
LRMSNet: A New Lightweight Detection Algorithm for Multi-Scale SAR Objects



Abstract
1. Introduction
- We have devised a novel context aggregation module termed the Global Enhancement (GE) block, which comprises two attention modules adept at capturing global information more effectively within SAR images.
- Given that the majority of targets in SAR images are small and the background environment is susceptible to interference, we design a new backbone network with a large receptive field to significantly enhance feature expression ability. We add the GE block to the backbone network to increase the network’s depth and enhance long-range dependencies.
- We designed an Information Fusion Module (IFM) to effectively integrate the multi-layer feature layers obtained from the backbone network and re-output them without altering the scale. This approach enables better aggregation of feature information extracted from the backbone network and helps prevent information loss.
- To enhance feature extraction and aggregation while addressing potential information loss during the extraction process of SAR targets, we have devised an efficient multi-scale feature fusion network. This network comprises feature extraction modules for effectively aggregating feature layers and a feature pyramid network.
2. Related Work
2.1. SAR Image Object Detection
2.2. YOLOv8
3. Materials and Methods
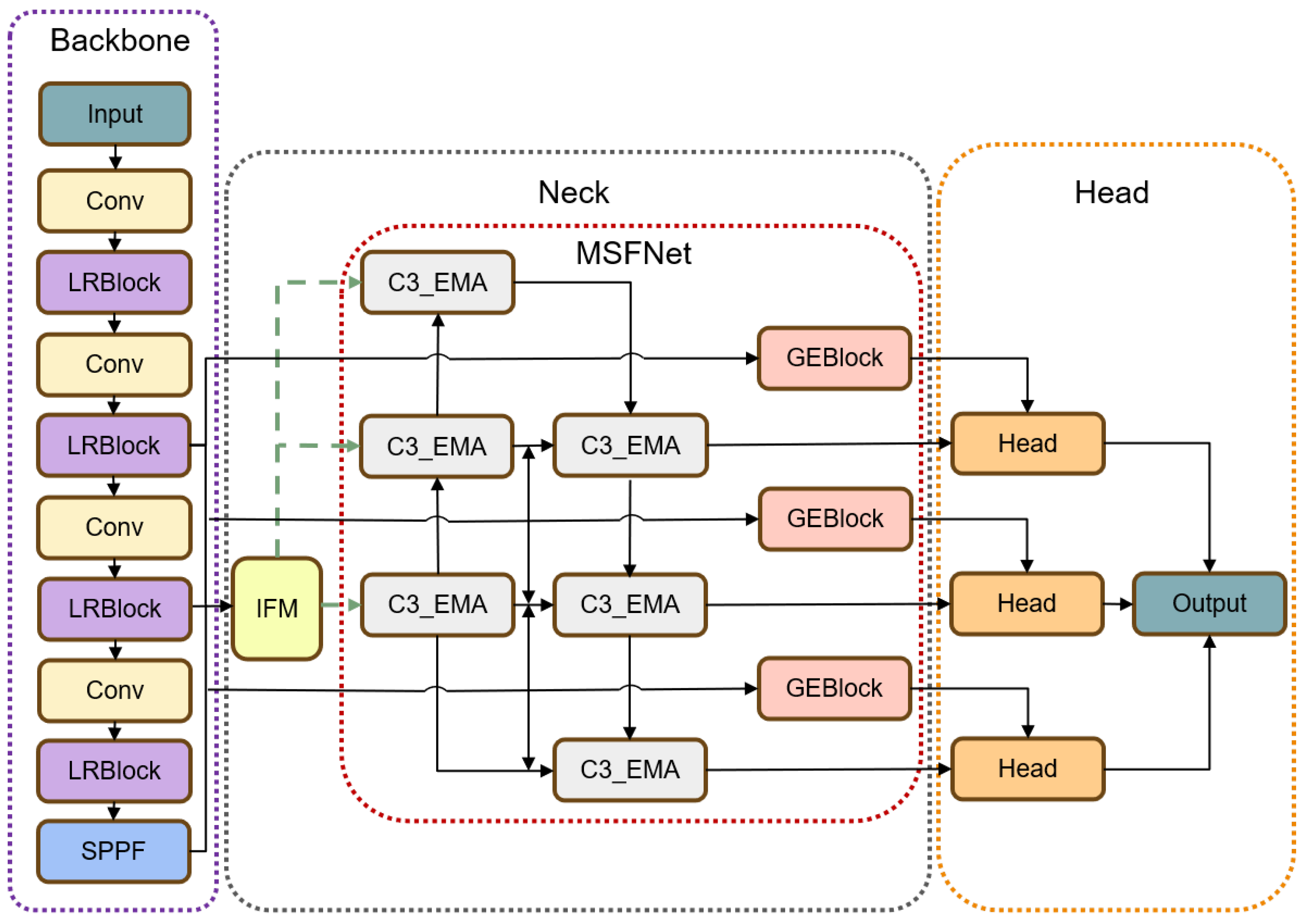
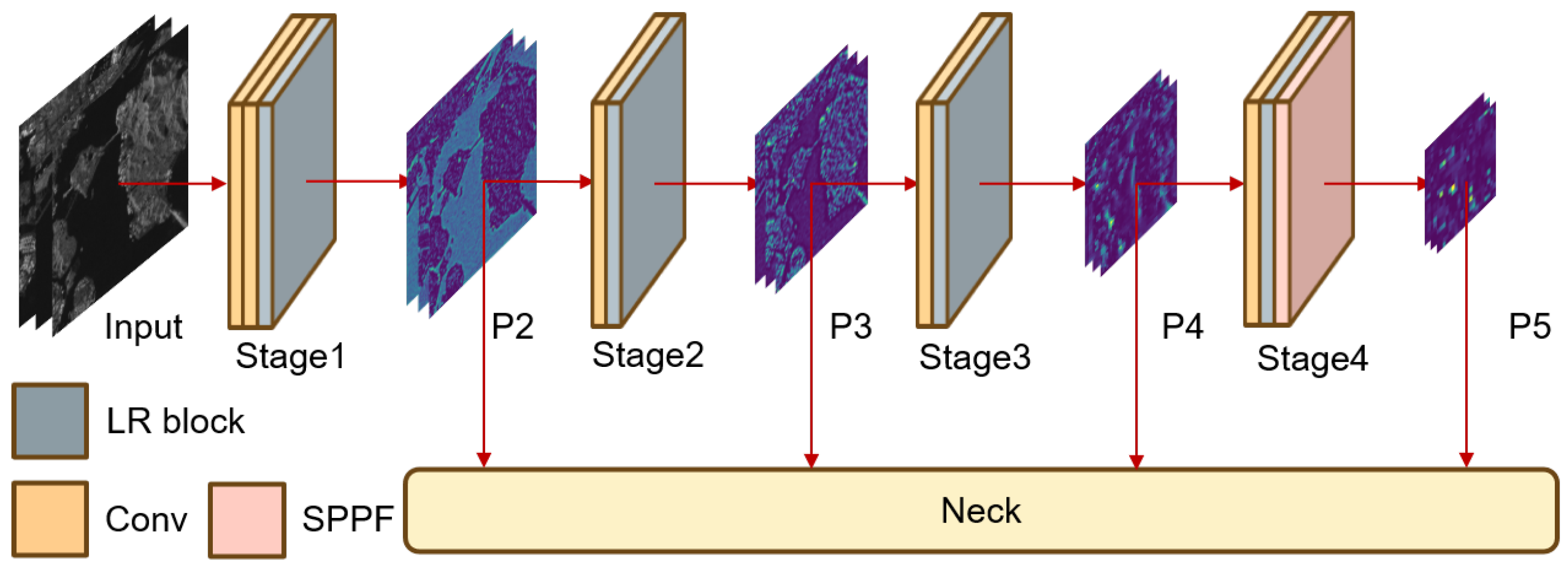
3.1. Overall Network Structure
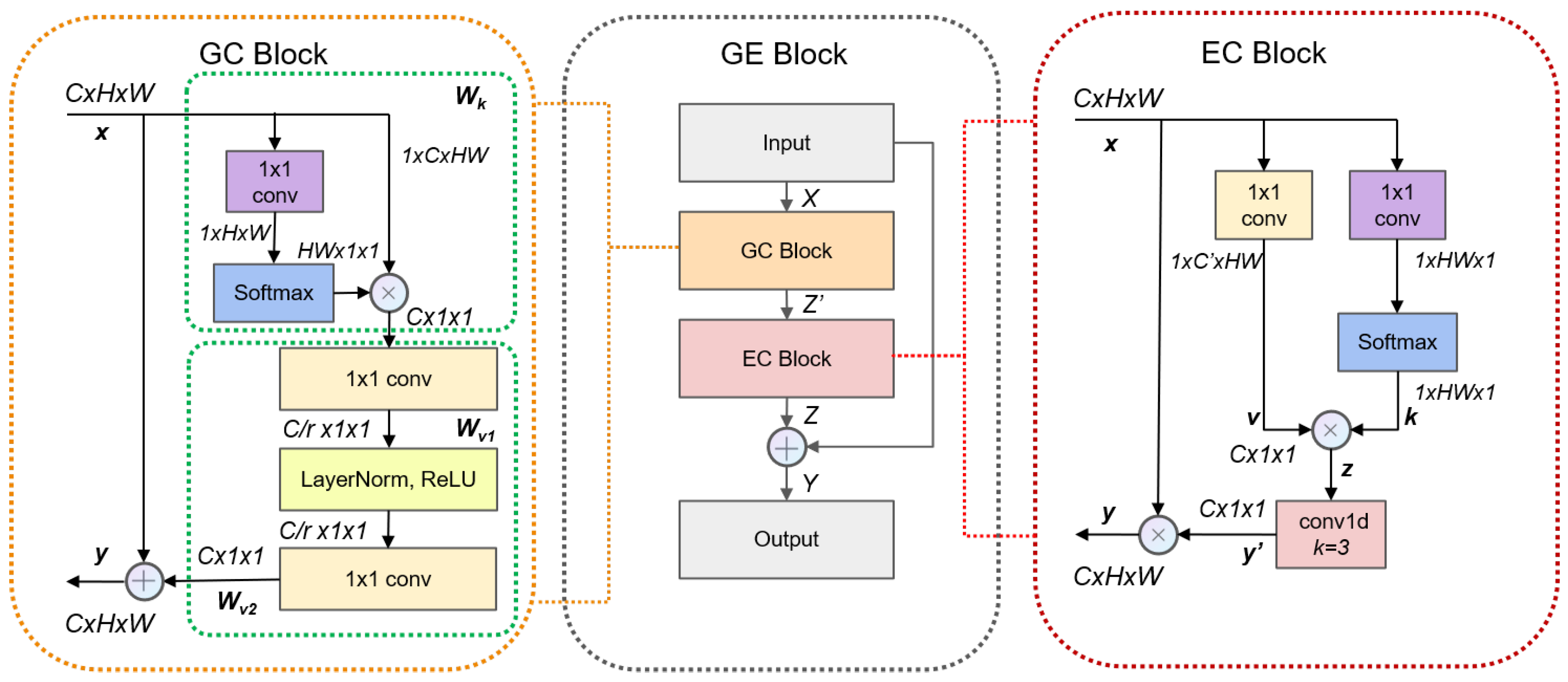
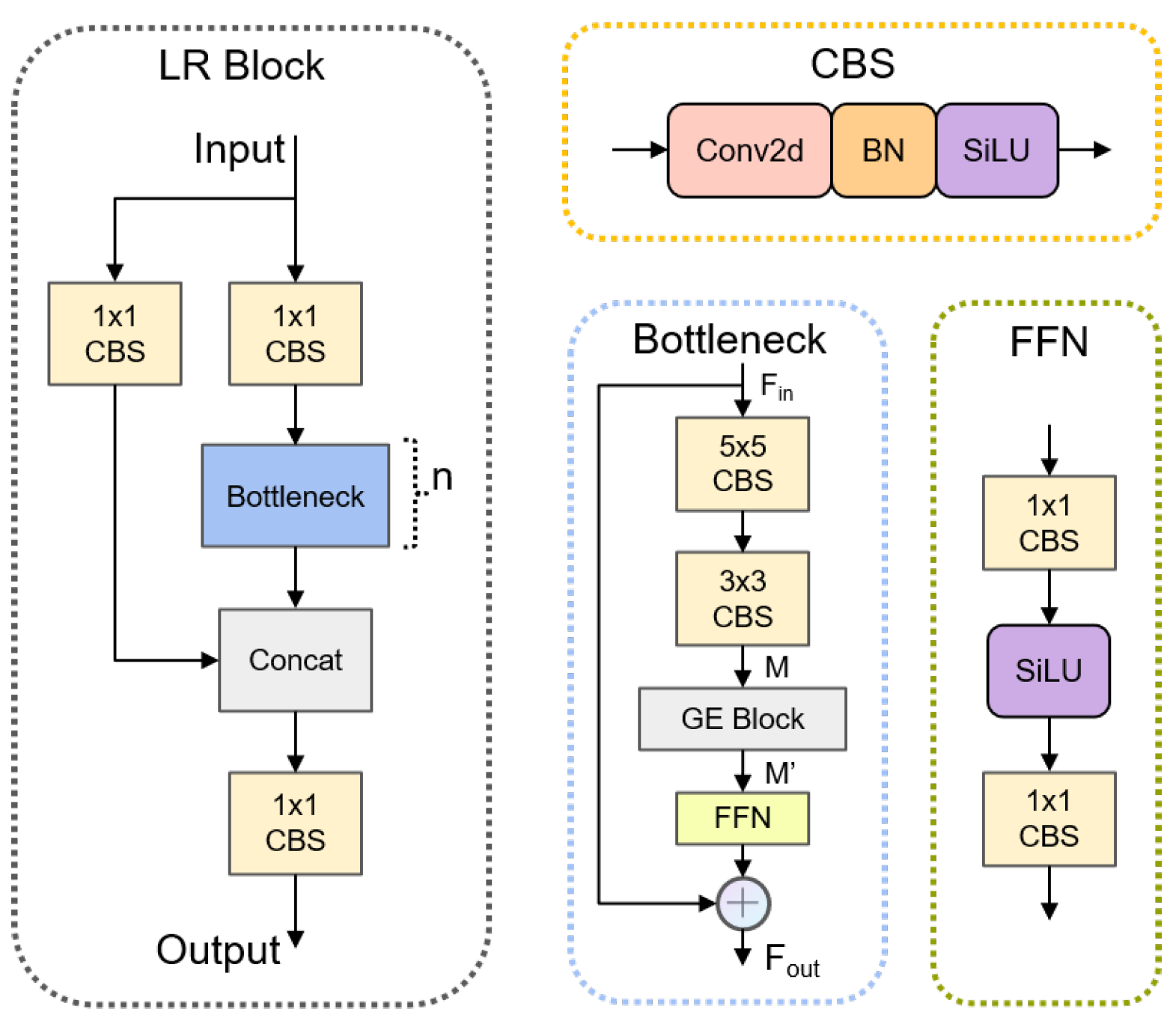
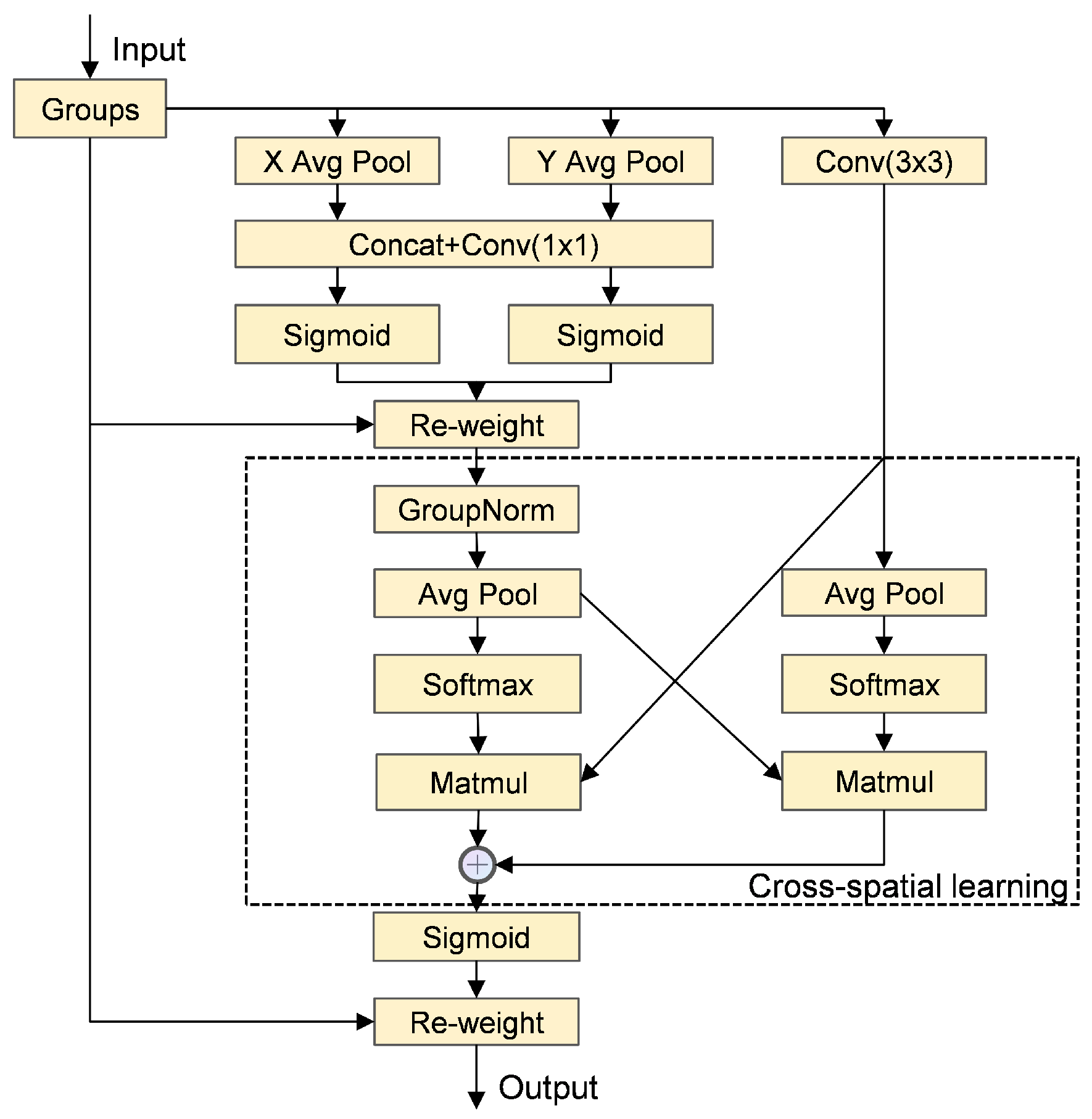
3.2. Global and Efficient Context Block (GE Block)
| Algorithm 1 The EC Block. |
| Input: Input tensor x, input channels , reduction factor , kernel size Output: Output tensor y
|
3.3. Large Receptive Field Backbone (LRFB)
| Algorithm 2 The Bottleneck of LR Block. |
| Input: Input tensor x, input channels , output channels , shortcut flag , groups g, expansion factor e Output: Output feature map
|
3.4. Information Fusion Module
