1. Introduction
Target detection represents one of the most important fundamental tasks in the domain of computer vision, attracting substantial scholarly and practical interest in recent years. The core objective of target detection lies in accurately identifying and classifying various targets within digital images, such as humans, vehicles, or animals, and precisely determining their spatial locations. The advent and rapid evolution of deep learning technologies have significantly propelled advancements in target detection, positioning them as a focal point of contemporary research with extensive applications across diverse sectors [
1,
2]. Notably, drones, leveraging their exceptional flexibility, mobility, and cost-effectiveness, have been integrated into a wide array of industries. These applications span emergency rescue [
3], traffic surveillance [
4], military reconnaissance [
5], agricultural monitoring [
6], and so on.
For natural images, target detection technology has made considerable progress. This technology can be divided into single-stage and two-stage detection methods. Two-stage detection methods primarily include region-based target detection approaches such as R-CNN [
7], Fast R-CNN [
8], Faster R-CNN [
9], and so on. Single-stage detection methods encompass techniques like YOLO, SSD, and DETR [
10,
11]. Natural images are typically captured from a ground-level perspective, with a relatively fixed viewpoint and minimal changes in the shapes and sizes of targets. In contrast, drone images are usually taken from high altitudes, offering a bird’s-eye view. Under this perspective, especially when the drone’s flight altitude varies, the shapes and sizes of targets can change significantly. As shown in
Figure 1, we analyzed the number of small, medium, and large targets in the VisDrone 2019 and UAVDT datasets (the latter being divided into training, testing, and validation sets for clarity). The results indicate that the training, testing, and validation sets of both the VisDrone 2019 and UAVDT datasets contain targets of various sizes, showing significant differences in target scale distribution.
Moreover, targets in the drone images often have more complex backgrounds due to variations in lighting, weather conditions, and surrounding environments. As shown in
Figure 2a, the buildings, trees, and other non-target categories presented in the images, along with the dim lighting conditions, make target detection in UAV images more challenging. For
Figure 2b, the occlusion by trees, shadows, and adverse weather conditions introduces more challenges to the target detection task. Consequently, the significant scale differences and complex backgrounds make it challenging to directly apply existing detection models designed for natural images to UAV images.
In this paper, to address the challenges of significant scale variability of targets and complex backgrounds in UAV images, we propose the UAV target detection network, FSTD-Net. The design of FSTD-Net is based on three principal aspects. Firstly, to capture more effective multi-level features and avoid the interference of complex backgrounds, the multi-scale and contextual information extraction module (MSCIEM) is designed. Secondly, to extract full-scale object information that can better represent targets of various scales, we designed the feature extraction module fitting different shapes (FEMFDS), which is guided by the deformable convolutions. The positions of the sampling points in deformable convolutions can be dynamically adjusted during the learning process; the FEMFDS is positioned before the detection heads for different scales, enabling it to effectively capture full-scale target features of different target shapes. Finally, to fully utilize the detailed information contained in the low-level features, we propose the low-level feature enhancement branch (LLFEB), which uses a top-down and bottom-up feature fusion strategy to incorporate low-level semantic features. In summary, the main contributions are as follows:
- (1)
The MSCIEM is proposed to optimize the semantic features of targets on different scales while avoiding the interference of complex backgrounds. MSIEM employs parallel convolutions with different kernel sizes to capture the features of targets on different scales. The CIEM embedded in MSCIEM is to capture long-range contextual information. Thus, the MSCIEM can effectively capture multi-scale and contextual information.
- (2)
We design the FEMFDS, which is guided by the deformable convolutions. Due to the FEMFDS breaking through the conventional feature extraction paradigm of standard convolution, the FEMFDS can dynamically match full-scale target shapes.
- (3)
Due to the rich, detailed features in low-level features, such as edges and textures, we designed the LLFEB. The LLFEB uses a top-down and bottom-up feature fusion strategy to incorporate low-level and high-level features, which can effectively utilize the detailed information in low-level features.
- (4)
Experiments on the VisDrone2019 and UAVDT dataset show that the proposed FSTD-Net surpasses the state-of-the-art detection models. Our proposed FSTD-Net can achieve more accurate detection of targets at various scales and in a complex background. In addition, FSTD-Net is lightweight. These experiments demonstrate the superior performance of the proposed FSTD-Net.
This paper is structured into six distinct sections.
Section 2 reviews the related work pertinent to this work.
Section 3 elaborates on the design details of the FSTD-Net.
Section 4 presents the parameter settings of the model training process, training environment, and experimental results.
Section 5 provides an in-depth discussion of the advantages of FSTD-Net and the impacts of the cropping and resizing methods designed for the experiments. Finally,
Section 6 summarizes the current work and proposes directions for future research.
3. Methods
In this section, the baseline model YOLOv5s and the proposed FSTD-Net will be introduced. Firstly, the overall framework of the baseline model YOLOv5s will be introduced. Then, we will give an overall introduction to the FSTD-Net. Finally, we will discuss the components of FSTD-Net in detail: the LLFEB, which can provide sufficient detailed information from low-level features; the MSCIEM, which can effectively capture target features at different scales; and long-range context information. The FEMFDS, which is based on deformable convolution, is sensitive to full-scale targets of different scales.
