
A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance

Abstract
1. Introduction
2. Datasets and Features
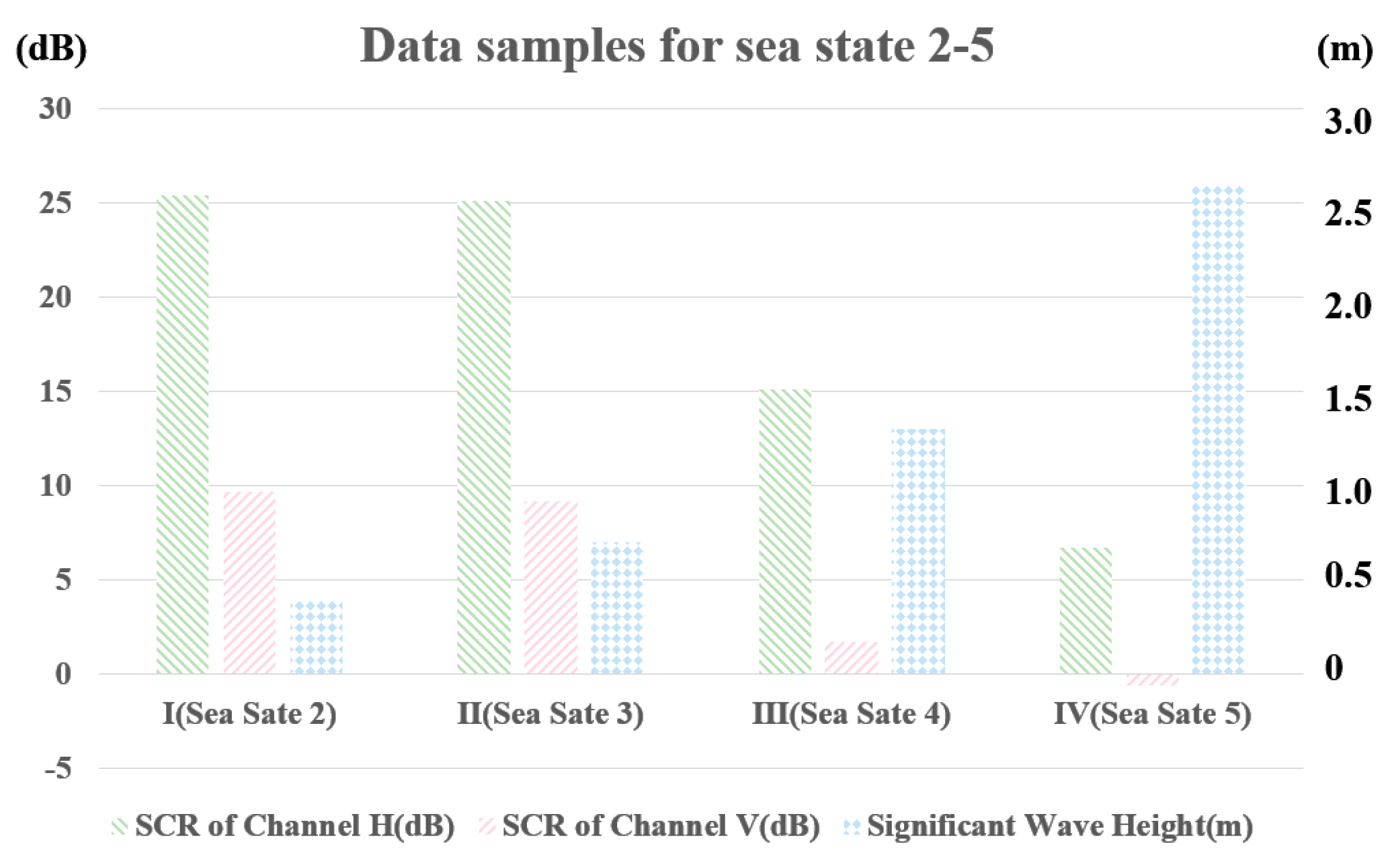
2.1. Description of the Measured Experimental Data
2.2. Description of the Significant Features
2.2.1. Features in the Time Domain
- Relative Average Amplitude [8]: RAA is defined as the ratio of the average amplitude of the CUT to that of the RCs, and it is used to measure the amplitude difference between the CUT and the RCs, as shown in (2):where and are abbreviations of and .
