1. Introduction
The advancement of these methods or technologies has led to the widespread utilization of object detection in remote sensing images for a multitude of purposes, including maritime rescue operations, environmental monitoring, and so on [
1,
2,
3,
4]. Nonetheless, the limited processing capabilities available in actual applications place major constraints on the size of the detector backbone in terms of both FLOPS and the number of parameters Although many detectors, such as YOLOv8-v10, incorporate three levels of features to handle objects of different sizes, their restricted receptive fields still hinder effective multi-scale object detection [
5].
As depicted in
Figure 1, the discrepancy in scale among objects in remote sensing images, when considered alongside the absence of robust scale invariance in detection models, hinders the effectiveness of deep convolutional networks. Studies such as [
6,
7,
8] have highlighted that the significant variations in object scales in remote sensing images present a notable challenge for object detection models. Consequently, the detection of objects in remote sensing images exhibiting significant variations represents a challenging task.
Detectors that utilize deep learning networks often use image pyramids or feature pyramids to address multi-scale detection [
9,
10,
11]. As illustrated in
Figure 2a, the single-shot detector exhibits superior performance due to its consideration of features across all scales. Image pyramids and feature pyramids provide strong support for the ability to deal with multi-scale objects [
12,
13,
14]. Enhancing detection accuracy in multi-scale scenarios through computing multi-layer feature maps is effective [
15].
Deep learning algorithms frequently employ image or feature pyramids to address scale issues. These algorithms assume 4–5 different scale objects in an image, then sequentially perform feature extraction and object detection across all scales. However, the image captured by a camera may not include objects at all scales. Additionally, recent works such as PalmProbNet [
16] combine traditional techniques with deep learning methods to further enhance detection accuracy and robustness in multi-scale scenarios. However, the image captured by a camera may not include objects at all scales. The detector has to detect objects at all scales one after the other, as it is not possible to determine in advance at which scale the object is present. Redundant scales in the network design significantly reduce the miss rate of objects in images, but waste a lot of inference time. It leads to significant computational redundancy, which results in persistently high inference times for the detection model [
17]. Therefore, it is necessary to find a strategy that balances inference time and detection accuracy. The objective of this paper is to reduce the miss rate of multi-scale objects while simultaneously reducing the time required for inference.
The influence of object size on visual perception within cognitive scaling mechanisms has been extensively documented. Inferred physical size influences attentional allocation and selection in retinal size-matched objects [
18]. The process of handling multi-scale information in cognitive scaling mechanisms is summarized as inferring the potential scale and then considering the allocation of attention. Automatic filtering of redundant scales helps cognitive systems quickly and accurately process potential scales that may be present in an image.
In light of the insights gained from the study of cognitive scaling mechanisms for multi-scale information, we have developed a scale-aware network, informed by observations of scale distribution in remote sensing object detection scenes. To address the computational redundancy issue in detecting objects and effectively handle significant scale differences in FCN-based detection systems [
19], our approach uses shallow CNNs to directly predict object scales. The entire detection pipeline is illustrated in
Figure 2b, where all components have been consolidated into a single CNN framework. Traditional deep learning algorithms extensively utilize image or feature pyramids to address scale issues. These algorithms assume 4–5 different scale objects in an image, then sequentially perform feature extraction and object detection across all scales. However, the image captured by a camera may not include objects at all scales, as variations in scale are intrinsic to the objects themselves and influenced by factors such as altitude and distance from the camera.
Our research focuses on the problem of significant scale differences in object detection systems, which is influenced by various factors, including the inherent quadratic scaling of objects and the distance between the camera and the objects. Drawing on cognitive scaling mechanisms’ ability to process multi-scale information efficiently, we have developed a scale-aware network to handle scale variations effectively in remote sensing scenes. By predicting object scales directly using shallow CNNs, our approach addresses computational redundancy and improves detection accuracy.
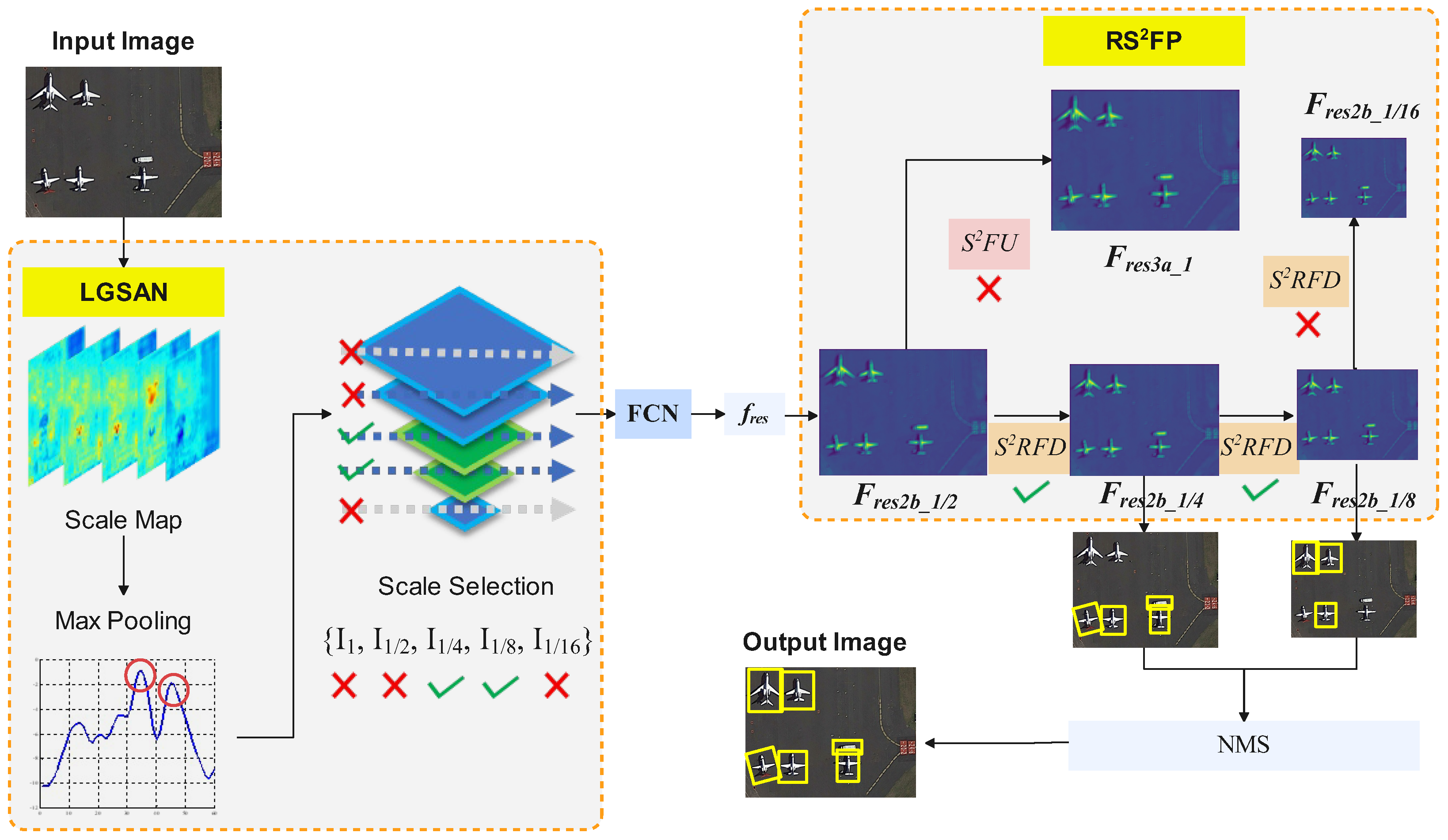
