1. Introduction
Satellite remote sensing image data are increasingly used in a wide range of fields such as meteorological forecasting, weather analysis, environmental disaster response and monitoring of agricultural land resources. However, the performance of satellite sensors is compromised by operational environments and the aging of devices during in-orbit operations, while natural factors such as lighting conditions, atmospheric composition and meteorological conditions also greatly affect the spectral data of features acquired by the sensors. These factors together lead to the problem of distortion in the acquired satellite data, which has a significant impact on further applications. Therefore, the calibration process of satellite sensors has become a crucial step in satellite big data mining, which is defined as the establishment of a quantitative conversion relationship between the output value of the thermal remote sensor and the brightness value of the incident radiation. In order to ensure that the acquired data can truly reflect the changes in the ground features and to improve the quality and reliability of the data, the calibration has become an indispensable part of the satellite data application.
The traditional calibration methods are mainly divided into two categories: absolute radiometric calibration and relative radiometric calibration. Absolute radiometric calibration usually has to dispatch technicians to conduct field surveys for obtaining the surface reflectance during the satellite transit [
1]. Alternative methods involve using ground-based automatic station data. For example, Chen Y. et al. used ground-based automatic station data to realize the calibration of the MERSI-II sensors through the BRDF calibration [
2], and D. Rudolf et al. used Absolute radiometric calibration for the novel DLR “Kalibri” transponder [
3]. However, these methods are often time-consuming, labor-intensive and costly, and obtaining accurate reference data for historical datasets is challenging. Therefore, the relative radiometric calibration method is more commonly used nowadays. Relative radiometric calibration leverages the statistical characteristics of the pixel gray values within the image itself to establish a correction equation between the target image and a reference image, facilitating direct radiometric calibration [
4], which is more time-saving and labor-saving than the absolute radiometric calibration and can even yield superior results.
The concept of relative radiometric calibration is based on the assumption that the radiance response is linearly related to digital counts. The calibration process adjusts the gain of this linear response to match the radiance that would be consistent with the initial radiance if the Earth’s reflectance were constant. It assumes that at different times at the same place on the two images, the existence of invariant characteristics of the surface reflectance of the approximate linear changes, so to find out the invariant characteristics of the point for linear regression, this linear regression is the value of the ratio of the relative sensitivity coefficients of the two images. Then, the target image, by multiplying this ratio coefficient, can be realized by correcting the reference image, the process is called calibration. Relative radiometric calibration encompasses various methods, with one of the simplest being the histogram matching (HM) method. HM uses a statistical method to calculate the cumulative histogram of the original image and the reference image, followed by a matching transformation to align their hue contrasts, thereby correcting the target image to the reference image [
5]. Although this method is straightforward and user-friendly, its accuracy is often suboptimal. Schott and Salvaggio introduced the concept of pseudo-invariant features (PIFs) [
6] in 1988, selecting stable reflectance spectra features with minimal change over time as sample points for radiometric correction. However, manually selecting invariant feature points can be subjective, as these points are not truly invariant. However, the concept of no-change pixels (NCPs) opened the door to linear regression for relative radiometric calibration, and after that, Nielsen, Conradsen et al. proposed a novel method of multivariate alteration detection (MAD) [
7] by integrating the radiometric information of each spectral band through a statistical analysis. This approach reduced the influence of subjective judgment by utilizing a mathematical method of statistical analysis for NCP identification. Moreover, the authors enhanced their methodology by introducing a weighting coefficient and a loop, leading to the development of the iteratively reweighted multivariate alteration detection (IR-MAD) method [
8]. IR-MAD utilizes iterative reweighting, which updates the weight value of each pixel point. Large weights are assigned to observation points exhibiting minimal change over time. This is carried out until the correlation coefficient of the typical correlation analysis converges or is smaller than a certain threshold. The pixel point with the largest weight in the final result is selected as the stable pixel sample point detected in the image pair. Others are image regression (IR) [
9], dark setbright (DB) set normalization [
10] and no-change (NC) set radiometric normalization [
11]. Overall, traditional calibration methods typically require the identification of NCPs, presenting a considerable challenge in the calibration process. The initial phase involves eliminating subjectivity and thoroughly filtering the data to ensure consistency among the identified points. However, this process is inherently uncertain, lacking a definitive method for determining the number of points or establishing a standard threshold for identification.