- Time Domain Entropy Mean [30]: TEM is defined as the average entropy of the echo at the CUT. Due to the differing fluctuations in the echoes, it reflects the level of disorder in the waveforms of the target and sea clutter signals. Using a wide rectangular window and an S wide step, slide the echo signal at the CUT to obtain time-domain short sequences with a length of . The calculation is shown in (7).where represents rounding up, and represents the time-domain entropy value of the i-th short sequence .
- Relative Peak Height: RPH is defined as the ratio of the peak amplitude of the pulse echo at the CUT to the average amplitude of adjacent pulses. This can be used to reflect the differences in energy proportion and peak fluctuations between the target and sea clutter echoes, as shown in (8):where represents the number of units in set , while and collectively specify the pulse range used in the ratio calculation.
2.2.2. Features in the Frequency Domain
- Relative Doppler Peak Height [8]: RDPH is defined as the ratio of the Doppler peak at the CUT to the average Doppler peak of the RCs. This can illustrate the differences in the proportion of energy at frequency peaks and the degree of abrupt changes between the two types of echoes. The calculation is shown in (10):where represents the pulse repetition period and is the Doppler frequency. indicates the number of channels in set , and and together define the range of Doppler channels involved in the ratio calculation.
- Relative Vector Entropy [8]: RVE is defined as the ratio of the information entropy between the CUT and the RCs, which reflects the level of disorder in the signal waveforms. The calculation is shown in (15).
- Second Moment of Frequency Domain Entropy: SOFE is defined as the variance of the entropy in the frequency domain at the CUT, reflecting the dispersion of entropy values across the series. The calculation is shown in (21).
2.2.3. Features in the Time-Frequency Domain
- Ridge Integration [9]: RI is defined as the cumulative value of time-frequency ridges in the spectrum of the CUT, reflecting the energy strength of the time-frequency ridges. The calculation is shown in (22):where represents the smoothed pseudo-Wigner–Ville distribution of the received sequence at the CUT.
- Maximal Size of Connected Regions [9]: MS is defined as the maximum number of threshold-exceeding points in each connected region in the binary time-frequency spectrum. The calculation is shown in (24):where represents one connected region in the set of connected regions , and is the number of time-frequency ridge points within the connected region .
- Number of Connected Regions [9]: NR is defined as the count of connected regions in the binary time-frequency spectrum, indicating the degree of dispersion of time-frequency ridge energy. The calculation is shown in (25).
2.2.4. Features in the Time-Frequency Ridge Transform Domain
- Ridges Radon Transform Maximum Value [31]: RRT-MV is defined as the maximum value in the time-frequency ridge transform domain. The calculation is shown in (26):where refers to the time-frequency ridge image of , is the angle parameter, is the distance parameter, and represents the Dirac function.
- Ridges Radon Transform Band Width [31]: RRT-BW reflects the dispersal of time-frequency ridge sequences along the radial coordinate axis and the concentration of ridge energy. The calculation is shown in (29):where represents the coordinates of the peak point , represents the number of coherent pulses, and is the preset bandwidth coefficient.