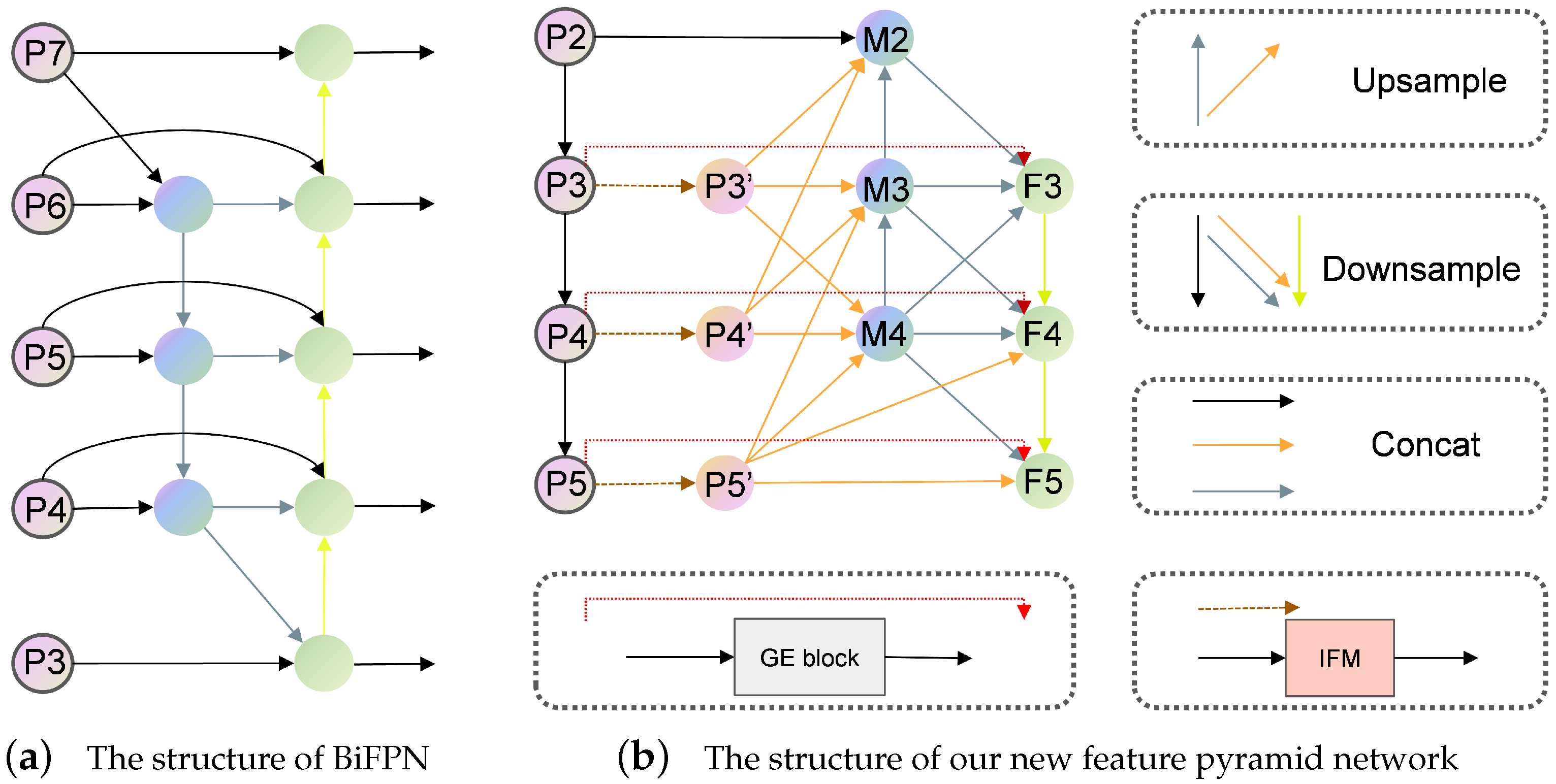
- Feature alignment module (FAM). We choose the P3, P4, and P5 features outputted by the backbone network for fusion. By performing up-sample and down-sample on the three feature layers to achieve uniform scale size, we retain both the detailed information of low-level features and the semantic information of high-level features. In FAM, we employ the average pooling (AvgPool) operation to down-sample and the bilinear interpolation to up-sample input features. Subsequently, we employ convolution modules to process different branches, ensuring the attainment of an equal number of channels for subsequent processing.
- Feature fusion module (FFM). FFM consists of a convolutional fusion module and an attention module. Initially, a convolutional layer is utilized to concatenate the feature tensors of the three branches along the channel dimension, followed by the employment of an attention module (GE block) to further aggregate the fused features. Using the information aggregation of