1. Introduction
Remote sensing (RS) is a powerful technology that plays an essential role in monitoring and understanding our planet’s surface, oceans, and atmosphere. This represents a method that deals with gathering information about the Earth’s properties, processes, and changes over time through the collection of data from different distances, usually using satellites or aircraft. The fact that RS can overcome the limitations imposed by traditional data collection methods is a motivating factor for its use [
1]. One of the key motivations for using RS is the ability to access remote or inaccessible areas. This would include areas from which there may be difficulty or risk in gathering data, i.e., forests, polar regions, and areas hit by natural disasters [
2]. Through remote sensing, researchers and scientists are able to obtain valuable information about these areas, which will allow them to gain a better understanding of their characteristics and dynamics.
RS is utilized in a diverse array of disciplines, encompassing numerous areas of study. For instance, it is employed in environmental monitoring, where it plays a crucial role in evaluating climate change patterns, mapping alterations in land cover, monitoring deforestation, and assessing the overall health of ecosystems. In addition, it plays a pivotal role in resource management by overseeing the utilization of water resources, monitoring agricultural output, and evaluating soil conditions. RS is also widely utilized in disaster management by facilitating the prompt evaluation of impacted regions, tracking the progression of wildfires, and assisting in post-disaster recovery endeavors. It is heavily used in the fields of urban planning, transportation, and infrastructure development. Furthermore, it facilitates archaeological surveys, enables the exploration of natural resources, and aids in climate modeling [
3,
4,
5].
RS scene classification entails the classification of satellite or aerial images into distinct land-cover or land-use categories with the objective of deriving valuable insights about the Earth’s surface. The accurate realization of this task permits the use of various applications such as land-cover mapping, urban planning, environmental monitoring, and natural resource management. Scene classification offers valuable information regarding the spatial distribution and temporal changes in various land-cover categories, such as forests, agricultural fields, water bodies, urban areas, and natural landscapes. This information is vital for decision-making processes concerning land management, disaster response, and sustainable development. Moreover, the application of scene classification in RS plays an important role in conducting change-detection analysis. This allows for the identification and monitoring of temporal variations in land cover over a period of time via the utilization of advanced image analysis techniques to obtain valuable land-cover data to be applied for various purposes including the enhancement of land management practices and the facilitation of well-informed decision making [
6].
The impetus for federated learning (FL), which places significant emphasis on safeguarding data privacy, stems from the difficulty of readily sharing data between different entities. Distributed data across multiple devices and organizations pose challenges in terms of their efficient centralization and their proper utilization for machine learning models in various domains. Data privacy concerns and legal restrictions frequently impede the sharing of these data. FL offers a solution by enabling collaborative model training while ensuring that the data remain in their original location without being transferred elsewhere. FL ensures privacy and confidentiality by maintaining decentralized and local data. This approach aims to utilize the collective knowledge stored in distributed data sources, while also ensuring that the privacy rights of data owners are respected. Hence, the provision of FL would ensure that these data owners are complying with different types of regulations. FL facilitates a framework that prioritizes privacy and security, allowing organizations to collaborate and gain insights from each other’s data while ensuring that data privacy remains intact. FL currently offers a range of solutions, which include horizontal and vertical federated learning [
7,
8].
In this regard, horizontal FL is specifically designed for situations in which multiple devices or entities share similar characteristics but have distinct sets of data samples. In this methodology, the models are trained individually on each device using their respective datasets, and subsequently, the model updates are combined to generate a global model. This approach guarantees that the data remain stored on the individual devices, thus addressing concerns related to privacy. At the same time, it enables collaboration and the sharing of knowledge among the devices [
7].
On the other hand, vertical FL is well suited for scenarios in which multiple entities possess complementary information regarding the same features. Vertical FL involves the horizontal partitioning of data, where each entity has ownership of a specific subset of features. By jointly training models using their own datasets, the entities can acquire knowledge from the combined data without directly sharing their individual data. FL encompasses other variations such as federated transfer learning, which involves refining pre-trained models using federated methods, and federated reinforcement learning, which expands the concept to reinforcement learning scenarios. In general, the current solutions in FL consist of various methods designed for different situations where data are distributed. These methods allow for the collaborative training of models while also ensuring the privacy and security of the data. The techniques are constantly evolving to meet the requirements of various applications and tackle the difficulties related to decentralized and privacy-preserving machine learning [
8].
It is worth recalling that FL is applicable in diverse domains. FL has a notable application in healthcare, specifically in facilitating collaboration among various healthcare providers. This collaboration allows for the training of models using patient data that are distributed across different sources, all while ensuring the preservation of privacy [
9]. FL is utilized in various industries, including energy, to optimize smart grids, and in personalized recommendation systems to enhance user experiences [
10]. Additionally, FL is highly beneficial in the financial services industry for the purposes of fraud detection and risk assessment. It enables institutions to exchange valuable insights without jeopardizing the confidentiality of sensitive customer data. In the domain of autonomous vehicles [
11], FL can be employed to train models using data collected from numerous vehicles, thereby enhancing safety and performance. Furthermore, FL can be implemented in various other domains such as natural language processing (NLP), agriculture, intelligent homes, and scene classification in RS imagery. The flexibility of FL renders it a potent method for collaborative machine learning, all the while guaranteeing the confidentiality and protection of data.
As far as we know, there are no previous studies that specifically utilize FL in the field of RS. By utilizing FL techniques, it is feasible to exploit the combined expertise from dispersed data sources in recommender systems while guaranteeing the confidentiality and protection of the data. Additional research in this domain can enhance the progress of remote sensing by facilitating cooperative machine learning methods that exploit the potential of decentralized data without jeopardizing confidential information.
