


InstLane Dataset and Geometry-Aware Network for Instance Segmentation of Lane Line Detection

Abstract
1. Introduction
- We introduce a novel instance segmentation benchmark for lane line detection, termed InstLane. Distinctively characterized by its challenging and intricate scenarios, InstLane encompasses a variety of data acquisition conditions and encompasses interference from unrelated road information. The objective of this benchmark is to enhance the generalization and robustness of lane detection algorithms.
- We propose GeoLaneNet, a highly efficient, instance-level lane line segmentation network. Through the strategic design of a large receptive field to improve the perception of lane structures, the utilization of geometric features to realize finer instance localization, and the introduction of a partial feature transform to boost speed, GeoLaneNet significantly enhances detection efficiency while maintaining detection accuracy.
- We conduct a thorough set of experiments, including comparative studies, ablation studies, and visualization of results, to assess the effectiveness, robustness, and efficiency of GeoLaneNet. These studies serve to verify the significant performance improvements that GeoLaneNet delivers in the realm of lane detection.
2. Related Work
2.1. Lane Dataset
2.2. Lane Detection
3. InstLane Dataset
4. Methodology
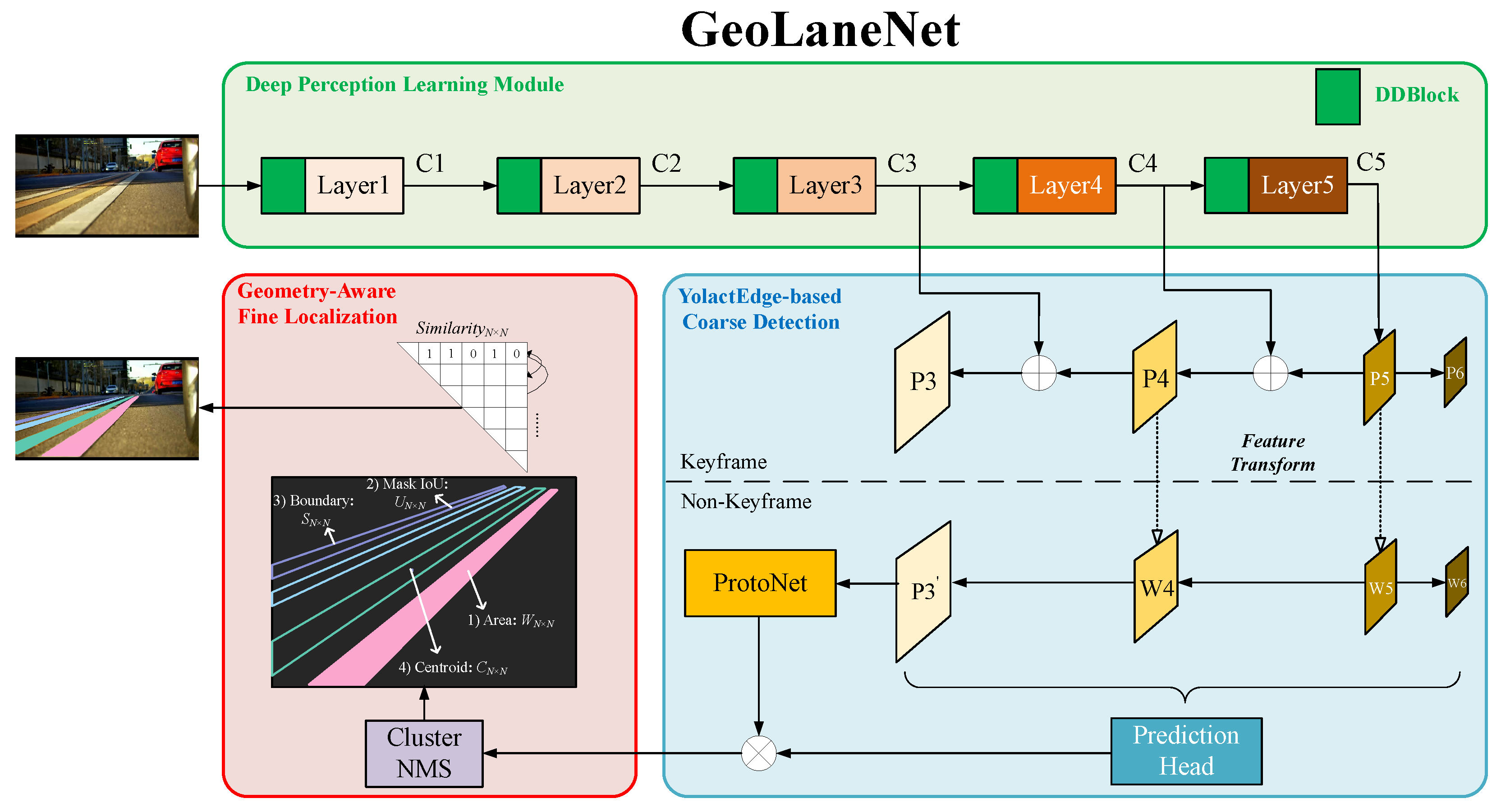
4.1. Pipeline of GeoLaneNet
- Deep Perception Learning Module: This module aims to facilitate the identification of semantic characteristics at deeper and higher levels and better perceive the long and large-scale lane lines. It is achieved through the fusion of various reception fields.
