
Snow Detection in Gaofen-1 Multi-Spectral Images Based on Swin-Transformer and U-Shaped Dual-Branch Encoder Structure Network with Geographic Information

 ,
,
Abstract
1. Introduction
- (a)
- Threshold rule-based methods: the fundamental principle of these methods is based on exploiting the disparities in the response of snow and other objects to electromagnetic waves across various sensor bands. Subsequently, specific computational indices are devised and suitable thresholds are established to detect snow by leveraging these disparities. For example, the Normalized Difference Snow Index (NDSI) [14,15], the Function of mask (Fmask) [16,17], and the let-it-snow (LIS) [18] are three classical threshold rule-based methods. Nevertheless, the thresholds in these methods are inevitably influenced by the characteristics of the ground objects [19,20,21], which may exhibit variability across different elevations, latitudes, and longitudes. Consequently, the effectiveness of these methods is restricted due to the ambiguity in selecting the optimal threshold, and the numerous demands for expert knowledge in image interpretation by professionals.
- (b)
- Machine learning methods: compared with the threshold rule-based methods, the machine learning methods [22,23,24,25,26], are more adept at capturing the shape, texture, context relationships, and other characteristics of snow, providing new insights for identifying snow more accurately. However, the early-developed machine learning methods are easily constrained by the classifier’s performance and the training parameter’s capacity [27], leaving ample opportunity to improve classification efficiency.
- (c)
- Deep learning methods: compared with machine learning methods, deep learning methods have the advantages of higher computing speed and accuracy. In 2015, Long [28] first proposed a fully convolutional neural network (FCN), a network replaced with the fully connected layer, to accomplish pixel-by-pixel image classification, also known as semantic segmentation. The success of this segmentation task has also established a solid basis for the advancement of subsequent segmentation. Convolutional Neural Networks (CNN) can automatically extract the local features from the images. In recent years, researchers have successfully achieved the segmentation of cloud and snow by using CNN. For example, Kai et al. [29] proposed a cloud and snow detection method based on ResNet50 and DeepLabV3+. The experimental results show that this method has low discrimination of cloud and snow and tends to misjudge them. Zhang et al. [30] suggested the CSDNet by fusing multi-scale features to detect clouds and snow in the CSWV dataset. However, the CSDNet is prone to omitting thin clouds and delicate snow coverage areas. Yin et al. [31] developed an enhanced U-Net3+ model incorporating the CBAM attention mechanism to extract cloud and snow from Gaofen-2 images. As a result, this approach still has the problem of confusing the cloud and snow. Lu et al. [32] employed green, red, blue, near-infrared, SWIR, and NDSI bands of Sentinel-2 images to construct 20 distinct three-channels DeepLabV3+ sub-models and then ensembled them to obtain the ultimate cloud and snow detection results, but it was still unable to distinguish the overlapping clouds and snow in high mountain areas. In addition to CNN, many researchers have applied Transformer to cloud and snow detection in remote-sensing images in recent years. With the successful application of Transformer [33] in the field of natural language processing, researchers have developed Vision Transformer (ViT) [34], which is specifically devised for computer vision tasks due to its robust feature extraction capability. The multi-head attention mechanism of ViT enables it to not only perceive local regional information but also engage with global information. Hu et al. [35] proposed the improved ViT as an encoder in the multi-branch convolutional attention network (MCANet) to better separate cloud and snow boundaries compared to a single CNN in WorldView2 images. Still, it is easy to miss thin snow. Ma et al. [36] suggested the UCTNet, a model constructed by CNN and ViT for the semantic segmentation of cloud and snow in Sentinel-2 images. They obtained a higher Mean Intersection over Union (MIoU) score than the CNN. Nevertheless, the network with ViT has demonstrated superior performance in cloud and snow extraction compared to a standalone CNN. It also results in a significant requirement in the number of training parameters and datasets, posing a considerable challenge regarding computational resources [34]. In 2021, the Microsoft Research Institute released Swin Transformer (Swin-T) [37]. Swin-T adopts a hierarchical modeling method similar to CNN to carry out feature downsampling and utilizes Window Multi-head Self-attention (W-MSA) and Shifted Window Multi-head Self-attention (SW-MSA) [37] to facilitate the interaction of feature information across different windows and enable parallel processing of global information extraction, which effectively reduces parameters and accelerates computation speed in comparison to ViT. It has achieved remarkable results on large-scale datasets and has been extensively utilized.
