1. Introduction
With the continuous development and popularization of digital technology, 3D point cloud data are increasingly applied in various fields, especially in object recognition [
1,
2], scene segmentation [
3,
4], pose estimation [
5,
6], etc. The Terracotta Warriors, as outstanding representatives of ancient Chinese culture, attract scholars, researchers, and cultural enthusiasts worldwide due to their immense historical and cultural value. With the development of digital technology, the 3D scan data of the Terracotta Warriors are increasing, and how to effectively use these data for classification and analysis has become an urgent problem. Traditional methods for classifying Terracotta Warriors primarily rely on manually designed features and traditional machine learning algorithms, which often require substantial human and time costs and are sensitive to data quality and feature selection, making it difficult to adapt to large-scale and diverse Terracotta Warriors data.
In point cloud classification tasks, traditional methods often use feature extraction and machine learning, implementing classification through manually designed feature extraction operators and classifiers. However, this approach often requires substantial human effort and experience, and it is challenging to fully exploit the features of point cloud data, resulting in low classification accuracy and robustness. Therefore, designing an automated, efficient, and accurate point cloud classification method has become a research hotspot [
7,
8,
9,
10,
11].
To address these issues, a series of deep learning methods have emerged in recent years, such as PointNet [
12], PointNet++ [
13], DGCNN [
14], etc. These methods extract features directly from the raw point cloud data through end-to-end learning and use deep neural networks for classification. Although these methods have achieved certain results, they still have problems such as insufficient utilization of local geometric information and inadequate handling of multi-scale information.
