
Self-Attention Progressive Network for Infrared and Visible Image Fusion


Abstract
1. Introduction
- We develop a progressive image fusion framework that explores the information contained within two modalities. This framework can autonomously learn advanced image features based on lighting intensity, and adaptively fuse complementary and common information, thereby effectively fusing meaningful information in the source image in an all-weather environment.
- A multi-state joint feature extraction module is proposed to enable context mining between keywords and self-attentive learning of feature maps in an intra-clustered manner. The module integrates these elements into a unified architecture that merges static and dynamic contextual representations into a consistent output.
- We introduce a differential module with learnable parameters for the activation function. It can dynamically adapt to the distribution of input data, effectively extracting and integrating key information from the source images while supplementing differential information.
- The rest of this paper is organized as follows: Section 2 reviews the related works based on techniques for infrared and visible images. Section 3 describes the proposed method in detail, including multi-state joint feature extraction, Difference-Aware Propagation Module and loss function. The experiments are thoroughly analyzed and discussed in Section 4. Finally, Section 5 provides a comprehensive summary of this work.
2. Related Work
2.1. Traditional Methods
2.2. Deep Learning-Based Methods
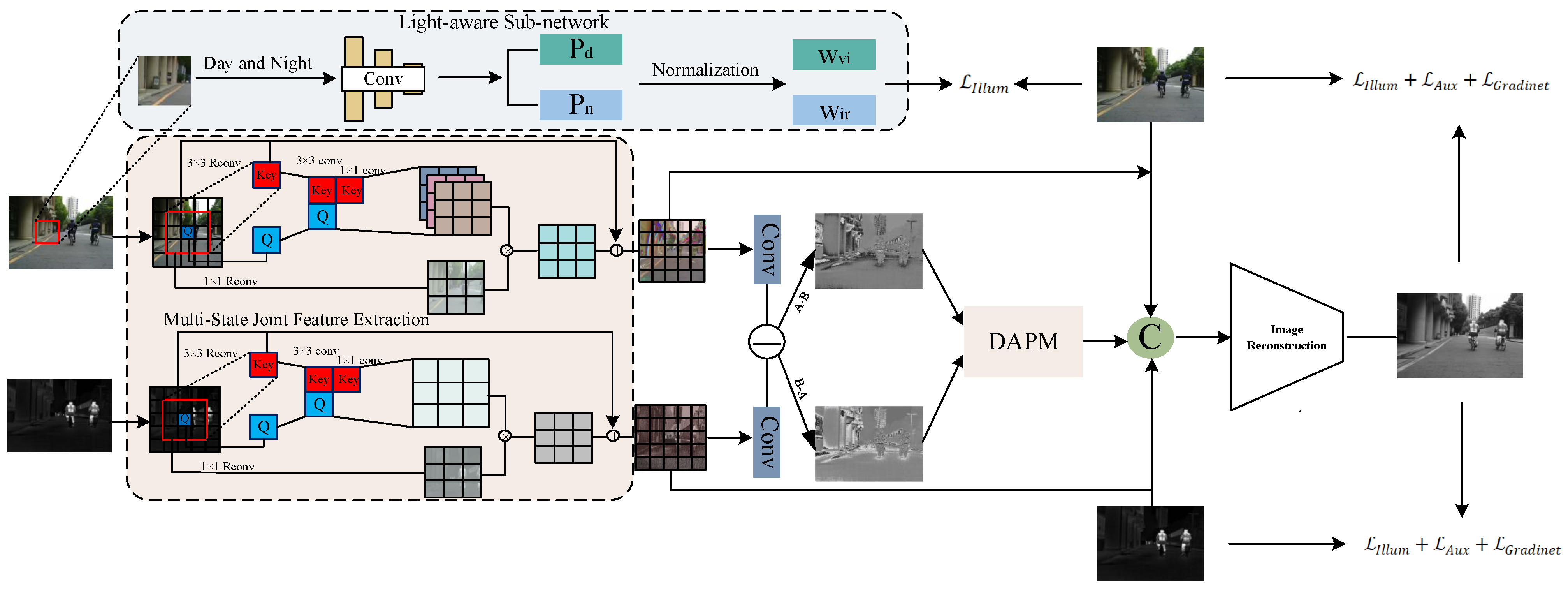
3. Method
3.1. Overview
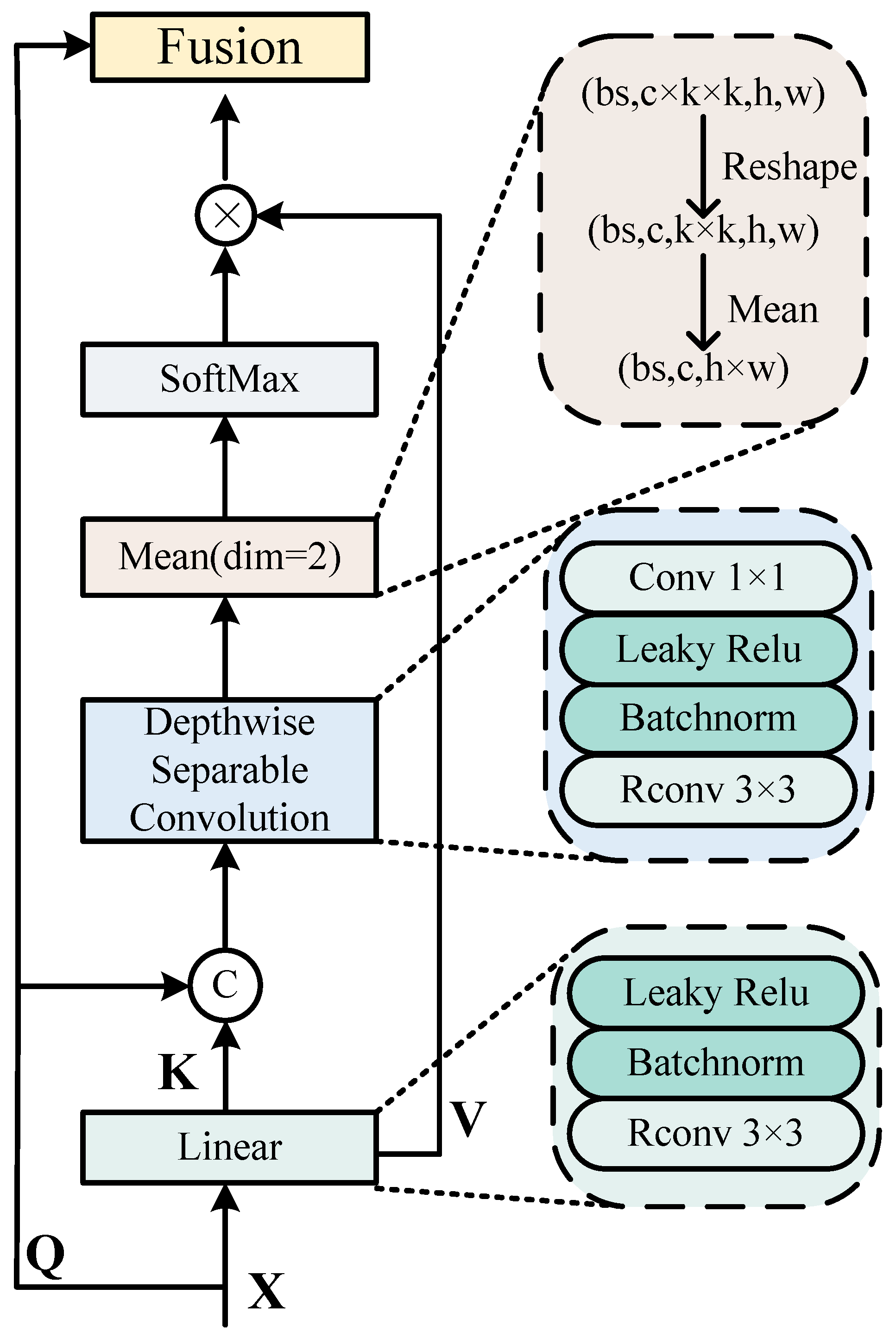
3.2. Multi-State Joint Feature Extraction
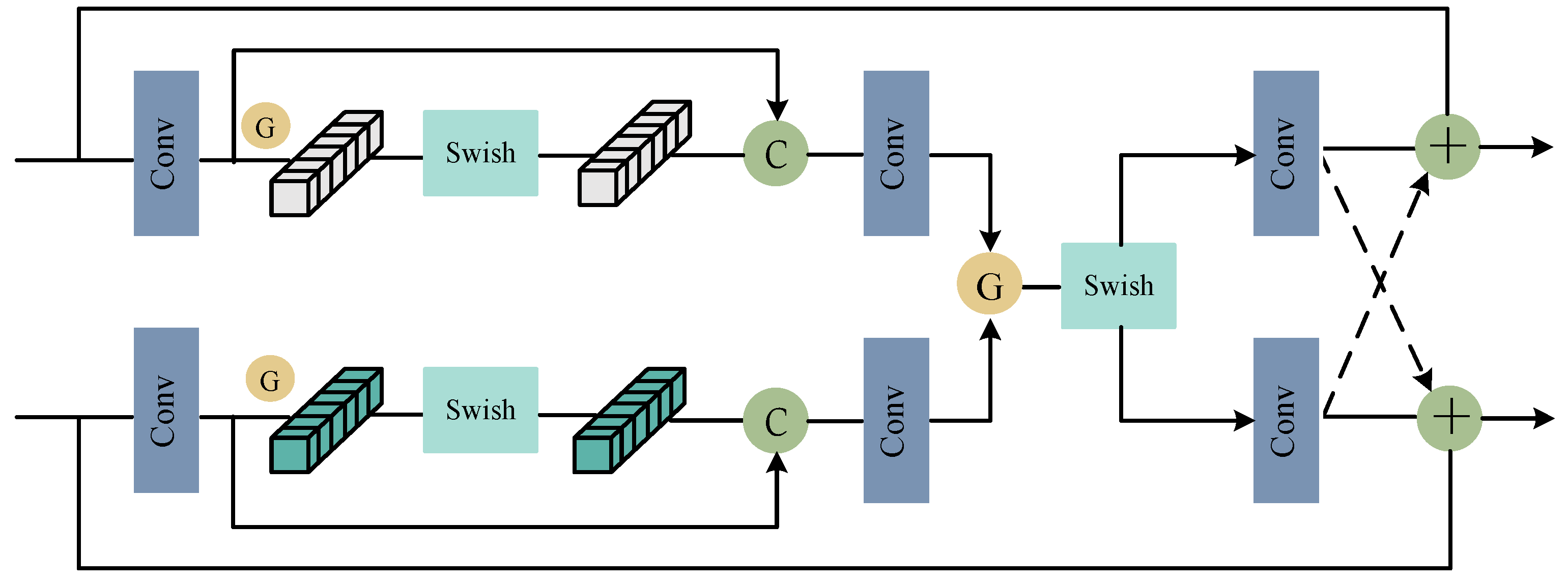
3.3. Difference-Aware Propagation Module
3.4. Light-Aware Sub-Network
3.5. Loss Function
3.5.1. Loss Function of Light-Aware Sub-Network
