Abstract
Multi-object tracking in satellite videos (SV-MOT) is an important task with many applications, such as traffic monitoring and disaster response. However, the widely studied multi-object tracking (MOT) approaches for general images can rarely be directly introduced into remote sensing scenarios. The main reasons for this can be attributed to the following: (1) the existing MOT approaches would cause a significant rate of missed detection of the small targets in satellite videos; (2) it is difficult for the general MOT approaches to generate complete trajectories in complex satellite scenarios. To address these problems, a novel SV-MOT approach enhanced by high-resolution feature fusion and a two-step association method is proposed. In the high-resolution detection network, a high-resolution feature fusion module is designed to assist detection by maintaining small object features in forward propagation. By utilizing features of different resolutions, the performance of the detection of small targets in satellite videos is improved. Through high-quality detection and the use of an adaptive Kalman filter, the densely packed weak objects can be effectively tracked by associating almost every detection box instead of only the high-score ones. The comprehensive experimental results using the representative satellite video datasets (VISO) demonstrate that the proposed HRTracker with the state-of-the-art (SOTA) methods can achieve competitive performance in terms of the tracking accuracy and the frequency of ID conversion, obtaining a tracking accuracy score of 74.6% and an ID F1 score of 78.9%.
1. Introduction
With the rapid development of remote sensing earth observation technology and the successive launch of video satellites, such as Jilin-1, SkySat, etc. [1,2,3], remote sensing video data are becoming increasingly easy to obtain, and they play an important role in the tasks of military precision strikes, civilian traffic flow estimation, fire detection, etc. [4,5,6]. Video satellites complete dynamic ground observation by focusing on specific areas for a certain period of time and can provide richer temporal information and a larger observation area. For example, in October 2015, the “Jilin-1” satellite developed by Changguang Satellite Company was launched. It can obtain full-color video data of 11 × 4.5 m with a resolution of 1 m. The video can reach a maximum length of 90 s and a frame rate of 25 frames per second. From 2013 to 2017, the United States launched 13 SkySat satellites developed by Skybox. These satellites can obtain full-color video data with a 0.8-m resolution and multispectral video data with a 1-m resolution, and they have a maximum duration of 90 s. Therefore, SV-MOT has become one of the hotspots in satellite video processing and analysis. Unlike the general MOT approaches, SV-MOT has to face more challenges [7], such as cloud interference and targets with very small sizes that would only account for one thousandth of the video sizes.
In recent decades, significant breakthroughs have been made in general MOT, which can be divided into two branches: detection-based tracking (DBT) and joint tracking and detection (JDT). Specifically, as shown in Figure 1a, the DBT approaches first obtain detection boxes in every frame and then perform association over time. Furthermore, the detection and association modules have no interconnection, and their tracking performance is mainly dependent on the quality of detection. However, the independent structure has low tracking efficiency, and it cannot produce joint optimization. These approaches can achieve a competitive performance easily but with a heavy training cost. As shown in Figure 1b, the JDT approaches use a network to perform both detection and association subtasks simultaneously, so as to estimate the objects and learn re-ID features simultaneously. These models are more efficient and faster because they consider detection and association at the same time, but it is difficult to maintain a balance between detection and association, leading to one subtask dominating the training process, while the performance of the other subtasks decreases. For example, detection involves discovering all the targets in the current frame, while association involves establishing an association between all the current targets and the targets in the previous frames. An association task needs more low-level features than detection. Thus, the shared features in the JDT approaches lead to a reduction in tracking performance.

Figure 1.
The different MOT paradigms: (a) the network of detection-based tracking (DBT); (b) the network of joint detection and tracking (JDT).
As there is a big difference between the general videos and the satellite videos, a significant performance degradation occurs when directly applying any of the methods discussed above to satellite videos. This is because, in comparison with natural scenes, the following challenges exist in remote sensing:
- Small objects. As shown in Figure 2a, in the natural scene the object size is 30 × 70 pixels. However, due to the low spatial resolution of satellite videos, the target size in satellite videos is approximately 10 × 8 pixels. The size of the objects in satellite videos decreases their features, which makes it difficult for the detectors that are widely used in natural scenes to recognize targets in satellite videos. Therefore, in SV-MOT problems, it is difficult to accurately detect all the targets, resulting in a large number of missed detections and false alarms.
 Figure 2. Challenges of satellite videos: (a) comparison of object size in satellite videos and natural videos; (b) complex background and motion noise in satellite videos.
Figure 2. Challenges of satellite videos: (a) comparison of object size in satellite videos and natural videos; (b) complex background and motion noise in satellite videos. - Low contrast and complex background. As shown in Figure 2b, the low contrast and complex background scenarios can easily lead to a large number of missed detections and false alarms, resulting in a decrease in tracking performance. In addition, the detected targets are easily removed due to low confidence during data association processing, resulting in discontinuous trajectories. There is also a large amount of motion noise in satellite videos, which affects trajectory prediction and further increases the difficulty of multi-target tracking.
To fill the gap between MOT and SV-MOT, the use of a few tracking methods for satellite videos in succession is proposed. However, they are unable to effectively solve the problems of small object detection and fragmented trajectories in satellite videos. Some methods cannot achieve online tracking, while others require complex and time-consuming network training.
It is worth mentioning that although some progress has been made with the existing SV-MOT methods, the high frequency of tracking misses and ID switches while dealing with dense target occlusion is still a key issue which has not been well handled. In our opinion, the missing tracking problem is mainly due to the poor detection of small objects, the high frequency of ID switches and tracking instability is mainly due to weak data association. The real targets with a small size cannot always be detected with a high level of confidence in satellite videos. Thus, the filter operation based on confidence may cause a lot of small objects to be lost. However, associating all the detection boxes may result in the tracking of many false alarms. To tackle this issue, the similarity of the trajectories is applied to distinguish between the false alarms and the correct targets. Therefore, this study focuses on both the detection and the association parts and proposes an adaptive association-based multi-object tracking approach for satellite videos, enhanced by high-resolution feature fusion (HRTracker). For a better tracking performance, we follow the branch of DBT, which performs detection first, and then association. In detail, a novel detection module with high-resolution feature fusion for small targets is introduced. It is combined with an association method for tracklet prediction based on adaptive Kalman filtering.