- YolactEdge-based Coarse Detection: This module aims to speed up the generation of proto-instances by introducing the partial feature transformation strategy between key frames and non-key frames in YolactEdge.
- Geometry-Aware Fine Localization: This module is designed to achieve a fine-grained localization task, in which various geometric features are subtly utilized to alleviate the problem of omission or multiple detections in dense lane scenarios due to NMS.
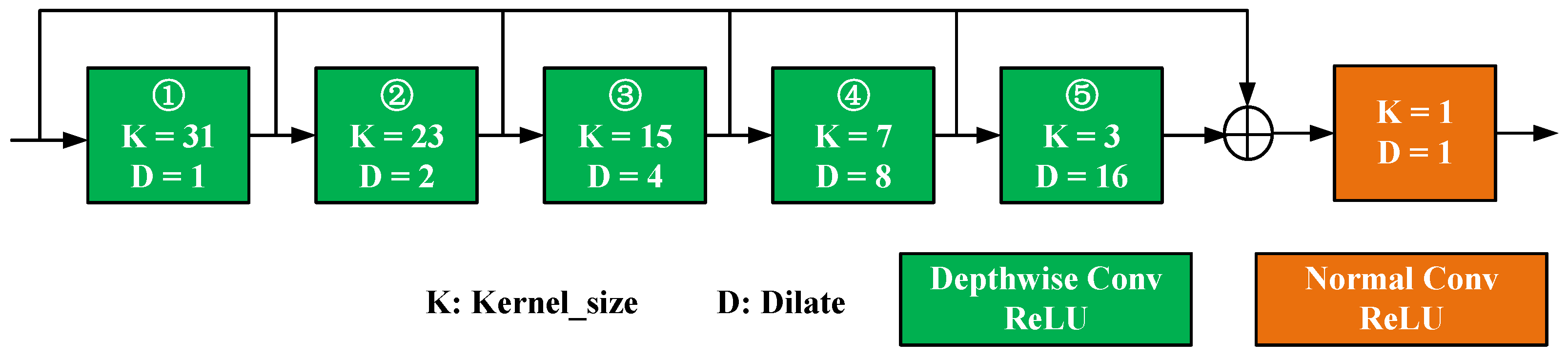
4.2. Deep Perception Learning Module
- (1)
- It is different from the rigid way of altering independent dilated rate [40,42,45] or kernel size [41,44]. The former can enlarge the receptive field by crossing regions with limited parameters and operations but suffer from the poor representation of the depth features because of few feature sampled points. The latter achieves a large receptive field and a better representation through larger convolution kernels but also brings more parameters and operations and makes real-time performance worse, which is unacceptable for the autonomous driving system. Therefore, DDBlock considers their characteristics comprehensively and adjusts both parameters simultaneously, obtaining a variety of receptive field features compared to an independent parameter.
- (2)
- Different from D-LinkNet [45], which only learns the receptive field in the deepest layer, we integrate the receptive field features acquired in different ways in each layer. It can obtain comparable receptive field features in all layers to more fully conduct the mining of semantic information.
