
Deep Hybrid Fusion Network for Inverse Synthetic Aperture Radar Ship Target Recognition Using Multi-Domain High-Resolution Range Profile Data


Abstract
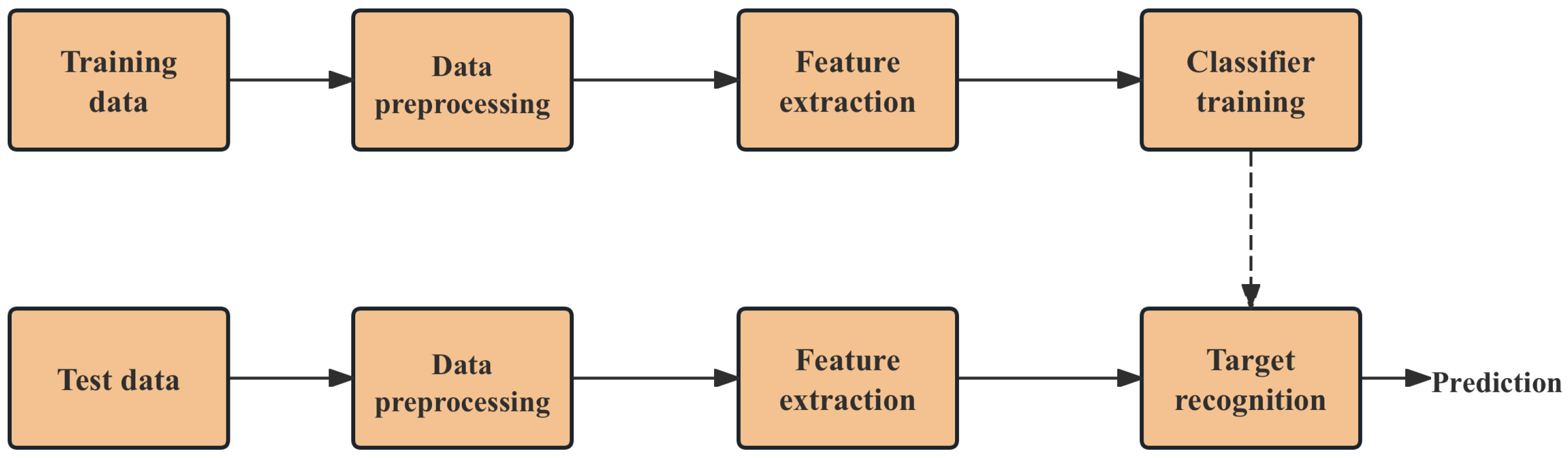
1. Introduction
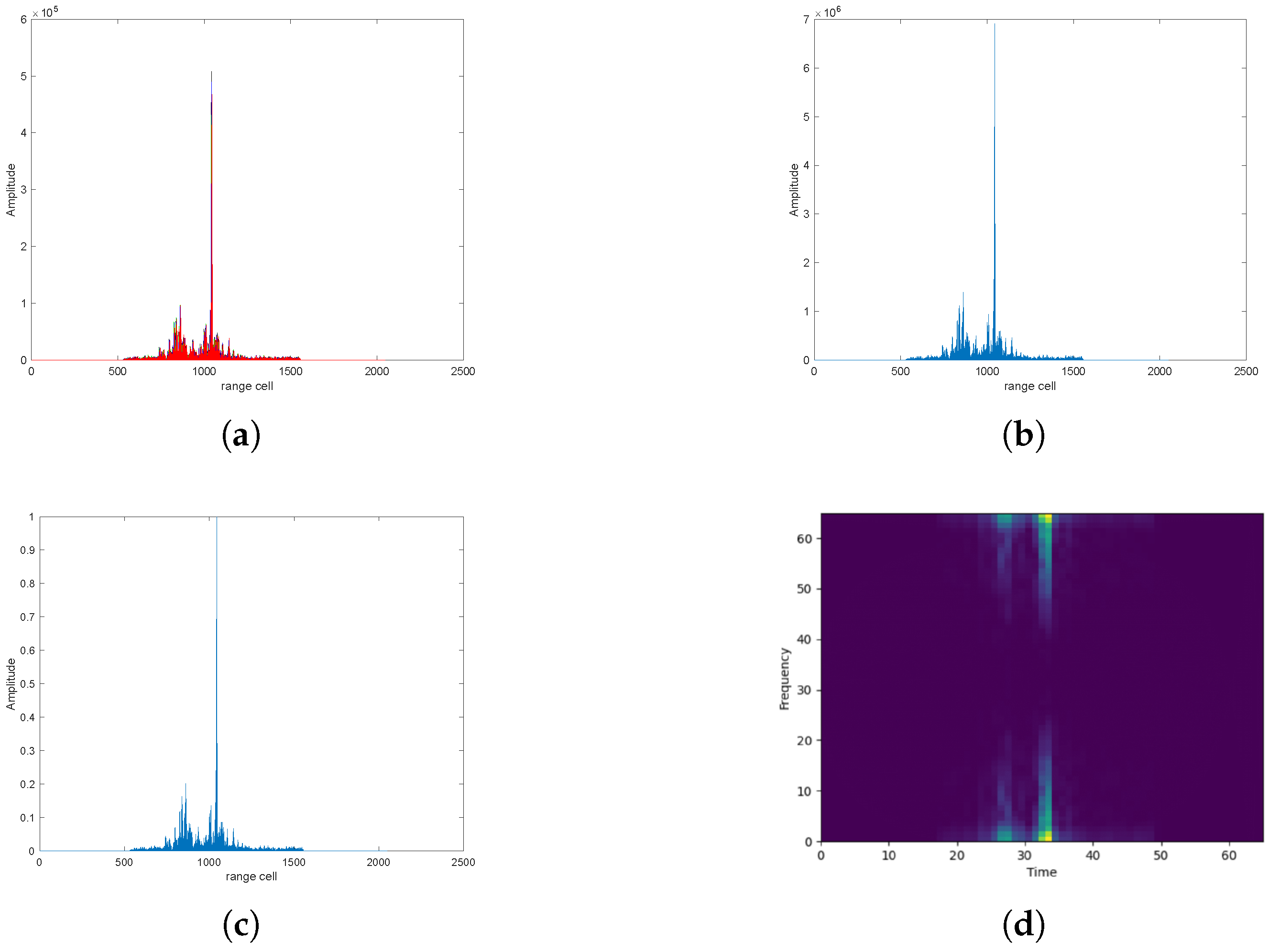
2. Data Preprocessing
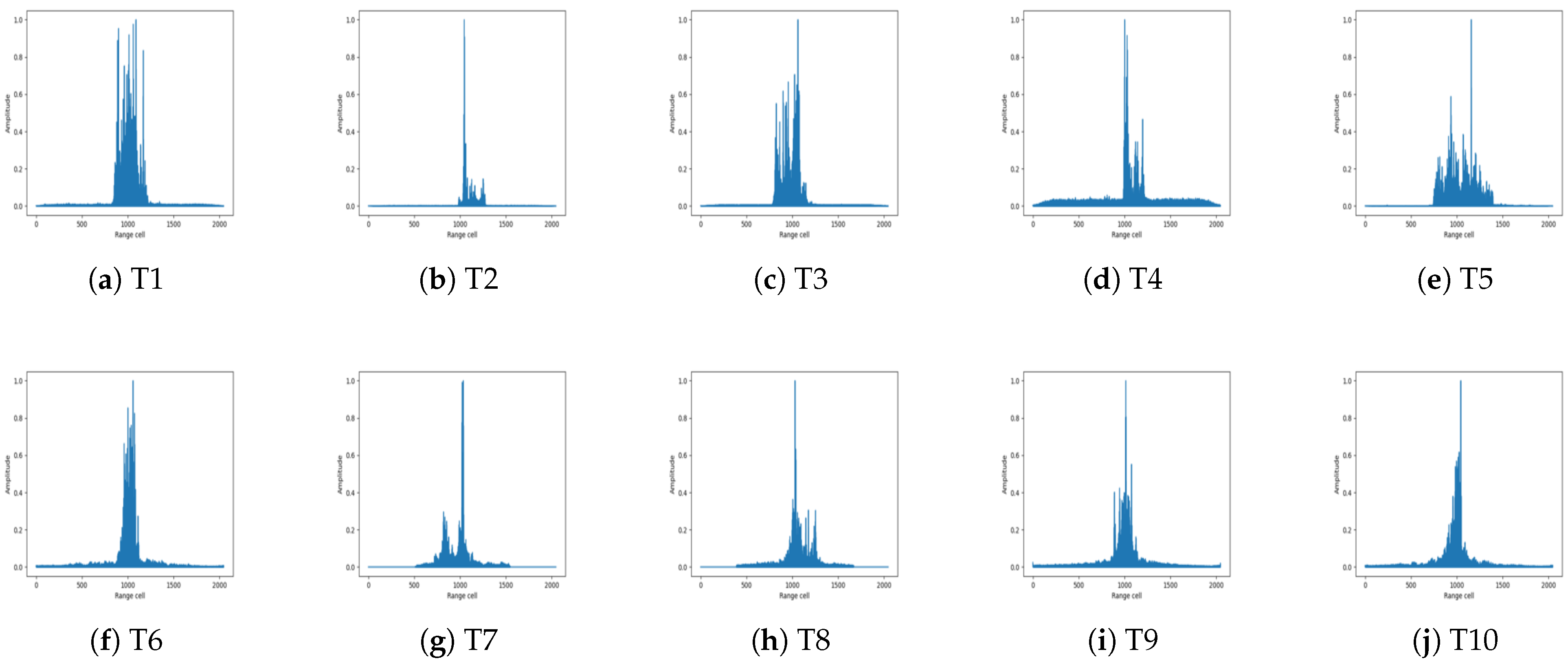
2.1. Time-Domain HRRP
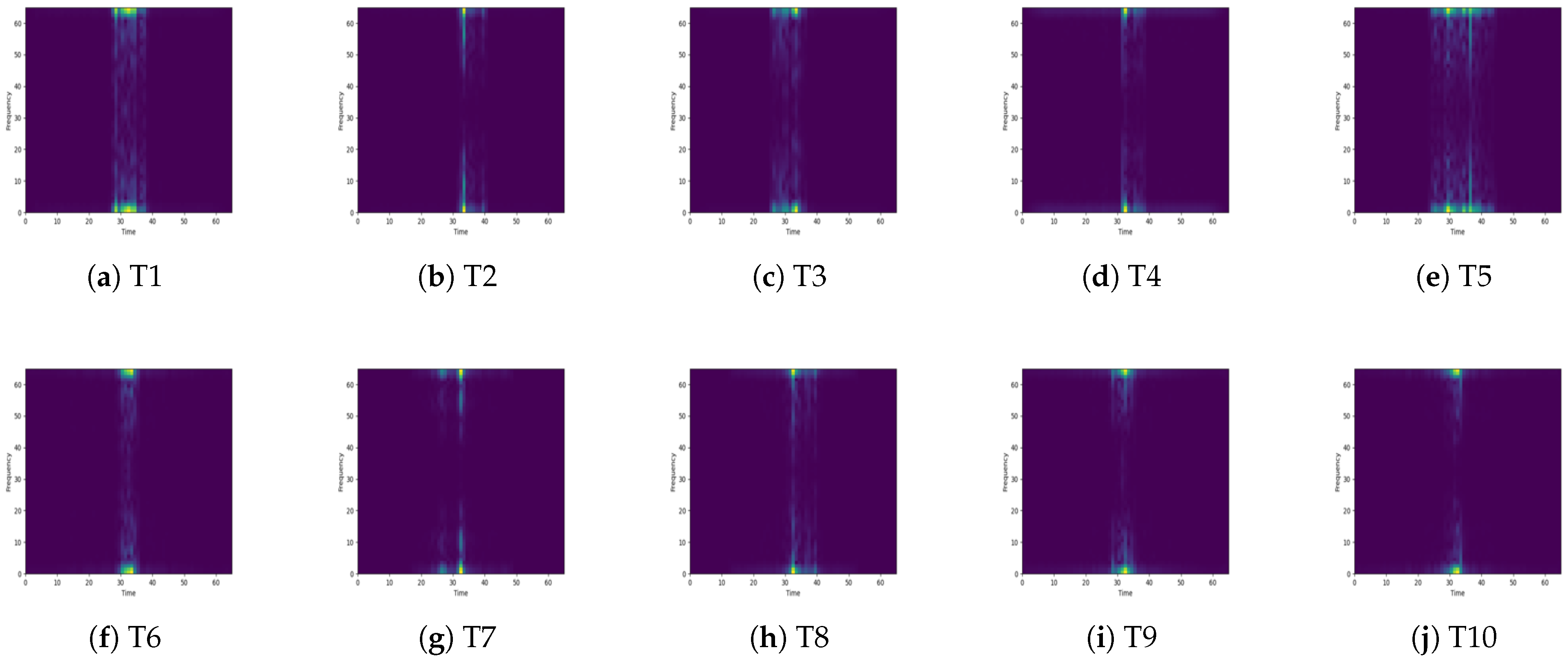
2.2. Spectrogram
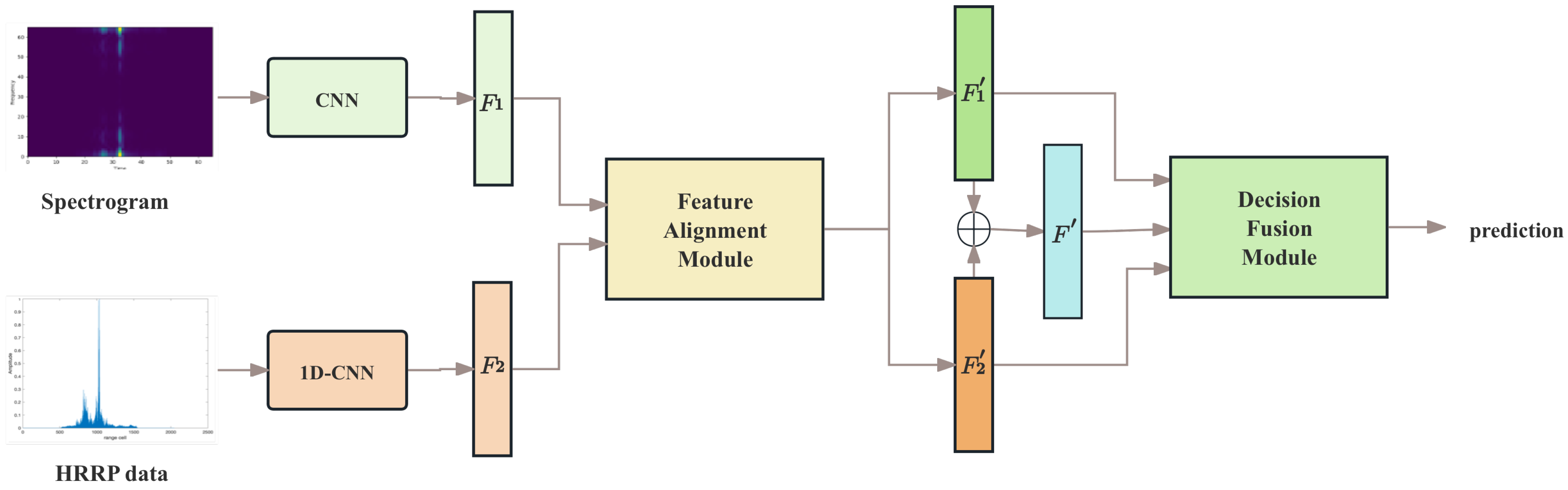
3. The Proposed Method
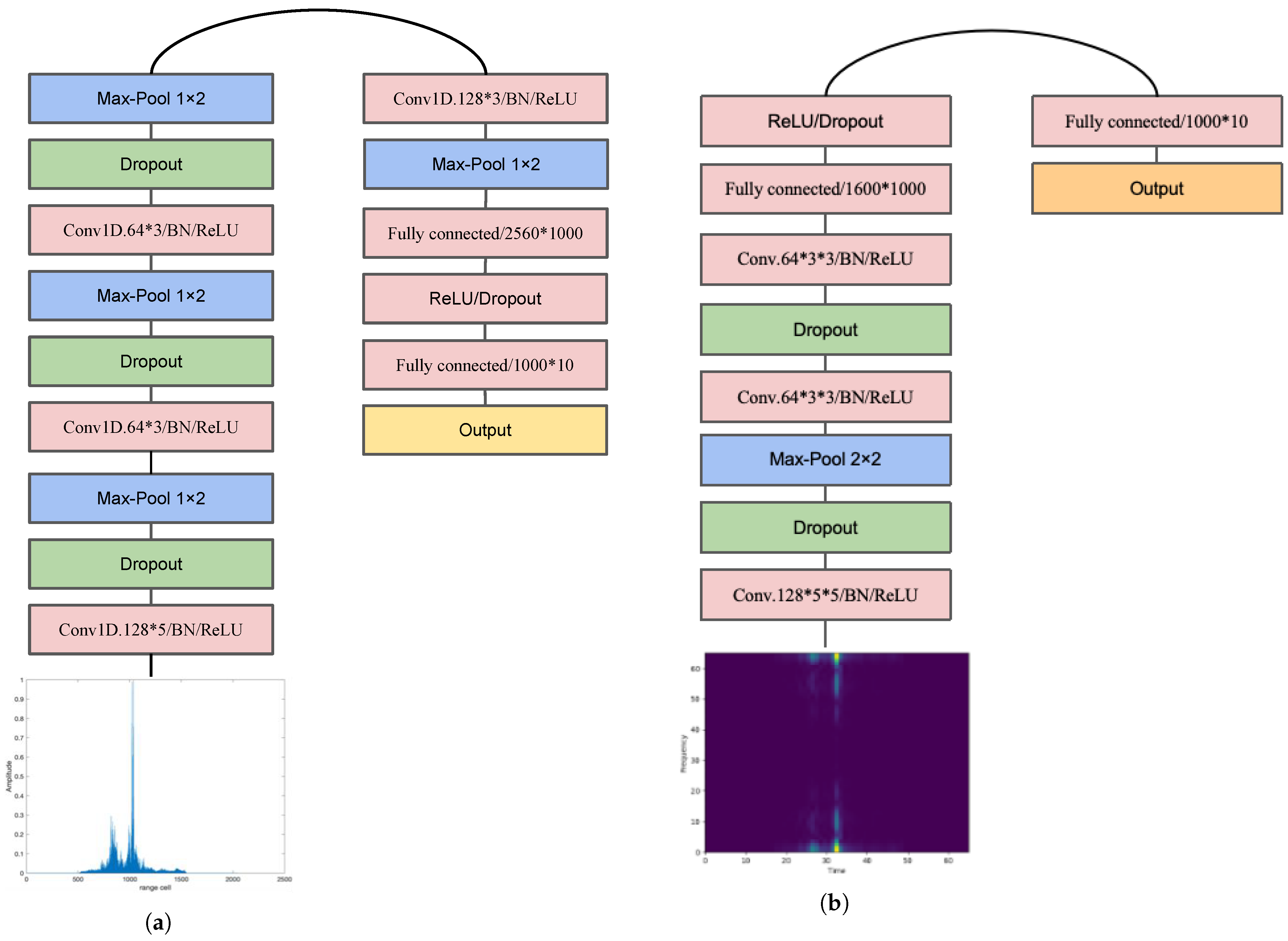
3.1. Initial Feature Extraction
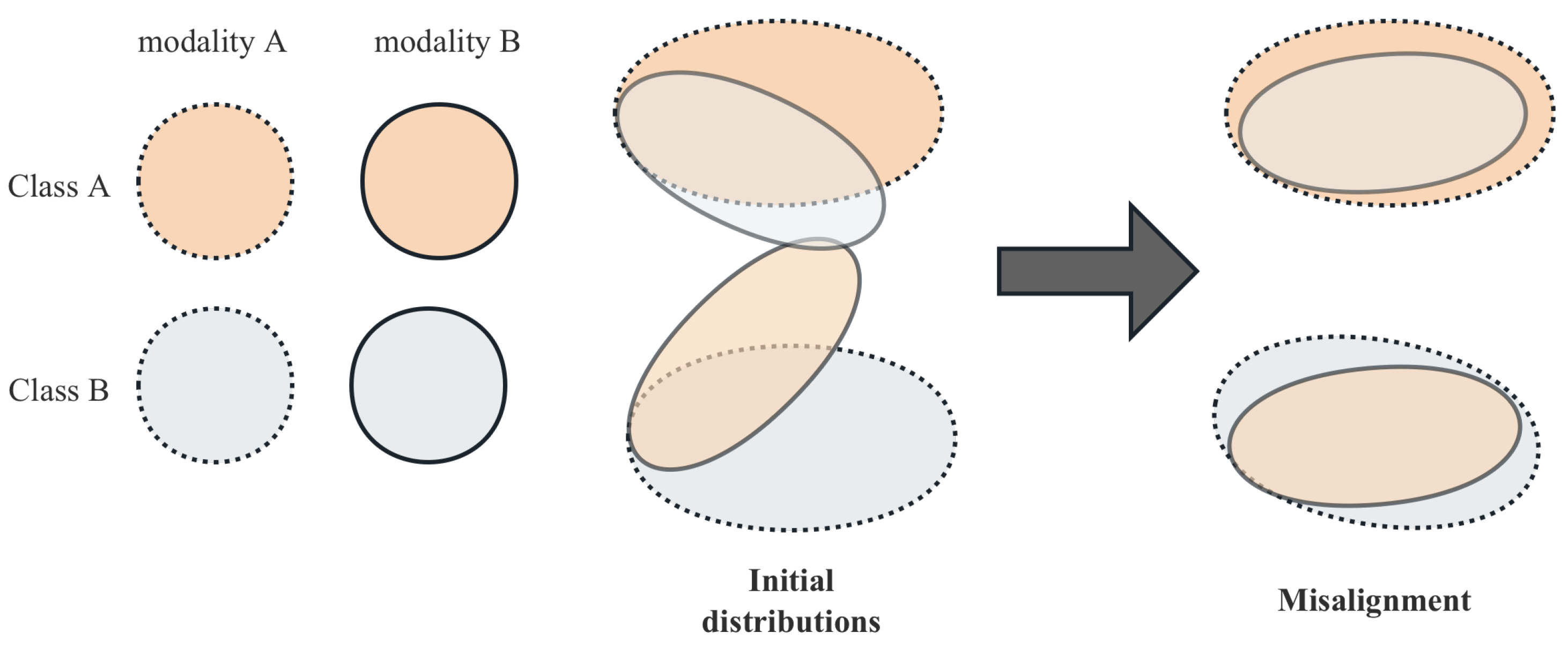
3.2. Feature Alignment
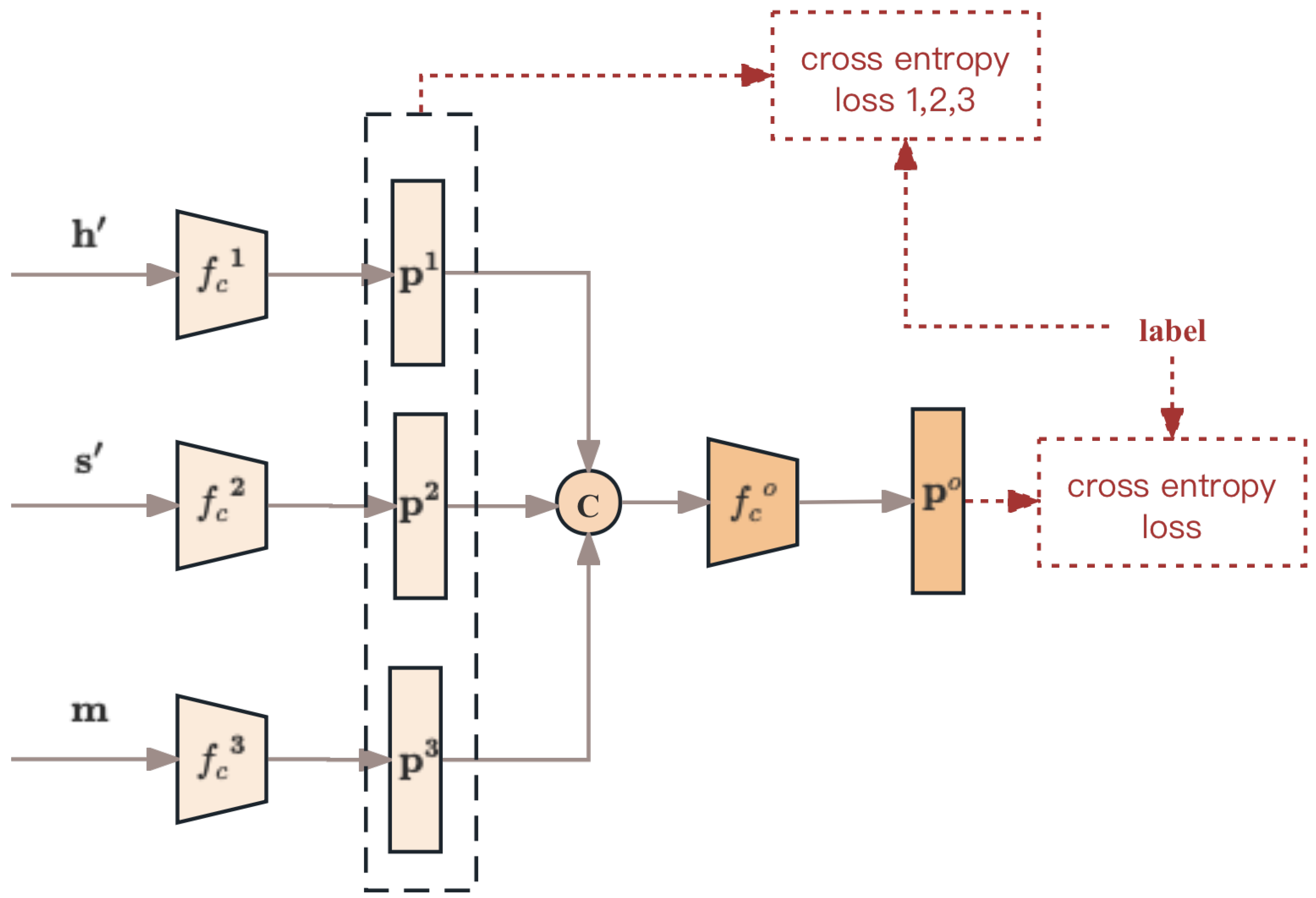
3.3. Decision Fusion
| Algorithm 1 Training Process of the Proposed Method |
| 1. Set the network architecture for the proposed method, including the number of fully connected layers, the number of units in each fully connected layer, the batch size, and other hyperparameters. |
| 2. Initialize the parameters for the two feature extraction networks ; the base classifier parameters ; and the meta-classifier parameters . |
| 3. while not converged do |
| 4. Randomly sample a batch of examples and their corresponding labels from the entire dataset. |
| 5. Following the preprocessing steps outlined in Section 2, obtain the preprocessed time-domain profile and spectrogram for each sample. |
| 6. Use and as inputs to obtain the initial features of the two modalities, and , through Equations (5) and 6, respectively. |
| 7. Using , , and , compute through Equations (8) and (9). |
| 8. In the decision fusion section, obtain the prediction vector using Equations (10)–(12). |
| 9. Calculate the total loss and update the network parameters. |
| 10. end while |
4. Experiments and Results
4.1. Simulated Data
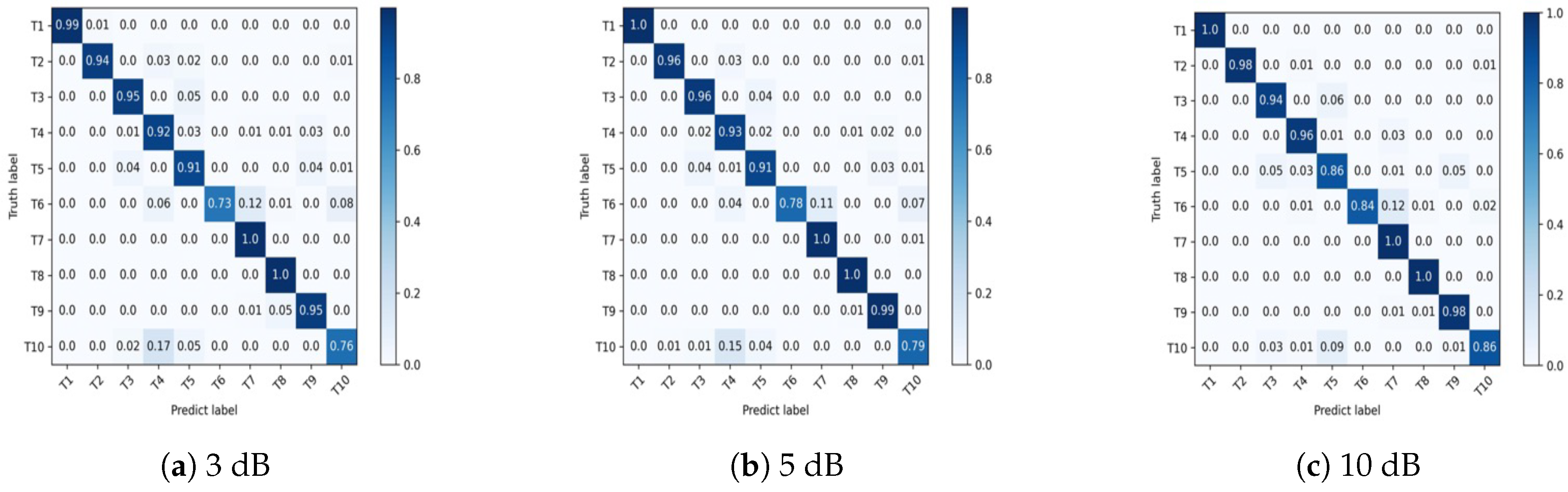
4.2. Measured Data
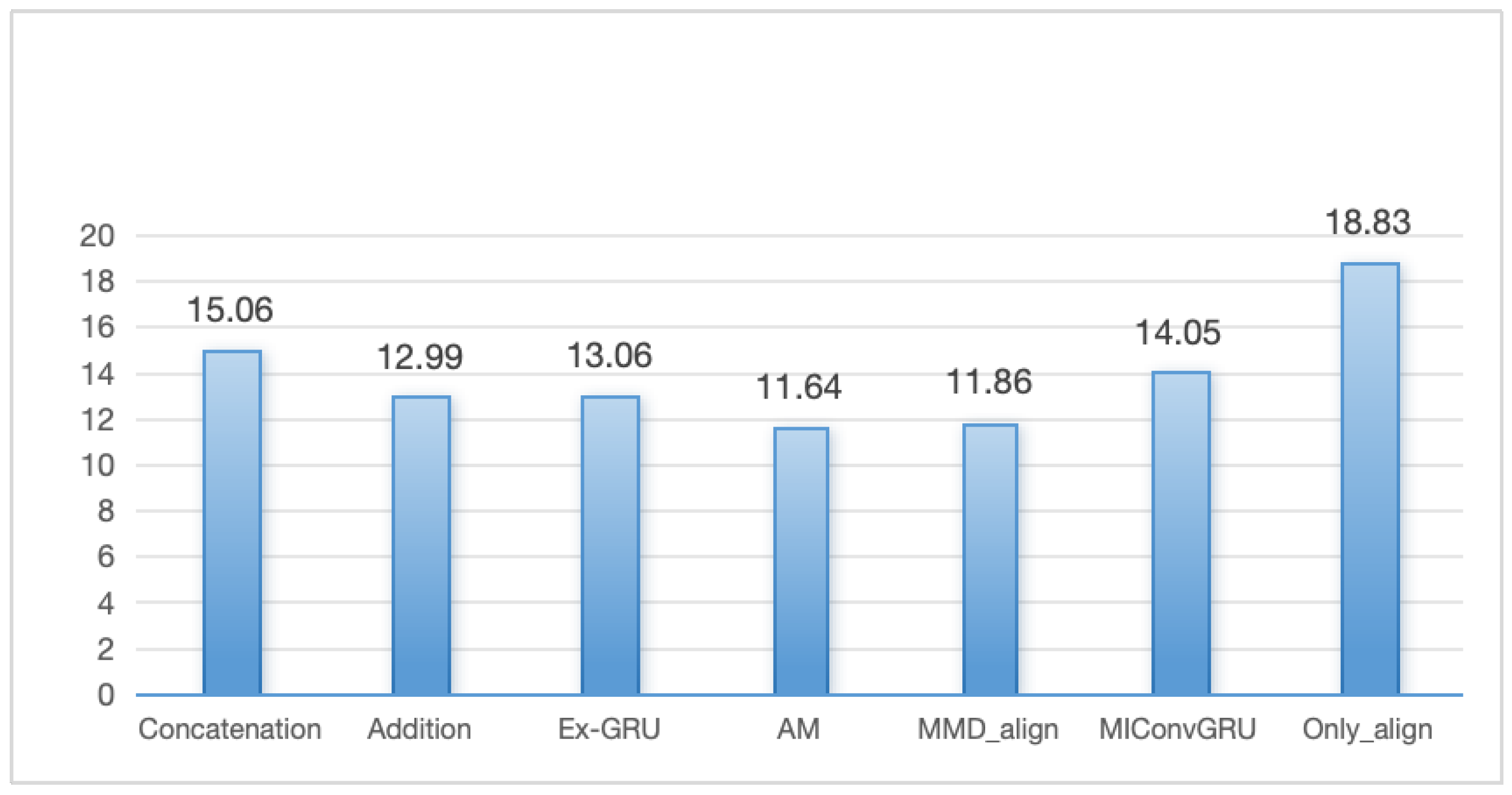
4.3. Ablation Study
5. Discussion
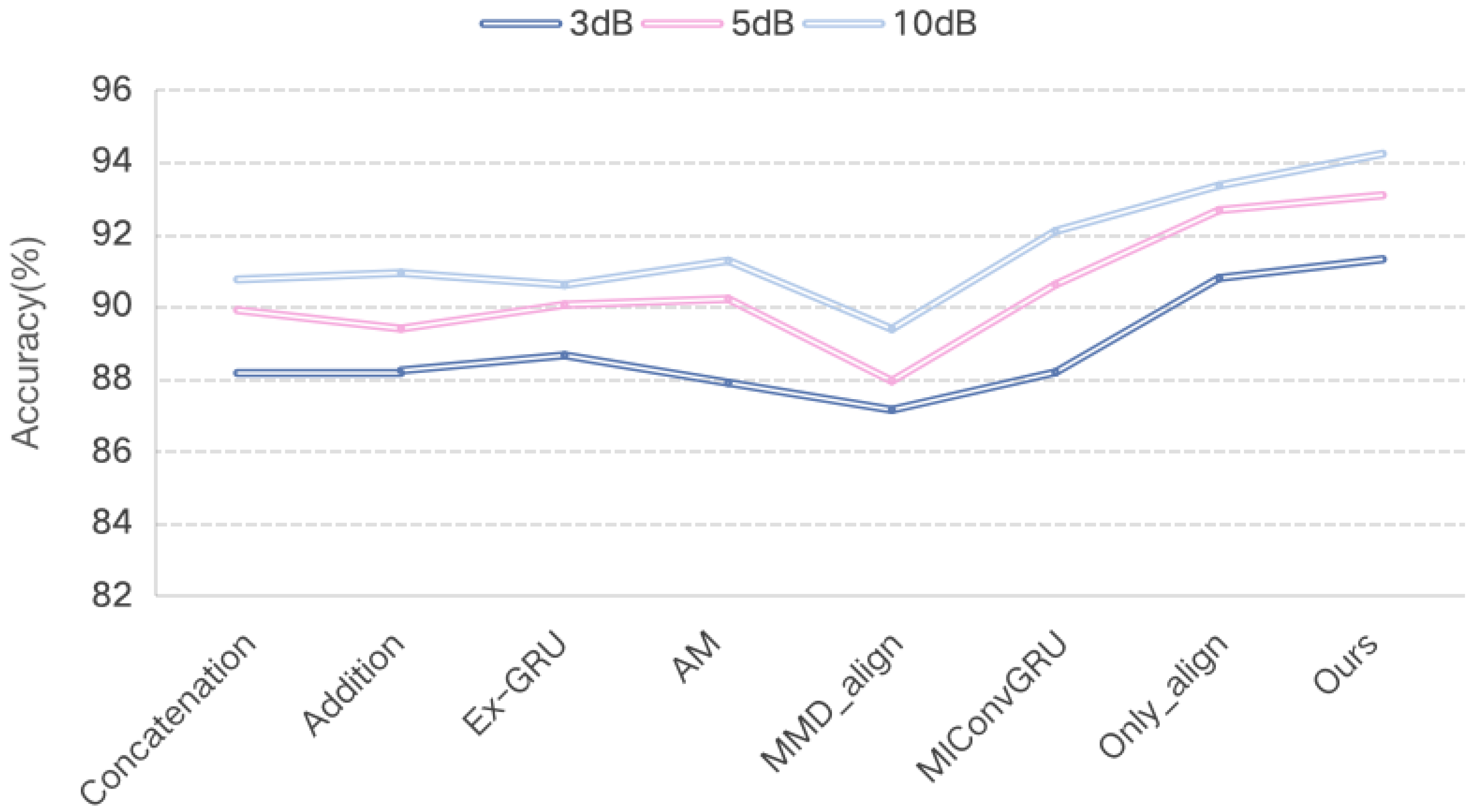