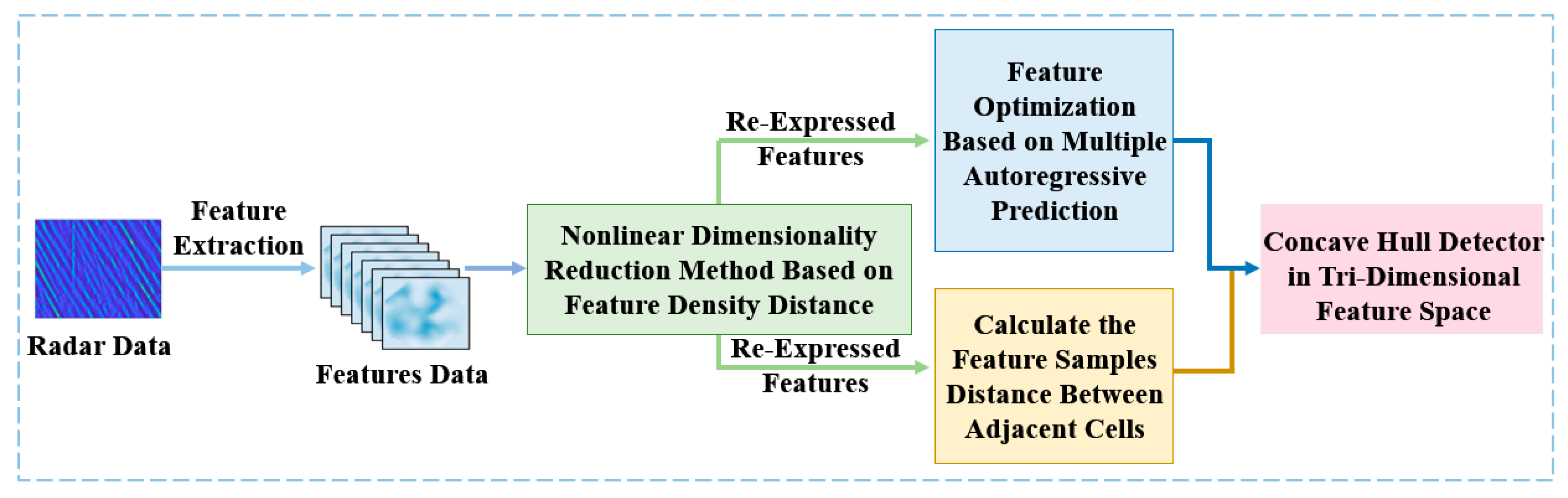
3. A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance
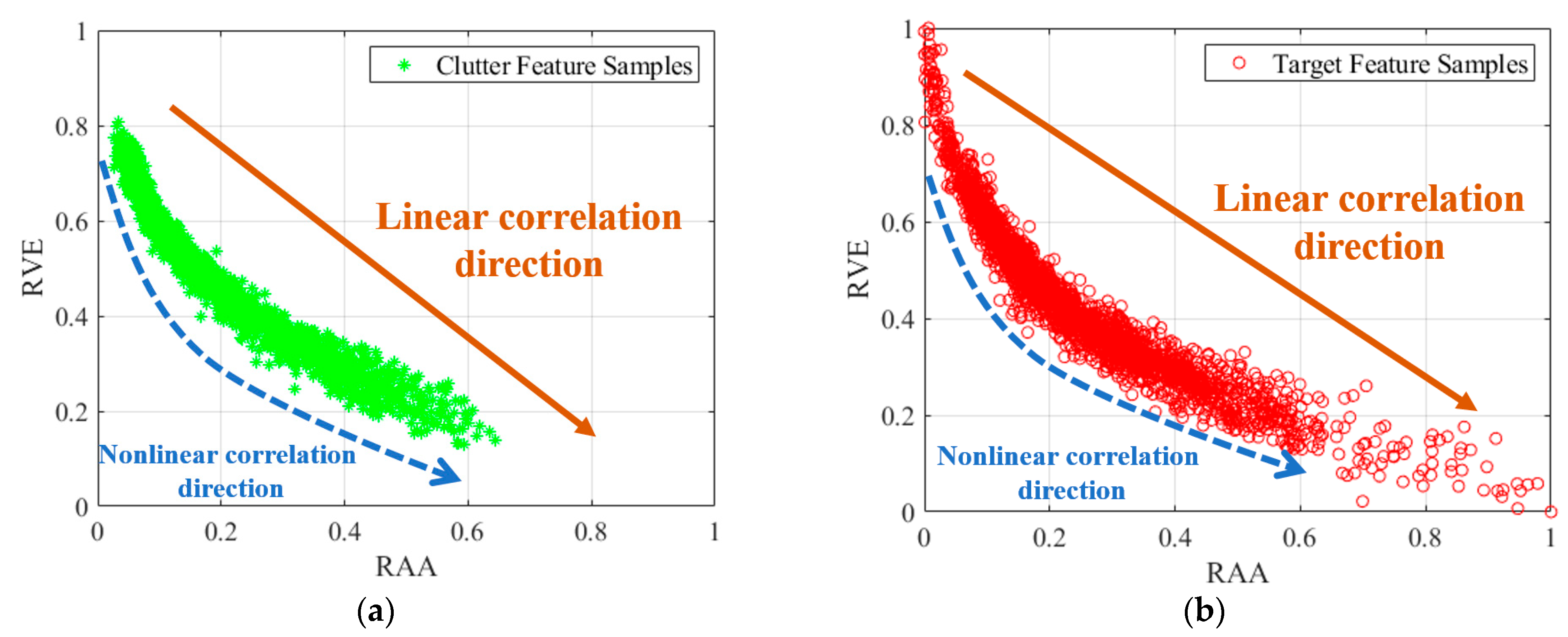
3.1. Analysis of the Correlations between Features
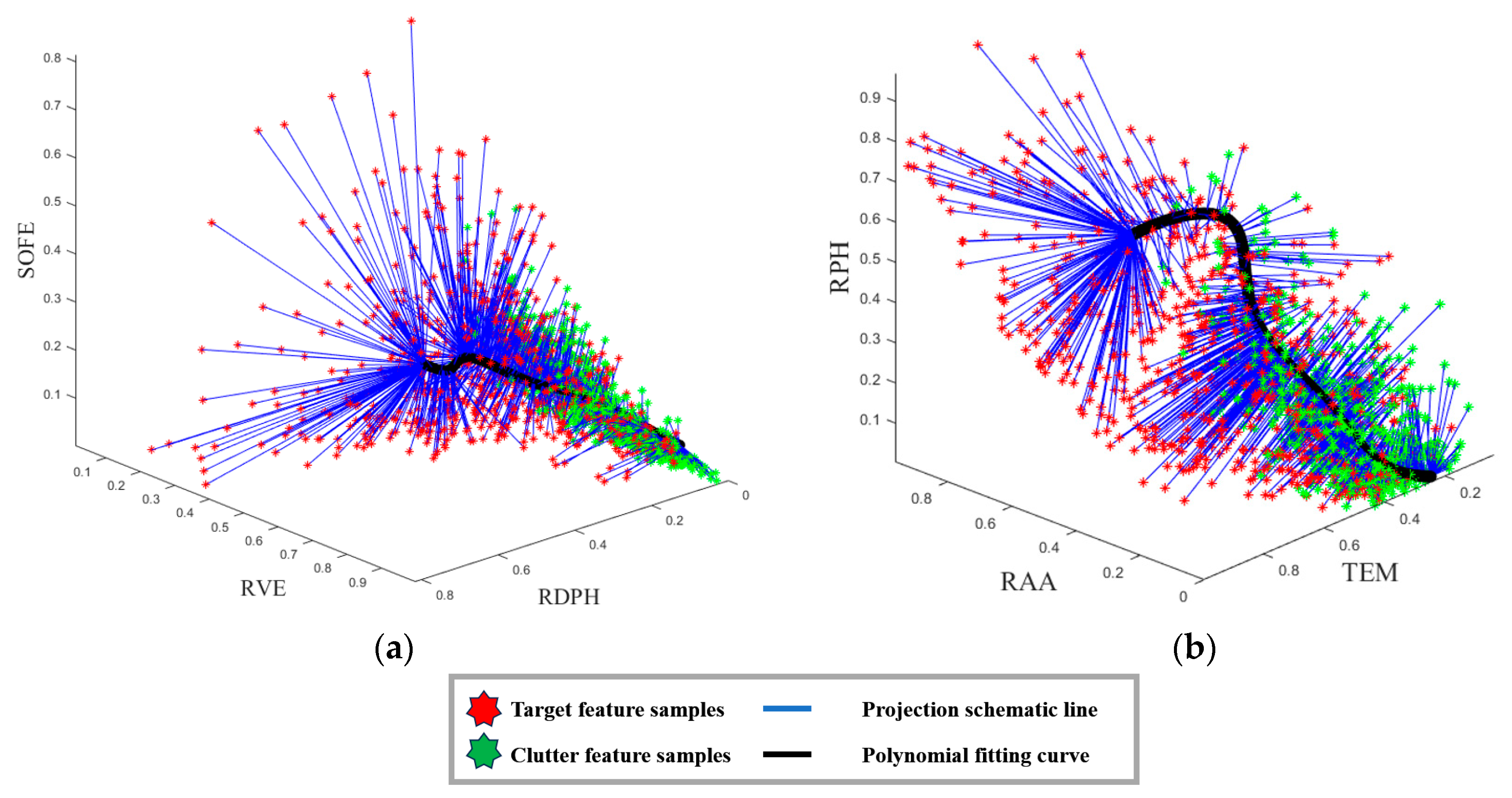
3.2. Nonlinear Dimensionality Reduction Method Using a Feature Density Distance Metric
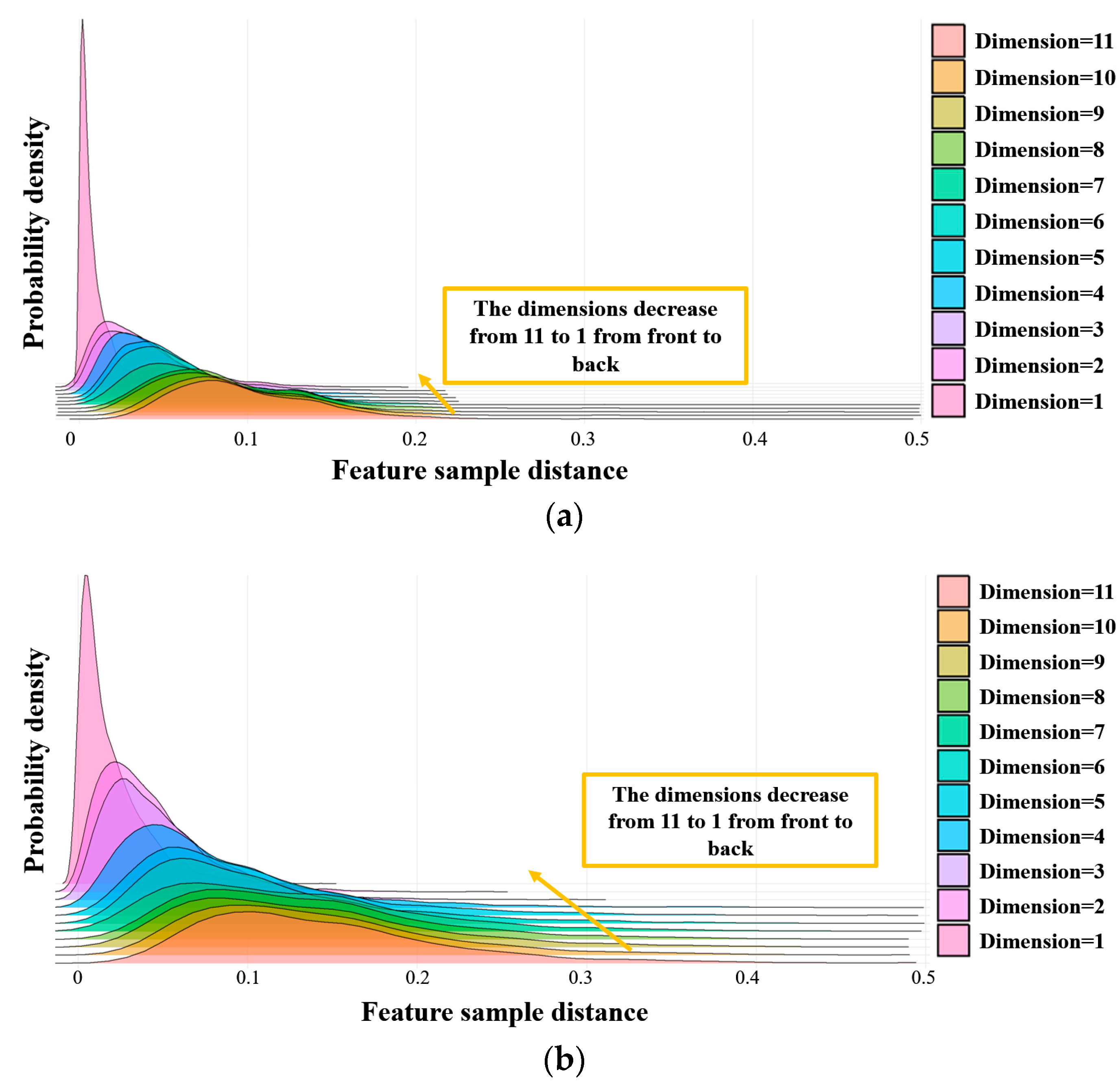
3.2.1. Feature Density Distance
3.2.2. Nonlinear Dimensionality Reduction Method Using a Lightweight Self-Attention Mechanism Network
3.3. Target Detector Based on Feature Sample Distance