the P4 feature layer illustrated in Figure 5b as an example, the convolutional fusion module receives three feature layers with an identical number of channels as inputs and generates a feature layer . GE blocks are subsequently utilized to aggregate the fused features, resulting in () as the final output. The formula is as follows:
3.5. Multi-Scale Feature Fusion Network
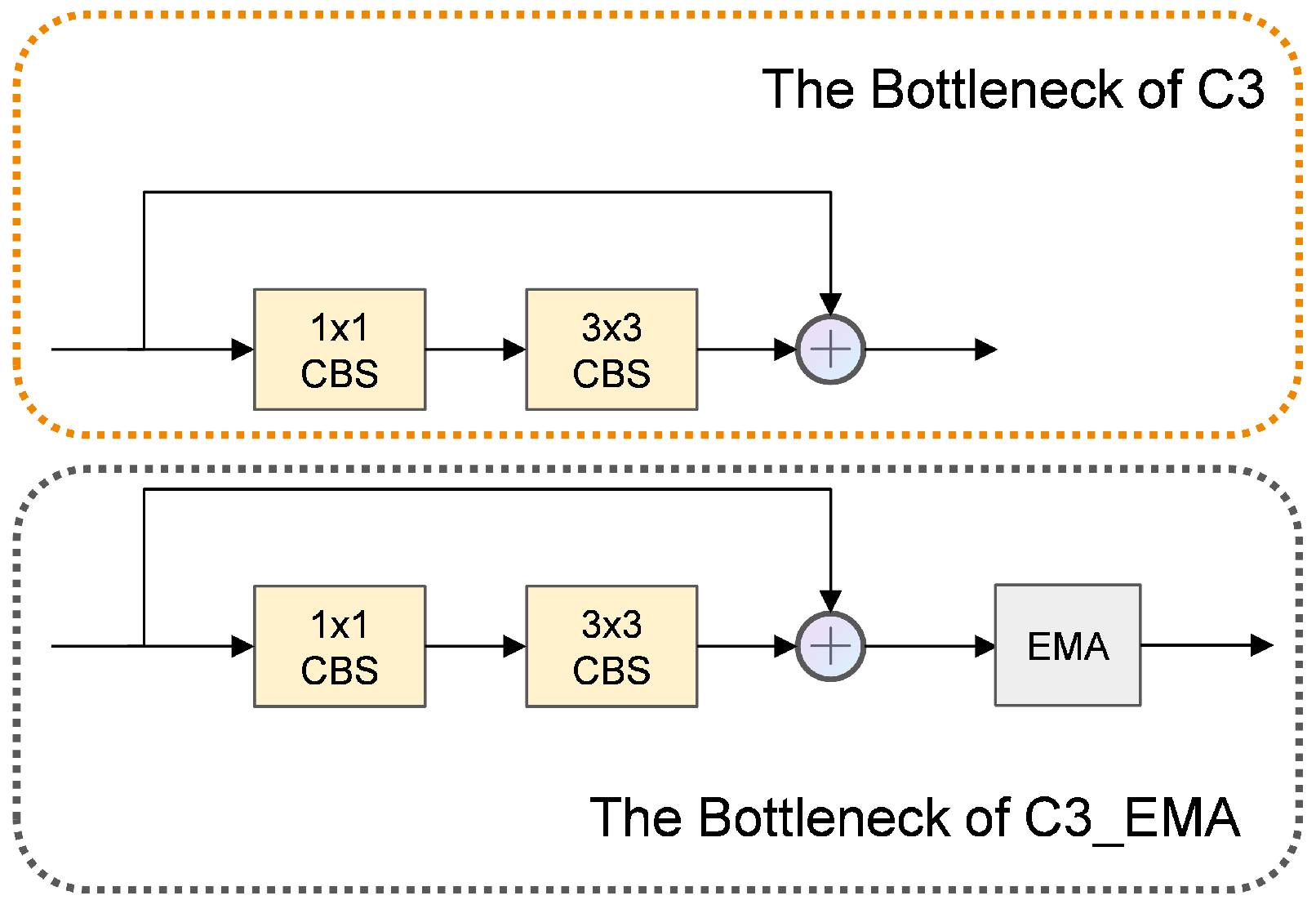
3.5.1. C3_EMA
3.5.2. Bi-Directional Feature Pyramid Network (BiFPN)
3.6. Evaluation Metrics
4. Experiments and Results
4.1. Datasets
- MSAR-1.0: The MSAR-1.0 is a large-scale multi-class SAR image target dataset released in 2022, comprising 28,449 images and scenes, including airports, ports, nearshore areas, islands, open seas, urban areas, etc. The target types consist of four categories: 6368 aircraft, 29,858 ships, 1851 bridge beams, and 12,319 oil tanks [44]. As the official dataset does not specify a partition, we randomly divided the dataset into training, validation, and testing sets in a ratio of 7:2:1.