3.1. The Original Structure of Baseline YOLOv5s
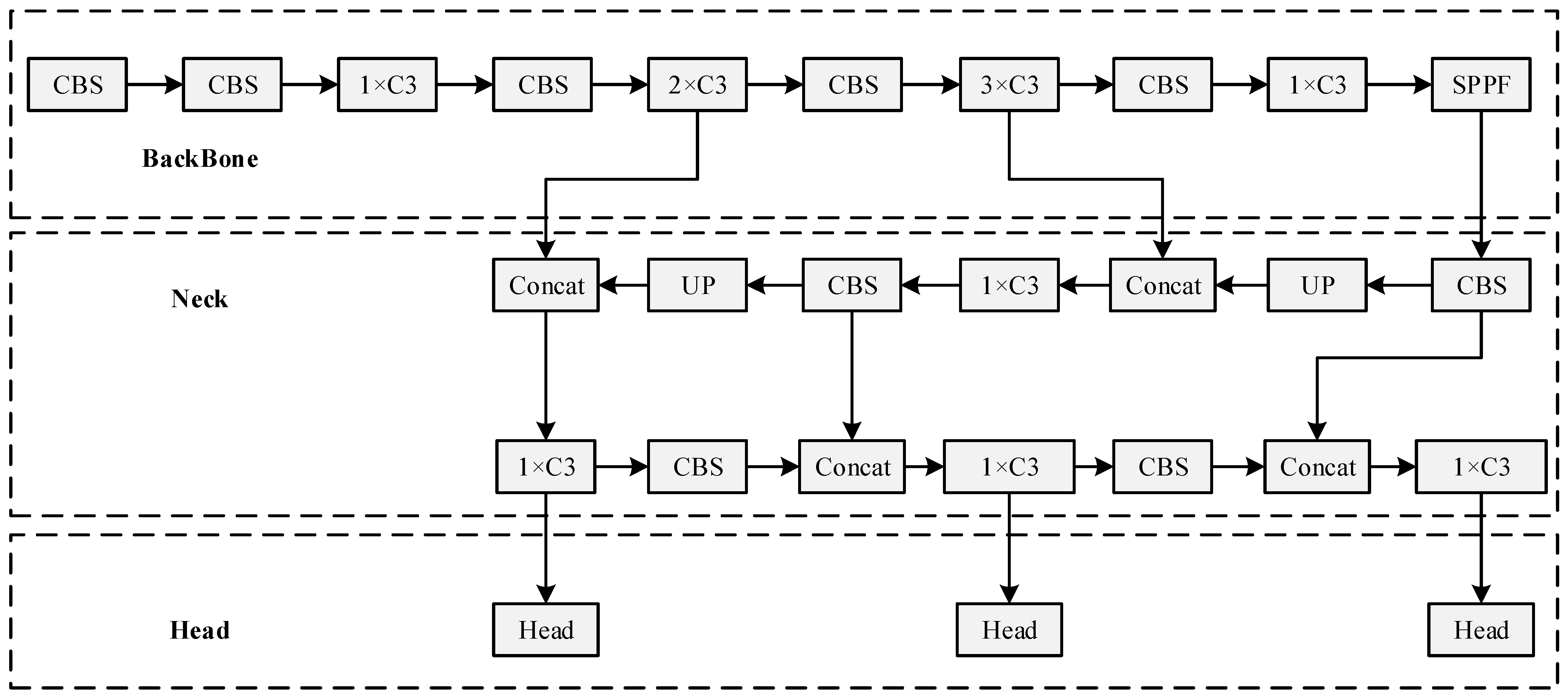
YOLOv5 is a classic single-stage target detection algorithm known for its fast inference speed and good detection accuracy. It comprises five different models: n, s, m, l, and x, which can meet the needs of various scenarios. As shown in
Figure 3, the YOLOv5s architecture consists of a backbone for feature extraction, which includes multiple CBS modules composed of convolutional layers, batch normalization layers, and SiLU activation functions, as well as C3 modules for complex feature extraction (comprising multiple convolutional layers and cross-stage partial connections). At the end of the backbone, global feature extraction is performed using the SPPF module. The SPPF (Spatial Pyramid Pooling-Fast) module in YOLOv5 serves the purpose of enhancing the receptive field and capturing multi-scale spatial information without increasing the computational burden significantly. By applying multiple pooling operations with different kernel sizes on the same feature map and then concatenating the pooled features, SPPF effectively aggregates contextual information from various scales. This helps in improving the model’s ability to detect targets of different sizes and enhances the robustness of feature representations, contributing to better overall performance in target detection tasks.
The Neck incorporates both FPN and PANet [
51] structures, employing concatenation and nearest-neighbor interpolation for upsampling to achieve feature fusion. FPN is utilized to build a feature pyramid that enhances the model’s ability to detect targets at different scales by combining low-level and high-level feature maps. PANet further improves this by strengthening the information flow between different levels of the feature pyramid, thus enhancing the model’s performance in detecting small and large targets.
The Head consists of several convolutional layers that transform the feature maps into prediction outputs, providing the class, bounding box coordinates, and confidence for each detected target. In the YOLOv5s, the detection head adopts a similar structure to YOLOv3 due to its proven efficiency and effectiveness in real-time target detection. This structure supports multi-scale predictions by detecting targets at three different scales, handles varying target sizes accurately, and utilizes anchor-based predictions to generalize well across different target shapes and sizes. Its simplicity and robustness make it easy to implement and optimize, leading to faster training and inference times while ensuring high performance and reliability across diverse applications.
