
SE-RRACycleGAN: Unsupervised Single-Image Deraining Using Squeeze-and-Excitation-Based Recurrent Rain-Attentive CycleGAN



Abstract
1. Introduction
2. Related Works
2.1. Model-Based Approaches
2.2. Data-Driven Approaches
2.2.1. Supervised Learning Method
2.2.2. Unsupervised Learning Method
2.3. Visual Attention
3. The Proposed Method
3.1. Recurrent Rain-Attentive Module (RRAM)
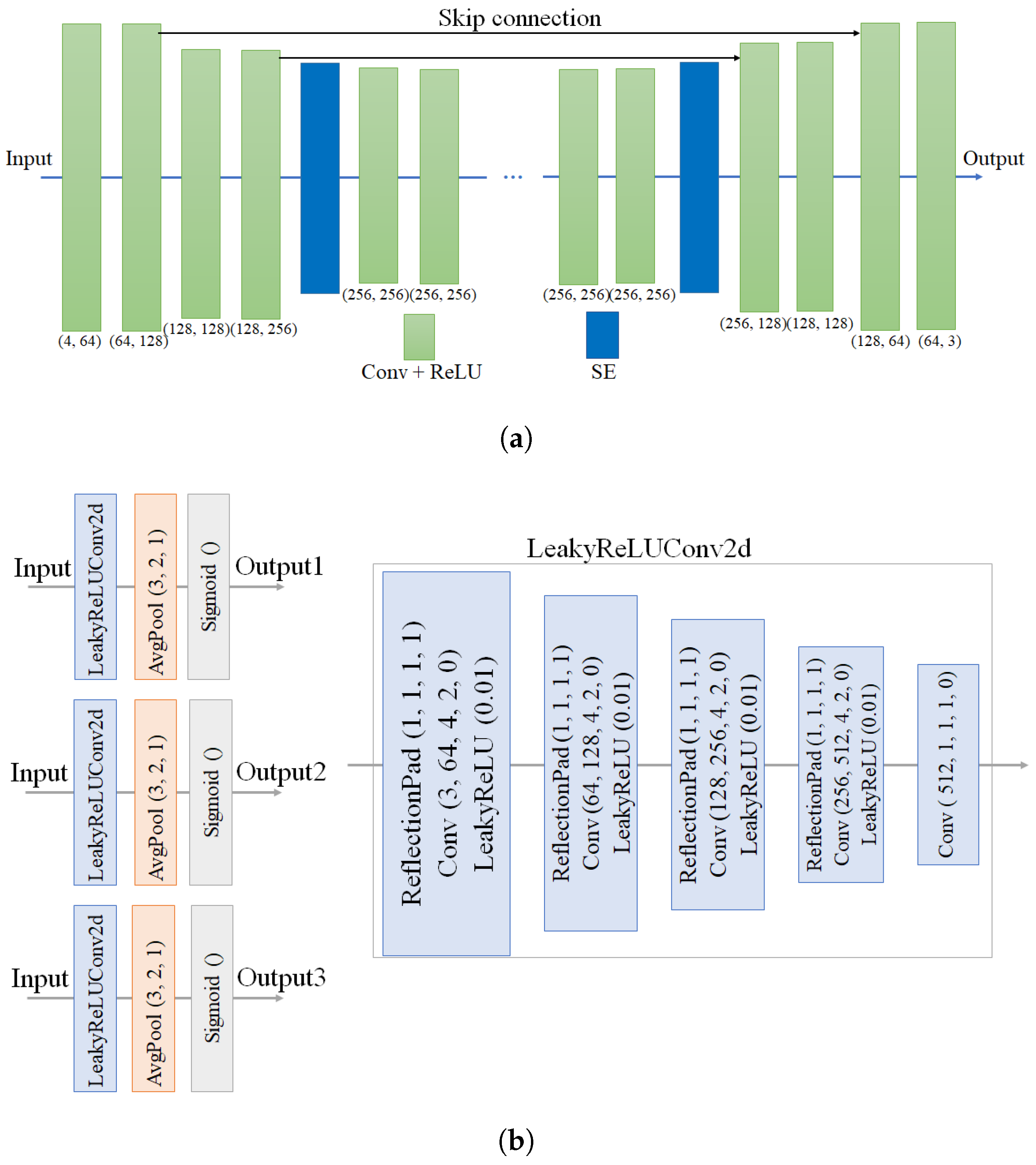
3.2. Generator
Squeeze-and-Excitation Block
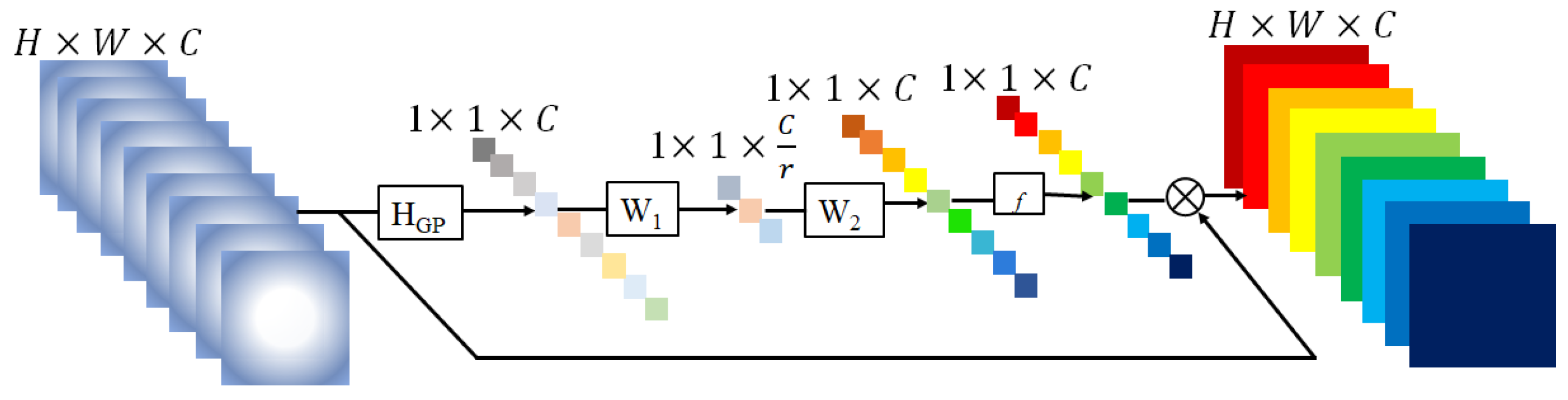
3.3. Discriminator
3.4. Objective Function
4. Experimental Results and Discussion
4.1. Network Training and Parameter Setting
4.1.1. Implementation Details
4.1.2. Datasets and Evaluation Metrics
4.2. Comparisons with State-of-the-Art Methods
4.2.1. Comparisons Using a Synthetic Datasets
4.2.2. Comparisons Using a Real Datasets
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qiao, J.; Song, H.; Zhang, K.; Zhang, X.; Liu, Q. Image super-resolution using conditional generative adversarial network. IET Image Process. 2019, 13, 2673–2679. [Google Scholar] [CrossRef]
- Mao, J.; Xiao, T.; Jiang, Y.; Cao, Z. What can help pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3127–3136. [Google Scholar]
- Song, Y.; Ma, C.; Wu, X.; Gong, L.; Bao, L.; Zuo, W.; Shen, C.; Lau, R.W.; Yang, M.H. Vital: Visual tracking via adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8990–8999. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Tripicchio, P.; Camacho-Gonzalez, G.; D’Avella, S. Welding defect detection: Coping with artifacts in the production line. Int. J. Adv. Manuf. Technol. 2020, 111, 1659–1669. [Google Scholar] [CrossRef]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Lian, Q.; Yan, W.; Zhang, X.; Chen, S. Single image rain removal using image decomposition and a dense network. IEEE/CAA J. Autom. Sin. 2019, 6, 1428–1437. [Google Scholar] [CrossRef]
- Liu, J.; Yang, W.; Yang, S.; Guo, Z. D3r-Net: Dynamic routing residue recurrent network for video rain removal. IEEE Trans. Image Process. 2018, 28, 699–712. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Xie, Q.; Zhao, Q.; Wei, W.; Gu, S.; Tao, J.; Meng, D. Video rain streak removal by multiscale convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6644–6653. [Google Scholar]
- Ahn, N.; Jo, S.Y.; Kang, S.J. EAGNet: Elementwise attentive gating network-based single image de-raining with rain simplification. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 608–620. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, Z.; Wang, Y.; Xu, M.; Yang, Y.; Yan, S.; Wang, M. Deraincyclegan: Rain attentive cyclegan for single-image deraining and rainmaking. IEEE Trans. Image Process. 2021, 30, 4788–4801. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Wang, P.; Shang, D.; Wang, P. Cycle-Attention-Derain: Unsupervised rain removal with CycleGAN. Vis. Comput. 2023, 39, 3727–3739. [Google Scholar] [CrossRef]