5.1. Comparison
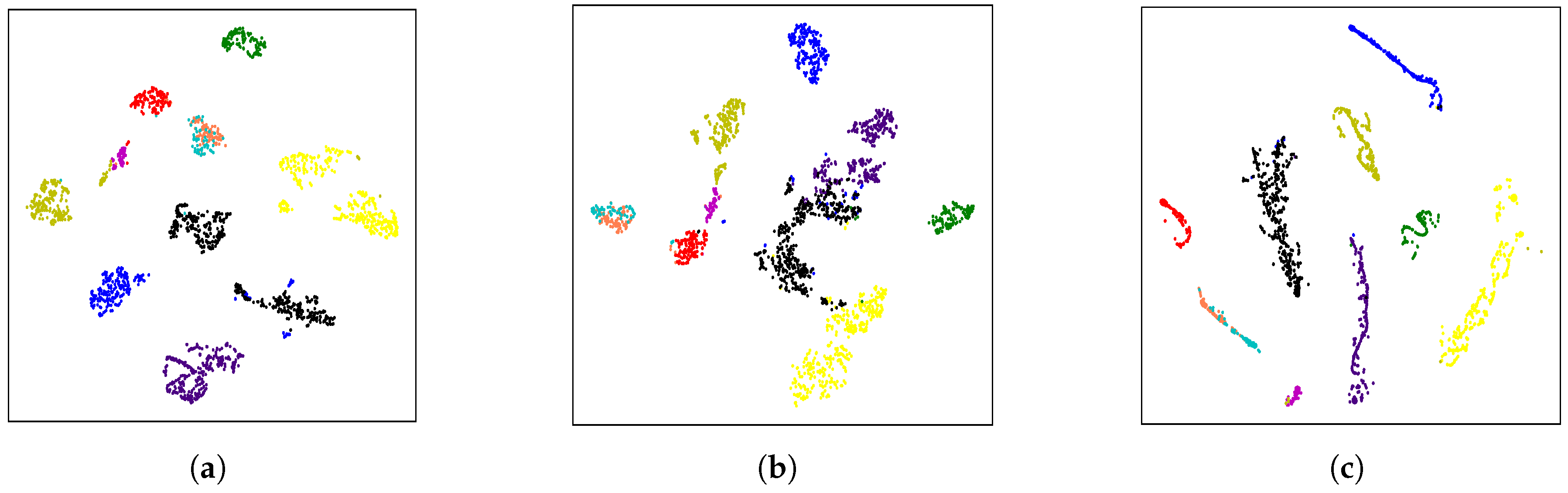
5.2. Impact of Feature Alignment on Reducing Ambiguity
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Du, C.; Chen, B.; Xu, B.; Guo, D.; Liu, H. Factorized discriminative conditional variational auto-encoder for radar HRRP target recognition. Signal Process. 2019, 158, 176–189. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, S.; Luo, Y.; Liu, H. Measurement matrix optimization based on target prior information for radar imaging. IEEE Sens. J. 2023, 23, 9808–9819. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, B.; Yu, H.; Chen, J.; Xing, M.; Hong, W. Sparse synthetic aperture radar imaging from compressed sensing and machine learning: Theories, applications, and trends. IEEE Geosci. Remote Sens. Mag. 2022, 10, 32–69. [Google Scholar] [CrossRef]
- Deng, J.; Su, F. SDRnet: A Deep Fusion Network for ISAR Ship Target Recognition Based on Feature Separation and Weighted Decision. Remote Sens. 2024, 16, 1920. [Google Scholar] [CrossRef]
- He, Y.; Yang, H.; He, H.; Yin, J.; Yang, J. A ship discrimination method based on high-frequency electromagnetic theory. Remote Sens. 2022, 14, 3893. [Google Scholar] [CrossRef]
- Zeng, Z.; Sun, J.; Han, Z.; Hong, W. Radar HRRP target recognition method based on multi-input convolutional gated recurrent unit with cascaded feature fusion. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xing, M.; Bao, Z.; Pei, B. Properties of high-resolution range profiles. Opt. Eng. 2002, 41, 493–504. [Google Scholar] [CrossRef]
- Chen, J.; Du, L.; Guo, G.; Yin, L.; Wei, D. Target-attentional CNN for radar automatic target recognition with HRRP. Signal Process. 2022, 196, 108497. [Google Scholar] [CrossRef]