3.5.2. Loss Function of Self-Attention Progressive Network
4. Experiment
4.1. Datasets
4.1.1. Msrs Dataset [37]
4.1.2. TNO Dataset [41]
4.1.3. RoadScene Dataset [42]
4.2. Evaluation Metrics and Comparison Methods
4.3. Implementation Details
4.4. Performance Comparison with Existing Approaches
4.4.1. Quantitative Evaluation
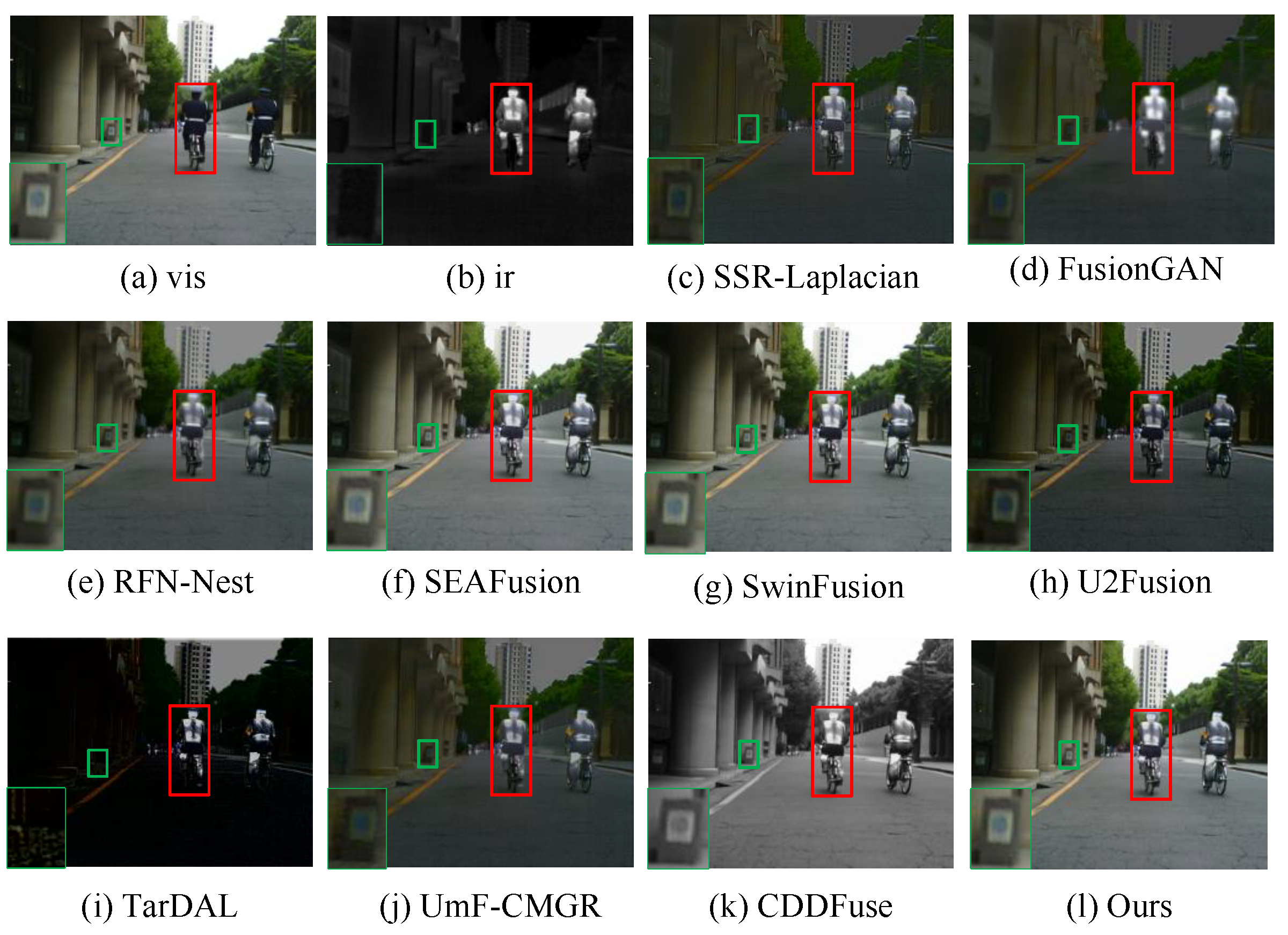
4.4.2. Qualitative Evaluation
4.5. Efficiency Comparison
4.6. Ablation Study
4.6.1. Study of Multi-State Joint Feature Extraction
4.6.2. Study of Difference-Aware Propagation Module
4.6.3. Study of Bidirectional Difference-Aware Propagation Module
4.6.4. Study of Illumination Guidance Loss
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Guo, Y.; Wu, X.; Qing, C.; Liu, L.; Yang, Q.; Hu, X.; Qian, X.; Shao, S. Blind Restoration of a Single Real Turbulence-Degraded Image Based on Self-Supervised Learning. Remote Sens. 2023, 15, 4076. [Google Scholar] [CrossRef]
- Wang, R.; Wang, Z.; Chen, Y.; Kang, H.; Luo, F.; Liu, Y. Target Recognition in SAR Images Using Complex-Valued Network Guided with Sub-Aperture Decomposition. Remote Sens. 2023, 15, 4031. [Google Scholar] [CrossRef]
- Tang, H.; Liu, G.; Qian, Y.; Wang, J.; Xiong, J. EgeFusion: Towards Edge Gradient Enhancement in Infrared and Visible Image Fusion with Multi-Scale Transform. IEEE Trans. Comput. Imaging 2024, 10, 385–398. [Google Scholar] [CrossRef]
- Li, Q.; Yuan, Y.; Wang, Q. Multi-Scale Factor Joint Learning for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5523110. [Google Scholar]
- Ji, C.; Zhou, W.; Lei, J.; Ye, L. Infrared and Visible Image Fusion via Multiscale Receptive Field Amplification Fusion Network. IEEE Signal Process. Lett. 2023, 30, 493–497. [Google Scholar] [CrossRef]
