4.2. Context Enhancement Module
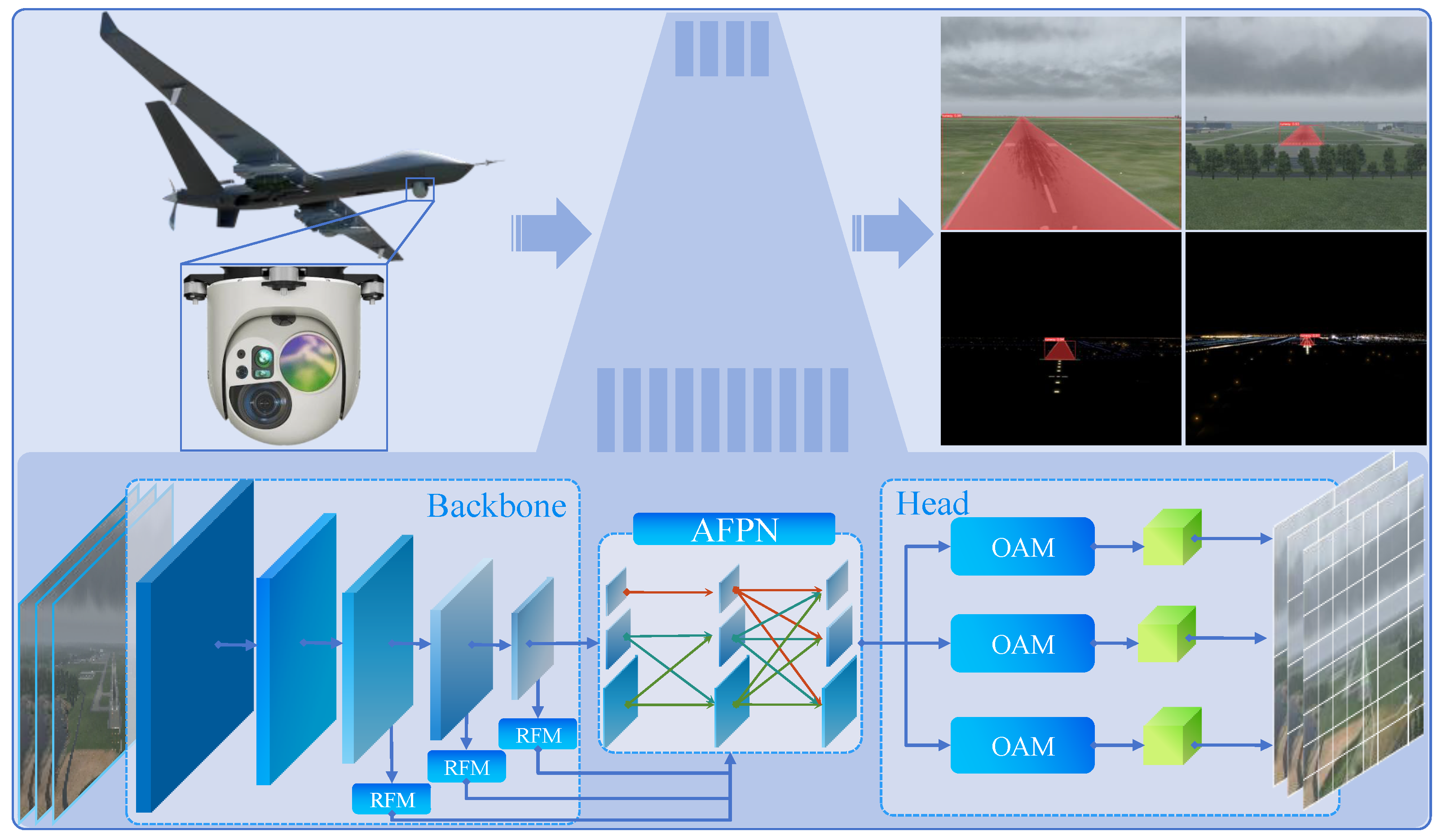
Due to rapid changes in the height and speed of UAVs during landing, the runway’s scale undergoes significant distortion in captured images, along with substantial fluctuations in background information, which poses two primary challenges: one problem is the loss of target runway caused by the drastic distortion of the field of view, especially small targets in the distance; another concern is false positives and false negatives in the presence of confusing objects. What is more, inherent noise in the original images makes it hard to classify the pixels of the runway, and the downsampling in the backbone of YOLOv8-seg further reduces the image resolution, erasing crucial and fine details. To address the challenges, a dual strategy comprising CEM and AFPN is proposed, where CEM focuses on contextual enhancement, while AFPN is dedicated to alleviating semantic gaps between different layers.