- Pilcher, C.M.; Khotanzad, A. Maritime ATR using classifier combination and high resolution range profiles. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 2558–2573. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L.; Wang, S.; Zhao, T.; Wang, Y.; Li, Y. Radar HRRP target recognition using scattering centers fuzzy matching. In Proceedings of the 2016 CIE International Conference on Radar (RADAR), Philadelphia, PA, USA, 2–6 May 2016; pp. 1–5. [Google Scholar]
- Zhou, D. Radar target HRRP recognition based on reconstructive and discriminative dictionary learning. Signal Process. 2016, 126, 52–64. [Google Scholar] [CrossRef]
- Jiang, Y.; Han, Y.; Sheng, W. Target recognition of radar HRRP using manifold learning with feature weighting. In Proceedings of the 2016 IEEE International Workshop on Electromagnetics: Applications and Student Innovation Competition (iWEM), Nanjing, China, 16–18 May 2016; pp. 1–3. [Google Scholar]
- Liu, M.; Zou, Z.; Hao, M. Radar target recognition based on combined features of high range resolution profiles. In Proceedings of the 2009 2nd Asian-Pacific Conference on Synthetic Aperture Radar, Xi’an, China, 26–30 October 2009; pp. 876–879. [Google Scholar]
- Lundén, J.; Koivunen, V. Deep learning for HRRP-based target recognition in multistatic radar systems. In Proceedings of the 2016 IEEE Radar Conference (RadarConf), Philadelphia, PA, USA, 2–6 May 2016; pp. 1–6. [Google Scholar]
- Li, J.; Li, S.; Liu, Q.; Mei, S. A novel algorithm for HRRP target recognition based on CNN. In IoT as a Service, Proceedings of the 5th EAI International Conference, IoTaaS 2019, Xi’an, China, 16–17 November 2019; Proceedings 5; Springer: Cham, Switzarland, 2020; pp. 397–404. [Google Scholar]
- Feng, B.; Chen, B.; Liu, H. Radar HRRP target recognition with deep networks. Pattern Recognit. 2017, 61, 379–393. [Google Scholar] [CrossRef]
- Liao, L.; Du, L.; Chen, J. Class factorized complex variational auto-encoder for HRR radar target recognition. Signal Process. 2021, 182, 107932. [Google Scholar] [CrossRef]