- Deng, C.; Chen, Y.; Zhang, S.; Li, F.; Lai, P.; Su, D.; Hu, M.; Wang, S. Robust dual spatial weighted sparse unmixing for remotely sensed hyperspectral imagery. Remote Sens. 2023, 15, 4056. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Tu, W.; Wang, J.; Liu, Y.; Li, X.; Tang, C.; Feng, R. Contrastive Multiview Subspace Clustering of Hyperspectral Images Based on Graph Convolutional Networks. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5510514. [Google Scholar] [CrossRef]
- Wang, X.; Guan, Z.; Qian, W.; Cao, J.; Wang, C.; Yang, C. Contrast Saliency Information Guided Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2023, 9, 769–780. [Google Scholar] [CrossRef]
- Wang, Z.; Cao, B.; Liu, J. Hyperspectral image classification via spatial shuffle-based convolutional neural network. Remote Sens. 2023, 15, 3960. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Yan, H.; Su, S.; Wu, M.; Xu, M.; Zuo, Y.; Zhang, C.; Huang, B. SeaMAE: Masked Pre-Training with Meteorological Satellite Imagery for Sea Fog Detection. Remote Sens. 2023, 15, 4102. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Fan, L.; Yuan, J.; Niu, X.; Zha, K.; Ma, W. RockSeg: A Novel Semantic Segmentation Network Based on a Hybrid Framework Combining a Convolutional Neural Network and Transformer for Deep Space Rock Images. Remote Sens. 2023, 15, 3935. [Google Scholar] [CrossRef]
- Li, Q.; Gong, M.; Yuan, Y.; Wang, Q. Symmetrical feature propagation network for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Palsson, B.; Ulfarsson, M.O.; Sveinsson, J.R. Synthesis of Synthetic Hyperspectral Images with Controllable Spectral Variability Using a Generative Adversarial Network. Remote Sens. 2023, 15, 3919. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Xiao, B.; Xu, B.; Bi, X.; Li, W. Global-Feature Encoding U-Net (GEU-Net) for Multi-Focus Image Fusion. IEEE Trans. Image Process. 2021, 30, 163–175. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Liu, S.; Yan, A.; Huang, S. Seismic Data Denoising Based on DC-PCNN Image Fusion in NSCT Domain. IEEE Geosci. Remote Sens. Lett. 2024, 21, 7502205. [Google Scholar] [CrossRef]