In the field of signal processing, low-pass and high-pass filters can be used to adjust the frequency components of signals in the frequency domain to achieve different processing requirements for signals. In practical applications, low-pass and high-pass filters are often combined to form band-pass filters to achieve more refined signal processing goals. The design of CEM is inspired by the above frequency domain analysis concept. As shown in
Figure 7 natural images can be decomposed into two main components: one is the feature that describes the smooth transition or gradient in the image, which corresponds to the low-frequency component
; the other is the feature that represents the sudden changes or subtle details in the image, which corresponds to the high-frequency component
. The original image
, where
C represents the channel dimension, and
represents the spatial resolution. This decomposition satisfies satisfies Equation (
1):
The decomposition makes it easy to understand and process the overall trends and local details in the image. Similarly, annotated instance segmentation images can also be decomposed into the sum of low-frequency and high-frequency components. The low-frequency component can be obtained by using mean or Gaussian filtering, while the high-frequency component can be obtained by using Laplacian or Sobel filtering. Here, the high-frequency component is obtained by original feature
I minus the low-pass component
as in
where
is the Fourier transform,
is the inverse Fourier transform,
x and
y denote the horizontal and vertical offsets in the
c channel, respectively, and
represents the standard deviation of the Gaussian function.
As shown in the second column of
Figure 7, the low-pass component is relatively smooth, while the high-pass component in the third column contains clearer details and more contours.
In order to extract runway features more effectively, CEM introduces the idea of band-pass filters. The idea is based on an understanding of the frequency domain information of images, where the edges of the runway are considered to be of high frequency and the background of low frequency. The contained area, especially the center area, of the runway has the band-pass information to be segmented in target instances. As shown in
Figure 8, after the original images are filtered by the band-pass filter, not only are the edges of the runway successfully highlighted, making them clearer and more distinguishable, but so is the low-frequency object area.
In this way, sensitivity to the features of specific target areas is introduced in VALNet for better adaption to image changes of runway under different scenarios and lighting conditions, and for improving the network’s perception of the center area of runway and instance segmentation of the runway, especially in cases involving complex textures and large-scale changes. By integrating band-pass filters into the instance segmentation network, improvement in the robustness and generalization of the network is expected, making it more suitable for various complex landing scenarios.
