

iblueCulture: Data Streaming and Object Detection in a Real-Time Video Streaming Underwater System

 ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Pilot Sites
2.2. System Composition
2.2.1. Underwater System
2.2.2. Surface Close-Proximity Installation
2.2.3. Remote Site
2.3. Mobile Application
2.4. Real-Time Texturing
2.5. Object Detection in the Underwater Environment
2.5.1. Relevant Bibliography
- On one hand, in the underwater environment of the wreck, other moving objects could appear besides fish (e.g., a bottle or other debris) or even a moving current that would not allow the correct creation of a stable background.
- The algorithm had relatively low speeds that were prohibitive for the part of real-time analysis that we aimed at.
2.5.2. Methodology
- Video object tracking and segmentation with shot changes.
- Visualized development and data annotation for video object tracking and segmentation.
- Object-centric downstream video tasks, such as video inpainting and editing.
- A network that performs the extraction of the features from the image (Backbone).
- A network that connects these features to the final stage where the predictions are made (Neck).
- A network that makes the final predictions and gives its output to the bounding box, within which the object (Head) is detected.
- The use of the Kalman filter [35], which is one of the most powerful tools for measuring and predicting quantities over time (Motion Models). Once initialized, the Kalman filter predicts the state of the system at the next step. It also provides a measure of the uncertainty of the prediction. Once the measurement is obtained, the Kalman filter updates (or corrects) the prediction and uncertainty of the current state. Then, it predicts the following situations and so on.
- The alignment of the predictions of the new frames with the predictions that have already been made and the use of separate additional models that enhance the appearance characteristics of the objects (appearance models and re-identification).
