1. Introduction
Hyperspectral imaging (HSI) creates hundreds of tiny spectral bands using specialized sensors and a large portion of the electromagnetic spectrum [
1], which may be used to analyze data about objects and landscapes. HSI methods have grown rapidly with the development of remote sensing techniques. They typically cover the visible to infrared response range and offer more common spectral data than the other types of images for improved material component characterization. By capturing reflections from hundreds of distinct electromagnetic spectrum bands, a hyperspectral image may be created [
2,
3]. The target’s detection efficiency and ability to blend in with the background can be significantly enhanced by incorporating the difference between the target and background in high-dimensional space into the evaluation system for camouflage efficacy [
4,
5] using HSI technology.
Hyperspectral remote sensing (HSRS) has been one of these remote sensing technologies that has grown steadily due to its effectiveness. Typically, HSRS equipment is operated from an aerial platform [
6,
7]. Following the capture of the image, a cube of data (hypercube) including spectral and spatial data emerges. The resolution along with the number of bands in the image make up the data cube’s dimensions [
8]. A vector of reflections within each electromagnetic band corresponds to each pixel within a hyperspectral image. This vector also conveys a spectral characteristic for each pixel within the hypercube [
9]. In order to create a hyperspectral cube, one can use one of four techniques: spectral scanning, spatial–spectral scanning, snapshot hyperspectral imaging or spatial scanning [
10]. However, because of thermal electronics and dark current, HSI is quickly impacted by undesirable components like noise [
11] such as impulse noise, Gaussian noise and sparse noise. These inevitable noise corruptions affect the visual quality of the images. The task of removing the HSI noise [
12] has become a very relevant research topic in recent years. HSI compression involves taking an input to reduce the volume of data to be transmitted. In particular, compression [
13] reduces the dimensionality in a way that enables the perfect reconstruction of the original scenes. Deep learning network-based compression [
14] methods are seen as very useful due to their learning abilities and capacity for noise reduction. Some of the models showing HSI denoising [
15] and compression are discussed below. Kong, X. et al. [
16] presented a novel tensor-based HSI denoising approach by fully identifying the intrinsic structures of the clean HSI and the noise. Specifically, the HSI is first divided into local overlapping full-band patches, then the nonlocal similar patches in each group are unfolded and stacked into a new third order tensor. This method is designed to model the spatial–spectral nonlocal self-similarity and global spatial–spectral smoothness simultaneously. This work concentrated more on spectral–spatial smoothing than on noise suppression. Y.Q. Zhao et al. [
17] proposed a HSI denoising method by jointly utilizing the global and local redundancy and correlation (RAC) in spatial/spectral domains. First, sparse coding is exploited to model the global RAC in the spatial domain and local RAC in the spectral domain. Noise can be removed by sparse approximated data with a learned dictionary. This work faced a major disadvantage of poor denoising performance at stronger noise levels.
Zhao, S et al. [
18] explained a spatial–spectral interactive restoration (SSIR) framework by utilizing the complementarity of model-based and data-driven methods. Specifically, a deep learning-based denoising module that includes both convolutional neural networks (CNN) and Swin Transformer (TF) blocks is described. Though the analysis showed better results, the performance of the model is limited to specific types of data. Wang, P et al. [
19] proposed a denoising method for HSI based on deep learning and a total variation (TV) prior. The method minimizes the first-order moment distance between the deep prior of a fast and flexible denoising convolutional neural network (FFDNet) and the enhanced 3D TV (E3DTV) prior, obtaining dual priors that complement and reinforce each other’s advantages. The work demonstrated significant advantages compared to existing methods in quantitative and qualitative analysis and effectively enhanced the quality of HSIs. The work lacked detailed analysis of more quantitative metrics. Accessible model-based approaches depend significantly on carefully selected priors, computationally intensive iterative optimization, and meticulous hyperparameter adjustment in order to produce effective models [
20,
21]. The visual quality of the HSI is impacted by this noise, which also reduces precision in band selection and classification [
22,
23]. Mohan et al. [
24] proposed a new and successful methodology for denoising, compressing and reconstructing HSI. For denoising, the SqueezeNet model is trained on noisy images and tested in BGU-ICVL dataset. The denoised images were delivered into the tunable spectral filter (TSF) algorithm for compression. The compressed images were passed into dense attention net (DAN) for reconstruction by reverse dual level prediction operation. However, the model’s performance is not particularly spectacular. No proper tuning of hyperparameters and increased training time for compression were the major limitations of this model.
Peng et al. [
25] suggested an enhanced 3D TV (E-3DTV) regularization term used for image compression and denoising. E-3DTV can determine sparsity based on subspace support on gradient maps along all bands in an HSI. The algorithm was tested on the Indian Pines dataset which naturally produces the correlation and difference between all of these bands, which is how they accurately showed the insightful configurations of an HSI. Large HSI images were not compressed properly using this model. An alternate method for HSI compression was presented by Deng et al. [
26] using a generative neural network (GNN), which derives the probability distribution for the actual data using random latent coding. The complexity of the GNN determines the compression ratio and the well-trained network serves as a representation of the HSI. However, the model takes a lot of time and its overall performance due to GNN is assigned to a limited set of points only.
In order to integrate a convolutional neural network (CNN) with a transformer for hyperspectral image (HSI) denoising, Pang et al. [
27] developed a novel deep neural network called TRQ3DNet. Two different branches, namely 3D quasi-recurrent blocks and U-former blocks, were used in this network. The initial version was built on a 3D quasi-recurrent block that included convolution and a quasi-recurrent pooling functioning, which assisted in extracting both local as well as global spatial correlations throughout the spectrum. The U-former block is present in the second branch and is used to take use of the global spatial characteristics. However, compared to other models, the validation approach is poor and the model required more time to execute. A spectrum signal compressor utilizing the deep convolutional autoencoder (SSCNet) was created by La Grassa et al. [
28], which also examined the learning process and evaluated the compression and spectral signal reconstruction. However, while using this technique, the image characteristics will be lost. H. Pan et al. [
29] studied denoising using adaptive fusion network where they designed a coattention fusion module to adaptively collect informative features from multiple scales, and thereby enhance the differential learning capability for denoising.
The detailed review of related works pointed out that the existing denoising models struggle to include the contextual information while preserving the spectral and spatial information. Image details from different scales could not ensure flexible exchange of information. Also, the existing denoising techniques have limitations due to the variations in data acquisition methods, resulting in local distortion of HSIs. The discussed traditional HSI compression algorithms consider the characteristics of HSI in all aspects, but due to the iterative methods used, the computational complexity is high and the compression quality is poor. To solve the aforementioned issues, we propose an image denoising model using an adaptive fusion network and a compression model which uses an optimized deep learning technique called "chaotic Chebyshev artificial hummingbird optimization algorithm-based bidirectional gated recurrent unit."