- SSDD: The SSDD dataset, released in 2017, comprises 1160 images, including 2546 ships. The ship targets in the SSDD dataset are categorized into three types: large, medium, and small, with small targets being the majority [45]. According to the official regulations, we divided the dataset into training and testing sets in a ratio of 8:2 for fair comparison.
- HRSID: The HRSID dataset, released in 2020, comprises 5604 images and 16,951 ships, with 98% of them being small to medium-sized targets, making it suitable for evaluating the model’s small object detection performance [46]. According to official regulations, we divided the dataset into training and testing sets in a ratio of 6.5:3.5.
4.2. Experiment Settings
4.3. Experiments on MSAR-1.0 Dataset
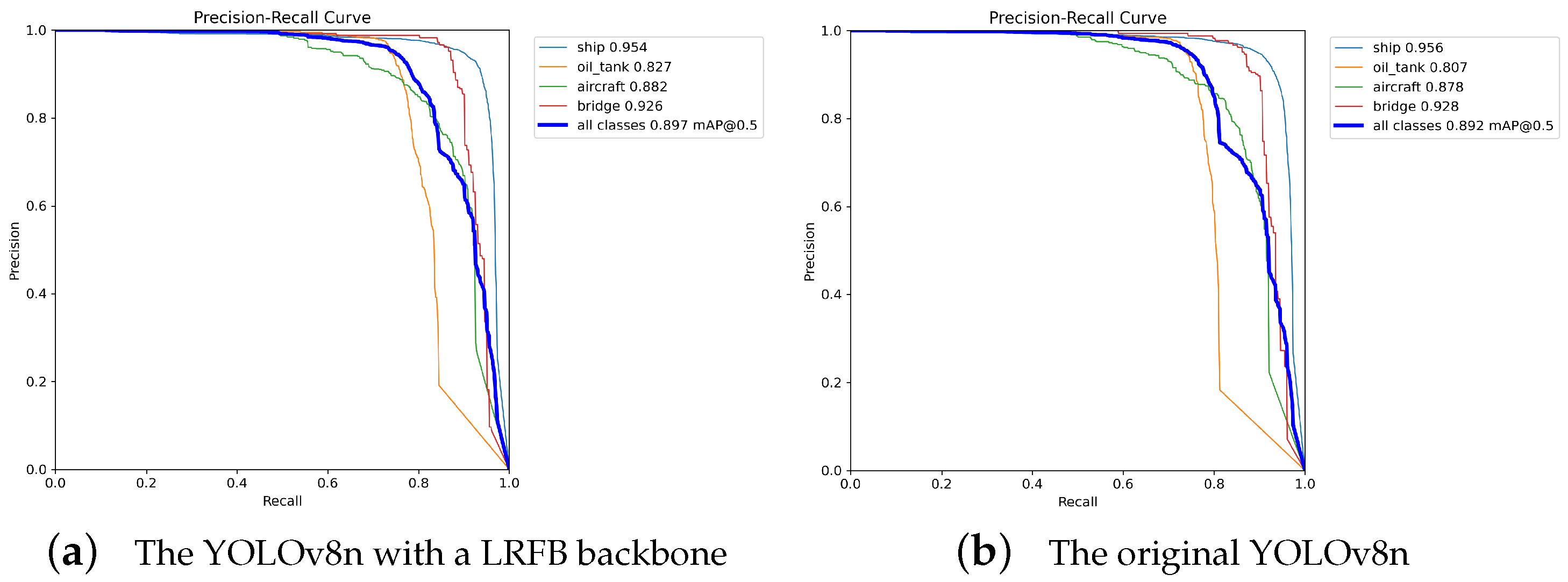
4.3.1. Influence of the LRFB Network on the Experimental Results
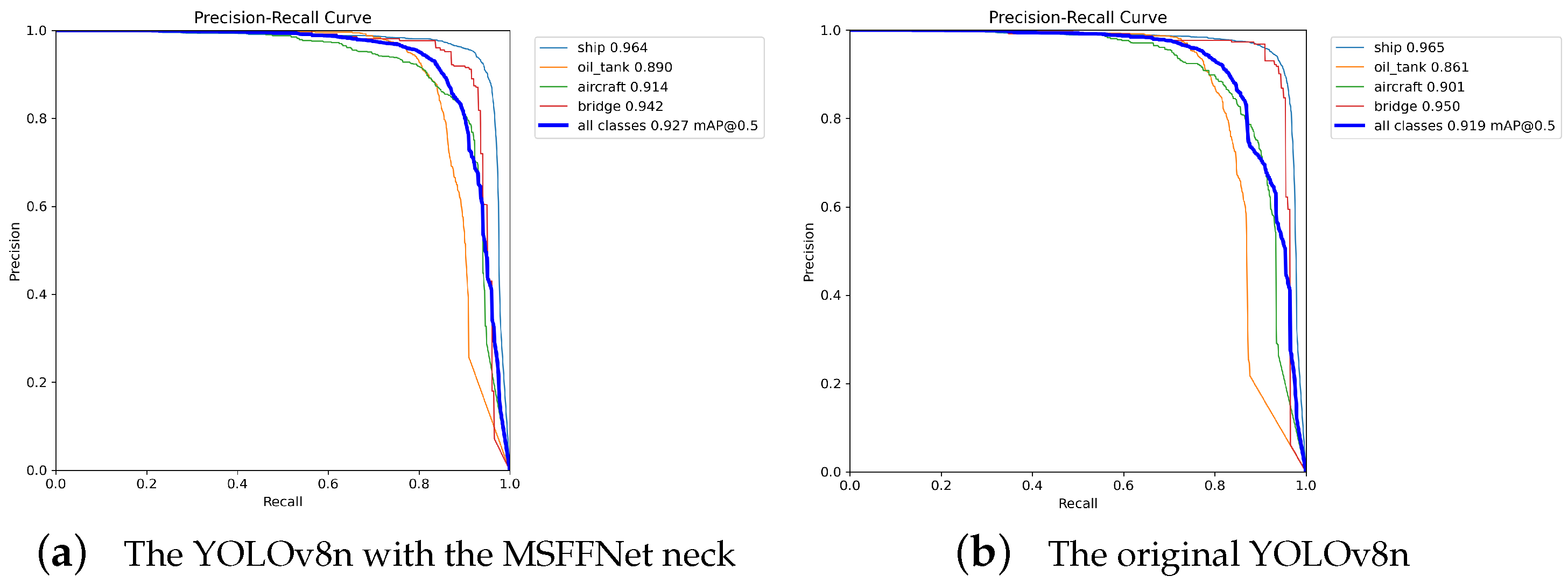
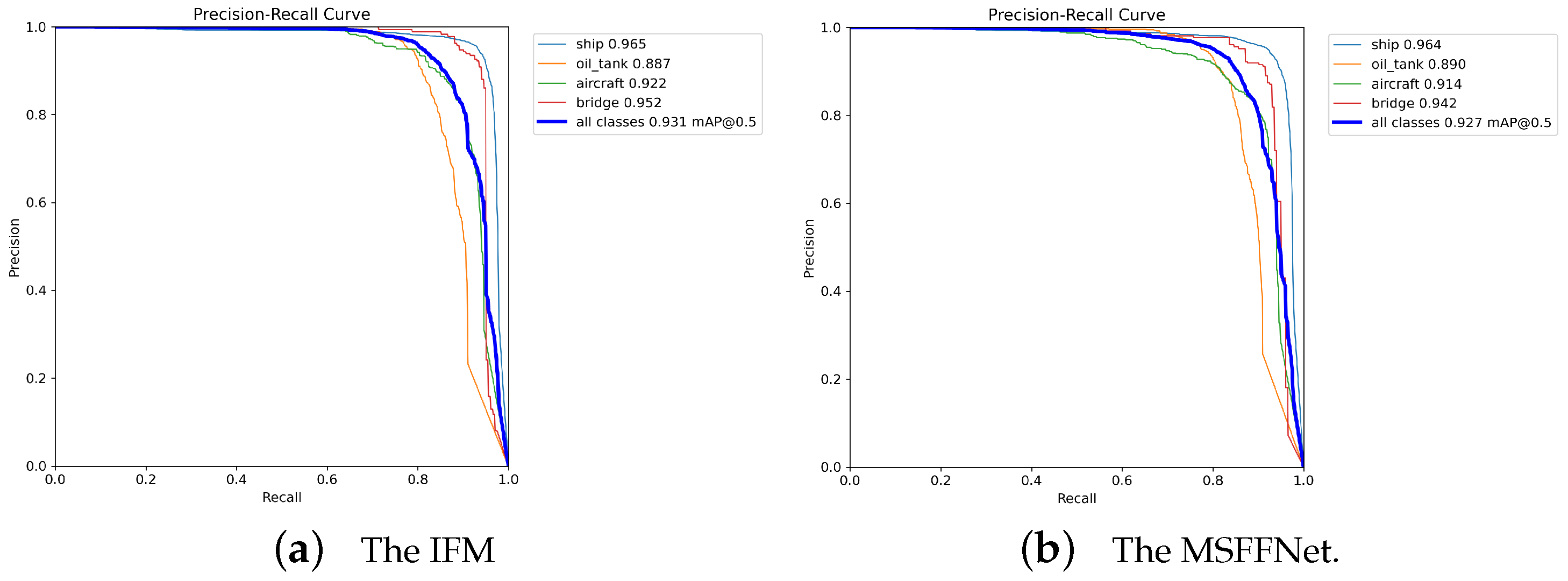
4.3.2. Influence of MSFFNet on the Experimental Results
4.3.3. Influence of IFM on the Experimental Results
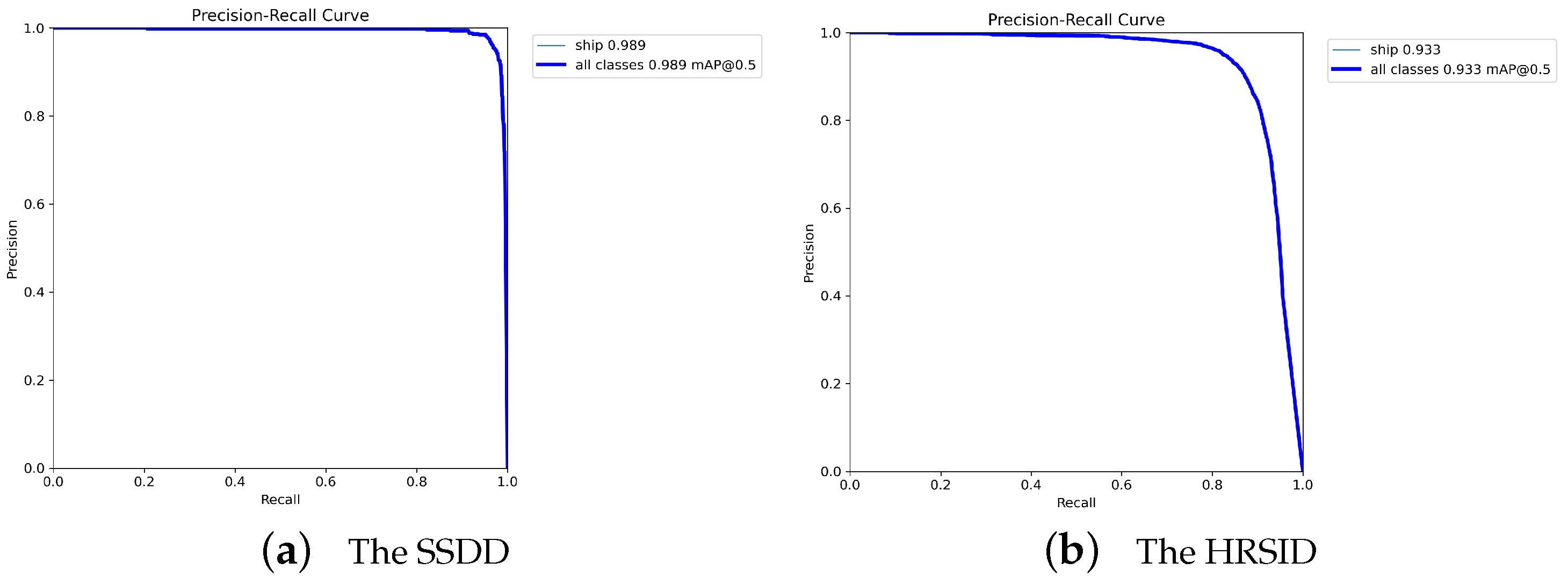
4.4. Experiments on SSDD and HRSID Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, X.; Bai, Y.; Liu, G.; Zhang, P. YOLO-Lite: An Efficient Lightweight Network for SAR Ship Detection. Remote Sens. 2023, 15, 3771. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Qu, L.; Cai, J.; Fang, J. A Spatial Cross-Scale Attention Network and Global Average Accuracy Loss for SAR Ship Detection. Remote Sens. 2023, 15, 350. [Google Scholar] [CrossRef]
- Liu, C.; Chen, Z.; Shao, Y.; Chen, J.; Hasi, T.; Pan, H. Research Advances of SAR Remote Sensing for Agriculture Applications: A Review. J. Integr. Agric. 2019, 18, 506–525. [Google Scholar] [CrossRef]