3.3.1. Feature Sample Distance
3.3.2. Concave Hull Target Detector Based on Feature Sample Distance
- (1)
- Extract feature samples using historical frame sea clutter data from the same scene and re-express the features using the method proposed in Section 3.2 to obtain sample sequences of three new features.
- (2)
- Calculate and statistically analyze the feature sample distances of adjacent clutter samples, then sort these distances from largest to smallest. Multiply the false alarm probability factor by the sample quantity to select the corresponding index’s feature sample distance as the distance threshold . Here, the preset false alarm probability factor for sample feature distance is 10−3.
- (3)
- Construct the concave hull decision region using historical clutter feature samples after removing false alarm control vertices [19].
- (4)
- Extract the features of the current CUT and its adjacent RC, then perform nonlinear re-expression to obtain the sample sequences of three new features.
- (5)
- Calculate the feature sample distance between adjacent cells and compare it with the threshold . If the distance is less than the threshold, classify the CUT as clutter; if it is greater than the threshold, proceed to step (6) for further judgment.
- (6)
- Compare the relative position of the RC sample and the concave hull decision region in the three-dimensional feature space. If the RC sample is within the concave hull, classify the CUT as a target; if the RC sample is outside the concave hull, classify the CUT as clutter. This step is executed only if the feature sample distance in step (5) exceeds the threshold.