This paper presents the Scale Selection Network (SSN), which has been developed with the objective of addressing the issue of scale distribution tendency in remote sensing object detection tasks. The SSN contains two components: a Landmark Guided Scale Attention Network (LGSAN) and a Reversible Scale Semantic Flow Preserving strategy. LGSAN is a scale prediction network that differs from conventional models in that it does not provide an exact size for the predicted object. Instead, it restores the range of scale information present in the image through encoding and mapping. The scale range provided by LGSAN enables detection networks to compute feature maps at specific required scales while significantly reducing computation. In addition, a novel for generating cross-level feature maps is proposed. In the event that a feature map is provided with an arbitrary scale, the remaining feature maps for detecting different scale objects are generated, thereby ensuring optimal efficiency and accuracy. The semantic flow module produces feature maps of other scales sequentially to enhance the detector’s inference speed without compromising detection accuracy. The SSN has been designed to emulate the functionality of the human brain; it solves the issue of computational redundancy and enables the detection network to focus on the specific scales required.
In conclusion, our contributions in this paper are summarized as follows:
- (1)
Inspired by the mechanism of cognitive scaling mechanisms processing multi-scale information, we propose a novel SSN to eliminate computational redundancy through scale attention and selection. The SSN facilitates the acceleration of image pyramid-based detectors by approximately 5.3 times on widely utilized remote sensing object detection benchmarks.
- (2)
A lightweight LGSAN has been created with the goal of predicting probable scales in images. LGSAN is a plug-and-play module that is capable of working with any image pyramid or feature pyramid-based detector without the necessity for retraining, achieving 1.6× to 3.4× inference speedups with almost the same accuracy.
- (3)
We devise a novel reversible strategy . In the event that a feature map is provided with an arbitrary scale, the remaining feature maps are generated for the detector, thereby ensuring that efficiency and accuracy are fully leveraged. The strategy achieves 1.61× to 1.76× speedups without sacrificing detection accuracy.
Extensive experimentation has yielded clear evidence that the proposed algorithm significantly accelerates the inference of image pyramid-based object detection frameworks, while exhibiting performance that is comparable to that of other sophisticated remote sensing object detection algorithms.
3. Scale Selection Network
This section presents a detailed and structured overview of each unit within our proposed pipeline, as illustrated in
Figure 3. Our approach consists of three main stages: initial scale prediction, scale semantic transfer, and feature map generation.
Initial Scale Prediction. First, we use a lightweight Global Scale Attention Network (LGSAN), which predicts the potential scales in an image. LGSAN forecasts the prospective dimensions of an image, and the designated layers in the pyramid are chosen to ensure that all objects fall within the detection range of the detector, while the rest of the layers in the image pyramid are ignored.
Scale Semantic Transfer. Next, the middle scale image is designated to forward the Fully Convolutional Network (FCN), e.g.,
. In the scale semantic transfer stage, the middle feature map
is sent to our proposed Residual Scale Semantic Feature Projection
as illustrated in
Figure 4.
Feature Map Generation. processes the mid-scale image only once to efficiently generate feature maps for images at multiple scales. It contains two units: Scale Semantic Feature Upsampling () and Scale Semantic Feature Downsampling (). is used for predicting the scale semantic feature map corresponding to a 2× image, while is used to predict other scale semantic feature maps of × images.
The advantage of our algorithm lies in its efficiency; by processing the mid-scale image only once, there is no need to process each scale in the image pyramid individually. This significantly reduces computational complexity and enhances performance. More detailed descriptions of each component and their interconnections are introduced in the subsequent sections.
3.1. LGSAN
The feature pyramid mechanism is an excellent method for remote sensing object recognition with scale variance. Scale semantic information at various levels is suitable for finding the appropriate scales. The detector adds significant support to the capacity to handle scale variance and improves performance. However, this mechanism brings huge computational cost. The image captured by a camera may not include objects at all scales. The detector has to detect objects at all scales one after the other, as it is not possible to determine in advance at which scale the object is present. Redundant scales result in additional computational costs. In light of the necessity to strike a balance between the speed of inference and the accuracy of detection, we put forward the LGSAN as a means of predicting potential scales. It significantly accelerates the multi-shot single-scale detector while maintaining excellent performance.
