | 99.51 |
| AA | 91.17 | 96.98 | 91.21 | 85.92 | 96.61 | 98.75 | 98.83 |
| mIoU | 86.69 | 87.78 | 82.79 | 76.27 | 94.89 | 97.96 | 98.14 |
| mDice | 91.23 | 90.39 | 84.35 | 80.28 | 97.29 | 98.96 | 99.06 |
| Kappa | 0.9438 | 0.9674 | 0.9780 | 0.9603 | 0.9896 | 0.9906 | 0.9940 |
| Class | SVM- PB | CNN- PB | U-Net- DS | SETR- DS | U-Net- DA | SETR- DA | Ours- DA |
|---|---|---|---|---|---|---|---|
| Build-up | 61.17 | 58.37 | 68.47 | 84.61 | 87.42 | 78.19 | 91.83 |
| Wood Land | 80.29 | 98.55 | 98.54 | 95.88 | 91.55 | 83.53 | 91.59 |
| Open Areas | 98.11 | 87.98 | 95.26 | 98.77 | 97.05 | 71.78 | 98.12 |
| OA | 85.52 | 81.85 | 88.65 | 94.47 | 93.61 | 78.67 | 95.32 |
| AA | 79.86 | 81.63 | 87.42 | 93.09 | 92.01 | 77.83 | 93.85 |
| mIoU | 69.22 | 68.84 | 75.64 | 88.14 | 86.39 | 64.17 | 89.60 |
| mDice | 80.92 | 81.04 | 85.80 | 93.62 | 92.59 | 78.11 | 94.46 |
| Kappa | 0.7814 | 0.8126 | 0.8064 | 0.9048 | 0.8862 | 0.5976 | 0.9176 |
| Dataset | Method | OA | AA | mIoU | mDice | Kappa |
|---|---|---|---|---|---|---|
| Flevoland I | Base Method + FM + CLA + FM + CLA | 96.05 | 93.30 | 89.52 | 94.25 | 0.9567 |
| 98.51 | 98.05 | 95.46 | 98.19 | 0.9836 | ||
| 97.86 | 97.00 | 94.82 | 97.32 | 0.9765 | ||
| 98.90 | 98.69 | 97.52 | 98.74 | 0.9879 | ||
| Flevoland II | Base Method + FM + CLA + FM + CLA | 99.12 | 96.61 | 94.89 | 97.29 | 0.9896 |
| 99.21 | 98.75 | 97.96 | 98.96 | 0.9906 | ||
| 99.18 | 98.55 | 97.77 | 98.86 | 0.9902 | ||
| 99.51 | 98.83 | 98.14 | 99.06 | 0.9940 | ||
| Oberpfaffenhofen | Base Method + FM + CLA + FM + CLA | 93.61 | 92.01 | 86.39 | 92.59 | 0.8862 |
| 94.84 | 93.00 | 88.63 | 93.91 | 0.9087 | ||
| 94.96 | 93.76 | 88.89 | 94.07 | 0.9113 | ||
| 95.32 | 93.85 | 89.60 | 94.46 | 0.9176 |
| Dataset | OA | AA | mIoU | mDice | Kappa | |
|---|---|---|---|---|---|---|
| Flevoland I | 8 × 8 | 96.83 | 95.67 | 92.35 | 95.96 | 0.9652 |
| 16 × 16 | 98.90 | 98.69 | 97.52 | 98.74 | 0.9879 | |
| 32 × 32 | 98.26 | 97.87 | 96.38 | 98.16 | 0.9702 | |
| Flevoland II | 8 × 8 | 93.80 | 68.98 | 62.82 | 66.51 | 0.9265 |
| 16 × 16 | 99.51 | 98.83 | 98.14 | 99.06 | 0.9940 | |
| 32 × 32 | 96.87 | 80.96 | 76.23 | 79.60 | 0.9630 | |
| Oberpfaffenhofen | 8 × 8 | 88.25 | 85.99 | 76.01 | 86.11 | 0.7867 |
| 16 × 16 | 95.32 | 93.85 | 89.60 | 94.46 | 0.9176 | |
| 32 × 32 | 96.99 | 96.32 | 93.44 | 96.58 | 0.9476 |
| Preprocessing | Patch Base | Direct Segmentation | Data Augmentation |
|---|---|---|---|
| Construct Patch | √ | × | × |
| Cut and Merge | × | √ | × |
| Global Inference | × | × | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, Z.; Qiu, X.; Zhang, Z. Global Polarimetric Synthetic Aperture Radar Image Segmentation with Data Augmentation and Hybrid Architecture Model. Remote Sens. 2024, 16, 380. https://doi.org/10.3390/rs16020380
Wang Z, Wang Z, Qiu X, Zhang Z. Global Polarimetric Synthetic Aperture Radar Image Segmentation with Data Augmentation and Hybrid Architecture Model. Remote Sensing. 2024; 16(2):380. https://doi.org/10.3390/rs16020380
Chicago/Turabian StyleWang, Zehua, Zezhong Wang, Xiaolan Qiu, and Zhe Zhang. 2024. "Global Polarimetric Synthetic Aperture Radar Image Segmentation with Data Augmentation and Hybrid Architecture Model" Remote Sensing 16, no. 2: 380. https://doi.org/10.3390/rs16020380
APA StyleWang, Z., Wang, Z., Qiu, X., & Zhang, Z. (2024). Global Polarimetric Synthetic Aperture Radar Image Segmentation with Data Augmentation and Hybrid Architecture Model. Remote Sensing, 16(2), 380. https://doi.org/10.3390/rs16020380