1. Introduction
In recent years, extreme weather events have become increasingly frequent due to global warming, highlighting the urgent need to enhance the accuracy and reliability of weather forecasting systems. Weather forecasting methods can be broadly classified into two main categories: numerical weather prediction (NWP) and radar echo extrapolation.
NWP is a method that involves using the spatial distribution of meteorological variables at a given time as initial conditions and solving complex physical equations with specified boundary conditions to simulate future atmospheric motions and obtain weather forecasts [
1]. However, NWP methods face challenges, such as difficulties in solving the system of differential equations, resulting in forecast delays and a low forecast resolution. Additionally, NWP models have a noticeable spin-up issue in short-term forecasting. Therefore, radar echo extrapolation methods are more likely to be used in nowcasting. Radar echo extrapolation is of great significance for obtaining early warnings of severe convective weather, such as heavy precipitation, typhoons, and hail.
Currently, traditional radar echo extrapolation methods mainly include centroid tracking [
2,
3,
4], cross-correlation [
5,
6,
7], and optical flow [
8,
9]. The centroid tracking method predicts the evolution of centroid positions in the future based on the trend of centroid position changes in radar echoes. This method relies solely on extrapolating centroid positions and does not consider more complex physical processes and dynamic effects. As a result, its predictive accuracy is limited, especially in complex weather conditions. The cross-correlation method calculates cross-correlation coefficients by comparing consecutive radar echo images, aiming to find the best-matching evolution trend of echo images and enable the tracking and extrapolation of individual storm cells. However, when the shape of the echo changes rapidly, the algorithm may yield low cross-correlation coefficients, making it challenging to achieve matching and extrapolation for echo forecasting. The optical flow method was first developed in the field of computer vision. It calculates the velocity field for each pixel by analyzing the pixel variations and the correlation between consecutive frames of an image sequence. This allows for the estimation of motion in future frames. The optical flow method assumes that the motion of objects in an image follows rigid body motion, meaning that the entire object moves with the same speed and in the same direction. However, radar echoes are often influenced by atmospheric conditions and terrain, leading to non-rigid movements such as spreading, bending, and rotation. These non-rigid motions can result in inaccurate motion estimation when using the optical flow method for radar echo extrapolation.
With the rapid development of deep learning techniques, the application of artificial intelligence in short-term weather forecasting has received significant attention. Among various approaches, methods based on recurrent neural networks (RNNs) are widely used in spatiotemporal sequence prediction. A milestone work in this field is the ConvLSTM proposed by Shi et al. [
10]. By employing an encoding–prediction structure, the radar echo extrapolation problem is transformed into a spatiotemporal sequence prediction problem. Using convolution instead of the fully connected layer, LSTM can extract spatial features while reducing the number of network parameters. Wang et al. [
11] proposed the PredRNN based on the ConvLSTM. Compared with the ConvLSTM, a spatiotemporal memory unit is added and connected through a Z-shaped structure so that the memory unit can obtain the information of all layers at the previous moment. However, more gates are needed to control the flow of information, causing the model to become more complex. Wang et al. [
12] proposed the Memory In Memory (MIM), which replaces the forget gate with two cascaded MIM-S and MIM-N modules. At the same time, oblique propagation paths are added in adjacent moments to enhance feature propagation at different moments. Wu et al. [
13] proposed the MotionRNN, which can be flexibly used in many prediction models such as ConvLSTM, PredRNN, and MIM to enhance these models’ spatiotemporal information transmission capabilities. Geng et al. [
14] proposed the MCCS-LSTM. MCCS-LSTM integrates the attention mechanism into the ConvLSTM, improving the model context utilization. In the GAN-rcLSTM [
15] proposed by Geng et al., the residual module alleviates the problem of the echo intensity gradually weakening as the prediction time increases. However, due to the characteristics of recurrent neural networks that recursively generate future frames, as the number of prediction times increases, the model prediction error gradually increases, resulting in poor prediction results.
Some convolutional neural network models are also used in spatiotemporal sequence prediction tasks. A precipitation forecast with a spatial resolution of 1 km in the next hour is obtained using radar echo data and training with the U-Net based on CNN. The forecast accuracy is improved compared with the model based on optical flow methods [
16]. Gao et al. [
17] proposed the SimVP and constructed a simple and efficient video prediction network by adding a U-shaped Inception module. Trebing [
18] proposed the SmaAt-UNet, which adds an attention mechanism and depth-separable convolution to the UNet; it can better extract spatiotemporal information, and its effect is better than that of the traditional UNet. Wu et al. [
19] used a combination of 3D convolution and LSTM to predict precipitation in a specific area. Due to a CNN’s lack of extraction of temporal features, the prediction effect is obviously insufficient for long-term prediction tasks.