3.2. The Overall Framework of FSTD-Net
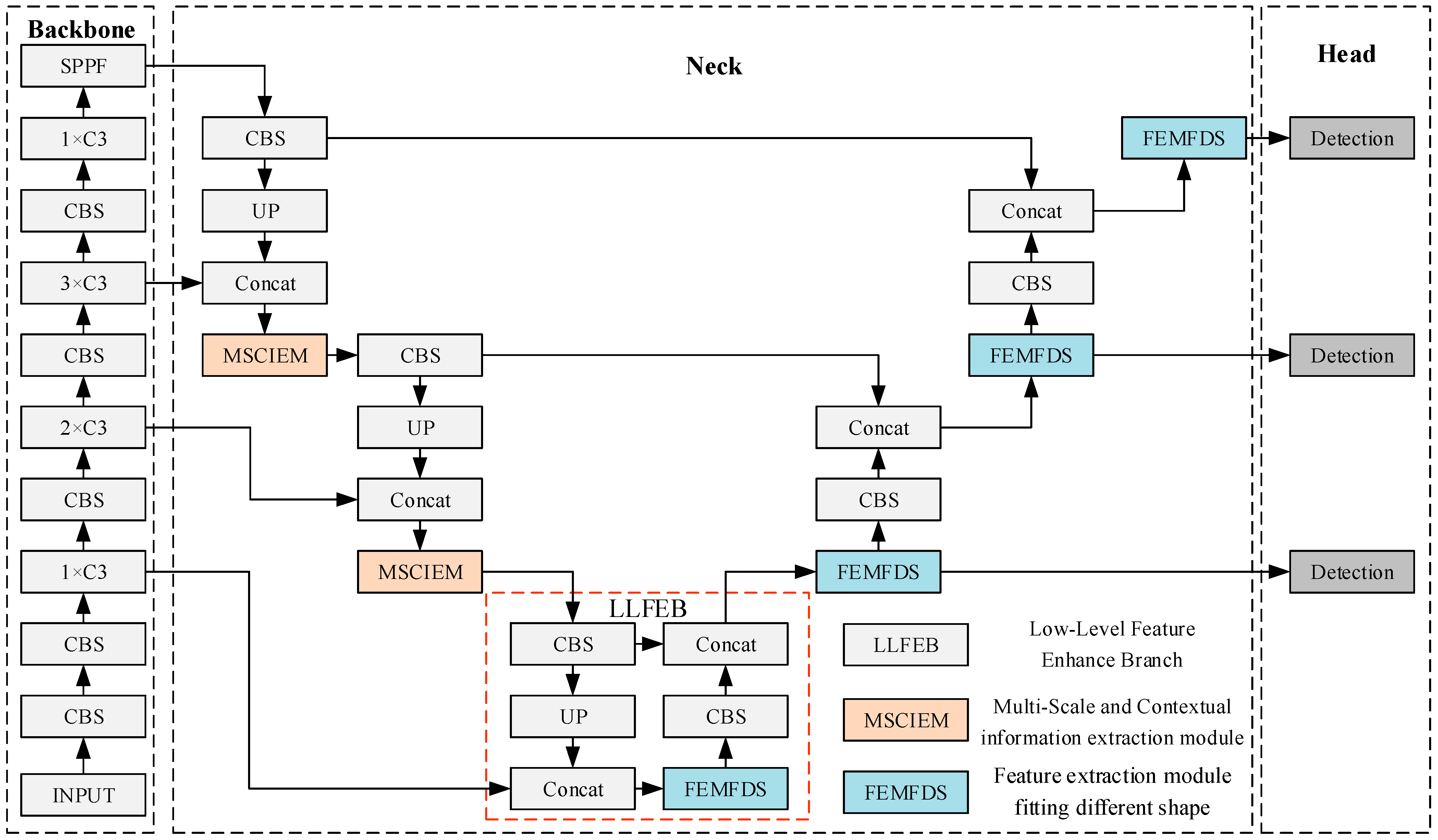
In this paper, our proposed FSTD-Net is based on the YOLOv5s architecture, as illustrated in
Figure 4. The structure of FSTD-Net includes three main components: The Backbone, the Neck, and the Head, all integrated into an end-to-end framework for efficient and precise target detection. The Backbone is responsible for feature extraction, leveraging YOLOv5s for its lightweight design, which balances performance with computational efficiency. The Neck further processes and fuses these features from different levels of the backbone, enhancing the network’s ability to recognize targets of varying scales and complex backgrounds through multi-scale feature fusion. The Head, employing a detection mechanism similar to YOLOv3, accurately identifies and localizes target categories and positions using regression methods, ensuring high accuracy and reliability. Overall, FSTD-Net’s design combines lightweight architecture with multi-scale feature integration, achieving high detection accuracy while maintaining low computational complexity and high processing efficiency, making it suitable for UAV target detection tasks.
For FSTD-Net, the Backbone adopts the CSP-Darknet network structure, which effectively extracts image features. In the Neck part, to better suppress complex background information in UAV images and extract information from targets of different scales, the MSCIEM replaces the original C3 module. The MSCIEM is mainly composed of MSIEM and CIEM. MSIEM utilizes multiple convolutional kernels with different receptive fields to better extract information from targets on different scales. Meanwhile, the context information extraction module (CIEM) is embedded in the MSCIEM to extract long-distance contextual semantic information. To improve the detection of targets of different scales in UAV images, the FEMFDS module breaks through the inherent feature extraction method of standard convolution. It can better fit the shapes of targets of different scales and extract more representative features. The designs of MSCIEM and FEMFDS aim to enhance the detection performance of FSTD-Net for targets of different sizes. Furthermore, considering that low-level features contain rich, detailed features such as edges, corners, and texture features, the LLFEB is separately designed to better utilize low-level semantic features and enhance the target detection performance of FSTD-Net.