2.5.3. Real-Time Analysis
2.5.4. Evaluation
2.5.5. Data and Training
- Epochs = 30;
- Learning rate = 0.001;
- Batch size = 16;
- Optimizer = ‘auto’.
- Network architecture = ‘yolov8’;
- Activation function = ‘leaky relu’.
3. Results
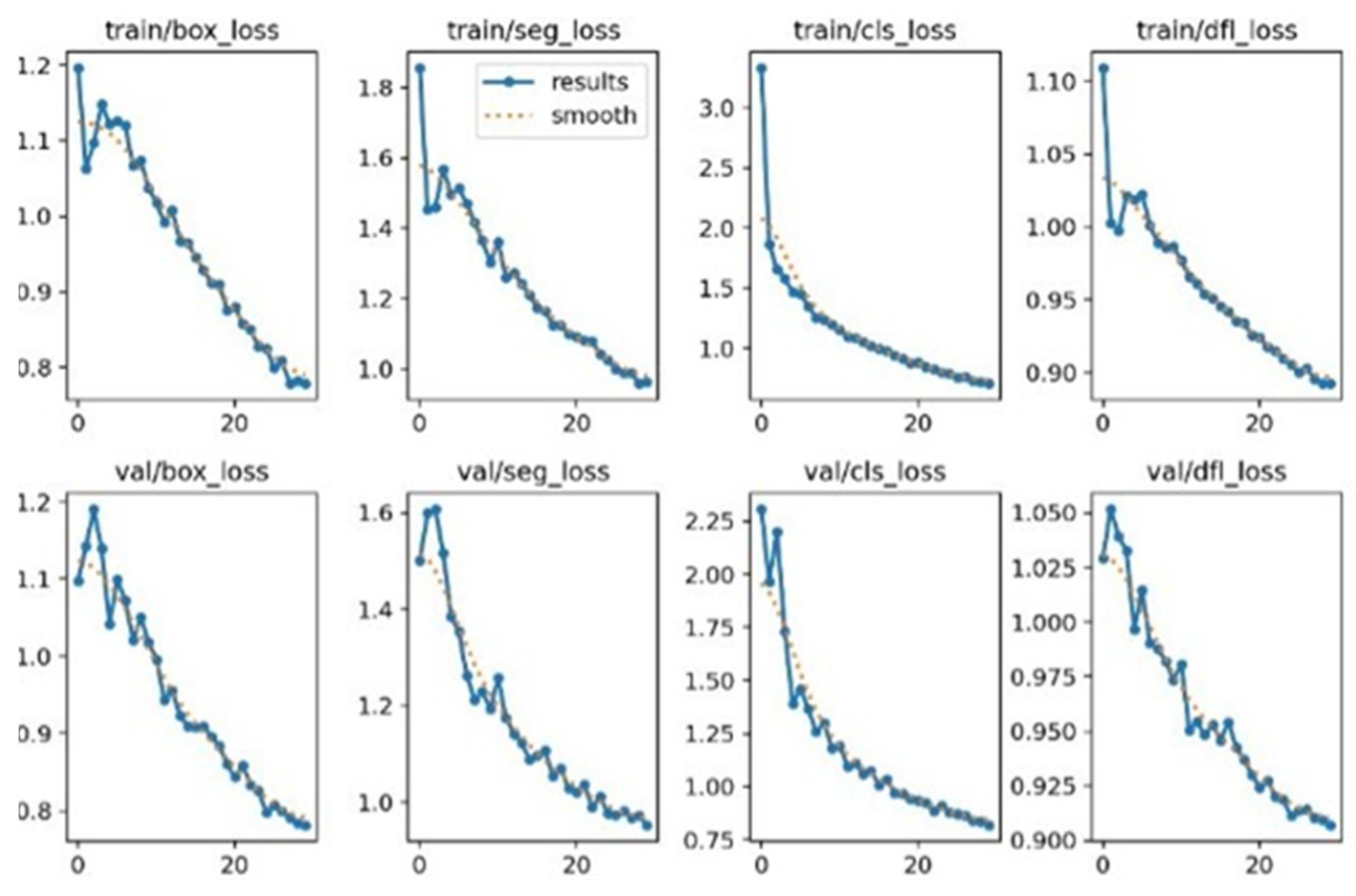
3.1. Losses
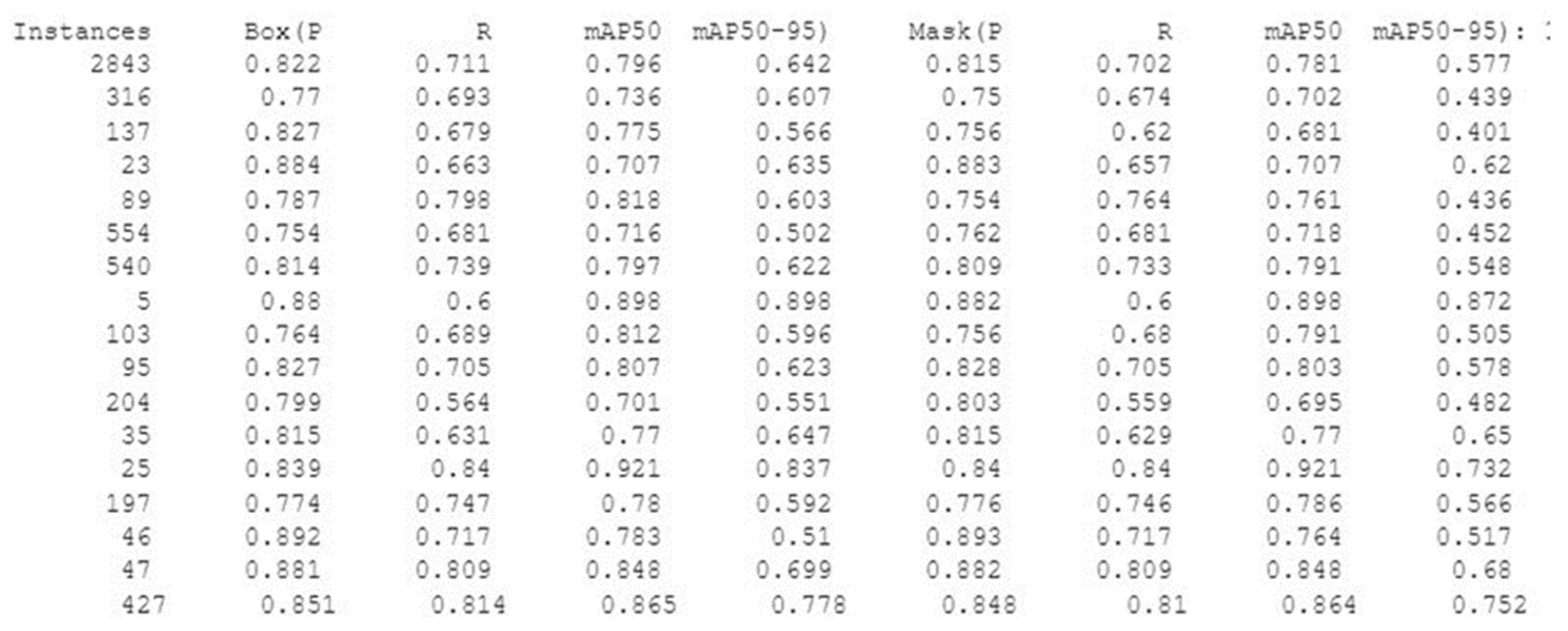
3.2. Validation
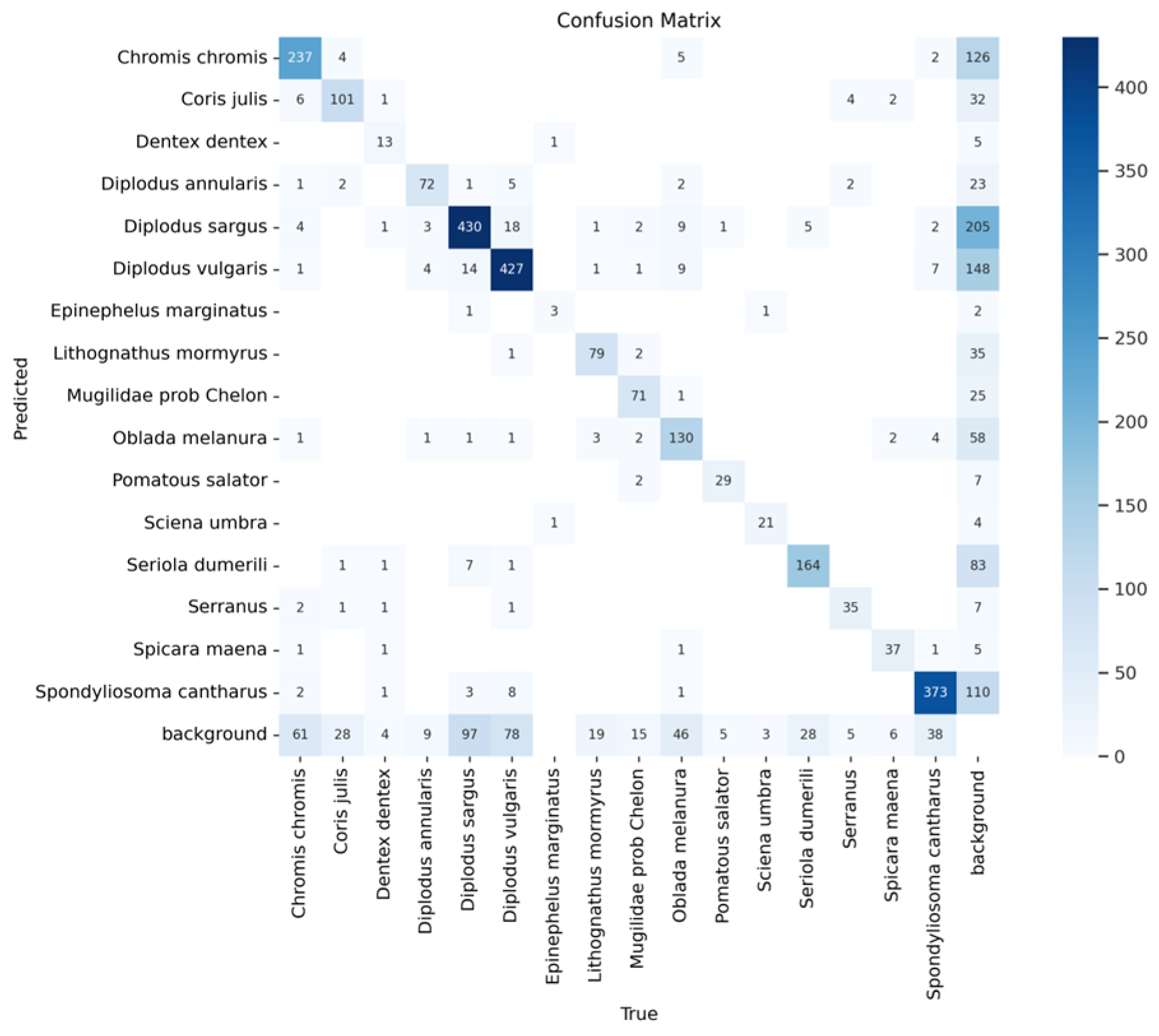
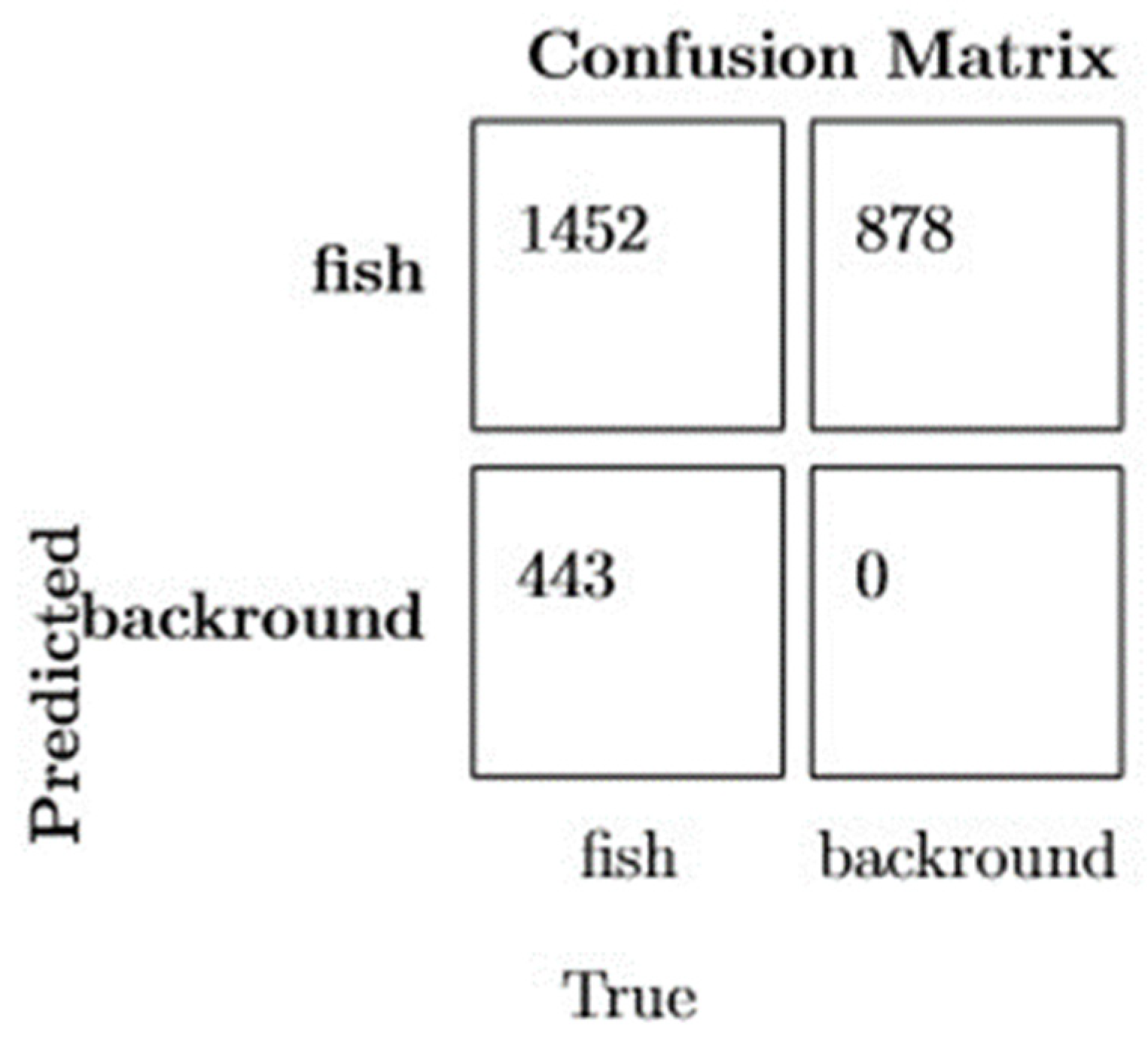
3.3. Confusion Matrix
3.4. Times
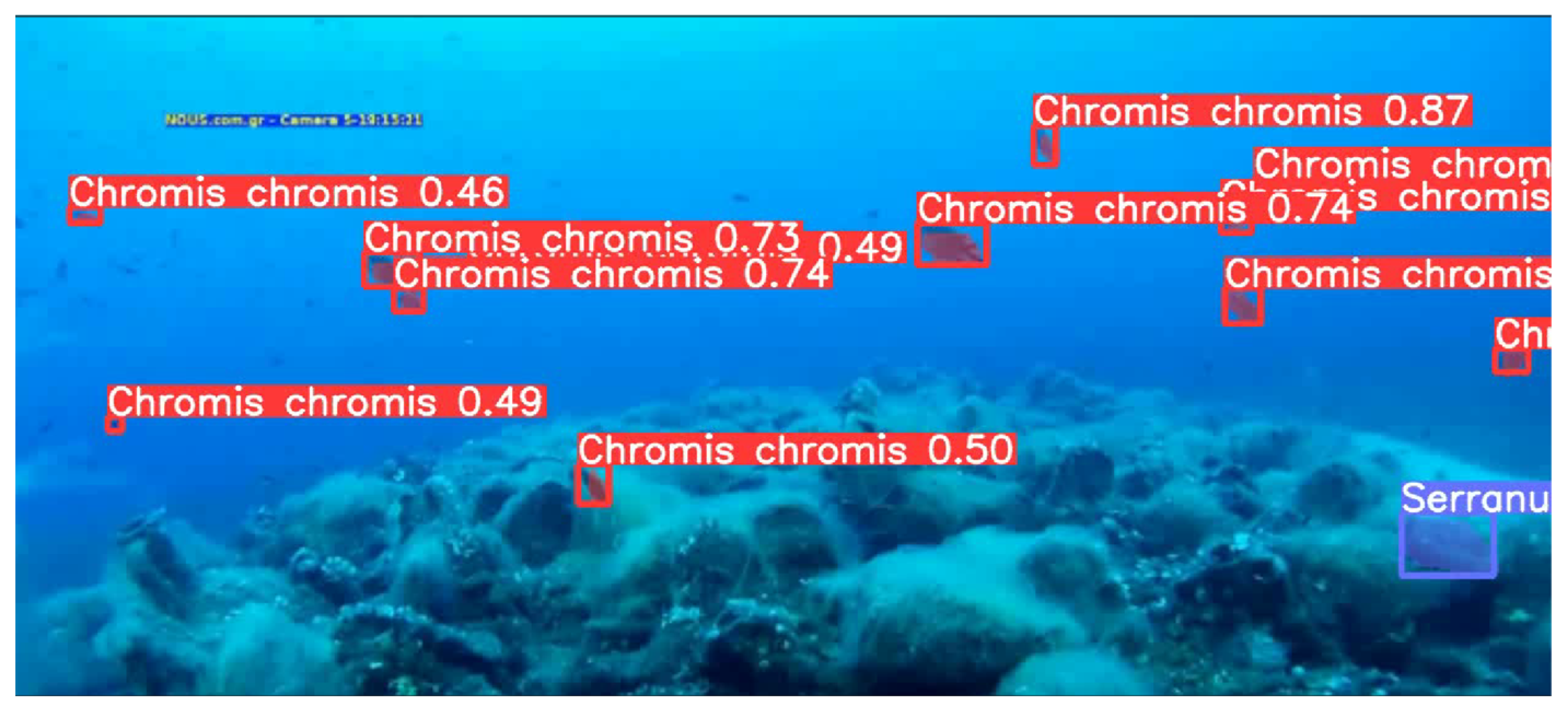
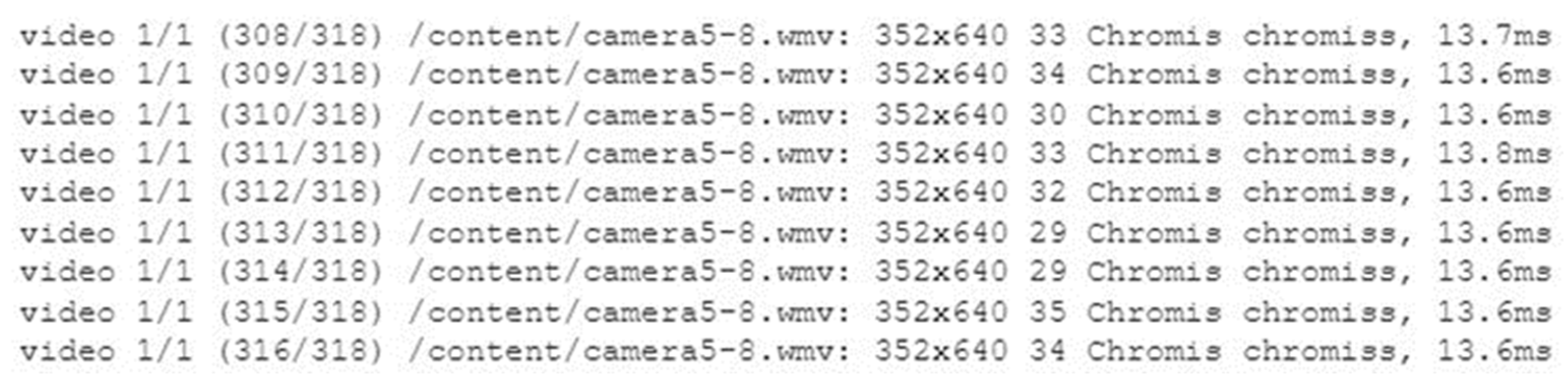
3.5. Detection and Segmentation per Frame
3.6. Masking per Frame
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vasa Museum. Available online: https://www.vasamuseet.se/en (accessed on 4 March 2024).
- O’Leary, M.J.; Paumard, V.; Ward, I. Exploring Sea Country through high-resolution 3D seismic imaging of Australia’s NW shelf: Resolving early coastal landscapes and preservation of underwater cultural heritage. Quat. Sci. Rev. 2020, 239, 106353. [Google Scholar] [CrossRef]