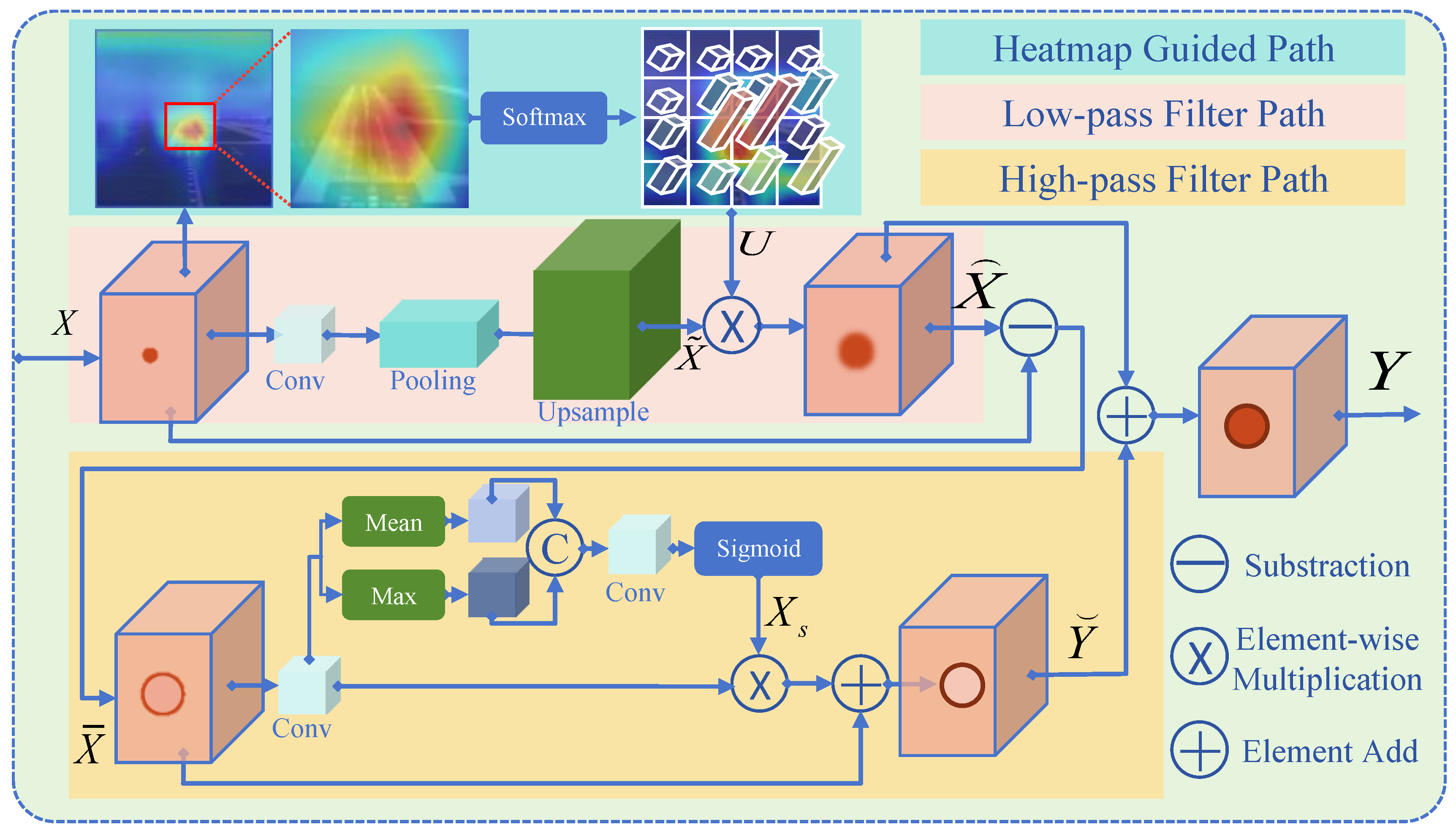
As mentioned above, the concept of band-pass filters in CEM is introduced for the effective extraction of runway features. The model can learn appropriate “frequencies” when focusing on the middle area of the runway rather than on edge and background information. Thus, CEM is designed by a three-channel method.
The goal of the heatmap-guided channel is to filter out the background information in the image by the low-pass filter and the heatmap. To achieve it, the heatmap of the image is generated, where the intensity in the heatmap reflects the contribution of the pixel to the overall semantics. By multiplying the heatmap feature with the low-pass filtered feature, an adaptive filtering mechanism focusing more on areas with high semantic intensity is achieved. It helps the model to reduce background interference and emphasize more on the central part of the runway and overall contextual features.
The high-pass filter channel aims to capture the high-frequency information of the image, especially the edges and subtle geometric features of the runway. When combined with the spatial attention mechanism, it can self-adaptively adjust the model’s attention to different regions of the image. The combination enhances the model’s perception of the runway boundary, thus improving its ability to capture detailed information and to understand the geometric shape and structure of the runway.