3.3. Details of MSCIEM
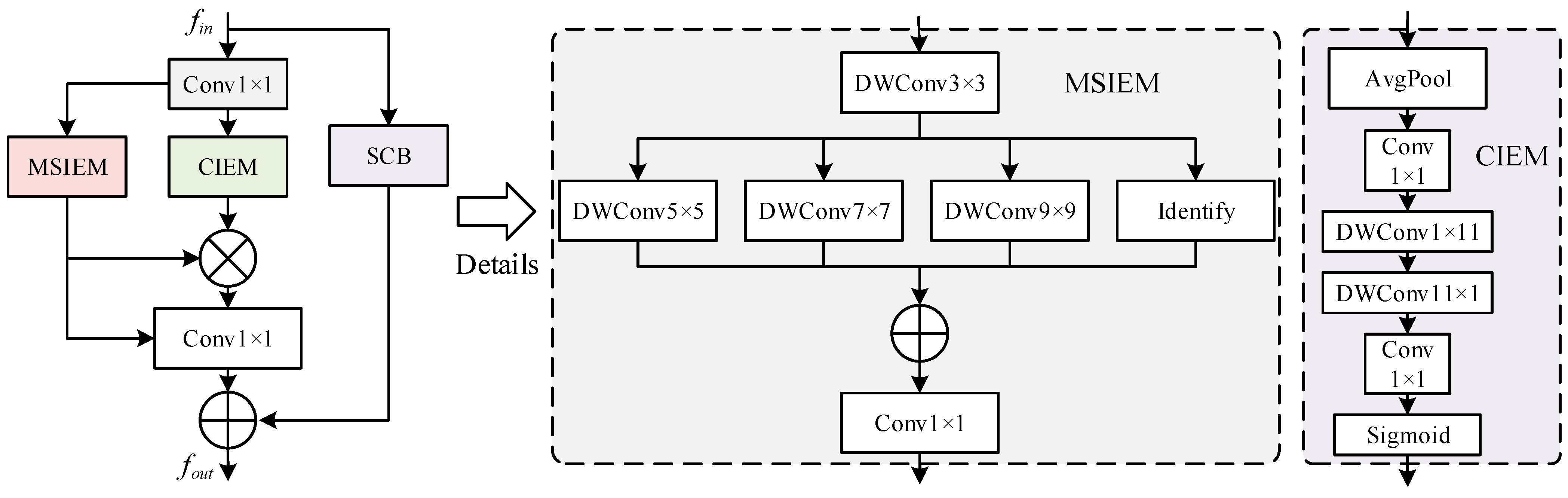
Since UAV images are captured from a high-altitude perspective, they introduce complex background information and contain various types of targets. The complexity of the background and the scale differences can significantly impact the performance of target detection. To mitigate the introduction of complex background information and address the issue of scale differences in targets, MSCIEM is designed. As shown in
Figure 5, the structural composition of MSCIEM is illustrated. MSCIEM consists of an independent shortcut connection branch (SCB), MSIEM, and CIEM, where features from these three paths are fused as the final output feature. The MSIEM, designed with convolutional kernels of various sizes, effectively captures feature information from targets of different scales in feature maps. Meanwhile, the CIEM is employed to capture contextual information, enhancing the overall feature representation capability.
The inputs and outputs of MSCIEM are respectively
and
. For the independent branch SCB, it consists of a convolutional layer with a kernel size of 3 × 3 and a stride of 1. The input is
. The output feature after processing by SCB is
, as shown in Equation (1).
For MSIEM and CIEM, before being fed into MSIEM and CIEM,
undergoes a convolutional layer with a 1 × 1 kernel size to reduce the number of channels to 1/4 of the original, resulting in the inputs
for MSIEM and CIEM, respectively. For MSIEM, it follows an inception-style structure [
52,
53]. It first undergoes 3 × 3 depth-wise convolutions (DWConvs) to extract local information and is then followed by a group of parallel DWConv with kernel sizes of 5 × 5, 7 × 7, and 9 × 9 to extract cross-scale contextual information. Let
represent the local features extracted by the 3 × 3 DWConv, and
represent the cross-scale contextual features extracted by the DWConvs with kernel sizes of 5 × 5, 7 × 7, and 9 × 9, respectively. The contextual features
and the local features
are fused using 1 × 1 convolutions, resulting in the features
, as shown in Equation (2).
For CIEM, its main role is to capture long-range contextual information. CIEM is integrated into MSIEM to strengthen the central features while further capturing the contextual interdependencies between distant pixels. As shown in
Figure 5, by using an average pooling layer followed by a 1 × 1 convolutional layer on
, the local features are gained.
represents the average pooling operation, followed by two depth-wise strip convolutions applied to
, and then the long-range contextual information
is extracted. Finally, the sigmoid activation function is used to extract the final attention feature map
.