3.1.1. Scale Index Mapping
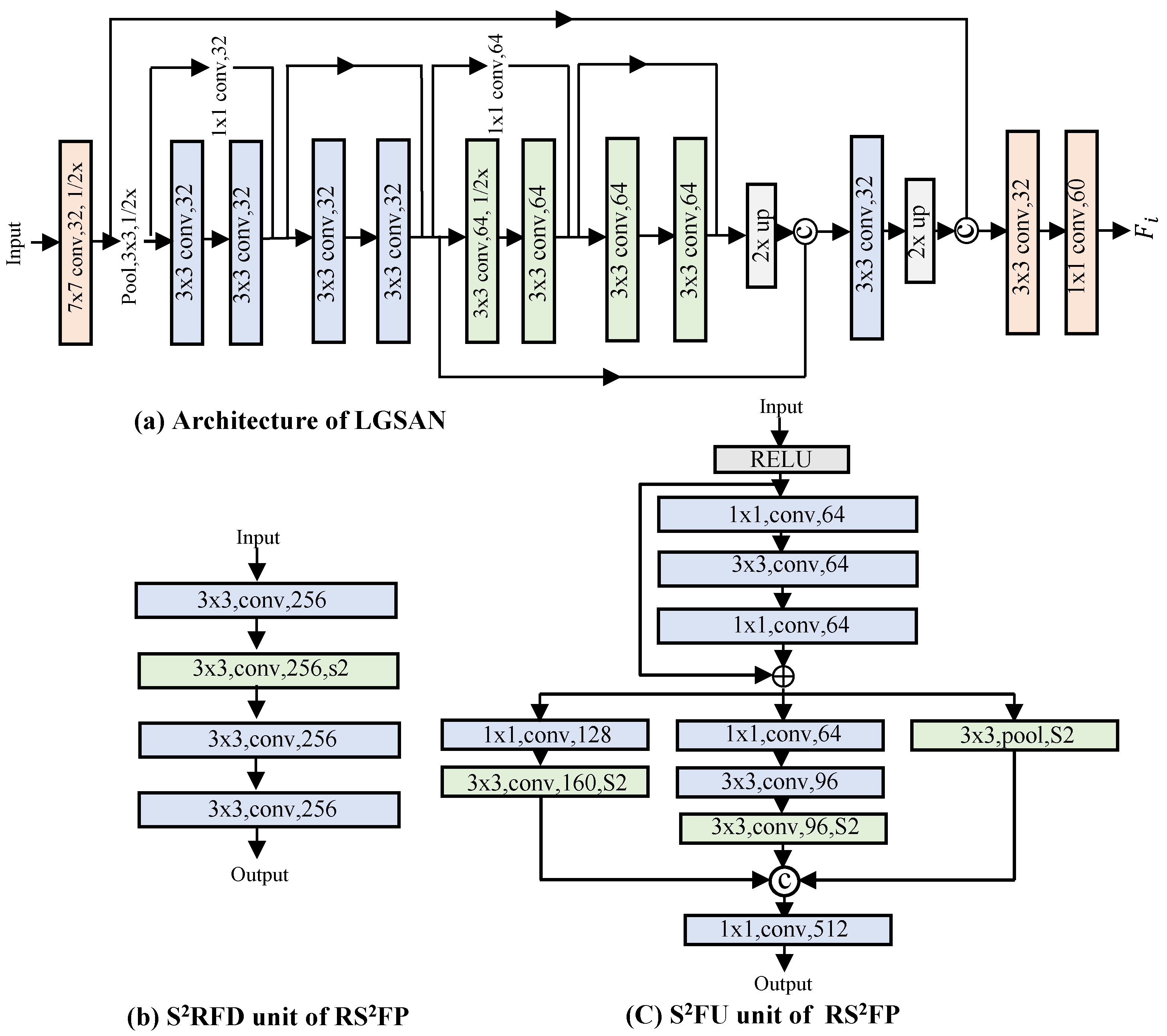
The primary limitation to the image pyramid’s advancement is the necessity to extensively sample layers such that the detector can capture all objects of varied sizes. The process of aimless sampling is inherently time-consuming, and in order to more effectively address this challenge, we have designed LGSAN with a mere 800 K parameters.
The input image I has a resolution of 224 × 224. The output is a 60-length vector named . Each pixel value represents the likelihood that the matching scale object exists. The 224 × 224 image is created by scaling an arbitrary-sized image and applying border interpolation. Consider an image with a long edge and its ground truth , which specifies the locations. The mapping of the scale index in and is as follows:
Firstly, the area of each ground truth bounding box
is calculated with:
where
represents the square root of the area of the bounding box
t.
Next, we normalize this area with respect to the maximum dimension of the image, while scaling it logarithmically to align with a broader range of object sizes found in
:
where
scales and normalizes the bounding box size
so that it fits within a logarithmic scale range tailored to the dimensions of a typical 224 × 224 image.
Finally, we update the corresponding position in the vector
:
where
t represents the number of boxes in
and
is rounded down as an exponent in the non-integer case. Thus, the object scale associated with
is decoded into
. This step assigns a value of ‘1’ to the vector
at the position corresponding to the normalized scale index
, indicating the presence of an object of that scale. Note that
is rounded down to eliminate non-integer issues and ensure a clear index mapping.
This comprehensive approach ensures that our model accurately captures and represents varying object sizes within a consistent framework. By elaborating on these steps and their rationale, we aim to provide a more transparent understanding of the object scale encoding process.
The rationale behind the utilization of Equations (2) and (3) for image coding is to compute an object-to-image ratio of the long edges where the object exists to the long edges of the input image. This ratio enables the inversion of the object’s scale, thereby facilitating the attainment of a mathematical abstraction of the object scale.
After abstracting the scale information of the target object into numbers, we can train a shallow neural network to predict the possible scales of the target objects within the image. The output vector is a one-dimensional vector of length 60, and their values represent the probability that the prediction network believes that a target object exists at each mapping scale, and when this value is above a threshold, the prediction network believes that the image contains a target object of the corresponding mapping scale.