- Yang, B.; Zhang, H. A CFAR Algorithm Based on Monte Carlo Method for Millimeter-Wave Radar Road Traffic Target Detection. Remote Sens. 2022, 14, 1779. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, P.; Li, Y.; Ding, B. A New Deep Neural Network Based on SwinT-FRM-ShipNet for SAR Ship Detection in Complex Near-Shore and Offshore Environments. Remote Sens. 2023, 15, 5780. [Google Scholar] [CrossRef]
- Conte, E.; De Maio, A.; Galdi, C. CFAR Detection of Multidimensional Signals: An Invariant Approach. IEEE Trans. Signal Process. 2003, 51, 142–151. [Google Scholar] [CrossRef]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P. Manifold Adaptation for Constant False Alarm Rate Ship Detection in South African Oceans. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3329–3337. [Google Scholar] [CrossRef]
- Qin, X.; Zhou, S.; Zou, H.; Gao, G. A CFAR Detection Algorithm for Generalized Gamma Distributed Background in High-Resolution SAR Images. IEEE Geosci. Remote Sens. Lett. 2013, 10, 806–810. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Int. Conf. Comput. Vis. 2018, 42, 318–327. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, W.; Zhang, Z.; Yu, W. A Coupled Convolutional Neural Network for Small and Densely Clustered Ship Detection in SAR Images. Sci. China Inf. Sci. 2018, 62, 42301. [Google Scholar] [CrossRef]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Jiang, J.; Fu, X.; Qin, R.; Wang, X.; Ma, Z. High-Speed Lightweight Ship Detection Algorithm Based on YOLO-V4 for Three-Channels RGB SAR Image. Remote Sens. 2021, 13, 1909. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, T.; Tong, X.; Zhang, Y.; Jiang, S.; Zhou, R.; Han, Y.; Wang, J.; Yang, S.; Liu, S. Multi-Scale Ship Detection From SAR and Optical Imagery Via A More Accurate YOLOv3. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6083–6101. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Zhang, T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship Detection in SAR Images Based on Multi-Scale Feature Extraction and Adaptive Feature Fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Liu, S. BANet: A Balance Attention Network for Anchor-Free Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Tang, L.; Tang, W.; Qu, X.; Han, Y.; Wang, W.; Zhao, B. A Scale-Aware Pyramid Network for Multi-Scale Object Detection in SAR Images. Remote Sens. 2022, 14, 973. [Google Scholar] [CrossRef]
- Miao, T.; Zeng, H.; Yang, W.; Chu, B.; Zou, F.; Ren, W.; Chen, J. An Improved Lightweight RetinaNet for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4667–4679. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, Z.; Guo, W.; Luo, Y. An Automatic Ship Detection Method Adapting to Different Satellites SAR Images With Feature Alignment and Compensation Loss. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, J.; Huang, Z.; Wan, H.; Xia, R.; Wu, B.; Sun, L.; Xing, M. A Lightweight Position-Enhanced Anchor-Free Algorithm for SAR Ship Detection. Remote Sens. 2022, 14, 1908. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Zhao, W.; Wang, X.; Li, G.; He, Y. Frequency-Adaptive Learning for SAR Ship Detection in Clutter Scenes. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Zhou, Y.; Fu, K.; Han, B.; Yang, J.; Pan, Z.; Hu, Y.; Yin, D. D-MFPN: A Doppler Feature Matrix Fused with a Multilayer Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2023, 15, 626. [Google Scholar] [CrossRef]
- Wang, H.; Han, D.; Cui, M.; Chen, C. NAS-YOLOX: A SAR Ship Detection Using Neural Architecture Search and Multi-Scale Attention. Connect. Sci. 2023, 35, 1–32. [Google Scholar] [CrossRef]
- Tang, G.; Zhao, H.; Claramunt, C.; Zhu, W.; Wang, S.; Wang, Y.; Ding, Y. PPA-Net: Pyramid Pooling Attention Network for Multi-Scale Ship Detection in SAR Images. Remote Sens. 2023, 15, 2855. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv8. Available online: https://github.com/ultralytics/ultralytics?tab=readme-ov-file (accessed on 7 March 2024).
