1. Introduction
Remote sensing images encompass imagery captured from a distance by sensors or instruments mounted on various platforms such as satellites, aircraft, drones, and other vehicles. These images serve to gather information about the Earth’s surface, atmosphere, and other objects or phenomena without requiring direct physical contact [
1]. There are two main types of remote sensing images: aerial and satellite. Both aerial and satellite images are valuable sources of data, but they differ in how they collect data and their characteristics [
2]. Satellites travel around Earth, collecting data from large areas at regular intervals. This provides a broad view of the entire planet. Aerial images are captured from airplanes or drones flying closer to the ground. They cover smaller areas but with much finer detail, making them ideal for studying specific locations. The choice between aerial and satellite imagery depends on the specific needs of the application at hand, such as the level of detail required and the availability of data [
3].
The recent surge in sophisticated machine learning techniques, coupled with the ever-growing availability of remote sensing data, has significantly empowered image analysis and interpretation [
4,
5,
6,
7]. Semantic segmentation, a technique that assigns a specific class/annotation/label to each pixel in an image, has become a major research focus for remote sensing imagery [
3]. This approach allows for a highly detailed analysis of ground objects and their spatial relationships. Unlike object detection, which focuses on identifying and roughly locating objects, semantic segmentation provides fine-grained pixel-level identification, enabling a deeper understanding of the image’s content [
8,
9,
10]. Semantic segmentation in remote sensing has far-reaching implications across various domains, such as urban planning [
11,
12,
13], disaster management [
14,
15,
16], environmental monitoring, and precision agriculture [
17,
18,
19,
20].
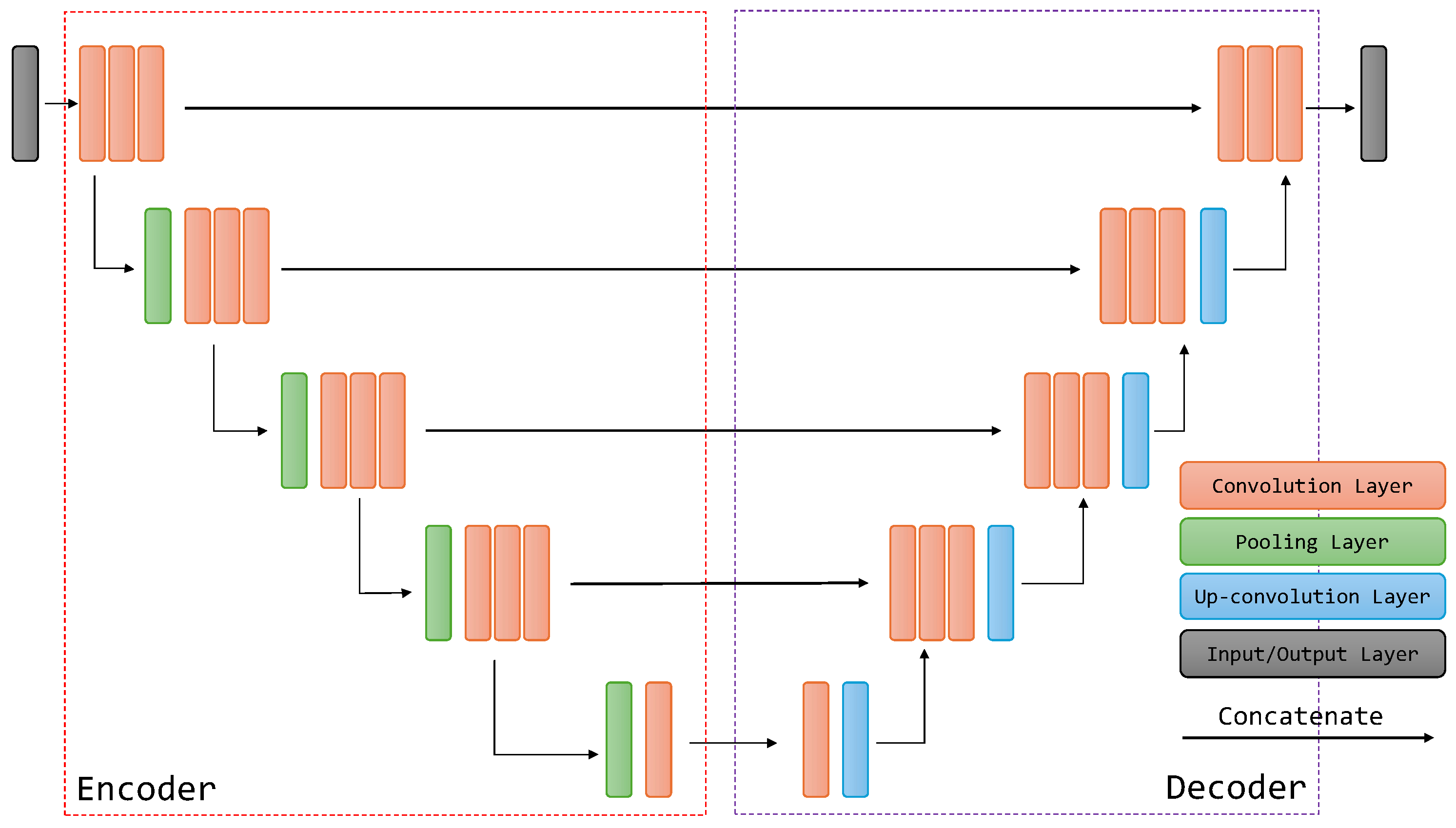
The emergence of deep learning, particularly convolutional neural networks (CNNs) and fully convolutional networks (FCNs), revolutionized the field of semantic segmentation by enabling the automatic learning of hierarchical representations from data [