- (1)
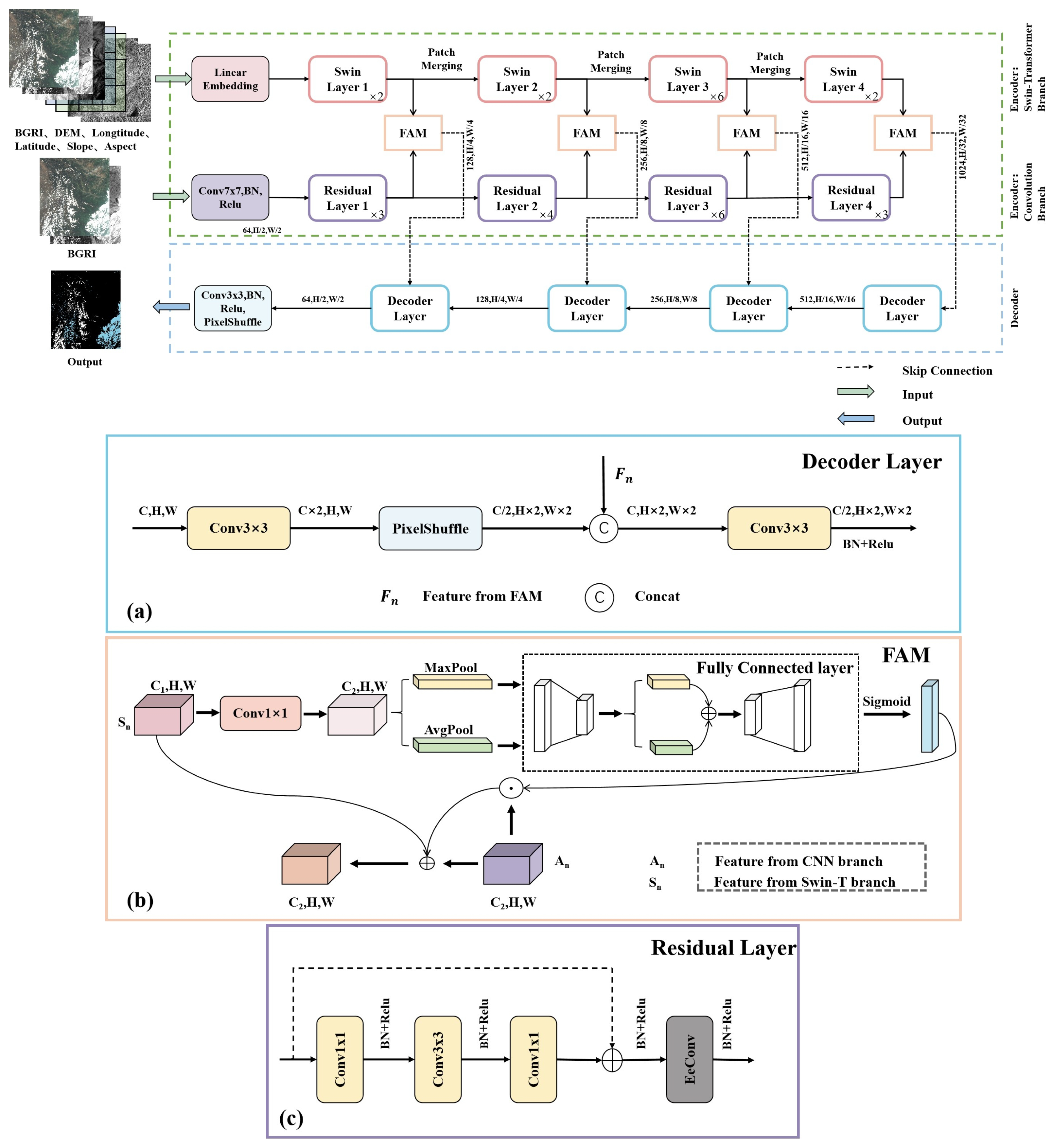
- A dual-branch network SD-GeoSTUNet is proposed to solve the challenge of snow detection in Gaofen-1 satellite images, which are limited in their application for snow detection due to the lack of a 1.6 µm shortwave infrared band.
- (2)
- This paper maximally integrates the feature information extracted via the dual branches by designing a new Feature Aggregation Module (FAM), which can not only strengthen the learning and utilization of global features but also enhance the network’s capacity for representation.