3.4. Feature Optimization Based on Multivariate Autoregressive Prediction
4. Performance Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Serafino, F.; Bianco, A. X-Band Radar Detection of Small Garbage Islands in Different Sea State Conditions. Remote Sens. 2024, 16, 2101. [Google Scholar] [CrossRef]
- Shui, P.L.; Zhang, L.X. Small Target Detection in Sea Clutter by Weighted Biased Soft-Margin SVM Algorithm in Feature Spaces. IEEE Sens. J. 2024, 24, 10419–10433. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, H. Detection Based on Semantics and a Detail Infusion Feature Pyramid Network and a Coordinate Adaptive Spatial Feature Fusion Mechanism Remote Sensing Small Object Detector. Remote Sens. 2024, 16, 2416. [Google Scholar] [CrossRef]
- Xiong, G.; Wang, L. Radar Sea Clutter Reconstruction Based on Statistical Singularity Power Spectrum and Instantaneous Singularity Exponents Distribution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5687–5697. [Google Scholar] [CrossRef]
- Xu, S.W.; Wang, Z. Optimum and near-optimum coherent false alarm rate detection of radar targets in compound-Gaussian clutter with generalized inverse Gaussian texture. IEEE Trans. Aerosp Electron. 2022, 58, 1692–1706. [Google Scholar] [CrossRef]
- Shui, P.L.; Liu, M. Sub-band adaptive GLRT-LTD for weak moving targets in sea clutter. IEEE Trans. Aerosp. Electron. 2016, 52, 423–437. [Google Scholar] [CrossRef]
- Shi, S.N.; Shui, P.L. Detection of low-velocity and floating small targets in sea clutter via income-reference particle filters. Signal Process. 2018, 148, 78–90. [Google Scholar] [CrossRef]
- Shui, P.L.; Li, D.C. Tri-feature-based detection of floating small targets in sea clutter. IEEE Trans. Aerosp Electron. 2014, 50, 1416–1430. [Google Scholar] [CrossRef]
- Shi, S.N.; Shui, P.L. Sea-surface floating small target detection by one-class classifer in time-frequency feature space. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6395–6411. [Google Scholar] [CrossRef]
- Xie, J.; Xu, X. Phase-feature-based detection of small targets in sea clutter. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Guo, Z.X.; Shui, P.L.; Bai, X.H. Small target detection in sea clutter using all-dimensional Hurst exponents of complex time sequence. Digit. Signal Process 2020, 101, 102707. [Google Scholar] [CrossRef]
- Li, D.C.; Shui, P.L. Floating small target detection in sea clutter via normalised Doppler power spectrum. IET Radar Sonar Navig. 2016, 10, 699–706. [Google Scholar] [CrossRef]
- Qu, Q.; Wang, Y.L.; Liu, W.; Li, B. A false alarm controllable detection method based on CNN for sea-surface small targets. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shi, Y.L.; Guo, Y.X. Sea-surface small floating recurrence plots FAC classification based on CNN. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Shui, P.L.; Guo, Z.X. Feature-compression-based detection of sea-surface small targets. IEEE Access. 2020, 8, 8371–8385. [Google Scholar] [CrossRef]
- Guo, Z.X.; Shui, P.L. Anomaly-based sea-surface small target detection using K-nearest-neighbor classification. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4947–4964. [Google Scholar] [CrossRef]
- Li, Y.; Xie, P. SVM-based sea-surface small target detection: A false-alarm-rate-controllable approach. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1225–1229. [Google Scholar] [CrossRef]
- Chen, S.; Ouyang, X.; Luo, F. Ensemble One-Class Support Vector Machine for Sea Surface Target Detection Based on K-Means Clustering. Remote Sens. 2024, 16, 2401. [Google Scholar] [CrossRef]
- Wu, X.; Ding, H.; Liu, N.B. A method for detecting small targets in sea surface based on singular spectrum analysis. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Shi, Y.L.; Hu, Y.F. mRMR-Tri-ConcaveHull detector for the floating small targets in sea clutter. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6799–6811. [Google Scholar] [CrossRef]