21]. Methods based on FCNs in combination with encoder–decoder architectures have become the dominant approach for semantic segmentation. Early methods utilized a series of successive convolutions followed by spatial pooling to achieve dense predictions [
22]. Subsequent approaches, for example, U-Net [
23] and SegNet [
24], employed upsampling of high-level feature maps combined with low-level ones during decoding, aiming to capture global context and restore precise object boundaries. To enhance the receptive field of convolutions in initial layers, various techniques such as DeepLab [
25] introduced dilated or atrous convolutions. Subsequent advancements integrated spatial pyramid pooling to capture multiscale contextual details in higher layers, as seen in models like PSPNet [
26] and UperNet [
27]. Incorporating these advancements, including atrous spatial pyramid pooling, DeepLabV3+ introduced a straightforward yet efficient encoder–decoder FCN architecture [
28]. Subsequent developments, such as those seen in PSANet [
29] and DRANet [
30], replaced traditional pooling with attention mechanisms atop encoder feature maps to better grasp long-range dependencies.
Most recently, the adoption of transformer architectures, which utilize self-attention mechanisms and capture long-range dependencies, has marked additional advancement in semantic segmentation [
31]. Transformer encoder–decoder architectures like Segmenter [
32], SegFormer [
33], and MaskFormer [
34] harness transformers to enhance performance. Segmenter, a transformer encoder–decoder architecture designed for semantic image segmentation, utilizes a vision transformer (ViT) backbone and incorporates a mask decoder. SegFormer is a semantic segmentation framework that combines mix transformer encoders with lightweight multilayer perceptron (MLP) decoders, offering a simple, efficient, yet powerful solution. MaskFormer is a versatile semantic segmentation architecture inspired by DEtection TRansformer (DETR) [
35]. It employs a transformer decoder to generate masks for individual objects in an image, utilizing a single decoder for various segmentation tasks. In response to the constraints of MaskFormer, Mask2Former was developed, featuring a multiscale decoder and a masked attention mechanism [
36].