Overall, the work described herein makes the following two main research contributions:
Evaluation of using the FL technique in the classification of RS scenes from three different datasets: Optimal-31, UCMerced, and NWPU in conjunction with four deep learning (DL) models. Two of these models, EfficientNet-B1 and EfficientNet-B3, belong to the CNN family while the remaining two, ViT-Tiny and ViT-Base, are part of Vision Transformers. To the best of our knowledge, this may be the first time that FL is being utilized in the context of a RS application.
Analysis of classification results yielded by the highest performing model (ViT-Base) by considering multiple scenarios of dropped clients. In particular, we focused our examination on assessing the performance of two cases of FL: one with 10 clients and the other with 40 clients. By varying the number of dropped clients, we were able to affirm the observation that selectively dropping clients during training enhances the robustness and performance of the model in FL scenarios.
The rest of the paper is organized as follows:
Section 2 gives a short review of some recent works related to scene classification in RS that employ the centralized learning paradigm. Then,
Section 3 describes our methodology used in undertaking this research by applying FL in the context of RS scene classification. This is followed by
Section 4, where our experimental results are presented and analyzed. Finally, before concluding the paper and outlining our future work, we further discuss our results by considering multiple FL scenarios, where the number of dropped clients is varied, for the highest-performing model among the four considered networks.
2. Related Work
We review in this section some of the recent research works dealing with RS scene classification using centralized methods. In this context, Cheng et al. introduced in [
12] a technique for classifying RS scenes using convolutional features. This method extracts depth features and generates visual words. Wang et al. presented the concept of attention by proposing the Attention Recurrent Convolutional Network [
13]. The method employs adaptive attention region selection and sequential processing to generate highly accurate predictions. Additionally, the authors develop a recurrent attention framework to compress high-level semantic and spatial characteristics into a few simplex vectors, thereby reducing the number of parameters required for learning. Lu et al. in [
14] showed that feature learning and aggregation can improve network performance.
Bazi et al. propose a simple yet effective method for fine-tuning deep convolutional neural networks (CNNs) [
15]. This method uses an auxiliary classification loss function to inject gradients into an earlier layer of the network, helping to mitigate the problem of vanishing gradients and improving classification accuracy. The authors demonstrate that their method is efficient in several benchmark datasets. Ji et al. introduce a technique that utilizes the attention mechanism to identify and combine features from multiscale discriminative regions [
16]. Guo et al. in [
17] disclose a method called Saliency Dual Attention Residual Network to effectively capture both cross-channel and spatial saliency information. Spatial attention is incorporated into low-level features to highlight the location of important information and reduce the influence of irrelevant background information. Channel attention, on the other hand, is applied to high-level features to extract significant information.
Alswayed et al. introduce a deep attention model that utilizes the pre-trained SqueezeNet CNN [
18]. A distinct branch is added to the network, which incorporates an attention mechanism and acquires optimal weights for the features learned in the primary branch. The authors in [
19] suggest a CNN with an attention mechanism and multiple augmentation schemes to enhance the problem of scene classification. The augmentation operation applied to attention mechanism feature maps serves to compel the model to capture features specific to each class and remove unnecessary information. It also encourages the model to focus on discriminative regions as much as possible, rather than relying solely on global information without any preference.
The study described in [
20] introduces an attention-based approach. This method effectively distinguishes the important information from the intricate content of the scene. The approach relies on the DenseNet CNN model as its foundation and is referred to as channel-attention-based DenseNet. DenseNet is capable of extracting spatial features at various scales and establishing correlations between them. A channel attention mechanism is implemented to enhance the weights of significant feature channels and suppress the less important ones.
The authors of the research presented in [
21] suggest a dual attention-aware network. They employ two types of attention modules, namely, channel attention and spatial attention. The attention-aware feature representation, which is crucial for enhancing classification performance, is obtained by combining the outputs of two attention modules. The classification network consists of three subnetworks. Each subnetwork is trained using specific scaled regions. The feature outputs of these subnetworks are then combined before the final classification. Xue et al. introduced a technique that utilizes three deep networks to independently extract deep features from the RS image [
22]. The features were combined to form a unified feature vector for classification. Further, AlHichri et al. described an improved CNN structure called EfficientNet-B3-Attn, specifically designed for scene classification in RS [
23]. This model incorporates an attention mechanism into the pre-trained EfficientNet-B3 CNN, effectively tackling the difficulties related to large datasets and varied scene types.
A method based on Vision Transformers has been proposed by Bazi et al. in [
24]. The Transformer model, unlike CNNs, is capable of detecting long-range correlations between patches using an attention module. The proposed method has been assessed using four publicly available remote sensing image datasets, and the test results showed that these new types of networks will improve classification accuracies better than state-of-the-art methods. More recently, Zhao et al. [
25] proposed a novel approach using aerial and ground-based dual-view images. They use Dempster–Shafer theory to combine information from both views, overcoming single-view limitations and improving reliability. Chen et al. [
26] propose a new model, called BiShuffleNeXt. The model is a lightweight bi-path network combining spatial and spectral paths for improved feature representation. It balances model complexity and classification accuracy, making it suitable for resource-constrained applications. The work in [
27] reviews deep learning techniques in RS scene classification and analyzes various architectures and methodologies. It discusses strengths and weaknesses, data augmentation, transfer learning, and fusion strategies. The paper also addresses related challenges like data scarcity and class imbalance and suggests potential solutions and future research directions.
3. Materials and Methods
In the context of centralized learning, the dataset comprises N pairs denoted as (
), where
represents an image and
represents its related label. The index
varies from 1 to
, representing the overall number of images in the dataset. The training process entails optimizing the network parameters by utilizing a loss function, specifically the multiclass entropy loss
, which is formulated as below:
which is a measure of the difference between the predicted distribution (
p) and the true distribution of the classes (
y), with
representing the number of classes in the dataset.
