To efficiently cater to the urgent matters in maritime rescue, we carefully considered the specific categories in the UAV remote sensing SeaDronesSee-MOT dataset:
swimmer,
swimmer with life jacket,
boat, and
life jacket. As far as we know, no other dataset has such detailed classifications as SeaDronesSee, making it extremely challenging to train a new tracker from scratch. Inspired by prompt learning [
55], we can use specific prompts such as category names to apply a pretrained model to the SeaDronesSee dataset and other multi-class multi-object tracking datasets such as BURST [
53], without making significant parameter adjustments or requiring large amounts of data. To use text prompts to track objects with fine classifications, we improve the well-known text–image object detector Grounding DINO [
17]. However, text is semantic in nature, and image features fused with text features mainly contain classification features. In addition, tracking also requires instance features for each object. Therefore, on this basis, we developed the
TG-MCMOT (
Text-
Guided
Multi-
Class
Multi-
Object
Tracker).
3.1.2. Encoder
We follow the well-known pre-trained language model architecture, Bidirectional Encoder Representations from Transformers (BERT) [
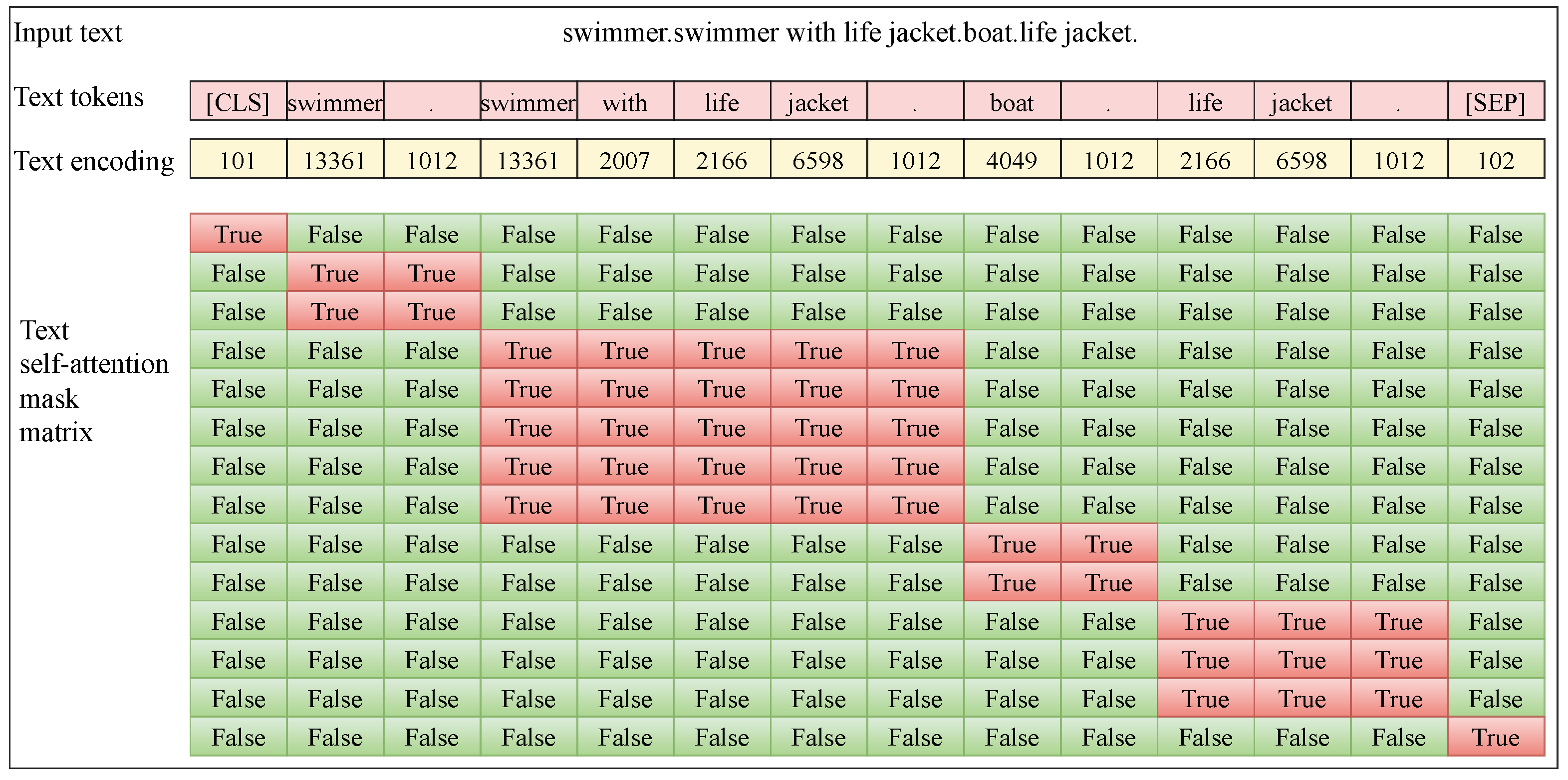
56] for text encoding. In the multi-class multi-object tracking task, the objects that need to be tracked in each video may not belong to the same category, but it may involve multiple categories. In the proposed TG-MCMOT method, the categories of interest