- Yu, S.H.; Xie, Y.J. Application of a convolutional autoencoder to half space radar hrrp recognition. In Proceedings of the 2018 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Chengdu, China, 15–18 July 2018; pp. 48–53. [Google Scholar]
- Xu, B.; Chen, B.; Wan, J.; Liu, H.; Jin, L. Target-aware recurrent attentional network for radar HRRP target recognition. Signal Process. 2019, 155, 268–280. [Google Scholar] [CrossRef]
- Du, C.; Tian, L.; Chen, B.; Zhang, L.; Chen, W.; Liu, H. Region-factorized recurrent attentional network with deep clustering for radar HRRP target recognition. Signal Process. 2021, 183, 108010. [Google Scholar] [CrossRef]
- Wang, P.; Chen, T.; Ding, J.; Pan, M.; Tang, S. Intelligent radar HRRP target recognition based on CNN-BERT model. EURASIP J. Adv. Signal Process. 2022, 2022, 89. [Google Scholar] [CrossRef]
- Wang, X.; Wang, P.; Song, Y.; Li, J. Recognition of HRRP sequence based on TCN with attention and elastic net regularization. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 346–351. [Google Scholar]
- Diao, Y.; Liu, S.; Gao, X.; Liu, A. Position embedding-free transformer for radar HRRP target recognition. In Proceedings of the IGARSS 2022-2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1896–1899. [Google Scholar]
- Wan, J.; Chen, B.; Xu, B.; Liu, H.; Jin, L. Convolutional neural networks for radar HRRP target recognition and rejection. EURASIP J. Adv. Signal Process. 2019, 2019, 5. [Google Scholar] [CrossRef]
- Tao, Y.; Quan, P.; Yuhang, H.; Rong, X. Target recognition algorithm based on HRRP time-spectrogram feature and multi-scale asymmetric convolutional neural network. Xibei Gongye Daxue Xuebao/J. Northwestern Polytech. Univ. 2023, 41, 537–545. [Google Scholar]
- Wan, J.; Chen, B.; Yuan, Y.; Liu, H.; Jin, L. Radar HRRP recognition using attentional CNN with multi-resolution spectrograms. In Proceedings of the 2019 International Radar Conference (RADAR), Toulon, France, 23–27 September 2019; pp. 1–4. [Google Scholar]