- (3)
- Moreover, DDBlock adjusts inversely for the two parameters, which has two benefits. One is that different modules can use different settings to control the number of parameters and calculation of the whole network, thus maintaining a large receptive field and real-time performance simultaneously. The other is that the setting is not arbitrary but fully considers the respective characteristics of different levels. We use a combination of large kernels with small dilated rates, small kernels with large dilated rates for shallow layers, and small kernels with small dilated rates for deep layers, which can maintain relatively large and reasonable rerceptive fields in all layers.
4.3. YolactEdge-Based Coarse Detection
- Partial Feature Transform: This part uses features of keyframes to predict features of non-keyframes. YolactEdge employs a method to exploit temporal redundancy by processing keyframes in detail and using partial feature transformations for non-keyframes. Specifically, all feature maps in the backbone (C1∼C5) and FPN (P3∼P6) for keyframes and several feature maps (C1∼C3 in the backbone and P3, P6 in FPN) for non-keyframes are computed from the previous Deep Perception Learning Module:where is upsampling. Then, W4 and W5 in FPN of non-keyframes are transformed from P4 and P5 features of the previous keyframe by FeatFlowNet proposed also in [35].
- Instances Generation: This part is composed of ProtoNet and Prediction Head. ProtoNet is used to generate a certain number of prototype masks. The prediction Head is used for mask coefficient generation. Finally, these prototype masks are linearly combined based on mask coefficients to obtain the proto-instance segmentation results:where is k prototype masks, h and w are the size of the box, is k mask coefficients, n is the number of objects predicted in the detection branch, and is the sigmoid function. This approach significantly reduces computational overhead while maintaining high accuracy in instance segmentation. Thus, the computation of the backbone and FPN in non-keyframes can be significantly reduced, greatly improving the speed of inference.
4.4. Geometry-Aware Fine Localization
- (1)
- Area of mask: The smaller the difference between two mask areas, the greater the probability that they belong to the same instance. The area similarity factor weights between the two instances are shown below:where is a pre-set threshold, is the area of the i-th mask, which is very simple to find by calculating the number of pixels where the pixel values are equal to 1. are used to constrain the range between 0 and 1.
- (2)
- Mask IoU: Mask IoU is defined as the overlapping degree between two masks. It equals 1 when the two masks totally overlap and 0 when they do not overlap at all.where sum(·) is the operation of the area calculation of a mask. N is the number of masks. Mask IoU between any two masks is first computed, and the threshold for classification is set. Then two masks corresponding to the same instance can be considered when mask IoU:
- (3)
- Coordinate distribution of mask: We measure the coordinate distribution of the mask by calculating the similarity between the two unequal two-dimensional sets of masks. The coordinates of the two masks are first flattened into 1D vectors, and the ratio of the elements of the intersection to the two 1D vectors is calculated separately:where f(·) is the flatten operation, calculates the number of elements of the intersection of and in , calculates the sum of the frequencies of each element of the intersection, and len(·) calculates the length of the vector. The higher the similarity, the closer the spatial distribution of the two mask pixels.Since this operation on all the pixels of the two masks is relatively large, edge detection on the masks can effectively reduce the computation and achieve a similar performance. Therefore, and are replaced by and in Equation (4), where and represent the results of edge detection of and . In addition, because , the calculation of the average is needed to regulate the similarity of the two boundaries:where , are the set of edge points of i-th and j-th masks.