With the development of deep learning, the Transformer has become a powerful sequence modeling tool and has achieved significant success in natural language processing. Transformer is capable of extracting global features from the entire point cloud, rather than just local features, which is very helpful for understanding the overall structure of the point cloud. Recently, the Transformer has been successfully applied to images, audio, etc., achieving a series of breakthroughs [
15,
16]. However, so far, the application of Transformer in point cloud data processing is still limited and has not fully realized its potential [
17,
18,
19,
20].
Besides the Transformer, the Mamba model has also been proposed as a powerful sequence modeling tool, achieving certain results in fields such as natural language processing [
21,
22,
23]. The Mamba model can effectively capture long-range dependencies between sequence data and has good sequence modeling capabilities. However, the application of the Mamba model in point cloud data processing is also relatively rare and has not been fully utilized.
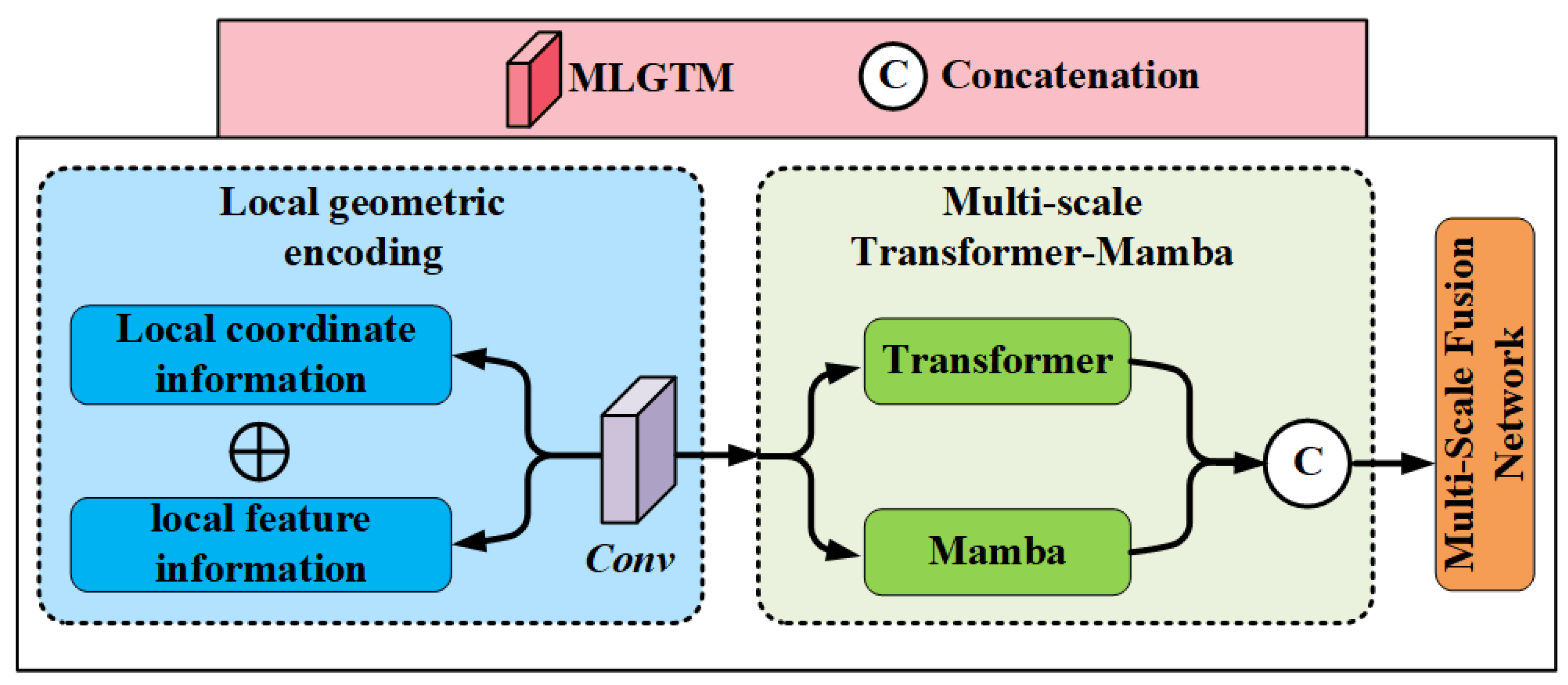
To address these issues, this paper proposes a method called Multi-scale Local Geometric Transformer-Mamba (MLGTM) application in the classification task of Terracotta Warriors point clouds. Specifically, we apply the Transformer and Mamba models to the feature extraction and classification process of point cloud data, utilizing their powerful sequence modeling capabilities to achieve global feature modeling and information interaction of point cloud data. At the same time, we combine local geometric encoding methods to fully exploit the local geometric features of point cloud data, improving classification accuracy and robustness.
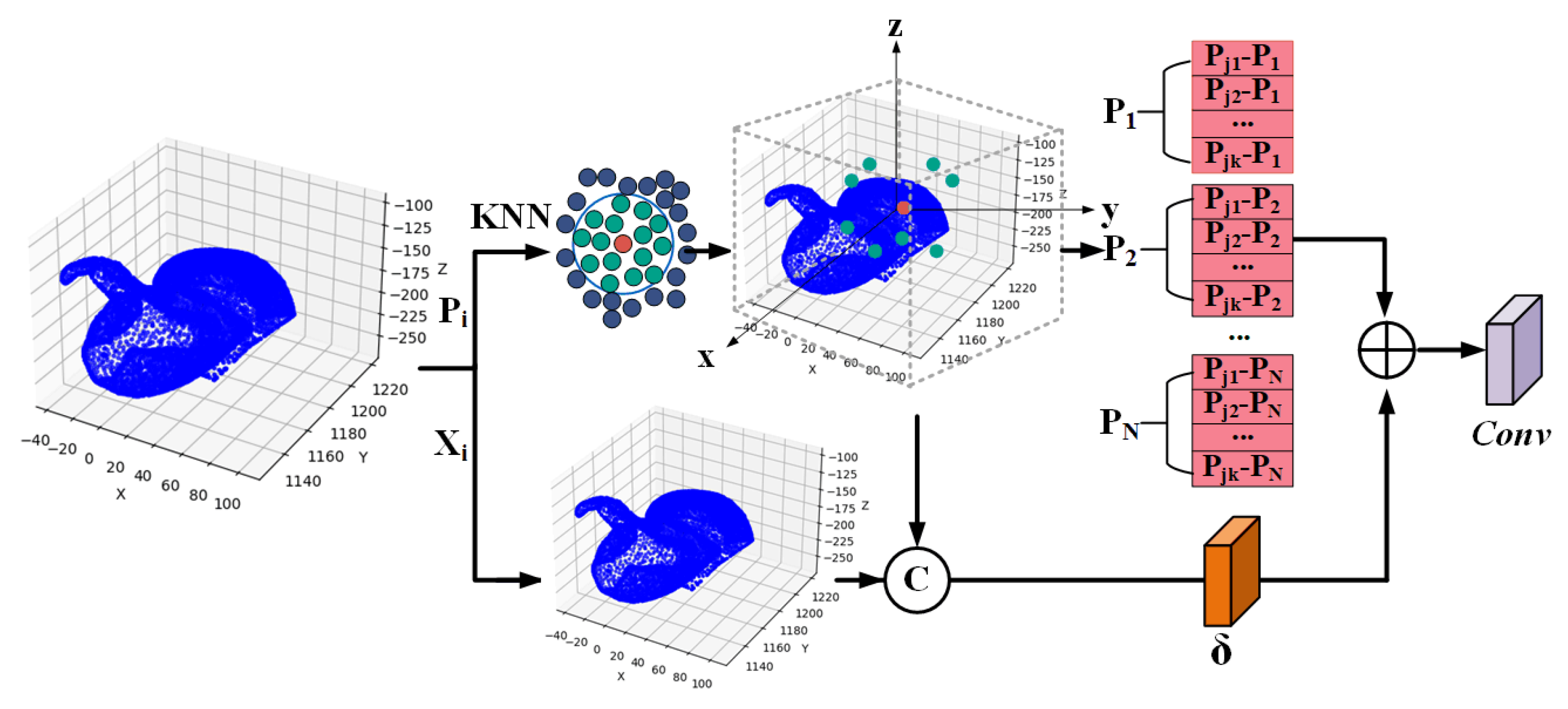
Local Geometric Encoding:Local geometric encoding includes local coordinate information and local feature information. For each point, we select its surrounding neighboring points as local information and calculate their relative positions with respect to the center point, as well as the attributes of each point and its nearest neighbors. This method effectively captures the complex local morphology and structural variations of the Terracotta Warriors, improving classification accuracy and robustness.