By repeatedly optimizing the detection network and matching strategy, the proposed SV-MOT can reduce miss detection and ID switches and achieve precise and stable tracking and a performance that is comparable with that of the SOTA methods. The contributions can be summarized as follows:
- We propose a satellite video multi-target tracking method based on a detection and tracking paradigm for satellite videos. Compared with other tracker detection methods, our method can reduce miss detection and false alarms.
- An adaptive data association strategy is proposed to handle the problems related to the deletion of low-confidence detection boxes and fragmented trajectories.
The comprehensive experimental results using the VISO datasets [7] demonstrate the effectiveness of our method. The remainder of this paper is organized as follows. Section 2 introduces the related work that inspired this study. Section 3 explains the details of our method, and the extensive experiments are presented in Section 4. Finally, the conclusion and future work are outlined in Section 4.
2. Related Work
MOT can be divided into two paradigms based on whether the detection and computation feature networks share a network: DBT methods and JDT methods. Next, we briefly introduce the representative methods of MOT and the related research on multi-object tracking in satellite videos.
2.1. DBT Method
DBT is an important branch of MOT, it designs correlation methods based on detection results to achieve multi-object tracking. Some data association methods use motion information, and others use ReID information.
Motion models: SORT [8] is the most representative DBT method, and most DBT methods are improved based on the SORT algorithm, which is based on Kalman filtering. It establishes an observation model foundation, which can accurately predict the position and motion speed of the object and uses the Hungarian algorithm to associate objects frame by frame. Sometimes, ReID falls short when scenes are crowded and the objects are represented coarsely. Therefore, some methods have been proposed to address these issues. For example, Bytetrack [9] first associates high-score detection boxes and then associates low-score detection boxes. Finally, it distinguishes between real targets and false alarms through the similarity of trajectories. OC-SORT [10] pointed out the limitations of the SORT algorithm and proposed an observation-centered online smoothing strategy to alleviate the cumulative errors generated during the Kalman filtering process. BoT-SORT [11] combines the advantages of motion and appearance information, camera motion compensation, and more accurate Kalman filtering state vectors. To achieve continuity of tracking in satellite videos, GMPHD-SAR [12] adopts border tracking and morphological operations to extract the detection boxes and uses the GMPHD filter instead of the Kalman filter to predict trajectories. SDT-SAT [13] uses target shadow features to extract detection boxes and uses the SCEA [14] method to achieve data association. CKDNet-SMTNet [15] proposed a spatial motion information-guided network for tracking performance enhancement, extracting the spatial information of targets in the same frame and the motion information of targets in consecutive frames. In CKDNet, a customized cross-frame module was designed to assist in keypoint detection by utilizing complementary information between frames. SMTNet effectively tracks dense targets by constructing two branches of long short-term memory. SFMFMOT [16] adopts the FairMOT detection network with an improved NMS and SF module to extract the targets in satellite videos. In the data association stage, it adopts the three-stage judgment principle and the NMS strategy.
Appearance models: In order to reduce the number of ID conversions, DeepSORT [17] introduced ReID features on the basis of SORT, which can better distinguish different feature targets in videos. StrongSORT [18] features a series of improvements based on DeepSORT, which enhance tracking accuracy and performance. ER-MOT [19] proposes an adaptive resolution optimization method and uses composite features to achieve feature extraction and a trajectory reliability assessment metric to perform data association. TC-MOT [20] proposes a Siamese-based appearance model with online transfer learning to fine-tune the model parameters. It performs data association with trajectory confidence and uses a confidence-based association method. HMAR [21] adopts a human mesh and appearance recovery method and performs data association using transformer models.
2.2. JDT Method
In the JDT branches, which perform both detection and association in the same network, JDE [22] is a classic and representative method. It highlights the fact that executing these two stages separately can lead to serious efficiency issues, and the entire runtime is basically equal to the sum of the execution times of the two stages when run separately. To address fair training for the detection and ReID tasks in the previous methods, FairMOT [23] was proposed. It optimizes both the detection model and the ReID model and achieves a balance between detection and ReID tasks through several strategies. At the same time, CSTracker [24] proposed a reciprocal network and SAAN method to extract the object features. In order to further improve the accuracy and speed of MOT, CenterTrack [25] proposed an integrated network of detection and tracking based on key points. In the data association stage, it performs data association based on the distance between the predicted offset of the center point and the center point of the tracked target in the previous frame. For satellite videos, the JDT methods such as TGraM [26] proposed a graph-based spatiotemporal inference module to explore potential high-order correlations between video frames, modeling multi-object tracking as a graph information inference process from the perspective of multitask learning. In order to cope with low spatial resolution and a widespread indistinguishable background, CFTracker [27] proposed a cross-frame feature update module and a method for cross-frame training. FairMOT-SAR [28] combined FairMOT with shadow tracking to improve the tracking performance.
However, we believe that multi-object tracking methods based on the JDT paradigm and the appearance model are not suitable for multi-object tracking in satellite videos. This is because in satellite videos the target only occupies a few pixels, which only represent one thousandth of the size of the satellite video, and there is no appearance information that can be extracted and utilized. Therefore, in this study, we adopt the DBT paradigm based on a motion model for multi-object tracking in satellite videos.
