

IfCMD: A Novel Method for Radar Target Detection under Complex Clutter Backgrounds



Abstract
1. Introduction
- (1)
- Some researchers are devoted to improving the signal-to-clutter plus noise ratio (SCNR) of targets. One way is to suppress the clutter, and the representatives are moving target indication (MTI) [3,4,5] and adaptive filtering methods. But MTI is vulnerable to dynamic clutter [6], and adaptive filtering methods require prior knowledge of the target. Another way is to enhance the power of the target, such as the moving-target detection (MTD) [7] method. Its prevalence stems from the capability of coherently integrating the energy of the target and separating it from the clutter (due to their considerable speed difference) in the Doppler domain. However, the low-speed property of the slow-moving target causes its coupling with the clutter within the Doppler domain. As a result, the detection performance remains unsatisfactory after MTD.
- (2)
- Another group of methods detects targets by estimating the power level of the clutter background and calculating the detection threshold under the condition of the constant false alarm rate (CFAR) [8,9,10]. This type of method, called the CFAR detection method, typically assumes that the amplitude of the clutter obeys homogeneous Rayleigh distribution. So, the power level of the background can be estimated using reference cells adjacent to the cell under test (CUT) in space. Until now, many efforts and contributions have been devoted to the research and application of CFAR detection schemes. However, the non-homogeneous clutter in realistic environments hinders the effectiveness of these CFAR detectors [11,12,13].
- (3)
- The third kind of method models the clutter in space with a settled probabilistic distribution and estimates the clutter precisely [14,15]. Typically, a test statistic is deduced by assuming a known distribution form for the clutter beforehand. Then, the clutter covariance matrix (CCM), estimated based on the secondary data collected from the vicinity of the CUT, is employed in the test statistic for subsequent detection. Many relative methods have been proposed over the past years [16,17,18,19]. However, due to the sensitivity to the background clutter distribution, these methods suffer from target detection performance degradation in low-altitude backgrounds where the clutter is complex and uncontrollable.
- Inspired by the discovery that clutter remains stable between adjacent frames, we provide a novel DL-based RTD approach in which the signal variation in the range cell between adjacent frames is utilized to determine if a target is present.
- We adopt the supervised contrastive loss and the Siamese network architecture to encourage learning from hard negative samples to promote the detection of moving targets.
- We induce the meta-learning paradigm to equip our model with superior generalization ability to the new task.