- Guo, Z.; Hou, M.; Sima, M.; Feng, Z. DerainAttentionGAN: Unsupervised single-image deraining using attention-guided generative adversarial networks. Signal Image Video Process. 2022, 16, 185–192. [Google Scholar] [CrossRef]
- Yang, W.; Tan, R.T.; Wang, S.; Fang, Y.; Liu, J. single-image deraining: From model-based to data-driven and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4059–4077. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, G.; Tan, F.; Li, F.; Xie, W. Progressive hybrid-modulated network for single-image deraining. Mathematics 2023, 11, 691. [Google Scholar] [CrossRef]
- Liu, T.; Zhou, B.; Luo, P.; Zhang, Y.; Niu, L.; Wang, G. Two-Stage and Two-Channel Attention single-image deraining Network for Promoting Ship Detection in Visual Perception System. Appl. Sci. 2022, 12, 7766. [Google Scholar] [CrossRef]
- Wang, Y.T.; Zhao, X.L.; Jiang, T.X.; Deng, L.J.; Chang, Y.; Huang, T.Z. Rain streaks removal for single image via kernel-guided convolutional neural network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3664–3676. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kang, L.W.; Lin, C.W.; Fu, Y.H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2736–2744. [Google Scholar]
- Wang, Y.; Liu, S.; Chen, C.; Zeng, B. A hierarchical approach for rain or snow removing in a single color image. IEEE Trans. Image Process. 2017, 26, 3936–3950. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3943–3956. [Google Scholar] [CrossRef]
- Yang, W.; Tan, R.T.; Feng, J.; Guo, Z.; Yan, S.; Liu, J. Joint rain detection and removal from a single image with contextualized deep networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1377–1393. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, H.; Peng, X.; Zhou, J.T.; Yang, S.; Chanderasekh, V.; Li, L.; Lim, J.H. Singe image rain removal with unpaired information: A differentiable programming perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9332–9339. [Google Scholar]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified visual attention networks for fine-grained object classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Zheng, M.; Xu, J.; Shen, Y.; Tian, C.; Li, J.; Fei, L.; Zong, M.; Liu, X. Attention-based CNNs for image classification: A survey. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2171, p. 012068. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2482–2491. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chao, Z.; Pu, F.; Yin, Y.; Han, B.; Chen, X. Research on real-time local rainfall prediction based on MEMS sensors. J. Sens. 2018, 2018, 6184713. [Google Scholar] [CrossRef]