3. Methods
At present, in the research on satellite video multi-object tracking, we believe that the main challenges we face are excessive missed tracking and incomplete trajectories. So, we propose an improved detection network to address the issue of missed tracking and an adaptive data association method for incomplete trajectories. In this section, we provide a detailed introduction to our method, which follows the detection-based multi-objective tracking paradigm. It proposes three innovative points and integrates them into YOLOv5+SORT.
3.1. Reasons for Selecting YOLOv5
Object detection is a fundamental and significant challenge in the field of computer vision, aimed at identifying and locating objects of interest within images or videos. Traditional object detection methods, such as the R-CNN series of algorithms, while achieving high accuracy, tend to be slow and are not suitable for real-time applications. The emergence of the YOLO algorithm, with its single-stage detection and high efficiency, addresses the demands of real-time object detection and fosters advancements in object detection technology. The development history of the YOLO algorithm illustrates the application and progress of deep learning in object detection tasks. From the initial YOLOv1 to the current YOLOv10, each iteration has demonstrated improvements in performance, speed, and accuracy. The popularity of the YOLO algorithm is also attributed to its ease of understanding and implementation, as well as its high adaptability to real-time performance. With the ongoing advancement of technology, the YOLO algorithm and its variants have been widely applied and studied in both industry and academia.
From YOLOv1 to YOLOv5, and now to the latest YOLOv10, each generation of models has undergone continuous optimization and improvement. This paper will compare and analyze the performance differences among the YOLOv10, YOLOv8, and YOLOv5 models. The performance comparison primarily focuses on two aspects: accuracy and inference speed. Accuracy refers to a model’s ability to correctly identify targets, while inference speed indicates the model’s real-time performance in practical applications. Existing research shows that YOLOv8 and YOLOv10 demonstrate some improvement in accuracy compared to YOLOv5, although the extent of this improvement is not substantial. In terms of inference speed, both YOLOv8 and YOLOv10 are faster than YOLOv5. YOLOv10 has further enhanced performance and efficiency through a continuous dual allocation strategy that eliminates the need for Non-Maximum Suppression (NMS) training, along with a comprehensive efficiency-accuracy-driven model design strategy. However, our experiments revealed that YOLOv5 outperforms both YOLOv8 and YOLOv10, as evidenced by its higher mean Average Precision (mAP), recall, and precision. This discrepancy may be attributed to the structural differences among YOLOv5, YOLOv8, and YOLOv10. Although their architectures are generally similar, YOLOv5 may be more adept at detecting small objects in satellite videos for the following reasons: (1) YOLOv8 and YOLOv10 enhance the CSPDarknet backbone network and introduce Anchor-Free point detection heads, whereas YOLOv5 employs Anchor-Based detection heads. While Anchor-Free methods are relatively straightforward and do not require the design of numerous anchor boxes, their performance tends to be suboptimal for multi-scale and multi-aspect ratio targets. In scenarios with densely arranged targets, inaccurate positioning is more likely to occur. Conversely, Anchor-Based methods are well-suited for targets with varying scales and aspect ratios, and anchor boxes can enhance detection performance for densely packed targets. Given the dense distribution and varying scales of targets in satellite videos, YOLOv5 may be more effective for small target detection in this context; (2) YOLOv8 and YOLOv10 are designed to be lighter and have significantly reduced computational parameters compared to YOLOv5. However, due to the larger amplitude of satellite videos and the lower proportion of targets within these videos, detecting targets in satellite imagery necessitates a greater amount of computational resources. The intricate architecture of the YOLOv5 network may be more suitable for object detection in satellite scenes.
We will provide a detailed explanation of the experimental results for YOLOv10, YOLOv8, and YOLOv5 in the experimental section. Our findings indicate that YOLOv5 demonstrates superior performance; therefore, we have selected YOLOv5 as the baseline detection method for this paper.
3.2. High-Resolution Detection for Network
HRNet (High Resolution Network) is specifically designed for 2D human pose estimation, also referred to as keypoint detection. This network is primarily intended for assessing the pose of a single individual, meaning that the input image should contain only one human target. However, HRNet has also improved the performance of various computer vision tasks, including object detection, image super-resolution, image segmentation, image classification, and change detection. This enhancement is largely attributed to its capability to maintain high resolution.
In satellite videos, the appearance information of an object is weak because the object is very small in satellite scenarios and the background is complex and is affected by factors such as cloud interference, which results in a considerable amount of missed detection. The large scale of missed detection is one of the main reasons why general MOT cannot be introduced into satellite videos. If there are not enough detection boxes generated at the beginning, any data association has to face a tracking failure. Therefore, in this study, the general detection module is replaced by a small object detection module to adapt to the characteristics of satellite video. At present, most small target detectors obtain strong semantic information through downsampling and then use upsampling to recover high-resolution location information. However, these approaches can lead to the loss of a large amount of effective information during the continuous upsampling and downsampling process. HRNet achieves the goal of strong semantic information and precise positional information by parallelizing multiple resolution branches and continuously exchanging information between different branches. Thus, the most representative concept of multi-resolution is introduced for an essential improvement in tracking performance. Specifically, the most representative detection framework, YOLOv5 [29], is set as the baseline, and a high-resolution feature fusion strategy [30] is designed to make full use of the features in multi-resolution, whose network structure is shown in Figure 3.
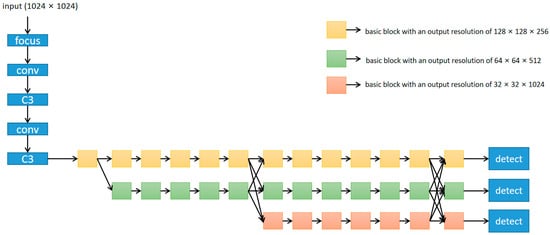
Figure 3.