- We design a novel detection strategy that can accomplish RTD tasks efficiently and assess the detection performance statistically under the CFAR condition.
2. Related Work
2.1. Meta-Learning
2.2. Contrastive Learning
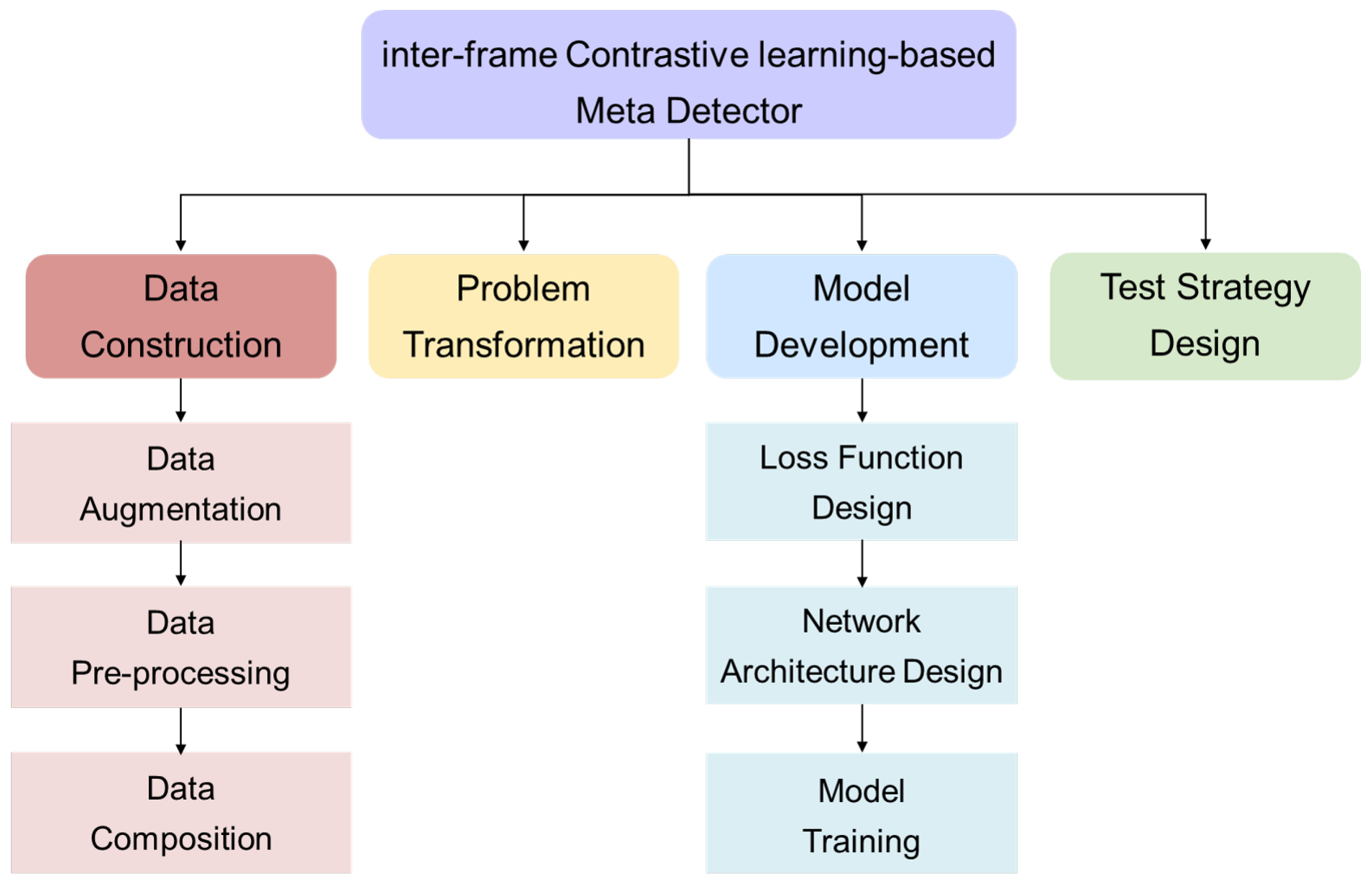
3. Proposed Method
3.1. Overview of the Proposed Method
3.2. Data Construction
3.2.1. Data Augmentation
3.2.2. Data Pre-Processing
3.2.3. Data Composition
3.3. Problem Transformation
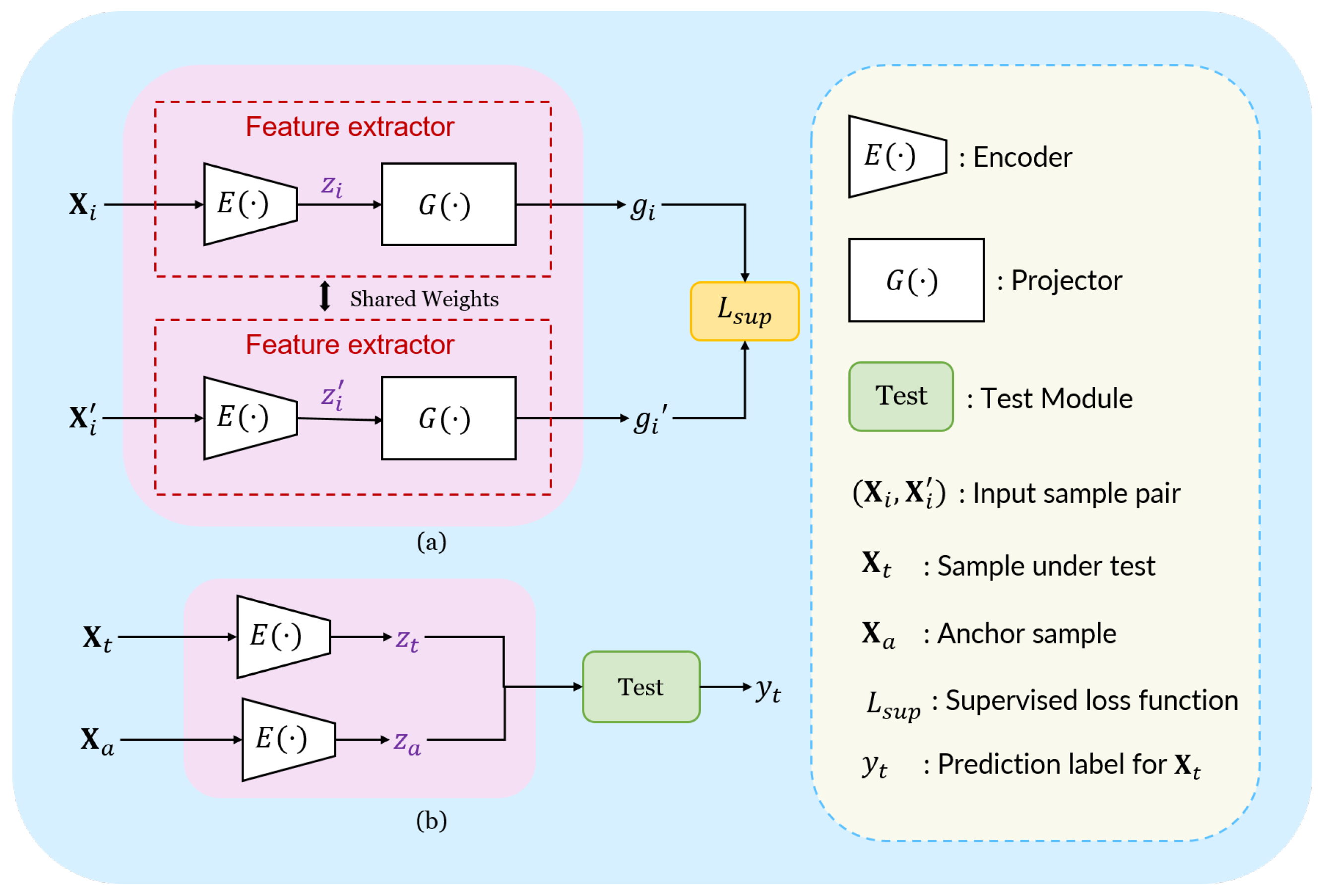
3.4. Model Development
3.4.1. Loss Function Design
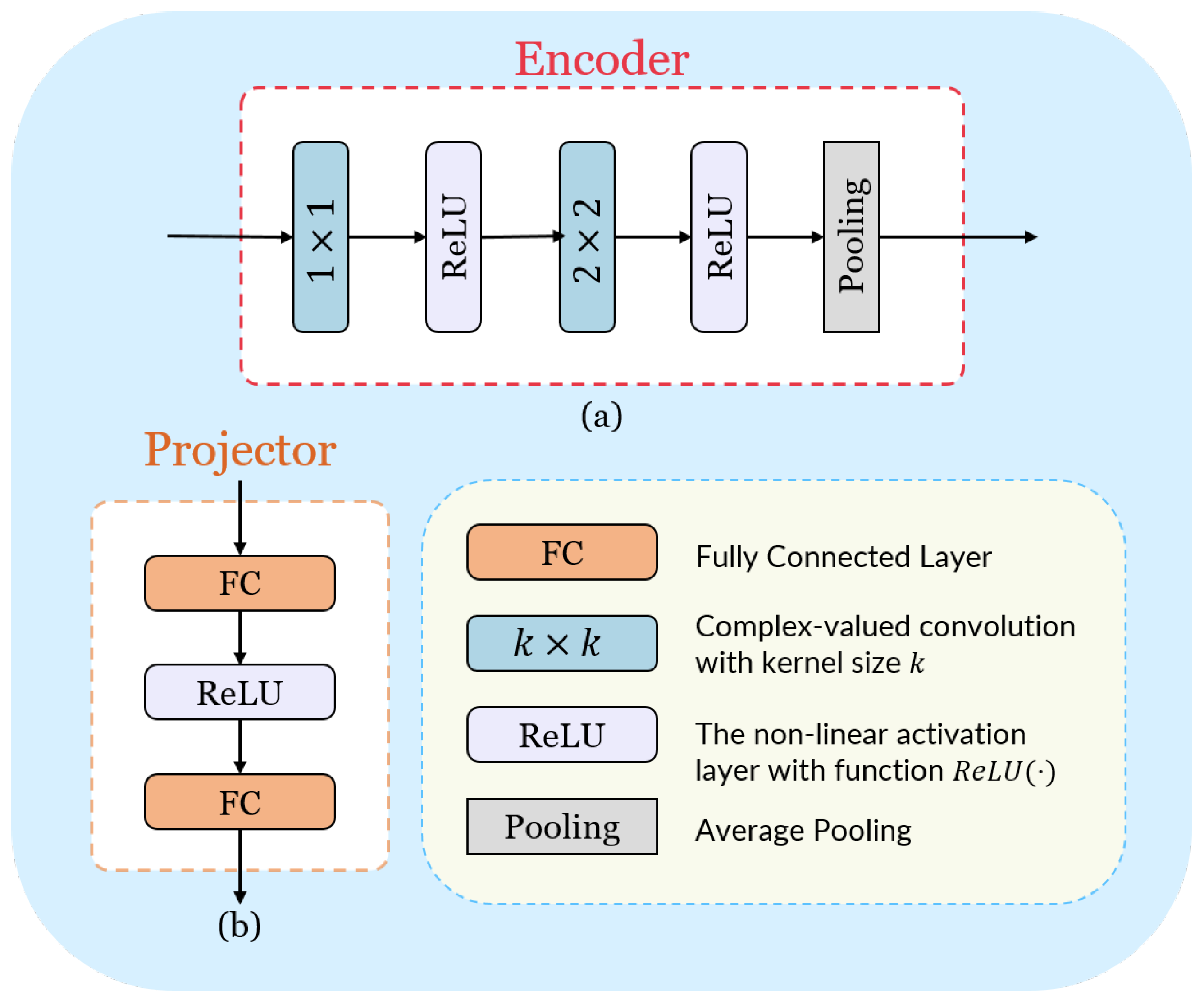
3.4.2. Network Architecture Design
3.4.3. Model Training
| Algorithm 1 Model Training Algorithm for IfCMD |
|
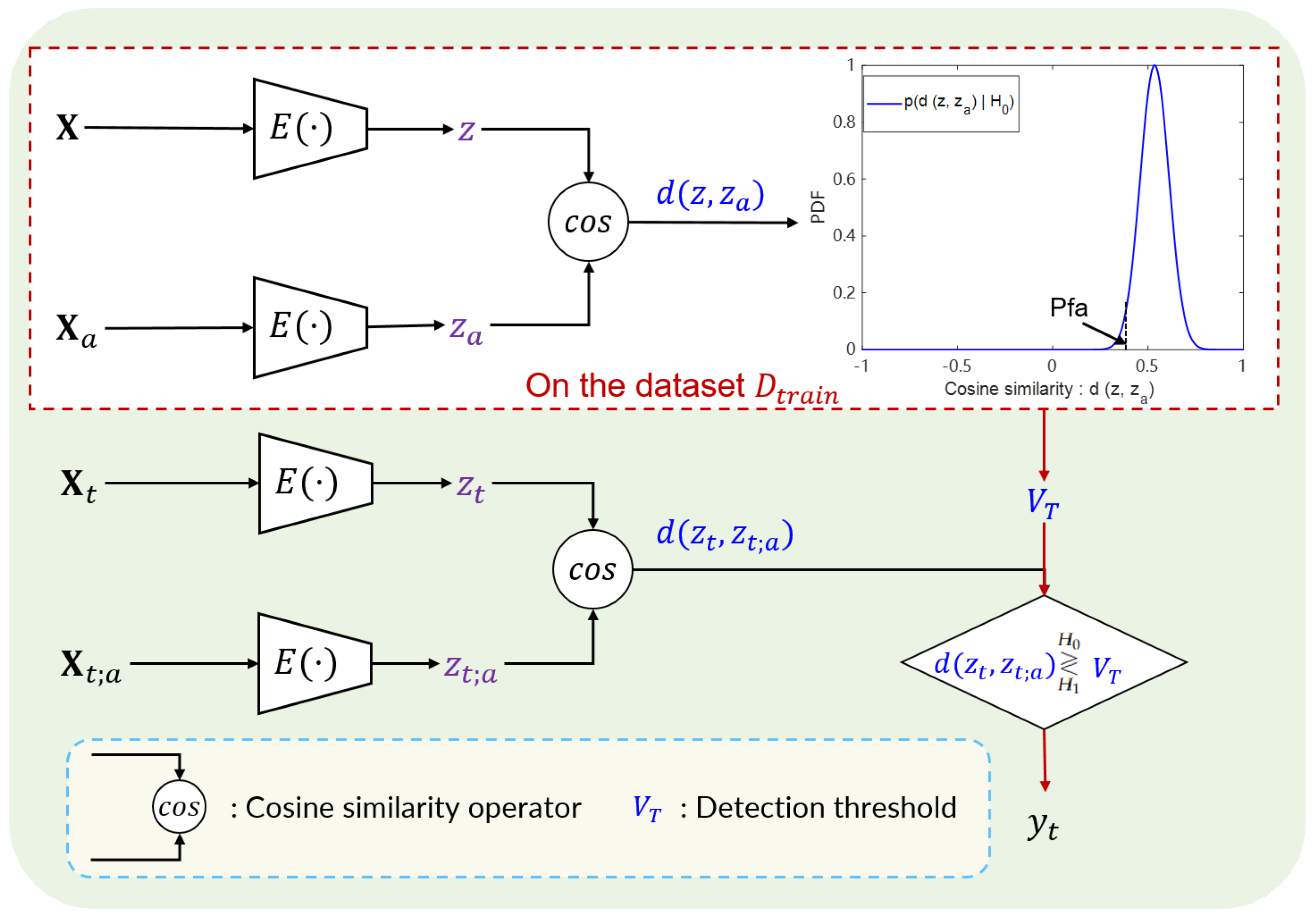
3.5. Test Strategy Design
4. Experimental Results
4.1. Experimental Settings
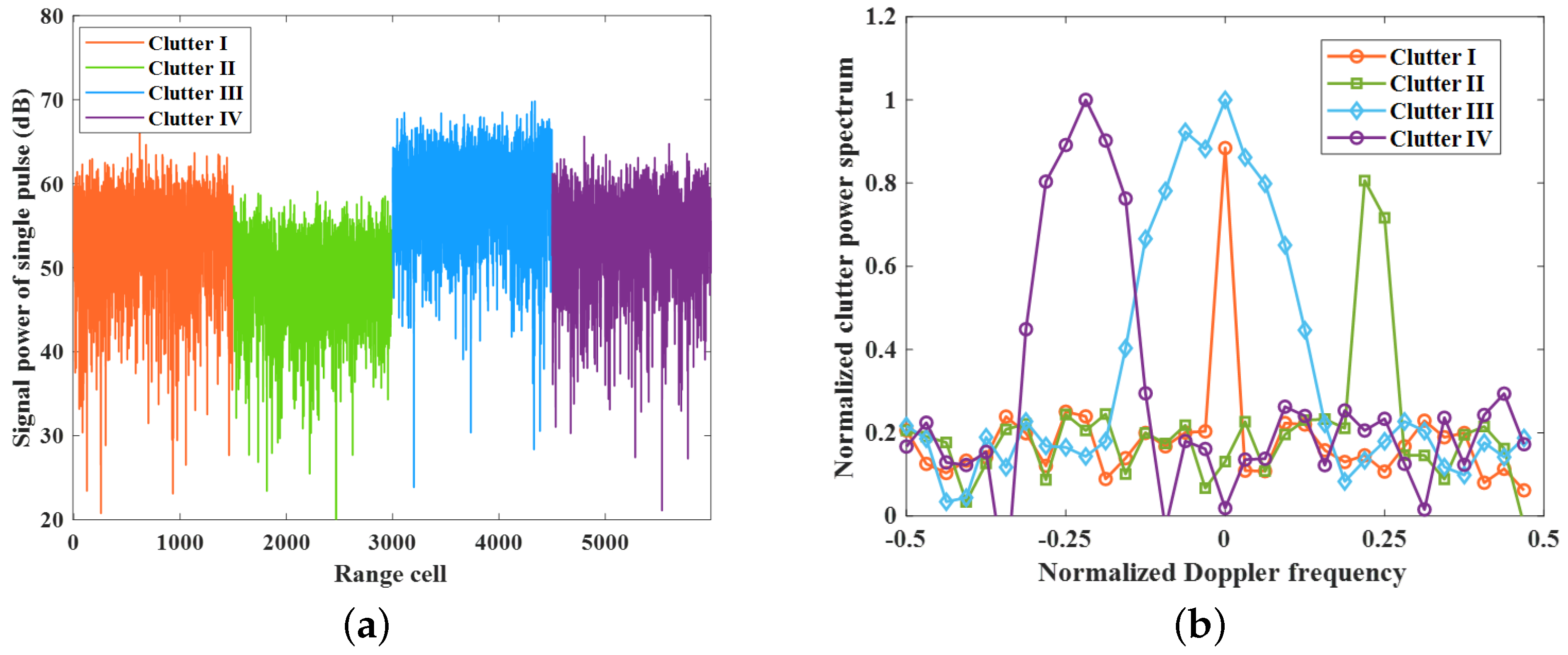
4.1.1. Dataset Description
- Since Clutter I is the static clutter background causing little performance loss in traditional RTD methods, the RTD tasks of all range cells in Clutter I are used to train the model.
- We randomly select 80% of the tasks from Clutter II and Clutter III for meta-training, while the remaining 20% are used for performance evaluation.
- To enhance the generalization ability of the trained model, we employ 9-fold cross-validation during training to tune the parameters.
- Finally, all tasks of Clutter IV are reserved for the generalization performance test.
