
DOA Estimation Based on Virtual Array Aperture Expansion Using Covariance Fitting Criterion


Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Signal Model
3. Methodology of Virtual Aperture Expansion
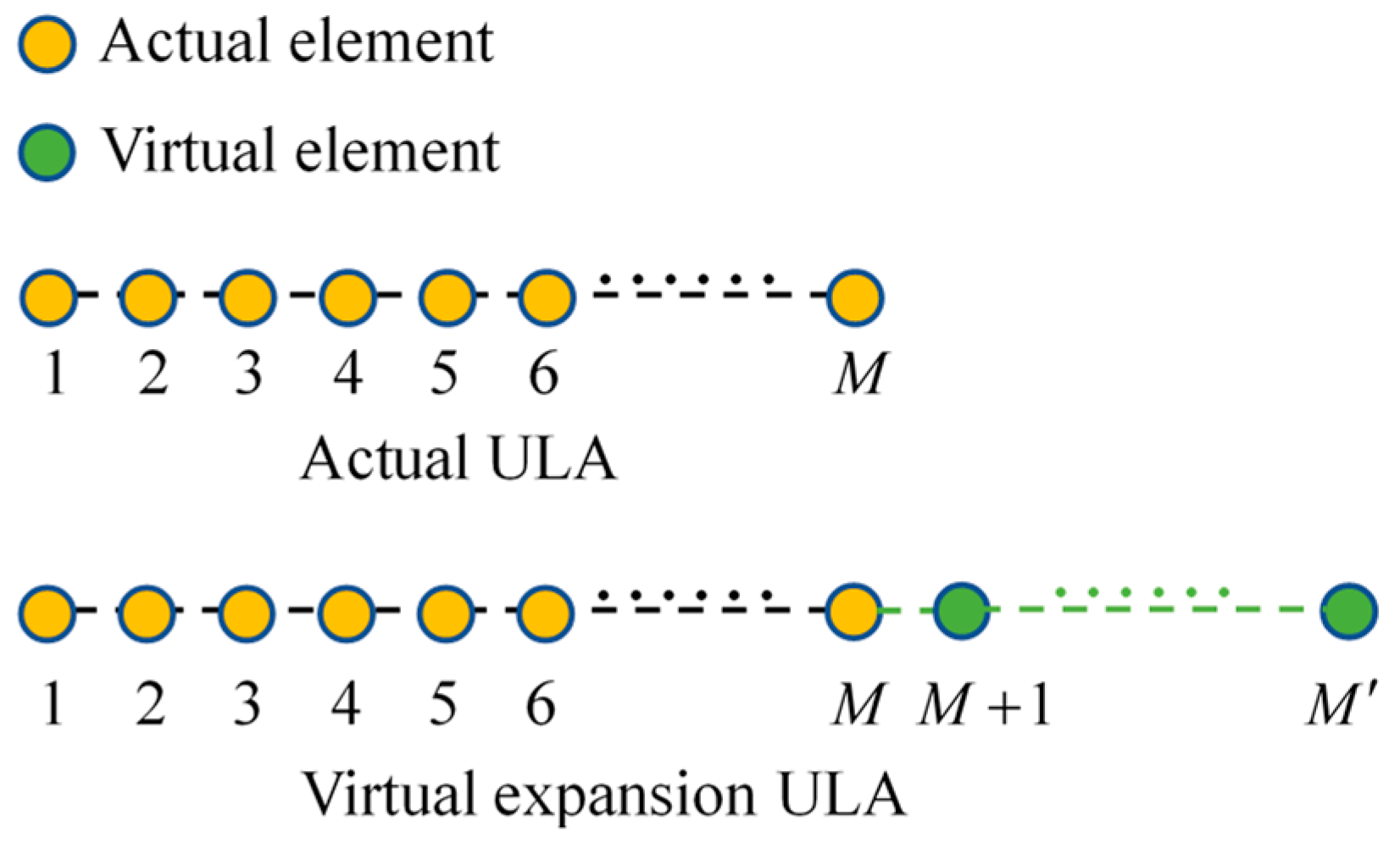
3.1. The Case of ULA when
3.2. The Case of ULA when
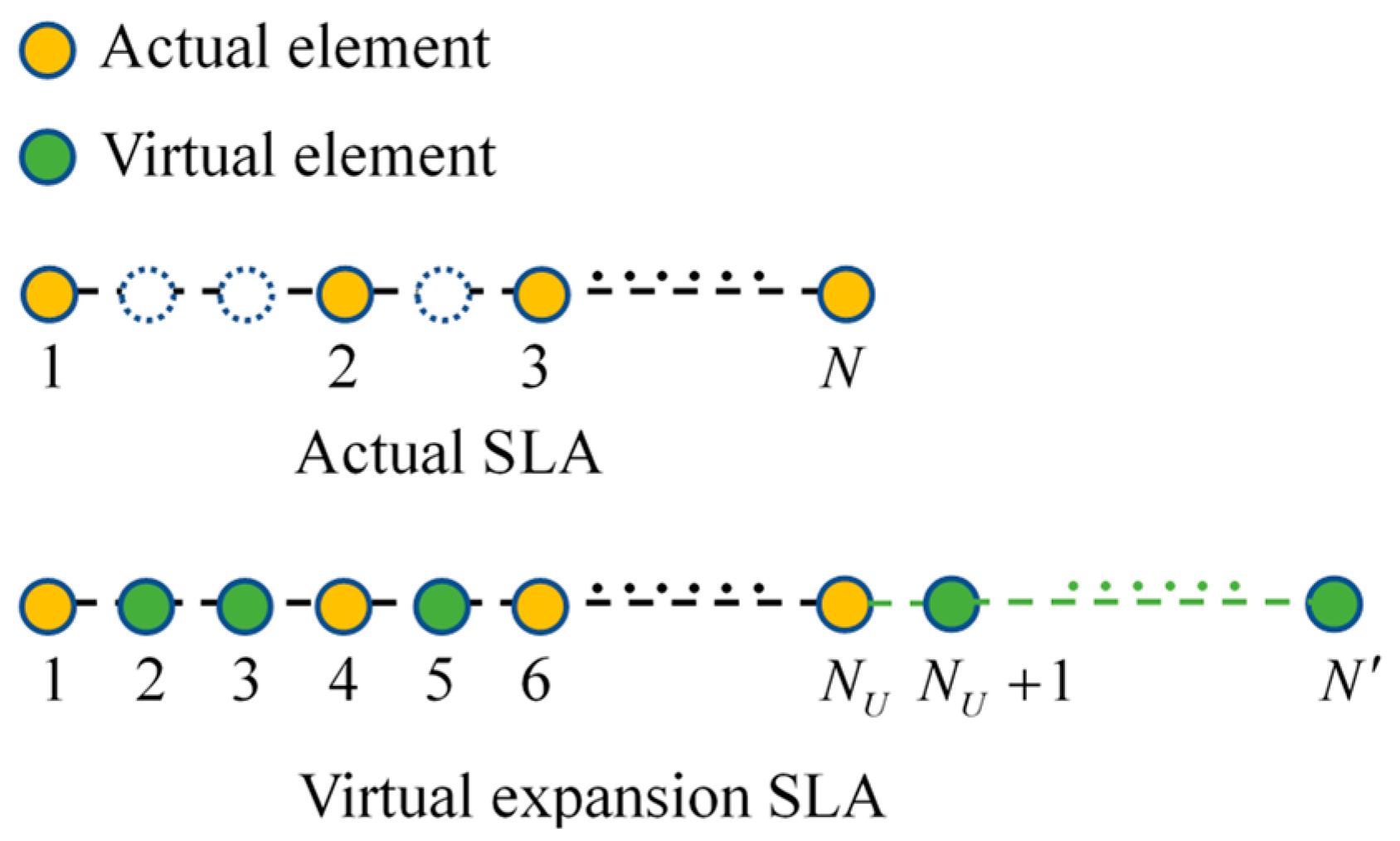
3.3. The Case of SLA when
3.4. The Case of SLA when