The structure of the proposed high-resolution detection network.
As illustrated in the figure, we substituted the neck region of the YOLOv5 network with the HRNet network, pruned the YOLOv5 backbone region, and preserved the original detection head within the YOLOv5 network. After modification, the backbone part of the network mainly consisted of two parts: the focus module and the C3 module. The focus structure, a convolutional neural network layer for feature extraction, compresses and combines information from input feature maps to extract high-level feature representations. It is a special convolutional operation in YOLOv5 and is used as the first convolutional layer in the network to downsample input feature maps, thereby reducing computational demands and parameter counts. Specifically, the focus structure can divide the input feature map into four subgraphs and concatenate these four subgraphs through channels to obtain a smaller feature map. Assuming that the size of the input feature map is N × N × C, where N is the size of the feature map and C is the number of channels, then the output feature map size of the focus structure is N/4 × N/4 × C/2. The C3 structure is an important component of YOLOv5, as shown in Figure 4, and is used to build backbone networks. The C3 structure can effectively reduce network parameters and computational complexity, while improving the efficiency of feature extraction. The core idea of the C3 structure is to divide the input feature map into two parts, one part is processed by a small convolutional network, and the other part is directly processed by the next layer. Then, the two feature maps are concatenated as input for the next layer. This can combine low-level detail features with high-level abstract features to improve the efficiency of feature extraction. Finally, the size of the satellite data we input is 1024 × 1024 × 3; therefore, the feature map output from the backbone structure of the detection network is 128 × 128 × 256.
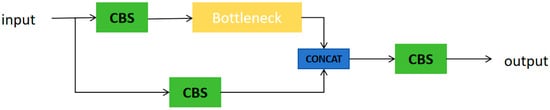
Figure 4.
The structure of C3. Here, CBS represents convolutional module, CONCAT represents connection layer, and Bottleneck is a residual structure.
The idea of HRNet [31] was introduced into YOLOv5 to allow high-resolution feature fusion. In the original HRNet network, as illustrated in Figure 5a, only a high-resolution feature representation was output, signifying that only high-resolution convolutional features were retained. Consequently, we also investigated outputting feature representations from several other low-resolution convolutions. This approach benefitted from the utilization of multi-resolution convolutional features while incurring minimal additional parameters and computational overhead. However, unlike the original HRNet, which only uses the highest resolution feature map as the output of the model, HRNetv2 [32] added a concatenation operation for feature maps with different resolutions and then subsampled the combined feature maps with average pooling to obtain multiple feature maps with different resolutions. In order for it to be applied to object detection tasks, HRNetV2p was obtained by post-processing the concatenated feature representation, as shown in Figure 5b,c. Specifically, HRNetV2 upsamples the low-resolution outputs bilinearly to match the sizes of the high-resolution outputs and concatenates these high-resolution outputs to produce high-resolution feature representations. These representations are employed in semantic segmentation and facial feature detection, among other applications. The feature fusion across different resolutions employs a 1 × 1 convolution. For object detection tasks, HRNetv2p adopts multi-level feature representation. The method involves using the high-resolution feature representation obtained from the previous step of average pooling downsampling to obtain another feature representation with lower resolution.
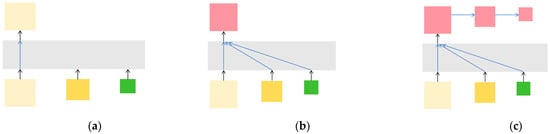
Figure 5.
Three different output representations: (a) HRNetv1; (b) HRNetv2; (c) HRNetv2p.
Therefore, in this study, an operation similar to that of HRNetv2p is adopted. Specifically, the HRNet retains high-level semantic information by adopting a parallel structure with different resolutions. Within the forward propagation, multiple resolutions interact between different branches, which further reduces the impact caused by the decreasing channel dimensions. The HRNet is composed of basic blocks and fuse layers. The input of the basic block is , and the output of each basic block can be expressed as
where f(.) denotes the convolutional layer with a batch normalization layer (BN) and an ReLU activation function layer. Regarding the fuse layer, the input is combined with multi-resolution features, which are concatenated in the channel dimension. Then, the concatenated feature goes through an f(.) operation to generate the output, where the output channel varies with the position of the fuse layer.
In addition, to reduce the information loss of the feature maps with different resolutions in the sampling process and to reduce the calculation amount, the feature maps with the current resolution are also concatenated. Finally, three feature maps with different resolutions and channel numbers are obtained. These feature maps are then fed into the detection head for further prediction.
3.3. An Adaptive Association-Based SV-MOT
Even though our detection network architecture and the detection rate of the targets in satellite videos were improved, we focused more on improving feature representation performance in the process of improving the network and did not pay attention to how to more efficiently associate interframe targets into trajectories. Further improvement and research are needed to address the robustness of the tracking trajectory estimation and data association methods. Below, we introduce our proposed adaptive Kalman trajectory method and two-step matching spatial data association method.
3.3.1. The Adaptive Kalman Filter for Trajectory Prediction
Kalman filtering [32] is a commonly used method for object tracking. However, in practical applications, the variance of observed noise is often unknown, which can have a certain impact on the performance of Kalman filtering. To solve this problem, an adaptive Kalman filtering method is adopted. In the following, a detailed introduction to the process of this method is provided.
Firstly, we introduce the universal Kalman filtering method, which is an algorithm that utilizes linear system state equations to perform an optimal estimation of the system state through system input and output observation data. In the study, the state vector of each object was chosen to be an eight-tuple:
where x and y represent the horizontal and vertical coordinates of the object, while a and h represent the aspect ratio and the height of the object’s bounding box, respectively. The last four parameters represent their respective rates of change.
