1. Introduction
Chaos theory is a critical area within the realm of nonlinear science, focusing on the complex, irregular, and unpredictable behavior observed in deterministic systems. The origins of chaos theory can be traced back to the late 19th century. In 1892, Russian mathematician Aleksandr Lyapunov introduced the concept of the Lyapunov exponent as part of his work on analyzing the stability of dynamical systems [
1]. This measure provided a way to quantify the exponential rates at which small perturbations in initial conditions either diverge or converge, offering a crucial tool for determining system stability. However, without the computational tools to numerically solve the complex equations governing such systems, the application of Lyapunov exponents was severely limited before the mid-20th century. In the early 20th century, French mathematician Henri Poincaré, while studying the three-body problem, first identified the non-periodicity of orbits and the sensitivity of systems to initial conditions [
2]. Poincaré’s work laid the foundation for chaos theory, revealing that even simple deterministic systems can exhibit highly complex behavior. In the 1930s, the behavior observed by Balthasar van der Pol in his studies of nonlinear circuit oscillators demonstrated the complex dynamics of systems and further revealed chaotic characteristics [
3].
The significant breakthrough in chaos theory occurred in the 1960s. Meteorologist Edward Lorenz, while working on weather prediction models, accidentally discovered the system later known as the Lorenz attractor [
4]. This discovery demonstrated that even simple weather models could exhibit unpredictable long-term behavior, showing extreme sensitivity to initial conditions—a phenomenon later termed the “butterfly effect”. In 1967, Stephen Smale introduced the horseshoe map theory [
5], providing another classic model of chaotic systems and further deepening the understanding of chaotic behavior. Furthermore, with the development of computational techniques, the ability to characterize the sensitivity to initial conditions of Lyapunov exponent has since made it a fundamental instrument in the study of chaos and complex systems.
In the 1970s, research in chaos theory entered a phase of rapid development. In 1975, James Yorke and his student introduced the concept of “Period Three Implies Chaos” [
6], further enriching the mathematical foundation of chaos theory. In the same year, Mitchell Feigenbaum discovered the universal constants present in the period-doubling bifurcation process [
7], unveiling the patterns through which nonlinear systems transition to chaos. This is a discovery with broad applicability. In 1976, Robert May published research on population models [
8], revealing that complex chaotic behavior could also emerge in simple biological models.
In the 1980s, chaos theory experienced significant development and application. Floris Takens introduced the Embedding Theorem [
9], which provided a method to reconstruct the phase space of a dynamical system using time series data from a single observable variable. Benoit Mandelbrot’s fractal geometry [
10] provided a new perspective for studying chaotic systems, illustrating the nature of chaotic behavior through complex fractal structures. Peter Grassberger and Itamar Procaccia introduced the concept of correlation dimension and developed the Grassberger–Procaccia (G–P) algorithm to compute this dimension from time series data [
11], making it possible to characterize the complexity and quantify the fractal structure of chaotic systems. Simultaneously, the concept of strange attractors gained widespread use, aiding scientists in better understanding the long-term behavior of complex systems. Chaos theory began to be widely applied across various scientific and engineering fields, including biology, economics, physics, circuit design and meteorology.
Atmospheric systems exhibit similar chaotic behavior to the Lorenz system due to the interactions among internal components, external disturbances from solar and terrestrial radiation, and the complex influences of various variables across different temporal and spatial scales. These systems, driven by complete physical mechanisms, present pseudo-random phenomena due to their intricate structure and dynamics.
The study of the chaotic properties of the atmosphere, as a core component of the Earth’s climate system, is of great significance for better understanding global climate change and predicting meteorological disasters. In recent years, the rapid advancement of satellite remote-sensing technology has enabled us to obtain abundant and precise meteorological data from the atmosphere, greatly enhancing our understanding and predictive capabilities regarding atmospheric dynamics and climate change. Radiometric imagers, by detecting radiation at different wavelengths, provide detailed information on temperature, water vapor, and cloud distribution [
12]. These data play a vital role in weather forecasting, climate monitoring, and environmental protection and offer valuable resources for atmospheric science research.
Satellite remote-sensing data are categorized into different levels based on the degree of processing of the raw data. In engineering practice, Level 1 (L1) satellite data is a commonly used foundational data type. It refers to raw observation data that have undergone preliminary processing, including radiometric calibration, geometric correction, and georeferencing. L1 data are significant in studying chaotic properties of the atmosphere, as they reflect the true state and complexity of the atmospheric system. The high temporal resolution and accuracy of L1 data enable the capture of minor disturbances and changes in the atmospheric system, providing rich data sources for chaotic analysis.