- Wu, R.; Yu, D.; Liu, J.; Wu, H.; Chen, W.; Gu, Q. An improved fusion method for infrared and low-light level visible image. In Proceedings of the ICCWAMTIP, Chengdu, China, 15–17 December 2017; IEEE: New York, NY, USA, 2017; pp. 147–151. [Google Scholar]
- Zhang, Q.; Maldague, X. An adaptive fusion approach for infrared and visible images based on NSCT and compressed sensing. Infrared Phys. Technol. 2016, 74, 11–20. [Google Scholar] [CrossRef]
- Wu, M.; Ma, Y.; Fan, F.; Mei, X.; Huang, J. Infrared and visible image fusion via joint convolutional sparse representation. JOSA A 2020, 37, 1105–1115. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Zhao, W.; Rong, S.; Li, T.; Feng, J.; He, B. Enhancing underwater imagery via latent low-rank decomposition and image fusion. IEEE J. Ocean. Eng. 2022, 48, 147–159. [Google Scholar] [CrossRef]
- Sun, Y.; Lei, L.; Liu, L.; Kuang, G. Structural Regression Fusion for Unsupervised Multimodal Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4504018. [Google Scholar] [CrossRef]
- Shen, S.; Wang, X.; Wu, M.; Gu, K.; Chen, X.; Geng, X. ICA-CNN: Gesture Recognition Using CNN with Improved Channel Attention Mechanism and Multimodal Signals. IEEE Sens. J. 2023, 23, 4052–4059. [Google Scholar] [CrossRef]
- Xia, Z.; Chen, Y.; Xu, C. Multiview PCA: A Methodology of Feature Extraction and Dimension Reduction for High-Order Data. IEEE Trans. Cybern. 2022, 52, 11068–11080. [Google Scholar] [CrossRef]
- Li, X.; Zhang, X.; Yuan, Y.; Dong, Y. Adaptive Relationship Preserving Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5504516. [Google Scholar] [CrossRef]
- Lv, J.; Kang, Z.; Wang, B.; Ji, L.; Xu, Z. Multi-view subspace clustering via partition fusion. Inf. Sci. 2021, 560, 410–423. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.G.; You, C. Stochastic sparse subspace clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 4155–4164. [Google Scholar]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar]