Despite the advancements in deep learning and semantic segmentation techniques, accurately segmenting remote sensing images remains a challenging task due to factors like complex spatial structures, diverse object sizes, data imbalance, and high background complexity [
3]. Remote sensing images can have a wide range of resolutions and object orientations, posing challenges for consistent segmentation. Objects within a single image can vary dramatically in size. Buildings might stand tall next to tiny patches of vegetation. Effective models need to handle this wide spectrum of scales and accurately segment objects regardless of their relative size. Densely packed objects (like urban buildings) or very small objects (like individual trees) can be difficult for models to identify and segment accurately. Certain classes within a remote sensing image might be under-represented compared to others. For example, rare land cover types might have far fewer pixels compared to common vegetation classes. This data imbalance can make it difficult for models to learn accurate representations of all classes and lead to biased segmentation results. The foreground (objects of interest) might occupy a much smaller area compared to the background, making segmentation lopsided. Moreover, backgrounds in aerial images can be intricate and cluttered (e.g., urban environments), further complicating object segmentation [
37].
In the context of semantic segmentation of remote sensing images, several approaches were proposed to overcome these challenges [
38,
39,
40]. AerialFormer utilizes a hierarchical structure, in which a transformer encoder generates multiscale features, while a multidilated convolutional neural network (MD-CNN) decoder aggregates information from these diverse inputs [