Besides L1 satellite data, reanalysis data is another critical tool for atmospheric research. Reanalysis data combines satellite remote-sensing data, ground-based observations, and numerical weather prediction models to generate high spatial resolution, long-term continuous global meteorological datasets using advanced data assimilation techniques. Reanalysis data fill observation gaps and provide homogenized meteorological data, offering indispensable support for studying long-term trends in chaotic properties of the atmosphere [
13]. By integrating multi-source observational data, reanalysis data eliminate uncertainties and errors from single observation methods.
In this study, we investigate the chaotic properties of the atmosphere using L1 data from FY-4A and Himawari-8 and the ERA5 reanalysis dataset from the European Centre for Medium-Range Weather Forecasts (ECMWF). For L1 satellite data, a 2–3 months time frame is selected because this period allows for the capture of short-term chaotic behaviors such as synoptic-scale weather patterns, including the development and evolution of cyclones, anticyclones, and frontal systems. Satellite data are well-suited for short-term analysis due to their high temporal and spatial resolution, which is critical for resolving these transient atmospheric phenomena. For ERA5, a 5–10 years period is appropriate because reanalysis data is designed to provide a consistent and continuous record of the atmosphere over extended periods. It allows for the identification of chaotic behavior at larger scales, such as those related to persistent anomalies, large-scale teleconnection patterns, and climate oscillations.
Section 2 systematically reviews the definition and main characteristics of chaos, discussing phase space reconstruction methods centered on Takens’ theorem.
