
HeightFormer: A Multilevel Interaction and Image-Adaptive Classification–Regression Network for Monocular Height Estimation with Aerial Images



 , and
, and
Abstract
1. Introduction
2. Related Work
2.1. Overview
2.2. Height Estimation Based on Manual Features
2.3. Height Estimation Based on CNN
2.4. Attention and Transformer in Remote Sensing
2.4.1. Attention Mechanism and Transformer
2.4.2. Transformers Applied in Remote Sensing
3. Methodology
3.1. Overview
3.2. Multilevel Interactive Backbone
3.2.1. Convolution-Based Pixel Interaction Backbone
3.2.2. Transformer-Based Patch Interaction Backbone
3.2.3. Heterogeneous Feature Coupling
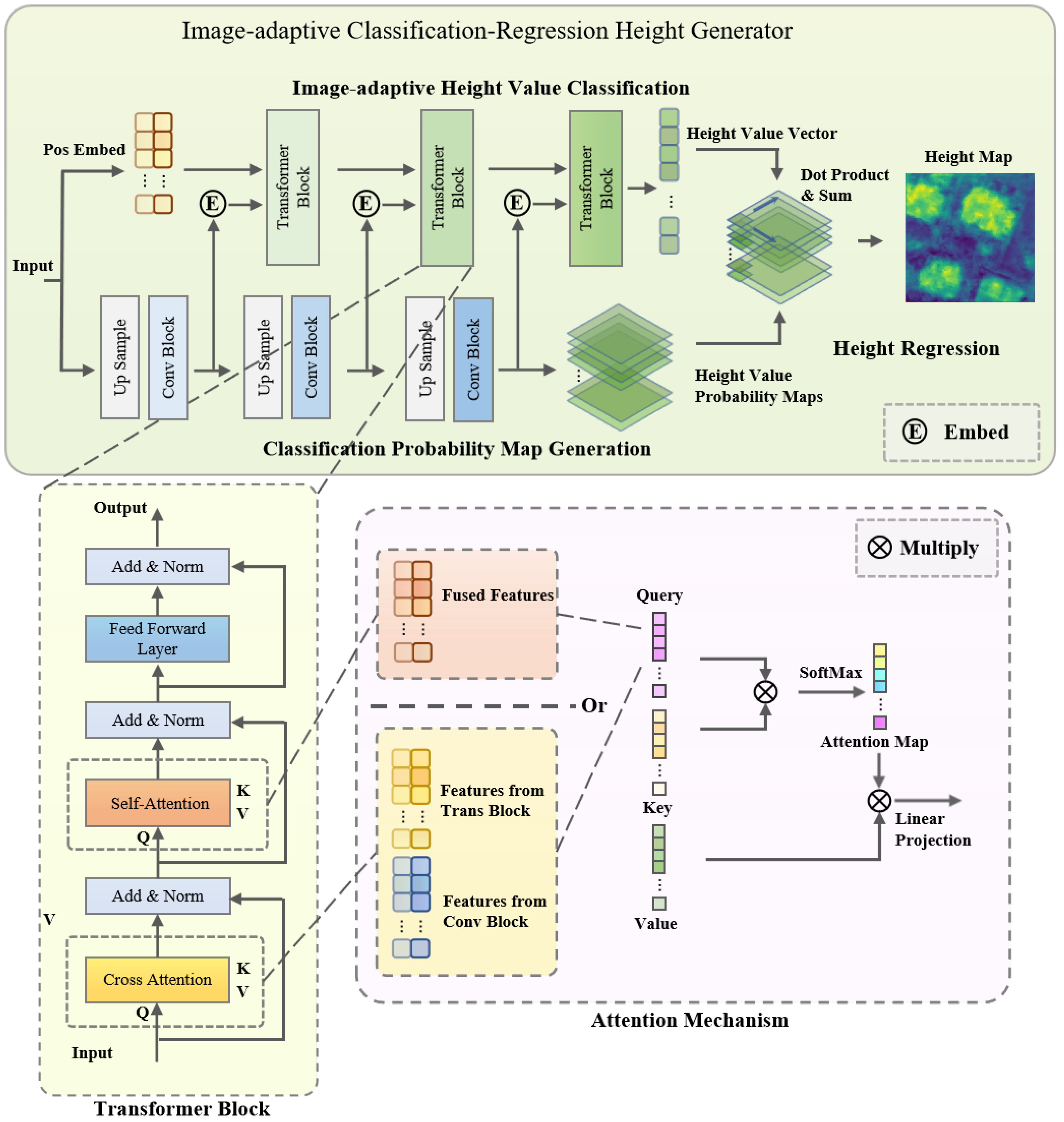
3.3. Image-Adaptive Classification–Regression Height Generator
3.3.1. Image-adaptive Height Value Classification
3.3.2. Classification Probability Map Generation
3.3.3. Height Regression
3.4. Loss Function
4. Experiment
4.1. Datasets
4.2. Metrics
4.3. Experimental Settings
4.3.1. Hardware Platform and Libraries
4.3.2. Training
4.3.3. Data Augmentation
5. Results
5.1. Quantitative and Qualitative Analysis on Vaihingen
5.2. Ablation Study on Vaihingen
5.2.1. Ablation of Multilevel Interaction Backbone (MIB)
5.2.2. Ablation of Image-Adaptive Classification–Regression Height Generator (ICG)
5.3. Method Comparison of the Computational Power Consumption
5.4. Quantitative and Qualitative Analysis on Potsdam
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Benediktsson, J.A.; Chanussot, J.; Moon, W.M. Very high-resolution remote sensing: Challenges and opportunities. Proc. IEEE 2012, 100, 1907–1910. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote. Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, H.; Zhu, Y.; Song, M. A review of 3D reconstruction from high-resolution urban satellite images. Int. J. Remote Sens. 2023, 44, 713–748. [Google Scholar] [CrossRef]
- Mahabir, R.; Croitoru, A.; Crooks, A.T.; Agouris, P.; Stefanidis, A. A critical review of high and very high-resolution remote sensing approaches for detecting and mapping slums: Trends, challenges and emerging opportunities. Urban Sci. 2018, 2, 8. [Google Scholar] [CrossRef]
- Coronado, E.; Itadera, S.; Ramirez-Alpizar, I.G. Integrating Virtual, Mixed, and Augmented Reality to Human–Robot Interaction Applications Using Game Engines: A Brief Review of Accessible Software Tools and Frameworks. Appl. Sci. 2023, 13, 1292. [Google Scholar] [CrossRef]
- Takaku, J.; Tadono, T.; Kai, H.; Ohgushi, F.; Doutsu, M. An Overview of Geometric Calibration and DSM Generation for ALOS-3 Optical Imageries. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 383–386. [Google Scholar]