The combination of the three channels, namely, the heatmap-guided channel, the high-pass filter channel, and the spatial attention channel, forms the overall design framework of CEM. By integrating information of different frequencies, CEM can more comprehensively and accurately capture the runway features in the image, providing an effective feature extraction method for visual tasks. It improves the model’s understanding and generalizing of the runway structure and contextual features in practical applications.
As shown in
Figure 9, we define the feature input to the CEM structure from the backbone network as X, which is the input to CEM. We define the CEM output as
Y, whose size is equal to
X. The heatmap channel first obtains the heatmap from the input feature as shown in Equation (
3):
where
i is the row index,
j is the column index,
n is the feature index, and
c is the total number of channels.
The heatmap consists of background region
, high-temperature target region
, and low-temperature target region
, satisfying
The goal is to make the background region
small enough while
and
each adequately cover the target area such that the corresponding heatmap
corresponding to the low-pass filter path output feature
satisfies
To meet Equation (
5) is to expand and amplify the targeted high-temperature region
in the heatmap. Therefore, as shown in
Figure 9, in each local region of size
, guided by
M, a vector
U with the highest probability representing the target region is obtained by Softmax:
where
and
.
For the low-pass filter path, feature extraction is performed on the entire input through convolutional operations, and subsequent pooling operations reduce the spatial resolution of the feature map and preserve the main feature information, allowing the model to better focus on the overall structure of the image. The final up-sampling restores the spatial resolution of the feature map to the size of original heatmap and output .
After the feature map
is obtained from the low-pass filter path, the heatmap-guided low-pass filtering result
can then be obtained by elementwise multiplication of
and
U:
Throughout the design, the output guides the low-pass filter to pay more attention to the target region, making it more targeted in capturing task-relevant information. The strategy of combining heatmap information helps improve the model’s perception and understanding of the target region, enhancing semantic information related to the targeted area.
For the high-pass filter path, the input
is obtained by subtracting the output of the low-pass filter path
from the original feature
X:
As shown in Equation (
8), the original high-pass filter directly extracts the runway’s edges from the image. However, due to the presence of a large amount of texture and details in the features, these pieces of information may introduce unnecessary complexity to the model, causing some challenges.
Given that the spatial attention mechanism enables the model to focus more on specific regions of the image and to capture important task-relevant information, introducing a weighting mechanism allows the model to dynamically adjust its attention to different areas, thereby enhancing its perceptual capabilities and task performance. Therefore, for more accurate capturing of the edge information of the runway and suppression of irrelevant textures, especially the details and edge features of the target region, a spatial attention mechanism is introduced to enhance high-frequency information.
In the high-pass filter pathway, the intermediate features are obtained by the original high-pass filter, which includes edge information of the runway and the textures in the image. After that, the spatial attention mechanism is introduced, which emphasizes important areas in the image while suppressing irrelevant texture information by weighting the intermediate features. Specifically, mean and max operations are performed to obtain the spatially attention-weighted high-pass features. Thus, more focus is placed on the positions containing target information in the image, diminishing the influence of regions containing only texture information at the same time. In this way, fine-tuning of the output of the high-pass filter is achieved, making it more focused on the critical areas of runway edges. The spatial attention
where
is the sigmoid activation function, ∘ is the concatenation operation, and
is the
convolution operation.
indicates taking the maximum value at the same position on the feature map, and
represents taking the average value at the same position on the feature map along the channel dimension.
So, the final output of the high-pass filter channel is
where ⊙ is the elementwise dot product, and
F is the
convolution operation.