Multi-scale Transformer-Mamba: The multi-scale information interaction module inputs local geometric encoding into a dual-branch Transformer-Mamba network and aggregates multi-scale Transformer and Mamba information to achieve local–local and local–global information interaction. This method effectively improves point cloud classification performance, especially when dealing with the sparsity and irregularity of Terracotta Warriors point cloud data, as well as complex scenes and large-scale data, demonstrating good adaptability and generalization ability.
In the experimental section, we validate our proposed method on several commonly used point cloud datasets, including the ModelNet40, ScanObjectNN, ShapeNetPart, ETH, and 3D Terracotta Warriors fragment datasets. The experimental results show that, compared with traditional classification methods, our method significantly improves classification accuracy and robustness, especially when processing Terracotta Warriors point cloud data.
2. Related Work
Feature Learning-based Methods: Feature learning-based methods aim to use deep learning techniques to learn meaningful feature representations from point cloud data. Traditional point cloud deep learning models, such as those based on PointNet architecture and graph convolutional neural networks, mainly focus on local geometric structures. However, due to the high complexity and unstructured nature of the point cloud data of the Terracotta Warriors, this task is extremely challenging.
To address the issues of time-consuming and labor-intensive traditional, manual-based classification methods application in Terracotta Warriors, which heavily rely on archaeologists’ expertise, Yang et al. [
24] propose a novel 3D Terracotta Warriors fragment classification framework. At its core is a dual-modal neural network that integrates both geospatial and texture information of the fragments to output their respective categories. Geospatial information is directly extracted from the point cloud, while texture information is extracted using a method based on 3D mesh models and an improved Canny edge detection algorithm.
To address the issue of insufficient accuracy of PointNet++ in point cloud understanding, PointNeXt [
25] introduces a set of improved training strategies, significantly enhancing the overall accuracy in object classification tasks. Additionally, it incorporates an inverted residual bottleneck design and separable MLPs to achieve efficient and effective model scaling. This algorithm demonstrates superior performance in 3D classification and segmentation tasks.
To address the classification problem of unstructured 3D point clouds, Huang et al. [
26] proposed a global–local graph attention convolutional neural network method. This method introduces a graph attention convolution module, where the global attention module analyzes spatial relationships between all points, while the local attention module dynamically learns convolution weights of local neighborhood points and reweights the convolution weights based on the density of the local region.
To further improve the robustness of the model, Li et al. [
27] proposed an innovative point anomaly removal method using the capabilities of downstream classification models. This method draws on tail risk minimization methods in finance, rephrasing the anomaly removal process as an optimization problem.
To better classify the Terracotta Warriors by recognizing facial features, Sheng et al. [
28] proposed an enhanced SqueezeNet model, replacing the initial convolution kernels and improving the FaceNet backbone feature extraction network. The feature extraction layer of this model is composed of alternating convolution layers, pooling layers, Fire modules, and pooling layers, with the introduction of an exponential function to smooth the shape of the loss function. Finally, Agglomerative Clustering is used for the facial classification of the Terracotta Warriors. This method meets the requirements for facial recognition and classification of the Terracotta Warriors.
Transformer-based Methods: Compared with traditional CNN methods, Transformers can better capture global dependencies among point cloud data, making them suitable for irregular shapes and sparsely distributed point cloud data, which facilitates the handling of the sparse distribution and complex structure of Terracotta Warriors data. Inspired by the success of self-attention networks in natural language processing and image analysis, Zhao et al. [
29] proposed a self-attention layer for point clouds and used these layers to construct self-attention networks for semantic scene segmentation, object part segmentation, and object classification tasks.