- Pydyn, A.; Popek, M.; Kubacka, M.; Janowski, Ł. Exploration and reconstruction of a medieval harbour using hydroacoustics, 3-D shallow seismic and underwater photogrammetry: A case study from Puck, southern Baltic Sea. Archaeol. Prospect. 2021, 28, 527–542. [Google Scholar] [CrossRef]
- Violante, C.; Masini, N.; Abate, N. Integrated remote sensing technologies for multi-depth seabed and coastal cultural resources: The case of the submerged Roman site of Baia (Naples, Italy). In Proceedings of the EUG 2022, Vienna, Austria, 23–27 May 2022. [Google Scholar]
- Menna, F.; Agrafiotis, P.; Georgopoulos, A. State of the art and applications in archaeological underwater 3D recording and mapping. J. Cult. Herit. 2018, 33, 231–248. [Google Scholar] [CrossRef]
- Gkionis, P.; Papatheodorou, G.; Geraga, M. The Benefits of 3D and 4D Synthesis of Marine Geophysical Datasets for Analysis and Visualisation of Shipwrecks, and for Interpretation of Physical Processes over Shipwreck Sites: A Case Study off Methoni, Greece. J. Mar. Sci. Eng. 2021, 9, 1255. [Google Scholar] [CrossRef]
- Bruno, F.; Barbieri, L.; Mangeruga, M.; Cozza, M.; Lagudi, A.; Čejka, J.; Liarokapis, F.; Skarlatos, D. Underwater augmented reality for improving the diving experience in submerged archaeological sites. Ocean Eng. 2019, 190, 106487. [Google Scholar] [CrossRef]
- Yamafune, K.; Torres, R.; Castro, F. Multi-Image Photogrammetry to Record and Reconstruct Underwater Shipwreck Sites. J. Archaeol. Method Theory 2017, 24, 703–725. [Google Scholar] [CrossRef]
- Aragón, E.; Munar, S.; Rodríguez, J.; Yamafune, K. Underwater photogrammetric monitoring techniques for mid-depth shipwrecks. J. Cult. Herit. 2018, 34, 255–260. [Google Scholar] [CrossRef]
- Balletti, C.; Beltrame, C.; Costa, E.; Guerra, F.; Vernier, P. 3D reconstruction of marble shipwreck cargoes based on underwater multi-image photogrammetry. Digit. Appl. Archaeol. Cult. Herit. 2016, 3, 1–8. [Google Scholar] [CrossRef]