4.1.2. Implementation Details
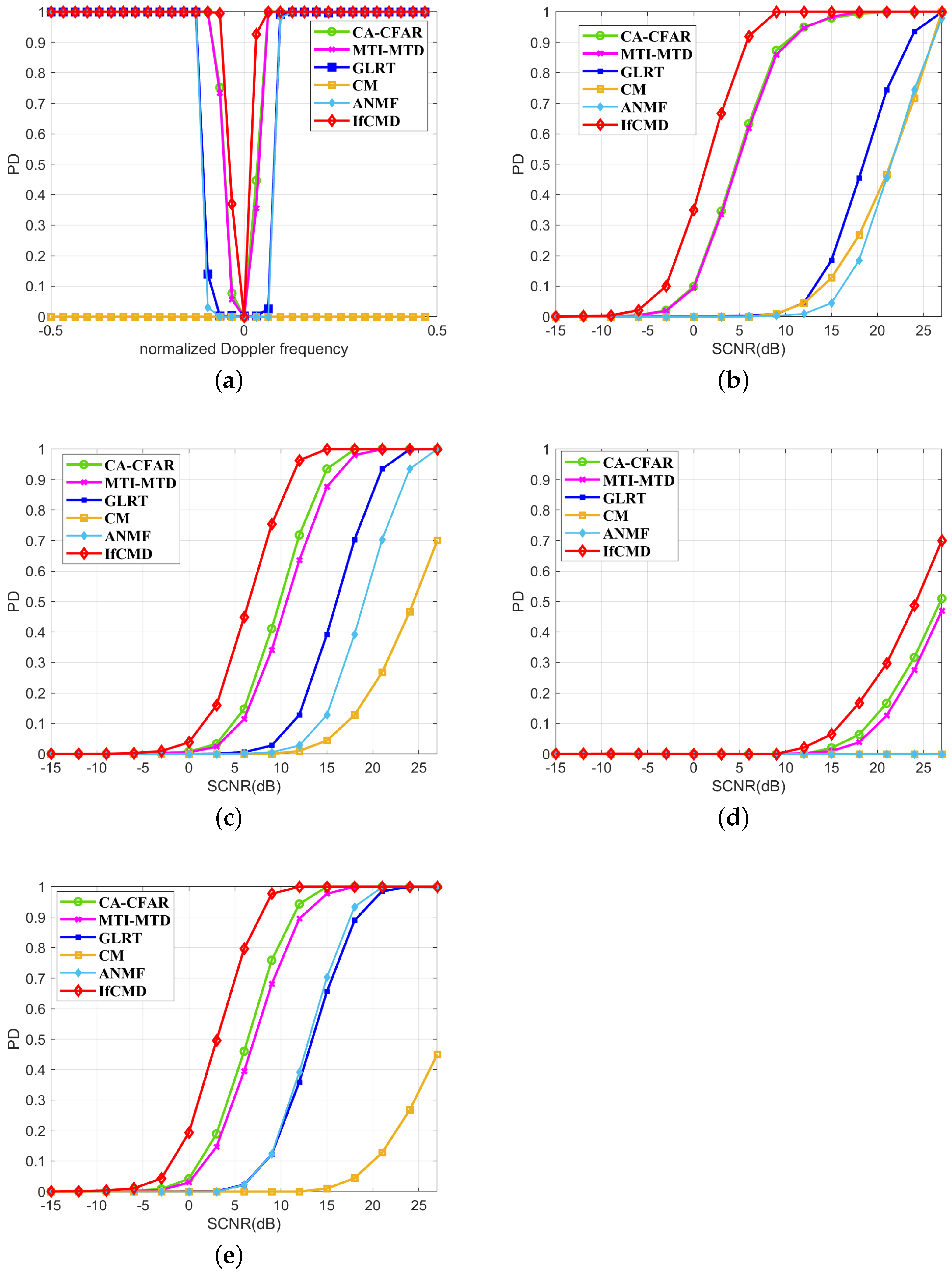
4.1.3. Compared Methods
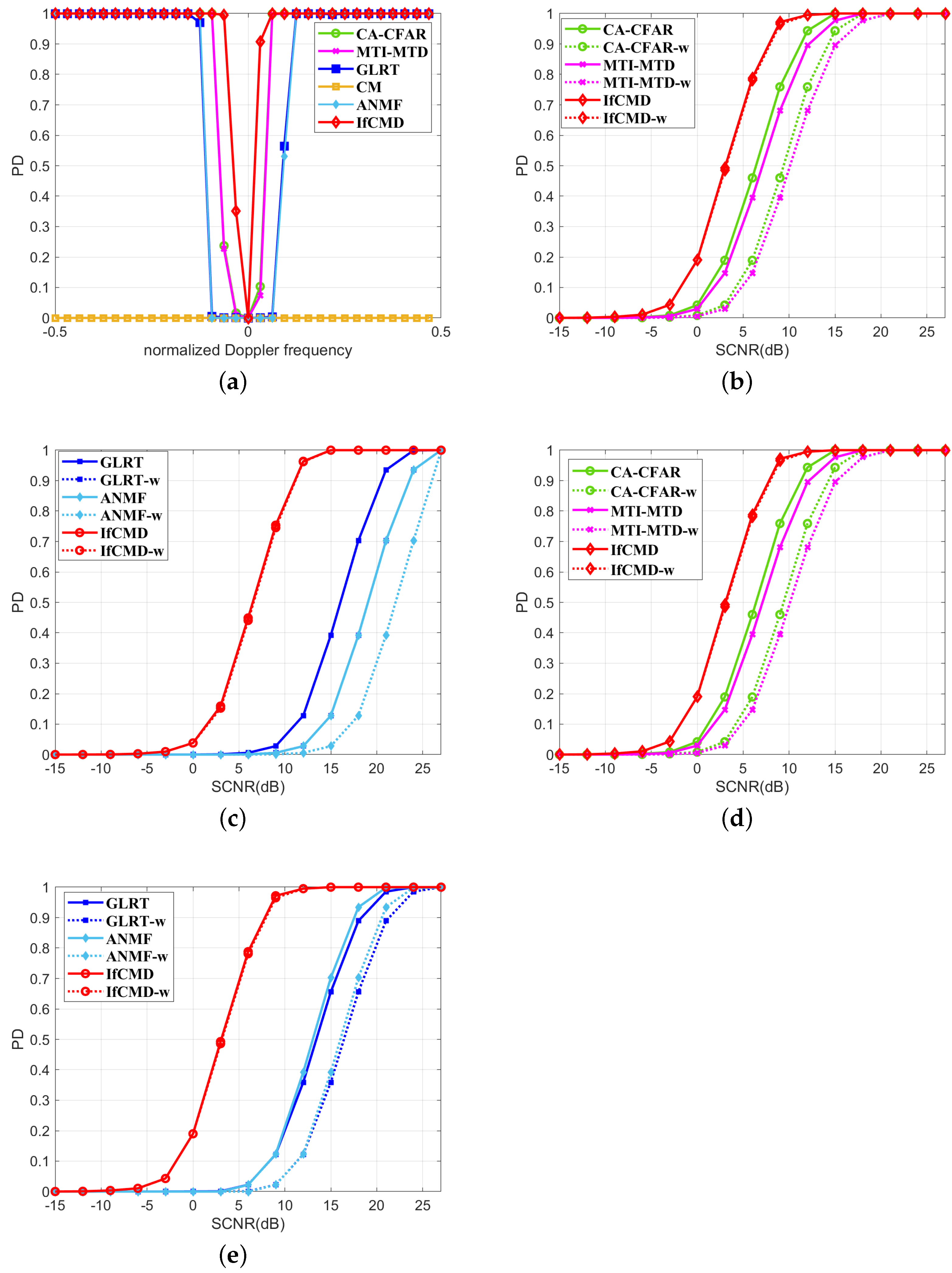
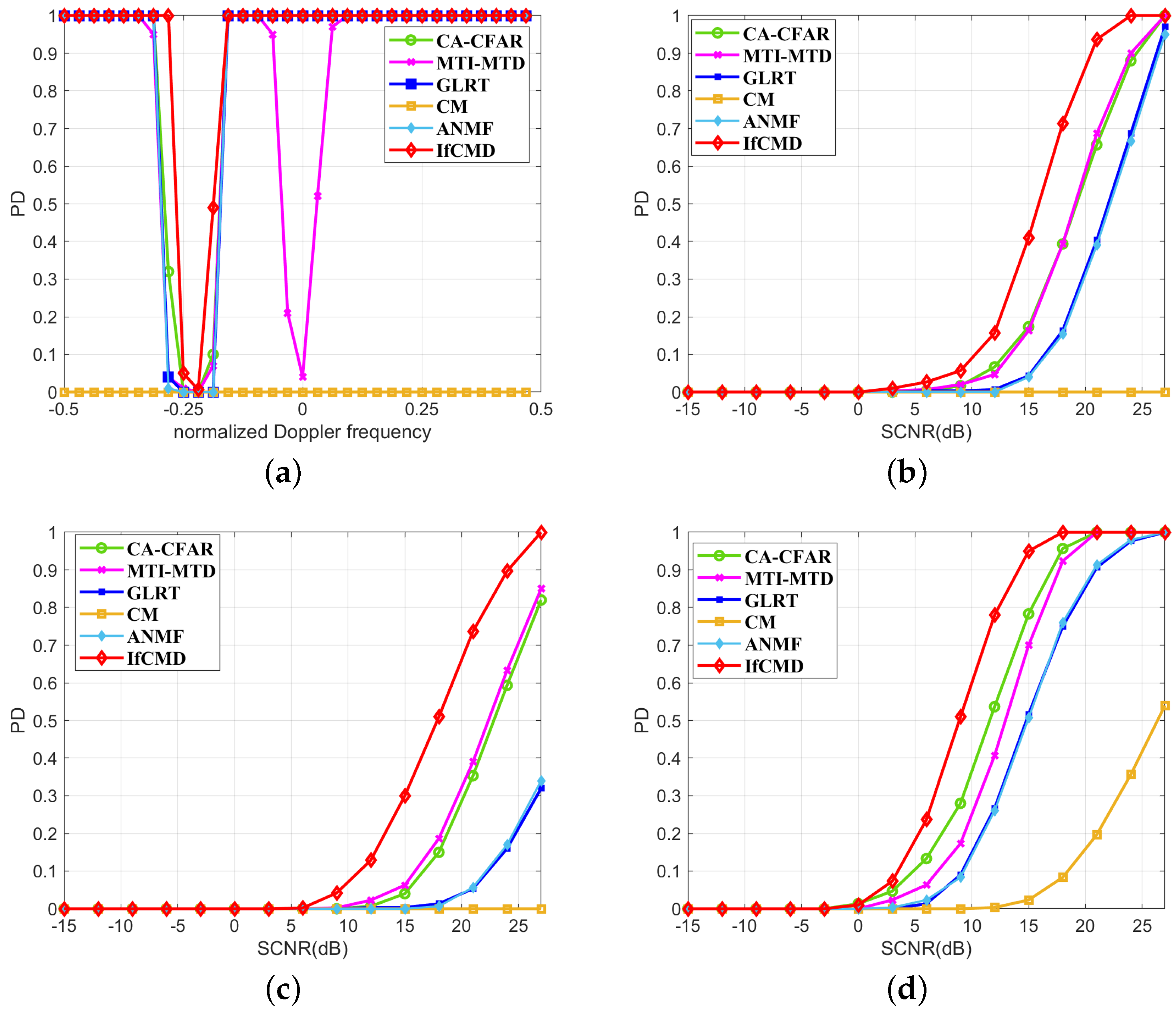
- CA-CFAR: a kind of CFAR detector that is widely explored in both theoretical analysis and realistic applications for RTD tasks.
- MTI-MTD: a conventional processing flow for target detection in clutter environments.
- GLRT: the representative of the likelihood ratio test (LRT) algorithm for RTD in a clutter background.