To address the issue of low accuracy in traditional Terracotta Warriors classification, Liu et al. [
30] propose an attention-based multi-scale neural network named AMS-Net. This network includes a multi-scale set abstraction block (MS-BLOCK) and a fully connected (FC) layer. The MS-BLOCK consists of a local–global layer (LGLayer) and an improved multi-layer perceptron (IMLP). Using a multi-scale strategy, LGLayer can simultaneously extract local and global features from different scales. IMLP concatenates high-level and low-level features for classification tasks. The results demonstrate that this method achieves high accuracy in classifying Terracotta Warriors fragments.
To address the issues of location information leakage and uneven information density in point cloud self-supervised learning, Point-MAE [
31] proposes a neat masked autoencoding scheme for point cloud self-supervised learning. The specific method involves dividing the input point cloud into irregular point patches and randomly masking them at a high ratio. Then, a standard Transformer-based autoencoder learns high-level latent features from the unmasked point patches, aiming to reconstruct the masked point patches. The results show that this method is efficient during the pre-training phase and generalizes well to various downstream tasks, improving the state-of-the-art accuracy in classification tasks by 1.5%–2.3%.
To address the problem of generalizing the concept of Masked Point Modeling (MPM) to 3D point clouds, Point-BERT [
32] pre-trains point cloud Transformers by designing an MPM task. Specifically, the method involves dividing the point cloud into local patches, generating discrete point tokens through a discrete Variational AutoEncoder (dVAE), and randomly masking some of the input point cloud patches. These masked patches are then fed into the backbone Transformer with the goal of recovering the original point tokens at the masked locations under the supervision of the tokenizer-generated point tokens. The results show that this pre-training strategy significantly enhances the performance of standard point cloud Transformers, achieving high accuracy on ModelNet40 and ScanObjectNN, demonstrating good transferability and advancements in point cloud classification tasks.
Due to the irregularity and disorder of point clouds, adopting a 3D Transformer to improve point cloud processing brings significant computational and memory costs. To address this issue, Lu et al. [
33] proposed a hierarchical framework combining convolution and Transformer for point cloud classification. This method combines the powerful local feature learning capabilities of convolution with the excellent global context modeling capabilities of Transformer. The main module of this method operates on downsampled point sets, with each module including a multi-scale local feature aggregation block and a global feature learning block implemented through graph convolution and Transformer, respectively.
Unlike most existing methods focusing on local spatial attention, PointConT [
34] leverages the locality of points in feature space, clustering sampling points with similar features into the same category and computing self-attention within each category to balance capturing long-range dependencies and computational complexity. Additionally, an Inception feature aggregator for point cloud classification uses a parallel structure to aggregate high-frequency and low-frequency information in each branch.
For the feature learning difficulties caused by the irregularity and disorder of point clouds, Zhou et al. [
35] proposed a hierarchical local–global framework based on Transformer networks. This method uses two parallel branches in the local feature extraction module: the Transformer branch and the shared multi-layer perceptron branch, designed to learn the related features between any two points and the local high-dimensional semantic features between sampling center points and their neighborhoods. The global feature extraction module consists of a center point contact module and a global point cloud Transformer layer, improving the effectiveness of global feature extraction without increasing parameters and computation.
Mamba-based Methods: Inspired by the success of the Mamba model in achieving fast inference and linear sequence length extension, recent research has extended it to 3D point cloud tasks [
36,
37]. The Transformer has become a fundamental architecture in point cloud analysis tasks due to its excellent global modeling capabilities, but its attention mechanism has quadratic complexity, making it challenging to scale to long sequence modeling. To address this issue, Liang et al. [
38] proposed the PointMamba framework, aiming to improve point cloud analysis tasks through global modeling and linear complexity. This method embeds point patches as input and proposes a reordering strategy to provide a more logical geometric scan order to enhance the global modeling capabilities of the SSM. The reordered point tokens are sent to a series of Mamba modules to gradually capture the point cloud structure.
To more effectively process 3D point cloud data, Zhang et al. [
39] proposed a consistent traversal serialization method that converts the point cloud into a 1D point sequence while ensuring that neighboring points in the sequence are also adjacent in space. This method generates six variants by arranging the x, y, and z coordinates in different orders. To better handle point sequences with different orders, point hints are introduced to inform the Mamba sequence’s arrangement rules, combined with position encoding based on spatial coordinate mapping, to better inject positional information into the point cloud sequence.
Although SSM performs well in language and image fields with linear complexity and long sequence modeling capabilities, extending it to point cloud fields is not easy due to the unordered and irregular nature of point clouds and the causality requirement of SSM. To build causal dependencies, Liu et al. [
40] proposed an octree-based sorting strategy, operating on the original irregular points, performing global sorting by z-order while maintaining spatial adjacency.
Inspired by feature learning for irregular, complex spatial structures; the generalization ability of Transformer learning methods for different scenarios; and the success of the Mamba model in achieving fast inference and linear sequence length extension, we propose a Multi-Scale Local Geometric Transformer-Mamba point cloud classification method.