The final output of CEM comes from the combination of the high-pass features of the weighted spatial attention and the output of the heatmap-guided low-pass filtering path. It retains the runway edge information and reduces interference from textures and irrelevant details, providing the model with a clearer and more precise feature representation as shown in
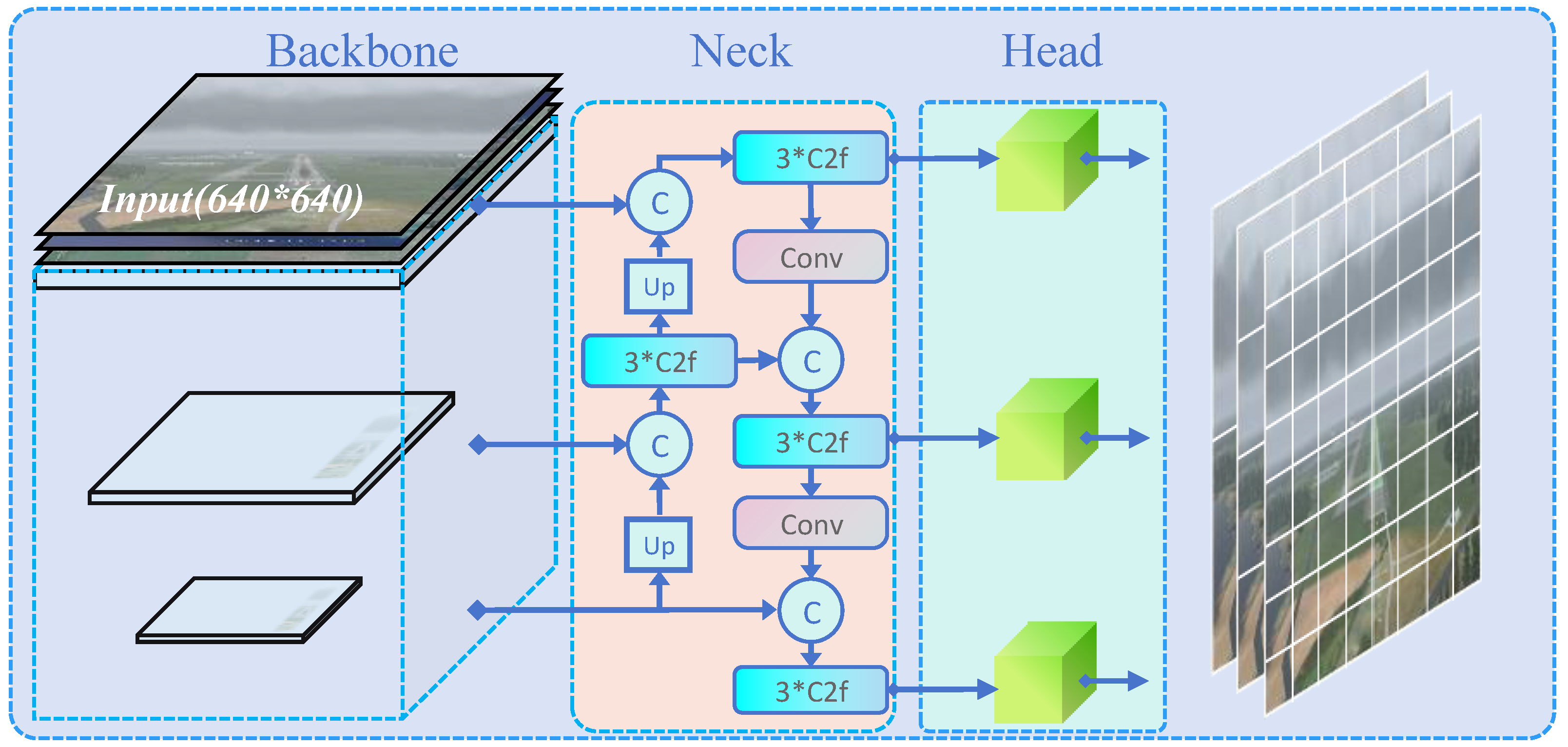
Note that the original YOLOv8 model employs the Path Aggregation Feature Pyramid Network (PAFPN) which introduces a bottom–up pathway on top of the Feature Pyramid Network (FPN). It aims to facilitate the propagation of high-level features from top to bottom, allowing low-level features to acquire more detailed information. However, a challenge appears such that detailed information from low-level features may be lost or degraded during the propagation and interaction process, resulting in a certain degree of semantic gap.