that need to be tracked in each video are specified by the text. The BERT architecture can encode multiple sentences simultaneously and separate different sentences within the same text sequence, allowing downstream models to know which sentence each token belongs to. Therefore, in the proposed TG-MCMOT method, the names of the multiple object categories of interest in the video are considered individual “sentence”, i.e., connected with the English full stop “.”, for example, “swimmer.swimmer with life jacket.boat.life jacket.”. The details of the text encoding are shown in
Figure 4. BERT introduces a text self-attention mask matrix, as shown in
Figure 4, to delineate the boundaries of each sentence. Therefore, we focus only on the relative positions of words within each sentence, rather than the order of the sentences themselves.
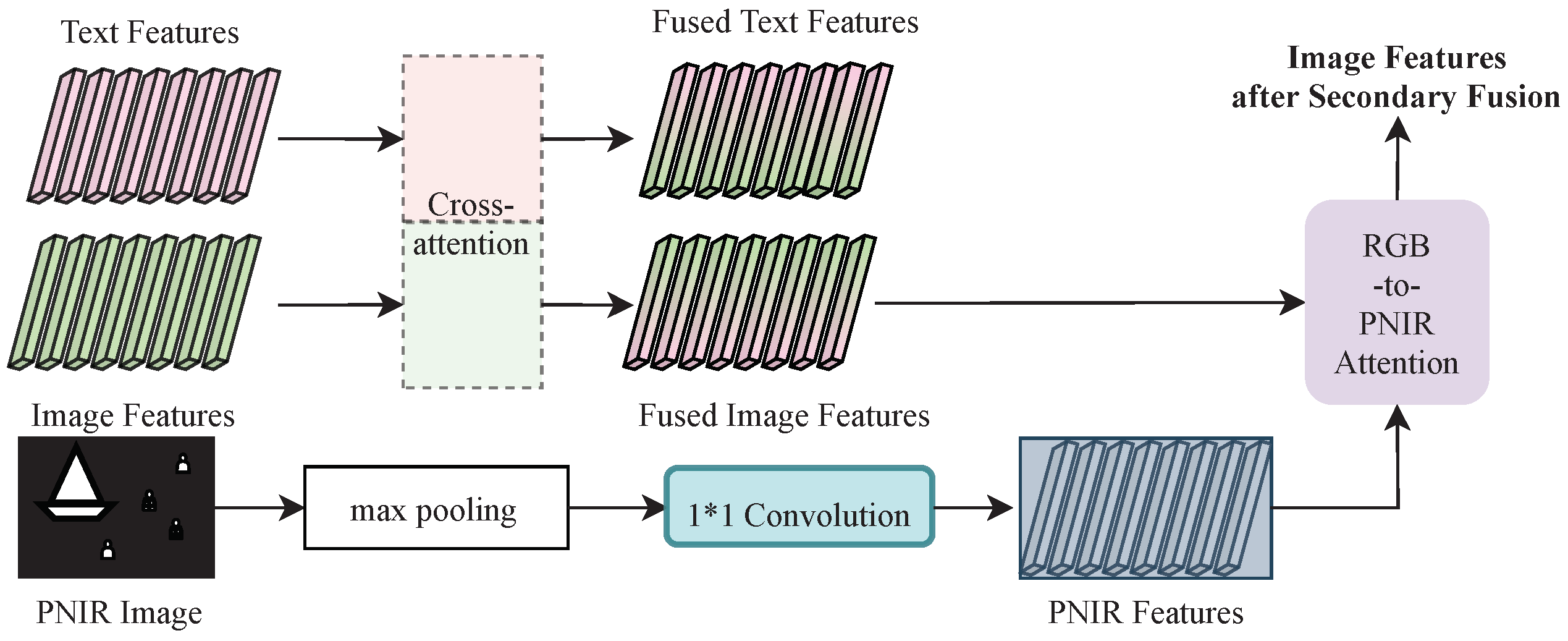
The primary function of TG-MCMOT encoder is to fuse category text features and image visual features using a cross-attention mechanism. Its structure is similar to the encoder of the object detection model Grounding DINO [
17], but the specific fusion steps are different. Grounding DINO first performs self-attention to text and image information separately, and it then fuses the information together, whereas our proposed TG-MCMOT first fuses text and image information and then applies self-attention to fused features, as shown in
Figure 5. Self-attention introduces positional information from the image and contextual information from the text into fused features.