- Pan, M.; Du, L.; Wang, P.; Liu, H.; Bao, Z. Multi-task hidden Markov modeling of spectrogram feature from radar high-resolution range profiles. EURASIP J. Adv. Signal Process. 2012, 2012, 86. [Google Scholar] [CrossRef]
- Jiang, L.; Yan, L.; Xia, Y.; Guo, Q.; Fu, M.; Lu, K. Asynchronous multirate multisensor data fusion over unreliable measurements with correlated noise. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 2427–2437. [Google Scholar] [CrossRef]
- Rasti, B.; Ghamisi, P.; Plaza, J.; Plaza, A. Fusion of hyperspectral and LiDAR data using sparse and low-rank component analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6354–6365. [Google Scholar] [CrossRef]
- Bassford, M.; Painter, B. Intelligent bio-environments: Exploring fuzzy logic approaches to the honeybee crisis. In Proceedings of the 2016 12th International Conference on Intelligent Environments (IE), London, UK, 14–16 September 2016; pp. 202–205. [Google Scholar]
- Zhang, Y.; Xie, Y.; Kang, L.; Li, K.; Luo, Y.; Zhang, Q. Feature-Level Fusion Recognition of Space Targets with Composite Micromotion. IEEE Trans. Aerosp. Electron. Syst. 2023, 60, 934–951. [Google Scholar] [CrossRef]
- Chen, B.; Liu, H.W.; Bao, Z. Analysis of three kinds of classification based on different absolute alignment methods. Xiandai Leida (Mod. Radar) 2006, 28, 58–62. [Google Scholar]
- Zhai, Y.; Chen, B.; Zhang, H.; Wang, Z. Robust variational auto-encoder for radar HRRP target recognition. In Intelligence Science and Big Data Engineering, Proceedings of the 7th International Conference, IScIDE 2017, Dalian, China, 22–23 September 2017; Proceedings 6; Springer: Cham, Switzerland, 2017; pp. 356–367. [Google Scholar]
- Du, L.; Liu, H.; Bao, Z.; Zhang, J. Radar automatic target recognition using complex high-resolution range profiles. IET Radar Sonar Navig. 2007, 1, 18–26. [Google Scholar] [CrossRef] [PubMed]