- Estornell, J.; Ruiz, L.; Velázquez-Martí, B.; Hermosilla, T. Analysis of the factors affecting LiDAR DTM accuracy in a steep shrub area. Int. J. Digit. Earth 2011, 4, 521–538. [Google Scholar] [CrossRef]
- Nemmaoui, A.; Aguilar, F.J.; Aguilar, M.A.; Qin, R. DSM and DTM generation from VHR satellite stereo imagery over plastic covered greenhouse areas. Comput. Electron. Agric. 2019, 164, 104903. [Google Scholar] [CrossRef]
- Hoja, D.; Reinartz, P.; Schroeder, M. Comparison of DEM generation and combination methods using high resolution optical stereo imagery and interferometric SAR data. Rev. Française Photogramm. Télédétect. 2007, 2006, 89–94. [Google Scholar]
- Xiaotian, S.; Guo, Z.; Xia, W. High-precision DEM production for spaceborne stereo SAR images based on SIFT matching and region-based least squares matching. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 39, 49–53. [Google Scholar] [CrossRef]
- Li, Q.; Zhu, J.; Liu, J.; Cao, R.; Li, Q.; Jia, S.; Qiu, G. Deep learning based monocular depth prediction: Datasets, methods and applications. arXiv 2020, arXiv:2011.04123. [Google Scholar]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semi-supervised deep learning for monocular depth map prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6647–6655. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhao, S.; Luo, Y.; Zhang, T.; Guo, W.; Zhang, Z. A domain specific knowledge extraction transformer method for multisource satellite-borne SAR images ship detection. ISPRS J. Photogramm. Remote Sens. 2023, 198, 16–29. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Diao, W.; Yan, Z.; Yin, D.; Fu, K. Transformer-induced graph reasoning for multimodal semantic segmentation in remote sensing. ISPRS J. Photogramm. Remote Sens. 2022, 193, 90–103. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4009–4018. [Google Scholar]
- Sun, W.; Zhang, Y.; Liao, Y.; Yang, B.; Lin, M.; Zhai, R.; Gao, Z. Rethinking Monocular Height Estimation From a Classification Task Perspective Leveraging the Vision Transformer. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wojek, C.; Walk, S.; Roth, S.; Schindler, K.; Schiele, B. Monocular visual scene understanding: Understanding multi-object traffic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 882–897. [Google Scholar] [CrossRef] [PubMed]
- Goetz, J.; Brenning, A.; Marcer, M.; Bodin, X. Modeling the precision of structure-from-motion multi-view stereo digital elevation models from repeated close-range aerial surveys. Remote Sens. Environ. 2018, 210, 208–216. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Li, X.; Wen, C.; Wang, L.; Fang, Y. Geometry-aware segmentation of remote sensing images via joint height estimation. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. IM2HEIGHT: Height estimation from single monocular imagery via fully residual convolutional-deconvolutional network. arXiv 2018, arXiv:1802.10249. [Google Scholar]