In the prediction step, use the state transition matrix and control the inputs to predict the new state of the target. The specific prediction formulae are as follows:
where is the predicted state vector, A is the state transition matrix, is the previous state vector, is the predicted state covariance matrix, and Q is the process noise covariance matrix.
In the update step, compare the predicted state with the observation and update the state vector and covariance matrix. The specific update formulae are as follows:
where K is the Kalman gain matrix, H is the observation matrix, R is the observation noise covariance matrix, is the observation vector, and I is the identity matrix.
In the prediction step of Kalman filtering, the model predicts the current state based on the most recent best estimate and the process noise covariance, Q. If Q is set too high, the model may place excessive trust in the predicted values, leading to estimation results that deviate from the true values. Conversely, if Q is set too low, the model may disregard the predicted values, resulting in estimation outcomes that are overly sensitive to changes in the observed values. The observed values are then used to correct the predicted values, yielding the optimal estimate. The weight assigned to the observed values is determined by the covariance, R, of the observed noise. If R is set too high, the model may place undue trust in the observed values, which can also lead to estimation results that deviate from the true values. On the other hand, if R is set too low, the model may overlook the observed values, causing the estimation results to rely excessively on the predicted values. Therefore, the process of adjusting Q and R is essentially about balancing the trustworthiness of model predictions and observed data. Generally, these two parameters can be adjusted based on the specific application scenarios and the characteristics of the observed data. If the observed data is relatively accurate and reliable, the value of R can be reduced to increase the weight of the observed values in the estimation results. Similarly, if the model predictions are accurate and reliable, the value of Q can be decreased, thereby increasing the weight of the predicted values in the estimation results.
In standard Kalman filtering, the observed noise variance is considered to be a known constant. However, in practical applications, the variance of observed noise may vary over time or be uncertain due to other factors. Due to the large motion noise in the video, the observation noise is constantly changing, especially in satellite videos. To solve this problem, an adaptive method can be used to estimate the variance of the observation noise. A common method is to use the minimum variance unbiased estimate. In statistics, the minimum variance unbiased estimate is an unbiased estimate that has the minimum level of variance among all the unbiased estimates. Regardless of the true parameter values, the minimum variance unbiased estimate has lower variance than the other unbiased estimates, or, at most, the variance is equal. Then, this estimate is called the uniform minimum variance unbiased estimate (MVUE). The basic purpose of the minimum variance unbiased estimate method is to estimate the variance of the unknown observation noise by minimizing the variance of the estimation error. The specific steps are as follows:
where e is the estimation error vector, and R is the updated observation noise covariance matrix.
During the target tracking process, the prediction and update steps are iteratively executed. Each iteration predicts and updates the state based on new observations and adaptively updates the variance of the observation noise.
3.3.2. The Two-Step Data Association for Satellite Videos
Targets in satellite videos that had a small size or were affected by a complex background would easily obtain low detection confidence. Common MOT associations always first filtered out the detection boxes with low confidence and then performed association, which caused many objects to be lost. Specifically, in order to make more objects in satellite videos associate and form a trajectory, a two-step association method is proposed, which first associates the high-score detection frames and then associates the low-score detection frames. Finally, it filters out false alarms according to their similarity to the trajectory. The flowchart can be seen in Figure 6.
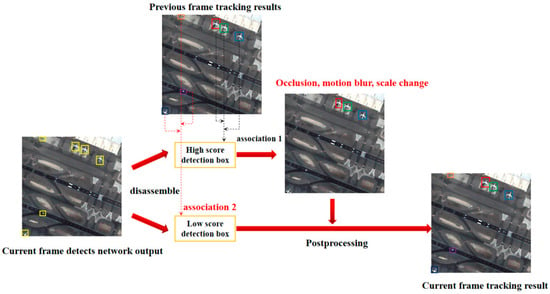
Figure 6.
Flowchart of the two-step association.
Below, we specifically discuss the data association methods. Firstly, according to an adaptive threshold, the detection boxes were divided into high-score detection boxes and low-score detection boxes. Secondly, the trajectory was predicted in the new frame using an adaptive Kalman filter. Thirdly, the high-score detection boxes in the new frame were associated with the existing trajectory. The similarity between the predicted trajectory and the high-score detection boxes was calculated using IOU. The Hungarian algorithm [33] was used to solve the optimal matching between the tracking and the detection boxes. Fourthly, the unmatched trajectories were associated with the low-score detection boxes in order to achieve better tracking performance in terms of scale change, occlusion, and motion ambiguity. The false alarms were distinguished from the real target by their similarity to the trajectories. Finally, the high-score detection boxes that had no match were initialized to a new track, and the tracklets which had not been matched over a certain number of frames were deleted.
4. Experiments
To verify whether our proposed method could solve the missed tracking and incomplete trajectory problems, we conducted a series of experiments to verify its effectiveness. In this section, we first introduce the details of the implementation, including the dataset, metrics, and experimental setup. Then, ablation experiments are performed to verify the effectiveness of each proposed module. Finally, the performance of HRTracker is compared with that of start-of-the-art methods, and the experimental results demonstrate the superiority of the proposed HRTracker.
4.1. Datasets
We validated our method using the VISO dataset, which consists of 47 satellite videos captured by the Jilin-1 satellite. The satellite video obtained by the Jilin-1 satellite consists of a series of true-color images. The coverage area of real scenes can reach several square kilometers. The majority of instances in VISO have a size smaller than 50 pixels, and the videos cover different types of city-scale elements, such as roads, bridges, lakes, and a variety of moving vehicles. VISO is a diverse and comprehensive dataset which consists of different traffic situations, such as dense lanes and traffic jams. Therefore, the satellite videos in the dataset cover a wide range of challenges, including complex backgrounds, illumination variations, dense targets, and so on. The size of every video is 1024 × 1024. The frame numbers are different and range from 324 to 326. We randomly selected 20 videos as a training set and 5 unrepeated videos as a testing set from the VISO dataset.