- (3)
- This paper discriminates the cloud and snow boundaries more accurately by using a difference convolution module named EeConv to extract high-frequency boundary information.
- (4)
- Considering the impact of two important geographical factors, slope and aspect, on the spatial distribution pattern of snow, this paper explores their potential as auxiliary information in deep learning and accomplishes the purpose of improving the accuracy of snow detection in mountainous regions, which which is often easy to be ignored in deep learning.
2. Methodology
2.1. Network Architecture
2.2. Feature Aggregation Module (FAM)
2.3. Residual Layer Embedded with EeConv
2.4. Experiment Settings
2.5. Evaluation Metrics
3. Data
3.1. Data Introduction
3.2. Data Preprocessing
4. Results
4.1. Ablation Experiment
4.1.1. Ablation Experiment of Network Structure and Module Components
4.1.2. Ablation Experiment of Geographic Information
4.2. Comparative Experiment
4.2.1. Accuracy Evaluation
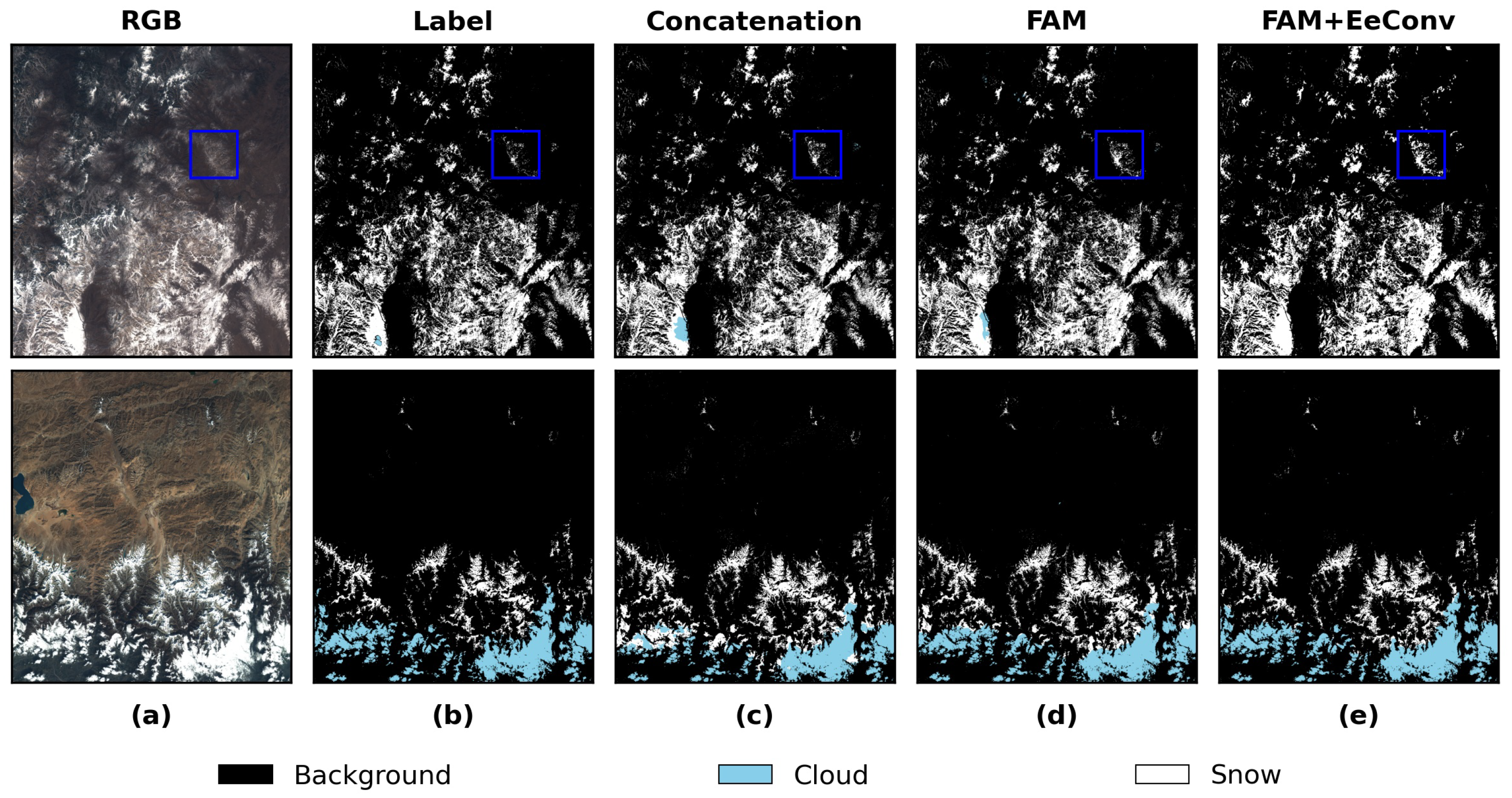
4.2.2. Visualization Results
5. Discussion
6. Conclusions
- (1)
- The respective advantages of CNN and Swin-T in feature extraction are combined by a dual-branch encoder structure in parallel. By concatenating the dual-branch features along channels, the MPA reached 91.24%, which is 0.95% higher than the best performance of the single-branch network. SD-GeoSTUNet can deeply extract the detailed information between the features by combining the CNN and Swin-T through FAM and reserving the high-frequency edge information by EeConv.