Since Transformer was proposed in natural language processing, networks based on Transformer have achieved outstanding results in various deep learning fields such as computer vision, text image generation, and speech processing. Due to its powerful modeling capabilities for complex conditions and long-term dependencies, people have begun to pay attention to how to apply the Transformer architecture to short-term weather forecasting tasks. FourCastNet [
20], a neural network forecast model based on the Fourier transform, uses the Transformer framework to provide global precipitation forecasts with a higher spatial resolution. Yang et al. [
21] proposed the TCTN, which combines 3D Conv and attention mechanisms to extract short-term and long-term relationships. However, a recursive generation mode like a RNN is still used in the model inference stage, causing errors to accumulate as the time series increases, causing problems such as inaccurate extrapolation results and blurred radar echoes. Wang et al. [
22] proposed the Earthformer, which limits the scope of the attention mechanism within the cube and uses a global vector to focus on all cubes to achieve the purpose of global modeling. This method reduces the computational overhead of the attention mechanism and is an improvement compared to the traditional RNN method on the MovingMNIST dataset. However, cutting the cube often leads to some problems. For example, a large echo area exceeds the cube’s side length. Cutting the cube will cause the echoes that were originally in the same area to be allocated to different cubes, thereby increasing the difficulty of model processing. However, relying only on global vectors cannot achieve the effect of global modeling, resulting in poor extrapolation effects in radar echo extrapolation tasks because long-term and global dependencies cannot be established. It is challenging to reduce the model’s computational overhead while ensuring its modeling capabilities.
To address the issues of blurriness and intensity decay in radar echo extrapolation, we propose a new multi-scale encoder–decoder structure Transformer model. By incorporating the multi-resolution (MR) branch, we effectively enhance the model’s focus on local details of the echo while improving its ability to discern the overall echo movement trend. This approach alleviates the blurriness issue in radar echoes and enhances the accuracy of the model’s predictions. At the same time, we also use a non-autoregressive radar echo sequence generation mode to avoid errors accumulating over time and alleviate the problem of the radar echo intensity weakening.
Since ViT [
23] was proposed, the Patch Embedding layer has been widely used in computer vision. However, due to its inability to establish interactions between features of different scales, Wang et al. [
24] proposed using patches of different sizes in the Patch Embedding layer, which helps the model learn cross-scale information. For radar echo extrapolation tasks, the model not only needs to pay attention to radar echo information at different scales but also needs to pay attention to the dependence of the echo in the long and short term. Therefore, we have made further improvements based on the Patch Embedding layer of the CrossFormer. We not only use multi-scale patches in the width and height dimensions of the input image but also perform multi-scale patch embedding in the time dimension according to the length of the input radar data.
In addition, we use the Spatial–Temporal Attention (STA) block to model the spatiotemporal information efficiently while reducing the computational overhead of the attention mechanism. The STA block incorporates the Window Attention and Shift Window Attention modules from the Video Swin Transformer [
25], as well as a dedicated Time Attention module focusing on the temporal dimension. In the Swin Transformer, a basic computational unit consists of two LayerNorm layers, a Shift Window/Window Attention module, and a multi-layer perceptron (MLP) layer. However, we found that directly applying the structural design of the Video Swin Transformer in radar echo extrapolation tasks incurred high computational costs and resulted in severe overfitting due to the excessive use of linear layers. In our proposed STA block, we combine the LayerNorm layer, Window Attention, Shift Window Attention, Time Attention, and parallel Spatial–Temporal Fusion (STF) layer with the MLP layer within a single unit. This approach reduces the computational cost while enhancing the model’s ability to extract temporal information. Due to the local nature of convolutional operations, the STF layer better captures local patterns and structural features of the input data.
Our main contributions can be summarized as follows:
A new encoder–decoder structure capable of extracting multi-scale information is proposed. By using radar echo features of different resolutions, we can ensure the precision of the radar echo and at the same time strengthen the judgment of the overall development trend of the radar echo.
A multi-scale Patch Embedding layer that focuses on both time and space helps the model obtain radar echo information from different time and space ranges.