With the rapid development of deep learning in recent years, many people have started to use neural networks in remote sensing, such as Velloso et al. for radiometric normalization of land cover change detection [
12] and G. Yang et al. for estimating sub-pixel temperature [
13], as opposed to the research on intelligent self-calibration, because the advantage of intelligent self-calibration is that it can bypass the identification of pseudo-invariant feature points and has a faster speed and less computational effort. Convolutional neural networks [
14], a powerful tool in the field of computer vision, have also achieved good results in the field of remote sensing, for example, mapping the continuous cover of invasive noxious weed species [
15], sea surface temperature reconstruction [
16] and GNSS deformation monitoring forecasting [
17]. Meanwhile, they also have applications in calibration. In the relative radiometric calibration method using the convolutional neural network proposed by Xutao Li et al. [
18], they directly try to use deep learning to solve the relative radiometric calibration of on-orbit satellites and solve the calibration task as an image classification problem in the field of computer vision. However, there are two primary weaknesses with this approach. Firstly, directly applying computer vision (CV) models for calibration is evidently insufficient. Calibration focuses on examining the relationship and differences between the reference image and the target image, which involves concatenating the two images along the channel dimension. In traditional CV tasks, channels typically represent RGB values, and the relationships between these channels are not closely related to calibration. Therefore, when designing deep-learning-based calibration methods, it is inadequate to directly transplant CV models. Instead, a new framework needs to be designed to assist the model in exploring the correlations between channels specifically for calibration purposes. Secondly, temporal information is critically important in calibration. Generally, the larger the time span between two images, the smaller the corresponding relative sensitivity coefficient. For deep learning, this temporal information is crucial for fitting the final labels. However, the previous work has not sufficiently investigated this aspect.
Therefore, we propose a relative radiometric calibration method using deep learning with a multi-task module. This method emphasizes the crucial temporal information in calibration by incorporating time as an auxiliary task within a multi-task module. Additionally, since the temporal information used is the time span between the reference and target images, the multi-task module can effectively focus on the correlations between the two images across different channels, aligning seamlessly with the specific calibration requirements. Finally, our experiments show that the framework surpasses state-of-the-art methods, validating the effectiveness of incorporating the time span as a task rather than merely a feature across various neural networks.
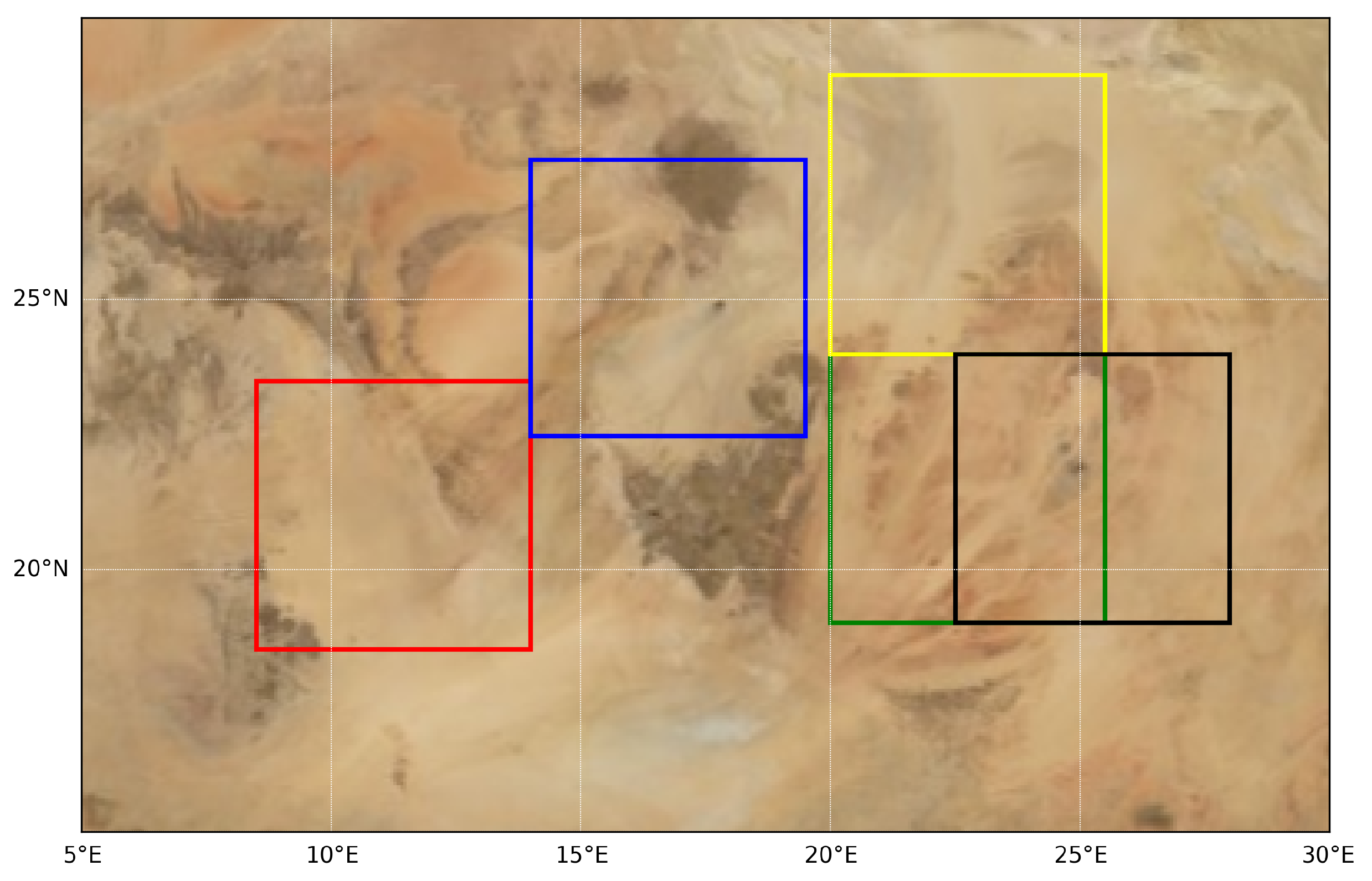
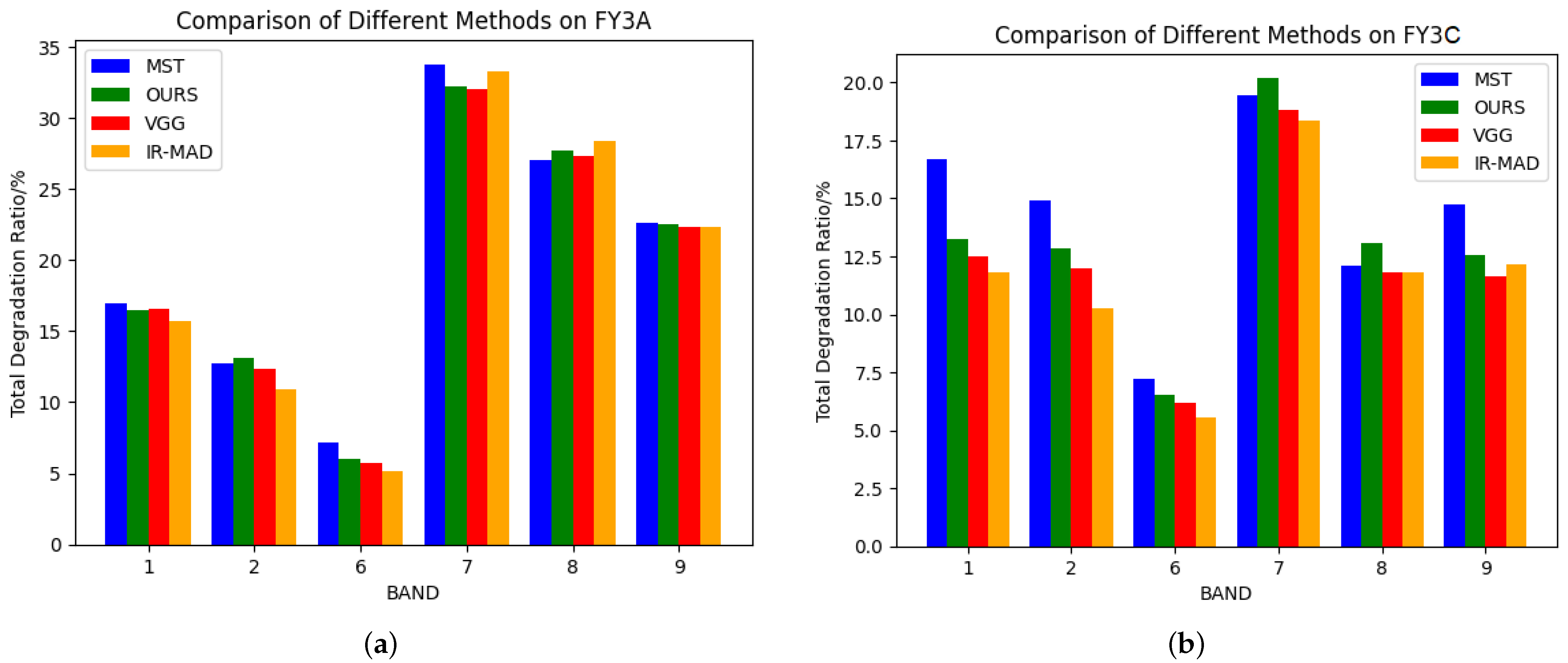
Figure 1 presents the calibration results visualized using multisite (MST) [
19] calibration, IR-MAD, VGG and our method. In summary, our contributions are as follows:
- 1.