- (4)
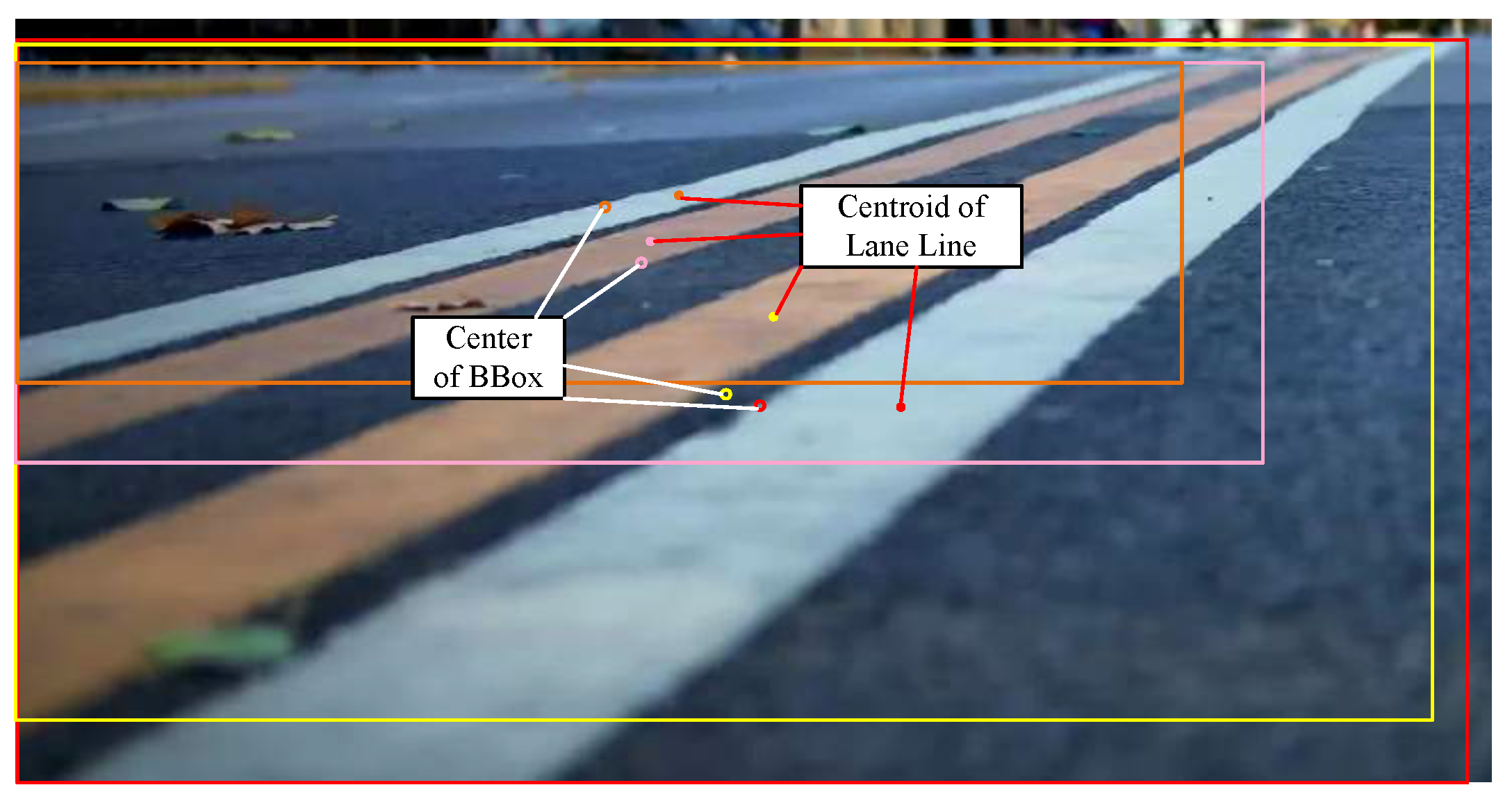
- Centroid of mask: Clustering the centers of these original instances using DBSCAN can further distinguish their true belongings. To avoid the clustering errors resulting from directly calculating the center of the prediction boxes, as illustrated in Figure 8, we use the centroids of the lanes for clustering. The calculation formula of the centroid is shown in Equations (9) and (10):where in binary images, and is the area of mask.
- Make preliminary judgments of classification based on the different areas of masks and calculate .
- Calculate mask IoU directly at pairwise marks and calculate .
- Cluster the masks by the distribution of the coordinate of contours of masks and calculate .
- Calculate the centroids of all masks and use a clustering algorithm like DBSCAN to cluster and obtain .
- Add them all up to obtain a similarity matrix:where , , , are hyper parameters. Then, use Equation (12) to binarize the matrix by the threshold value.
- Combine the scores of the masks corresponding to 1 and select the one with the highest score as the result of the instance.
4.5. Differences to Other Methods
- Network and Loss-based Methods: Approaches such as [50,51] incorporate specific loss functions during training to ensure proposals are closely aligned with ground truth. AdaptiveNMS [52] focuses on learning optimal NMS thresholds, while [53] introduces a branch and uses EMDLoss to handle multiple predictions per proposal.