3.1.2. Landmark Guided Constraint
In order to make LGSAN robust for different scale objects, we use the landmark information to constrain
, which is used for generating
by a max-pooling operation [
47].
represents the landmarks of an object corresponding to
, with
,
, and
representing the two diagonal coordinates of the upper-left and lower-right corners as well as the coordinates of the centre point, respectively.
is a feature map with the shape 112 × 112 × 60. The values of the coordinates in the neighborhood collections are assigned as follows:
where
means the stride of LGSAN. For
, the Manhattan Distance
is used to find its neighborhood within a given radius
r. Let
represent the neighborhood collections of
; we have:
The output of LGSAN is a one-dimensional vector of length 60, which represents the network’s confidence prediction of the scale-mapping information that may be present in the image. However, what we need to obtain in the next stage is the scale information present in the image, and therefore, the one-dimensional vector needs to be mapped back into the layers of the pyramid.
Taking the 5-layer pyramid detection structure used in this paper as an example, we divide the 60 sets of values into five groups of [1, 12], [13, 24], [25, 36], [37, 48], [49, 60], which correspond to , , , , and , respectively. These 60 values are examined sequentially to find the groups in which all the numbers exceeding the threshold are located.
As shown in
Figure 3, the 33rd to 37th values and the 45th value given by the prediction network in that round of detection are greater than the threshold, and they fall in the intervals [25, 36] and [37, 48], respectively, which corresponds to
and
, respectively. By way of analogy, it is possible to predict the extent of the presence of all objects in the image based on the one-dimensional vectors of the LGSAN output, and guide the subsequent detection network to choose the pyramid that enables the corresponding layer.
LGSAN is a network of minimal complexity, comprising a feature pyramid mechanism that is more accommodating of scale variations. Empirical evidence indicates that our approach markedly accelerates the detection of remote sensing objects and yields results that are commensurate with those achieved by alternative methods.
3.2.
In this paper, we propose a novel
network based on the image pyramid with both efficiency and accuracy, which contains
and
for the reversible scale semantic transform. In order to proceed, a feature map corresponding to the middle scale image in the image pyramid must first be provided;
helps transfer it to a high-level scale semantic for detecting smaller objects, and
helps to recurrently transfer it to 2× for detecting other objects. The
unit is designed to predict feature maps on arbitrary scales in an image pyramid.
Figure 5 illustrates the specifics of
.
With the underlying structure derived from ResNet [
48].
contains two units,
and
, which are used for predicting the scale semantic feature map corresponding to a 2× image and other scale semantic feature maps of a
× image. In this paper,
is the full-size feature map generated in the original detector, and
is the full-size feature map quickly generated in this paper using a feature generation network. In the training stage,
will be used as the instructor of
, and the approximation training will be carried out using L2 Loss to ensure that the
generated by
can approximate
nearly perfectly. Without affecting the detection performance of the detector, the direct generation of the feature maps saves a great deal of computation.
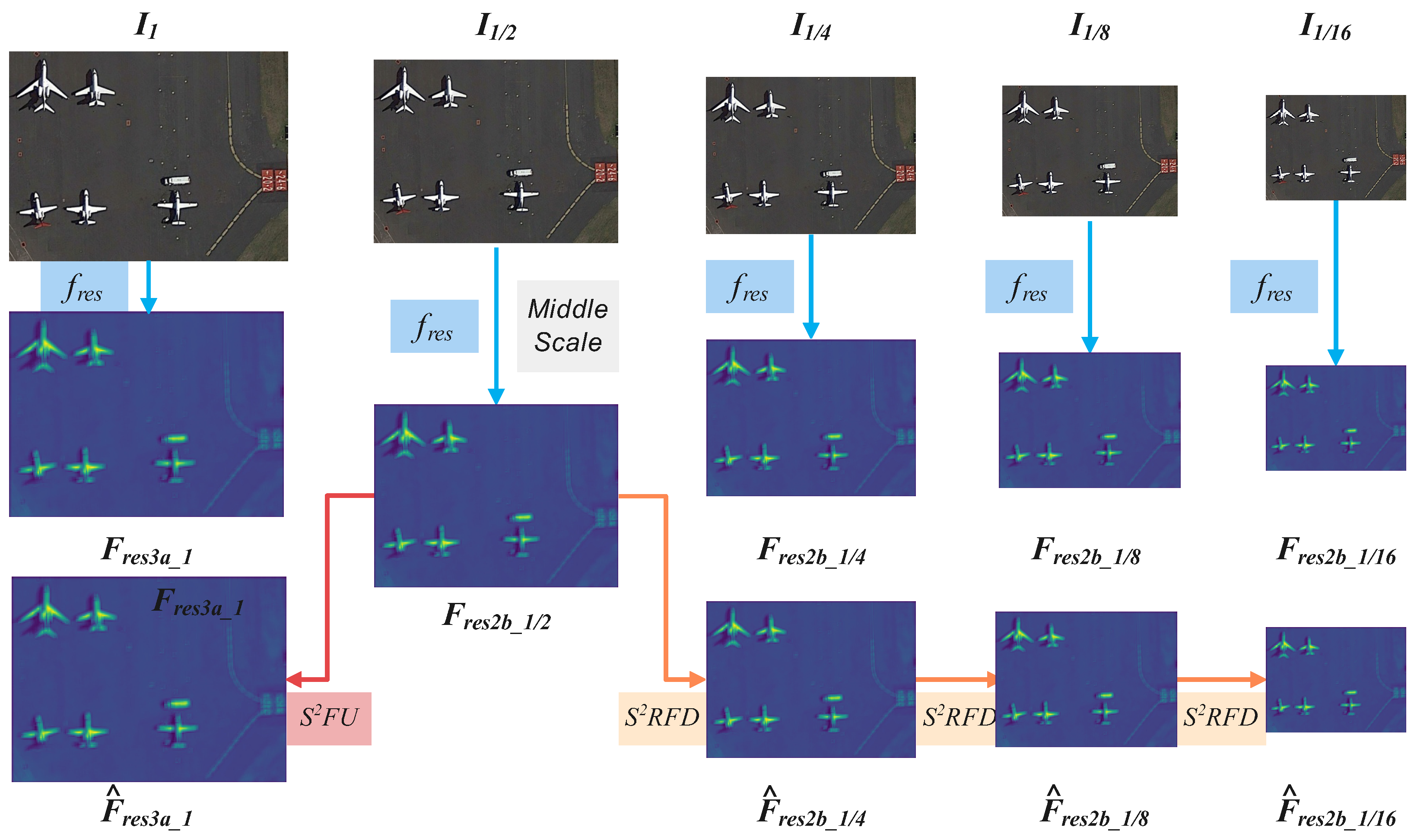
We chose the image at 1/2 scale as the intermediate layer, which is intended to balance inference speed and detection accuracy. The experiments showed that selecting the original image is time-consuming, while selecting a 1/4 scale as the intermediate layer significantly reduces the final detection accuracy.