Section 3 categorizes and summarizes qualitative and quantitative methods for determining the chaotic nature of time series data. To compensate for the shortcomings of the traditional G–P algorithm, a new method named Improved Saturated Correlation Dimension method was proposed to address the subjectivity and noise sensitivity when determining the scaling region.
Section 4 employs quantitative determination methods, specifically the largest Lyapunov exponent and saturated correlation dimension, to analyze the chaotic nature of FY-4A and Himawari-8 remote-sensing data and ERA5 reanalysis data. In this section, we focus on the short-term chaotic nature of the atmosphere using infrared band data from L1 satellite data, while T850 and Z500 reanalysis data from ERA5, supplementing L1 data, further validate the long-term chaotic nature of the atmosphere. These analyses demonstrate that the atmospheric system exhibits chaotic behavior across different time scales. Finally,
Section 5 provides prospects for future applications, including short-term prediction of atmospheric infrared radiation fields and the detection of weak time-sensitive signals in complex atmospheric environments, based on the chaotic properties of the atmosphere.
3. Methods for Determining Chaotic Nature
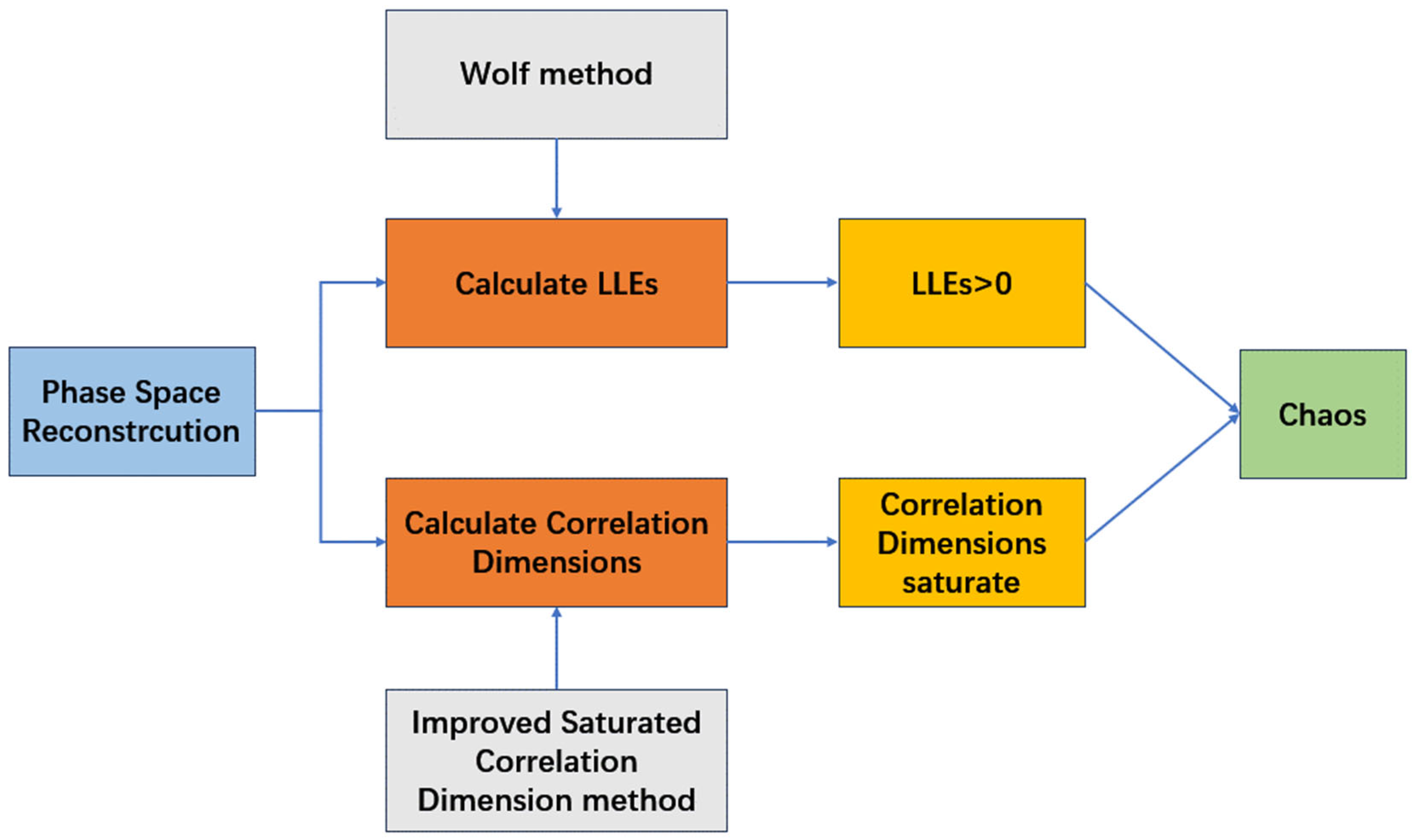
To determine whether a nonlinear system is chaotic, qualitative or quantitative methods can be used to analyze the intrinsic properties of its time series, such as phase diagrams, Lyapunov exponents, and correlation dimensions. Qualitative methods include the Phase Diagram method, the Power Spectrum method, and the Poincare Surface of Section method, while quantitative methods include the Lyapunov Exponent (LE) method, the Kolmogorov Entropy method, and the Saturated Correlation Dimension method [