The major contributions of the work are as follows:
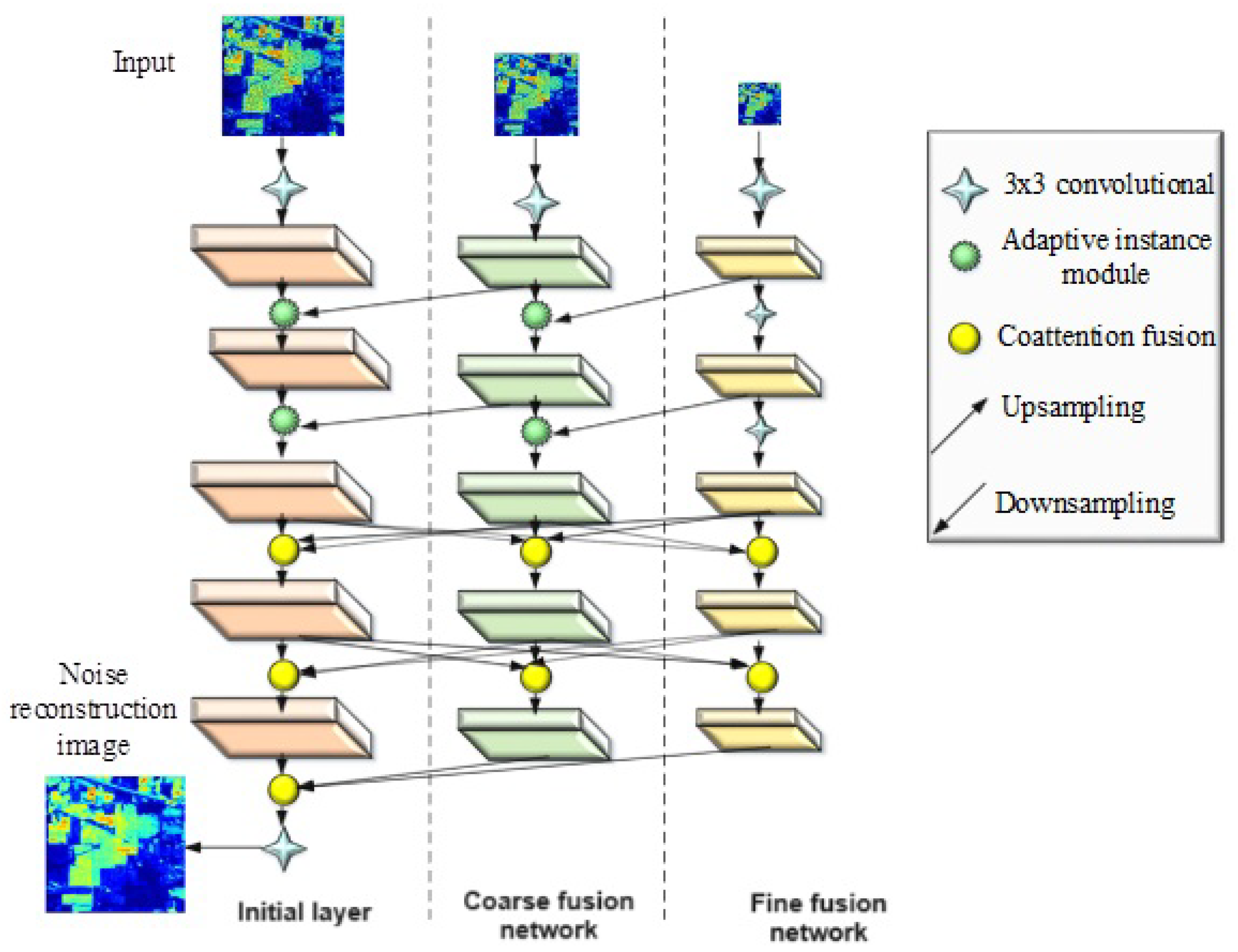
Creating an effective framework for HSI denoising using an improved adaptive fusion network which helps to learn the complex nonlinear mapping between noise-free and noisy HSI for obtaining the denoised images.
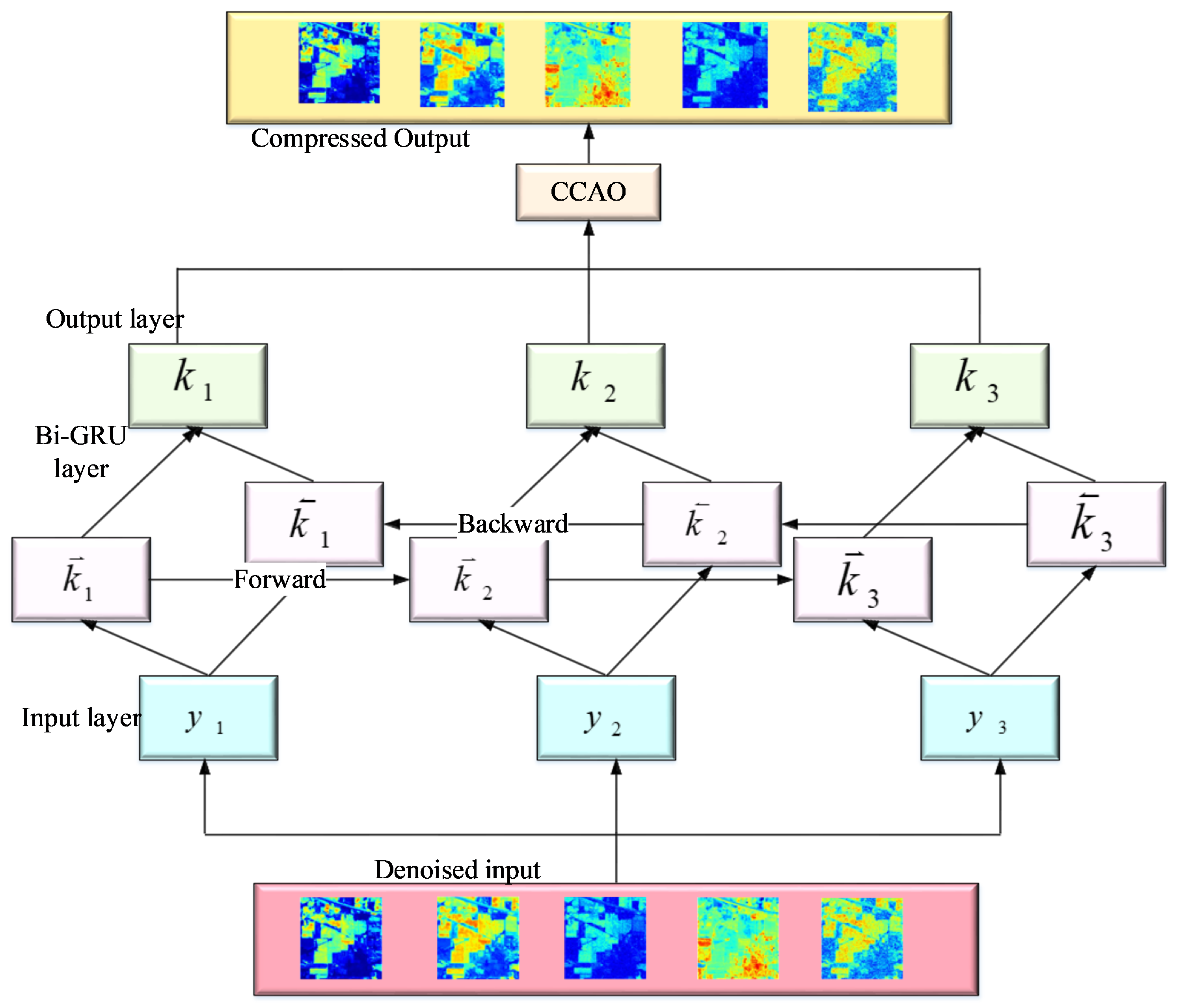
Presenting a model to compress the denoised image using the chaotic Chebyshev artificial hummingbird optimization algorithm-based bidirectional gated recurrent unit (CCAO-BiGRU) technique. The hyperparameters in the model have been tuned by the optimization algorithm.