A Spatial–Temporal Attention Block, which efficiently extracts spatiotemporal features and establishes long-term radar echo dependencies while reducing computational overhead as much as possible is developed.
The experimental results demonstrate the effectiveness and superiority of the proposed MS-RadarFormer compared to the competing methods for radar echo extrapolation tasks.
3. Methods
3.1. Overall Architecture
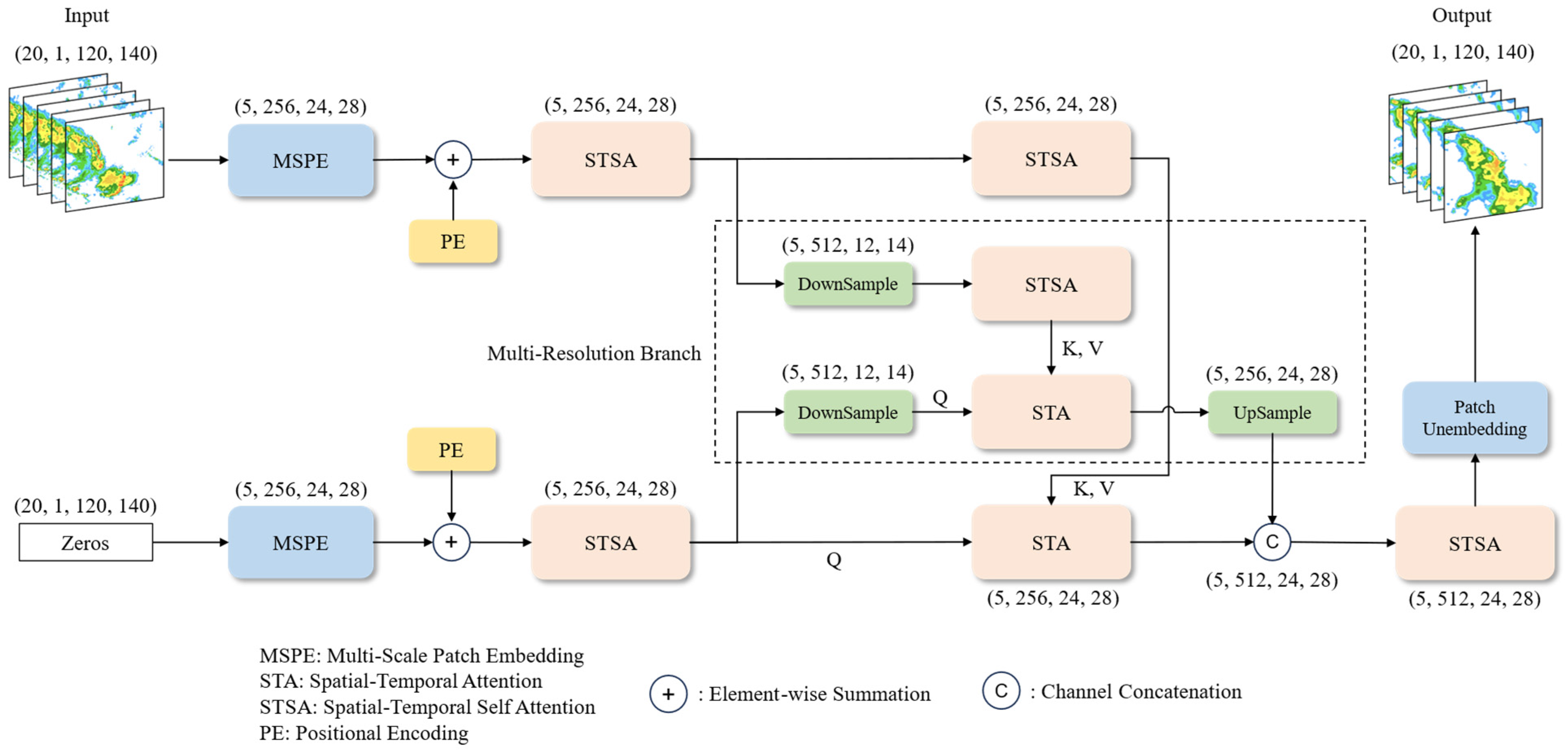
The model structure of MS-RadarFormer is shown in
Figure 1. For the radar echo extrapolation task of inputting 20 frames (2 h) of images to predict the next 20 frames (2 h) of images, the input shape is 20, 1, 120, and 140. The model consists of two parts: the encoder and the decoder.