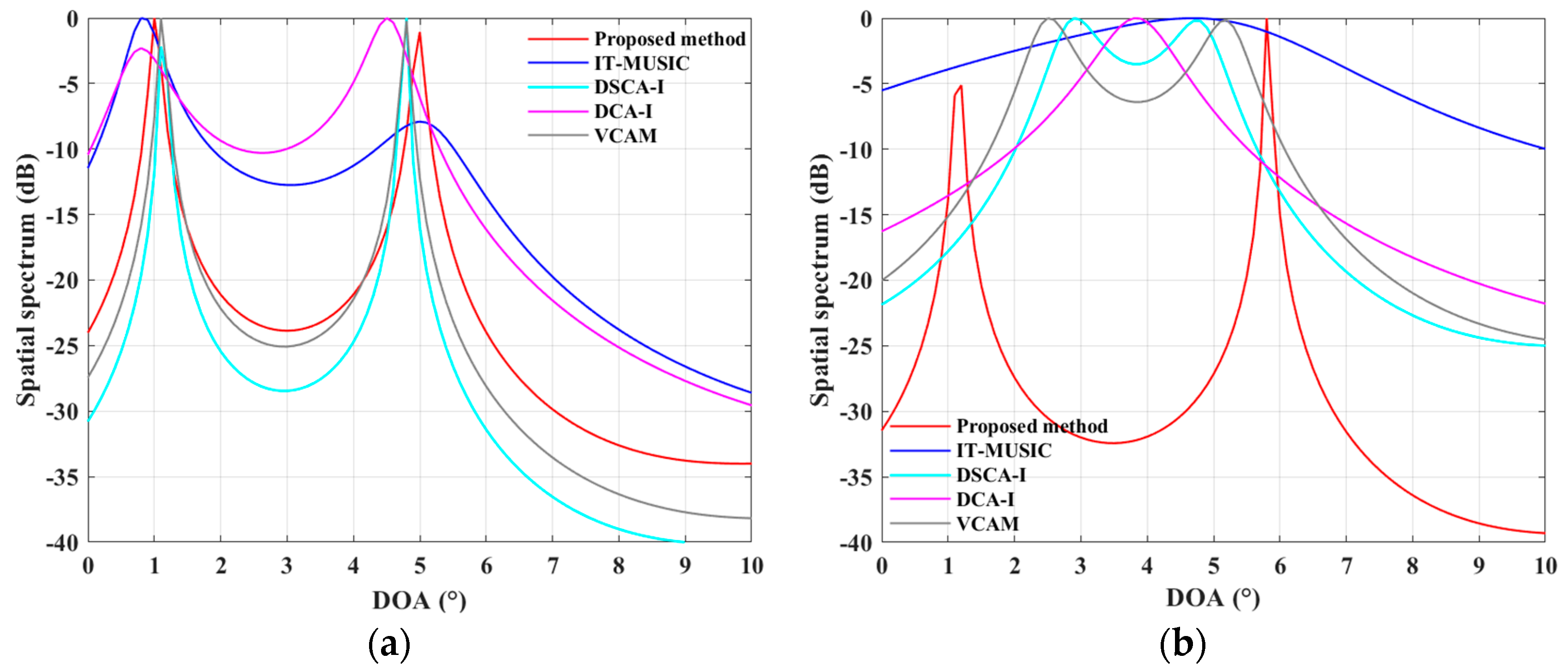
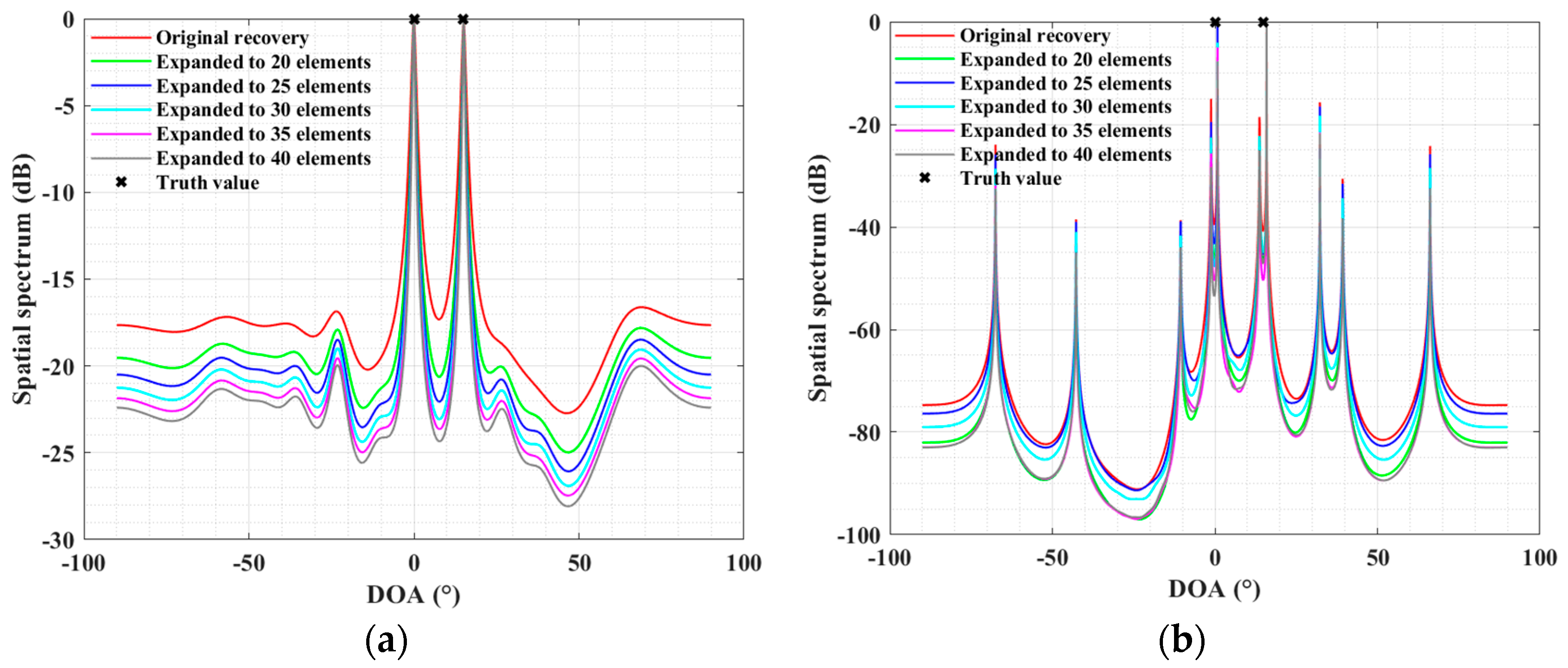
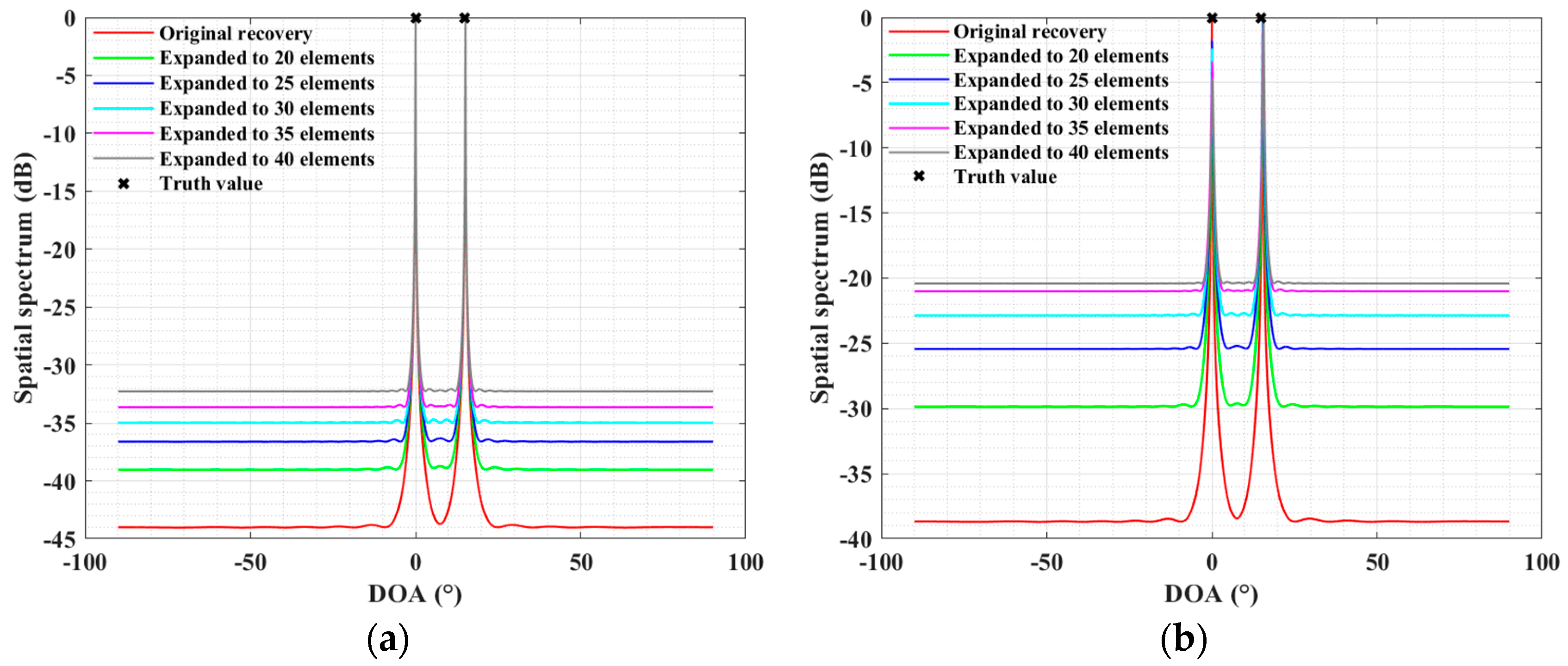
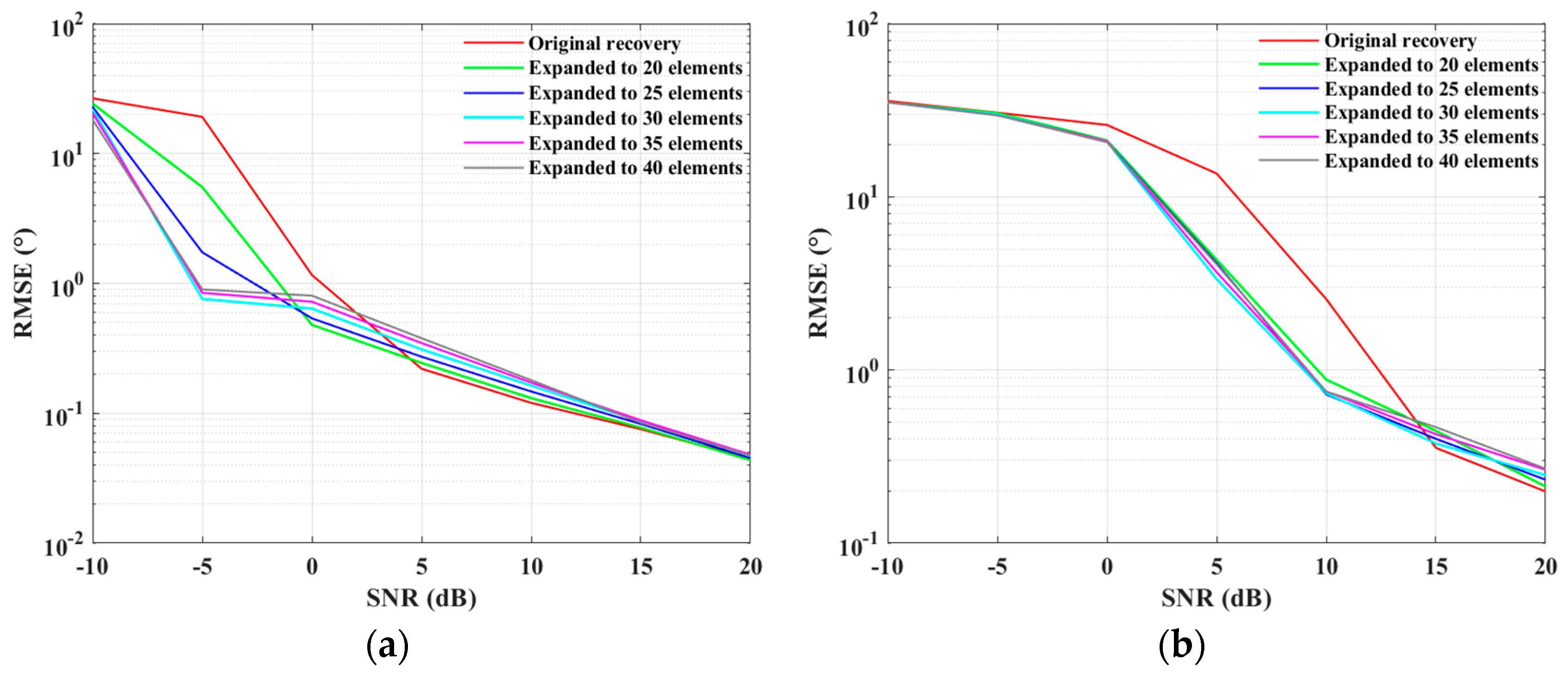
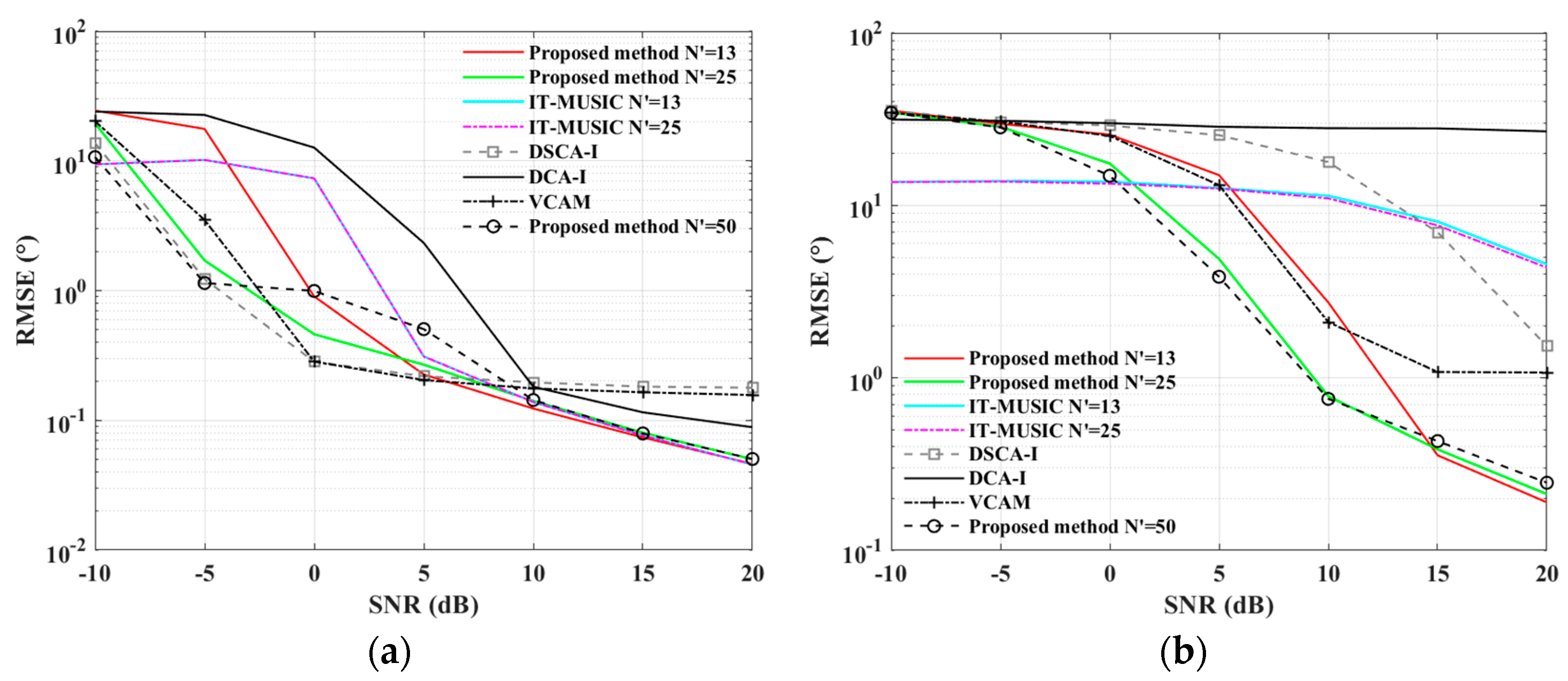