4. Experiments
4.1. Dataset, Implementation Details, and Evaluation Metrics
Dataset: In this section, we evaluated the proposed Multi-Scale Local Geometric Transformer-Mamba (MLGTM) model on multiple datasets to validate its performance and generalization ability. Below is a brief overview of the main datasets used in the experiments:
ModelNet40: ModelNet40 [
41] is a 3D model classification dataset consisting of CAD models, containing 40 categories of models from common object categories such as chairs, tables, airplanes, etc.
ScanObjectNN: ScanObjectNN [
42] is a real-world 3D scanning dataset containing 15 object categories, with multiple scan sequences per category, totaling approximately 1500 scan sequences.
ShapeNetPart dataset: ShapeNetPart [
43] is a dataset for object part segmentation, containing 16 object categories, each with multiple models and corresponding part annotations, totaling approximately 16881 point cloud models.
ETH: The core of the ETH [
44] dataset consists of 3D laser point clouds, primarily composed of vegetation (trees, gazebo, shrubs, etc.). The only structured element is a small paved path that runs through the forest. The scanner path starts in the forest, continues with approximately 12 scans, and then merges into the path.
Three-Dimensional Terracotta Warriors fragment dataset: The 3D Terracotta Warriors fragment dataset is specifically designed for Terracotta Warriors point cloud processing. The point cloud models of the Terracotta Warriors fragments were obtained using the Artec EVA 3D Scanner handheld 3D scanner. This dataset includes point cloud models from different parts of the Terracotta Warriors, covering various poses and details. In this experiment, we extracted 11,996 point cloud fragments from 40 complete Terracotta Warriors to train the network. For the Terracotta Warriors fragment dataset, there are four categories: Arm, Body, Head, and Leg. Among them, 10,144 fragments are used for training (Arm: 2656, Body: 2720, Head: 2272, Leg: 2496) and the remaining 1852 for testing (test Arm: 476, test Body: 504, test Head: 428, test Leg: 444).
Implementation Details: To ensure fairness in the experiments, we used consistent settings for training, testing, and validation hyperparameters across each dataset. We adopt the Stochastic Gradient Descent (SGD) method, and the SGD optimizer trains for 350 epochs. The initial learning rate of the SGD optimizer is set to 0.01, the weight decay is 0.0002, and the dropout rate is set to 0.5. The batch size for all training models is set to 32. Additionally, we implemented the proposed algorithm using the PyTorch language and deployed it for training on a system with an Nvidia RTX 4090, Intel(R) Core(TM) i7-13700KF CPU @ 3.40 GHz, and 128 GB RAM running Windows 10.
Evaluation Metrics: In the experiments, we used metrics such as mean accuracy within each category (mAcc), overall accuracy (OA), mean class Intersection over Union (mcIoU), mean instance Intersection over Union (mIoU), Parameter, FLOPs, and Throughput to evaluate the effectiveness of the algorithm. The detailed definitions of Parameter, FLOPs, and Throughput are as follows.
Parameter: The Parameter refers to the total number of trainable weights and biases in a model. It determines the model’s complexity and expressive power. Assuming
represents all model parameters, and
denotes the number of parameters in the
i-th layer of the network, Parameter is defined as
FLOPs: FLOPs (Floating Point Operations Per Second) refers to the total number of floating-point operations executed by a model during one forward and backward pass. It reflects the computational complexity of the model. Assuming that
represents the number of operations in each layer
i, the total FLOPs is defined as
Throughput: Throughput refers to the amount of data processed by a model per unit of time, measured in this study as the number of point cloud fragments processed per second. Throughput reflects the operational efficiency of the model in practice. Assuming the model processes
N samples in
T seconds, the throughput is defined as
4.2. Classification Based on ModelNet40 Dataset
We evaluated the performance of the proposed model algorithm on the ModelNet40 dataset using the mean accuracy within each category (mAcc) and the overall accuracy (OA) across all categories. Additionally, we compared the proposed algorithm with other state-of-the-art algorithms on the ModelNet40 dataset, such as PointNet [
12], PointCNN [
45], PointNet++ [
13], DGCNN [
14], PointNeXt [
25], Point-MAE [
31], Point-BERT [
32], OctFormer [
46], PCM [
39], and PointMamba [
38].
Figure 5 shows visualizations for the ModelNet40 dataset.
From
Table 1, it can be seen that the proposed algorithm not only achieves significant improvements in accuracy on the ModelNet40 dataset compared with other outstanding algorithms but also exhibits greater efficiency. Additionally, compared to the PCM, OctFormer, and Point-BERT algorithms, we have increased the overall accuracy by 0.8, 1.1, and 0.7, respectively.