- Liu, R.W.; Hu, K.; Liang, M.; Li, Y.; Liu, X.; Yang, D. QSD-LSTM: Vessel trajectory prediction using long short-term memory with quaternion ship domain. Appl. Ocean Res. 2023, 136, 103592. [Google Scholar] [CrossRef]
- Brown, M.J.; Hutchinson, L.A.; Rainbow, M.J.; Deluzio, K.J.; De Asha, A.R. A comparison of self-selected walking speeds and walking speed variability when data are collected during repeated discrete trials and during continuous walking. J. Appl. Biomech. 2017, 33, 384–387. [Google Scholar] [CrossRef] [PubMed]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, C.; Fan, W.; Zhu, H.; Su, Z. single-image deraining via nonlocal squeeze-and-excitation enhancing network. Appl. Intell. 2020, 50, 2932–2944. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Qiao, J.; Song, H.; Zhang, K.; Zhang, X. Conditional generative adversarial network with densely-connected residual learning for single image super-resolution. Multimed. Tools Appl. 2021, 80, 4383–4397. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Du, R.; Li, W.; Chen, S.; Li, C.; Zhang, Y. Unpaired underwater image enhancement based on cyclegan. Information 2021, 13, 1. [Google Scholar] [CrossRef]
- Karen, S. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 1 January 2024).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial attentive single-image deraining with a high quality real rain dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12270–12279. [Google Scholar]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-supervised transfer learning for image rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3877–3886. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—A comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed]
- Su, Z.; Zhang, Y.; Shi, J.; Zhang, X.P. A Survey of Single Image Rain Removal Based on Deep Learning. ACM Comput. Surv. 2023, 56, 1–35. [Google Scholar] [CrossRef]
- Ratner, B. The correlation coefficient: Its values range between +1/−1, or do they? J. Target. Meas. Anal. Mark. 2009, 17, 139–142. [Google Scholar] [CrossRef]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3855–3863. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Wang, H.; Wu, Y.; Li, M.; Zhao, Q.; Meng, D. Survey on rain removal from videos or a single image. Sci. China Inf. Sci. 2022, 65, 111101. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Channel | Kernel Size | Striding | Padding | Dilation |