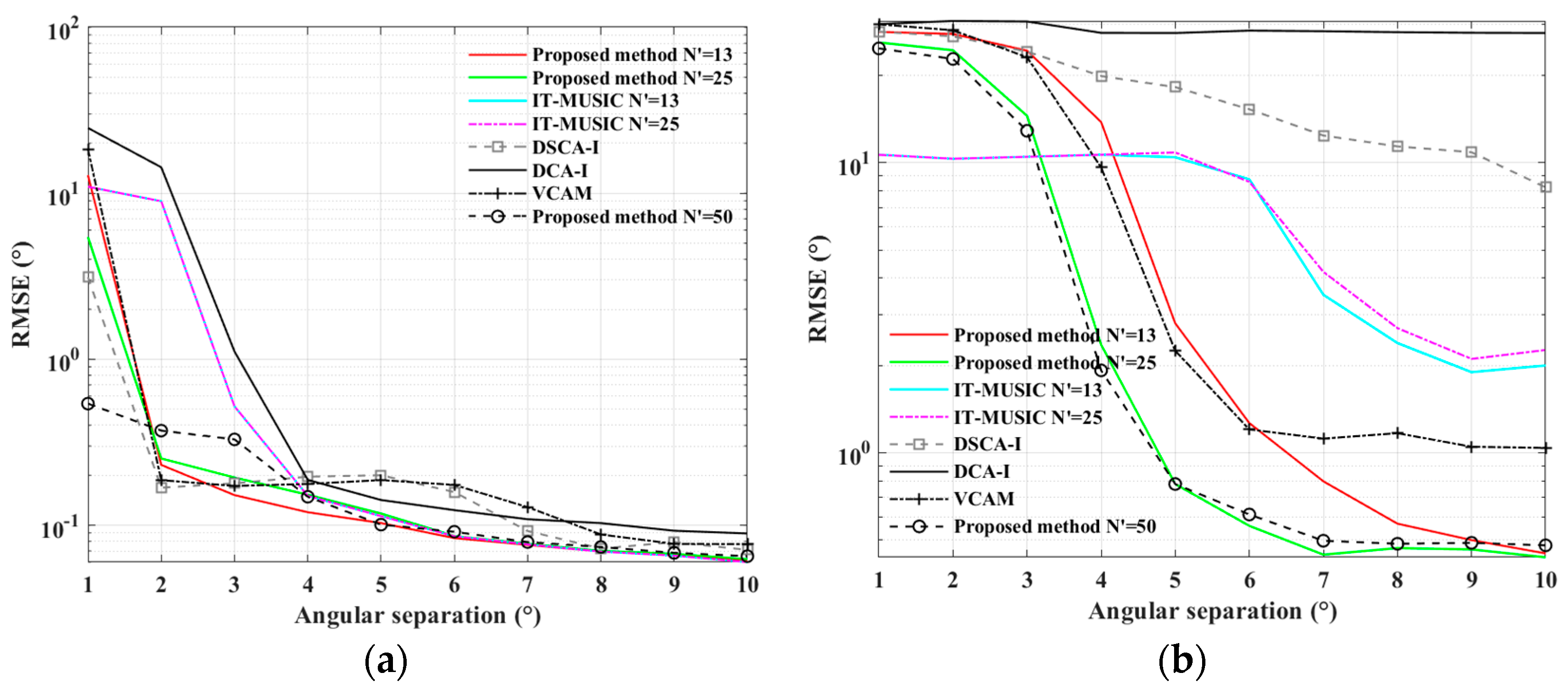
4. Experiment Results
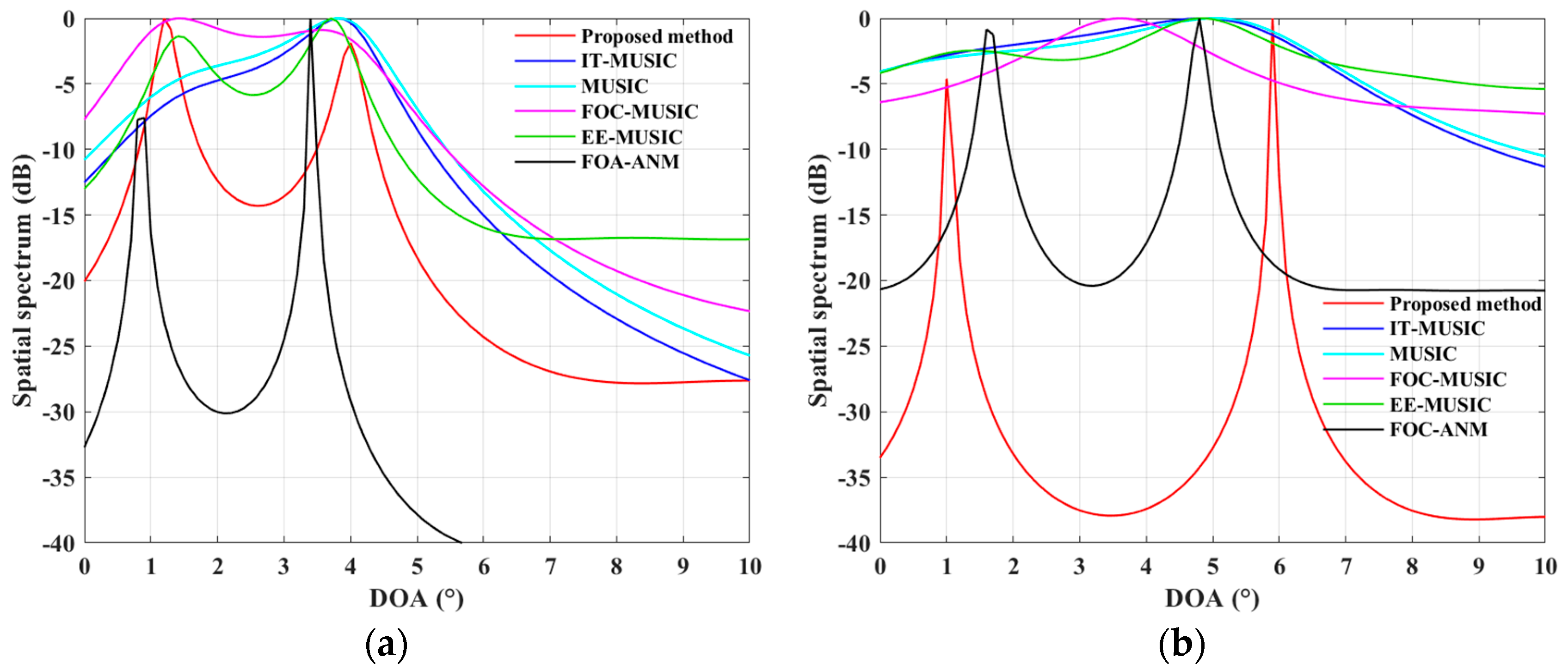
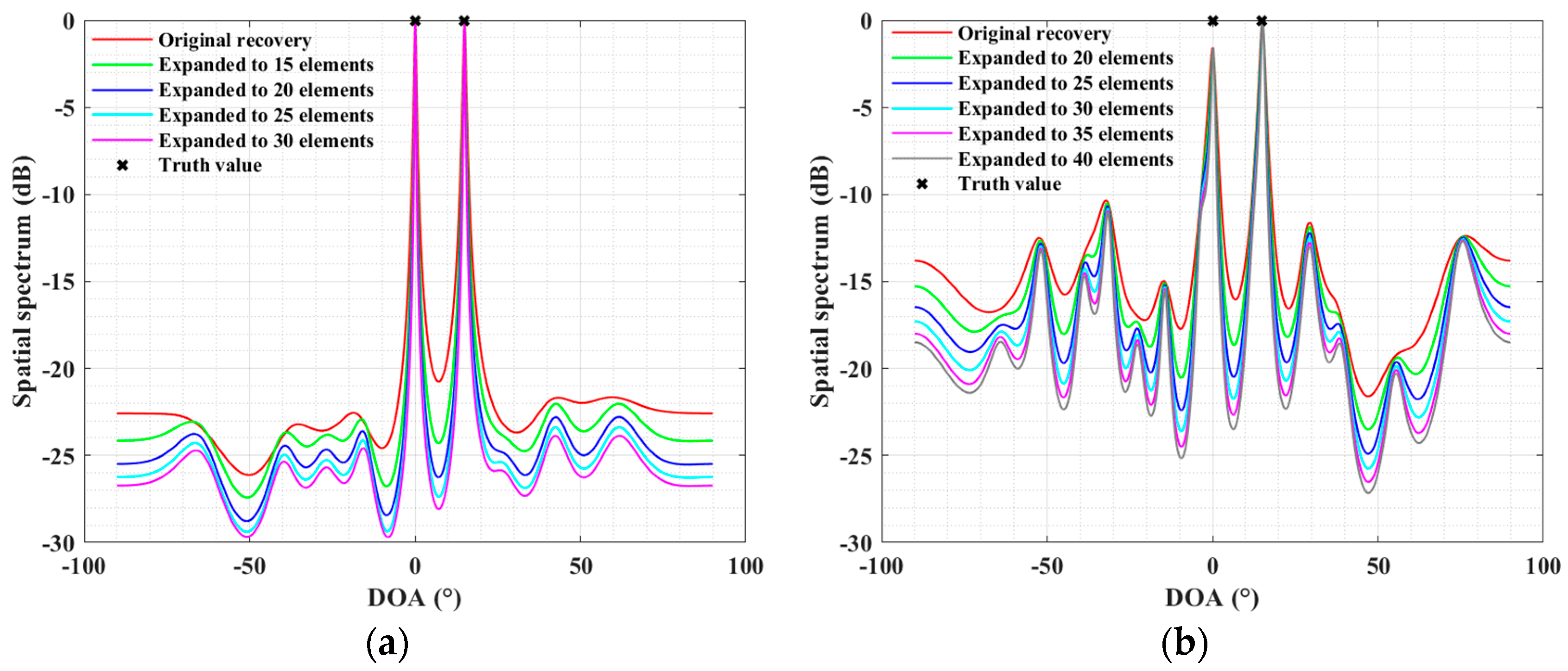
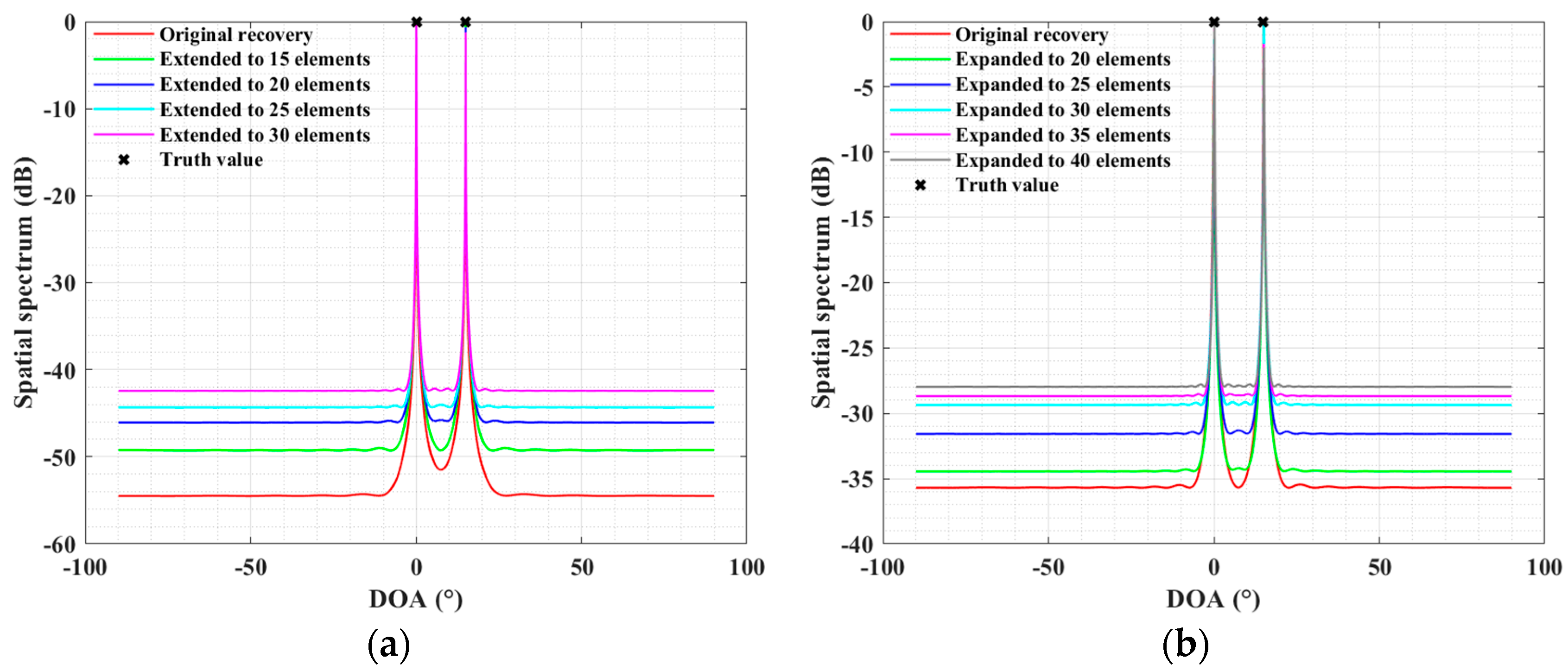