- Enhanced Geometric Distinction: Unlike NMS-improvement methods that rely on a single geometric parameter to address overlapping instances, our approach uses a comprehensive set of lane line geometric features, including area, mask Intersection over Union (IoU), coordinate distribution, and geometric centroid. This multi-faceted geometric analysis enables more precise distinction between adjacent instances, overcoming the limitations of single-parameter approaches.
- Simplified Integration: Unlike network and loss-based methods that require modifications to network architecture or training processes, our approach operates in the post-processing stage, following network output. This design avoids complex retraining and parameter adjustments, offering a plug-and-play solution that can be easily integrated across various platforms.
- Superior Real-Time Performance: While NMS-free approaches can directly recognize instances without NMS, they often exhibit slower performance. Our method, by contrast, maintains high-speed processing suitable for real-time lane detection scenarios, ensuring it meets the stringent demands of practical applications.
5. Experimental Results and Analysis
5.1. Experimental Settings and Metrics
5.2. Ablation Study
5.2.1. Deep Perception Learning Module
5.2.2. Geometry-Aware Fine Localization
5.2.3. Ablation Study of Proposed Modules
5.3. Comparison with other Baselines
5.4. Visualization Results
5.5. Discussion of Limitations
6. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, X.; Cao, Y.; Zhou, J.; Huang, Y.; Li, B. HDM-RRT: A Fast HD-Map-Guided Motion Planning Algorithm for Autonomous Driving in the Campus Environment. Remote Sens. 2023, 15, 487. [Google Scholar] [CrossRef]
- Yan, S.; Zhang, M.; Peng, Y.; Liu, Y.; Tan, H. AgentI2P: Optimizing Image-to-Point Cloud Registration via Behaviour Cloning and Reinforcement Learning. Remote Sens. 2022, 14, 6301. [Google Scholar] [CrossRef]
- Aldibaja, M.; Suganuma, N.; Yanase, R. 2.5D Layered Sub-Image LIDAR Maps for Autonomous Driving in Multilevel Environments. Remote Sens. 2022, 14, 5847. [Google Scholar] [CrossRef]
- Ling, J.; Chen, Y.; Cheng, Q.; Huang, X. Zigzag Attention: A Structural Aware Module For Lane Detection. In Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 4175–4179. [Google Scholar] [CrossRef]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Polylanenet: Lane estimation via deep polynomial regression. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 6150–6156. [Google Scholar]
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L. Rethinking Efficient Lane Detection via Curve Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17062–17070. [Google Scholar]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit. In IEEE Transactions on Intelligent Transportation Systems; IEEE: Piscataway, NJ, USA, 2019; pp. 1–11. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 276–291. [Google Scholar]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 286–291. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 7276–7283. [Google Scholar]
- Cheng, W.; Luo, H.; Yang, W.; Yu, L.; Chen, S.; Li, W. Det: A high-resolution dvs dataset for lane extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 1666–1675. [Google Scholar]
- Gurghian, A.; Koduri, T.; Bailur, S.V.; Carey, K.J.; Murali, V.N. DeepLanes: End-To-End Lane Position Estimation Using Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, Nevada, USA, 26 June–1 July 2016; pp. 38–45. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; Souza, A.; Oliveira-Santos, T. Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 294–302. [Google Scholar]
- Qin, Z.; Zhang, P.; Li, X. Ultra Fast Deep Lane Detection With Hybrid Anchor Driven Ordinal Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 2555–2568. [Google Scholar] [CrossRef] [PubMed]
- Van Gansbeke, W.; De Brabandere, B.; Neven, D.; Proesmans, M.; Van Gool, L. End-to-end lane detection through differentiable least-squares fitting. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Repulic of Korea, 27–28 October 2019; pp. 905–913. [Google Scholar]
- Han, J.; Deng, X.; Cai, X.; Yang, Z.; Xu, H.; Xu, C.; Liang, X. Laneformer: Object-aware Row-Column Transformers for Lane Detection. arXiv 2022, arXiv:2203.09830. [Google Scholar] [CrossRef]
- Tusimple. 2019. Available online: https://github.com/TuSimple/tusimple-benchmark (accessed on 11 May 2023).