- CM: a popular non-coherent RTD method involving multi-frame data processing.
- ANMF: a novel adaptive filter for RTD in low-rank Gaussian clutter.
4.1.4. Evaluation Metrics
4.2. Detection Performance and Comparisons
4.2.1. Detection Performance for Targets under a Dynamic Clutter Background
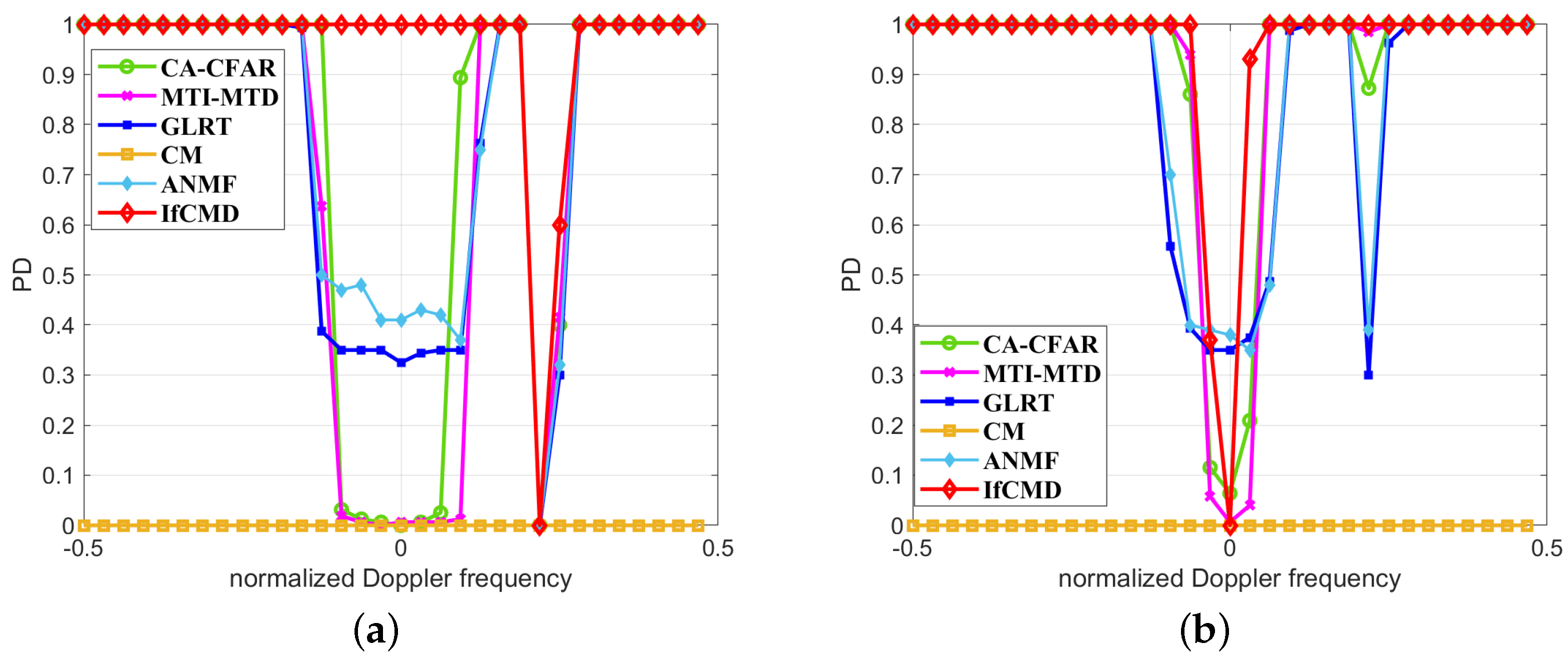
4.2.2. Detection Performance for Targets near the Clutter Edge