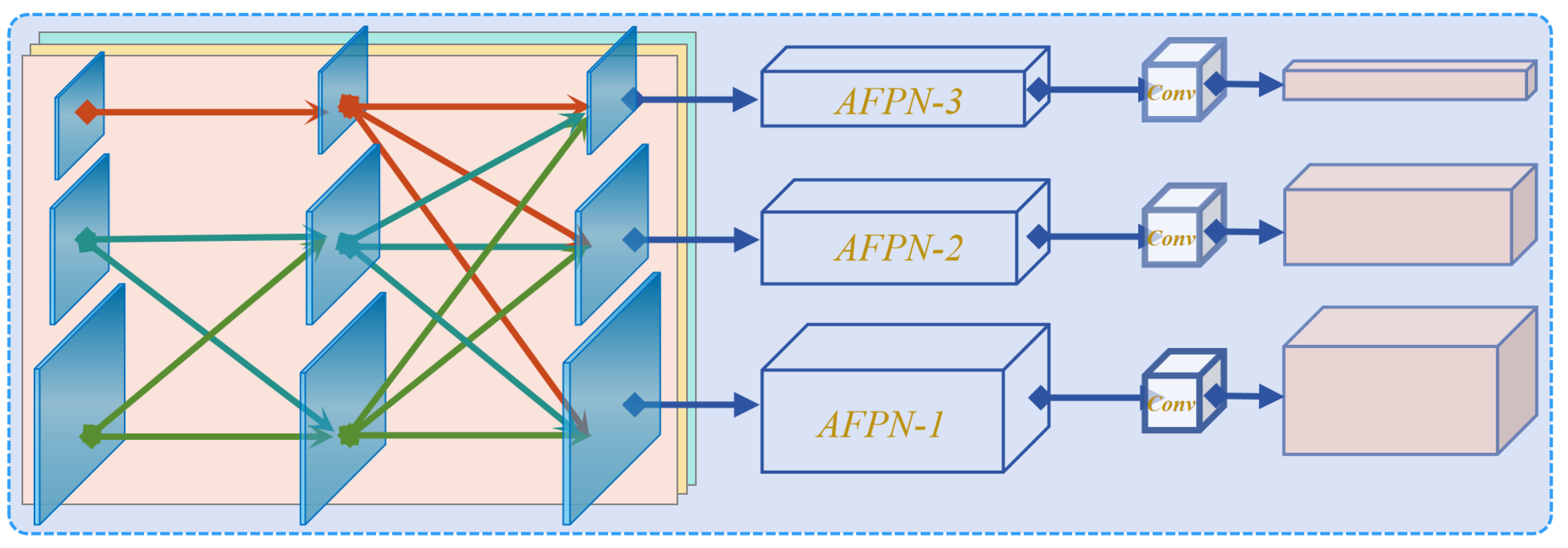
To handle the challenge, AFPN is introduced as shown in
Figure 10. AFPN is designed to facilitate direct interaction between non-adjacent layers by first fusing features from two adjacent layers and gradually incorporating high-level features into the fusion process. In contrast to traditional top–down pathways, AFPN emphasizes more on narrowing the semantic gap between low-level and high-level features, thus mitigating large semantic differences between non-adjacent layers.
In practical implementation, to integrate detailed information from low-level features effectively, AFPN progressively fuses high-level features to improve the overall understanding across different hierarchical features of the model, thus enhancing its performance in object detection tasks. The progressive fusion of AFPN alleviates the issue of semantic gap, allows the features from various layers to be comprehensive used, and increases the accuracy and robustness of runway segmentation.
4.3. Orientation Adaptation Module
The direct augmentation of data to improve a model’s robustness to rotation during training may deviate from real-world scenarios. Data augmentation involves transforming and distorting the original data to expand the training set and enhance the model’s robustness to various changes. However, in the practical application scenarios of autonomous landing systems, conventional data augmentation techniques may lead to some unrealistic scenarios.