3.3. Training Pipeline
Through coordination among LGSAN,
, and the base detector, we have produced a multi-shot single-scale detector. The Res-101 model [
48], from input to Res-3b3 with a stride of 16, is employed as the backbone for object detection at scales [64, 128]. In this way, we only use one anchor with a fixed size [64].
The image pyramid P = [0, 4] with five layers is used for assisting the detector to handle scale variance. Obviously, LGSAN is applied naturally to the image pyramid. We select some specific layers in the image pyramid P according to the predicted scales of LGSAN, which largely reduces the invalid computation caused by aimless dense sampling in the image pyramid. In order to obtain different scale semantic feature maps for the purpose of detecting objects, the image pyramid must forward the images through a series of stages at varying scales. The scale semantic flow-up-preserving and scale semantic flow-down-preserving mechanisms work effectively.
Given the middle scale image, we obtain all of the scale semantic feature maps corresponding to different scale images by forwarding it only once. It is not difficult to see that LGSAN, , and the base detector work together harmoniously. LGSAN instructs the to only transfer the valid scale semantic feature maps and both of them accelerate the base detector without performance loss. The details of the experiments are shown in a later section.
Training Loss
Both of the training losses of
and
are cross-entropy losses:
where
represents the computed label and
represents the output. During the inference stage, the potential object scale is calculated based on the predicted
. To ensure that all objects are within the detection range, the specific layers in the image pyramid are selected. The L2 Loss for
is defined as follows:
where N represents the number of pixels in F. In the stage of inference, as shown in
Figure 4, the middle scale
is selected to forward the base detector and generate the
and
. Then,
and other
are transferred by the flow-up unit
and recurrent flow-down unit
.
The total loss used in this study is a weighted mixture of Equations (
7) and (
8):
where
represents the loss function of the landmark-guided scale attention network referenced in
Section 3.1, and
represents the
strategy referenced in
Section 3.2. In this paper, the weighting factor, denoted by
, is set to 0.5 based on experimental evidence.
Finally, the use of and allows for the detection of different scale objects, according to the base detector. This approach has the advantage of reducing the computational cost, particularly in comparison to the image pyramid.
4. Experiments
In this section, we undertake a series of comprehensive experiments to validate the efficacy of LGSAN and . Subsequently, an ablation study is conducted to assess the enhancement of various elements of the base detector. Finally, we undertake a comparative analysis of our proposed pipeline with the current advanced remote sensing object detection method, utilizing a selection of the most widely used standard benchmarks.
4.1. Setup and Implementation Details
In this section, the datasets and experimental setup details are presented. Subsequently, the SSN algorithm proposed in this paper is analyzed qualitatively and quantitatively in comparison with other advanced algorithms on DOTA-v1.0 [
49], DOTA-v1.5 [
49], DOTA-v2.0 [
50], HRSC2016 [
51], and FAIR1M [
52]. Subsequently, an ablation study is conducted to substantiate the efficacy and plug-and-play characteristics of the modules.
4.2. Datasets
4.2.1. DOTA
DOTA-v1.0 represents a comprehensive dataset for the purpose of object detection in remote sensing images, thereby facilitating the development and evaluation of detectors [
49]. DOTA-v1.5 employs the identical images as DOTA-v1.0, yet incorporates annotations for instances measuring less than 10 pixels [
49]. DOTA-v2.0 builds upon this foundation by incorporating a more expansive array of data sources [
50]. The database includes two additional categories not present in DOTA-v1.5: airports (AIR) and helicopter pads (HP).
4.2.2. FAIR1M
The FAIR1M dataset, released in 2021, comprises a large-scale rotation box dataset for object detection in remote sensing images [
52]. It comprises 15,266 images and 37 subcategories, including aircraft, ships, vehicles, sports fields, and roads. Compared to existing fine-grained detection datasets, FAIR1M offers significantly more instances and images. It offers more detailed and nuanced classification data and superior image quality.
4.2.3. HRSC2016
HRSC2016 is a dataset released in 2016 for ship detection in optical remote sensing images [
51]. All images included in the HRSC2016 dataset have been sourced from Google Earth and originate from six major ports. The dataset features two scenarios: offshore and nearshore vessels. It contains 1061 images, totaling 2976 object instances. Annotations are provided in three formats: horizontal boxes, rotated boxes, and key point markers. Ships are classified into three levels to support fine-grained detection tasks.
4.2.4. Metrics
We report results for the mean Average Precision (mAP), which is a common metric in the field of object detection. A higher mAP is better.
4.2.5. Training Details
Base Detector. The LGSAN is a lightweight FPN structure with 800 K parameters and the input size is 224 × 224. Both and consist of two Res-Blocks with a total stride of 2. The positive/negative sample ratio is set at 1:1. The batch size is 8. SGD is used as the optimizer and in the preprocessing of the image. The speed is tested on an RTX 3080.