- (2)
- The SD-GeoSTUNet model improves when encoding altitude, longitude, and latitude with the remote sensing image’s BGRI. Furthermore, encoding the slope and aspect further improves the snow detection performance in hillside and valley areas.
- (3)
- Compared with other existing CNN framework models or transformer framework models, SD-GeoSTUNet shows the best cloud and snow detection performance, with more clear and accurate detection results and the least thin cloud and snow omission, and achieves the highest , , , , and , which are 90.37%, 78.08%, 95.25%, 85.07%, and 92.89%, respectively, outperform other models profoundly.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, T. Influence of the seasonal snow cover on the ground thermal regime: An overview. Rev. Geophys. 2005, 43, 1–23. [Google Scholar] [CrossRef]
- Zhang, Y. Multivariate Land Snow Data Assimilation in the Northern Hemisphere: Development, Evaluation and Uncertainty Quantification of the Extensible Data Assimilation System. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2015. [Google Scholar]
- Wijngaard, R.R.; Biemans, H.; Lutz, A.F.; Shrestha, A.B.; Wester, P.; Immerzeel, W. Climate change vs. socio-economic development: Understanding the future South Asian water gap. Hydrol. Earth Syst. Sci. 2018, 22, 6297–6321. [Google Scholar] [CrossRef]
- Barnett, T.P.; Adam, J.C.; Lettenmaier, D.P. Potential impacts of a warming climate on water availability in snow-dominated regions. Nature 2005, 438, 303–309. [Google Scholar] [CrossRef]
- Kraaijenbrink, P.D.A.; Stigter, E.E.; Yao, T.; Immerzeel, W.W. Climate change decisive for Asia’s snow meltwater supply. Nat. Clim. Chang. 2021, 11, 591–597. [Google Scholar] [CrossRef]
- Morin, S.; Samacoïts, R.; François, H.; Carmagnola, C.M.; Abegg, B.; Demiroglu, O.C.; Pons, M.; Soubeyroux, J.M.; Lafaysse, M.; Franklin, S.; et al. Pan-European meteorological and snow indicators of climate change impact on ski tourism. Clim. Serv. 2021, 22, 100215. [Google Scholar] [CrossRef]
- Deng, G.; Tang, Z.; Hu, G.; Wang, J.; Sang, G.; Li, J. Spatiotemporal dynamics of snowline altitude and their responses to climate change in the Tienshan Mountains, Central Asia, During 2001–2019. Sustainability 2021, 13, 3992. [Google Scholar] [CrossRef]
- Ayub, S.; Akhter, G.; Ashraf, A.; Iqbal, M. Snow and glacier melt runoff simulation under variable altitudes and climate scenarios in Gilgit River Basin, Karakoram region. Model. Earth Syst. Environ. 2020, 6, 1607–1618. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, X.; Deng, G.; Wang, X.; Jiang, Z.; Sang, G. Spatiotemporal variation of snowline altitude at the end of melting season across High Mountain Asia, using MODIS snow cover product. Adv. Space Res. 2020, 66, 2629–2645. [Google Scholar] [CrossRef]
- Huang, N.; Shao, Y.; Zhou, X.; Fan, F. Snow and ice disaster: Formation mechanism and control engineering. Front. Earth Sci. 2023, 10, 1019745. [Google Scholar] [CrossRef]
- Tsai, Y.L.S.; Dietz, A.; Oppelt, N.; Kuenzer, C. Remote sensing of snow cover using spaceborne SAR: A review. Remote Sens. 2019, 11, 1456. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, J.; Li, H.; Liang, J.; Li, C.; Wang, X. Extraction and assessment of snowline altitude over the Tibetan plateau using MODIS fractional snow cover data (2001 to 2013). J. Appl. Remote Sens. 2014, 8, 084689. [Google Scholar] [CrossRef]