We propose a time-based multi-task neural network framework for calibration, demonstrating broad applicability and compatibility with numerous CNN models, thereby enhancing the calibration results.
- 2.
We introduce time span information by using the interval between the reference image and the target image for calibration, effectively prompting the model to recognize the importance of temporal factors in determining the ratio coefficients.
- 3.
Leveraging the multi-task module and time information, our proposed approach achieves state-of-the-art performance on the VIRR sensor dataset from FY3A and FY3C satellites, with improvements of 9.38% for FY3A and 22.00% for FY3C compared to the current state-of-the-art methods.
2. Preliminary
The first step in the calibration process is to establish a conversion relationship between the raw satellite digital numbers (DNs) and the top of atmosphere (TOA) reflectance. This relationship is defined as follows:
where
is the TOA reflectance corresponding to channel
c, and
is the DN value of channel
c. Both
and
are the absolute calibration coefficients of channel
c prior to launch,
d is the Sun–Earth distance, and
is the solar zenith angle. With this formula, we can obtain the TOA reflectance for in-orbit calibration.
The calibration coefficients are divided into two categories: absolute calibration coefficients and relative calibration coefficients. The absolute calibration coefficients are the pre-launch calibration coefficients mentioned in the equation above. In contrast, relative calibration coefficients, which are the focus of this study, are used for in-orbit calibration to account for changes over time. Meanwhile, the sensitivity coefficient is the inverse of the correction coefficient. As mentioned above, the ultimate goal of calibration is to fit the ratio of the relative sensitivity coefficients of the two images. This is because there is such a relationship between the reference and target images and the relative sensitivity coefficients of both, shown as follows:
where
represents the NCPs on the image at times
and
for channel
c. The terms
and
denote the relative sensitivity coefficients corresponding to channel
c at times
and
. By applying certain transformations to Equation (
2), we derive Equation (
3), where
is the parameter we need to fit. This parameter is highly correlated with the sensitivity coefficient of the input image.
3. Proposed Method
In this section, we show the comprehensive model of a multi-task convolutional neural network based on temporal information. Our method bypasses the detection of NCPs by directly fitting the ratio coefficients , thereby avoiding the associated challenges and potential interferences. First, we introduce the overall architecture of the model, followed by detailed descriptions of the feature extraction module, the multi-task module and the composite loss computation within the multi-task module.