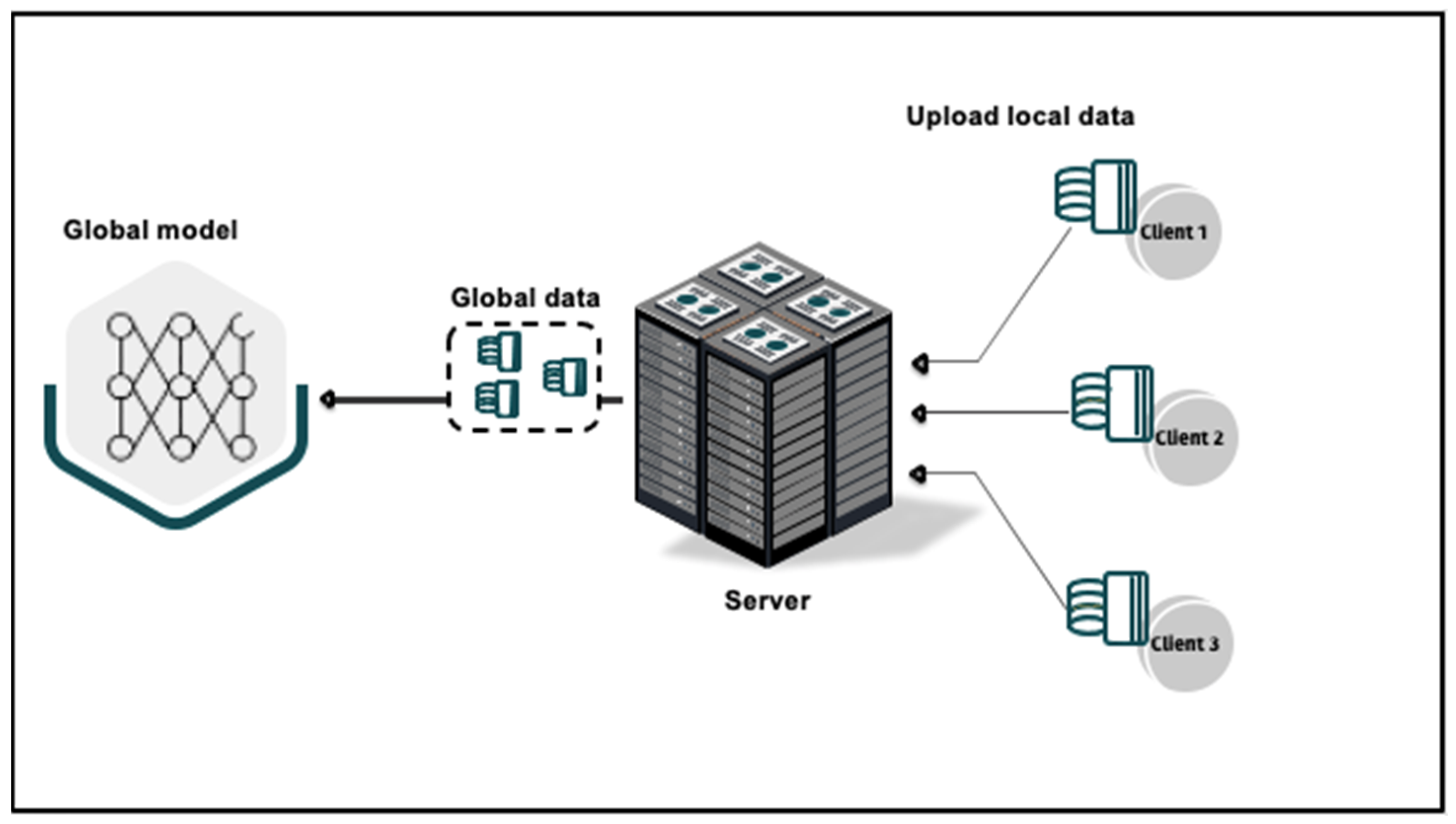
Centralized machine learning involves the connection of different clients to a central server as shown in
Figure 1, where they can upload their data. From one perspective, centralized training offers computational efficiency for participants by relieving them of computational duties that typically demand significant resources. However, the privacy of users’ data is significantly compromised because of the potential for harmful activities or unauthorized access by adversaries on the server. In the context of data uploading, it is important to note that a substantial volume of data can result in increased communication overhead between participants and the server [
28].