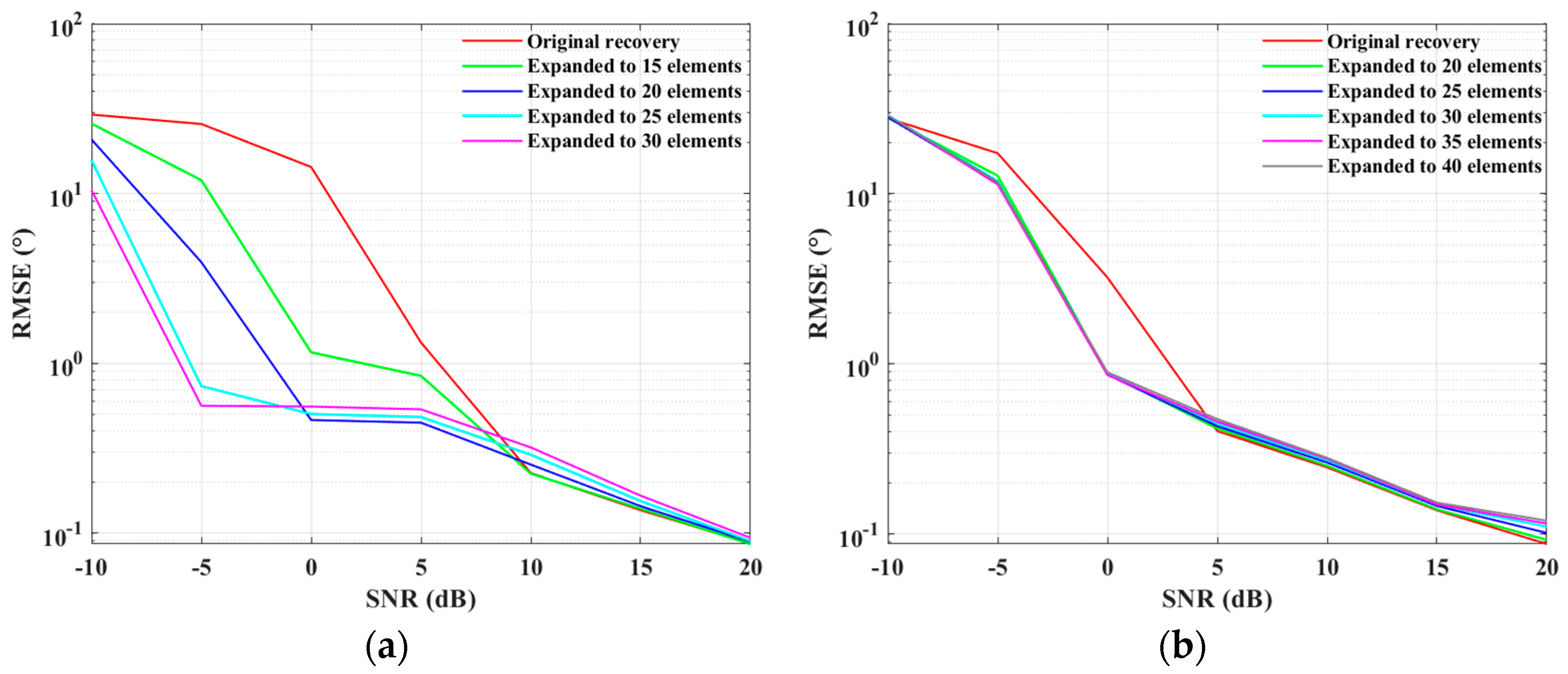
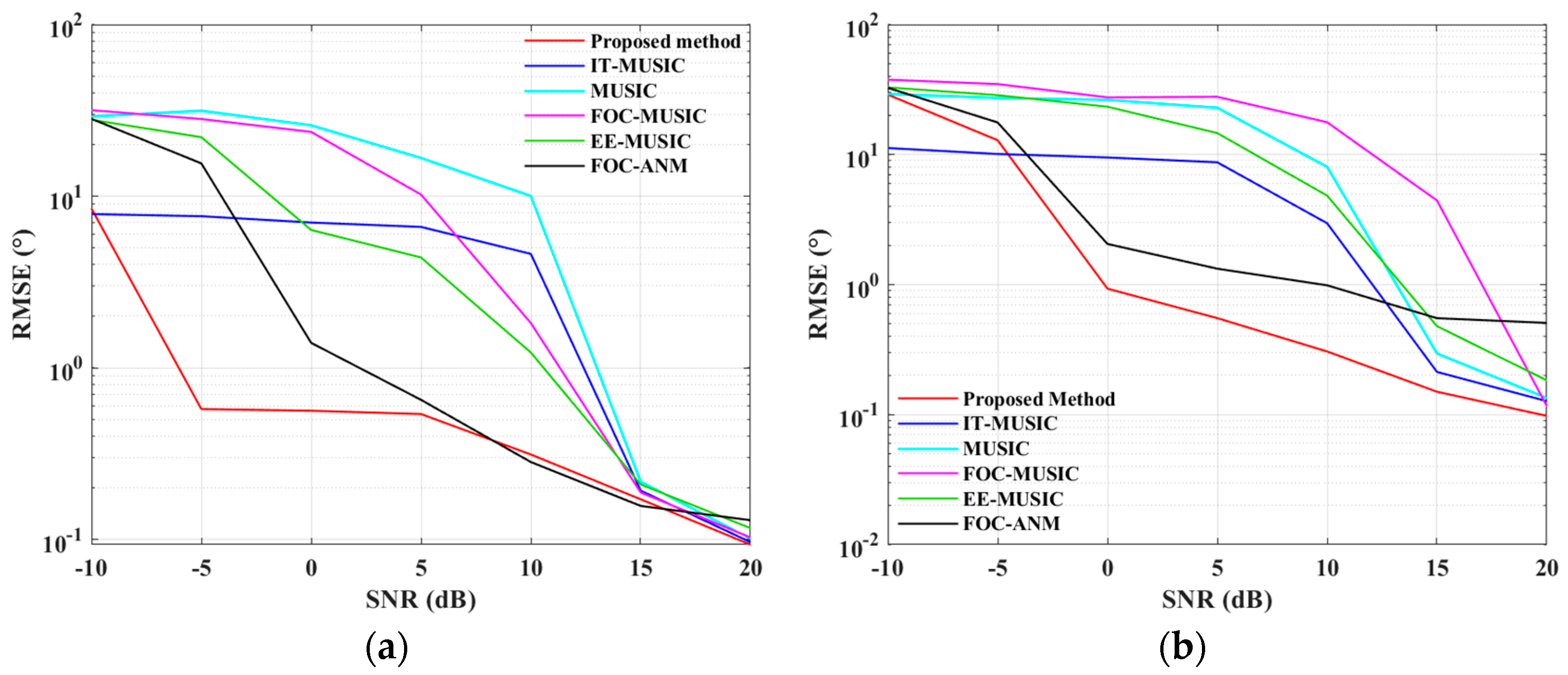
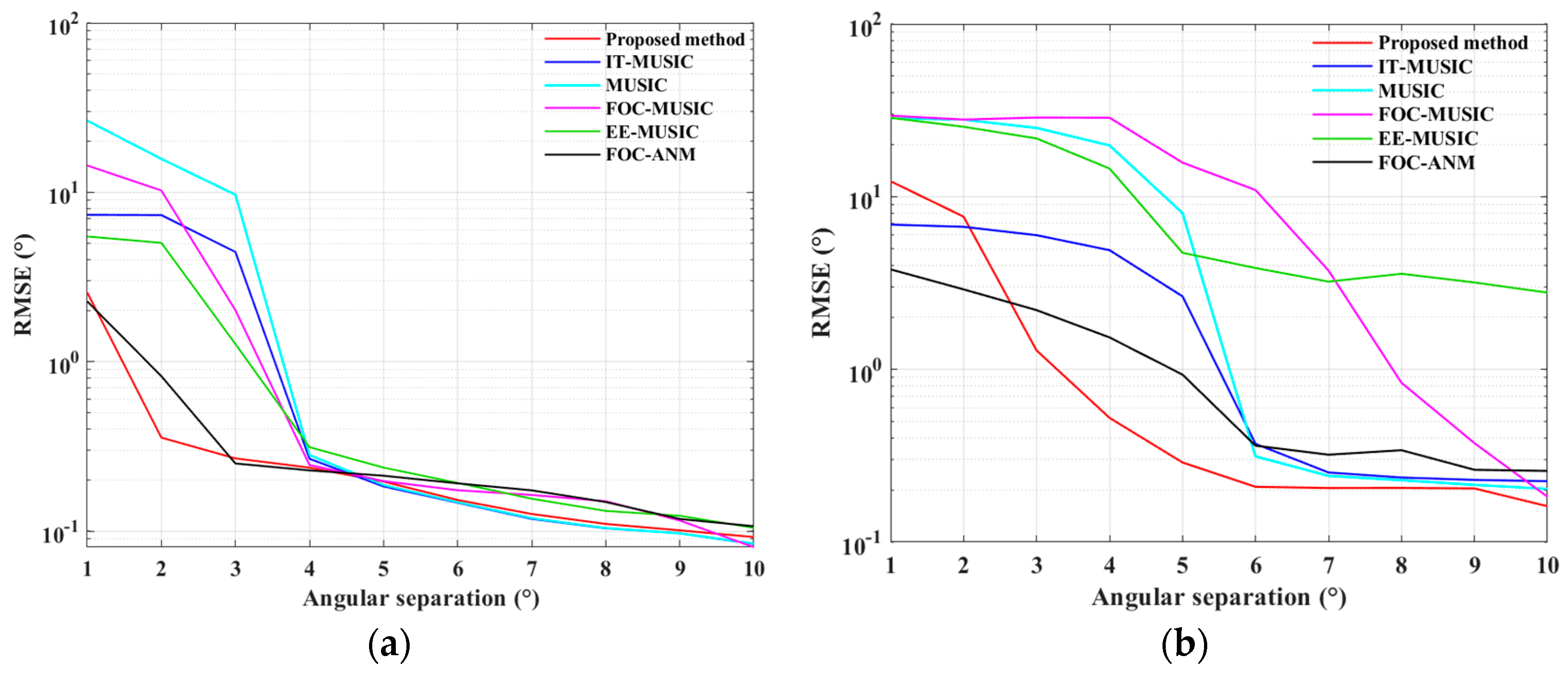
4.1. Simulations for the ULA Case
4.2. Simulations for the SLA Case
5. Conclusions
- (1)
- It remains a continuous domain sparse solving problem constructed based on the atomic norm, avoiding issues with angles not falling on a grid and offering higher estimation accuracy.