20]. This section will mainly discuss two of the quantitative methods which will be used in
Section 4. One is the Lyapunov Exponent method. The other is the Improved Saturated Correlation Dimension method proposed in this article, which is based on curvature and the least squares method. This new method has addressed the subjectivity and noise sensitivity inherent in the traditional G–P method when determining the scaling region of the
−
plot.
3.1. The Lyapunov Exponent Method
In chaos theory, Lyapunov exponents (LE) are key tools for quantifying the sensitivity of a system to initial conditions [
21]. Lyapunov exponents represent the rate at which nearby trajectories in the phase space diverge or converge. The formula for calculating LE is as follows:
where
is the time (number of iterations).
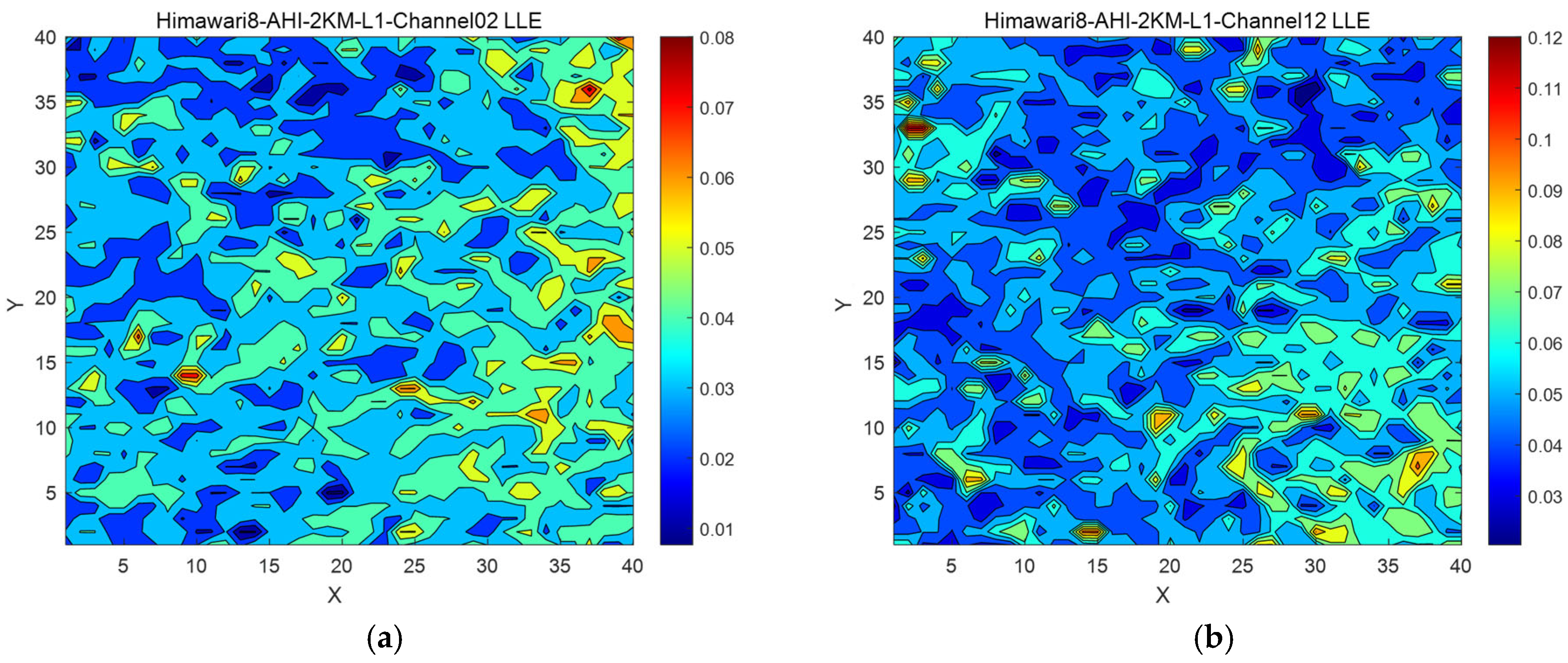
The number of Lyapunov exponents is generally equal to the dimension of the reconstructed phase space, so calculating Lyapunov exponents is based on phase space reconstruction. When the largest Lyapunov exponent (LLE) is positive, it indicates that nearby trajectories in the phase space will exponentially diverge over time, and the system exhibits chaotic behavior. When all LEs are negative, it indicates that nearby trajectories converge over time, and the system exhibits a large-scale periodic state. When LE is zero, it indicates that the distance between nearby trajectories remains unchanged over time, which is a critical state between chaos and periodicity [
22]. Therefore, the sign of the largest Lyapunov exponent (LLE) can be used to determine the state of the system.
Methods for calculating LLE include the direct method, the Jacobian method, the Wolf method, and the Small Data method [