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops (ICCVW), Seoul, Republic of Korea, 27–29 October 2019. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ding, X.; Zhang, Y.; Ge, Y.; Zhao, S.; Song, L.; Yue, X.; Shan, Y. UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition. arXiv 2021, arXiv:2311.15599. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. Adv. Neural Inf. Process. Syst. 2024, 36, 51094–51112. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Xia, R.; Chen, J.; Huang, Z.; Wan, H.; Wu, B.; Sun, L.; Yao, B.; Xiang, H.; Xing, M. CRTransSar: A Visual Transformer Based on Contextual Joint Representation Learning for SAR Ship Detection. Remote Sens. 2022, 14, 1488. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement 2018. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 March 2024).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–21 June 2023; pp. 7464–7475. [Google Scholar]
- Zhou, Z.; Chen, J.; Huang, Z.; Lv, J.; Song, J.; Luo, H.; Wu, B.; Li, Y.; Diniz, P.S.R. HRLE-SARDet: A Lightweight SAR Target Detection Algorithm Based on Hybrid Representation Learning Enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5203922. [Google Scholar] [CrossRef]
- Chang, H.; Fu, X.; Dong, J.; Liu, J.; Zhou, Z. MLSDNet: Multiclass Lightweight SAR Detection Network Based on Adaptive Scale Distribution Attention. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Du, W.; Chen, J.; Zhang, C.; Zhao, P.; Wan, H.; Zhou, Z.; Cao, Y.; Huang, Z.; Li, Y.; Wu, B. SARNas: A Hardware-Aware SAR Target Detection Algorithm via Multiobjective Neural Architecture Search. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Cheng, P.; Yu, Z.; Yu, L.; Chi, C. A Survey on Deep-Learning-Based Real-Time SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3218–3247. [Google Scholar] [CrossRef]
- Feng, K.; Lun, L.; Wang, X.; Cui, X. LRTransDet: A Real-Time SAR Ship-Detection Network with Lightweight ViT and Multi-Scale Feature Fusion. Remote Sens. 2023, 15, 5309. [Google Scholar] [CrossRef]
- Gao, S.; Liu, J.M.; Miao, Y.H.; He, Z.J. A High-Effective Implementation of Ship Detector for SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Details | MSAR-1.0 | SSDD | HRSID |
|---|---|---|---|
| Satellite | HISEA-1 | RadarSat-2, TerraSAR-X, Sentinel-1 | Sentinel-1B, TerraSAR-X, TanDEM |
| Polarization | HH, VV, HV, VH | HH, VV, HV, VH | HH, HV, VV |
| Images size (pixel2) | 2048 × 2048, 1024 × 1024, 512 × 512, 256 × 256 | 217 × 214–526 × 646 | 800 × 800 |
| Number of images | 28,449 | 1160 | 5604 |
| Number of class | 4 | 1 | 1 |
| Class | aircraft, ship, bridge, oil tank | ship | ship |
| Item | Description |
|---|---|
| Operating System | Ubuntu 18.04.6 |
| CUDA and CUDAVersion | CUDA12.0 + CUDANN11.3 |
| Python | 3.9.16 |
| Torch | 1.10.1 |
| Epoch | 300 |
| Batch size | 16 |
| Learning rate | 0.007 |
| Momentum | 0.937 |
| Optimizer | SGD |
| Baseline | LRFB | IFM | MSFFNET | Params (M) | FLOPs ( G) | P (%) | mAP (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|---|---|---|
| ✓ | × | × | × | 3.15 | 8.9 | 92.2 | 91.9 | 94.0 | 89.0 |
| ✓ | × | × | ✓ | 3.29 | 10.3 | 89.6 | 92.7 | 95.0 | 89.0 |
| ✓ | × | ✓ | ✓ | 4.01 | 11.9 | 92.7 | 93.1 | 95.0 | 90.0 |
| ✓ | ✓ | ✓ | ✓ | 4.36 | 12.6 | 93.7 | 95.2 | 96.0 | 92.0 |
| Method | Paramas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| RetinaNet [10] | 55.38 | 176 | 51.1 |
| YOLOv3 [47] | 61.52 | 154.6 | 78.2 |
| Tood [48] | 32.0 | 180 | 80.3 |
| YOLOv5m [49] | 20.85 | 47.9 | 94.7 |
| YOLOX-s [50] | 8.94 | 13.32 | 87.4 |
| YOLOv7-tiny [51] | 6.2 | 3.5 | 90.7 |
| YOLOv8s [31] | 11.17 | 28.8 | 95.54 |
| LRMSNet | 4.36 | 12.6 | 95.2 |
| Method | Paramas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| HRLE-SARDet [52] | 1.09 | 2.5 | 88.4 |
| MLSDNet [53] | 0.9 | 1.4 | 93.0 |
| SAR-Nas [54] | 2.21 | 5.10 | 91.8 |
| LRMSNet | 4.36 | 12.6 | 95.2 |
| LRFB | Params (M) | FLOPs (G) | P (%) | mAP (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| × | 3.15 | 8.9 | 90.0 | 89.2 | 91.0 | 87.0 |
| ✓ | 3.65 | 10.1 | 89.4 | 89.7 | 92.0 | 87.0 |
| MSFFNet | Params (M) | FLOPs (G) | P (%) | mAP (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| × | 3.15 | 8.9 | 92.2 | 91.9 | 94.0 | 89.0 |
| ✓ | 3.29 | 10.3 | 89.6 | 92.7 | 95.0 | 89.0 |
| IFM | Params (M) | FLOPs (G) | P (%) | mAP (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|---|
| × | 3.29 | 10.3 | 89.6 | 92.7 | 95.0 | 89.0 |
| ✓ | 4.01 | 11.9 | 92.7 | 93.1 | 95.0 | 90.0 |
| Method | Paramas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| RetinaNet [10] | 55.38 | 176 | 97.2 |
| YOLOv3 [47] | 61.52 | 49.85 | 94.7 |
| YOLOX-s [50] | 8.94 | 13.32 | 94.6 |
| Tood [48] | 32.0 | 180 | 95.7 |
| YOLOv5m [49] | 20.85 | 48.2 | 98.6 |
| LRTransDet [56] | 3.07 | 3.85 | 97.8 |
| HRLE-SARDet [52] | 1.09 | 2.5 | 98.4 |
| SAR-Nas [54] | 1.99 | 2.4 | 98.5 |
| LRMSNet | 4.36 | 12.6 | 98.9 |
| Method | Paramas (M) | FLOPs (G) | mAP (%) |
|---|---|---|---|
| RetinaNet [10] | 55.38 | 176 | 86.4 |
| YOLOv3 [47] | 61.52 | 49.85 | 90.2 |
| YOLOX-s [50] | 8.94 | 13.32 | 89.7 |
| Tood [48] | 32.0 | 180 | 89.3 |
| YOLOv5s [49] | 7.02 | 15.9 | 92.7 |
| SAR-Net [57] | 42.6 | 104.2 | 87.5 |
| HRLE-SARDet [52] | 1.09 | 2.5 | 92.5 |
| SAR-Nas [54] | 1.99 | 2.4 | 92.8 |
| LRMSNet | 4.36 | 12.6 | 93.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Sang, H.; Zhang, Z.; Guo, W. LRMSNet: A New Lightweight Detection Algorithm for Multi-Scale SAR Objects. Remote Sens. 2024, 16, 2082. https://doi.org/10.3390/rs16122082
Wu H, Sang H, Zhang Z, Guo W. LRMSNet: A New Lightweight Detection Algorithm for Multi-Scale SAR Objects. Remote Sensing. 2024; 16(12):2082. https://doi.org/10.3390/rs16122082
Chicago/Turabian StyleWu, Hailang, Hanbo Sang, Zenghui Zhang, and Weiwei Guo. 2024. "LRMSNet: A New Lightweight Detection Algorithm for Multi-Scale SAR Objects" Remote Sensing 16, no. 12: 2082. https://doi.org/10.3390/rs16122082
APA StyleWu, H., Sang, H., Zhang, Z., & Guo, W. (2024). LRMSNet: A New Lightweight Detection Algorithm for Multi-Scale SAR Objects. Remote Sensing, 16(12), 2082. https://doi.org/10.3390/rs16122082