3.1. Overview of the Proposed Method
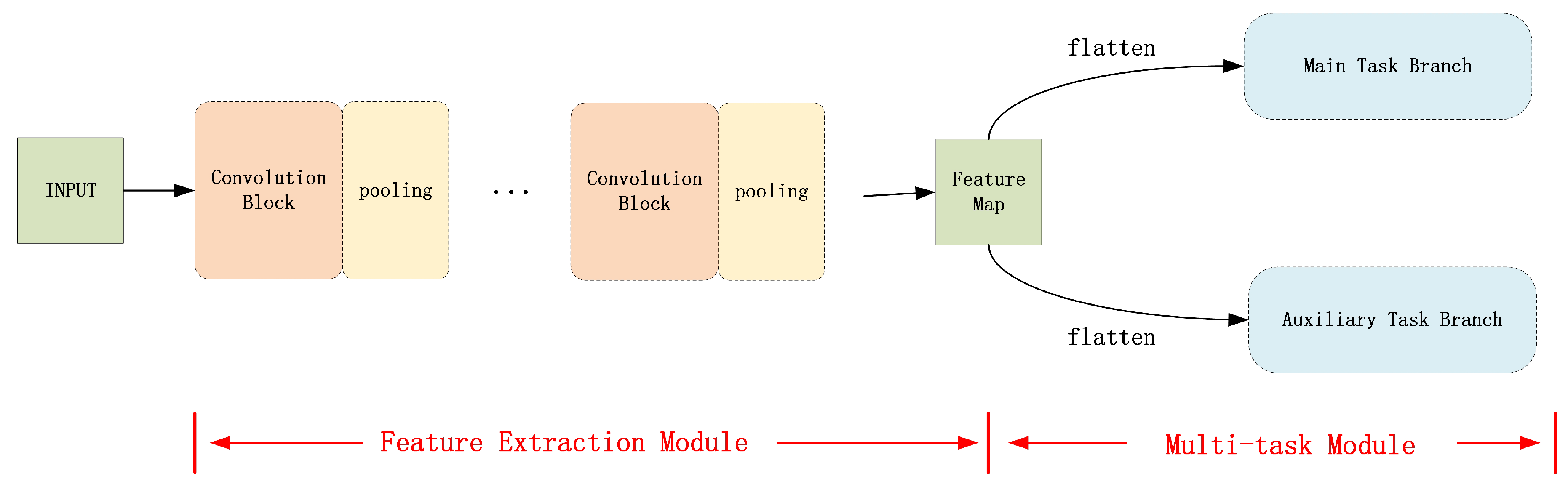
This section presents an overview of the network architecture, which comprises two primary modules: a feature extraction module and a multi-task module, shown in
Figure 2.
The feature extraction module, containing convolutional and pooling layers, extracts features from images, addressing the low resolution and redundant information typical of remote sensing images. Given that crucial information may be localized at the pixel level, the module effectively filters out redundant and extraneous features, retaining only those essential for accurate label fitting.
The multi-task module further facilitates label fitting. It takes the output of the feature extraction module, stretches it into vectors and fits the respective labels. Recognizing that fitting a single branch may not fully exploit the available information, a multi-task module is employed to indirectly support the main task fitting through auxiliary task branches. In this module, the feature extraction module is shared across tasks during backpropagation, facilitating parameter updates in two ways: primarily tuning for the main task and secondarily for the auxiliary tasks. By combining the losses from both tasks into a composite loss, this approach ensures the effective utilization of image information for fitting . Detailed explanations follow in the later subsections.
3.2. Feature Extraction Module
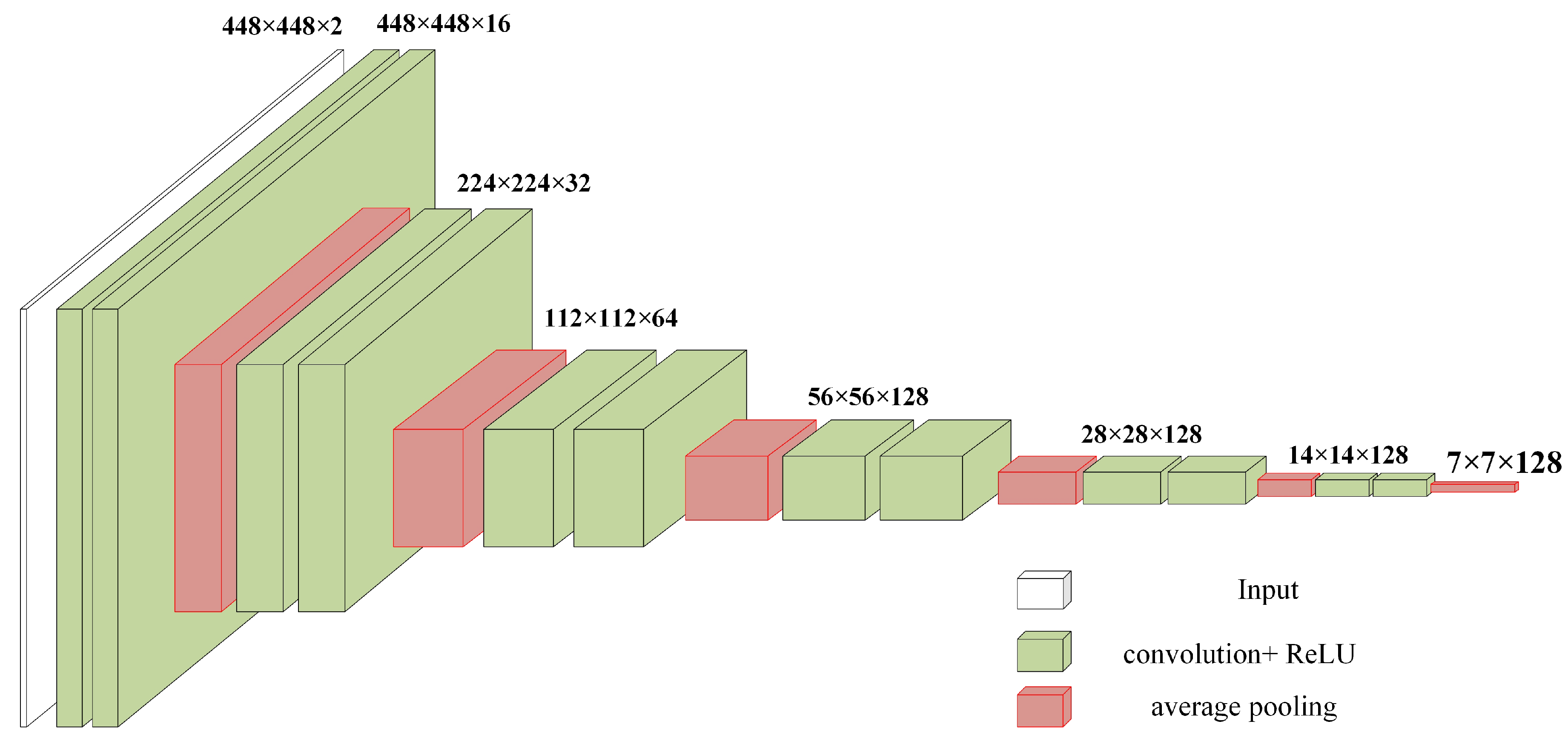
This paper introduces a feature extraction module inspired by a VGG-like network, as shown in
Figure 3, with detailed parameters listed in
Table 1. This module is an enhanced version of the VGG13 neural network [
20] and consists of 12 layers. Each convolutional block, made up of two identical convolutional layers, aims to extract features from images of the same size. Following each convolutional block is a pooling layer, which downsamples the image to compress and filter features while expanding the channels to minimize information loss from downsampling.
Given that the input is a remote sensing image where each pixel represents a 1.1 km × 1.1 km area, small pixels can contain substantial information. Therefore, a 3 × 3 convolution size is used for small-area convolution. This captures detailed information, thus preventing important information from being lost due to convolution. Furthermore, the rectified linear unit (ReLU) is chosen as the activation function. The feature map sizes change as follows: 448→224→112→56→28→14→7.
In contrast to the VGG13 network, which uses max pooling to capture prominent features, this module focuses on background features rather than texture details. The research by Bolei Zhou et al. [
21] demonstrated that average pooling has a localizable depth representation and is better at capturing deep details and background features. Therefore, average pooling is used for downsampling, positioned between two convolutional blocks as a downsampling transition layer. The channel variations are: 2→16→32→64→128→128→128.