The upper part of the model is the encoder, which is responsible for extracting the spatiotemporal information in the input radar echo sequence. This process plays a guiding role in the decoder’s generation of future radar echoes. The encoder first performs multi-scale patch embedding operations on the input image. It divides the image into small patches, which can reduce the input data’s size and the Transformer model’s computational pressure. Then, because the model cannot directly capture the timing and location information in the radar echo, it is necessary to add positional encoding to the embedded patches. The positional encoding method helps the model distinguish information from different locations at different times. We use learnable positional encoding to teach the optimal position representation during model training. After that, a Spatial–Temporal Self Attention (STSA) block is used to perform a preliminary information extraction on the input data. Then, the output features are input to the STSA blocks in two branches with different resolutions, where the number of STSA blocks is 6. The finally extracted high-dimensional features are input to the decoder as key and value.
The lower part of the model Is the decoder, which is responsible for making judgments on future radar echo trends based on the spatiotemporal features in the input sequence that is extracted by the encoder and the radar echo motion patterns that are summarized during the training process. This process is like human weather forecasters observing radar echoes in a past period, understanding the movement trends of radar echoes, and predicting future radar echoes based on their own experience. The decoder structure is like the encoder, using an all-zero metric as input and adding positional encoding after patch embedding. An STSA block is used to convert the position being encoded into two query vectors with different resolutions. In this way, query vectors corresponding to different positions are generated, helping the model capture and generate radar echoes from different areas accurately in the next stage. The query vector is input to the STA block to perform operations with the key and value vectors that are generated in the encoder. After the above calculation, we up-sample the coarse resolution result and perform a concatenate operation with the original resolution result. Then, the STSA block is used again to integrate high-dimensional features that combine different resolutions. The number of STSA blocks is 3. Finally, the predicted future radar echo image is obtained by mapping the high-dimensional radar echo features to the original image resolution through the Patch Unembedding layer.
3.2. Multi-Resolution Branch