Extending evaluations of the proposed study in terms of quantitative and qualitative analysis to prove the performance compared to the other existing state-of-the-arts methods.
4. Discussion
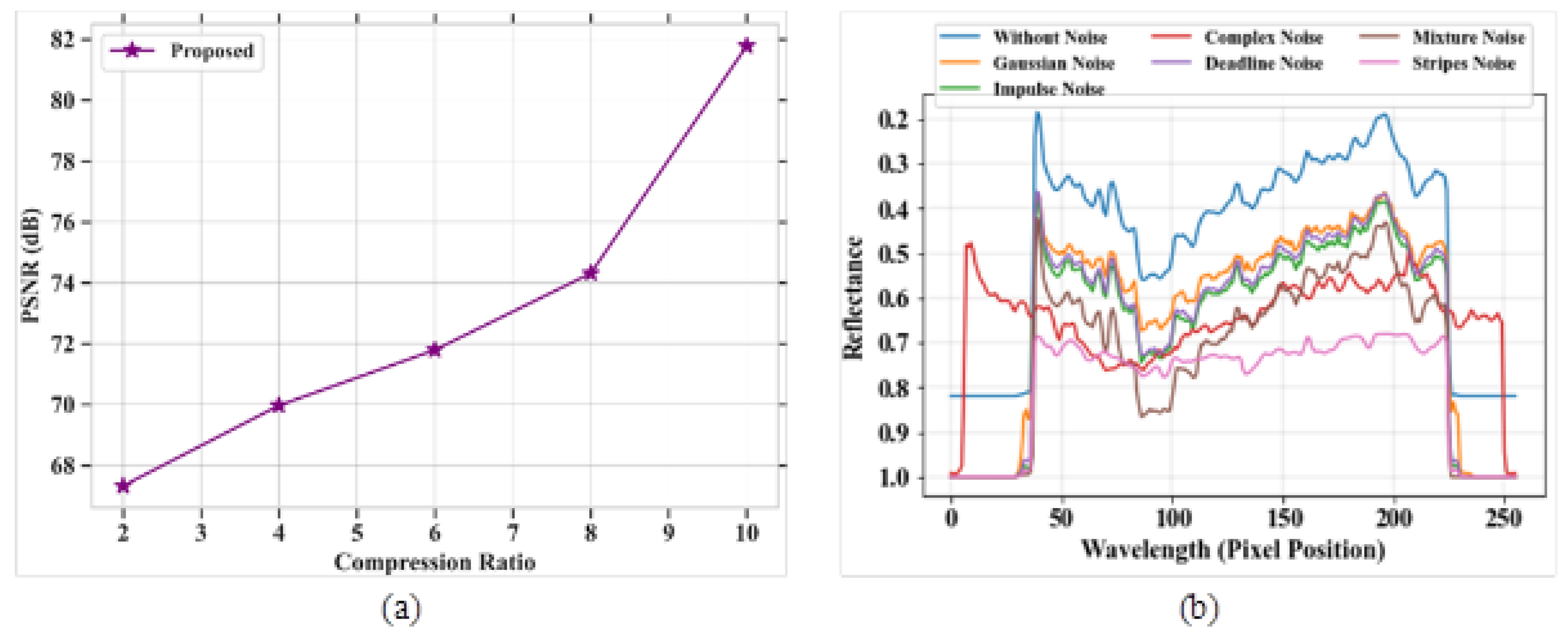
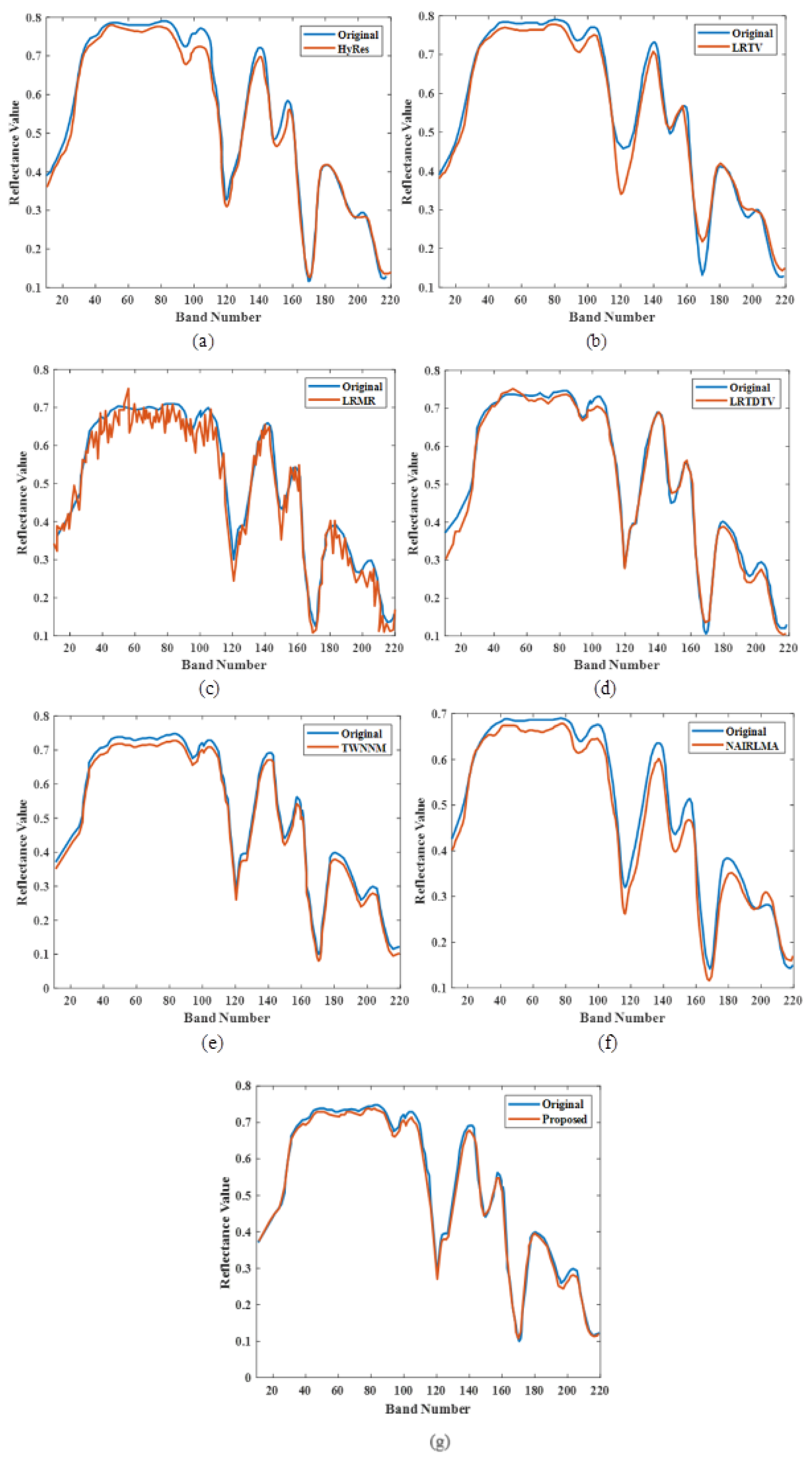
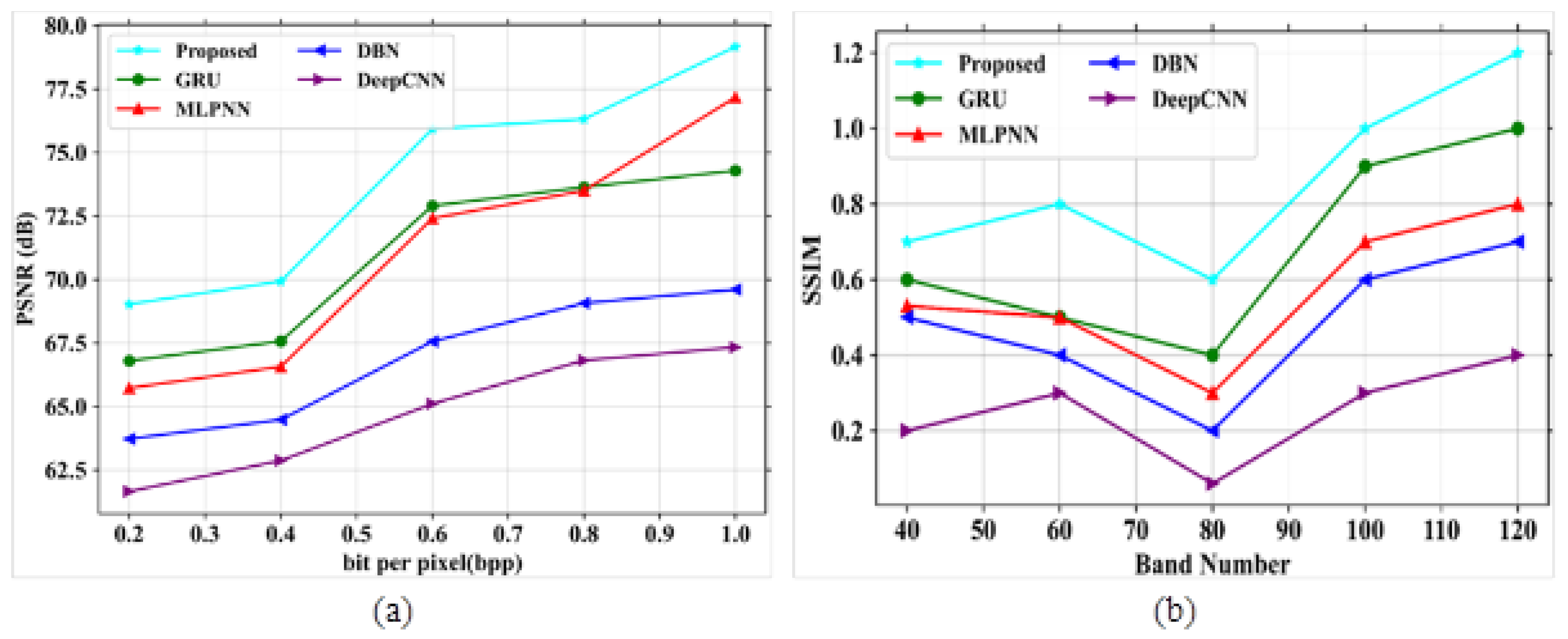
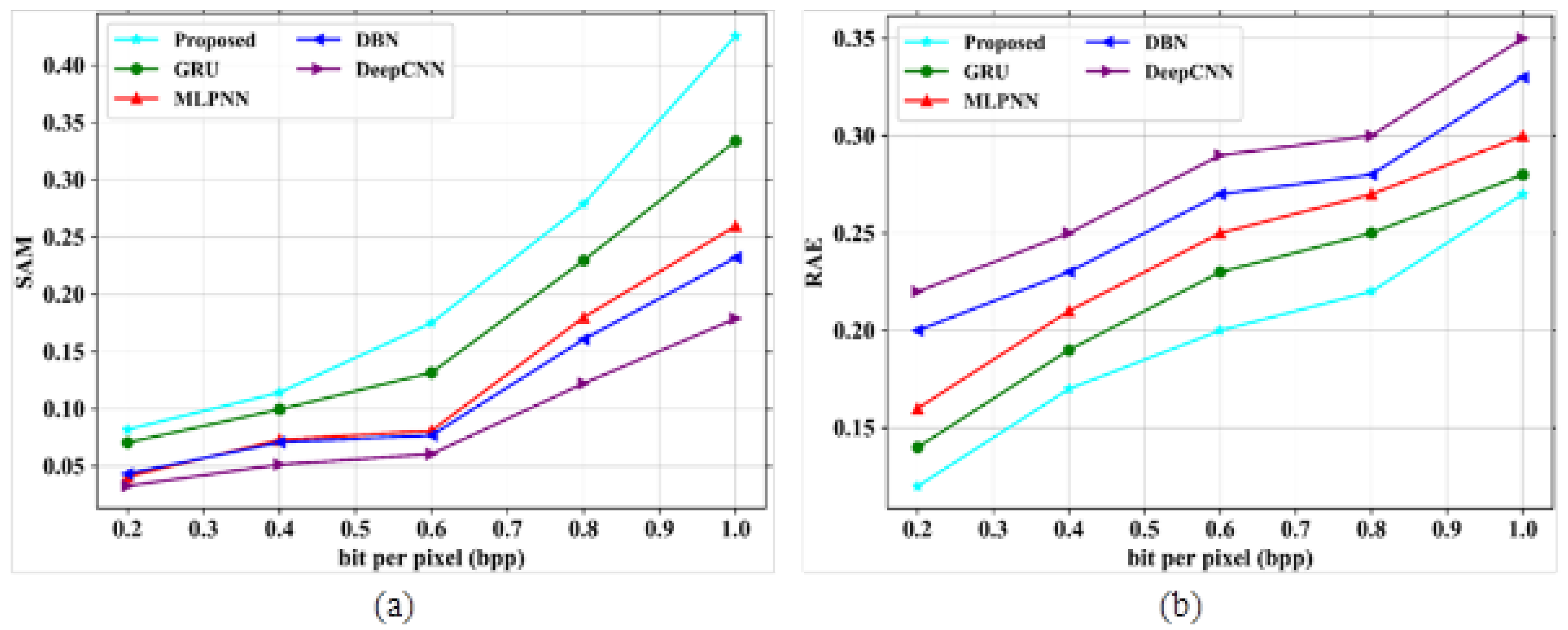
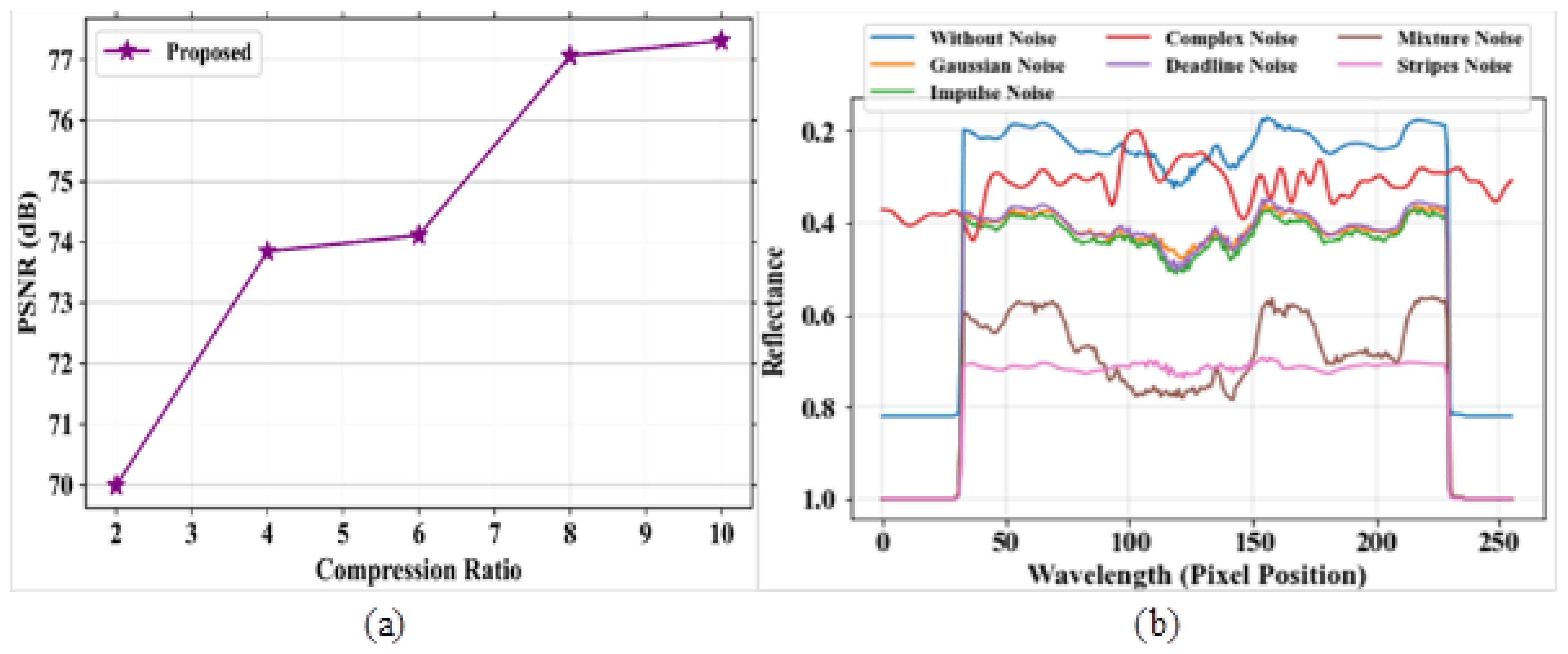
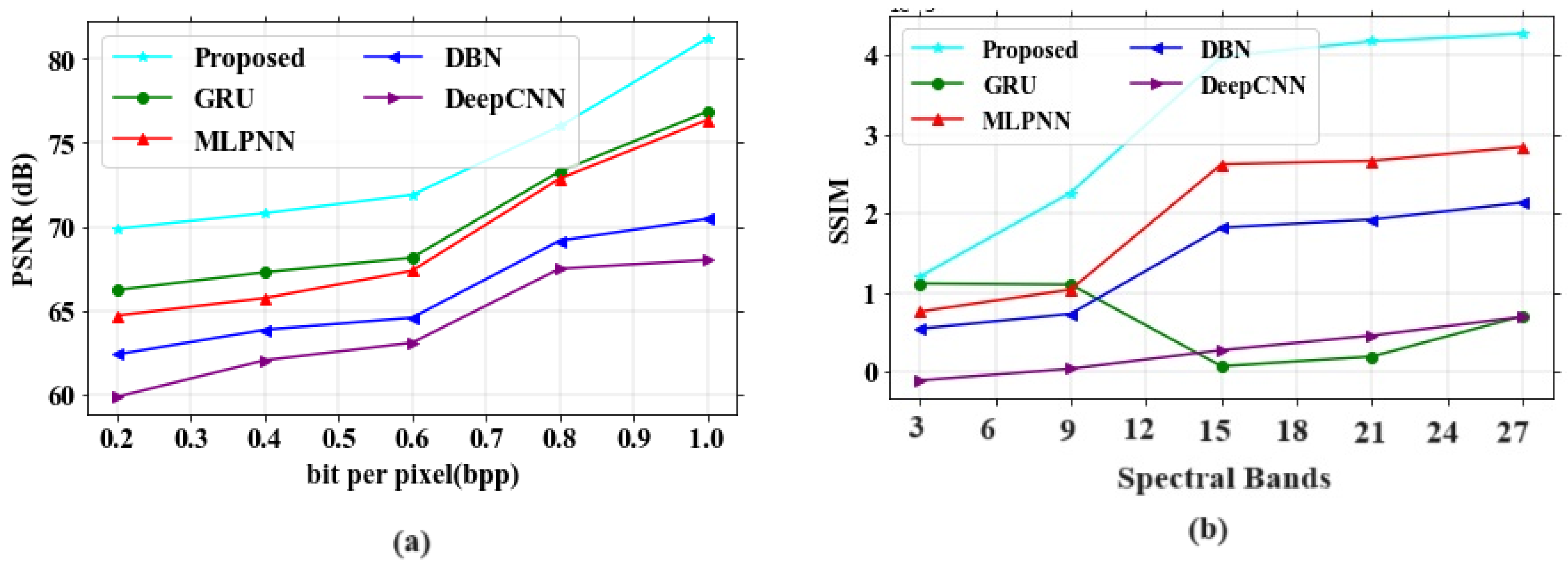
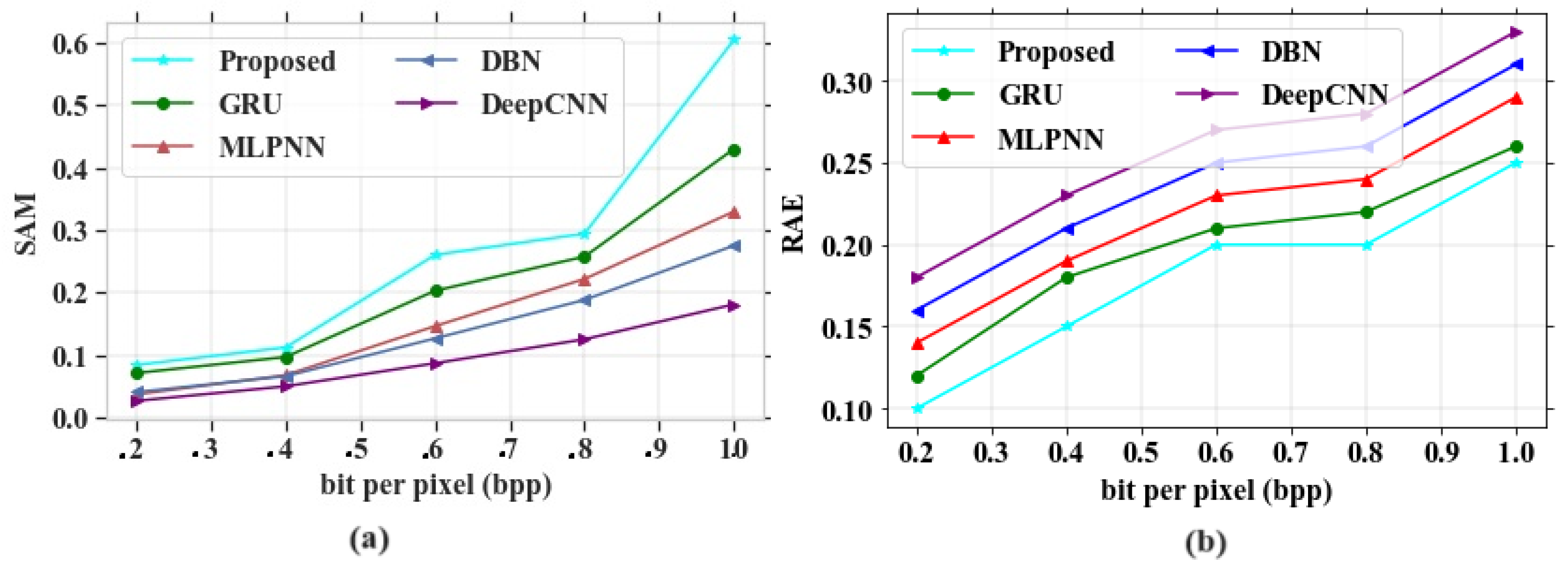
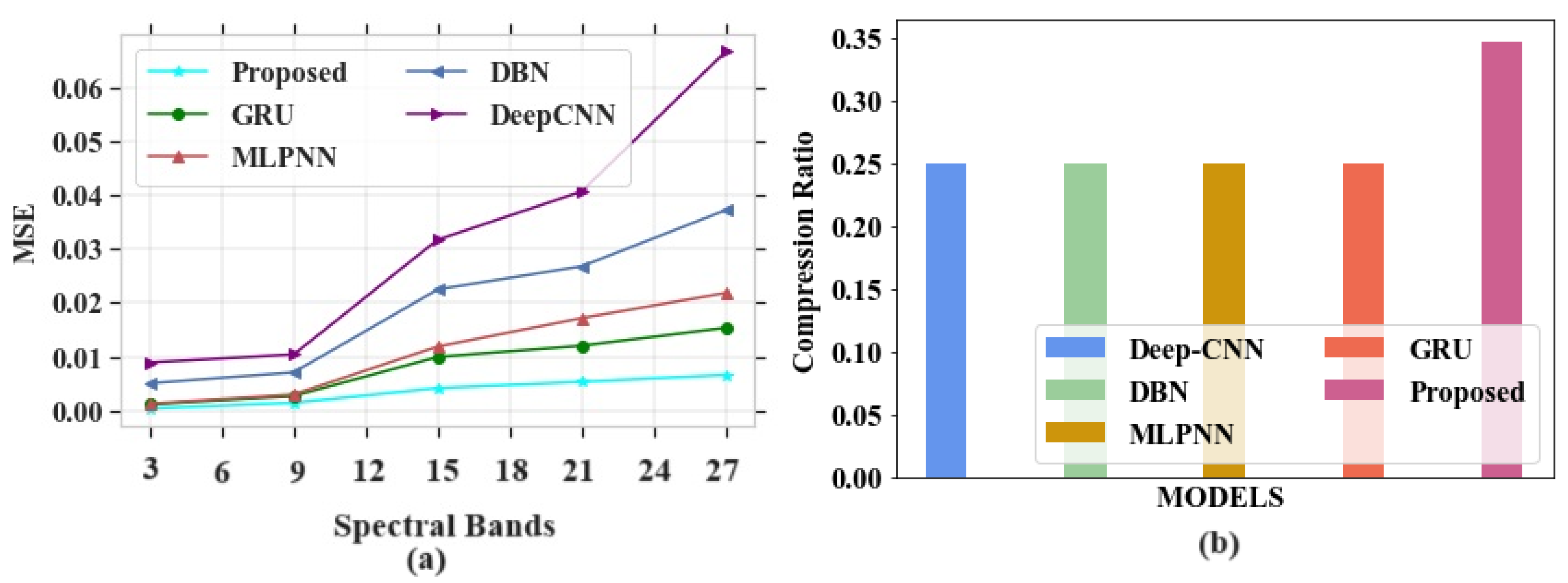
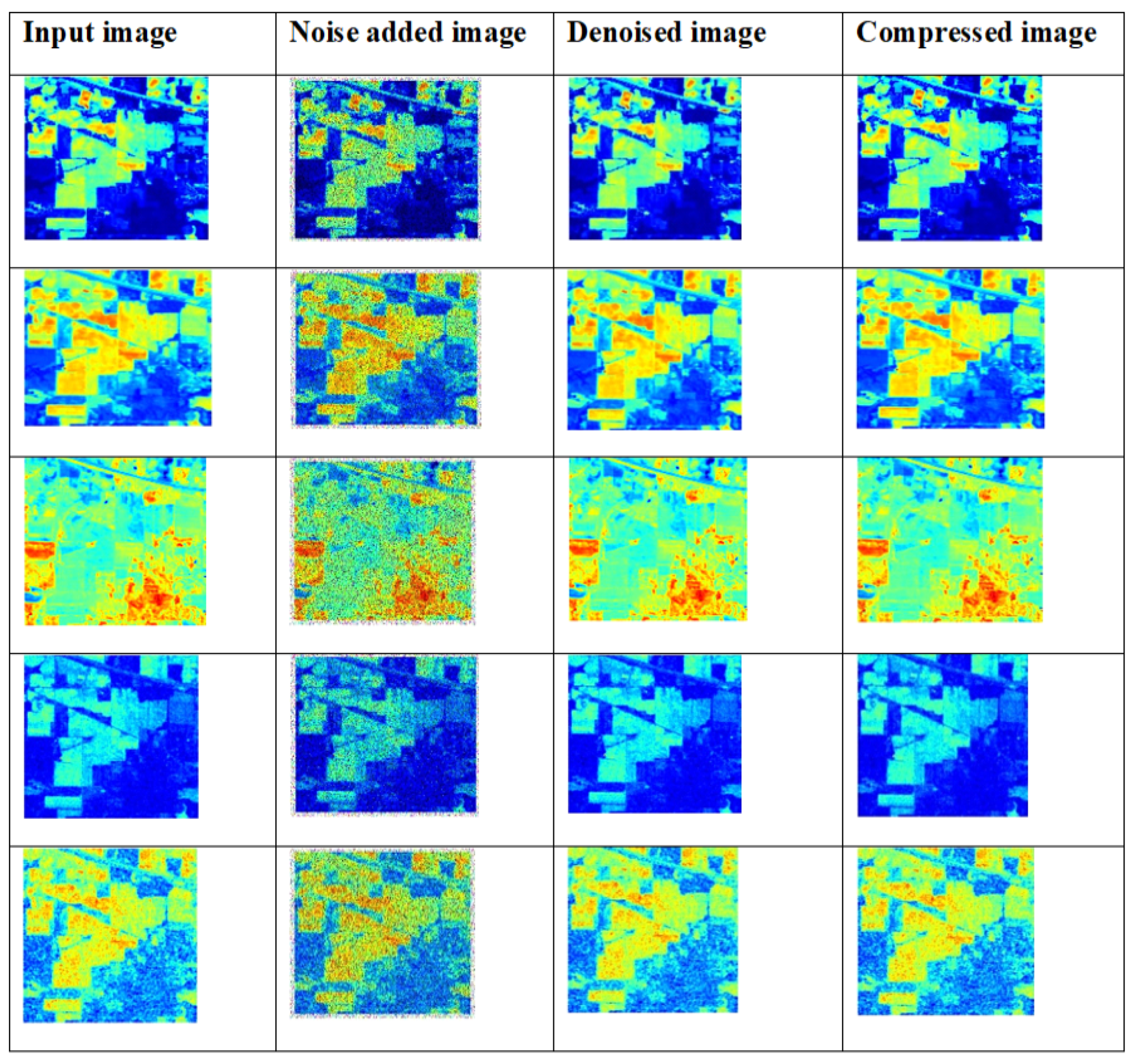
The major aim of this research work is to denoise and compress the HSI images [
34,