4.3. Classification Based on ScanObjectNN Dataset
We continue to evaluate the performance of the proposed model algorithm on the ScanObjectNN dataset using mAcc and OA. Additionally, we compare the proposed algorithm with other state-of-the-art algorithms on the ScanObjectNN dataset, such as PointNet, PointCNN, PointNet++, DGCNN, Point-MAE, Point-BERT, TNPC [
35], and PointMamba.
From
Table 2, it can be observed that the proposed algorithm achieves significant improvements in accuracy on the ScanObjectNN dataset compared to other outstanding algorithms. Additionally, compared to the PointMamba, TNPC, and Point-BERT algorithms, we have increased the overall accuracy by 1.3, 4.8, and 3.1, respectively.
4.4. Part Segmentation
We use the mean class Intersection over Union (mcIoU) and mean instance Intersection over Union (mIoU) to evaluate the performance of the proposed model algorithm on the ShapeNetPart dataset. Additionally, we compare the proposed algorithm with other state-of-the-art algorithms on the ShapeNetPart dataset, such as PointNet, PointCNN, PointNet++, DGCNN, PointNeXt, Point-MAE, 3DGTN [
47], MNAT-Net [
48], and PointMamba.
From
Table 3, it is evident that the proposed algorithm achieves significant improvements in accuracy on the ScanObjectNN dataset compared to other outstanding algorithms. Additionally, compared to the PointMamba, Point-MAE, and PointNeXt algorithms, we have increased the mIoU by 0.9, 0.8, and 0.2, respectively.
4.5. ETH Dataset
To validate the performance of our proposed algorithm in complex scenes such as forests and gazebos, we conducted experiments using the ETH dataset. We evaluated the model algorithm’s performance on the ETH dataset using Overall Accuracy (OA). Additionally, we compared our proposed algorithm with other algorithms on this dataset, such as PointNet and DGCNN.
Figure 6 depicts the classification visualization results.
From
Table 4, it can be seen that the proposed algorithm achieves significant improvements in accuracy on the ETH dataset. Additionally, compared to the PointNet and DGCNN algorithms, our overall accuracy improved by 8.08 and 0.67, respectively.
Figure 6 depict the classification of gazebos in summer and dynamic settings, as well as tree classification in summer and autumn. It is evident that our proposed algorithm performs well in complex structures and scenes, demonstrating good accuracy.
4.6. Cultural Heritage Dataset
Unlike the previous datasets, to validate the performance of the model algorithm on cultural heritage data, we conducted experiments using the 3D Terracotta Warriors fragment dataset. We used the overall accuracy (OA) to evaluate the performance of the proposed model algorithm on the Terracotta Warriors fragment dataset. Additionally, we compared the proposed algorithm with other outstanding algorithms on this dataset, such as PointNet, DGCNN [
14], Yang et al. [
24], AMS-Net [
30], and UMA-Net [
49].
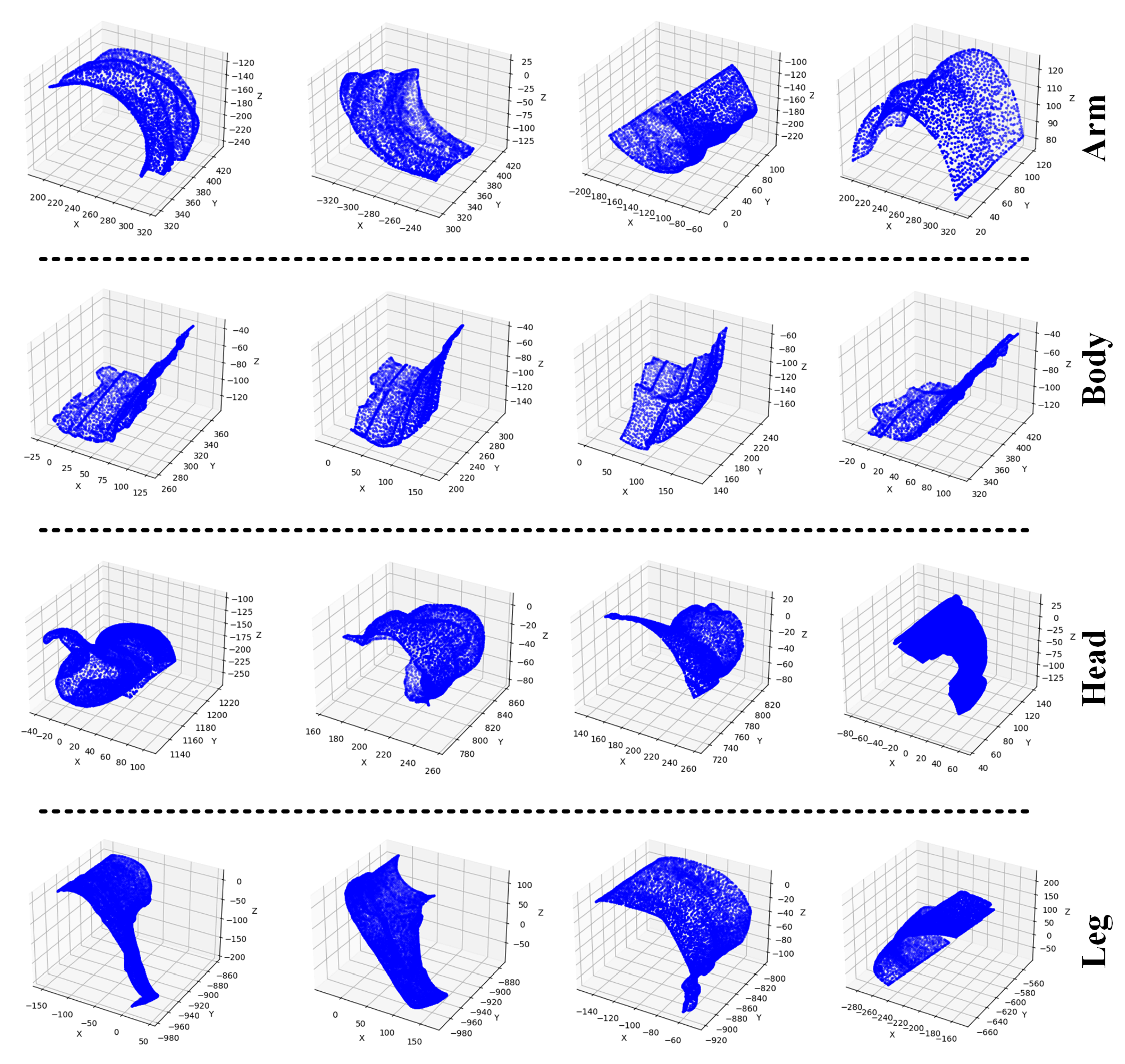
Figure 7 shows visualizations for the 3D Terracotta Warriors fragment dataset.
From