To improve the prediction accuracy of the overall motion trend of large-scale echoes, we have introduced the MR branch. We perform down-sampling operations on the width and height dimensions of one branch in the network, providing the model with coarse-resolution information. While slightly increasing the computational cost, this enables the model to make overall estimations of the future development of radar echoes. The other branch maintains the original resolution and focuses on fine-grained information during the radar echo process, helping the model ensure the clarity of echo predictions. The reason for only performing down-sampling operations on the width and height dimensions is that for a radar echo extrapolation task of 0 to 2 h, the time dimension of the embedded patches is 5. If we also perform down-sampling operations on the time dimension, we need to perform pad operations on the data. However, pad operations would result in significant information loss during the up-sampling process due to the need for additional cropping operations. Although we cannot perform down-sampling on the time dimension to obtain different time resolutions of the information, we have introduced Temporal Attention to enhance the model’s ability to extract information from the time dimension. For more details on this, please refer to
Section 3.4.
3.3. Multi-Scale Patch Embedding and Patch Unembedding Layer
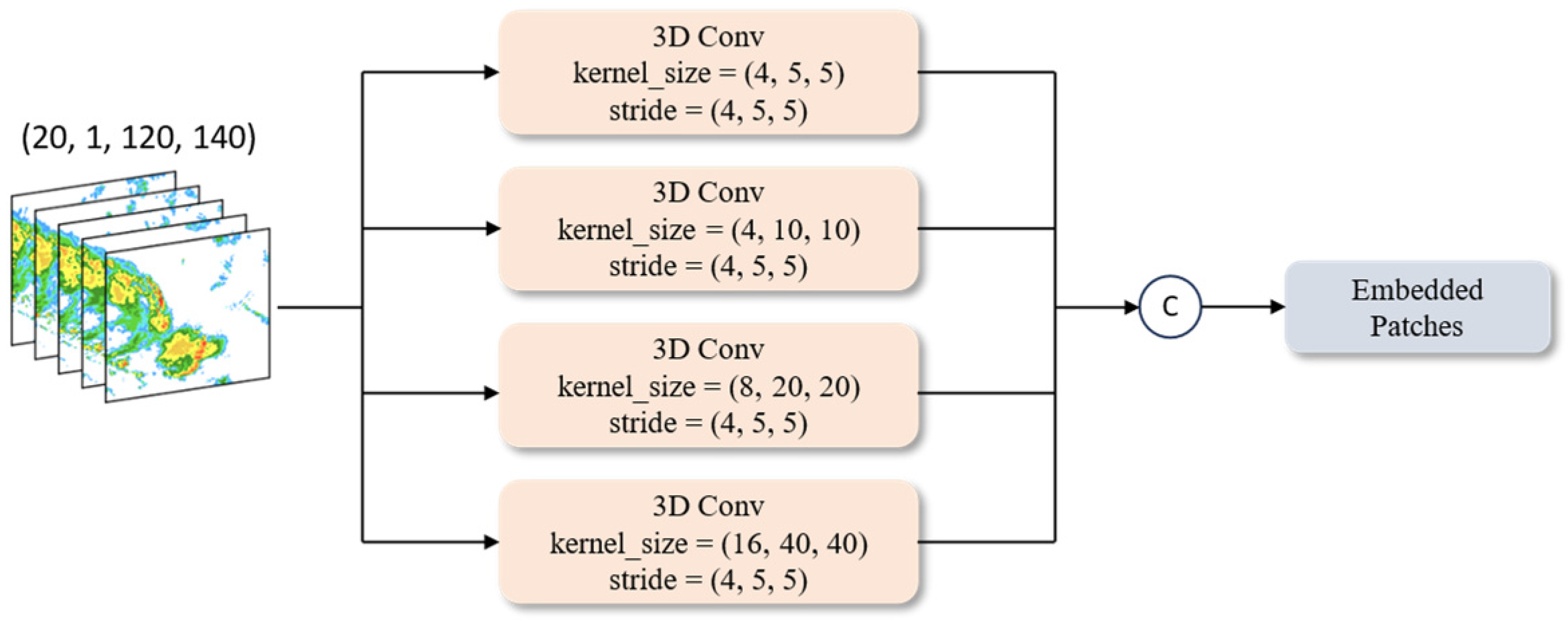
Due to the complex and diverse characteristics of radar echoes, radar echo data exhibit multiple spatial scales and complex temporal scales. Using the multi-scale Patch Embedding (MSPE) layer, the model can capture information from multiple spatial and temporal scales, helping it understand the spatiotemporal structure of the radar echo data and improve its ability to model radar echoes at different scales.
The MSPE layer takes the radar echo sequence as input and uses four 3D convolution operations to obtain the desired patches. These four convolutions have different kernel sizes and the same stride size, as shown in
Figure 2. We use pad operations to adjust the output dimensions to maintain consistent output dimensions. The formula for calculating the number of pixels that need to be padded is as follows:
where
represents the required padding size for the time dimension, height, and width, respectively;
represents the time dimension, height, and width of each convolutional kernel; and
represents the time dimension, height, and width of the smallest kernel size.
In addition, in each convolution operation of the MSPE, the out channels are set to 64. In the channel dimension, the output of each convolution operation is concatenated, resulting in the final shape of the embedded patches being (5, 256, 24, 28). The combination of MSPE and a multi-head attention mechanism will enhance the model’s feature extraction capability for input radar echoes, better capturing and learning the mechanisms of radar echo generation and dissipation. In the computation of the multi-head attention mechanism, the channel dimension will be segmented, allowing different heads to focus on processing information from different dimensions.