3.3. Multi-Task Module
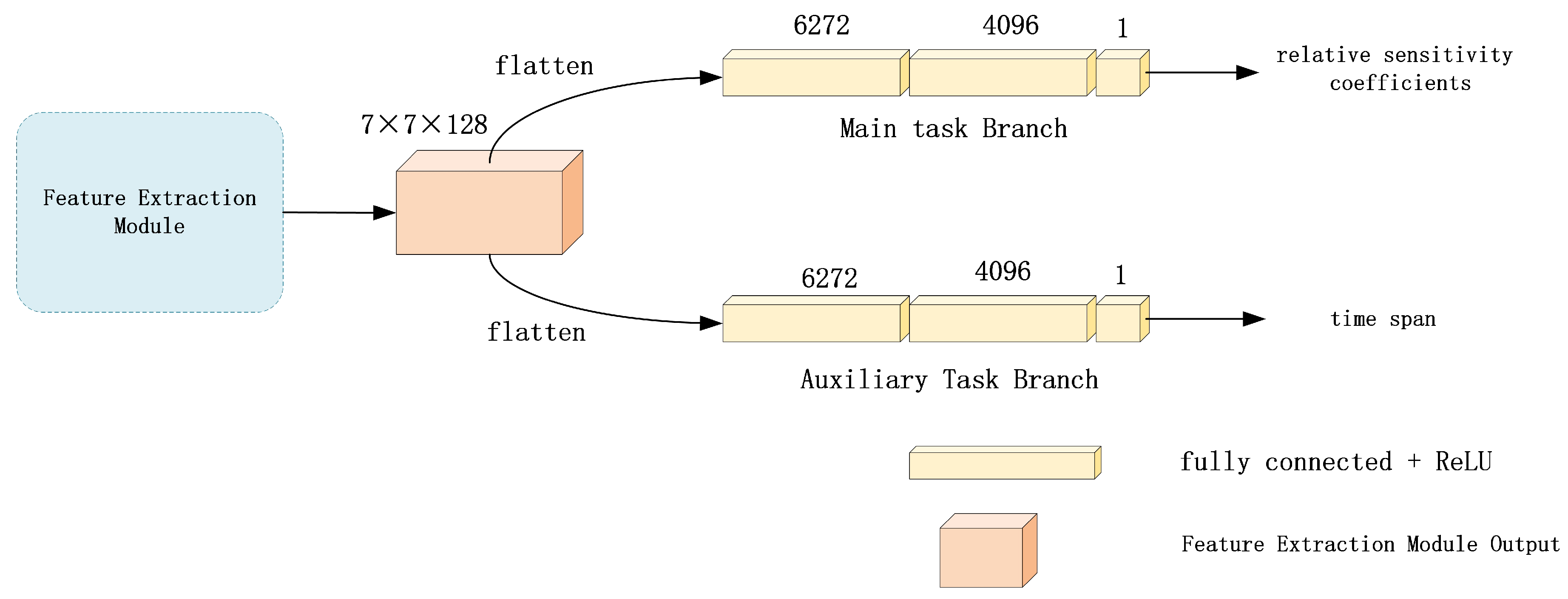
We propose a multi-task module based on time-assisted tasks to address the specific requirements of calibration. This module is illustrated in
Figure 4. It is well-known that the cornerstone of calibration is obtaining the ratio coefficient
. The primary goal of calibration is to correct images that have undergone degradation due to factors such as atmospheric changes, instrument aging, and varying lighting conditions over time. Consequently, we posit that time information is uniquely critical for accurately fitting
.
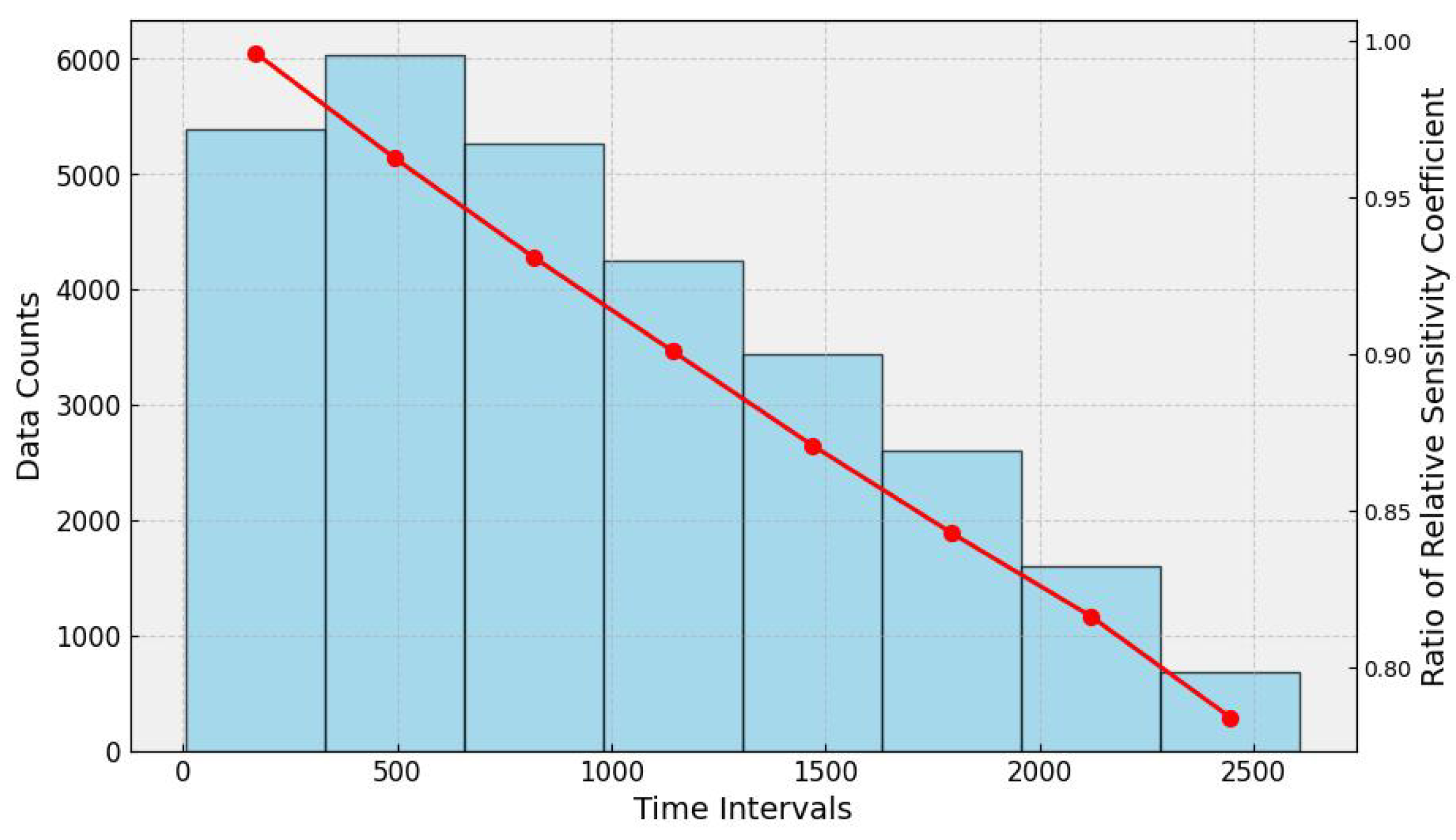
Generally, as the time span increases, image degradation becomes progressively more severe. The calibration process involves multiplying the ratio coefficient
by the target image, thereby aligning the target image with the reference image. This implies that over longer time spans, the relative sensitivity coefficient decreases, exhibiting a non-linear relationship. Therefore, the greater the time difference between the target image and the reference image, the smaller the ratio coefficient
. This relationship is evident in the multisite MST calibration results [
19], which also serve as the true values of the relative sensitivity coefficient used for training. This is shown in
Figure 5.
The integration of temporal information is a key innovation of this paper. Typically, temporal information is incorporated as a feature input. However, we argue that this approach can result in the loss of information during the convolution and pooling processes. This issue is particularly pronounced in deep learning, where the depth of neural networks can cause temporal information to become overshadowed by redundant features, potentially leading to its ablation within the network and resulting in suboptimal performance in the final fitting.