In Equation (3),
and
represent depth-wise strip convolutions with kernel sizes of 11 × 1 and 1 × 11, respectively.
denotes the activation function.
is used to enhance the contextual expression of features extracted by MSIEM. After the features extracted by MSIEM and CIEM are processed by a 1 × 1 convolution, they are fused with the features extracted by SCB to obtain the final features.
In Equation (4), represents element-wise multiplication.
3.4. The Design of FEMFDS
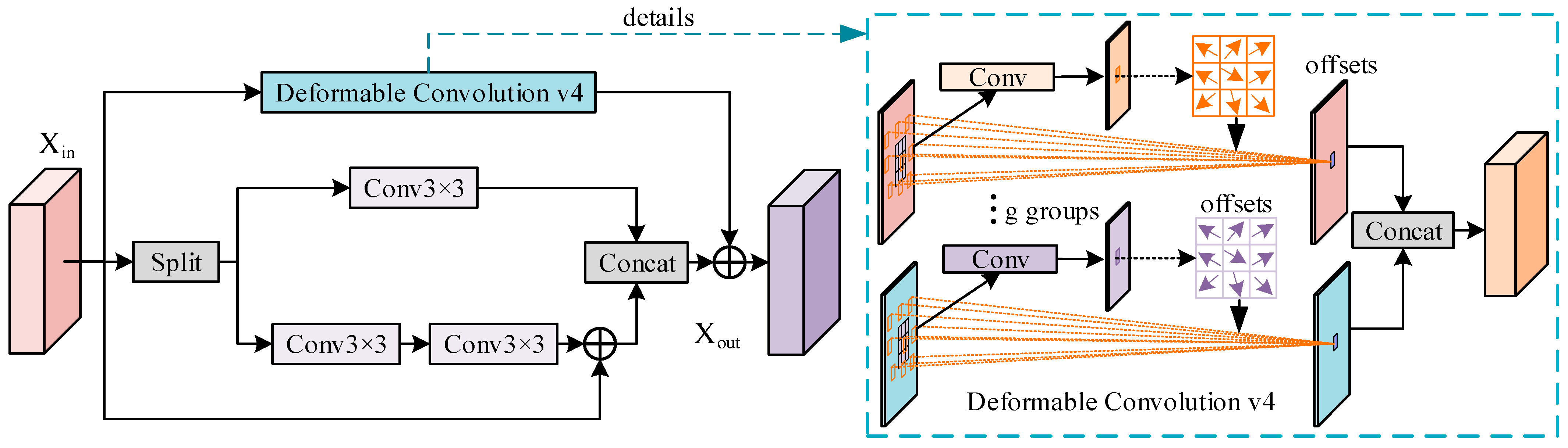
Standard convolutions have fixed geometric structures and receptive fields; thus, they have certain limitations in feature extraction. Standard convolutions cannot effectively model full-scale targets of different shapes present in UAV images. However, deformable convolutions, by adding additional offsets based on sampling positions within the module and learning these offsets during the target task, can better model full-scale targets of various shapes present in UAV images. Thus, we designed the FEMFDS to better fit different full-scale target shapes. As shown in
Figure 6, The FEMFDS consists of two branches: one branch is used to extract local features from the image, and the other branch is dedicated to extracting features that can better fit targets of different sizes. The features extracted by these two branches are then fused to obtain the final feature representation.
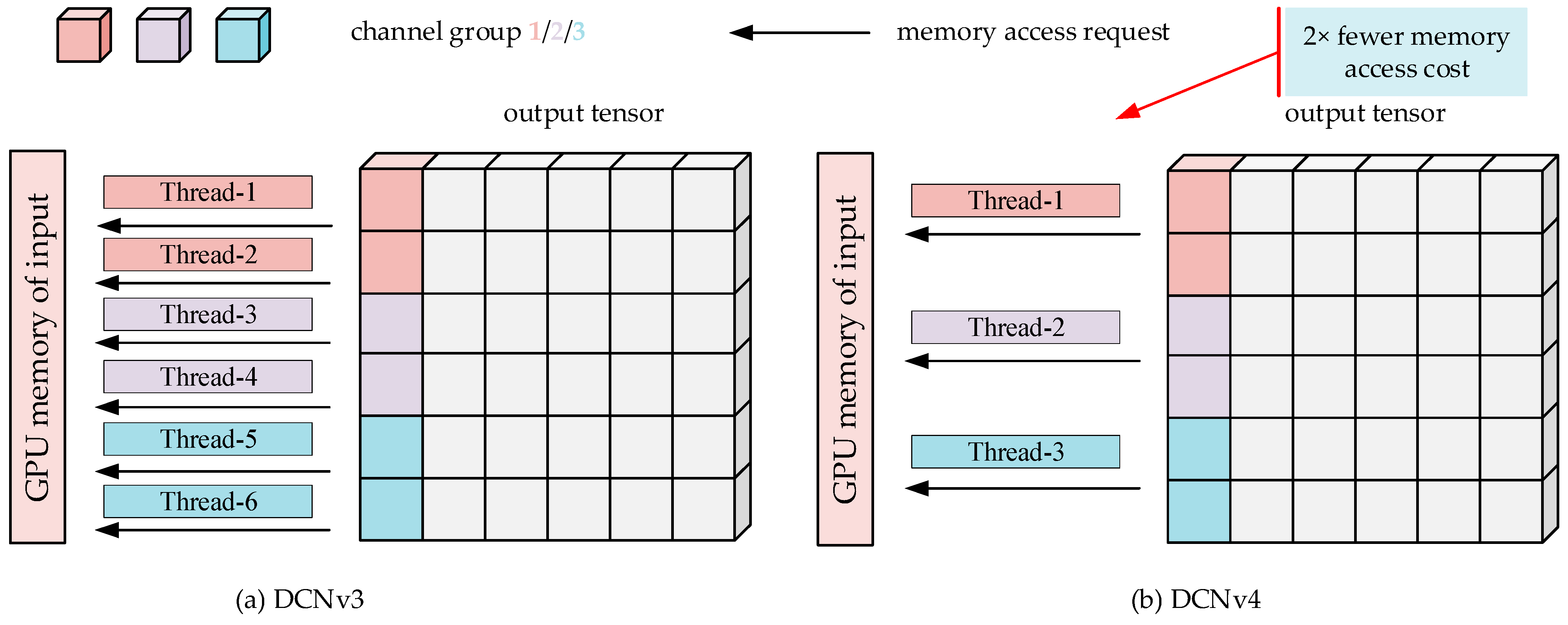
The deformable convolution used in FEFMDS is deformable convolution v4 (DCNv4). The reason for choosing DCNv4 is that, based on DCNv3, it removes the soft normalization to achieve stronger dynamic properties and expressiveness. Furthermore, as shown in
Figure 7, memory access is further optimized. DCNv4 uses one thread to process multiple channels in the same group that share sampling offset and aggregation weights. Thus, DCNv4 has a faster inference speed. When the input is
, with height H, width W, and C channels. The process of deformable convolution is as follows:
In Equation (5), g represents the number of groups for spatial grouping along the channel dimension. For the g-th group, the and respectively represents the feature maps for the g-th group. The dimension of the feature channels is represented by . represents the spatial aggregation weight of the k-th sampling point in the g-th group. represents the k-th position of the predefined grid sampling, similar to standard convolution . represents the offset corresponding to the position of the grid sampling in the g-th group.
3.5. The Structure of LLFEB
In convolutional neural networks, low-level semantic features include rich details such as edges, corners, textures, and so on. These features provide the foundation for subsequent high-level features, thereby enhancing the model’s detection performance on images. In the YOLOv5s baseline model, the feature maps obtained after two down-sampling operations are not directly used. Instead of directly fusing these low-level semantic features with the down-sample features, we adopt a top-down and bottom-up feature fusion approach. The fusion of low-level and high-level features combines local, detailed information with global semantic information, forming a more comprehensive feature representation. The multi-level information integration helps FSTD-Net better understand and parse image content, thereby further enhancing the detection performance of FSTD-Net on UAV images.
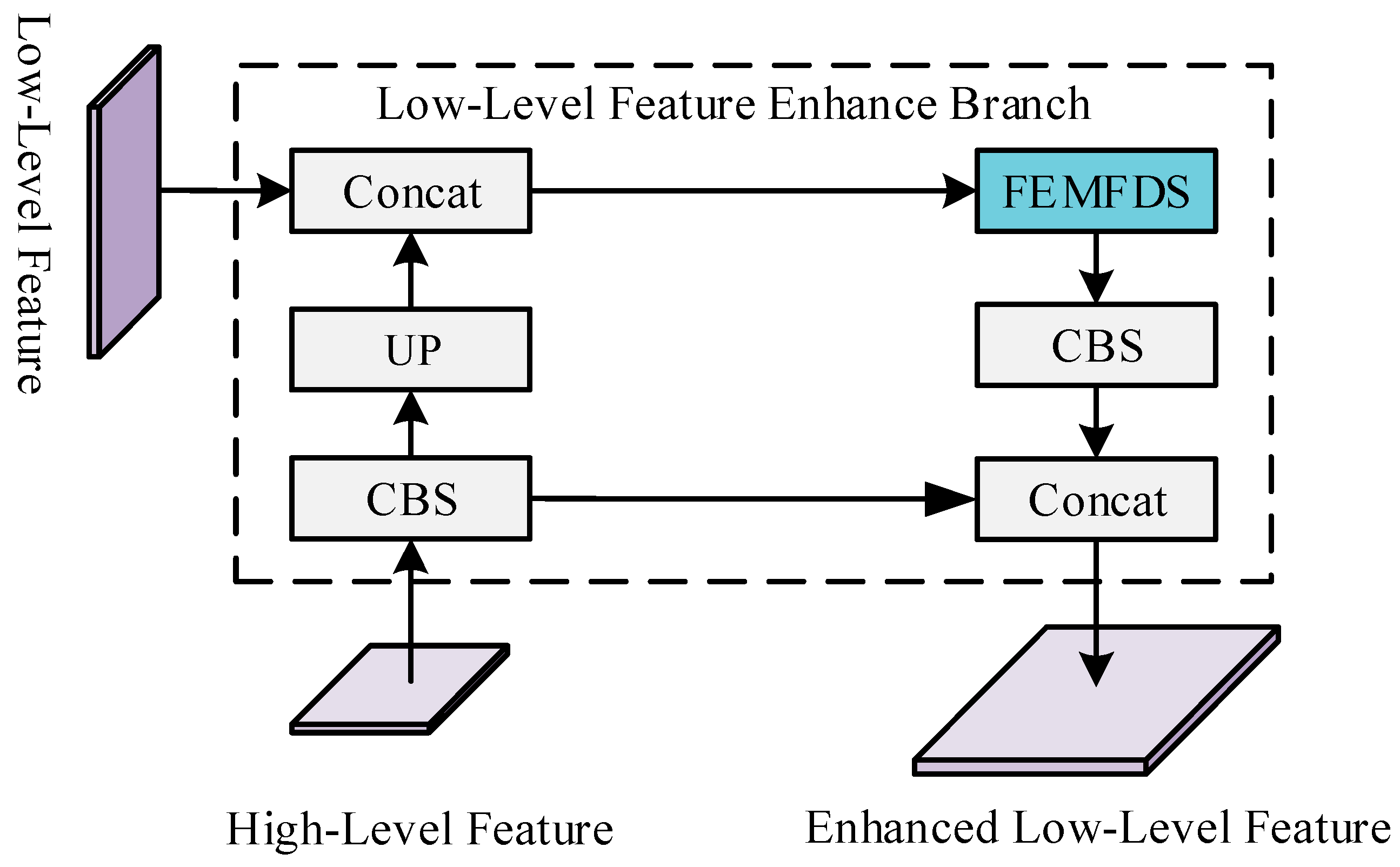
As shown in
Figure 8, the specific implementation process of LLFEB is as follows. The low-level feature map is
, a convolutional layer that first operates on the corresponding higher-level semantic feature
, followed by upsampling on the processed
, then the
is gained. Then,
and
are merged with the Concat operation, the fused feature map is further processed with FEMFDS and a convolutional layer, and finally, the enhanced low-level semantic feature
is obtained.