- Wang, J.; Tang, Z.; Deng, G.; Hu, G.; You, Y.; Zhao, Y. Landsat satellites observed dynamics of snowline altitude at the end of the melting season, Himalayas, 1991–2022. Remote Sens. 2023, 15, 2534. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A.; Salomonson, V.V. Development of methods for mapping global snow cover using moderate resolution imaging spectroradiometer data. Remote Sens. Environ. 1995, 54, 127–140. [Google Scholar] [CrossRef]
- Hall, D.K.; Riggs, G.A.; Salomonson, V.V.; DiGirolamo, N.E.; Bayr, K.J. MODIS snow-cover products. Remote Sens. Environ. 2002, 83, 181–194. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Gascoin, S.; Grizonnet, M.; Bouchet, M.; Salgues, G.; Hagolle, O. Theia Snow collection: High-resolution operational snow cover maps from Sentinel-2 and Landsat-8 data. Earth Syst. Sci. Data 2019, 11, 493–514. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Li, H.; Hao, X. Combination of NDSI and NDFSI for snow cover mapping in a mountainous and forested region. Natl. Remote. Sens. Bull. 2017, 21, 310–317. [Google Scholar] [CrossRef]
- Wang, L.; Chen, Y.; Tang, L.; Fan, R.; Yao, Y. Object-based convolutional neural networks for cloud and snow detection in high-resolution multispectral imagers. Water 2018, 10, 1666. [Google Scholar] [CrossRef]
- Deng, G.; Tang, Z.; Dong, C.; Shao, D.; Wang, X. Development and Evaluation of a Cloud-Gap-Filled MODIS Normalized Difference Snow Index Product over High Mountain Asia. Remote Sens. 2024, 16, 192. [Google Scholar] [CrossRef]
- Li, P.F.; Dong, L.M.; Xiao, H.C.; Xu, M.L. A cloud image detection method based on SVM vector machine. Neurocomputing 2015, 169, 34–42. [Google Scholar] [CrossRef]
- Ishida, H.; Oishi, Y.; Morita, K.; Moriwaki, K.; Nakajima, T.Y. Development of a support vector machine based cloud detection method for MODIS with the adjustability to various conditions. Remote Sens. Environ. 2018, 205, 390–407. [Google Scholar] [CrossRef]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-Use Methods for the Detection of Clouds, Cirrus, Snow, Shadow, Water and Clear Sky Pixels in Sentinel-2 MSI Images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef]
- Ghasemian, N.; Akhoondzadeh, M. Introducing two Random Forest based methods for cloud detection in remote sensing images. Adv. Space Res. 2018, 62, 288–303. [Google Scholar] [CrossRef]
- Tuia, D.; Kellenberger, B.; Pérez-Suey, A.; Camps-Valls, G. A deep network approach to multitemporal cloud detection. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4351–4354. [Google Scholar]
- Han, W.; Zhang, X.H.; Wang, Y.; Wang, L.Z.; Huang, X.H.; Li, J.; Wang, S.; Chen, W.T.; Li, X.J.; Feng, R.Y.; et al. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities. Isprs J. Photogramm. Remote Sens. 2023, 202, 87–113. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zheng, K.; Li, J.; Yang, J.; Ouyang, W.; Wang, G.; Zhang, X. A cloud and snow detection method of TH-1 image based on combined ResNet and DeeplabV3+. Acta Geod. Et Cartogr. Sin. 2020, 49, 1343. [Google Scholar]
- Zhang, G.B.; Gao, X.J.; Yang, Y.W.; Wang, M.W.; Ran, S.H. Controllably Deep Supervision and Multi-Scale Feature Fusion Network for Cloud and Snow Detection Based on Medium- and High-Resolution Imagery Dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]
- Yin, M.J.; Wang, P.; Ni, C.; Hao, W.L. Cloud and snow detection of remote sensing images based on improved Unet3+. Sci. Rep. 2022, 12, 14415. [Google Scholar] [CrossRef]