|---|---|---|---|---|---|
| (Input, Output) | |||||
| Conv + ReLU | (4, 64) | 5 × 5 | 1 × 1 | 2 × 2 | - |
| Conv + ReLU | (64, 128) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| Conv + ReLU | (128, 128) | 3 × 3 | 1× 1 | 1 × 1 | - |
| Conv + ReLU | (128, 256) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| AvgPool | |||||
| Conv | (256, 256/r) | 1 × 1 | 1 × 1 | - | - |
| ReLU | |||||
| Conv | (256, 256/r) | 1 × 1 | 1 × 1 | - | - |
| Sigmoid | |||||
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 2 × 2 | 2 |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 4 × 4 | 4 |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 8 × 8 | 8 |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 16 × 16 | 16 |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| Conv + ReLU | (256, 256) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| AvgPool | |||||
| Conv | (256, 256/r) | 1 × 1 | 1 × 1 | - | - |
| ReLU | |||||
| Conv | (256, 256/r) | 1 × 1 | 1 × 1 | - | - |
| Sigmoid | |||||
| ConvTranspose | (256, 128) | 4 × 4 | 2 × 2 | 1 × 1 | - |
| AvgPool | |||||
| ReLU | |||||
| Conv + ReLU | (128, 128) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| ConvTranspose | (128, 64) | 4 × 4 | 2 × 2 | 1 × 1 | - |
| AvgPool | |||||
| ReLU | |||||
| Conv + ReLU | (64, 1) | 3 × 3 | 1 × 1 | 1 × 1 | - |
| Layer | Channel | Kernel | Striding | Padding | ||
|---|---|---|---|---|---|---|
| (Input, | Size | |||||
| Output) | ||||||
| Conv | (4, 32) | 3 × 3 | 1 × 1 | 1 × 1 | Conv + ReLU | |
| ReLU | ||||||
| Conv | (64, 32) | 3 × 3 | 1 × 1 | 1 × 1 | LSTM | |
| Sigmoid | ||||||
| Conv | (64, 32) | 3 × 3 | 1 × 1 | 1 × 1 | ||
| Sigmoid | ||||||
| Conv | (64, 32) | 3 × 3 | 1 × 1 | 1 × 1 | ||
| Tanh | ||||||
| Conv | (64, 32) | 3 × 3 | 1 × 1 | 1 × 1 | ||
| Sigmoid | ||||||
| Conv | (64, 128) | 3 × 3 | 1 × 1 | 1 × 1 | CSAB | |
| BatchNorm | ||||||
| ReLU | ||||||
| Conv | (128, 128) | 3 × 3 | 1 × 1 | 1 × 1 | ||
| BatchNorm | ||||||
| Conv | (128, 64) | 3 × 3 | 1 × 1 | 1 × 1 | ||
| Avg out = | AvgPool | |||||
| Conv | (64, 4) | 1 × 1 | 1 × 1 | - | ||
| ReLU | ||||||
| Conv | (4, 64) | 1 × 1 | 1 × 1 | - | ||
| Max out = | MaxPool | |||||
| Conv | (64, 4) | 1 × 1 | 1 × 1 | - | ||
| ReLU | ||||||
| Conv | (4, 64) | 1 × 1 | 1 × 1 | - | ||
| Sigmoid | ||||||
| (Avg out + | ||||||
| Max out) | ||||||
| Conv | ||||||
| (AvgPool; | ||||||
| MaxPool) | (2, 1) | 7 × 7 | 3 × 3 | - | ||
| Sigmoid | ||||||
| ReLU | ||||||
| Conv | (64, 1) | 3 × 3 | 1 × 1 | 1 × 1 | Conv |