35] with less processing time and without compromising the image quality. Here, several performance metrics are analysed for proposed and existing models. Taking the results of quantitative and qualitative analyses [
36] into consideration, it can be shown that the proposed study provides better results. The two datasets, namely the Indian Pines dataset and Washington DC Mall dataset, were considered for the study. In the first stage, the input images were passed through an improved adaptive fusion network for noise removal. After denoising, the images were compressed with the CCAO-BiGRU model without reducing the quality of images [
37,
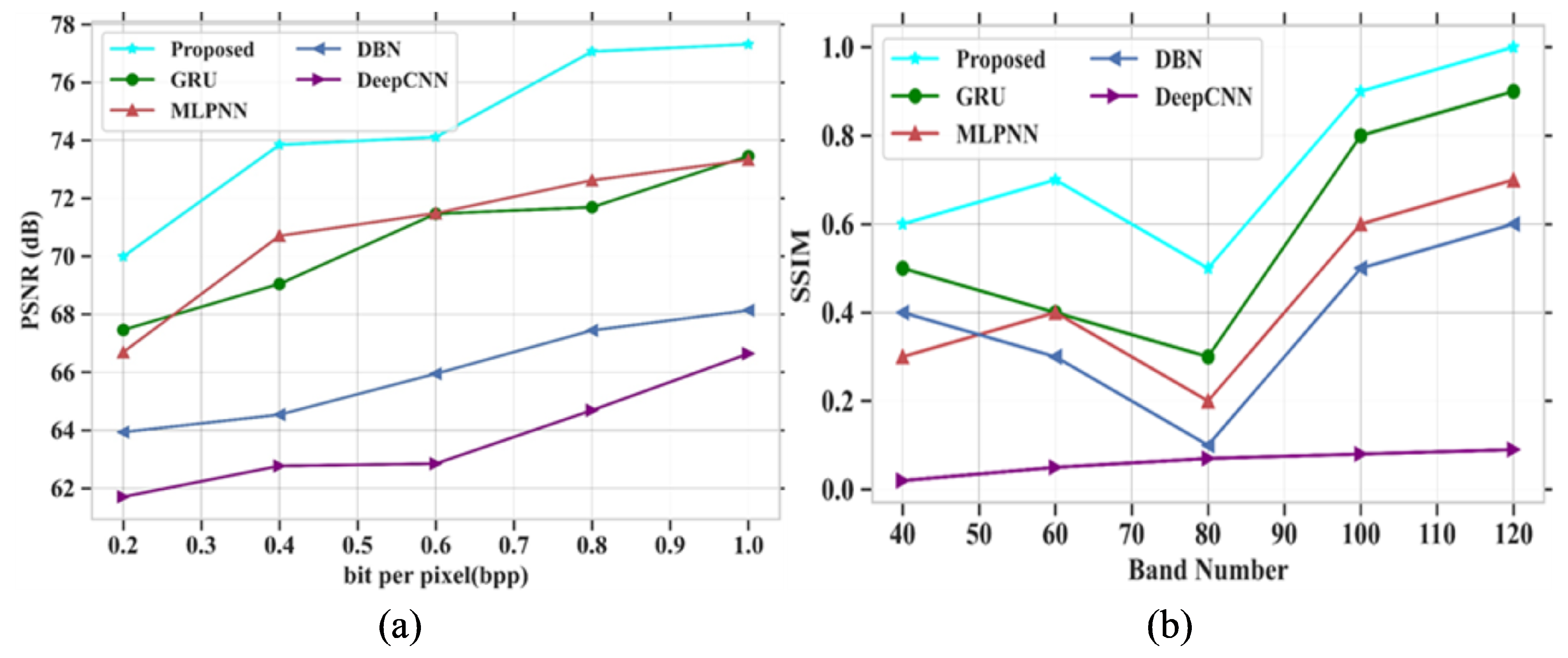
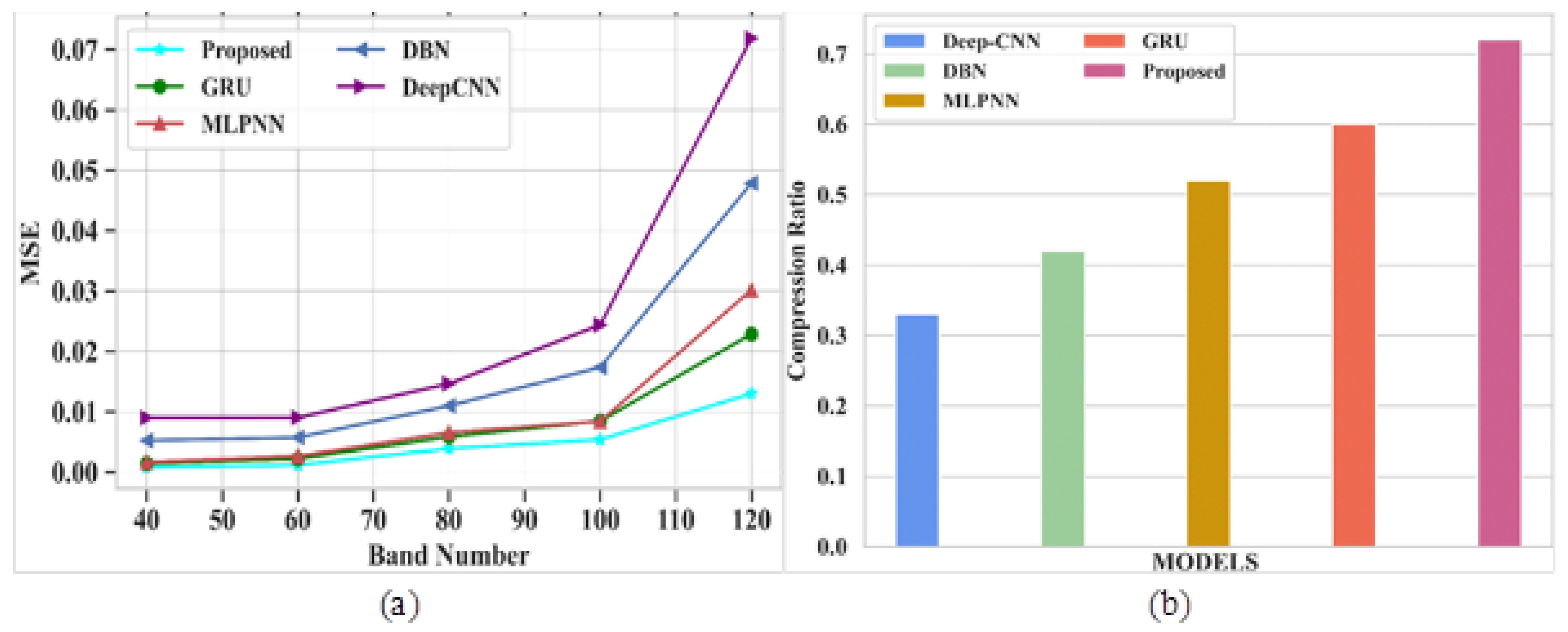