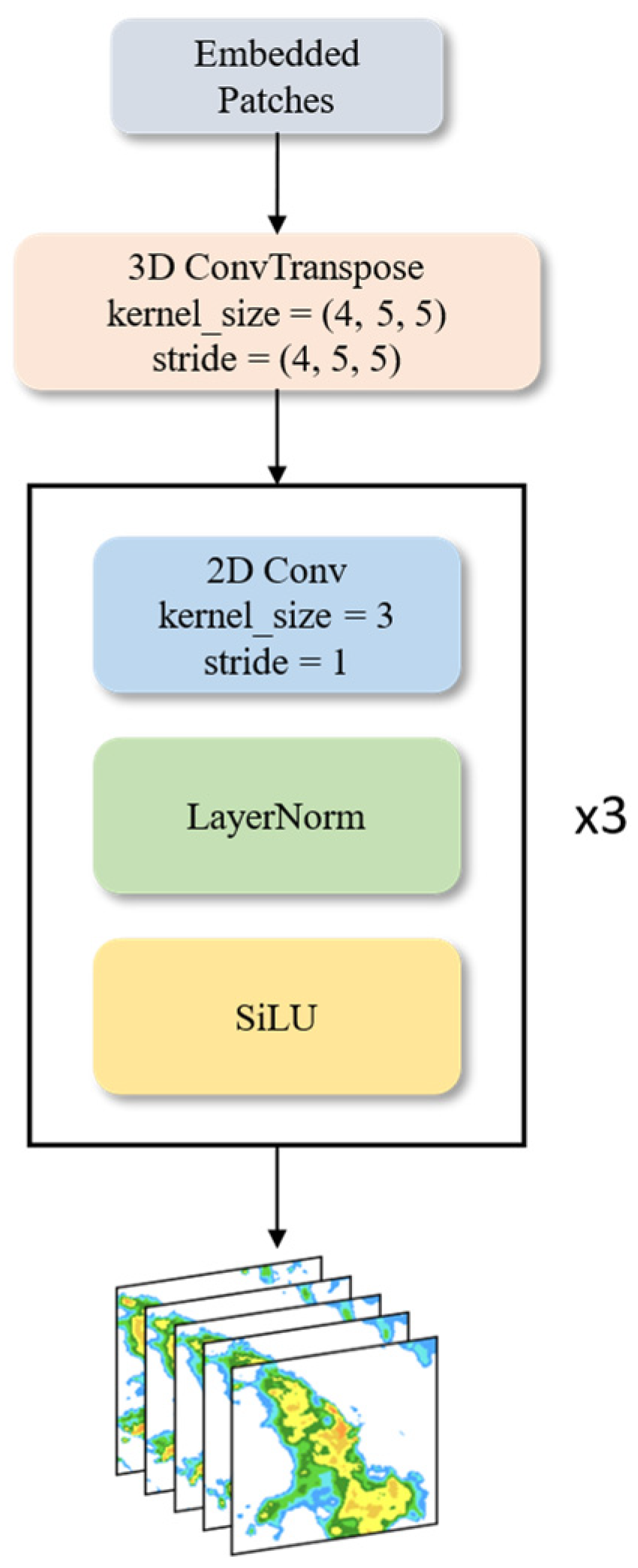
For the Patch Unembedding layer, we use a 3D ConvTranspose operation to restore the size of the feature map to the input size, keeping the number of channels unchanged. Then, the number of channels of the radar echo sequence is reduced through the combination of three groups of 2D Convolution, LayerNorm, and SiLU to obtain the final prediction result. The structure of the Patch Unembedding layer is shown in
Figure 3.
3.4. Spatial–Temporal Attention Block
The attention block in the vanilla transformer [
26] consists of two main modules: multi-head self-attention (MSA) and multi-layer perceptron (MLP). LayerNorm is also used before both MSA and MLP in each block. Applying the vanilla transformer directly to the extrapolation task will lead to a problem, in that converting input radar echo data directly into sequences will result in very long sequence lengths, leading to very high computational costs. The Video Swin Transformer, Window Attention, and Shift Window Attention are introduced to convert the quadratic computation complexity of the input image size into linear computation complexity, reducing the computational cost. A Video Swin Transformer block contains two consecutive modified transformer blocks, with the attention in the MSA module being replaced by Window Attention and Shift Window Attention, respectively. Using two transformer blocks as a computational unit in the Video Swin Transformer performs well in terms of object detection and image classification tasks. However, due to the lack of down-sampling of radar echo feature maps in radar echo extrapolation tasks, the excessive number of MLP parameters in the model easily leads to overfitting, affecting the effectiveness of radar echo extrapolation. To avoid this, in the proposed STA block, we no longer use two consecutive transformer blocks but instead merge Window Attention and Shift Window Attention into one block. In this way, under the same number of attention layers, the number of MLP layers is reduced by half, reducing the risk of overfitting while also reducing the network overhead.
The information from the time series is particularly important for the radar echo extrapolation task, and the effective utilization of the time information in the echo sequence plays a decisive role in predicting the trend of radar echoes. We found that simply using a combination of Window Attention and Shift Window Attention cannot effectively extract the information features in the spatiotemporal sequence. In
Section 4.1, we introduced a multi-branch network structure to add multi-scale spatial information to the model, improving the model’s spatial feature extraction capability. However, improving the model’s feature extraction capability for time series information remains a problem. We address this issue by introducing Temporal Attention. In the Temporal Attention module, we reshape the output of the Window Attention, converting (B, P
T, E, P
H, P
W) to (B × P
H × P
W, P
T, E), where P
T, P
H, and P
W are the time, height, and width dimensions after Patch Embedding, and E refers to the Embedding dimension. Since P
T is often small, the computational cost of using a full attention mechanism is not significant, so we use a full attention mechanism in Temporal Attention, which can more directly establish global temporal correlations compared to Window Attention.