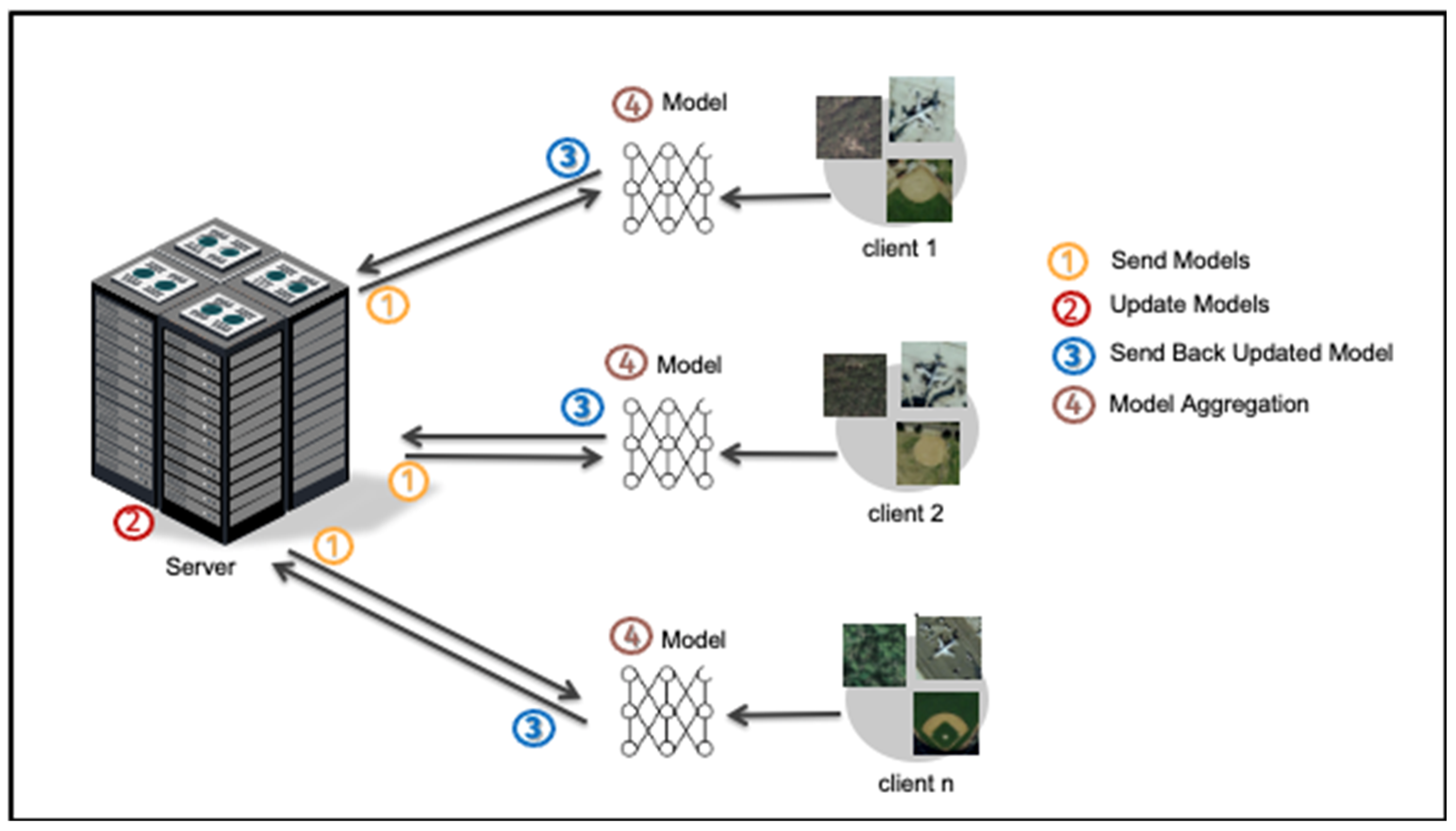
In order to tackle the issue of data privacy manifest in centralized machine learning, FL becomes a viable option. Here, a decentralized approach, in which the training procedure occurs on separate devices or clients, is employed. We will denote these clients as Client 1, Client 2, etc., as shown in
Figure 2. Rather than transmitting unprocessed data to a central server, the models undergo local training on each client, utilizing their particular datasets. The models’ updates are then transmitted in a safe manner to a central server, where they are consolidated to generate a comprehensive global model. Subsequently, the global model is transmitted to the clients, enabling them to make updates to their respective local models. The utilization of FL effectively addresses problems related to data privacy and security, as it ensures that raw data remain on the client’s side, and is not sent to a central server. The decentralized approach employed in this context also serves to decrease communication latency, as it solely transmits model updates. Therefore, FL offers notable advantages in situations where data are of a sensitive nature or dispersed across various locations. Another advantage is observed when there are constraints on connection capacity.
In FL, the global model is updated using the following global loss function
:
This is the result of the federated averaging process across multiple (= m) clients, is equal to the weight assigned to the contribution of the client i’s local model update. The term signifies the number of samples in the local dataset of client while represents the whole number of samples across all clients, and refers to the local loss function for client . The suggested approach entails the initialization of global parameters, the distribution of the model to clients for local training, the aggregation of local updates, and the collaborative iteration. This enables collaborative learning in a decentralized manner, allowing for modification to address privacy concerns or communication limitations in the federated learning environment.
In this work, we plan to implement and contrast two different architectures, one based on CNNs and the other based on Vision Transformers. For the CNN-based architecture, we will utilize two models, namely, EfficientNet-B1 and EfficientNet-B3. Likewise, for the Vision Transformer architecture, we will include two models, namely, ViT-Tiny and ViT-Base. These four models will be applied in the task of RS scene classification in both the centralized and FL paradigms of machine learning across three well-known datasets. We present below a brief synopsis of these DL models.
It is worth recalling that EfficientNet is a model developed by Google [
15] that aims to scale up CNNs. It employs a straightforward and highly efficient compound coefficient. The EfficientNet algorithm operates in a distinct manner compared to conventional techniques that adjust the dimensions of networks, including width, depth, and resolution. It achieves this by uniformly scaling each dimension using a predetermined set of scaling coefficients. In practical terms, the enhancement of model performance can be achieved by scaling individual dimensions. However, achieving a balanced distribution of all dimensions within the network, taking into account the available resources, leads to an overall improvement in performance. The effectiveness of model scaling is heavily influenced by the quality of the baseline network. In order to achieve this objective, a novel baseline network is established by employing the AutoML framework, which enhances both accuracy and efficiency. EfficientNet, similar to MobileNetV2 and MnasNet, uses mobile inverted bottleneck convolution (MBConv) as its primary component. Furthermore, the activation function employed by this network is called Swish, which replaces the Rectifier Linear Unit (ReLU) activation function.
Figure 3 shows the structure of the EfficientNet-B0 model, used as a baseline.
On the other side, Transformers have recently gained popularity in various domains due to their ability to capture long-range dependencies and effectively process sequential data. We incorporated these Transformer models to explore their potential in image classification tasks and compare them with the CNN-based approach. The Vision Transformer design is derived from the vanilla Transformer architecture [
24], which has garnered significant attention in recent years due to its exceptional performance in machine translation and other natural language processing (NLP) tasks. The Transformer model follows an encoder–decoder architecture, enabling concurrent processing of sequential input without the need for a recurrent network. The efficacy of Transformer models has been significantly enhanced by the incorporation of the self-attention mechanism, which is suggested as a means to capture extensive connections among the elements within a sequence.