- Liarokapis, F.; Kouřil, P.; Agrafiotis, P.; Demesticha, S.; Chmelík, J.; Skarlatos, D. 3D modelling and mapping for virtual exploration of underwater archaeology assets. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 425–431. [Google Scholar] [CrossRef]
- Skarlatos, D.; Agrafiotis, P.; Balogh, T.; Bruno, F.; Castro, F.; Davidde Petriaggi, D.; Demesticha, S.; Doulamis, A.; Drap, P.; Georgopoulos, A.; et al. Project iMARECULTURE: Advanced VR, iMmersive Serious Games and Augmented REality as Tools to Raise Awareness and Access to European Underwater CULTURal heritagE. In Digital Heritage. Progress in Cultural Heritage: Documentation, Preservation, and Protection, EuroMed 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 10058. [Google Scholar] [CrossRef]
- Markku Reunanen, M.; Díaz, L.; Horttana, T. A Holistic User-Centered Approach to Immersive Digital Cultural Heritage Installations: Case Vrouw Maria. J. Comput. Cult. Herit. 2015, 7, 1–16. [Google Scholar] [CrossRef]
- Bruno, F.; Lagudi, A.; Barbieri, L. Virtual Reality Technologies for the Exploitation of Underwater Cultural Heritage. In Latest Developments in Reality-Based 3D Surveying and Modelling; Remondino, F., Georgopoulos, A., González-Aguilera, D., Agrafiotis, P., Eds.; MDPI: Basel, Switzerland, 2018; pp. 220–236. [Google Scholar] [CrossRef]
- Metashape System Requirements, by Agisoft. Available online: https://www.agisoft.com/downloads/system-requirements/ (accessed on 4 March 2024).
- OpenSFM. Available online: https://opensfm.org (accessed on 4 March 2024).
- Viswanath, V. Object Segmentation and Tracking in Videos. UC San Diego. ProQuest ID: Viswanath_ucsd_0033M_19737. Merritt ID: Ark:/13030/m5wh83s6. 2020. Available online: https://escholarship.org/uc/item/4wk7s73k (accessed on 2 March 2024).
- Segmentation vs. Detection vs. Classification in Computer Vision: A Comparative Analysis. Available online: https://www.picsellia.com/post/segmentation-vs-detection-vs-classification-in-computer-vision-a-comparative-analysis (accessed on 3 March 2024).