The text contextual information includes the text position encoding and the text self-attention mask matrix. The text position encoding is a sinusoidal encoding that marks the positions of words within each sentence (category name) in a text sequence, indicating the location of each word in the sentence. The text self-attention mask matrix is used to decouple different category names within the same text sequence, preventing dependencies between different categories. The image position information is generated simultaneously with the extraction of image features by the image feature extractor, indicating the position information of image features at different scales. This includes position encodings for pixels at various scales, starting pixel index markers, shapes, and valid position mask markers. When introducing position information, image features utilize the multi-scale deformable attention module proposed in Deformable DETR [
58], which learns cross-scale features by sampling a set of “reference points”.
In the process of fusing image and text features, the feature fusion stage occurs before the introduction of positional information. However, both decoupled categorical text information and cross-scale image positional information are important for cross-modal information fusion. Moreover, as shown in
Figure 5, a single-feature fusion encoding and the introduction of positional information are not sufficient to extract the various levels of image features required for multi-object tracking tasks (such as depth features for detection tasks, abstract semantic-level features, and appearance, texture, and other instance-level features for tracking). Therefore, drawing on the experience of Grounding DINO, the encoding process shown in
Figure 5 was repeated six times in the TC-MCMOT encoder to facilitate cross-fusion of different category texts and different levels of image features. During the feature encoding process, the input text features and image features, apart from being the output of the text feature extractor and the image feature extractor for the first time, come from the output of the previous process at all other times.
3.1.3. Decoder
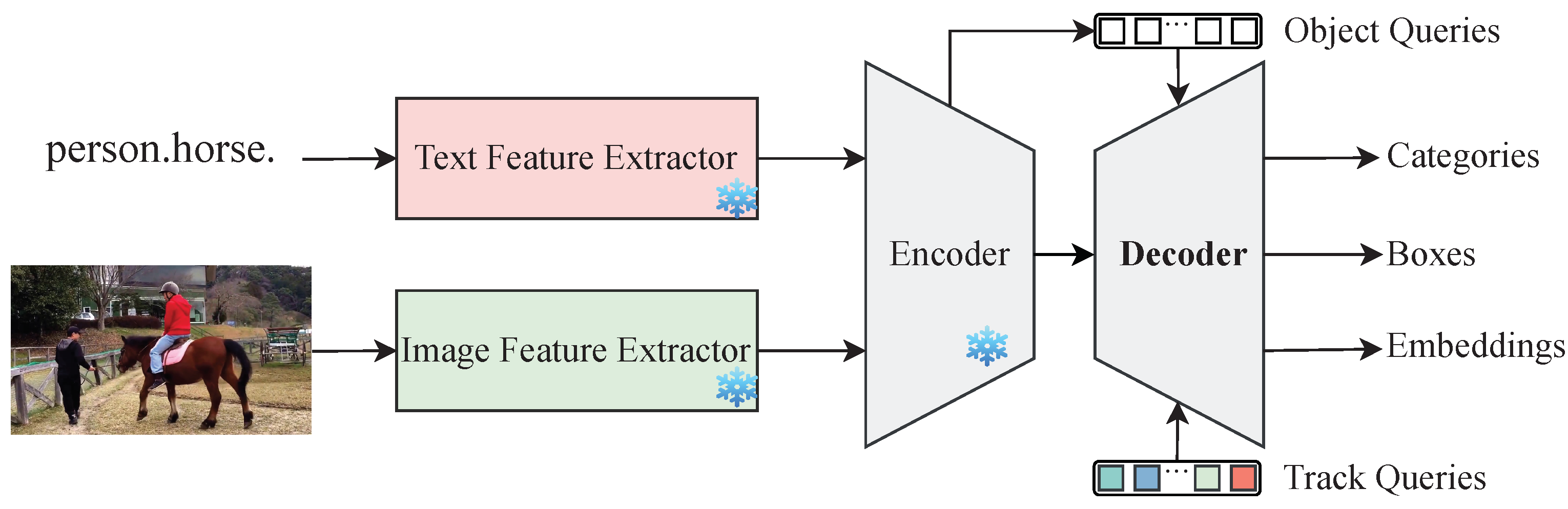
Multi-Object Tracking (MOT) involves two core subtasks: object detection and identity recognition. Multi-Class Multi-Object Tracking (MCMOT) adds complexity to these tasks, where the detection task must also deal with unknown categories. Therefore, TG-MCMOT follows Grounding DINO, using object queries for classification and localization to effectively address the detection task. In addition, TG-MCMOT introduces tracking queries to generate object identity embedding features.