- Li, Q.; Gong, M.; Yuan, Y.; Wang, Q. RGB-induced feature modulation network for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Karim, S.; Tong, G.; Li, J.; Yu, X.; Hao, J.; Qadir, A.; Yu, Y. MTDFusion: A Multilayer Triple Dense Network for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2023, 73, 5010117. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Feng, Q. AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks. IEEE Trans. Multimedia 2020, 23, 1383–1396. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Sakkos, D.; Ho, E.S.; Shum, H.P. Illumination-aware multi-task GANs for foreground segmentation. IEEE Access 2019, 7, 10976–10986. [Google Scholar] [CrossRef]
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Wang, D.; Liu, J.; Fan, X.; Liu, R. Unsupervised misaligned infrared and visible image fusion via cross-modality image generation and registration. arXiv 2022, arXiv:2205.11876. [Google Scholar]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. CddFuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision, Vancouver, BC, Canada, 24 June 2023; pp. 5906–5916. [Google Scholar]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | En | MI | AG | VIF | SSIM | |
|---|---|---|---|---|---|---|
| SSR-Laplacian | 3.437 | 1.203 | 2.131 | 0.138 | 0.217 | 0.134 |
| FusionGAN | 5.459 | 2.104 | 1.345 | 0.358 | 0.415 | 0.127 |
| RFN-Nest | 6.113 | 2.709 | 1.683 | 0.557 | 0.621 | 0.266 |
| SEAFusion | 6.755 | 4.056 | 3.425 | 0.953 | 0.933 | 0.647 |
| SwinFusion | 6.714 | 4.267 | 3.201 | 0.959 | 0.945 | 0.595 |
| U2Fusion | 5.637 | 2.467 | 2.635 | 0.535 | 0.729 | 0.376 |
| TarDAL | 3.573 | 1.391 | 3.061 | 0.177 | 0.122 | 0.135 |
| UMF-CMGR | 5.748 | 2.214 | 2.251 | 0.441 | 0.531 | 0.289 |
| CDDFuse | 6.761 | 5.165 | 3.436 | 1.037 | 0.963 | 0.648 |
| Ours | 6.822 | 4.382 | 3.742 | 0.993 | 1.034 | 0.678 |