For instance, directly flipping the upper half of an image (usually the sky or other irrelevant information) to the lower half through data augmentation might result in unreasonable scenarios, such as placing the sky at the bottom of the image and the ground at the top. Such situations are impossible in the real world because, during the autonomous landing process of an aircraft, the relative position and orientation of the aircraft are subject to physical laws, and the sky cannot be below the ground.
Therefore, to better adapt to the direction changes in real-world scenarios, the OAM is used to fuse rotation information instead of relying on data augmentation that does not conform to reality. This approach is more in line with the motion laws of aircraft during landing, ensuring consistency between model training and application, and improving the reliability, performance, and robustness of the overall system.
The inspiration behind the design of OAM stems from a profound understanding of the potential directional changes that may occur during an aircraft’s landing process. By introducing OAM into the segmentation head, the fusion of rotation information is achieved, which allows the model to perceive the relative position and orientation between the aircraft and the runway in different directions more comprehensively and accurately. In this way, the model exhibits more robust performance in real-flight scenarios, providing the autonomous landing system with a more reliable visual perception capability when facing the complexity and uncertainty of actual landing scenarios.
Of the triple-channel based OAM, the three branches can obtain features of a 90° clockwise rotation tensor, 90° counterclockwise rotation tensor, and original tensor by introduced rotation operations and residual transformations, where the 90° clockwise rotation tensor represents the state of the original feature after a clockwise rotation of 90°, the 90° counterclockwise rotation tensor represents the state of the original feature after a counterclockwise rotation of 90°, and the original tensor represents an unrotated state.
The triple-channel design allows the full usage of the rotation information by obtaining features of different angles through multiple channels, thereby enhancing the model’s ability to capture rotational transformations in input images. Each channel undergoes specialized processing to preserve and highlight the captured features of specific rotation directions.
The triple-channel based OAM uses the rotation operation;
Figure 11 shows the process.
The input features from the backbone network into the OAM structure are denoted as
. The output of OAM is defined as
, with the same size as
. OAM comprises three channels: the CR-Channel of 90° clockwise rotation around the C-axis, the CL-Channel of 90° counterclockwise rotation around the C-axis, and the Original-Channel representing the unrotated, original features. The operations for the CR-Channel and CL-Channel are similar: both involve rotation first, then feature extraction via Max-Avg Pooling, and finally reverse rotation to complete the process. By Rodrigues’ rotation formula, the rotation tensor around any axis is defined as
where
is the rotated tensor,
is the rotation matrix, and ⊙ denotes the elementwise multiplication. The rotation matrix
is expressed as
with
representing the identity matrix,
the rotation angle, and
the anti-symmetric rotation matrix around the axis.
Thus, the rotation expression of the input features for the first rotation stage of CR-Channel and CL-Channel is
where
represents the features after a 90° clockwise rotation,
represents the features after a 90° counterclockwise rotation,
denotes the rotation tensor around an axis by an angle
, and
are the input features, with
C representing the channel dimension and
representing the spatial resolution.
In the second rotation stage of the CR-Channel and CL-Channel, features are extracted at different angles by spatial attention mechanisms, followed by inverse rotation:
where
and
represent the output features of the CR-Channel and CL-Channel after inverse rotation, respectively.
denotes the inverse rotation by angle
,
is the sigmoid activation function,
is the convolution operation with a
kernel,
is the average pooling operation,
is the maximum pooling operation, and ⊙ denotes elementwise multiplication.
For the Original-Channel, the input feature is
, and the output is
where
stands for full connection,
for global average pooling, and
for global maximum pooling, with details in
By experiments, the form of adaptive parameters is adopted for the final output of OAM:
where
,
, and
are self-adaptive weights satisfying.
The three-channel structured design obtaining feature representations at different angles improves the ability, robustness, and adaptability of the model in capturing rotation transformations in input images. The model can strongly support autonomous landing systems in accurately determining the relative position between the aircraft and the runway.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}