- Zhou, H.K.; Jiang, T. Decision tree based sea-surface wake target detection with false alarm rate controllable. IEEE Signal Process Letter. 2019, 26, 793–797. [Google Scholar] [CrossRef]
- Su, N.; Chen, X. Radar Maritime Target Detection via Spatial–Temporal Feature Attention Graph Convolutional Network. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Wu, J.; Ni, R.; Chen, Z.; Huang, F.; Chen, L. FEFN: Feature Enhancement Feedforward Network for Lightweight Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 2398. [Google Scholar] [CrossRef]
- Guo, Z.X.; Bai, X.H. Fast Dual Trifeature-Based Detection of Small Targets in Sea Clutter by Using Median Normalized Doppler Amplitude Spectra. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4050–4063. [Google Scholar] [CrossRef]
- Gu, T. Detection of small floating targets on the sea surface based on multi-features and principal component analysis. IEEE Geosci. Remote Sens. Lett. 2020, 17, 809–813. [Google Scholar] [CrossRef]
- Ali, H.; Bahari, N.I.; Elshaikh, M. Shape Recognition of GPR Images using Hough Transform and PCA plus LDA. In Proceedings of the 2022 2nd International Conference on Electronic and Electrical Engineering and Intelligent System (ICE3IS), Yogyakarta, Indonesia, 4–5 November 2022; pp. 387–391. [Google Scholar] [CrossRef]
- Liu, N.B.; Dong, Y.L.; Wang, G.Q. Annual progress of the sea-detecting X-band radar and data acquisition program. J. Radars 2021, 10, 173–182. [Google Scholar] [CrossRef]
- Guan, J.; Liu, N.B.; Wang, G.Q. Sea-detecting Radar Experiment and Target Feature Data Acquisition for Dual Polarization Multistate Scattering Dataset of Marine Targets. J. Radars 2023, 12, 456–469. [Google Scholar] [CrossRef]
- Wang, J.H.; Wang, Z.H.; He, Z.S. GLRT-based polarimetric detection in compound-Gaussian sea clutter with inverse-Gaussian texture. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–15. [Google Scholar] [CrossRef]
- Yu, W.; Yang, G.; Zhao, H. A new method for ship length estimation based on Doppler spectrum analysis. Radar Sci. Technol. 2015, 12, 522–526. [Google Scholar] [CrossRef]
- Wu, X.J.; Ding, H. A Method for Detecting Small Targets in Sea Surface Based on Ridges-Radon Transform. J. Signal Process. 2021, 37, 1599–1611. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Z.; Li, X. Layered-Vine Copula-Based Wind Speed Prediction Using Spatial Correlation and Meteorological Influence. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Guan, J.; Wu, X.J.; Ding, H. Detection of Small Targets on Sea Surface Based on 3-D Concave Hull Learning Algorithm. J. Electron. Inf. Technol. 2023, 45, 1602–1610. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | SDRDSP |
|---|---|
| Carrier frequency | 9.3~9.5 GHz |
| PRF | 2000 Hz |
| Range resolution | 6 m |
| Polarization | HH/HV/VH/VV |
| Operating mode | Staring |
| Band | X |
| Test target | Two light buoys |
| Average SCR | −2~25.1 dB |
| Radial velocity | −0.8~0.9 m/s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, J.; Jiang, X.; Liu, N.; Ding, H.; Dong, Y.; Guo, Z. A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance. Remote Sens. 2024, 16, 2901. https://doi.org/10.3390/rs16162901
Guan J, Jiang X, Liu N, Ding H, Dong Y, Guo Z. A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance. Remote Sensing. 2024; 16(16):2901. https://doi.org/10.3390/rs16162901
Chicago/Turabian StyleGuan, Jian, Xingyu Jiang, Ningbo Liu, Hao Ding, Yunlong Dong, and Zhongping Guo. 2024. "A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance" Remote Sensing 16, no. 16: 2901. https://doi.org/10.3390/rs16162901
APA StyleGuan, J., Jiang, X., Liu, N., Ding, H., Dong, Y., & Guo, Z. (2024). A Small Maritime Target Detection Method Using Nonlinear Dimensionality Reduction and Feature Sample Distance. Remote Sensing, 16(16), 2901. https://doi.org/10.3390/rs16162901