23]. This section will mainly discuss the Wolf method.
Assume the chaotic time series is
x1,
x2, …,
xn, with embedding dimension
m and time delay
τ. After reconstructing the phase space, a point on the attractor
is taken as a point on the reference trajectory. The initial point on the reference trajectory
and its nearest neighbor point outside the reference trajectory
are taken as initial points, with an initial distance
. As the two points evolve over time to
, the distance
exceeds a certain threshold
. At this point, a new nearest neighbor point
is selected outside the reference trajectory, and the angle between the vectors of the new data point and the old data point with the corresponding point on the reference trajectory should be as small as possible [
24]. This process is repeated until the reference trajectory traverses all the data in the time series, with a total number of iterations M. The LLE is then calculated as follows:
3.2. The Improved Saturated Correlation Dimension Method
In 1983, Grassberger and Procaccia proposed the G–P algorithm for directly calculating the correlation dimension from time series using embedding theory and phase space reconstruction techniques [
25].
The correlation dimension is a measure of the degree of interdependence among variables in a complex system or dataset. It can be used to describe the complexity of attractors in the system’s phase space and to identify chaos. The correlation dimension is also a type of fractal dimension, characterized by conservativeness, simplicity of calculation, and stability [
26]. The process for calculating the saturated correlation dimension is as follows:
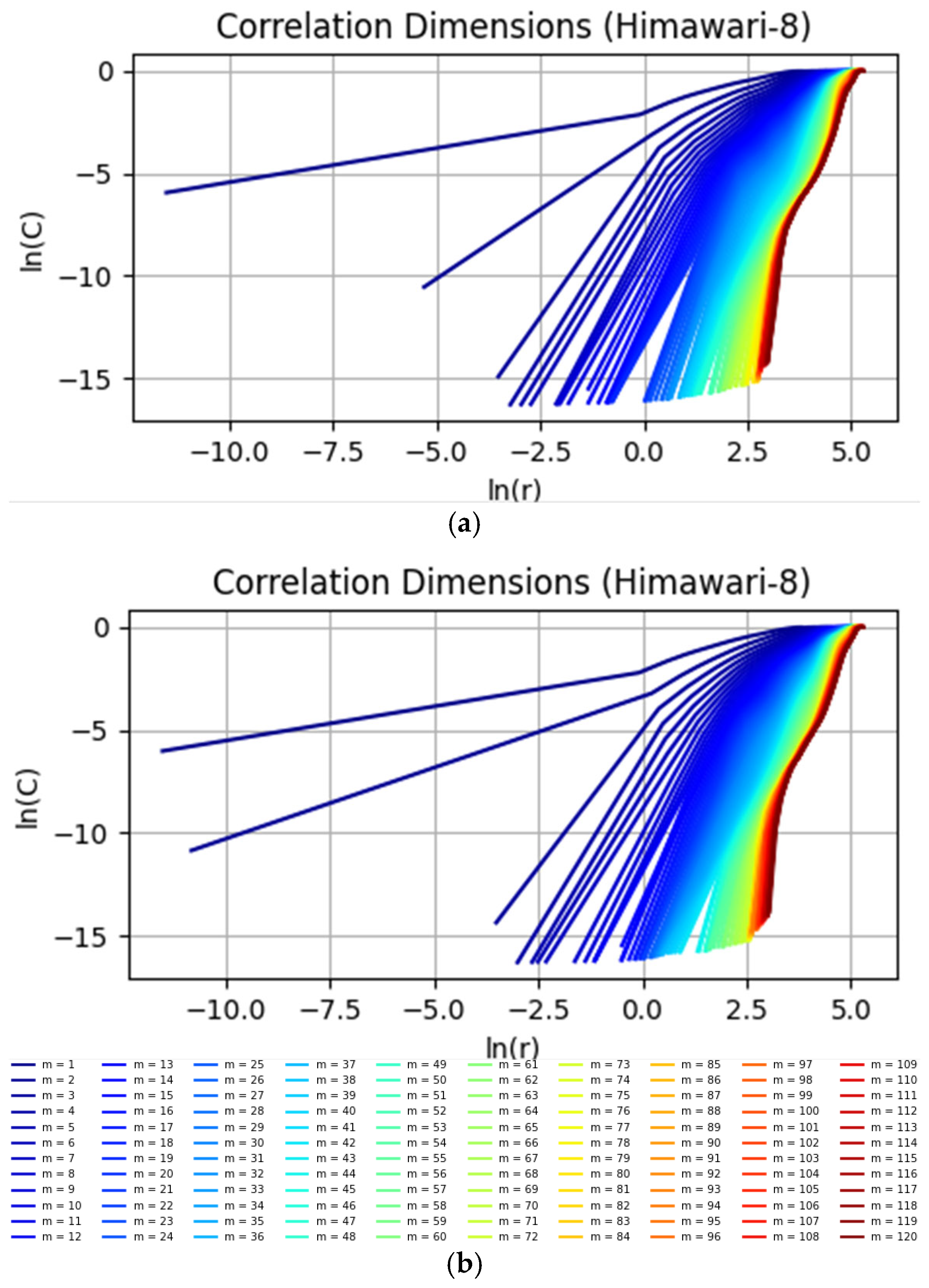
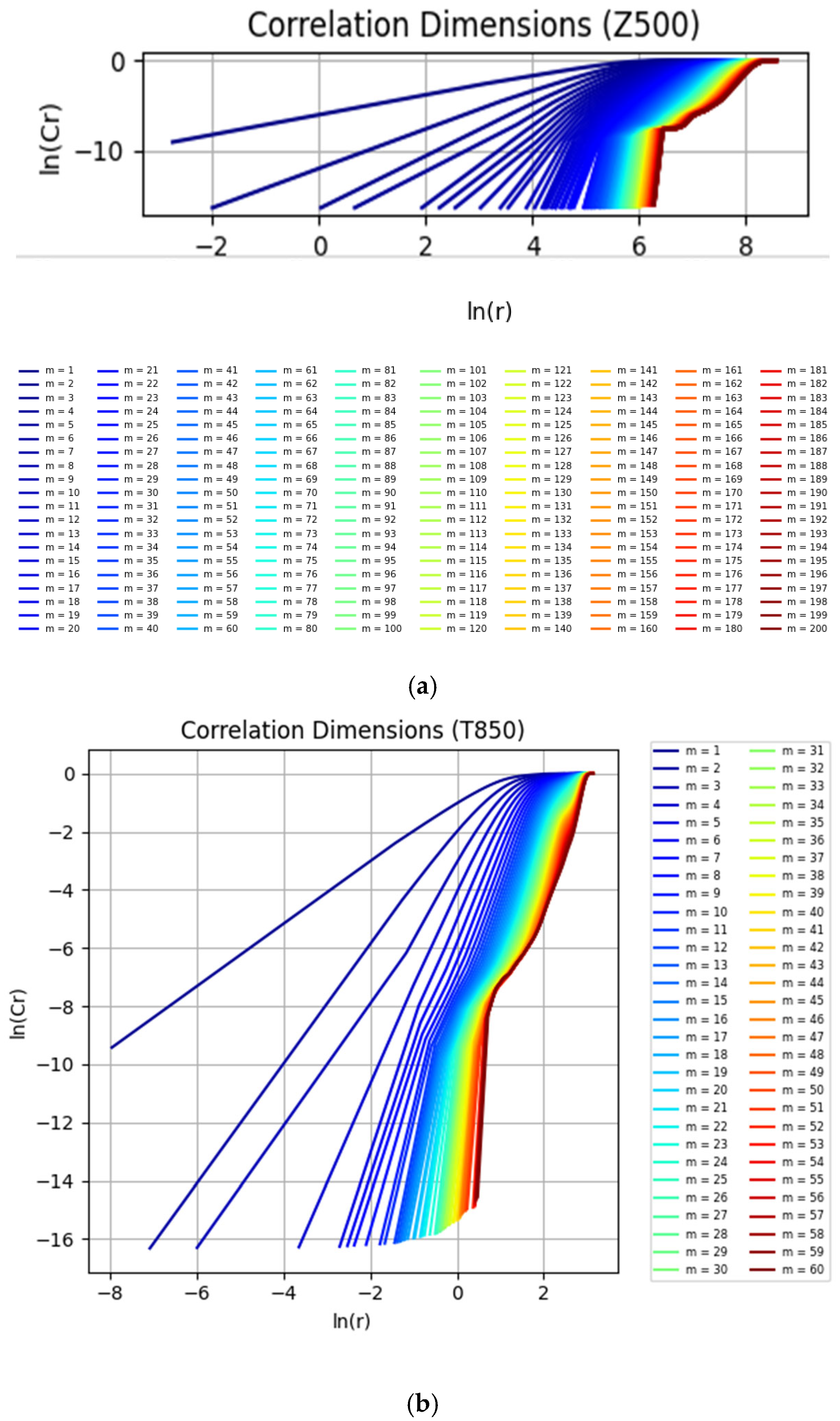
First, perform phase space reconstruction for the time series.