4.2. Evaluation Metrics
We evaluated the performances of the different methods and the proposed module for multi-object tracking in satellite videos. Six representative metrics were utilized for the evaluation, including false positives (FPs), false negatives (FNs), ID switches (IDs), the ID F1 score (IDF1), multi-object tracking precision (MOTP), and multi-object tracking accuracy (MOTA). The discrimination of the metrics is as follows:
- FP: the number of false positives in the whole video;
- FN: the number of false negatives in the whole video;
- IDs: the total number of ID switches;
- IDF1: the ratio of correctly identified tests to the average true and calculated number of tests;
- The MOTP is defined as follows, in which is the Euclidean distance between the i-th object, and the assumed position in frame t, and is the number of matches in frame t:
- The MOTA is defined as follows, in which GT is the ground truth:
4.3. Experimental Setup
In our HRTrack, the detection part with high-resolution feature fusion was first trained with the VISO dataset, and this was followed by the two-step association strategy to obtain the trajectories of multiple objects in the satellite video. Twenty video datasets in VISO were trained using GPU 3090. During the training process, random gradient descent (SGD) was selected as the optimizer. The initial learning rate was 0.01, and the weight attenuation parameter was 0.0005. In the tracking process, the maximum number of lost track frames was set to 30 frames, and the matching threshold of the tracking was set to 0.8. We compared our method with the state-of-the-art trackers in natural and satellite scenarios, such as SORT, FairMOT, TGraM, OC-SORT, BoT-SORT, and Bytetrack. To ensure the fairness of the experiment, all the method settings were consistent with those of the original study, and the same satellite video dataset was used for training with RTX 3090 GPU.
4.4. Ablation Experiments
To demonstrate that the detection performance of YOLOv5 is superior to other YOLO models in remote sensing scenarios, we randomly selected 6000 images from the VISO dataset for experimentation. We maintained consistent parameters to ensure fairness while testing YOLOv5, YOLOv8, and YOLOv10. The results of the tests are shown in Figure 7, which indicates that in satellite scenarios, YOLOv5 outperforms both YOLOv8 and YOLOv10 in terms of mean Average Precision (mAP), precision, and recall.
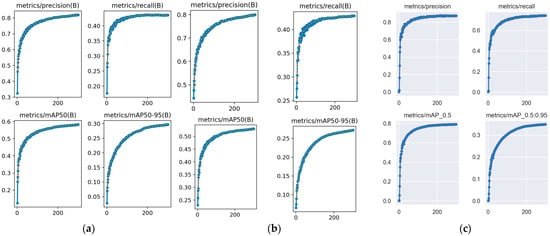
Figure 7.
The detection result of YOLOv8, YOLOv10 and YOLOv5 in remote sensing scenarios: (a) YOLOv8; (b) YOLOv10; (c) YOLOv5.
To verify the effectiveness of the separate proposed modules in HRTracker, five representative videos in the VISO datasets (as shown in Figure 8), with challenges such as serious occlusion and complex backgrounds, were selected as the testing set.

Figure 8.
Five selected test satellite videos in VISO: (a) video-train08; (b) video-train02; (c) video-train04; (d) video-train10; (e) video-train09.
YOLOv5 + SORT was selected as our baseline method. Each module was integrated independently into the baseline for an effective evaluation. Table 1 shows the results of the ablation experiment using the method we proposed.

Table 1.
Ablation study for different structures using test dataset.
HRNet is a network that integrates high and low resolution in the baseline detection network. Because it parallelizes multiple resolution branches and continuously exchanges information between different branches, the detector is more suitable for small targets in satellite videos.
TSA represents the use of a two-step matching spatial data association method in the baseline methods. By utilizing low-resolution detection boxes, it can more stably track targets and improve the performance of HRTracker.
AKF represents the insertion of adaptive Kalman filtering into the baseline method, which adaptively calculates the variance of observations and performs interframe updates to improve the performance of HRTracker.
It can be seen from Table 1 that compared with the baseline, YOLOv5 + TSP (the two-step association strategy is added) achieved great tracking enhancement by improving MOTA by 36% and IDF1 by 45.3%. At the same time, the FN, FP and IDs were significantly reduced, which verifies the effectiveness of the two-step association. HRNet was integrated into the framework of YOLOv5. After integrating HRNet into YOLOv5, we achieved improvements in tracking performance by improving MOTA by 1.4% and IDF1 by 0.4%, which verifies the effectiveness of HRNet. Finally, we integrated AKF into the tracking network, and it achieved a 0.6% increase in MOTA. The MOTA reached 74.6% and FN and FP were both decreased, but it can be seen that the IDF1 and IDs indicators were slightly decreased, indicating an increase in the number of ID conversions for the target. More accurate trajectory prediction increases the trajectory of each target in satellite videos, which also leads to more target box flickering and a decrease in the IDF1 index, but the improvement in the MOTA and MOTP indicators is sufficient to demonstrate the effectiveness of the AKF.
4.5. Comparison with Other Methods
In this section, the SOTA approaches, including FairMOT, SORT, Bytetrack, and TGraM are compared with the proposed method using the VISO test, and the experimental results are shown in Table 2. Although our proposed method showed a decrease in the MOTP metric, it can be seen from Table 2 that we achieved the best results for MOTA, IDF1, and other metrics. The proposed HRTracker achieved 74.6% for MOTA and 78.9% for IDF1, which were much better results than those of the previous work. Specifically, for the most representative MOT approach—Bytetrack—we were able to achieve results that were 4.7% higher for MOTA and 0.3% higher for IDF1. The superiority of the proposed method is not only reflected in the accuracy but also in the speed. Although our tracking method is based on the paradigm of DBT, our tracking part does not have a deep network model, and the detection network is simple with fast inference speed. Our tracking speed can reach over 100 FPS in satellite videos, making it suitable for in-orbit tracking. The decrease in MOTP is due to the fact that although our improved detection network can detect targets that the other methods cannot detect, the false positives also increase accordingly. This is also an area that we need to continue to improve in future work.