- Wang, P.; Huang, X.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Behrendt, K.; Soussan, R. Unsupervised Labeled Lane Markers Using Maps. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Repulic of Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 832–839. [Google Scholar]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 7–12. [Google Scholar]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-NAS: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020; pp. 689–704. [Google Scholar]
- Wu, T.; Ranganathan, A. A practical system for road marking detection and recognition. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 25–30. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; NIPS’17; pp. 6000–6010. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Wen, T.; Yang, D.; Jiang, K.; Yu, C.; Lin, J.; Wijaya, B.; Jiao, X. Bridging the Gap of Lane Detection Performance Between Different Datasets: Unified Viewpoint Transformation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6198–6207. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Xu, X.; Shi, Y. Adaptive Multi-Lane Detection Based on Robust Instance Segmentation for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2023, 8, 888–899. [Google Scholar] [CrossRef]
- Peng, S.; Jiang, W.; Pi, H.; Li, X.; Bao, H.; Zhou, X. Deep snake for real-time instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8533–8542. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single shot instance segmentation with polar representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Liu, Z.; Liew, J.H.; Chen, X.; Feng, J. Dance: A deep attentive contour model for efficient instance segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 345–354. [Google Scholar]
- Zhang, T.; Wei, S.; Ji, S. E2EC: An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4443–4452. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic and fast instance segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 17721–17732. [Google Scholar]
- Liu, H.; Soto, R.A.R.; Xiao, F.; Lee, Y.J. Yolactedge: Real-time instance segmentation on the edge. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA; pp. 9579–9585. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Repulic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C.C. K-net: Towards unified image segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 10326–10338. [Google Scholar]
- Cheng, T.; Wang, X.; Chen, S.; Zhang, W.; Zhang, Q.; Huang, C.; Zhang, Z.; Liu, W. Sparse Instance Activation for Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4433–4442. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion Loss: Detecting Pedestrians in a Crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining Pedestrian Detection in a Crowd. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chu, X.; Zheng, A.; Zhang, X.; Sun, J. Detection in Crowded Scenes: One Proposal, Multiple Predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Lee, Y.; Hwang, J.w.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Num. | Resolution | Areas | Challenging Scenes | Camera | Label |
|---|---|---|---|---|---|---|
| Caltech Lanes [21] | 1.2 k | 640 × 480 | Urban Road | —— | Front-RGB | Points |
| Road Marking [23] | 1.4 k | 800 × 600 | Superhighway | Cloudy, Twilight, night | Front-RGB | BBoxes |
| TuSimple [17] | 6.4 k | 1280 × 720 | Superhighway | —— | Front-RGB | Points |
| Llamas [20] | 100 k | 1276 × 717 | Superhighway | —— | Front-RGB | Points |
| BDD100K [19] | 100 k | 1280 × 720 | Urban Road, Rural Road, Superhighway | Rainy, Snowy, Night | Front-RGB | Semantic labels |
| CULane [10] | 133 k | 1640 × 590 | Urban Road, Rural Road, Superhighway | 8 complex scenes | Front-RGB | Points |