Table 5, it can be seen that the proposed algorithm not only achieves significant improvements in accuracy on the 3D Terracotta Warriors fragment dataset compared to other outstanding algorithms but also exhibits greater efficiency. Additionally, compared to UMA-Net, AMS-Net, and PointNet algorithms, we have increased the overall accuracy by 2.03, 0.25, and 7.0, respectively.
4.7. Ablation Study
To validate the effectiveness of our proposed method and the contributions of each module, we designed and conducted ablation experiments on the ModelNet40 dataset. By gradually removing key components in the modules, we were able to assess the impact of each part on overall performance. These experiments aim to demonstrate the importance of local geometric encoding, the feature extraction modules (Mamba and Transformer), and the contribution of multi-scale analysis to point cloud classification tasks.
In
Table 6, Feature infor. represents feature information only; Coordinate infor. represents coordinate information only; and F+C represents both feature and coordinate information, utilizing the local geometric encoding method. Mamba only represents Mamba operation only; Transformer only represents Transformer operation only; and M+T represents both Transformer and Mamba operations, utilizing the dual-branch Transformer-Mamba network. Multi-scale refers to the Multi-Scale Fusion Network. It can be observed that in the comparison of Local Geometric Encoding, F+C outperforms feature information only or coordinate information only. This indicates that local geometric encoding effectively captures the complex local morphology and structural variations of the Terracotta Warriors, extracting representative local features. In the comparison of Feature decisions, M+T performs better than Mamba only or Transformer only. Regarding multi-scale analysis, the multi-scale model outperforms the non-multi-scale model. This demonstrates that the multi-scale information interaction module exhibits superior performance in handling the sparsity and irregularity of Terracotta Warriors point cloud data, as well as in complex scenes and large-scale data scenarios.
Number of Neighbors: For the experiment on the number of nearest neighbors: Under uniform parameter settings, all networks were trained using 1k points as input points. For the ModelNet40 dataset, this paper randomly selected a series of representative numbers of nearest neighbors ranging from 8 to 40 for comparative testing experiments, with results shown in
Table 7. For the ScanObjectNN dataset, this paper randomly selected a series of representative numbers of nearest neighbors ranging from 16 to 40 for comparative testing experiments, with results shown in
Table 8.
From
Table 7 and
Table 8, it can be observed that when the number of nearest neighbors
k is 24, the model demonstrates better performance. As the number of nearest neighbors decreases within a certain range, the visual perception field is also limited, leading to a decrease in performance. However, when the number of neighbors reaches a certain level, with an increase in the nearest neighbors, adjacent local information also gets incorporated, leading to a decline in performance.