4.2.3. Detection Performance for Range-Spread Targets
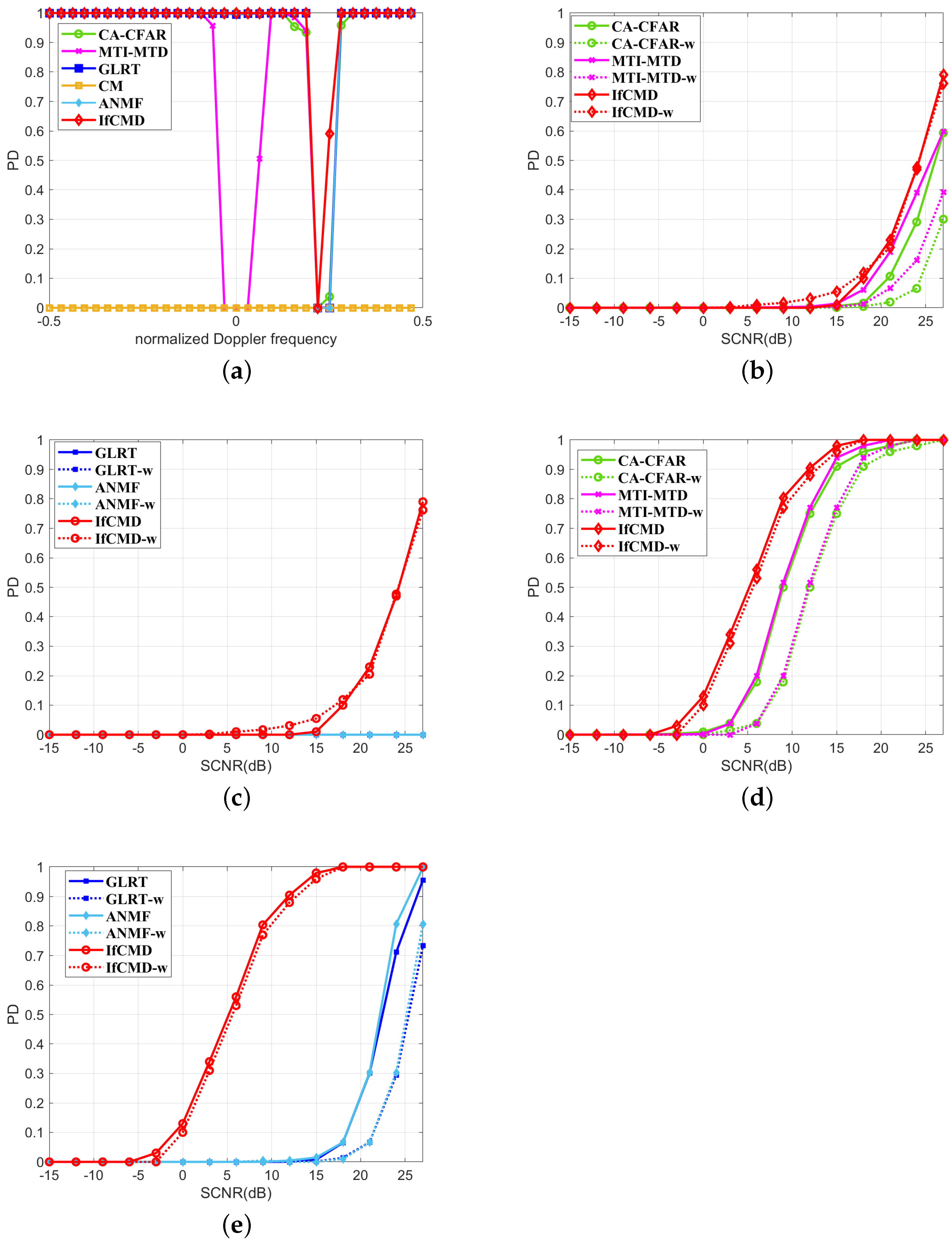
4.3. Generalization Performance Analysis
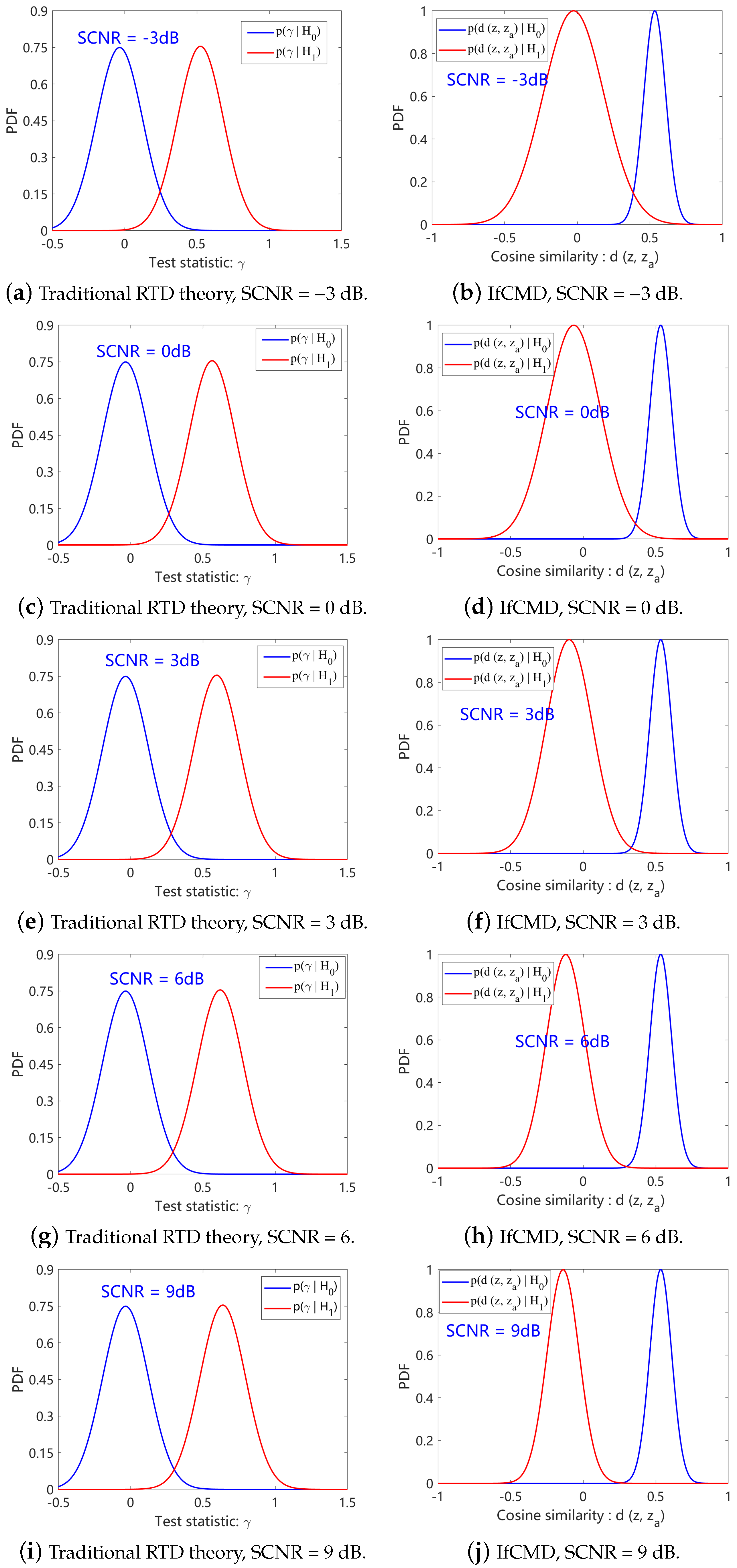
4.4. Qualitative Analysis
- Traditional RTD theory assumes that the difference between the statistical properties of target-present and target-absent signals is reflected in the mean rather than the variance. The mean difference between and amplifies as the SCNR increases.