- Lu, Y.; James, T.; Schillaci, C.; Lipani, A. Snow detection in alpine regions with Convolutional Neural Networks: Discriminating snow from cold clouds and water body. GIScience Remote Sens. 2022, 59, 1321–1343. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. Mcanet: A multi-branch network for cloud/snow segmentation in high-resolution remote sensing images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Ma, J.; Shen, H.; Cai, Y.; Zhang, T.; Su, J.; Chen, W.H.; Li, J. UCTNet with dual-flow architecture: Snow coverage mapping with Sentinel-2 satellite imagery. Remote Sens. 2023, 15, 4213. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Wang, Y.; Su, J.; Zhai, X.; Meng, F.; Liu, C. Snow Coverage Mapping by Learning from Sentinel-2 Satellite Multispectral Images via Machine Learning Algorithms. Remote Sens. 2022, 14, 782. [Google Scholar] [CrossRef]
- Guo, J.; Yang, J.; Yue, H.; Tan, H.; Hou, C.; Li, K. CDnetV2: CNN-based cloud detection for remote sensing imagery with cloud-snow coexistence. IEEE Trans. Geosci. Remote Sens. 2020, 59, 700–713. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Coexisting cloud and snow detection based on a hybrid features network applied to remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5405515. [Google Scholar] [CrossRef]
- Kormos, P.R.; Marks, D.; McNamara, J.P.; Marshall, H.P.; Winstral, A.; Flores, A.N. Snow distribution, melt and surface water inputs to the soil in the mountain rain-snow transition zone. J. Hydrol. 2014, 519, 190–204. [Google Scholar] [CrossRef]
- Hartman, M.D.; Baron, J.S.; Lammers, R.B.; Cline, D.W.; Band, L.E.; Liston, G.E.; Tague, C. Simulations of snow distribution and hydrology in a mountain basin. Water Resour. Res. 1999, 35, 1587–1603. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z.W.; Zou, Z.X. A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection. Isprs J. Photogramm. Remote Sens. 2021, 174, 87–104. [Google Scholar] [CrossRef]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. pp. 234–241. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. pp. 818–833. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Wang, C.; Shen, H.Z.; Fan, F.; Shao, M.W.; Yang, C.S.; Luo, J.C.; Deng, L.J. EAA-Net: A novel edge assisted attention network for single image dehazing. Knowl.-Based Syst. 2021, 228, 107279. [Google Scholar] [CrossRef]
- Yu, Z.; Zhao, C.; Wang, Z.; Qin, Y.; Su, Z.; Li, X.; Zhou, F.; Zhao, G. Searching central difference convolutional networks for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5295–5305. [Google Scholar]
- PyTorch. Available online: https://pytorch.org/ (accessed on 10 November 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Jarvis, A.; Guevara, E.; Reuter, H.; Nelson, A. Hole-Filled SRTM for the Globe: Version 4: Data Grid. 2008. Available online: http://srtm.csi.cgiar.org/ (accessed on 10 November 2023).
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Xie, E.Z.; Wang, W.H.; Yu, Z.D.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Kirkwood, C.; Economou, T.; Pugeault, N.; Odbert, H. Bayesian deep learning for spatial interpolation in the presence of auxiliary information. Math. Geosci. 2022, 54, 507–531. [Google Scholar] [CrossRef]
- Tie, R.; Shi, C.; Li, M.; Gu, X.; Ge, L.; Shen, Z.; Liu, J.; Zhou, T.; Chen, X. Improve the downscaling accuracy of high-resolution precipitation field using classification mask. Atmos. Res. 2024, 310, 107607. [Google Scholar] [CrossRef]
- Yue, S.; Che, T.; Dai, L.; Xiao, L.; Deng, J. Characteristics of snow depth and snow phenology in the high latitudes and high altitudes of the northern hemisphere from 1988 to 2018. Remote Sens. 2022, 14, 5057. [Google Scholar] [CrossRef]