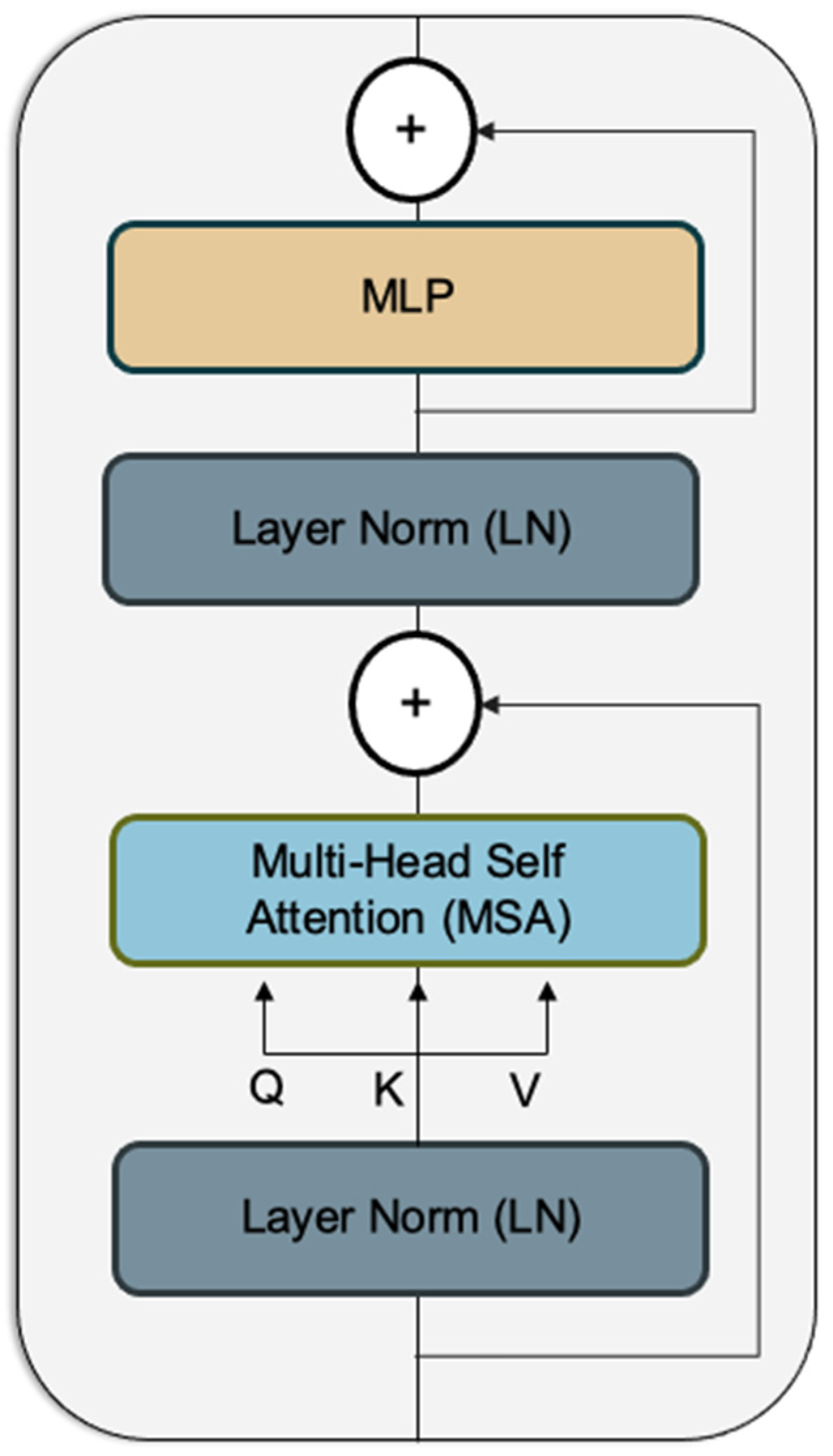
The suggested Vision Transformer aims to expand the application of the conventional Transformer model to the domain of picture categorization. The primary objective is to extend their applicability to modalities beyond text, while avoiding the incorporation of any data-specific design. The Vision Transformer model employs the encoder module of the Transformer architecture, as seen in
Figure 4 below, to carry out classification tasks by associating a series of patches with their corresponding semantic labels. The Vision Transformer employs an attention mechanism that enables it to attend to diverse regions of the image and integrate information throughout the full image, unlike standard CNN architectures that often use filters with a limited receptive field.
The Vision Transformer-based architecture was implemented using two models: ViT-Tiny and ViT-Base. The ViT-Base model has 86 million parameters, with a last feature representation dimension of 768. The ViT-Tiny model, on the other hand, utilized a Transformer variant with 5.7 million parameters. The last feature representation has a dimension of 192. For the EfficientNet-B1 model, we employed a model with 7.8 million parameters with its last feature representation having a dimension of 1280. On the other hand, the utilized EfficientNet-B3 model comprises 12 million parameters with its last feature representation having a dimension of 1408. We provide in
Table 1 a summary of the key characteristics of each model employed in our experiments.
4. Results
In this section, we outline the experimental work conducted in this study. We first describe the employed RS datasets, followed by detailing the experimental setup and concluding with a discussion of the outcomes from each experiment.
4.1. Dataset Description
To evaluate the utilized scene classification models, we selected three well-known datasets in RS, called Optimal-31 [
24], UCMerced [
24], and NWPU-RESISC451 [
32]. The Optimal-31 dataset was obtained from Google Earth images and includes 31 different scene classes. Each class consists of 60 images with dimensions of 256 × 256 pixels in the RGB color model. The resolution of an image is equal to 0.3 m per pixel. The UCMerced dataset comprises 2100 land-use images that were manually chosen from aerial ortho-imagery. These images are classified into 21 categories. The images were obtained from the United States Geological Survey National Map and then resized to smaller areas. The dataset is extensively utilized for aerial image classification owing to its varied spatial land-use patterns and significantly overlapping classes.