The overall process of LLFEB is as follows:
In Equation (6), represents the upsampling operation, represents the FEMFDS module.
3.6. Loss Function
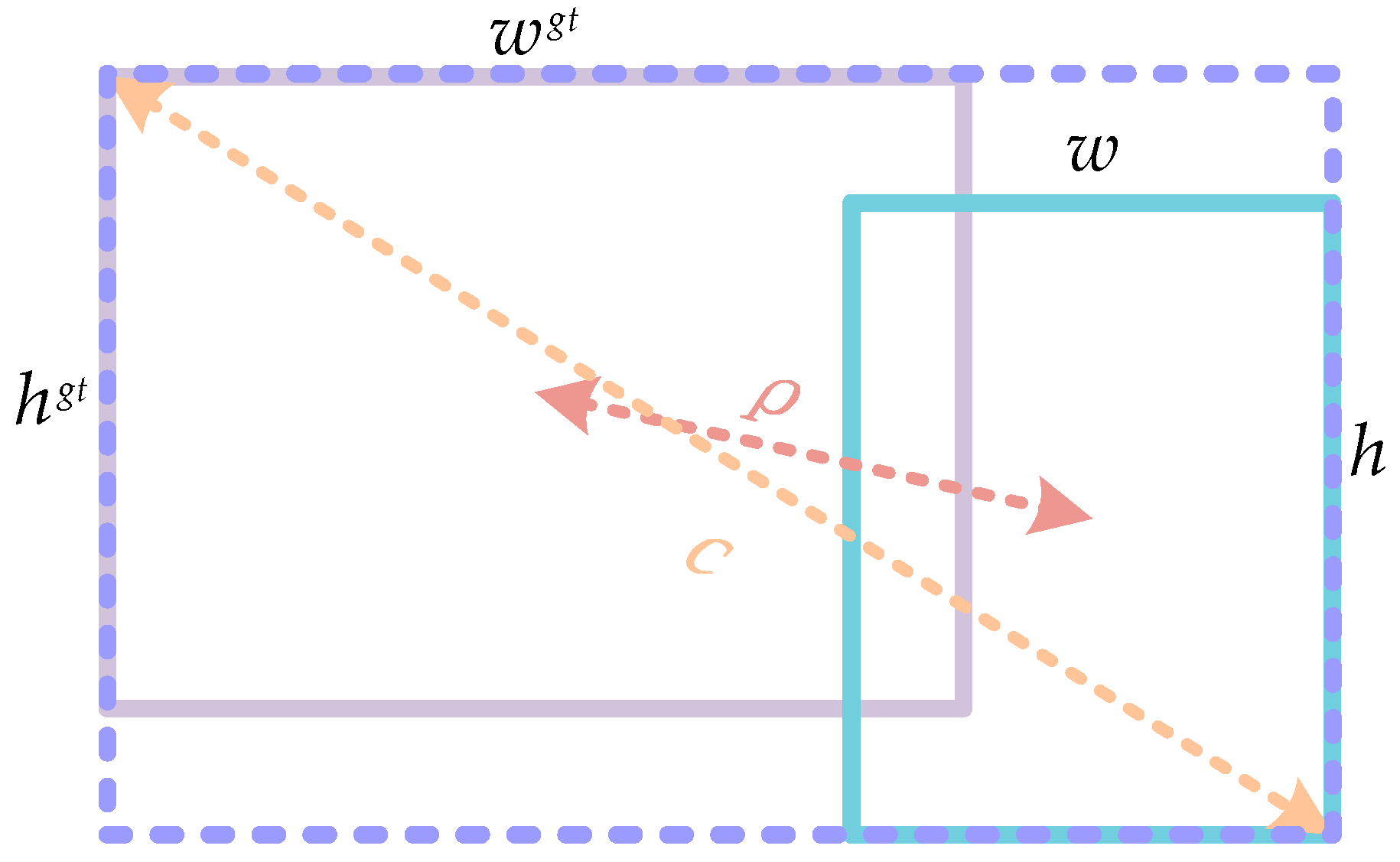
The loss function of FSTD-Net consists of three components, bounding box regression loss, classification loss, and objectness loss. For bounding box regression loss, the Complete Intersection over Union (CIoU) is used. The CIoU loss considers not only the IoU of the bounding box but also the differences in centroid distances and aspect ratios, which makes the prediction of the bounding box more accurate.