Table 2.
Comparison of the state-of-the-art methods using VISO test set.
Some of the visualization results of the proposed method are shown in Figure 9, Figure 10 and Figure 11. The tracked trajectories comparisons between the proposed method and the SOTA multi-object tracking methods are shown in Figure 9 and Figure 10. It can be concluded that the trajectories of TGraM, FairMOT, SORT, and other methods tend to be fragmented and confused. However, in Figure 9d,e and Figure 10d,e, it can be seen that our two-step association strategy could perform stable tracking and that the tracklets tended to be more complete, which demonstrates the viability of the two-step association. Finally, as shown in Figure 9f and Figure 10f, with high-resolution feature fusion added, the number of tracklets increased, which intuitively demonstrates the effectiveness of our detection network, YOLOv5 + HRNet. The key frames of the representative visual experimental results regarding the challenges of occlusion and intensive targets are shown in Figure 11. It can be seen in Figure 11a that when two cars meet and block each other, the IDs of the two cars remain unchanged and that there is no missed tracking. When a vehicle crosses the bridge, the ID information of the vehicle remains unchanged before and after the crossing of the bridge, which indicates that our method can effectively handle the problem of background occlusion and the mutual occlusion of targets in complex satellite scenes. It can be seen in Figure 11b that our method can maintain simultaneous and stable tracking of multiple targets in satellite scenes with dense targets. Overall, when facing rather complex tracking challenges, our HRTracker can achieve more stable tracking, forming more complete trajectories with fewer ID conversions and higher accuracy.

Figure 9.
The tracked trajectories comparison with the proposed method and the SOTA multi-object tracking methods. Different colors represent different trajectories (video1): (a) TGraM; (b) FairMOT; (c) SORT; (d) Bytetrack; (e) YOLOv5 + Bytetrack; (f) HRTracker.

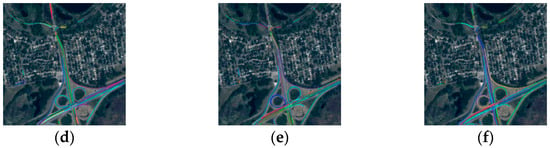
Figure 10.
The tracked trajectories comparison with the proposed method and the SOTA multi-object tracking methods. Different colors represent different trajectories (video2): (a) TGraM; (b) FairMOT; (c) SORT; (d) Bytetrack; (e) YOLOv5 + Bytetrack; (f) HRTracker.

Figure 11.
Detailed experimental results of the challenges of occlusion scene and intensive object: (a) occlusion scene; (b) intensive object.
In addition, to demonstrate the scalability and real-time performance of our algorithm, we applied it to various datasets for multi-object tracking. Specifically, we directly utilized the weights trained on our dataset with other satellite videos from the VISO datasets for multi-object tracking. The tracking results are presented in Figure 12. Although there may be some missed detection in certain scenarios, the results sufficiently indicate the scalability and real-time capabilities of this algorithm. We also employed this algorithm to track ships and planes in the satellite videos, with the tracking results displayed in Figure 13 and Figure 14.

Figure 12.
Results of tracking vehicles in other videos from the VISO(2024) dataset: (a) video-train38; (b) video-test03; (c) video-test07.

Figure 13.
Results of tracking ships in other videos from the VISO(2024) dataset: (a) video-train63; (b) video-validation 03; (c) video-test11.

Figure 14.
Results of tracking planes in other videos from the VISO(2022) dataset: (a) video-train71; (b) video-train08; (c) video-train53.
5. Conclusions
In this study, a novel multi-object tracking approach for satellite videos called HRTracker was proposed. It consists of a high-resolution detection network for small objects and an adaptive association method. Specifically, we combined a YOLOv5 network with an HRNet network to achieve both strong semantic information and high-resolution positional information, which improved the detection performance. We implemented a two-step matching data association technique that utilized adaptive Kalman filtering, enhancing the trajectory’s integrity. Compared with the SOTA approaches, our method achieved higher tracking accuracy and a lower frequency of ID switches. Nevertheless, due to the characteristics of satellite videos, there were some false positives; both the Multiple Object Tracking Precision (MOTP) and the identification of objects (IDs) still need optimization. In future work, we will analyze the reasons for the instability of MOTP and the increase in ID switches associated with the introduction of adaptive Kalman filtering. We will propose optimization strategies to enhance the capabilities of satellite video tracking and integrate detection and data association into a network, forming an end-to-end system.
Author Contributions
Conceptualization, Y.W.; methodology, Y.W. and Q.L.; software, Y.W.; validation, Y.W., Q.L. and H.S.; formal analysis, Y.W.; investigation, Y.W.; resources, H.S. and D.X.; data curation, Y.W.; writing—original draft preparation, Y.W.; writing—review and editing, Y.W. and Q.L.; visualization, Y.W.; supervision, H.S. and D.X.; project administration, H.S. and D.X.; funding acquisition, H.S. and D.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the National Natural Science Foundation of China under Grant 62075218, 62401538, 62401539, 62475255; in part by the 7th Batch of Jilin Province Youth Science and Technology Talent Support Project: E32492UZT0; in part by the Special High-tech Industrialization Cooperation Fund of Jilin Province and the Chinese Academy of Sciences (E21293U9T0); in part by the project of 7th Jilin Province Young Science and Technology Talents Promotion (QT202306), and in part by the Talented Scientist Fund for Distinguished Young Scholars of Changchun (E31093U7T010).