In the STA block, we added a Spatial–Temporal Fusion (STF) layer parallel to the MLP. This module consists of two 3D convolutions, like MLP, which perform a scaling operation on the number of input feature channels. There are two main reasons for doing this: first, the MLP only scales the channel dimension and does not further process the time and space feature information that is extracted in the attention module of the first half. We aim to increase the interaction of spatiotemporal information by adding the STF layer, helping the model better establish the long-term dependencies of echo features and improve the accuracy of predicting radar echo motion trends. Second, attention-based networks require a lot of training time to let the network learn where the attention mechanism should focus. By adding convolutional layers and using convolution operations’ local nature and inductive ability, the network can quickly learn the dependencies of adjacent parts in the radar echo feature map. This can help the network converge faster and improve the feature extraction capability. We concatenate the outputs of the convolution and MLP in the channel dimension, and to prevent the channel dimension from continuously increasing with the depth of the network, we use a linear layer to trim the concatenated result, thereby maintaining the same input and output dimensions.
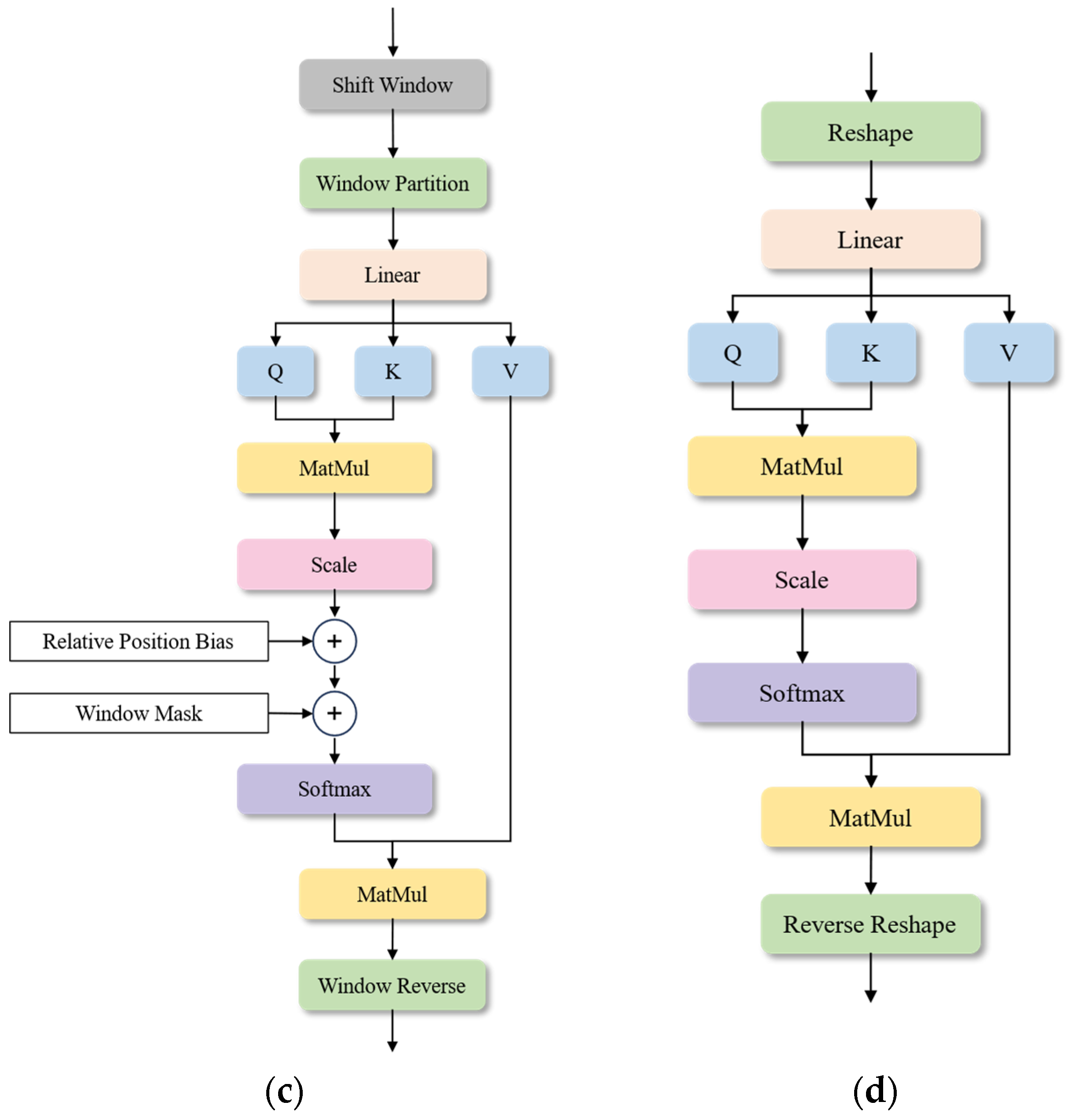
The overall structure of the STA block is shown in
Figure 4a, while
Figure 4b–d depict the structure of Window Attention, Shift Window Attention, and Temporal Attention, respectively. The input data first pass through an attention module composed of Window Attention, Shift Window Attention, and Temporal Attention in series, and then input to the Feed Forward module composed of a parallel MLP layer and STF layer. Additionally, LayerNorm is applied before the attention module and the Feed Forward module, and residual connect is used afterwards to help accelerate the model convergence and alleviate gradient disappearance.
5. Discussion
In recent years, radar echo extrapolation technology has become an important technique for short-term forecasting. The accurate and effective prediction of radar echo motions and intensity changes is crucial for improving short-term forecast accuracy. However, current radar echo extrapolation models face challenges such as intensity decay and image blurriness in the extrapolated results as the prediction time steps increase. CNN-based radar echo extrapolation models lack the ability to model temporal dependencies, leading to a significant decrease in prediction accuracy as time steps increase. On the other hand, RNN-based radar echo extrapolation models suffer from cumulative errors due to the recursive nature of image generation, resulting in poor prediction performance.