The queries are considered anchors, and each pixel point at each scale of the image is the potential center of an anchor. To select those anchors that are more likely to contain objects, a contrast embedding module is used to calculate the attention scores of the image features output by the encoder to the text encoding that has not been fused with the image, and then the positions of the pixels with the highest attention to the text are recorded. The image feature vectors at these positions are the classification part of the object query. The positioning part of the object query is the sinusoidal encoding of the initial reference box at these positions. The initial reference box is the sum of the initial proposal box and the initial offset. The initial proposal box is centered on each pixel point , and the width and height of the proposal box are defined in four sizes according to four different scales of image features. The initial offset of the proposal box is calculated using some linear layers based on the image features. In addition to appearance features, object category features and location features are also part of object identity features. Therefore, the tracking query will be initialized as the object query first, but the learning and optimization in the later learning process will be different from that of the object query.
As shown in
Figure 6, the image features output by the encoder and the original text features pass through a contrast embedding module to select the image content for decoding at 900 positions. This content, which serves as classification and localization information, is added together to form the object query for the detection decoding module.
The detection decoding module, depicted as the light-blue part in
Figure 6, includes a multi-head self-attention module, a text cross-attention module, and a multi-scale deformable attention module. The outputs of these modules are all used to update the image content information, and the inputs of these modules are shown in
Table 1.
Half the TG-MCMOT decoder follows the decoder of Grounding DINO [
17]. To accomplish the task of object identity recognition, TG-MCMOT also adds a tracking decoding module in the decoder, as shown in the orange part of
Figure 6. Since text information is semantic-level categorical information, interacting with text information during the decoding process may result in the loss of instance-level features required for tracking. Therefore, the TG-MCMOT tracking decoding module lacks a text cross-attention module compared to the detection decoding module.
Since TG-MCMOT has six encoding layers in its encoder module, six decoding layers were also designed in the decoder module to decode features at different levels, with each following the decoding process shown in
Figure 6. Content information, tracking information, initial reference boxes, and updated reference boxes from each decoding layer were recorded.
According to the decoder output, the information of the 900 anchors can be predicted as follows:
Object Category: The content information output by the last layer of the decoder, after passing through a contrast embedding module, is guided by the original text features to obtain attention scores for the position of each anchor’s text category token in the text sequence. That is, the decoder does not predict the specific category, but the position of this category in the text sequence encoding, and the content at this position is the encoding of the text of the category name in the vocabulary.
Object Bounding Box: The reference box input to the last layer of the decoder and the offset output from the last layer are added to obtain the predicted bounding box of the object.
Object Identity Embedding: The tracking information output by each decoder layer is transformed into six different levels of object identity embedding features through a series of linear feature transformations.
3.1.4. Segmentation Module
TG-MCMOT also supports generating masks for objects, enabling the Multi-Class Multi-Object Tracking and Segmentation (MCMOTS) task. The segmentation module of TG-MCMOT utilizes the well-known Segment Anything Model (SAM [
59]), and unlike other methods that employ SAM as the segmentation module [
60,
61,
62,
63,
64], SAM in TG-MCMOT is capable of being co-trained with other modules. Specifically, when extended to the segmentation task, TG-MCMOT uses the object bounding boxes output by the decoder as box prompts for the SAM model to guide the generation of masks for the objects.
TG-MCMOT predicts bounding boxes for 900 queries. To reduce the computational cost of the model, only the bounding boxes corresponding to queries that are more likely to contain objects are selected as prompts for mask generation. During the training process, a matching algorithm is used to select some predicted bounding boxes based on the Ground Truth (GT) labels of the objects. The algorithm (Algorithm 1) will be introduced in the following. In the inference process, the top predicted detection boxes with the highest category location response scores were selected as prompts for the segmentation module.