Data Enhancement. During training, a random subset of four photographs is chosen and enhanced with horizontal flipping (with a 50% probability), random cropping (20% to 80% of the original image size), and multi-scale transformation (scales ranging from 0.8 to 1.5) to enrich scale information in the data. This transformation also results in the conversion of potential multi-scale objects within the images into small-to-medium objects. The probability of utilizing this data enhancement during training is set to 0.5. After completing the training, this enhancement is disabled for the initial 10 rounds. This is because the semantic information obtained from these images differs significantly from the training images, which prevents the model from converging to a local minimum.
Learning Rate Decay. This step aims to increase the detection model’s sensitivity towards the dataset’s scenes, thereby attaining an enhanced detection accuracy. For optimal convergence and improved parameter sensitivity, the learning rate undergoes a gradual increase from 0 to 0.01 within the first 500 iterations of the model through linear warm-up during the initial stages of training.
4.3. Experiments on the DOTA Dataset
DOTA-v1.0. We compared the proposed SSN algorithm with advanced remote sensing object detection algorithms, including RetinaNet [
53], Faster R-CNN [
54], RoI Transformer [
55], S2ANet [
56], SASM [
57], Gliding Vertex [
58], AOPG [
59], ARC [
60], and Oriented R-CNN [
61], using the DOTA-v1.0 dataset.
The results of the experiment are presented in
Table 1. Our method achieved the highest detection accuracy for the categories of basketball courts (BC), baseball diamonds (BD), bridges (BR), large vehicles (LV), airplanes (PL), ships (SH), storage tanks (ST), and tennis courts (TC). The SSN algorithm attained 77.76% mAP. When using Res-50 as the backbone, it achieved a fastest frame rate of 16.8 FPS. These results demonstrate that the SSN algorithm effectively addresses multi-scale variation while maintaining a high inference speed in remote sensing object detection tasks.
The superior performance of the SSN algorithm can be attributed to its effective multi-scale feature extraction and semantic transformation capabilities. By leveraging the LGSAN and modules, the algorithm ensures that objects at various scales are detected accurately without loss of critical information. Additionally, the harmonious integration of these modules with the base detector accelerates the detection process while preserving performance.
DOTA-v1.5. We compared the SSN algorithm with advanced algorithms, including GWD [
62], KLD [
63], Faster R-CNN [
54], Master R-CNN [
39], HTC-O [
64], S2ANet [
56], RoIT [
55], ReDet [
65], and Oriented R-CNN [
61]. The SSN algorithm achieved 67.12% mAP and the fastest frame rate of 18.9 FPS on the DOTA-v1.5 dataset. The rResults are presented in
Table 2. The proposed method demonstrated the highest accuracy in the detection of five categories, namely, bridges (BR), ground track field (GTF), harbour (HA), helicopter (HC), and tennis courts (TC).
The SSN algorithm’s advantage over these methods lies in its ability to detect objects with varying scales more accurately, thanks to its efficient multi-scale semantic feature transformation. Unlike traditional detectors that may lose fine-grained details when scaling, our approach maintains critical information through the learnable unit.
DOTA-v2.0. On the DOTA-v2.0 dataset, SSN attained a second-highest mAP of 54.02% with the same frame rate of 18.9 FPS. The results are presented in
Table 3. The proposed method demonstrated optimal performance in terms of detection accuracy for the categories of bridges (BR), ships (SH), and soccer ball fields (SBF). The evaluation results demonstrate that the SSN algorithm optimally balances detection accuracy and speed, outperforming existing advanced algorithms.
Compared to algorithms like Faster R-CNN and S2ANet, our SSN algorithm offers a better trade-off between speed and accuracy. The use of LGSAN helps in calculating the potential object scale, ensuring that all objects fall within the designated detection range, while preserves the semantic integrity of the feature maps. These differences are crucial in practical applications where both speed and accuracy are of the essence.
4.4. Experiments on the HRSC2016 Dataset
HRSC2016. We conducted a comparison of the proposed SSN algorithm with advanced remote sensing object detection models, including Rotational R-CNN [
66], Rotated RPN [
67], RetinaNet [
53], RoIT [
55], DRN [
68], PIoU [
69], CSL [
70], DAL [
71], Gliding Vertex [
58], S2ANet [
56], R3Det [
72], RSDet [
73], BBAVectors [
74], DCL [
75], GWD [
62], KLD [
63], and Oriented R-CNN [
61], using the HRSC2016 dataset.
The results of the experiment are presented in detail in
Table 4. The SSN algorithm based on Res-50 achieved the fastest frame rate of 17.2 FPS. The Res-101 version reached 90.56% mAP (07) and 97.72% mAP (12), representing the highest detection accuracy. Moreover, when evaluated under the same backbone network, our SSN algorithm demonstrated the optimal performance–accuracy trade-off among all comparison methods. This demonstrates the algorithm’s advancement in remote sensing object detection. The experimental results provide further evidence that the SSN algorithm proposed in this paper offers an optimal balance between performance and accuracy. Our proposed algorithm not only achieves the fastest detection speed, but also demonstrates highly competitive performance under the same backbone network.
4.5. Experiments on the FAIR1M Dataset
FAIR1M. In order to provide further evidence of the algorithm’s efficacy, we conducted a comparative analysis between the proposed SSN method and a number of advanced remote sensing object detection models, including RetinaNet [
53], S2ANet [
56], GlidingVertex [
58], FRCNN [
54], RoIT [
55], and ORCNN [
61], using the FAIR1M dataset. The experimental results are presented in
Table 5. The SSN algorithm achieved the fastest frame rate of 18.2 FPS. Additionally, it attained the highest accuracy across 11 subclasses, including Airbus A321 (A321), Boeing 737 (B737), Boeing 777 (B777), COMAC C919 (C919), dry cargo ship (DCS), engineering ship (ES), tugboat (TB), dump truck (DT), excavator (EX), baseball field (BF), and tennis court (TC). The results illustrate the remarkable efficacy of the SSN algorithm in processing extensive remote sensing image datasets.
4.6. Analysis of Remote Sensing Object Detection
With the assistance of LGSAN, the potential object scale in an image is calculated in accordance with the predicted during the inference stage. Particular layers within the image pyramid are selected in order to guarantee that all of the objects fall within the designated detection range.