In Equation (7),
means the Intersection and juxtaposition ratio of predicted and true frames. As shown in
Figure 9, we use two different colors of boxes to represent the ground truth boxes and the predicted boxes,
,
,
,
represent the width and height of the ground truth boxes and predicted boxes, respectively.
represents the Euclidean distance between the center point of the predicted box and the center point of the ground truth box.
represents the length of the diagonal of the smallest enclosing box that contains both the predicted box and the ground truth box.
represents the weight parameter used to balance the impact of the aspect ratio.
represents the consistency measure of the aspect ratio.
For classification loss, the classification loss (CLoss) measures the difference between the predicted and true categories of the target within each predicted box. The Binary Cross-Entropy Loss (BCEloss) is used to calculate the classification loss.
In Equation (8), represents the total number of categories. represents the true label of class c (0 or 1). represents the predicted probability of class c.
For Objectness Loss (OLoss), the objectness loss measures the difference between the predicted confidence and the true confidence regarding whether each predicted box contains a target.
In Equation (9), represents true confidence (1 if the target is present, otherwise 0). is the predicted confidence.
The final total loss function (TLoss) is obtained by weighting and combining the three aforementioned loss components:
In Equation (10), , and represent the weight coefficients for the bounding box regression loss, classification loss, and objectness loss, respectively. In this experiment, the weights of the box regression loss, classification loss, and objectness loss are 0.05, 0.5, and 1.0, respectively.
5. Discussion
5.1. The Effectiveness of FSTD-Net
Targets in UAV images are more complex compared to those in natural images due to significant scale variability and complex background conditions. Target detection models suitable for natural images, such as the YOLO series of neural networks, cannot be directly applied to UAV images. To address this issue, we designed FSTD-Net, providing some insights on how to adapt models such as the YOLO series for use in UAV image detection.
Overall, the structure of FSTD-Net is essentially consistent with the YOLO series, including the backbone, neck, and head parts, maintaining a relatively lightweight structure. Its parameter count is 11.3M, which is roughly equivalent to that of YOLOv8s. However, compared to the YOLO series of neural networks, FSTD-Net is better suited for UAV image detection tasks.
Experimental results on the VisDrone 2019 and UAVDT datasets demonstrate that the methods proposed in this paper can enhance the applicability of the YOLO model for detection tasks involving UAV images. Additionally, we conducted further experiments on the general datasets VOC2007 and VOC2012. Experiments on the general datasets indicate that the proposed methods can also improve the baseline’s detection performance on natural images. Overall, FSTD-Net not only performs well on UAV image datasets but also achieves commendable results on general datasets.
5.2. The Impact of Image Resizing and Cropping on Target Detection Performance
We further conduct the experiments on VisDrone 2019, we cropped the train, test, and val sets into images of 640 × 640 pixels. The original training set contained 6471 images, and after cropping, the number of images in the training set increased to 44,205. We then compared the results of training on two datasets: one with the original images resized to 640 × 640, containing 6471 images, and the other with the cropped images, containing 44,205 images. FSTD-Net was trained for 80 epochs on both datasets. The detection results are shown in
Table 12.
As shown in
Table 12, it can be observed that the detection performance on the datasets with cropping methods is significantly better across all metrics compared to the performance on the datasets with resizing methods. On one hand, the cropping operation increases the number of data samples in the training set, allowing the network to undergo more iterations during training, which leads to improved detection performance on the cropped dataset. On the other hand, resizing methods change the original shape of the targets in the UAV images, which may significantly degrade detection performance compared to the cropped dataset.
6. Conclusions
In this paper, to address the target scale variability and complex background interference presented in UAV images, we propose the FSTD-Net, which effectively detects multi-scale targets in UAV images and avoids interference caused by complex backgrounds. Firstly, to better capture the features of targets at different scales in UAV images, MSCIEM utilizes a multi-kernel combination approach, and the CIEM in MSCIEM can capture long-range contextual information. Due to MSCIEM, the model can effectively capture features of targets at different scales, perceive long-range contextual information, and be sensitive to significant variations in scale. Secondly, to further account for the targets of different shapes on different scales, FEFMDS breaks through the conventional method of feature extraction by standard convolution, providing a more flexible approach to learning full-scale targets of different shapes. The FEFMDS can better fit full-scale targets of different shapes in UAV images, providing more representative features for the final detection of FSTD-Net. Finally, LLFEB is used to efficiently utilize low-level semantic features, including edges, corners, and textures, providing a foundation for subsequent high-level feature extraction and guiding the model to better understand various target features. Experimental results demonstrate that FSTD-Net outperforms the selected state-of-the-art models, achieving advanced detection performance. FSTD-Net achieves better detection results in terms of overall detection accuracy while maintaining a relatively lightweight structure. In the future, we will further explore more efficient and lightweight target detection models to meet the requirements for direct deployment on UAVs.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}