The NWPU-RESISC45 dataset was created by Northwestern Polytechnical University (NWPU) for REmote Sensing Image Scene Classification (RESISC). There are a total of 31,500 images in this dataset. It is composed of 45 classes such as airplane, airport, beach, bridge, forest, and desert. Each class includes 700 RGB images extracted from Google Earth imagery with each image size being equal to 256 × 256 pixels. Within the classes of this dataset, the spatial resolution decreases from 30.0 m to 0.2 m per pixel. In
Table 2, we disclose the various characteristics of these three datasets. In addition, we exhibit some examples of images from each dataset in
Figure 5.
4.2. Experimental Setup
In our experiments, we resized all dataset images to 224 × 224 as is performed by most other works to fit the models’ input dimensions. Each dataset was split randomly into two subsets, one used for training and the other for testing. In particular, we conducted experiments with a 50–50 split for UCMerced and Optimal-31 and a 20–80 split for NWPU, where the first value is equal to the percentage of training data while the second one represents the percentage of the testing data. We ran this split randomly five times and then considered the average classification results.
To evaluate the overall performance, we summarized the results using the overall accuracy (
OA) metric, calculated as the ratio of correctly identified samples to the total number of examined samples [
32]. It is defined by the following formula:
where
K is equal to the number of classes and
is equal to the count of accurate classifications for class
i within the test dataset while the total number of test samples is equal to |
|.
All our experiments were conducted on the Google Colab environment, utilizing the PyTorch deep learning library written in Python. The AdamW optimization algorithm was utilized with default parameter values. In order to accommodate memory limitations of the computing platform, the model was trained in batches of 16 images at a time in centralized mode and 10 images at a time in federated learning mode. In
Table 3, we reveal the different model parameters used in our experiments.
4.3. Results of Centralized Mode
We conducted experiments using two different models with each encompassing two variant networks: the Vision Transformer, with the Tiny-Base variants; and CNNs with EfficientNet-B1 and EfficientNet-B3 as the two selected networks. As stated previously, each dataset was split evenly into a 50–50 train–test split, except for the NWPU dataset. For the latter, we adopted a 20–80 split strategy for training and testing, due to the significantly larger size of this dataset. We repeated each experiment five times in a random fashion while running each experiment for 20 epochs. After training all models using the centralized approach, we evaluated each one in terms of overall accuracy (OA) using testing data. The calculated OA values, including their averages across these three datasets, are displayed in
Table 4.
4.4. Results of Federated Learning Mode
In this section, we present the results of FL mode, particularly focusing on the behavior of different models across the varying numbers of clients. The latter was chosen from the set {2, 5, 10, 15, 20, 40}. We then compare the results of using the FL mode for each number of clients and compare them with those generated by the centralized mode. In
Table 5 and
Figure 5 below, we show the OA results for the FL mode using the three different RS datasets for each of the two Transformer models and the two CNN models, respectively. To facilitate the comparison with the results of the centralized mode, we include them again in
Table 5 as the leftmost column under numbers of clients.
Analyzing the results reveals interesting trends in model performance as the number of clients increases. In both the Optimal-31 and UCMerced datasets, the Transformer models (ViT-Tiny and ViT-Base) exhibit a reduction in accuracy as the client count increases. However, for ViT-Base, this decrease only takes place up to five clients. In FL mode with a higher number of clients, ViT-Base starts to yield better performance results than in the centralized mode. The observed decrease in accuracy indicates that the FL mode presents difficulties in combining model updates from various clients, leading to a fall in overall accuracy. In contrast, the CNN models, EfficientNet-B1 and EfficientNet-B3, exhibit a more pronounced decline in accuracy with an increasing number of clients in FL mode, while accuracy increases with a decreasing number of clients in comparison to centralized mode. This behavior could suggest that the CNN models are more sensitive to variations in client data and struggle to maintain accuracy when faced with a larger number of clients.