Second, calculate the correlation integral. The correlation integral
is a statistical measure of the distances between pairs of points in the phase space. For each pair of points
and
(where
), calculate the distance between them:
The correlation integral
is defined as the proportion of point pairs within a given distance
:
where
is the Heaviside function, and
is the number of reconstructed phase space vectors.
Third, estimate the correlation dimension. The correlation dimension
is estimated as the slope of the log–log plot of the correlation integral
versus the distance
in the scaling region [
11]
The scaling region refers to a range of distances over which the correlation integral exhibits a power-law relationship with . In this region, the log–log plot appears as a straight line, indicating a linear relationship between these logarithmic values.
One of the traditional methods to identify the scaling region is to visually inspect the log–log plot to identify a linear segment [
27]. However, this method involves a degree of subjectivity, which can lead to variability in the results depending on the researcher’s judgment.
Another method is to estimate the slope in the region where
approaches 0 [
28].
The approach is grounded in the idea that, at sufficiently small scales, the system’s geometry should dominate, allowing for a more accurate determination of the fractal dimension. This method reduces the reliance on visual inspection for identifying the scaling region, making the estimation of the correlation dimension more objective. However, the method can be sensitive to noise, especially in the small region, where the behavior of may be distorted by data imperfections.
In order to address the subjectivity and noise sensitivity inherent in the aforementioned methods, this paper proposes a curvature-based approach for determining the scaling region, which can be effectively carried out through a systematic analysis of the first and second derivatives of the log–log plot.
The first derivative of
with respect to
gives the local slope
, which can be interpreted as the correlation dimension
in the linear region:
This derivative can be numerically approximated using the finite difference method:
The second derivative, representing the curvature of the log–log plot, is instrumental in identifying deviations from linearity:
Numerically, this can be approximated as:
The scaling region is identified by examining the stability of and minimal curvature. The range of values where the first derivative remains relatively constant, indicating a stable slope, suggests a linear region in the log–log plot. The region where the second derivative (curvature) is close to zero further supports the presence of a linear relationship. The overlap between these regions indicates the appropriate scaling region.
By analyzing the stability of the slope (first derivative) and minimizing the curvature (second derivative), this method ensures a reliable determination of the scaling region, facilitating a more accurate estimation of the correlation dimension.
After determining the scaling region, the slope of over is calculated using the least squares method to obtain the correlation dimension .