- Yu, D.; Ji, S.; Liu, J.; Wei, S. Automatic 3D building reconstruction from multi-view aerial images with deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 171, 155–170. [Google Scholar] [CrossRef]
- Mahdi, E.; Ziming, Z.; Xinming, H. Aerial height prediction and refinement neural networks with semantic and geometric guidance. arXiv 2020, arXiv:2011.10697. [Google Scholar]
- Batra, D.; Saxena, A. Learning the right model: Efficient max-margin learning in laplacian crfs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2136–2143. [Google Scholar]
- Saxena, A.; Chung, S.; Ng, A. Learning depth from single monocular images. Adv. Neural Inf. Process. Syst. 2005, 18, 1–16. [Google Scholar]
- Saxena, A.; Schulte, J.; Ng, A.Y. Depth Estimation Using Monocular and Stereo Cues. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 2197–2203. [Google Scholar]
- Liu, M.; Salzmann, M.; He, X. Discrete-continuous depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 716–723. [Google Scholar]
- Zhuo, W.; Salzmann, M.; He, X.; Liu, M. Indoor scene structure analysis for single image depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 614–622. [Google Scholar]
- Zhang, Y.; Yan, Z.; Sun, X.; Lu, X.; Li, J.; Mao, Y.; Wang, L. Bridging the Gap Between Cumbersome and Light Detectors via Layer-Calibration and Task-Disentangle Distillation in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–18. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, Z.; Sun, X.; Diao, W.; Fu, K.; Wang, L. Learning efficient and accurate detectors with dynamic knowledge distillation in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ghamisi, P.; Yokoya, N. IMG2DSM: Height simulation from single imagery using conditional generative adversarial net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 794–798. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X. Multi-path fusion network for high-resolution height estimation from a single orthophoto. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 186–191. [Google Scholar]
- Li, X.; Wang, M.; Fang, Y. Height estimation from single aerial images using a deep ordinal regression network. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Carvalho, M.; Le Saux, B.; Trouvé-Peloux, P.; Almansa, A.; Champagnat, F. On regression losses for deep depth estimation. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2915–2919. [Google Scholar]
- Zhu, J.; Ma, R. Real-Time Depth Estimation from 2D Images. 2016. Available online: http://cs231n.stanford.edu/reports/2016/pdfs/407_Report.pdf (accessed on 1 December 2023).