Furthermore, within the NWPU dataset, the accuracy of the Vision Transformer models, specifically ViT-Tiny and ViT-Base, exhibits a consistent relative level even when the number of clients is increased. This behavior demonstrates that these vision models have greater resilience in managing federated learning scenarios involving a higher number of clients. The CNN models, EfficientNet-B1 and EfficientNet-B3, exhibit a slight decrease in overall accuracy, but the decline is less pronounced compared to the Optimal-31 and UCMerced datasets. This is due to the different sizes of these datasets whereby the NWPU dataset is much larger than the first two datasets. In addition, we computed the average OA results over the three datasets for the four considered deep learning models in both centralized and FL modes. These values are presented in
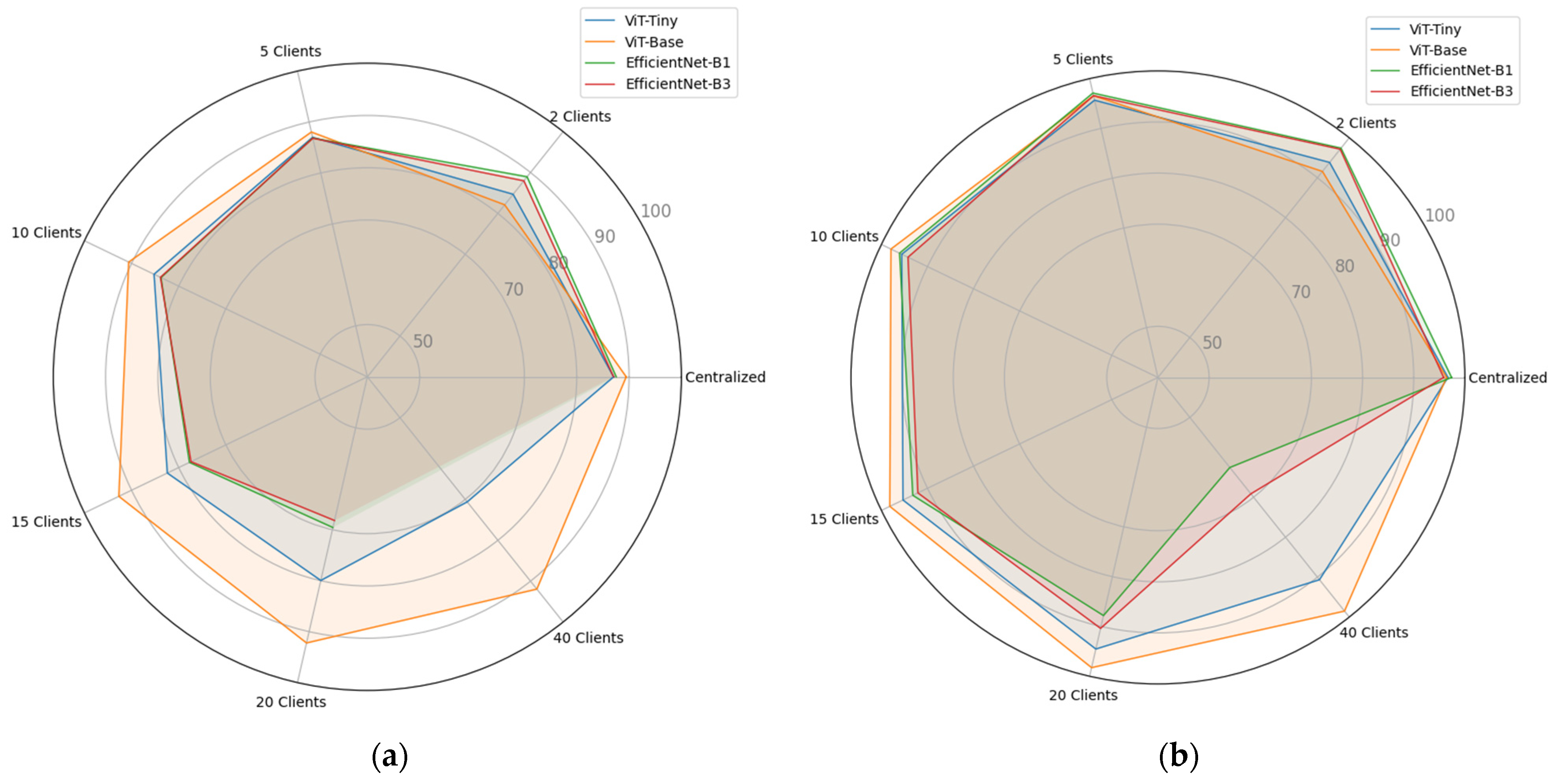
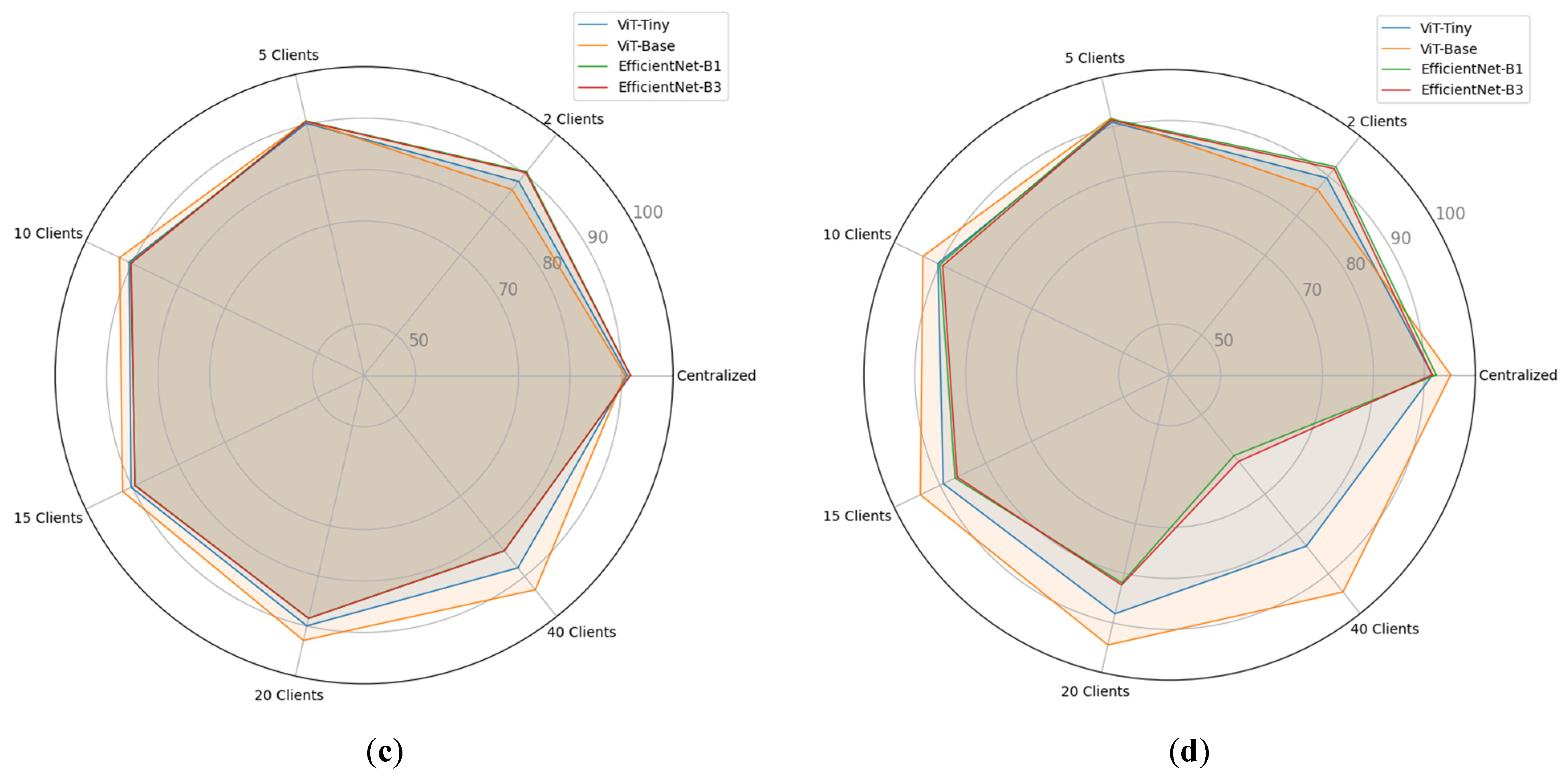
Table 6. We also exhibit the visualizations of these results in the form of radar charts in
Figure 6.