- Du, L.; Liu, H.; Bao, Z.; Xing, M. Radar HRRP target recognition based on higher order spectra. IEEE Trans. Signal Process. 2005, 53, 2359–2368. [Google Scholar]
- Xue, R.; Bai, X.; Zhou, F. SAISAR-Net: A robust sequential adjustment ISAR image classification network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Ni, P.; Liu, Y.; Pei, H.; Du, H.; Li, H.; Xu, G. Clisar-net: A deformation-robust isar image classification network using contrastive learning. Remote Sens. 2022, 15, 33. [Google Scholar] [CrossRef]
- Bai, X.; Zhou, X.; Zhang, F.; Wang, L.; Xue, R.; Zhou, F. Robust pol-ISAR target recognition based on ST-MC-DCNN. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9912–9927. [Google Scholar] [CrossRef]
- Zhao, W.; Heng, A.; Rosenberg, L.; Nguyen, S.T.; Hamey, L.; Orgun, M. ISAR ship classification using transfer learning. In Proceedings of the 2022 IEEE Radar Conference (RadarConf22), New York, NY, USA, 21–25 March 2022; pp. 1–6. [Google Scholar]
- Chen, J.; Du, L.; He, H.; Guo, Y. Convolutional factor analysis model with application to radar automatic target recognition. Pattern Recognit. 2019, 87, 140–156. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target classification using the deep convolutional networks for SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tian, X.; Bai, X.; Zhou, F. Recognition of micro-motion space targets based on attention-augmented cross-modal feature fusion recognition network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–9. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Z.; Tao, D.; See, S.; Wang, G. Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14; Springer: Cham, Switzerland, 2016; pp. 664–679. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Du, L.; Li, L.; Guo, Y.; Wang, Y.; Ren, K.; Chen, J. Two-stream deep fusion network based on VAE and CNN for synthetic aperture radar target recognition. Remote Sens. 2021, 13, 4021. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Top-View | Side-View | ||||