- Xiong, Z.; Huang, W.; Hu, J.; Zhu, X.X. THE benchmark: Transferable representation learning for monocular height estimation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5620514. [Google Scholar] [CrossRef]
- Tao, H. A label-relevance multi-direction interaction network with enhanced deformable convolution for forest smoke recognition. Expert Syst. Appl. 2024, 236, 121383. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, J.; Du, B.; Zhang, L. From center to surrounding: An interactive learning framework for hyperspectral image classification. ISPRS J. Photogramm. Remote Sens. 2023, 197, 145–166. [Google Scholar] [CrossRef]
- Chen, S.; Ogawa, Y.; Zhao, C.; Sekimoto, Y. Large-scale individual building extraction from open-source satellite imagery via super-resolution-based instance segmentation approach. ISPRS J. Photogramm. Remote Sens. 2023, 195, 129–152. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Wang, B.; Zhu, Z.; Diao, W.; Yang, M.Y. AST: Adaptive Self-supervised Transformer for optical remote sensing representation. ISPRS J. Photogramm. Remote Sens. 2023, 200, 41–54. [Google Scholar] [CrossRef]
- Li, Z.; Wang, X.; Liu, X.; Jiang, J. Binsformer: Revisiting adaptive bins for monocular depth estimation. arXiv 2022, arXiv:2204.00987. [Google Scholar]
- Li, Z.; Chen, Z.; Liu, X.; Jiang, J. Depthformer: Exploiting long-range correlation and local information for accurate monocular depth estimation. arXiv 2022, arXiv:2203.14211. [Google Scholar] [CrossRef]
- Amirkolaee, H.A.; Arefi, H. Height estimation from single aerial images using a deep convolutional encoder-decoder network. ISPRS J. Photogramm. Remote Sens. 2019, 149, 50–66. [Google Scholar] [CrossRef]
- Zhou, L.; Cui, Z.; Xu, C.; Zhang, Z.; Wang, C.; Zhang, T.; Yang, J. Pattern-structure diffusion for multi-task learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4514–4523. [Google Scholar]
- Ramamonjisoa, M.; Firman, M.; Watson, J.; Lepetit, V.; Turmukhambetov, D. Single image depth prediction with wavelet decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11089–11098. [Google Scholar]
- Yin, W.; Zhang, J.; Wang, O.; Niklaus, S.; Mai, L.; Chen, S.; Shen, C. Learning to recover 3d scene shape from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 204–213. [Google Scholar]
- Liu, W.; Sun, X.; Zhang, W.; Guo, Z.; Fu, K. Associatively segmenting semantics and estimating height from monocular remote-sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Mao, Y.; Chen, K.; Zhao, L.; Chen, W.; Tang, D.; Liu, W.; Wang, Z.; Diao, W.; Sun, X.; Fu, K. Elevation Estimation-Driven Building 3D Reconstruction from Single-View Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608718. [Google Scholar] [CrossRef]
- Wang, Y.; Ding, W.; Zhang, R.; Li, H. Boundary-Aware Multitask Learning for Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 951–963. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Ref | Rel↓ | RMSE(log)↓ | 1↑ | 2↑ | 3↑ |
|---|---|---|---|---|---|---|
| D3Net [38] | ICIP 2018 | 2.016 | - | - | - | - |
| Amirkolaee et al. [53] | ISPRS 2019 | 1.163 | 0.334 | 0.330 | 0.572 | 0.741 |
| PSDNet [54] | CVPR 2020 | 0.363 | 0.171 | 0.447 | 0.745 | 0.906 |
| Li et al. [37] | GRSL 2020 | 0.314 | 0.155 | 0.451 | 0.817 | 0.939 |