| CurveLanes [22] | 150 k | 2560 × 1440 | Urban Road | Curve Lanes | Front-RGB | Points |
| ApolloScape [18] | 170 k | 3384 × 2710 | Urban Road | Various weathers, Complex scenes | Front-RGB | Semantic labels |
| DeepLanes [12] | 120 k | 360 × 240 | Urban Road | —— | Laterally-RGB | —— |
| DET [11] | 5.4 k | 1280 × 800 | Urban Road | —— | Front-Event | Semantic labels |
| InstLane (ours) | 7.5 k | 4096 × 2160 | Urban Road | shadow, dazzle light grayscale with noise | Laterally -RGB | Instance labels |
| Dataset | Env | Num. | Total |
|---|---|---|---|
| train | Day | 1073 (14.23%) | 6787 |
| Night | 1004 (13.31%) | ||
| Gray | 4710 (62.46%) | ||
| testval | Day | 108 (1.43%) | 754 |
| Night | 111 (1.47%) | ||
| Gray | 535 (7.09%) |
| Layer | Configurations | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | ④ | ⑤ | ||||||
| K | D | K | D | K | D | K | D | K | D | |
| 1 | 31 | 1 | 23 | 2 | 15 | 4 | 7 | 8 | 3 | 16 |
| 2 | 23 | 1 | 15 | 2 | 7 | 4 | 3 | 8 | ||
| 3 | 15 | 1 | 7 | 2 | 3 | 4 | ||||
| 4 | 7 | 1 | 3 | 2 | ||||||
| Model | MACs(G) | Params(M) | AP(%) | FPS |
|---|---|---|---|---|
| ResNet18 (baseline) | 40.71 | 17.58 | 64.69 | 269 |
| ResNet18+DDBlock 1 | 42.95 | 17.70 | +1.13 | 252 |
| ResNet18+DDBlock 1, 2 | 43.52 | 17.82 | +1.38 | 235 |
| ResNet18+DDBlock 1, 2, 3 | 43.69 | 17.96 | +2.26 | 211 |
| ResNet18+DDBlock 1, 2, 3, 4 | 43.78 | 18.25 | +2.44 | 198 |
| ResNet50 | 55.91 | 30.60 | +2.76 | 153 |
| D-LinkNet34 (Enc) [45] | 64.49 | 46.57 | +2.68 | 158 |
| ConvNext-Small [55] | 80.91 | 56.10 | +2.89 | 89 |
| NMS | Score Filter by Geometry Features | AP (%) |
|---|---|---|
| Fast NMS [36] | 67.13 | |
| ✓ | 71.79 | |
| Traditional NMS | 67.28 | |
| ✓ | 72.02 | |
| Soft NMS [48] | 68.52 | |
| ✓ | 72.93 | |
| Cluster NMS [47] | 69.37 | |
| ✓ | 73.29 | |
| Cluster NMS (SPM) [47] | 70.57 | |
| ✓ | 73.50 | |
| Cluster NMS (SPM & Dist) [47] | 71.85 | |
| ✓ | 73.55 |
| Deep Perception Learning Module | Geometry-Aware Fine Localization | AP (%) | FPS |
|---|---|---|---|
| 64.69 | 269 | ||
| ✓ | 67.13 (+2.44) | 198 | |
| ✓ | 72.24 (+7.55) | 175 | |
| ✓ | ✓ | 73.55 (+8.86) | 139 |
| Model | Contour | NMS | Backbone | AP(%) | FPS | GPU Mem(M) |
|---|---|---|---|---|---|---|
| PolarMask [31] | ✓ | ✓ | ResNet50 | 53.64 | 40 | 135 |
| Dance [32] | ✓ | ✓ | ResNet50 | 64.66 | 56 | 174 |
| SparseInst [38] | ResNet50 | 78.08 | 67 | 128 | ||
| K-Net [37] | ResNet50 | 76.50 | 43 | 146 | ||
| MaskRCNN [58] | ✓ | ResNet50 | 56.64 | 36 | 175 | |
| CenterMask [59] | ✓ | VoVNet39 [60] | 62.35 | 44 | 134 | |
| SOLOv2 [34] | ✓ | ResNet18 | 70.50 | 49 | 90 | |
| YOLACT [36] | ✓ | ResNet50 | 65.52 | 62 | 153 | |
| YolactEdge [35] | ✓ | ResNet50 | 64.69 | 159 | 145 | |
| GeoLaneNet | ✓ | ResNet18- DDBlock | 73.55 | 139 | 98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Q.; Ling, J.; Yang, Y.; Liu, K.; Li, H.; Huang, X. InstLane Dataset and Geometry-Aware Network for Instance Segmentation of Lane Line Detection. Remote Sens. 2024, 16, 2751. https://doi.org/10.3390/rs16152751
Cheng Q, Ling J, Yang Y, Liu K, Li H, Huang X. InstLane Dataset and Geometry-Aware Network for Instance Segmentation of Lane Line Detection. Remote Sensing. 2024; 16(15):2751. https://doi.org/10.3390/rs16152751
Chicago/Turabian StyleCheng, Qimin, Jiajun Ling, Yunfei Yang, Kaiji Liu, Huanying Li, and Xiao Huang. 2024. "InstLane Dataset and Geometry-Aware Network for Instance Segmentation of Lane Line Detection" Remote Sensing 16, no. 15: 2751. https://doi.org/10.3390/rs16152751
APA StyleCheng, Q., Ling, J., Yang, Y., Liu, K., Li, H., & Huang, X. (2024). InstLane Dataset and Geometry-Aware Network for Instance Segmentation of Lane Line Detection. Remote Sensing, 16(15), 2751. https://doi.org/10.3390/rs16152751