Upon analyzing the average results of the three datasets, as shown in
Table 6 and
Figure 6, it becomes apparent that the performance of all models consistently decreases as the number of clients in the FL mode increases. Except that this behavior starts to move in the opposite direction for the ViT-Base model, starting with using ten clients in FL mode. Specifically, the average OA values for ViT-Base are greater than or equal to 94.30% when the number of clients is equal to 15, 20, and 40 clients. In addition, the ViT-Base and ViT-Tiny models regularly exhibit on average superior accuracy in comparison to the CNN models starting when the number of clients is ≥10. This implies that Vision Transformer models have the potential to perform effectively in distributed environments.
These observations emphasize the impact of the number of clients on model behavior in the FL mode. As the client count grows, the aggregation of model updates becomes more challenging, perhaps leading to a decline in accuracy except for the ViT-Base model. However, different models exhibit varying levels of resilience to this challenge. In FL, vision models, due to their capacity to capture global patterns with a larger number of clients, typically outperform CNN models.
5. Discussion
In this experimental methodology, we propose an efficient solution for enhancing the results of FL. To this end, a client-dropping mechanism is implemented as shown in
Figure 7, wherein one or more clients deliberately refrain from transmitting updates to the server. The objective of employing this methodology is to augment the resilience of the model.
The experimental procedure entails the utilization of a sample size of 10 clients, with the selection of clients to be eliminated being conducted in a random manner during an epoch. Through the implementation of random client dropping, our objective is to analyze the model’s performance across various circumstances and measure its capacity to manage missing updates from individual clients. The use of this technique in FL has demonstrated promising outcomes, as evidenced by the results presented in
Table 7 below. We note that the inclusion of client dropout throughout the training phase results in enhanced model accuracy. When doing a comparison between the ViT-Base model and the ViT-Base with Dropped-Clients model, it becomes evident that the latter model exhibits superior accuracy values when excluding two clients in Optimal-31 and UC-Merced datasets while the accuracy in NWPU decreases due to the size of the dataset. We think that this is primarily due to the loss of a significant amount of data engendered by the dropped clients.
In order to verify the accuracy of our experimental findings, we carried out additional training using ViT-Base in FL mode with 40 clients while employing the same variation in the number of dropped clients. The generated performance results from the testing set are presented in
Table 8.
To affirm our earlier findings when the training of 10 clients was applied, we observe once again that the ViT-Base model with dropped clients consistently outperforms the model in terms of overall accuracy across datasets with small sizes. This further confirms that our new technique of selectively dropping clients during training enhances the robustness and performance of the model in federated learning scenarios. Such results align with our prior experimentation, demonstrating the efficacy and dependability of the suggested method. The enhanced performance found in the dropped clients model provides more support for its capacity to improve the accuracy and robustness of the model in the context of FL paradigms.
The results confirm the efficacy of the proposed technique and emphasize its capacity to improve the precision and robustness of models in FL situations. Further analysis and experimentation could provide deeper insights into the specific mechanisms behind this improvement as well as potentially guide future advancements in the field of federated learning.
6. Conclusions
FL is a cutting-edge machine learning paradigm that has the potential to transform how we train models in a privacy- and security-conscious world. In this article, we describe our research work involving the use of FL in the classification of RS scenes. Four deep models belonging to Transformer- and CNN-based architectures are utilized, including ViT-Tiny, ViT-Base, EfficientNet-B1, and EfficientNet-B3 networks. In addition to the centralized mode, we considered the FL paradigm by varying the number of clients from 2 to 40 and examined the classification performance of these models in terms of overall accuracy. For a number of clients greater than or equal to ten, the two Transformer-based models, and especially ViT-Base, outperform the two CNN-based ones. On the other hand, the latter two models exhibit competitive performance for a small number of clients.
To ascertain further the results generated by the ViT-Base model, we conducted additional experiments to examine its effectiveness and robustness when it is trained in different FL contexts while facing a varied number of dropped clients. That is, we tested the classification performance of ViT-Base by implementing a client-dropping mechanism for two FL scenarios: one with ten clients and a second one with 40 clients. By varying the number of dropped clients in each scenario, we obtained results that attest to the high resiliency and robustness of ViT-Base, particularly when the number of dropped clients is in the range from two to five. For relatively small datasets, such as Optimal-31 and UCMerced, training ViT-Base in FL with dropped clients generated higher classification results than without any dropped-out clients. These results could point toward a new methodology of training DL models in the FL paradigm to enhance their robustness and classification performance. As part of our future work in this realm, we plan to employ FL in other RS tasks such as segmentation and object detection as well as in other application domains, where concerns about the security and privacy of clients’ data are more prominent. Another possible research direction is to explore alternative dropout mechanisms, such as those based on data quality rather than random dropout. This could potentially offer another solution to enhance classification results.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}