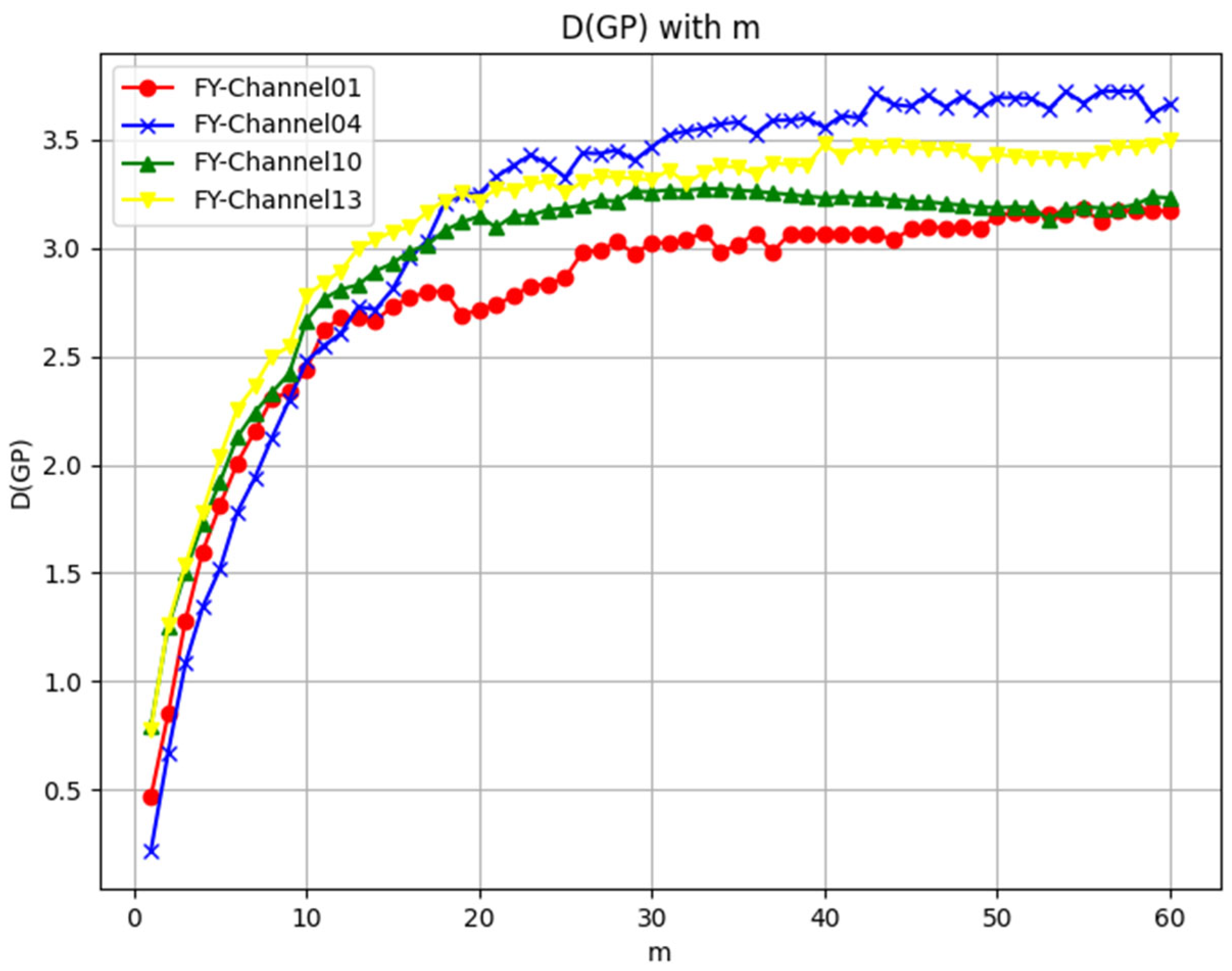
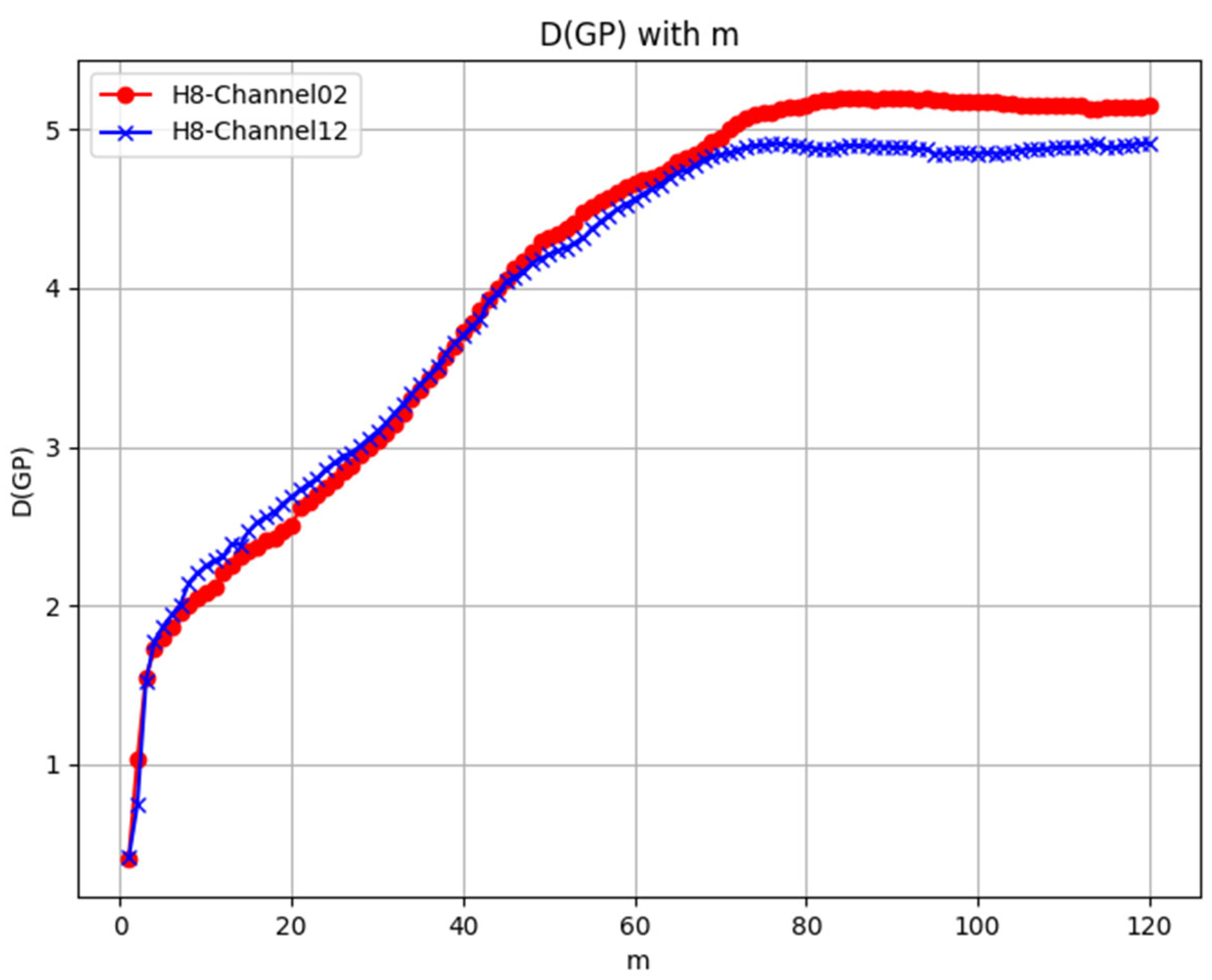
Fourth, verify saturation. Calculate the correlation dimensions for different embedding dimensions m and plot the variation curve with m as the horizontal axis and D2 as the vertical axis.
The correlation dimension is essentially a type of fractal dimension used to describe the complexity of an attractor. A fractal dimension greater than 1 indicates that the attractor possesses a complex geometric structure, which is characteristic of chaotic systems. For periodic or non-chaotic systems, their attractors are typically low-dimensional, such as fixed points, periodic orbits, or slightly more complex quasi-periodic structures. The correlation dimension of these systems is usually close to or equal to 1, as they do not exhibit fractal structures [
29,
30]. Therefore, if the correlation dimension saturates at dimension greater than 1, the time series has chaotic characteristics. The higher the saturated correlation dimension, the stronger the chaos.
5. Conclusions
In this paper, an overview of the definition and characteristics of chaos was provided. Phase space reconstruction, as a crucial preprocessing method for chaotic data, was introduced. And two quantitative methods for determining chaotic nature were thoroughly discussed. The first was the Lyapunov Exponent method, and the second was the Improved Saturated Correlation Dimension method, which was newly proposed in this work. This new method, based on curvature and the least squares approach, effectively addressed the subjectivity and noise sensitivity issues in determining the scaling region of the − curves associated with the traditional G–P method. On this basis, this paper innovatively applies the above two methods to satellite remote-sensing L1 datasets including FY-4A and Himawari-8, as well as ERA5 reanalysis dataset. Two indicators were analyzed: whether the system’s Largest Lyapunov Exponent is positive and whether the correlation