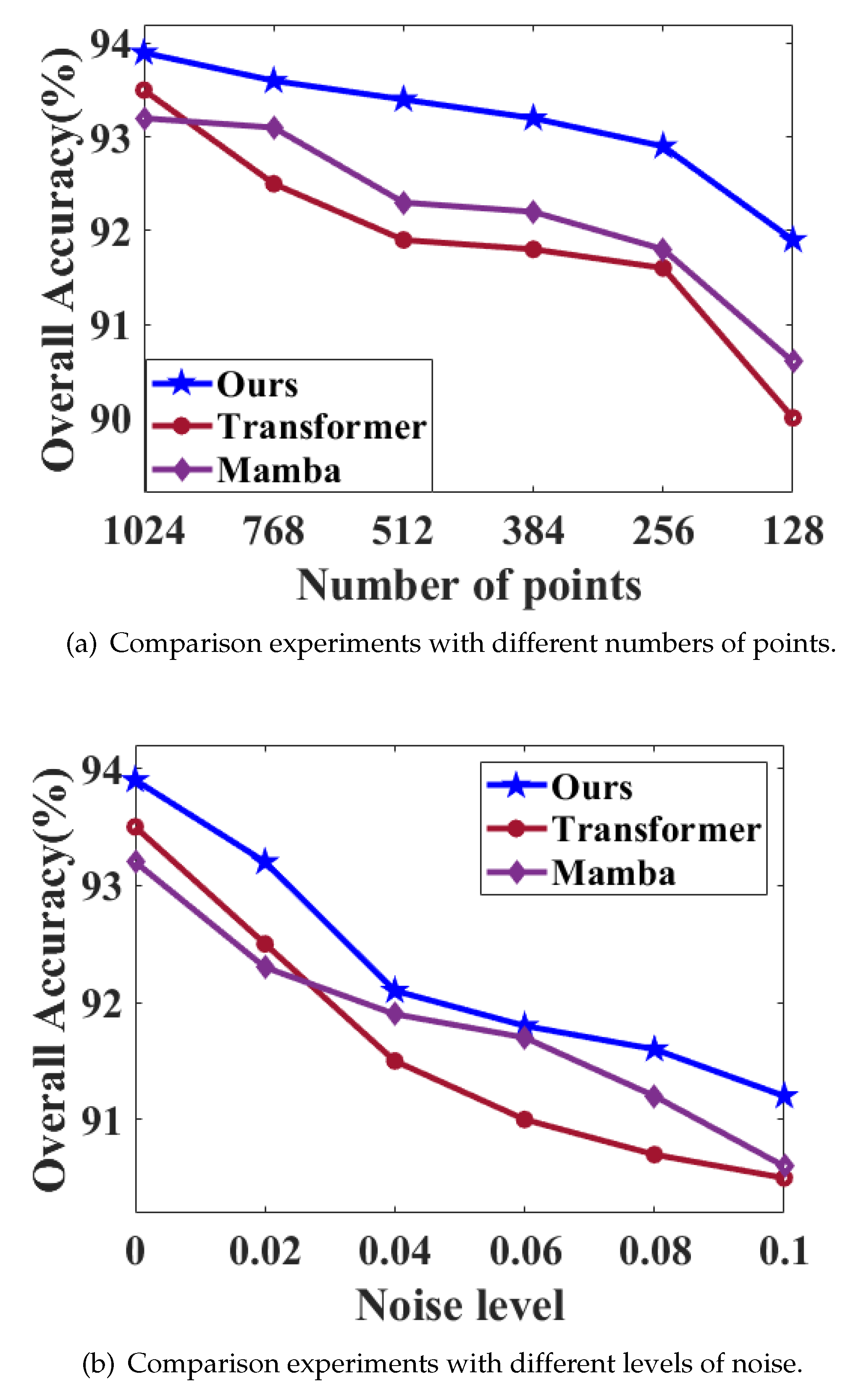
4.8. Robustness Study
In order to evaluate the robustness of the proposed model, we conducted point cloud density and noise test experiments on the ModelNet40 dataset.
For point cloud density and noise experiment, under the premise of unified parameter settings, the neighborhood size is set to
k = 24. To test the influence of point cloud density, a series of points were deleted randomly during the test. In this paper, a series of points from 128 to 1024 were selected randomly. The scatter diagram is shown in
Figure 8. For noise testing, we introduce additional Gaussian noise based on the standard deviation of the point cloud radius. The point cloud density and noise experiment results are shown in
Figure 9.
It can be seen from
Figure 9 that, compared with other structural models, the model proposed has better robustness in point cloud experiments.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}