In this paper, we propose a novel deep learning model called the MS-RadarFormer. To address the issues mentioned above, we adopt a non-autoregressive approach to radar echo image generation to avoid performance degradation caused by cumulative errors. In terms of model structure, we introduce the MR branch to the encoder–decoder network, enhancing the model’s ability to predict the overall motion trend of radar echoes while ensuring the clarity of the predicted radar echo images. Additionally, we utilize the MSPE layer to incorporate radar echo information from different temporal and spatial scales into the model, helping the model understand the spatiotemporal structural information of the echo data. Lastly, internally, we employ the STA block to efficiently establish long-term spatiotemporal feature dependencies, thereby improving the model’s ability to model radar echo sequences.
In the comparative experiments, the MS-RadarFormer showed improved performance on the validation set compared to other models. Furthermore, through visual analysis, we observed that as the prediction time steps increased, MS-RadarFormer exhibited less decay in echo intensity and produced clearer predicted images than the other models. Although the TCTN also utilizes a Transformer architecture, it lacks feature extraction and processing capabilities. Additionally, its autoregressive echo generation mode leads to severe blurriness during the prediction process. In the ablation experiments, after deleting the MR branch, the model encountered some problems in judging the overall motion trend of radar echoes. For example, the model might incorrectly interpret the decreasing intensity and shrinking area of echoes as an increasing trend in some cases. This indicates that the multi-scale features provided by the MR branch play a crucial role in predicting echo motion trends. After removing the MSPE layer, the predicted results of the model showed decreased image clarity and a tendency towards echo intensity decay compared to the original model. This demonstrates the effectiveness of the MSPE layer in improving blurriness and decay issues. When the STA block was replaced with the Swin Transformer block, severe overfitting occurred during training, resulting in a significant drop in model scores. This indicates that the STA block helps model long-term spatiotemporal dependencies and effectively mitigates the negative impact of introducing the Window Attention to radar echo extrapolation tasks.
However, the current MS-RadarFormer still has some limitations. There are still certain levels of echo intensity decay and image blurriness in MS-RadarFormer. Two main reasons are contributing to this issue. Firstly, the number of sequence samples in the training dataset is still insufficient to meet the requirements of training the Transformer-based model. We aim to enhance the model’s performance by increasing the dataset size. Secondly, using only single-radar data as input poses a significant challenge in predicting complex atmospheric motion processes. In the future, we plan to explore using multi-source observational data to address this challenge.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}