| Rain100L [49] | Rain12 [21] | Rain800 [23] | SPANet-Data [50] | |||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| DetailNet [57] | 32.38 | 0.926 | 34.04 | 0.933 | 21.16 | 0.732 | 34.70 | 0.926 |
| Clear [58] | 30.24 | 0.934 | 31.24 | 0.935 | - | - | 32.66 | 0.942 |
| RESCAN [59] | 38.52 | 0.981 | 36.43 | 0.952 | 24.09 | 0.841 | - | - |
| PReNet [60] | 37.45 | 0.979 | 36.66 | 0.961 | 26.97 | 0.898 | 35.06 | 0.944 |
| SPANet [50] | 34.46 | 0.962 | 34.63 | 0.943 | 24.52 | 0.51 | 35.24 | 0.945 |
| SSIR ** [51] | 32.37 | 0.926 | 34.02 | 0.935 | - | - | 34.85 | 0.936 |
| CycleGAN * [18] | 24.61 | 0.834 | 21.56 | 0.845 | 23.95 | 0.819 | 22.40 | 0.860 |
| RR-GAN * [26] | - | - | - | - | 23.51 | 0.757 | - | - |
| Derain | ||||||||
| CycleGAN * [11] | 31.49 | 0.936 | 34.44 | 0.952 | 24.32 | 0.842 | 34.12 | 0.950 |
| Derain Attention | ||||||||
| GAN * [13] | 34.01 | 0.969 | - | - | 25.22 | 0.856 | - | - |
| Cycle-attention- | ||||||||
| derain * [12] | 29.26 | 0.902 | 30.77 | 0.911 | 28.48 | 0.874 | 33.15 | 0.921 |
| Ours * | 31.87 | 0.941 | 34.60 | 0.954 | 27.92 | 0.879 | 34.17 | 0.953 |
| Qualitative Measures | ||||
|---|---|---|---|---|
| Datasets | RMSE | FSIM | MAE | CC |
| Rain100L [49] | 0.167 | 0.899 | 0.145 | 0.918 |
| Rain12 [21] | 0.159 | 0.915 | 0.138 | 0.926 |
| Rain800 [23] | 0.215 | 0.847 | 0.189 | 0.861 |
| SPANet-Data [50] | 0.162 | 0.908 | 0.143 | 0.922 |
| Dataset | Metrics | Baseline | Baseline + SE | Ours w/o LSTM | Ours w/o SE | Ours |
|---|---|---|---|---|---|---|
| Rain100L | PSNR | 24.61 | 26.94 | 28.43 | 30.25 | 31.87 |
| SSIM | 0.834 | 0.859 | 0.878 | 0.912 | 0.941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wedajew, G.N.; Xu, S.S.-D. SE-RRACycleGAN: Unsupervised Single-Image Deraining Using Squeeze-and-Excitation-Based Recurrent Rain-Attentive CycleGAN. Remote Sens. 2024, 16, 2642. https://doi.org/10.3390/rs16142642
Wedajew GN, Xu SS-D. SE-RRACycleGAN: Unsupervised Single-Image Deraining Using Squeeze-and-Excitation-Based Recurrent Rain-Attentive CycleGAN. Remote Sensing. 2024; 16(14):2642. https://doi.org/10.3390/rs16142642
Chicago/Turabian StyleWedajew, Getachew Nadew, and Sendren Sheng-Dong Xu. 2024. "SE-RRACycleGAN: Unsupervised Single-Image Deraining Using Squeeze-and-Excitation-Based Recurrent Rain-Attentive CycleGAN" Remote Sensing 16, no. 14: 2642. https://doi.org/10.3390/rs16142642
APA StyleWedajew, G. N., & Xu, S. S.-D. (2024). SE-RRACycleGAN: Unsupervised Single-Image Deraining Using Squeeze-and-Excitation-Based Recurrent Rain-Attentive CycleGAN. Remote Sensing, 16(14), 2642. https://doi.org/10.3390/rs16142642