|---|---|---|---|---|---|
| Target | T1 | T2–T10 | Target | T1 | T2–T10 |
| Pitch angle () | 80°/85° | 80°/85° | Azimuth angle () | 10°/15° | 10°/15° |
| Initial azimuth angle () | 5° | 5° | Initial pitch angle () | 40° | 40° |
| Azimuth motion 1 | 0.04°/s | 0.27°/s | Pitch motion 1 | 0.08°/s | 0.51°/s |
| Azimuth angle interval 1 | 0.02° | 0.132° | Pitch angle interval 1 | 0.04° | 0.240° |
| Azimuth motion 2 | 0.08°/s | 0.54°/s | Pitch motion 2 | 0.16°/s | 1.01°/s |
| Azimuth angle interval 2 | 0.04° | 0.211° | Pitch angle interval 2 | 0.08° | 0.384° |
| Parameter | Value |
|---|---|
| Center frequency | 8.075 GHz |
| Bandwidth | 150 MHz |
| PRF | 200 Hz |
| Observation time | 0.32 s |
| SNR | 3 dB | 5 dB | 10 dB |
|---|---|---|---|
| Acc. | 91.31% | 93.08% | 94.23% |
| SNR | 3 dB | 5 dB | 10 dB |
|---|---|---|---|
| Concatenation | 88.16% | 89.90% | 90.75% |
| Addition | 88.23% | 89.39% | 90.93% |
| Ex-GRU [49] | 88.65% | 90.05% | 90.60% |
| AM [31] | 87.89% | 90.21% | 91.27% |
| MMD_align | 87.14% | 87.94% | 89.38% |
| MIConvGRU [6] | 88.18% | 90.61% | 92.09% |
| Only_align | 90.79% | 92.67% | 93.35% |
| Ours | 91.31% | 93.08% | 94.23% |
| Target | T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | T10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Training Samples | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| Test Samples | 450 | 131 | 230 | 435 | 299 | 120 | 128 | 49 | 56 | 89 |
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | T9 | T10 | Accuracy (%) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Concatenation | 99.11 | 90.08 | 95.65 | 99.77 | 92.64 | 100 | 93.58 | 100 | 76.79 | 75.28 | 95.23 |
| Addition | 93.11 | 93.89 | 97.39 | 99.77 | 96.99 | 98.33 | 94.04 | 93.88 | 55.36 | 92.13 | 94.94 |
| Ex-GRU [49] | 92.00 | 98.47 | 95.22 | 95.63 | 94.98 | 99.17 | 95.41 | 100 | 85.71 | 74.16 | 93.98 |