dimension tends to saturate with the embedding dimension. The results showed that, on the one hand, the overwhelming majority of sequences of satellite remote-sensing L1 dataset (99.91% for FY-4A and 99.97% for Himawari-8) and all the sequences of ERA5 have positive LLEs. Considering the surface influences from the Earth’s surface, and boundary layer interactions, which may result in the negative LLEs of less than 0.01%, the results obtained from the more comprehensive ERA5 dataset can be considered reliable. On the other hand, all the sequences of both satellite remote-sensing L1 dataset and ERA5 dataset have correlation dimensions saturating at values greater than 1. Taking into account the above two indicators comprehensively, the following conclusion can be drawn: on both short-term and long-term scales, the atmospheric medium exhibits chaotic nature.
In summary, this paper demonstrated the chaotic behavior of the atmospheric system on different scales, which helps to reveal the multi-scale interactions and coupling mechanisms of the atmospheric system. This provides an experimental basis for a deeper understanding of the highly complex internal structure and dynamic evolution mechanisms of the atmospheric system. On this basis, the characteristics of chaotic systems can be utilized in the future to study the evolution of variables in the atmospheric system using numerical integration and data-driven methods, further improving the accuracy of weather forecasts. Additionally, early warning and prediction of natural disasters such as volcanic eruptions and typhoons can be conducted based on minute abnormal disturbances in the atmospheric medium. On the other hand, the sensitivity to initial conditions in chaos can be used to capture weak moving targets under the atmospheric infrared background radiation field, which is of great significance for improving the detection rate of hostile targets in military confrontations.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}