- Different from traditional RTD theory, in the latent space of our optimized model, the differences between the statistical properties of target-present signals and target-absent signals are reflected in both the mean and the variance. As the SCNR increases, the differences of both the mean and the variance between and amplify.
4.5. Computational Analysis
5. Measured Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CL | Contrastive learning |
| CFAR | Constant false alarm rate |
| CUT | Cell under test |
| CCM | Clutter covariance matrix |
| CDI | Complete Doppler information |
| CI | Coherent integration |
| CA-CFAR | Cell-averaging CFAR |
| CPI | Coherent pulse interval |
| CNR | Clutter-to-noise ratio |
| DL | Deep learning |
| DDI | Differential Doppler information |
| DFT | Discrete Fourier transform |
| GLRT | Generalized likelihood ratio test |
| i.i.d. | Independent and identically distributed |
| IfCMD | Inter-Frame Contrastive Learning-Based Meta Detector |
| LRT | Likelihood ratio test |
| MTI | Moving-target indication |
| MTD | Moving-target detection |
| Probability density function | |
| Pfa | The probability of false alarm |
| PD | The probability of detection |
| RCS | Radar cross-section |
| RTD | Radar target detection |
| std | Standard derivation |
| SCNR | Signal-to-clutter plus noise ratio |
| SNR | Signal-to-noise ratio |
References
- Liu, W.; Liu, J.; Hao, C.; Gao, Y.; Wang, Y.L. Multichannel adaptive signal detection: Basic theory and literature review. Sci. China Inf. Sci. 2022, 65, 121301. [Google Scholar] [CrossRef]
- Sun, H.; Oh, B.S.; Guo, X.; Lin, Z. Improving the Doppler resolution of ground-based surveillance radar for drone detection. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 3667–3673. [Google Scholar] [CrossRef]
- Brennan, L.; Mallett, J.; Reed, I. Adaptive arrays in airborne MTI radar. IEEE Trans. Antennas Propag. 1976, 24, 607–615. [Google Scholar] [CrossRef]
- Ash, M.; Ritchie, M.; Chetty, K. On the application of digital moving target indication techniques to short-range FMCW radar data. IEEE Sens. J. 2018, 18, 4167–4175. [Google Scholar] [CrossRef]
- Matsunami, I.; Kajiwara, A. Clutter suppression scheme for vehicle radar. In Proceedings of the 2010 IEEE Radio and Wireless Symposium (RWS), New Orleans, LA, USA, 10–14 January 2010; pp. 320–323. [Google Scholar]
- Shrader, W.W.; Gregers-Hansen, V. MTI radar. In Radar Handbook; Citeseer: Princeton, NJ, USA, 1970; Volume 2, pp. 15–24. [Google Scholar]
- Navas, R.E.; Cuppens, F.; Cuppens, N.B.; Toutain, L.; Papadopoulos, G.Z. Mtd, where art thou? A systematic review of moving target defense techniques for iot. IEEE Internet Things J. 2020, 8, 7818–7832. [Google Scholar] [CrossRef]
- Jia, F.; Tan, J.; Lu, X.; Qian, J. Radar Timing Range–Doppler Spectral Target Detection Based on Attention ConvLSTM in Traffic Scenes. Remote Sens. 2023, 15, 4150. [Google Scholar] [CrossRef]
- Jalil, A.; Yousaf, H.; Baig, M.I. Analysis of CFAR techniques. In Proceedings of the 2016 13th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 12–16 January 2016; pp. 654–659. [Google Scholar]
- Rohling, H. Ordered statistic CFAR technique—An overview. In Proceedings of the 2011 12th International Radar Symposium (IRS), Leipzig, Germany, 7–9 September 2011; pp. 631–638. [Google Scholar]
- Ravid, R.; Levanon, N. Maximum-likelihood CFAR for Weibull background. IEE Proc. F Radar Signal Process. 1992, 139, 256–264. [Google Scholar] [CrossRef]
- Qin, T.; Wang, Z.; Huang, Y.; Xie, Z. Adaptive CFAR detector based on CA/GO/OS three-dimensional fusion. In Proceedings of the Fifteenth International Conference on Signal Processing Systems (ICSPS 2023), Xi’an, China, 17–19 November 2024; Volume 13091, pp. 302–310. [Google Scholar]
- Rihan, M.Y.; Nossair, Z.B.; Mubarak, R.I. An improved CFAR algorithm for multiple environmental conditions. Signal Image Video Process. 2024, 18, 3383–3393. [Google Scholar] [CrossRef]
- Chalise, B.K.; Wagner, K.T. Distributed GLRT-based detection of target in SIRP clutter and noise. In Proceedings of the 2021 IEEE Radar Conference (RadarConf21), Atlanta, GA, USA, 7–14 May 2021; pp. 1–6. [Google Scholar]
- Shuai, X.; Kong, L.; Yang, J. Performance analysis of GLRT-based adaptive detector for distributed targets in compound-Gaussian clutter. Signal Process. 2010, 90, 16–23. [Google Scholar] [CrossRef]
- Kelly, E.J. An adaptive detection algorithm. IEEE Trans. Aerosp. Electron. Syst. 1986, AES-22, 115–127. [Google Scholar] [CrossRef]
- Robey, F.C.; Fuhrmann, D.R.; Kelly, E.J.; Nitzberg, R. A CFAR adaptive matched filter detector. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 208–216. [Google Scholar] [CrossRef]
- Fan, Y.; Shi, X. Wald, QLR, and score tests when parameters are subject to linear inequality constraints. J. Econom. 2023, 235, 2005–2026. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, H.; Li, Y.; Wang, D. Rao and Wald Tests for Moving Target Detection in Forward Scatter Radar. Remote Sens. 2024, 16, 211. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Wang, W.; Peng, Y. Deep learning-based uav detection in the low altitude clutter background. arXiv 2022, arXiv:2202.12053. [Google Scholar]
- Sun, H.H.; Cheng, W.; Fan, Z. Clutter Removal in Ground-Penetrating Radar Images Using Deep Neural Networks. In Proceedings of the 2022 International Symposium on Antennas and Propagation (ISAP), Sydney, Australia, 31 October–3 November 2022; pp. 17–18. [Google Scholar]
- Si, L.; Li, G.; Zheng, C.; Xu, F. Self-supervised Representation Learning for the Object Detection of Marine Radar. In Proceedings of the 8th International Conference on Computing and Artificial Intelligence, Tianjin, China, 18–21 March 2022; pp. 751–760. [Google Scholar]
- Coiras, E.; Mignotte, P.Y.; Petillot, Y.; Bell, J.; Lebart, K. Supervised target detection and classification by training on augmented reality data. IET Radar Sonar Navig. 2007, 1, 83–90. [Google Scholar] [CrossRef]
- Jiang, W.; Ren, Y.; Liu, Y.; Leng, J. A method of radar target detection based on convolutional neural network. Neural Comput. Appl. 2021, 33, 9835–9847. [Google Scholar] [CrossRef]
- Yavuz, F. Radar target detection with CNN. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 1581–1585. [Google Scholar]