Furthermore, creates the feature maps and for a given middle image, solves the multi-scale semantic transformation problem. It is not difficult to see that LGSAN, , and the base detector work together harmoniously. LGSAN instructs the to only transfer the valid scale semantic feature maps and both of them accelerate the base detector without performance loss. We confirm that the transfer of scale semantic information in the image pyramid is reversible.
Table 5.
Comparison with other remote sensing object detection algorithms on the FAIR1M Dataset.
Table 5.
Comparison with other remote sensing object detection algorithms on the FAIR1M Dataset.
| CoarseCategory | Airplane | Airplane | Airplane | Airplane | Airplane | Airplane | Airplane |
|---|
|
SubCategory
|
B737
|
B747
|
B777
|
B787
|
C919
|
A220
|
A321
|
|---|
| RetinaNet [53] | 35.24 | 74.90 | 10.54 | 38.49 | 0.96 | 41.39 | 63.51 |
| S2ANet [56] | 36.06 | 84.33 | 15.62 | 42.34 | 1.95 | 44.09 | 68.00 |
| GlidingVertex [58] | 36.50 | 81.88 | 14.06 | 44.60 | 10.16 | 46.43 | 65.47 |
| FRCNN [54] | 33.94 | 84.25 | 16.38 | 47.61 | 14.44 | 47.40 | 68.82 |
| RoIT [55] | 39.15 | 84.72 | 14.82 | 48.88 | 19.49 | 50.31 | 70.16 |
| ORCNN [61] | 35.17 | 85.17 | 14.57 | 47.68 | 11.68 | 46.55 | 68.18 |
| ORCNN-TTA [61] | 41.09 | 85.95 | 17.38 | 58.02 | 20.93 | 44.76 | 68.31 |
| SSN | 38.12 | 85.74 | 16.80 | 47.59 | 18.29 | 47.42 | 70.71 |
| SSN-TTA | 42.23 | 84.99 | 18.85 | 57.01 | 20.96 | 48.93 | 71.28 |
| CoarseCategory | Airplane | Airplane | Court | Court | Court | Court | Road |
| SubCategory | A330 | A350 | BC | BF | FF | TC | BR |
| RetinaNet [53] | 46.28 | 63.42 | 27.51 | 87.89 | 55.44 | 79.20 | 4.38 |
| S2ANet [56] | 63.84 | 70.00 | 38.44 | 87.47 | 56.34 | 80.44 | 17.24 |
| GlidingVertex [58] | 67.73 | 68.31 | 45.83 | 86.08 | 59.27 | 77.99 | 22.82 |
| FRCNN [54] | 72.71 | 76.53 | 45.18 | 87.19 | 52.05 | 77.75 | 20.76 |
| RoIT [55] | 70.34 | 72.19 | 46.93 | 87.21 | 56.72 | 79.29 | 23.31 |
| ORCNN [61] | 68.60 | 70.21 | 48.18 | 88.43 | 60.79 | 78.45 | 28.63 |
| ORCNN-TTA [61] | 74.48 | 76.74 | 54.70 | 89.60 | 65.59 | 83.08 | 30.60 |
| SSN | 70.20 | 69.42 | 46.65 | 89.12 | 55.03 | 80.69 | 25.45 |
| SSN-TTA | 73.83 | 74.54 | 54.80 | 89.77 | 61.86 | 83.48 | 27.97 |
| CoarseCategory | Road | Road | Ship | Ship | Ship | Ship | Ship |
| SubCategory | IS | RA | DCS | ES | FB | LCS | MB |
| RetinaNet [53] | 54.38 | 23.91 | 21.75 | 6.98 | 2.52 | 7.39 | 23.00 |
| S2ANet [56] | 50.76 | 16.67 | 37.62 | 7.49 | 6.79 | 18.30 | 48.03 |
| GlidingVertex [58] | 58.19 | 19.45 | 33.10 | 10.34 | 5.26 | 14.53 | 51.63 |
| FRCNN [54] | 58.71 | 19.38 | 32.26 | 9.41 | 6.41 | 15.17 | 51.22 |
| RoIT [55] | 58.21 | 21.98 | 34.15 | 9.27 | 6.12 | 15.95 | 55.98 |
| ORCNN [61] | 57.90 | 17.57 | 38.22 | 11.32 | 9.10 | 21.86 | 60.42 |
| ORCNN-TTA [61] | 60.83 | 19.50 | 38.42 | 14.11 | 13.40 | 26.75 | 70.13 |
| SSN | 57.26 | 18.95 | 39.45 | 10.89 | 10.76 | 18.98 | 58.56 |
| SSN-TTA | 59.51 | 19.02 | 39.86 | 15.24 | 12.85 | 26.48 | 66.77 |
| CoarseCategory | Ship | Ship | Ship | Vehicle | Vehicle | Vehicle | Vehicle |
| SubCategory | PS | TB | WS | Bus | CT | DT | EX |
| RetinaNet [53] | 5.78 | 24.87 | 2.75 | 4.25 | 18.38 | 12.59 | 0.13 |
| S2ANet [56] | 8.82 | 34.01 | 22.96 | 11.76 | 34.28 | 36.03 | 7.24 |
| GlidingVertex [58] | 10.01 | 34.00 | 12.45 | 28.63 | 36.90 | 42.16 | 12.19 |
| FRCNN [54] | 11.03 | 34.19 | 11.27 | 22.94 | 37.74 | 41.69 | 11.35 |
| RoIT [55] | 12.62 | 35.31 | 15.29 | 26.43 | 39.38 | 44.95 | 10.99 |
| ORCNN [61] | 13.77 | 36.83 | 22.67 | 24.40 | 40.84 | 45.20 | 13.55 |
| ORCNN-TTA [61] | 17.63 | 33.75 | 31.81 | 48.74 | 49.98 | 57.38 | 20.87 |
| SSN | 14.52 | 35.46 | 17.34 | 26.85 | 38.90 | 47.51 | 15.65 |
| SSN-TTA | 16.78 | 37.85 | 27.15 | 36.16 | 47.08 | 57.65 | 21.08 |
| CoarseCategory | Vehicle | Vehicle | Vehicle | Vehicle | Vehicle | mAP | FPS |
| SubCategory | SC | TRC | TRI | TT | VAN | - | - |
| RetinaNet [53] | 37.22 | 0.02 | 0.01 | 0.03 | 26.44 | 27.32 | - |
| S2ANet [56] | 61.57 | 0.96 | 3.47 | 0.40 | 54.62 | 35.39 | 14.7 |
| GlidingVertex [58] | 54.39 | 1.39 | 13.38 | 0.19 | 48.52 | 36.78 | - |
| FRCNN [54] | 54.56 | 2.44 | 12.46 | 0.32 | 48.23 | 37.15 | 15.0 |
| RoIT [55] | 57.55 | 2.13 | 10.95 | 0.60 | 53.69 | 38.64 | 12.4 |
| ORCNN [61] | 57.62 | 2.37 | 15.46 | 0.24 | 54.01 | 39.26 | 16.8 |
| ORCNN-TTA [61] | 74.42 | 5.38 | 21.06 | 3.49 | 75.39 | 45.28 | 8.1 |
| SSN | 66.71 | 2.51 | 12.32 | 0.69 | 58.26 | 39.78 | 18.2 |
| SSN-TTA | 69.42 | 4.97 | 20.89 | 2.51 | 66.65 | 44.19 | 7.4 |
In the case of an arbitrary scale feature map, both the feature maps for detecting objects at double the scale and those for objects at half the scale are generated by it according to without lack of important information. A scheme of this nature has the potential to feed the network with a single, middle-scale image on a single occasion, with the remaining features approximated on either a smaller or larger scale through the use of a learnable unit, thereby ensuring both efficiency and accuracy. Extensive experiments demonstrated that the proposed algorithm significantly speeds up the inference process while maintaining high performance standards.