- (2)
- The array aperture can be freely extended, unlike methods based on FOC, sparse arrays’ virtual arrays, and other extension methods where the virtual array aperture is fixed. It should be noted that the virtual extension in this method is also restricted.
- (3)
- It can suppress certain noise components, which is beneficial for parameter estimation.
- (4)
- For sparse arrays, it encompasses both interpolation and extrapolation, forming a larger virtual ULA covariance matrix, unlike interpolation methods that typically only fill in missing elements for sparse arrays.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
Appendix C
Appendix D
Appendix E
References
- Sharma, A.; Mathur, S. Performance analysis of adaptive array signal processing algorithms. IETE Tech. Rev. 2016, 33, 472–491. [Google Scholar] [CrossRef]
- Ma, T.; Du, J.; Shao, H. A Nyström-Based Low-Complexity Algorithm with Improved Effective Array Aperture for Coherent DOA Estimation in Monostatic MIMO Radar. Remote Sens. 2022, 14, 2646. [Google Scholar] [CrossRef]
- Pesavento, M.; Trinh-Hoang, M.; Viberg, M. Three More Decades in Array Signal Processing Research: An optimization and structure exploitation perspective. IEEE Signal Process. Mag. 2023, 40, 92–106. [Google Scholar] [CrossRef]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Yan, F.G.; Shen, Y. Overview of efficient algorithms for super-resolution DOA estimates. Syst. Eng. Electron. 2015, 37, 1465–1475. [Google Scholar]
- Paulraj, A.; Roy, R.; Kailath, T. A subspace rotation approach to signal parameter estimation. Proc. IEEE 1986, 74, 1044–1046. [Google Scholar] [CrossRef]
- Pan, J.; Sun, M.; Wang, Y.; Zhang, X. An enhanced spatial smoothing technique with ESPRIT algorithm for direction of arrival estimation in coherent scenarios. IEEE Trans. Signal Process. 2020, 68, 3635–3643. [Google Scholar] [CrossRef]
- Cox, H.; Zeskind, R.; Owen, M. Robust adaptive beamforming. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 1365–1376. [Google Scholar] [CrossRef]
- Chung, P.J.; Viberg, M.; Yu, J. DOA estimation methods and algorithms. In Academic Press Library in Signal Processing, 1st ed.; Elsevier: Oxford, UK, 2014; Volume 3, pp. 599–650. [Google Scholar]
- Abramovich, Y.I.; Johnson, B.A. Expected likelihood support for deterministic maximum likelihood DOA estimation. Signal Process. 2013, 93, 3410–3422. [Google Scholar] [CrossRef]
- Trinh-Hoang, M.; Viberg, M.; Pesavento, M. Partial relaxation approach: An eigenvalue-based DOA estimator framework. IEEE Trans. Signal Process. 2018, 66, 6190–6203. [Google Scholar] [CrossRef]
- Chen, H.; Li, H.; Yang, M.; Xiang, C.; Suzuki, M. General Improvements of Heuristic Algorithms for Low Complexity DOA Estimation. Int. J. Antennas Propag. 2019, 2019, 3858794. [Google Scholar] [CrossRef]
- Chen, H.; Ahmad, F.; Vorobyov, S.; Porikli, F. Tensor Decompositions in Wireless Communications and MIMO Radar. IEEE J. Sel. Top. Signal Process. 2021, 15, 438–453. [Google Scholar] [CrossRef]
- Massa, A.; Marcantonio, D.; Chen, X.; Li, M.; Salucci, M. DNNs as applied to electromagnetics, antennas, and propagation—A review. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2225–2229. [Google Scholar] [CrossRef]
- Papageorgiou, G.K.; Sellathurai, M.; Eldar, Y.C. Deep networks for direction-of-arrival estimation in low SNR. IEEE Trans. Signal Process. 2021, 69, 3714–3729. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; Huang, Y.; Zhang, P. DOA estimation method based on cascaded neural network for two closely spaced sources. IEEE Signal Process. Lett. 2020, 27, 570–574. [Google Scholar] [CrossRef]
- Zhu, H.; Feng, W.; Feng, C.; Ma, T.; Zou, B. Deep Unfolded Gridless DOA Estimation Networks Based on Atomic Norm Minimization. Remote Sens. 2022, 15, 13. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, X.; Yang, J.; Sun, M. How to overcome basis mismatch: From atomic norm to gridless compressive sensing. Acta Autom. Sin. 2016, 42, 335–346. [Google Scholar]
- Emadi, M.; Miandji, E.; Unger, J. OMP-based DOA estimation performance analysis. Digit. Signal Process. 2018, 79, 57–65. [Google Scholar] [CrossRef]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Chandrasekaran, V.; Recht, B.; Parrilo, P.A.; Willsky, A.S. The convex geometry of linear inverse problems. Found. Comput. Math. 2012, 12, 805–849. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L.; Stoica, P. Vandermonde decomposition of multilevel Toeplitz matrices with application to multidimensional super-resolution. IEEE Trans. Inf. Theory 2016, 62, 3685–3701. [Google Scholar] [CrossRef]
- Yang, Z.; Li, J.; Stoica, P.; Xie, L. Sparse Methods for Direction-of-arrival Estimation. In Academic Press Library in Signal Processing, 1st ed.; Elsevier: London, UK, 2018; Volume 7, pp. 509–581. [Google Scholar]
- Yang, Z.; Xie, L. Exact joint sparse frequency recovery via optimization methods. IEEE Trans. Signal Process. 2016, 64, 5145–5157. [Google Scholar] [CrossRef]
- Li, Y.; Chi, Y. Off-the-grid line spectrum denoising and estimation with multiple measurement vectors. IEEE Trans. Signal Process. 2015, 64, 1257–1269. [Google Scholar] [CrossRef]
- Candès, E.J.; Fernandez-Granda, C. Towards a mathematical theory of super-resolution. Commun. Pure Appl. Math. 2014, 67, 906–956. [Google Scholar] [CrossRef]
- Tang, G.; Bhaskar, B.N.; Shah, P.; Recht, B. Compressed sensing off the grid. IEEE Trans. Inf. Theory 2013, 59, 7465–7490. [Google Scholar] [CrossRef]
- Stoica, P.; Babu, P.; Li, J. SPICE: A sparse covariance-based estimation method for array processing. IEEE Trans. Signal Process. 2010, 59, 629–638. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L.; Zhang, C. A discretization-free sparse and parametric approach for linear array signal processing. IEEE Trans. Signal Process. 2014, 62, 4959–4973. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L. On gridless sparse methods for multi-snapshot direction of arrival estimation. Circuits Syst. Signal Process. 2017, 36, 3370–3384. [Google Scholar] [CrossRef]
- Si, W.; Qu, X.; Liu, L. Augmented lagrange based on modified covariance matching criterion method for DOA estimation in compressed sensing. Sci. World J. 2014, 2014, 241469. [Google Scholar] [CrossRef]