- Liang, X.; Chen, B.; Chen, W.; Wang, P.; Liu, H. Unsupervised radar target detection under complex clutter background based on mixture variational autoencoder. Remote Sens. 2022, 14, 4449. [Google Scholar] [CrossRef]
- Deng, H.; Clausi, D.A. Unsupervised segmentation of synthetic aperture radar sea ice imagery using a novel Markov random field model. IEEE Trans. Geosci. Remote Sens. 2005, 43, 528–538. [Google Scholar] [CrossRef]
- Le-Khac, P.H.; Healy, G.; Smeaton, A.F. Contrastive representation learning: A framework and review. IEEE Access 2020, 8, 193907–193934. [Google Scholar] [CrossRef]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning? Adv. Neural Inf. Process. Syst. 2020, 33, 6827–6839. [Google Scholar]
- Xiao, T.; Wang, X.; Efros, A.A.; Darrell, T. What should not be contrastive in contrastive learning. arXiv 2020, arXiv:2008.05659. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Melekhov, I.; Kannala, J.; Rahtu, E. Siamese network features for image matching. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 378–383. [Google Scholar]
- Chicco, D. Siamese neural networks: An overview. In Artificial Neural Networks; Humana: New York, NY, USA, 2021; pp. 73–94. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Huisman, M.; Van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Schmidhuber, J. Evolutionary Principles in Self-Referential Learning, or on Learning How to Learn: The Meta-Meta-…Hook. Ph.D. Thesis, Technische Universität München, München, Germany, 1987. [Google Scholar]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Gharoun, H.; Momenifar, F.; Chen, F.; Gandomi, A. Meta-learning approaches for few-shot learning: A survey of recent advances. ACM Comput. Surv. 2024. [Google Scholar] [CrossRef]
- Vettoruzzo, A.; Bouguelia, M.R.; Vanschoren, J.; Rognvaldsson, T.; Santosh, K. Advances and challenges in meta-learning: A technical review. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–20. [Google Scholar] [CrossRef]
- Dhillon, G.S.; Chaudhari, P.; Ravichandran, A.; Soatto, S. A baseline for few-shot image classification. arXiv 2019, arXiv:1909.02729. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1842–1850. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wu, J.; Chen, J.; Wu, J.; Shi, W.; Wang, X.; He, X. Understanding contrastive learning via distributionally robust optimization. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar]
- Chen, T.; Luo, C.; Li, L. Intriguing properties of contrastive losses. Adv. Neural Inf. Process. Syst. 2021, 34, 11834–11845. [Google Scholar]
- Awasthi, P.; Dikkala, N.; Kamath, P. Do more negative samples necessarily hurt in contrastive learning? In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 1101–1116. [Google Scholar]
- Wang, F.; Liu, H. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2495–2504. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9929–9939. [Google Scholar]
- Tian, Y. Understanding deep contrastive learning via coordinate-wise optimization. Adv. Neural Inf. Process. Syst. 2022, 35, 19511–19522. [Google Scholar]
- Gupta, K.; Ajanthan, T.; Hengel, A.v.d.; Gould, S. Understanding and improving the role of projection head in self-supervised learning. arXiv 2022, arXiv:2212.11491. [Google Scholar]
- Xue, Y.; Gan, E.; Ni, J.; Joshi, S.; Mirzasoleiman, B. Investigating the Benefits of Projection Head for Representation Learning. arXiv 2024, arXiv:2403.11391. [Google Scholar]
- Ma, J.; Hu, T.; Wang, W. Deciphering the projection head: Representation evaluation self-supervised learning. arXiv 2023, arXiv:2301.12189. [Google Scholar]
- Wen, Z.; Li, Y. The mechanism of prediction head in non-contrastive self-supervised learning. Adv. Neural Inf. Process. Syst. 2022, 35, 24794–24809. [Google Scholar]
- Gui, Y.; Ma, C.; Zhong, Y. Unraveling Projection Heads in Contrastive Learning: Insights from Expansion and Shrinkage. arXiv 2023, arXiv:2306.03335. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Antoniou, A.; Edwards, H.; Storkey, A. How to train your MAML. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Nitzberg, R. Clutter map CFAR analysis. IEEE Trans. Aerosp. Electron. Syst. 1986, AES-22, 419–421. [Google Scholar] [CrossRef]
- Kammoun, A.; Couillet, R.; Pascal, F.; Alouini, M.S. Optimal design of the adaptive normalized matched filter detector. arXiv 2015, arXiv:1501.06027. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Bandwidth (MHz) | 2.5 |
| Pulse repetition frequency (Hz) | 400 |
| Wavelength (m) | 0.25 |
| Pulse number in a CPI | 32 |
| Azimuth beamwidth (∘) | 2 |
| CNR | Velocity | Std of Velocity | Normalized Doppler Frequency | |
|---|---|---|---|---|
| Clutter I | 55 dB | 0 | 0.0017 m/s | 0 |
| Clutter II | 50 dB | 11.11 m/s | 0.32 m/s | 0.22 |
| Clutter III | 60 dB | 0 | 1.5 m/s | 0 |
| Clutter IV | 54 dB | —10.5 m/s | 1 m/s | —0.22 |
| Hyper-Parameter | Value |
|---|---|
| Number of DFT points | 32 |
| N | 33 |
| K | 25 |
| 0.01 | |
| 1 × 10−4 | |
| the temperature scalar | 0.1 |
| the number of episodes in a batch | 10 |
| the number of sample pairs in an episode | 512 |
| IfCMD | CA-CFAR | MTI-MTD | GLRT | ANMF | CM | |
|---|---|---|---|---|---|---|
| Time (s) | 1.25 × 10−5 | 6.5 × 10−3 | 0.174 | 1.28 | 3 | 5 × 10−3 |
| Parameter | Value |
|---|---|
| Wave band | X |
| Pulse repetition frequency (Hz) | 6000 |
| Pulse number in a CPI | 32 |
| Number of range cells | 2400 |
| Bandwidth (MHz) | 20 |
| IfCMD | CA-CFAR | MTI-MTD | GLRT | ANMF | CM | |
|---|---|---|---|---|---|---|
| PD | 0.80 | 0.60 | 0.46 | 0.17 | 0.17 | 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Xu, Y.; Chen, W.; Chen, B.; Gao, C.; Liu, H. IfCMD: A Novel Method for Radar Target Detection under Complex Clutter Backgrounds. Remote Sens. 2024, 16, 2199. https://doi.org/10.3390/rs16122199
Zhang C, Xu Y, Chen W, Chen B, Gao C, Liu H. IfCMD: A Novel Method for Radar Target Detection under Complex Clutter Backgrounds. Remote Sensing. 2024; 16(12):2199. https://doi.org/10.3390/rs16122199
Chicago/Turabian StyleZhang, Chenxi, Yishi Xu, Wenchao Chen, Bo Chen, Chang Gao, and Hongwei Liu. 2024. "IfCMD: A Novel Method for Radar Target Detection under Complex Clutter Backgrounds" Remote Sensing 16, no. 12: 2199. https://doi.org/10.3390/rs16122199
APA StyleZhang, C., Xu, Y., Chen, W., Chen, B., Gao, C., & Liu, H. (2024). IfCMD: A Novel Method for Radar Target Detection under Complex Clutter Backgrounds. Remote Sensing, 16(12), 2199. https://doi.org/10.3390/rs16122199