| AM [31] | 97.33 | 100 | 95.22 | 98.39 | 96.99 | 95.00 | 91.74 | 95.92 | 85.71 | 60.67 | 94.80 |
| MMD_align | 95.11 | 95.42 | 96.52 | 94.71 | 91.30 | 95.83 | 93.12 | 100 | 76.79 | 78.65 | 93.40 |
| MIConvGRU [6] | 97.11 | 99.23 | 99.13 | 99.54 | 95.98 | 99.17 | 92.20 | 87.76 | 80.36 | 73.03 | 95.71 |
| Only_align | 98.00 | 100 | 95.22 | 97.47 | 98.66 | 97.50 | 98.17 | 95.92 | 82.14 | 79.78 | 96.53 |
| Ours | 98.89 | 98.47 | 96.96 | 99.77 | 99.67 | 100 | 96.79 | 100 | 64.29 | 89.89 | 97.49 |
| HRRP | Spectrogram | Proposed Fusion Method | Accuracy (%) | ||
|---|---|---|---|---|---|
| ✓ | × | × | 86.88 | ||
| 3 dB | × | ✓ | × | 86.57 | |
| ✓ | ✓ | ✓ | 91.31 | ||
| ✓ | × | × | 88.70 | ||
| 5dB | × | ✓ | × | 88.86 | Simulated |
| ✓ | ✓ | ✓ | 93.08 | ||
| ✓ | × | × | 89.79 | ||
| 10 dB | × | ✓ | × | 88.93 | |
| ✓ | ✓ | ✓ | 94.23 | ||
| ✓ | × | × | 94.67 | ||
| × | ✓ | × | 93.92 | Measured | |
| ✓ | ✓ | ✓ | 97.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, J.; Su, F. Deep Hybrid Fusion Network for Inverse Synthetic Aperture Radar Ship Target Recognition Using Multi-Domain High-Resolution Range Profile Data. Remote Sens. 2024, 16, 3701. https://doi.org/10.3390/rs16193701
Deng J, Su F. Deep Hybrid Fusion Network for Inverse Synthetic Aperture Radar Ship Target Recognition Using Multi-Domain High-Resolution Range Profile Data. Remote Sensing. 2024; 16(19):3701. https://doi.org/10.3390/rs16193701
Chicago/Turabian StyleDeng, Jie, and Fulin Su. 2024. "Deep Hybrid Fusion Network for Inverse Synthetic Aperture Radar Ship Target Recognition Using Multi-Domain High-Resolution Range Profile Data" Remote Sensing 16, no. 19: 3701. https://doi.org/10.3390/rs16193701
APA StyleDeng, J., & Su, F. (2024). Deep Hybrid Fusion Network for Inverse Synthetic Aperture Radar Ship Target Recognition Using Multi-Domain High-Resolution Range Profile Data. Remote Sensing, 16(19), 3701. https://doi.org/10.3390/rs16193701