| WMD [55] | CVPR 2021 | 0.272 | - | 0.543 | 0.798 | 0.916 |
| LeReS [56] | CVPR 2021 | 0.260 | - | 0.554 | 0.800 | 0.932 |
| ASSEH [57] | TGRS 2022 | 0.237 | 0.120 | 0.595 | 0.860 | 0.971 |
| DepthFormer [52] | CVPR 2022 | 0.212 | 0.080 | 0.716 | 0.927 | 0.967 |
| BinsFormer [51] | CVPR 2022 | 0.203 | 0.076 | 0.745 | 0.931 | 0.975 |
| SFFDE [58] | TGRS 2023 | 0.222 | 0.084 | 0.595 | 0.897 | 0.970 |
| HeightFormer | - | 0.185 | 0.074 | 0.756 | 0.941 | 0.973 |
| Pixel- | Patch- | HFC | Rel ↓ | RMSE(log)↓ | 1↑ | 2↑ | 3↑ |
|---|---|---|---|---|---|---|---|
| √ | - | - | 0.281 | 0.113 | 0.564 | 0.794 | 0.947 |
| - | √ | - | 0.203 | 0.077 | 0.624 | 0.895 | 0.959 |
| √ | √ | √ | 0.185 | 0.074 | 0.756 | 0.941 | 0.973 |
| Type | N (Num of Height) | Rel↓ | RMSE(log)↓ | 1↑ | 2↑ | 3↑ |
|---|---|---|---|---|---|---|
| Fixed | 8 | 0.402 | 0.179 | 0.463 | 0.725 | 0.845 |
| 16 | 0.356 | 0.156 | 0.502 | 0.747 | 0.859 | |
| 32 | 0.314 | 0.129 | 0.581 | 0.813 | 0.862 | |
| 64 | 0.288 | 0.118 | 0.619 | 0.846 | 0.877 | |
| 128 | 0.263 | 0.114 | 0.653 | 0.836 | 0.912 | |
| 256 | 0.267 | 0.118 | 0.639 | 0.826 | 0.920 | |
| Image-adaptive | 8 | 0.341 | 0.135 | 0.458 | 0.742 | 0.903 |
| 16 | 0.307 | 0.119 | 0.519 | 0.795 | 0.938 | |
| 32 | 0.203 | 0.076 | 0.714 | 0.935 | 0.965 | |
| 64 | 0.185 | 0.074 | 0.756 | 0.941 | 0.973 | |
| 128 | 0.191 | 0.075 | 0.737 | 0.921 | 0.967 | |
| 256 | 0.224 | 0.084 | 0.673 | 0.901 | 0.959 |
| Method | Ref | Parameters | FPS |
|---|---|---|---|
| Li et al. [37] | GRSL 2020 | - | 8.7 |
| DepthsFormer [52] | CVPR 2022 | 273 M | 8.2 |
| BinsFormer [51] | CVPR 2022 | 254 M | 8.0 |
| SFFDE [58] | TGRS 2023 | >60 M | 8.7 |
| HeightFormer | - | 46 M | 10.8 |
| Method | Ref | Rel↓ | RMSE(log)↓ | 1↑ | 2↑ | 3↑ |
|---|---|---|---|---|---|---|
| Amirkolaee et al. [53] | ISPRS 2019 | 0.571 | 0.259 | 0.342 | 0.601 | 0.782 |
| BAMTL [59] | J-STARS 2020 | 0.291 | - | 0.685 | 0.819 | 0.897 |
| DepthsFormer [52] | CVPR 2022 | 0.123 | 0.050 | 0.871 | 0.981 | 0.997 |
| BinsFormer [51] | CVPR 2022 | 0.117 | 0.049 | 0.876 | 0.989 | 0.999 |
| HeightFormer | - | 0.104 | 0.043 | 0.893 | 0.987 | 0.997 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, Y.; Qi, X.; Mao, Y.; Zhou, X.; Wang, L.; Ge, Y. HeightFormer: A Multilevel Interaction and Image-Adaptive Classification–Regression Network for Monocular Height Estimation with Aerial Images. Remote Sens. 2024, 16, 295. https://doi.org/10.3390/rs16020295
Chen Z, Zhang Y, Qi X, Mao Y, Zhou X, Wang L, Ge Y. HeightFormer: A Multilevel Interaction and Image-Adaptive Classification–Regression Network for Monocular Height Estimation with Aerial Images. Remote Sensing. 2024; 16(2):295. https://doi.org/10.3390/rs16020295
Chicago/Turabian StyleChen, Zhan, Yidan Zhang, Xiyu Qi, Yongqiang Mao, Xin Zhou, Lei Wang, and Yunping Ge. 2024. "HeightFormer: A Multilevel Interaction and Image-Adaptive Classification–Regression Network for Monocular Height Estimation with Aerial Images" Remote Sensing 16, no. 2: 295. https://doi.org/10.3390/rs16020295
APA StyleChen, Z., Zhang, Y., Qi, X., Mao, Y., Zhou, X., Wang, L., & Ge, Y. (2024). HeightFormer: A Multilevel Interaction and Image-Adaptive Classification–Regression Network for Monocular Height Estimation with Aerial Images. Remote Sensing, 16(2), 295. https://doi.org/10.3390/rs16020295