The segmentation module plays a crucial role in providing pixel-level details that are more refined than bounding boxes for objects, allowing for a clear distinction of the contours and internal structures of each object in the image. Extending a segmentation branch to our TG-MCMOT model is vital for future applications that require precise understanding of image content, meticulous editing, or advanced analysis in complex scenes.
3.1.5. Training and Inference
For a single frame, the output of TG-MCMOT for object category is the category position prediction response scores for 900 queries, denoted to facilitate batch training, where the TG-MCMOT uniformly sets the length of the sequence token encoding to 256 so is a vector with size . The output of TG-MCMOT for object bounding boxes is the center coordinates and width and height of the predicted bounding boxes for 900 queries, denoted , which is a vector with size .
We selected queries that were closest to the GT through a matching Algorithm 1. Based on the object categories in the GT labels and the text decoding guide, a true category position response of length
(256) was generated for each object. The true category position responses corresponding to the
N objects in the current image are denoted as
, which is a vector with size
. Object bounding boxes in GT labels are recorded as
, which is a vector with size
.
| Algorithm 1 The matching algorithm for queries and GT labels |
Require: The output of TG-MCMOT: and , GT labels of objects: and
Ensure: One-to-one matching between queries and GT labels- 1:
- 2:
- 3:
- 4:
- 5:
, denotes GIoU loss [ 65] - 6:
- 7:
Match 900 queries and N real objects based on cost, and output a one-to-one corresponding “query index”-to-“real object index”
|
Based on the “query index”-to-“real object index” pairs output by Algorithm 1, we extended
N GT category position responses to 900 category position responses: the category position response of the query corresponding to object
was set to the GT category position response of object
i, and the category position responses of the other queries were set to 0. The extended GT category position responses are denoted
, with a size of
. Since the token encoding length
of a text sequence is uniformly set to 256, for short sequences, the latter part of the encoding is meaningless. Therefore, a text information mask is needed to truncate this part of the token encoding. For simplicity, the truncation encoding step is not reflected in the following classification loss calculation. The classification loss of TG-MCMOT is defined as follows:
where
denotes Binary Cross-Entropy (BCE) loss.
is the probability that the predicted value exactly matches the GT label:
is the probability weight when the predicted value responds to
:
We only calculate the localization loss for those queries that match the objects in the GT labels according to Algorithm 1. For object
i, its GT bounding box label is denoted
, and the query’s bounding box that matches it is recorded as
. The bounding box prediction loss of TG-MCMOT is defined as follows:
where bounding box loss is the weighted sum of
loss (
) and GIoU loss (
), with weights of
and
, respectively.
loss is defined as follows:
GIoU loss is defined as follows:
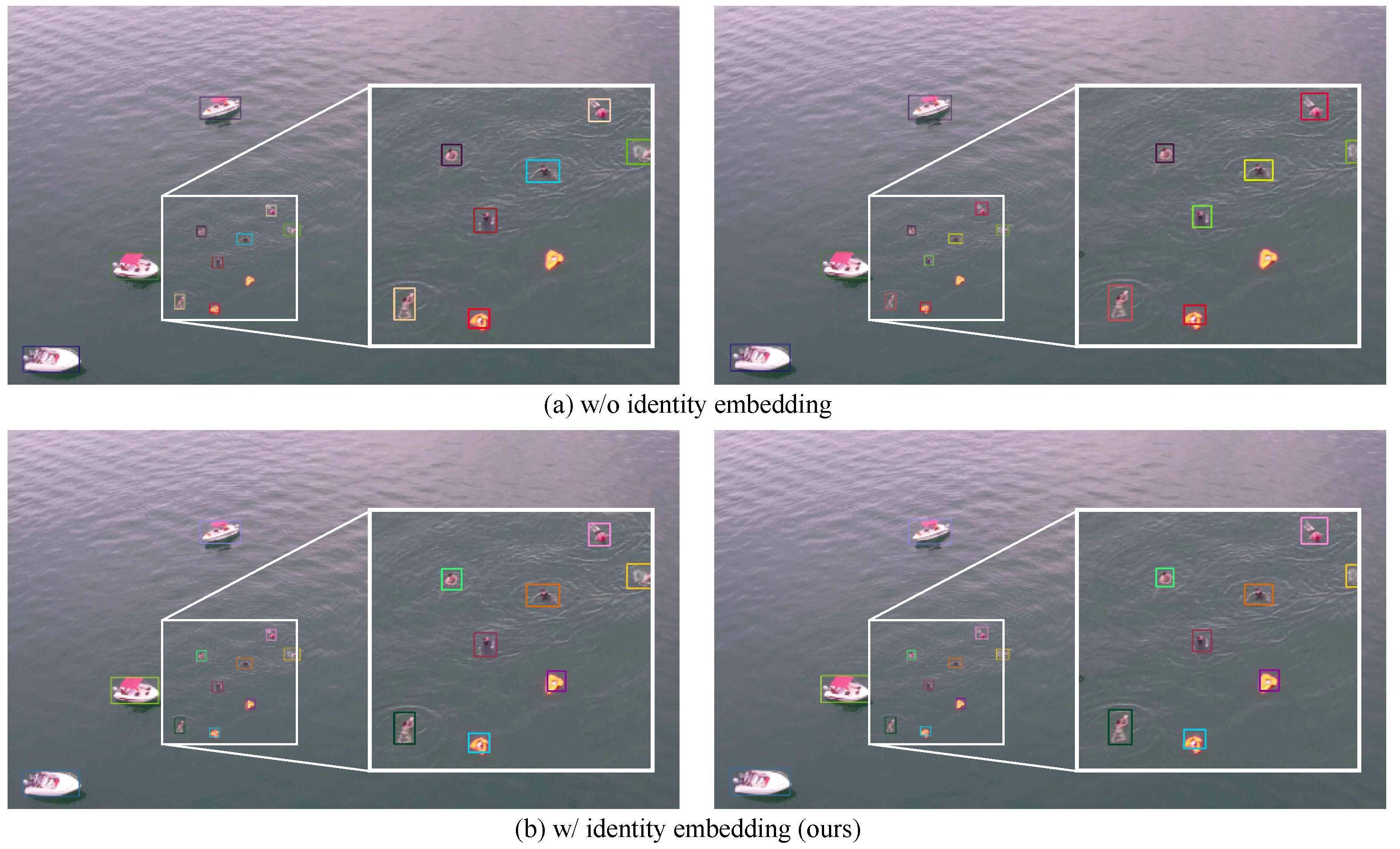