| Model | En | MI | AG | VIF | SSIM | |
|---|---|---|---|---|---|---|
| SSR-Laplacian | 6.779 | 1.683 | 6.423 | 0.356 | 0.525 | 0.193 |
| FusionGAN | 7.279 | 2.645 | 3.559 | 0.338 | 0.617 | 0.286 |
| RFN-Nest | 7.223 | 2.276 | 3.361 | 0.419 | 0.735 | 0.329 |
| SEAFusion | 7.304 | 2.954 | 7.027 | 0.591 | 0.837 | 0.469 |
| SwinFusion | 6.942 | 3.572 | 4.249 | 0.683 | 0.811 | 0.486 |
| U2Fusion | 6.991 | 2.129 | 5.553 | 0.442 | 0.808 | 0.455 |
| TarDAL | 7.324 | 1.844 | 13.481 | 0.343 | 0.525 | 0.263 |
| UMF-CMGR | 6.829 | 2.366 | 3.767 | 0.476 | 0.889 | 0.429 |
| CDDFuse | 7.609 | 3.101 | 6.826 | 0.639 | 0.861 | 0.462 |
| Ours | 7.349 | 3.577 | 5.488 | 0.693 | 0.891 | 0.573 |
| Model | En | MI | AG | VIF | SSIM | |
|---|---|---|---|---|---|---|
| SSR-Laplacian | 5.934 | 1.071 | 5.213 | 0.474 | 0.503 | 0.174 |
| FusionGAN | 6.234 | 2.011 | 1.953 | 0.289 | 0.527 | 0.165 |
| RFN-Nest | 6.931 | 1.781 | 2.443 | 0.514 | 0.773 | 0.327 |
| SEAFusion | 6.927 | 2.521 | 5.332 | 0.662 | 0.923 | 0.446 |
| SwinFusion | 6.836 | 3.078 | 3.908 | 0.658 | 1.052 | 0.521 |
| U2Fusion | 6.924 | 1.825 | 4.923 | 0.551 | 0.939 | 0.412 |
| TarDAL | 6.477 | 1.049 | 19.231 | 0.351 | 0.421 | 0.195 |
| UMF-CMGR | 6.422 | 1.791 | 2.827 | 0.524 | 1.033 | 0.392 |
| CDDFuse | 7.265 | 2.546 | 5.151 | 0.703 | 0.967 | 0.473 |
| Ours | 6.976 | 3.084 | 5.513 | 0.708 | 0.984 | 0.582 |
| Time | MSRS | RoadScene | TNO |
|---|---|---|---|
| SSR-Laplacian | 1.303 ± 0.131 | 1.213 ± 0.108 | 1.813 ± 0.114 |
| FusionGAN | 1.021 ± 0.108 | 0.7821 ± 0.256 | 0.874 ± 0.336 |
| RFN-Nest | 1.421 ± 0.436 | 0.885 ± 0.271 | 1.542 ± 0.724 |
| SEAFusion | 0.546 ± 0.239 | 0.673 ± 0.359 | 0.434 ± 0.264 |
| SwinFusion | 2.452 ± 0.136 | 1.734 ± 0.352 | 2.218 ± 0.214 |
| U2Fusion | 1.134 ± 0.376 | 0.745 ± 0.254 | 1.335 ± 0.579 |
| TarDAL | 0.489 ± 0.112 | 0.588 ± 0.234 | 0.579 ± 0.321 |
| UmF-CMGR | 0.379 ± 0.273 | 0.534 ± 0.369 | 0.528 ± 0.224 |