- Tang, Z.; Wang, X.; Wang, J.; Wang, X.; Li, H.; Jiang, Z. Spatiotemporal variation of snow cover in Tianshan Mountains, Central Asia, based on cloud-free MODIS fractional snow cover product, 2001–2015. Remote Sens. 2017, 9, 1045. [Google Scholar] [CrossRef]
- Zhu, L.; Xiao, P.; Feng, X.; Zhang, X.; Huang, Y.; Li, C. A co-training, mutual learning approach towards mapping snow cover from multi-temporal high-spatial resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2016, 122, 179–191. [Google Scholar] [CrossRef]
- Tang, Z.; Deng, G.; Hu, G.; Zhang, H.; Pan, H.; Sang, G. Satellite observed spatiotemporal variability of snow cover and snow phenology over high mountain Asia from 2002 to 2021. J. Hydrol. 2022, 613, 128438. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source | Wavelength (µm) |
|---|---|---|
| B | remote sensing image’s blue band [44] | 0.45~0.52 |
| G | remote sensing image’s green band [44] | 0.52~0.59 |
| R | remote sensing image’s red band [44] | 0.63~0.69 |
| I | remote sensing image’s near-infrared band [44] | 0.77~0.89 |
| DEM [44] | / | |
| Calculate from remote sensing image’s projection | / | |
| Calculate from remote sensing image’s projection | / | |
| Calculate from DEM | / | |
| Calculate from DEM | / |
| Name | IoU_c | IoU_s | F1_c | F1_s | MPA |
|---|---|---|---|---|---|
| CNN | 85.31% | 74.63% | 91.69% | 81.51% | 89.86% |
| Swin-T | 87.84% | 75.74% | 92.77% | 83.01% | 90.29% |
| CNN+Swin-T (Concatenation) | 88.75% | 76.36% | 93.85% | 83.93% | 91.24% |
| CNN+Swin-T+FAM | 89.63% | 77.25% | 94.67% | 84.69% | 92.01% |
| CNN+Swin-T+FAM+EeConv (SD-GeoSTUNet) | 90.37% | 78.08% | 95.25% | 85.07% | 92.89% |
| BGRI | IoU_c | IoU_s | F1_c | F1_s | MPA | ||
|---|---|---|---|---|---|---|---|
| ✓ | 88.57% | 77.14% | 93.98% | 83.91% | 91.10% | ||
| ✓ | ✓ | 90.02% | 78.22% | 94.61% | 85.26% | 93.01% | |
| ✓ | ✓ | ✓ | 90.37% | 78.08% | 95.25% | 85.07% | 92.89% |
| Model | IoU_c | IoU_s | F1_c | F1_s | MPA | Parameter (M) |
|---|---|---|---|---|---|---|
| PSPNet 1 | 85.57% | 74.37% | 89.87% | 81.20% | 85.25% | 65.703 |
| U-Net 2 | 88.76% | 77.08% | 93.17% | 83.89% | 91.29% | 17.267 |
| GeoInfoNet 3 | 89.74% | 77.81% | 94.78% | 84.69% | 92.14% | 29.324 |
| CDNetV2 4 | 89.01% | 77.45% | 94.08% | 84.53% | 91.68% | 67.677 |
| Segformer 5 | 87.99% | 75.99% | 92.98% | 83.04% | 90.32% | 84.614 |
| SD-GeoSTUNet | 90.37% | 78.08% | 95.25% | 85.07% | 92.89% | 77.749 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Shi, C.; Shen, R.; Gu, X.; Tie, R.; Ge, L.; Sun, S. Snow Detection in Gaofen-1 Multi-Spectral Images Based on Swin-Transformer and U-Shaped Dual-Branch Encoder Structure Network with Geographic Information. Remote Sens. 2024, 16, 3327. https://doi.org/10.3390/rs16173327
Wu Y, Shi C, Shen R, Gu X, Tie R, Ge L, Sun S. Snow Detection in Gaofen-1 Multi-Spectral Images Based on Swin-Transformer and U-Shaped Dual-Branch Encoder Structure Network with Geographic Information. Remote Sensing. 2024; 16(17):3327. https://doi.org/10.3390/rs16173327
Chicago/Turabian StyleWu, Yue, Chunxiang Shi, Runping Shen, Xiang Gu, Ruian Tie, Lingling Ge, and Shuai Sun. 2024. "Snow Detection in Gaofen-1 Multi-Spectral Images Based on Swin-Transformer and U-Shaped Dual-Branch Encoder Structure Network with Geographic Information" Remote Sensing 16, no. 17: 3327. https://doi.org/10.3390/rs16173327
APA StyleWu, Y., Shi, C., Shen, R., Gu, X., Tie, R., Ge, L., & Sun, S. (2024). Snow Detection in Gaofen-1 Multi-Spectral Images Based on Swin-Transformer and U-Shaped Dual-Branch Encoder Structure Network with Geographic Information. Remote Sensing, 16(17), 3327. https://doi.org/10.3390/rs16173327