38]. Several drawbacks were noticed in the existing techniques, such as poor accuracy in image compression, improper compression of large size images, and the loss of important characteristics of images after compression. The proposed model obtained a PSNR value of 77.31 dB, a SAM of 0.7, a RAE of 0.29 at bpp 1.0, a SSIM of 1, an MSE at 0.013 at band number 120, a CR of 0.72, and the PSNR value based on a compression ratio at 10 is 82 for the Indian Pines dataset. For the Washington DC Mall dataset, the following values were obtained: PSNR of 79.16 dB, SAM of 0.35, RAE of 0.27 at bpp 1.0, SSIM of 1.2, MSE of 0.0065 at band number 120, CR of 1, and the PSNR value based on a compression ratio of 10 is 78.4. The proposed model obtained better values of PSNR, SAM, SSIR and RAE for both the datasets. It also gave a good plot of PSNR vs. CR curve which gives the impression of it being a better compression model. In addition, visual analysis also provided good results, which in turn proves the quality of the developed model. The proposed algorithm is compared with different existing methods in terms of quantitative metrics and it showed that the proposed model performs better compared to the existing models. The performance accuracy of the proposed work indicates that this can be utilized for mineral mapping as well as for agricultural applications. The PSNR values in [
39] can be further improved using a different activation function.
5. Conclusions
In this study, a novel image denoising and compression technique based on a deep learning model is proposed to retain the overall quality of an image without limiting the compression ratio. Here, three datasets, namely the Indian Pines dataset, the Washington DC Mall dataset, and the CAVE dataset were considered for the study. In the first stage, an improved adaptive fusion network is used to remove undesirable noise from the images. In the second stage, the denoised image is passed into the compression phase. In the compression stage, the images are compressed without compromising the quality using the CCAO-BiGRU model. The performance metrics, such as PSNR, SSIM, MSE, CR, RAE and spectral reflectance curve for various types of noise were analysed for the proposed and existing models. From these analyses, we proved that the proposed model is a better system compared to the existing models. In future research, the replacement of the activation function in the proposed model (ReLU and sigmoid) with generalized divisive normalization (GDN) can be performed to improve the PSNR value further. Additionally, the proposed algorithm can be tested using real-time data.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}