| CDDFuse | 1.512 ± 0.298 | 0.875 ± 0.157 | 1.871 ± 0.312 |
| Ours | 0.653 ± 0.121 | 0.603 ± 0.098 | 0.611 ± 0.116 |
| MSRS Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Components | 640 × 480 Pixels | ||||||||
| Baseline | MSJFE | DAPM | IGL | EN | MI | AG | VIF | SSIM | |
| ✓ | ✓ | ✓ | 6.585 | 3.443 | 3.173 | 0.611 | 0.648 | 0.447 | |
| ✓ | ✓ | ✓ | 6.786 | 4.328 | 3.827 | 0.969 | 0.754 | 0.665 | |
| ✓ | ✓ | ✓ | 6.802 | 4.312 | 3.476 | 0.966 | 1.007 | 0.658 | |
| ✓ | ✓ | ✓ | ✓ | 6.822 | 4.382 | 3.742 | 0.993 | 1.034 | 0.678 |
| Dataset | Method | EN | MI | AG | VIF | SSIM | |
|---|---|---|---|---|---|---|---|
| MSRS | Baseline+Basic module+DAPM | 6.822 | 4.382 | 3.742 | 0.993 | 1.034 | 0.678 |
| Baseline+Basic module+BDA | 6.821 | 4.219 | 3.854 | 0.966 | 0.749 | 0.664 | |
| TNO | Baseline+Basic module+DAPM | 6.976 | 3.084 | 4.513 | 0.708 | 0.984 | 0.582 |
| Baseline+Basic module+BDA | 6.983 | 3.054 | 4.607 | 0.653 | 0.972 | 0.573 | |
| RoadScene | Baseline+Basic module+DAPM | 7.349 | 3.467 | 5.488 | 0.693 | 0.981 | 0.573 |
| Baseline+Basic module+BDA | 7.374 | 3.657 | 5.286 | 0.639 | 0.807 | 0.543 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Han, M.; Qin, Y.; Li, Q. Self-Attention Progressive Network for Infrared and Visible Image Fusion. Remote Sens. 2024, 16, 3370. https://doi.org/10.3390/rs16183370
Li S, Han M, Qin Y, Li Q. Self-Attention Progressive Network for Infrared and Visible Image Fusion. Remote Sensing. 2024; 16(18):3370. https://doi.org/10.3390/rs16183370
Chicago/Turabian StyleLi, Shuying, Muyi Han, Yuemei Qin, and Qiang Li. 2024. "Self-Attention Progressive Network for Infrared and Visible Image Fusion" Remote Sensing 16, no. 18: 3370. https://doi.org/10.3390/rs16183370
APA StyleLi, S., Han, M., Qin, Y., & Li, Q. (2024). Self-Attention Progressive Network for Infrared and Visible Image Fusion. Remote Sensing, 16(18), 3370. https://doi.org/10.3390/rs16183370