- Swärd, J.; Adalbjörnsson, S.I.; Jakobsson, A. Generalized sparse covariance-based estimation. Signal Process. 2018, 143, 311–319. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Zhang, Y.; Liu, S.; Luo, J.; Zhou, X.; Yang, J.; Jakobsson, A. High-throughput hyperparameter-free sparse source location for massive TDM-MIMO radar: Algorithm and FPGA implementation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Richards, M.A. Fundamentals of Radar Signal Processing, 2nd ed.; Mcgraw-hill: New York, NY, USA, 2005. [Google Scholar]
- Liu, Y.; Shi, J.; Li, X. Research progress on sparse array MIMO radar parameter estimation. Sci. Sin. Inform. 2022, 52, 1560–1576. (In Chinese) [Google Scholar] [CrossRef]
- Adhikari, K.; Wage, K.E. Sparse Arrays for Radar, Sonar, and Communications, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2024. [Google Scholar]
- Swingler, D.N.; Walker, R.S. Line-array beamforming using linear prediction for aperture interpolation and extrapolation. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 16–30. [Google Scholar] [CrossRef]
- Chen, H.; Kasilingam, D. Performance analysis of linear predictive super-resolution processing for antenna arrays. In Proceedings of the Fourth IEEE Workshop on Sensor Array and Multichannel Processing, Waltham, MA, USA, 12–14 July 2006; pp. 157–161. [Google Scholar]
- Mo, Q.; Ma, Z.; Yu, C. Azimuth super-resolution based on Improved AR-MUSIC algorithm. Sci. Technol. Eng. 2015, 15, 66–71. [Google Scholar]
- Sim, H.; Lee, S.; Kang, S.; Kim, S.C. Enhanced DOA estimation using linearly predicted array expansion for automotive radar systems. IEEE Access 2019, 7, 47714–47727. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, H.; Wan, S. An effective DOA method via virtual array transformation. Sci. China Ser. E Technol. Sci. 2001, 44, 75–82. [Google Scholar] [CrossRef]
- Kang, S.; Lee, S.; Lee, J.-E.; Kim, S.-C. Improving the performance of DOA estimation using virtual antenna in automotive radar. IEICE Trans. Commun. 2017, 100, 771–778. [Google Scholar] [CrossRef]
- Lee, S.; Kim, S.C. Logarithmic-domain array interpolation for improved direction of arrival estimation in automotive radars. Sensors 2019, 19, 2410. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhang, G.; Leung, H. Grid-less coherent DOA estimation based on fourth-order cumulants with Gaussian coloured noise. IET Radar Sonar Navig. 2020, 14, 677–685. [Google Scholar] [CrossRef]
- Chevalier, P.; Albera, L.; Ferréol, A.; Comon, P. On the virtual array concept for higher order array processing. IEEE Trans. Signal Process. 2005, 53, 1254–1271. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, G.; Leung, H. Gridless sparse methods based on fourth-order cumulant for DOA estimation. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3416–3419. [Google Scholar]
- Yuan, J.; Zhang, G.; Zhang, Y.; Leung, H. A gridless fourth-order cumulant-based DOA estimation method under unknown colored noise. IEEE Wirel. Commun. Lett. 2022, 11, 1037–1041. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, G.; Qi, C.; Yang, X.; Xiong, W. FOC-Based Gridless Harmonic Retrieval Joint MM-Estimation: DOA Estimation for FMCW Radar Against Unknown Colored Clutter-Noise. IEEE Sens. J. 2022, 22, 5879–5888. [Google Scholar] [CrossRef]
- Ma, W.K.; Hsieh, T.H.; Chi, C.Y. DOA estimation of quasi-stationary signals with less sensors than sources and unknown spatial noise covariance: A Khatri–Rao subspace approach. IEEE Trans. Signal Process. 2009, 58, 2168–2180. [Google Scholar] [CrossRef]
- Zhou, C.; Gu, Y.; Fan, X.; Shi, Z.; Mao, G.; Zhang, Y.D. Direction-of-arrival estimation for coprime array via virtual array interpolation. IEEE Trans. Signal Process. 2018, 66, 5956–5971. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Z.; Ren, S.; Cao, S. DOA estimation based on the difference and sum coarray for coprime arrays. Digit. Signal Process. 2017, 69, 22–31. [Google Scholar] [CrossRef]
- Ding, Y.; Ren, S.; Wang, W.; Xue, C. DOA estimation based on sum–difference coarray with virtual array interpolation concept. EURASIP J. Adv. Signal Process. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Zhang, Y.; Hu, G.; Zhou, H.; Bai, J.; Zhan, C.; Guo, S. Direction of Arrival Estimation of Generalized Nested Array via Difference–Sum Co-Array. Sensors 2023, 23, 906. [Google Scholar] [CrossRef]
- Liu, K.; Fu, J.; Zou, N.; Zhang, G.; Hao, Y. Array aperture extension method using covariance matrix fitting. ACTA ACUSTICA 2023, 48, 911–919. [Google Scholar]
- CVX Toolbox. 2020. Available online: http://cvxr.com/cvx (accessed on 1 January 2020).
- Fernández Rodríguez, A.; de Santiago Rodrigo, L.; López Guillén, E.; Rodríguez Ascariz, J.M.; Miguel Jiménez, J.M.; Boquete, L. Coding Prony’s method in MATLAB and applying it to biomedical signal filtering. BMC Bioinform. 2018, 19, 1–14. [Google Scholar] [CrossRef]
- Ottersten, B.; Stoica, P.; Roy, R. Covariance Matching Estimation Techniques for Array Signal Processing Applications. Digit. Signal Process. 1998, 8, 185–210. [Google Scholar] [CrossRef]
- Li, H.; Stoica, P.; Li, J. Computationally efficient maximum likelihood estimation of structured covariance matrices. IEEE Trans. Signal Process. 1999, 47, 1314–1323. [Google Scholar]
- Yang, Z.; Xie, L. Enhancing Sparsity and Resolution via Reweighted Atomic Norm Minimization. IEEE Trans. Signal Process. 2016, 64, 995–1006. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L. On Gridless Sparse Methods for Line Spectral Estimation From Complete and Incomplete Data. IEEE Trans. Signal Process. 2015, 63, 3139–3153. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Yang, M.; Zhu, H.; Zhang, Y.; Zhou, D. DOA Estimation Based on Virtual Array Aperture Expansion Using Covariance Fitting Criterion. Remote Sens. 2024, 16, 2517. https://doi.org/10.3390/rs16142517
Ma T, Yang M, Zhu H, Zhang Y, Zhou D. DOA Estimation Based on Virtual Array Aperture Expansion Using Covariance Fitting Criterion. Remote Sensing. 2024; 16(14):2517. https://doi.org/10.3390/rs16142517
Chicago/Turabian StyleMa, Teng, Minglei Yang, Hangui Zhu, Yule Zhang, and Dingsen Zhou. 2024. "DOA Estimation Based on Virtual Array Aperture Expansion Using Covariance Fitting Criterion" Remote Sensing 16, no. 14: 2517. https://doi.org/10.3390/rs16142517
APA StyleMa, T., Yang, M., Zhu, H., Zhang, Y., & Zhou, D. (2024). DOA Estimation Based on Virtual Array Aperture Expansion Using Covariance Fitting Criterion. Remote Sensing, 16(14), 2517. https://doi.org/10.3390/rs16142517