Data Availability Statement
The data that support the findings of this study are available from the corresponding author, upon reasonable request.
Acknowledgments
This work was supported in part by the Jilin Province Key Laboratory of Machine Vision and Intelligent Equipment.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, S.; Yuan, Q.; Li, J. Video satellite imagery super resolution for “JILIN-1” via a single and multi frame ensembled frame work. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2731–2734. [Google Scholar]
- Kong, L.; Yan, Z.; Zhang, Y.; Diao, W.; Zhu, Z.; Wang, L. Low-frequency attitude error compensation for the jilin-1 satellite based on star observation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1000617. [Google Scholar]
- Mari, R.; De Franchis, C.; Meinhardt-Llopis, E.; Facciolo, G. Automatic Stockpile Volume Monitoring Using Multi-view Stereo from Skysat Imagery. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4384–4387. [Google Scholar]
- Sumari, A.D.W. Smart Military Society: Defining the characteristics to score the “Smart” of the military service. In Proceedings of the International Conference on ICJ for Smart Society, Jakarta, Indonesia, 13–14 June 2013; pp. 1–8. [Google Scholar]
- Zou, X.; Wang, Z.; Zheng, L.; Dong, H.; Jia, L.; Qin, Y. Traffic impact analysis of urban construction projects based on traffic simulation. In Proceedings of the 2012 24th Chinese Control and Decision Conference (CCDC), Taiyuan, China, 23–25 May 2012; pp. 3923–3927. [Google Scholar]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 11th International Symposium on Computational Intelligence and Design(ISCID), Hangzhou, China, 8–9 December 2018; pp. 280–284. [Google Scholar]
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and tracking small and dense moving objects in satellite videos: A benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5612518. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramous, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Cao, J.; Khirodkar, X.W.R.; Pang, J.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. arXiv 2022, arXiv:2203.14360. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B. Bot-sort: Robust associations multi-pedestrain tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Zhang, Y.; Mu, H.; Jiang, Y.; Hua, Q. Moving target detection and tracking based on Gmphd filter in SAR system. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2318–2321. [Google Scholar]
- Zhang, Y.; Yang, S.; Li, H.; Xu, Z. Shadow tracking of moving target based on CNN for video SAR system. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4399–4402. [Google Scholar]
- Yoon, J.H.; Lee, C.-R.; Yang, M.-H.; Yoon, K.-J. Structural constraint data association for online multi-object tracking. Int. J. Comput. Vis. 2019, 127, 1–21. [Google Scholar] [CrossRef]
- Feng, J.; Zeng, D.; Jia, X.; Zhang, X.; Li, J.; Liang, Y.; Jiao, L. Cross-frame keypoint-based and spatial motion information-guided networks for moving vehicle detection and tracking in satellite videos. ISPRS J. Photogramm. Remote Sens. 2021, 177, 3464–3468. [Google Scholar] [CrossRef]
- Wu, J.; Su, X.; Yuan, Q.; Shen, H.; Zhang, L. Multivehicle object tracking in satellite video enhanced by slow features and motion features. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5616426. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make DeepSORT Great Again. IEEE Trans. Multimedia. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Yu, R.; Cheng, I.; Zhu, B.; Bedmutha, S.; Basu, A. Adaptiveresolution optimization and tracklet reliability assessment for efficient multi-object tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1623–1633. [Google Scholar] [CrossRef]
- Bae, S.-H.; Yoon, K.-J. Confidence-based data association and discriminative deep appearance learning for robust online multi-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Rajasegaran, J.; Pavlakos, G.; Kanazawa, A.; Malik, J. Tracking people with 3D representations. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Online, 6–14 December 2021; pp. 23703–23713. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vision 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Zhu, S.; Hu, W. Rethinking the competition between detection and ReID in multi-object tracking. IEEE Trans. Image Process. 2022, 31, 3182–3196. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Koltun, V. Tracking objects as points. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 474–490. [Google Scholar]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-object tracking in satellite videos with gragh-based multitask modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619513. [Google Scholar] [CrossRef]
- Kong, L.; Yan, Z.; Zhang, Y.; Diao, W.; Zhu, Z.; Wang, L. CFTracker: Multi-object tracking with cross-frame connections in satellite videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611214. [Google Scholar] [CrossRef]
- Wang, W.; Hu, Y.; Zou, Z.; Zhou, Y.; Wang, C.; Shi, J.; Zhang, X. Video SAR ground moving target indication based on multi-target tracking neural network. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4584–4587. [Google Scholar]
- Wu, H.; Zhao, X.; Qiao, J.; Che, Y. An Improved YOLOV5 Algorithm for Elderly Fall Detection. In Proceedings of the 2023 International Conference on Innovation, Knowledge and Management(ICIKM), Portsmouth, UK, 9–11 June 2023; pp. 83–88. [Google Scholar]
- Zhang, X.; Liu, Q.; Chang, H.; Sun, H. High-Resolution Network with Transformer Embedding Parallel Detection for Small Object Detection in Optical Remote Sensing Images. Remote Sens. 2023, 15, 4497. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Madhukar, P.S.; Prasad, L.B. State Estimation using Extended Kalman Filter and Unscented Kalman Filter. In Proceedings of the 2020 International Conference on Emerging Trends in Communication, Control and Computing(ICONC3), Lakshmangarh, India, 21–22 February 2020; pp. 1–4. [Google Scholar]
- Alhaj, F.; Sharieh, A.; Sleit, A. Reconstructing Colored Strip-Shredded Documents based on the Hungarians Algorithm. In Proceedings of the 2019 2nd International Conference on New Trends in Computing Sciences(ICTCS), Amman, Jordan, 9–11 October 2019; pp. 1–6. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).