In MCMOT tasks, different categories can have significant differences in appearance and other features, so object identity embedding features are primarily used to distinguish between different instances of the same category. Within the same frame, the same category may correspond to multiple different objects, and identity embedding needs to differentiate these objects. Therefore, the optimization goal of the TG-MCMOT identity embedding module is to make identities within the same frame as distinct as possible. The features obtained from multi-layer encoding and decoding are more for distinguishing semantic features of different categories. Therefore, we retained six layers of object identity embedding features during the decoding process. We selected the object identity embedding features output from the fourth decoder layer. According to the output of Algorithm 1, it obtains the fourth layer object identity embedding feature
corresponding to the query for object
i. The identity embedding loss of TG-MCMOT is calculated as follows:
where
represents cosine similarity, and the cosine similarity between different objects should be as small as possible (i.e., the identity embeddings of the two objects should be as different as possible).
The segmentation module of the TG-MCMOT uses predicted boxes of the queries matched with GT labels, obtained from Algorithm 1, as prompts to generate object masks. The predicted mask for object
i is denoted
, and the GT label mask is
. The segmentation loss of TG-MCMOT is calculated as follows:
where
represents the Mean Squared Error (MSE) loss.
The total loss of the TG-MCMOT is calculated as follows:
where
,
,
, and
are the weights of each subloss, and these hyperparameters work together across the TG-MCMOT model to balance various tasks. The segmentation task is optional, and when no segmentation module is added, there is no need to calculate the last term of Equation (
9).
In the inference stage, the top queries with the highest category position response scores are selected. Then, queries with a category position response score higher than are retained, and the category number (class_id) is predicted based on these scores (, , where is the number of queries that meet the criteria). Class numbers that cannot be obtained from the category decoding guidance were set to 9999, which can be considered “categories not present in this image”. In other words, the result corresponding to this query is a false positive (FP).
TG-MCMOT uses retained queries to perform online association based on their corresponding category numbers, detection boxes (or masks), and object identity embedding features.
The association process sequentially considers the following criteria for associating detected objects with existing trajectories:
The similarity of object identity embedding features.
The intersection over Union (IoU) score of high score detection boxes (or masks).
The IoU score of low score detection boxes (or masks).
During each association process, the model avoids assigning the same track_id to objects that belong to different categories. The high and low score thresholds for the category position response are denoted and , respectively.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}