To address this, we have adopted a multi-task module that uses time as a label value for auxiliary tasks. By treating time as a label, it effectively permeates the entire network and influences the network’s adjustments during backpropagation. Consequently, this approach allows temporal information to be effectively used throughout the network, even for deep neural networks with deep hierarchies, and ensures that it does not interfere with the fitting of the main task through the clever design of the composite loss. Moreover, we have conducted extensive experiments to validate the advantages of our method, which are detailed in the experimental section.
The multi-task module we design for temporal information fusion leverages the output of the feature extraction module. Initially presented as a matrix, this output undergoes flattening into a vector. Subsequently, the module branches into two multi-task pathways: a shared backbone and two specialized branches. Both branches are fitted using three fully connected layers. The primary task branch focuses on fitting , while the auxiliary task branch fits the time span. This design ensures that temporal information is effectively integrated and leveraged throughout the entire network.
3.4. Composite Loss
In addition to task selection, multi-task training is crucial, and the configuration of the loss function is equally significant [
22]. In this paper, we design a multi-task architecture with hard parameter sharing and make specific adjustments to the loss computation. First, we introduce a learnable parameter to regulate the weights of the main task (
loss1) and the auxiliary task (
loss2) during the loss generation. Given the hierarchical nature of these tasks, this coefficient is set between 0.1 and 0.4 to ensure that the main task contributes more significantly to the final calculated loss, thereby biasing the network towards the main task. The network is thus optimized with a preference for the primary task. The specific formula is presented as follows:
where
is the loss of main task, and
is the loss of auxiliary task.
is a learnable parameter that takes values from 0.1 to 0.4. Finally,
is the composite loss.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}