- Yao, R.; Lin, G.; Xia, S.; Zhao, J.; Zhou, Y. Video Object Seg-mentation and Tracking: A Survey. ACM Transactions on Intelligent Systems and Technology. arXiv 2019, arXiv:1904.09172. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Girshick, R.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Barnich, O.; Van Droogenbroeck, M. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.K.; Schwing, A.G. Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 640–658. [Google Scholar]
- Atkinson, R.C.; Shiffrin, R.M. Human memory: A proposed system and its control processes. In The Psychology of Learning and Motivation: II; Spence, K.W., Spence, J.T., Eds.; Academic Press: Cambridge, MA, USA, 1968. [Google Scholar] [CrossRef]
- Yang, J.; Gao, M.; Li, Z.; Gao, S.; Wang, F.; Zheng, F. Track Anything: Segment Anything Meets Videos. arXiv 2023, arXiv:2304.11968. [Google Scholar]
- ArtGAN. Available online: https://huggingface.co/spaces/ArtGAN/Segment-Anything-Video (accessed on 14 January 2024).
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ultralytics YOLO Documentation. Available online: https://docs.ultralytics.com/yolov5/ (accessed on 21 February 2024).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Wenkel, S.; Alhazmi, K.; Liiv, T.; Alrshoud, S.; Simon, M. Confidence Score: The Forgotten Dimension of Object Detection Performance Evaluation. Sensors 2021, 21, 4350. [Google Scholar] [CrossRef] [PubMed]
- Roboflow Fish Dataset. Available online: https://universe.roboflow.com/minor/fish_dataset_instance_segmentation/dataset/1/images (accessed on 3 March 2024).
- Roboflow. Available online: https://universe.roboflow.com/fish-dl/instance-con-sam-buenois/dataset/9 (accessed on 21 February 2024).
- Brief Review: YOLOv5 for Object Detection. Available online: https://sh-tsang.medium.com/brief-review-yolov5-for-object-detection-84cc6c6a0e3a (accessed on 20 February 2024).
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Kalman Filter. Available online: https://www.kalmanfilter.net/multiSummary.html (accessed on 14 January 2024).
- The Confusing Metrics of AP and MAP for Object Detection. Available online: https://yanfengliux.medium.com/the-confusing-metrics-of-ap-and-map-for-object-detection-3113ba0386ef (accessed on 3 March 2024).
- Zhou, Z. Detection and Counting Method of Pigs Based on YOLOV5_Plus: A Combination of YOLOV5 and Attention Mechanism. Math. Probl. Eng. 2022, 2022, 7078670. [Google Scholar] [CrossRef]
- Yang, F. An improved YOLO v3 algorithm for remote Sensing image target detection. J. Phys. Conf. Ser. 2021, 2132, 012028. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Secs | Quality Camera | Execution Time | Exec. Time w/o Vibrance | Exec. Time with No Preprocessing |
|---|---|---|---|---|
| 7 s | Camera 4 (blurred, not good) | 9 s | 7 s | 8–13 s (times varied) |
| 7 s | Camera 5 (good) | 11 s | 10 s | 10 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlachos, A.; Bargiota, E.; Krinidis, S.; Papadimitriou, K.; Manglis, A.; Fourkiotou, A.; Tzovaras, D. iblueCulture: Data Streaming and Object Detection in a Real-Time Video Streaming Underwater System. Remote Sens. 2024, 16, 2254. https://doi.org/10.3390/rs16132254
Vlachos A, Bargiota E, Krinidis S, Papadimitriou K, Manglis A, Fourkiotou A, Tzovaras D. iblueCulture: Data Streaming and Object Detection in a Real-Time Video Streaming Underwater System. Remote Sensing. 2024; 16(13):2254. https://doi.org/10.3390/rs16132254
Chicago/Turabian StyleVlachos, Apostolos, Eleftheria Bargiota, Stelios Krinidis, Kimon Papadimitriou, Angelos Manglis, Anastasia Fourkiotou, and Dimitrios Tzovaras. 2024. "iblueCulture: Data Streaming and Object Detection in a Real-Time Video Streaming Underwater System" Remote Sensing 16, no. 13: 2254. https://doi.org/10.3390/rs16132254
APA StyleVlachos, A., Bargiota, E., Krinidis, S., Papadimitriou, K., Manglis, A., Fourkiotou, A., & Tzovaras, D. (2024). iblueCulture: Data Streaming and Object Detection in a Real-Time Video Streaming Underwater System. Remote Sensing, 16(13), 2254. https://doi.org/10.3390/rs16132254