Figure 6 shows the comparative results of remote sensing image detection using DOTA-v1.0. The original images are too small for effective observation, so we magnified the local areas during visualization. Oriented R-CNN [
61] is an advanced approach for remote sensing image detection; however, it suffers with precise recognition of tiny objects. The SSN framework proposed in this study makes progress in addressing the issues of false positives and false negatives for small objects. It improves detection accuracy through scale prediction and semantic generation.
We have selected a subset of remote sensing images from DOTA-v1.0 additionally for the purpose of object detection and visualization. The detection results of the algorithm are presented in
Figure 7, featuring multi-scale objects in complex scenes. In the display figure, differently classified objects are marked using different colored boxes, along with the model’s classification results for that object with their corresponding confidence scores. The results clearly indicate that the SSN algorithm excels in object detection under challenging remote sensing conditions and substantiate the efficacy of the proposed method for object detection in remote sensing images.
The results of the detection process demonstrate that the algorithm presented in this paper is capable of accurately identifying a wide range of objects with significant variations in scale, including vehicles, ships, aircraft, and other common targets, even in the context of remote sensing images captured in complex scenes.
Extensive experiments have shown that the proposed SSN approach not only greatly accelerates the inference speed of the image pyramid-based object detection framework, but also its performance is comparable to other complex remote sensing object detection algorithms, which proves that our algorithm well achieves the balance point between detection accuracy and inference speed. Nevertheless, our model may be challenged by extreme scale variations and occlusions, which are areas for further improvement.
4.7. Ablation Study
We selected the traditional two-stage object detection framework as our baseline method. This framework is augmented with a feature pyramid network. Additionally, we conducted tests on each enhanced module recommended in the preceding section. The objective of these tests was to ascertain the individual efficacy of each module in detecting objects.
Module Validity. To further elucidate this study’s validity, we conducted an ablation study on the HRSC2016 using each SSN module. The backbone is based on ResNet, and we incorporated the LGSAN and
modules proposed in this research sequentially. As demonstrated in
Table 6, incorporating only the LGSAN module resulted in a 2.93× to 3.42× improvement in inference speed with a maximum loss of 0.02% in detection accuracy. As can be seen from
Table 6, under the Res-50 model benchmark detector, the addition of LGSAN only increases the number of model parameters by 0.4M, and at the same time reduces the total model computation from 170.3 GFLOPs to 29.4 GFLOPs due to the network’s ability to skip the pyramid computation where no scaling exists. This demonstrates that the LGSAN we designed is a very subtle lightweight model.
Similarly, using only the module resulted in an inference speed boost of 1.61× to 1.76× whilst limiting the loss of detection accuracy to a maximum of 0.04%. When the module is used concurrently with the LGSAN module, the performance of both sub-modules remains superb. This results in a 5.21× to 5.34× increase in inference speed, with a maximum reduction of 0.07% in detection accuracy. The ablation study demonstrates that the proposed modules accelerate the detector independently without compromising accuracy. Additionally, they operate concurrently in an end-to-end network for superior inference acceleration.
4.8. Plug-and-Play Properties
LGSAN is a lightweight network that predicts the range of object scales in an image after pre-training on the dataset. This guides the detection framework to skip some scale feature map computations during the inference process, thus eliminating time consumption due to computational redundancy. The network’s predictions are based on the tendencies of scale distribution in real-life scenes. The module’s effectiveness has already been confirmed in the aforementioned object detection framework.
Subsequently, we extend our validation of LGSAN’s effectiveness to HRSC2016, a classical dataset for object detection. As shown in
Table 7, LGSAN eliminates computational redundancy and improves inference speed without significantly affecting inference precision. The network achieves 1.96×, 2.33×, 1.66×, and 1.71× enhancement on the Rotational R-CNN [
66], Rotated RPN [
67], RetinaNet [
53], and R3Det [
72] algorithms, respectively. The experiment reveals that the network efficiently handles the computational redundancy brought about by the scale distribution tendency in object detection scenarios.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}