38]. The UNetFormer model incorporates a global–local transformer block (GLTB) within its decoder to construct the output [
39]. Additionally, it utilizes a feature refinement head (FRH) for optimizing the extracted global–local context. For efficiency, the transformer decoder is combined with a lightweight CNN-based encoder. Uncertainty-Aware Network (UANet) introduces the concept of uncertainty and proposes a novel network that leverages this concept [
40]. UANet improves the accuracy of distinguishing building footprints from the complex distribution of surrounding ground objects. These advancements demonstrate the ongoing efforts to improve the semantic segmentation of remote sensing images through innovative deep learning architectures.
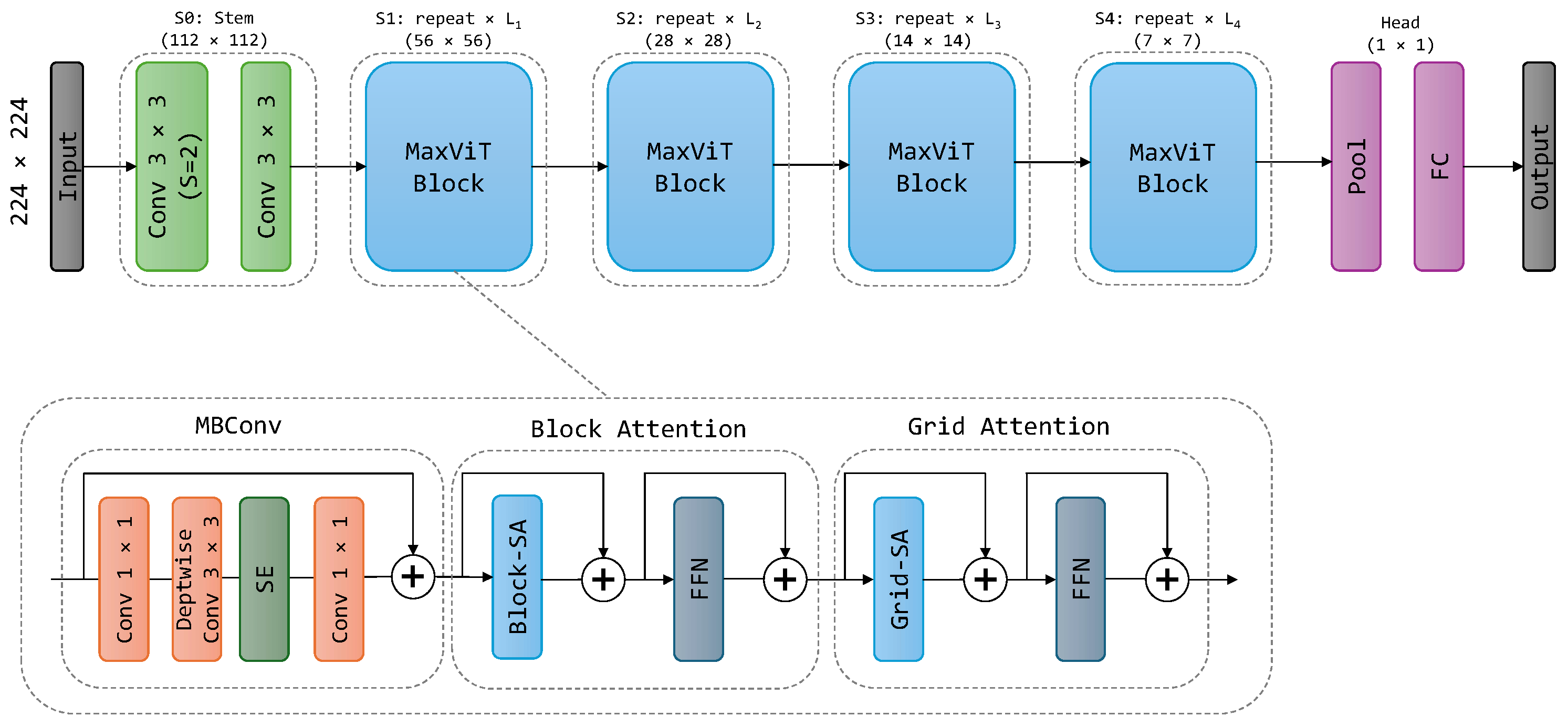
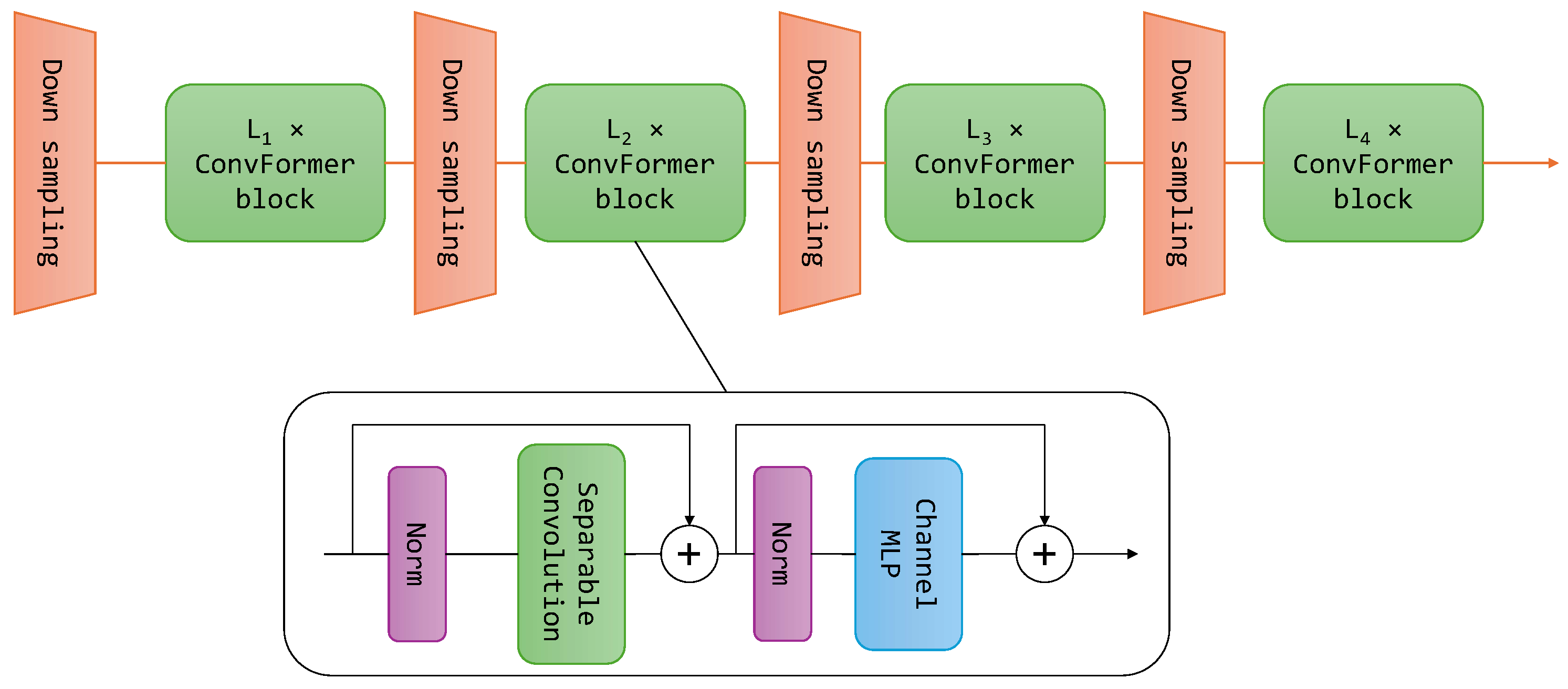
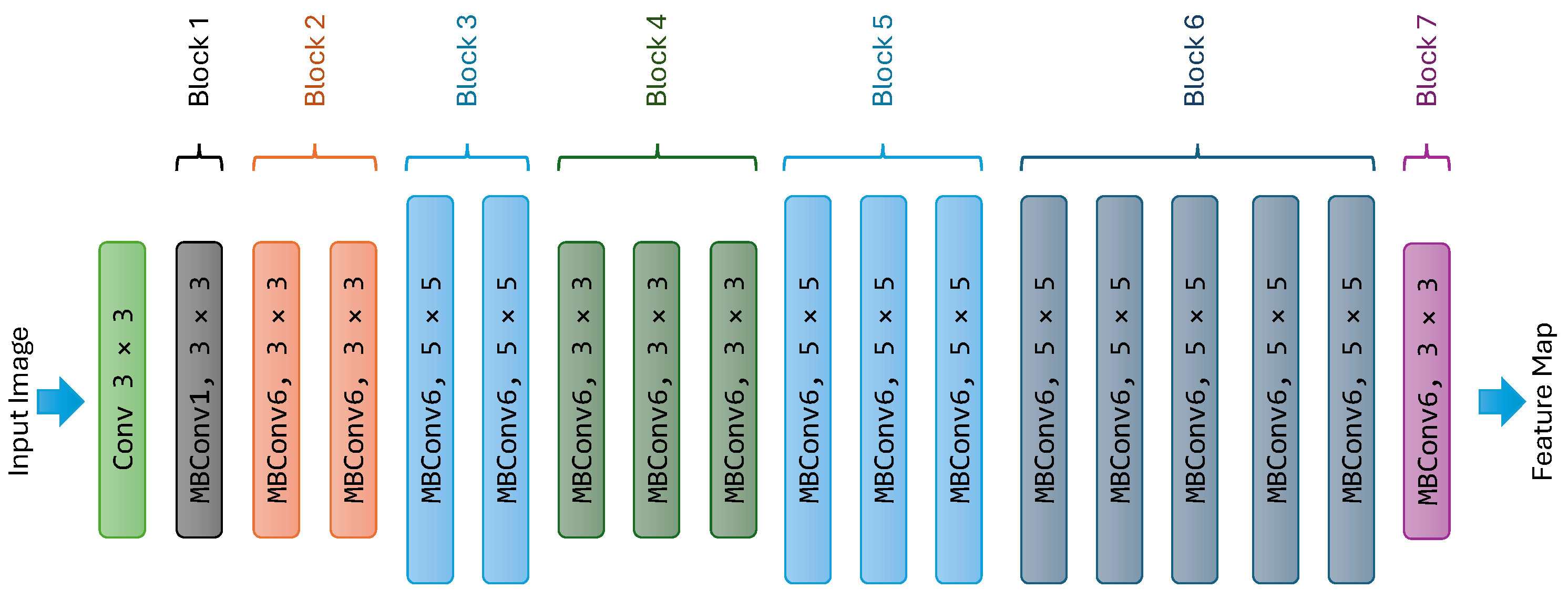
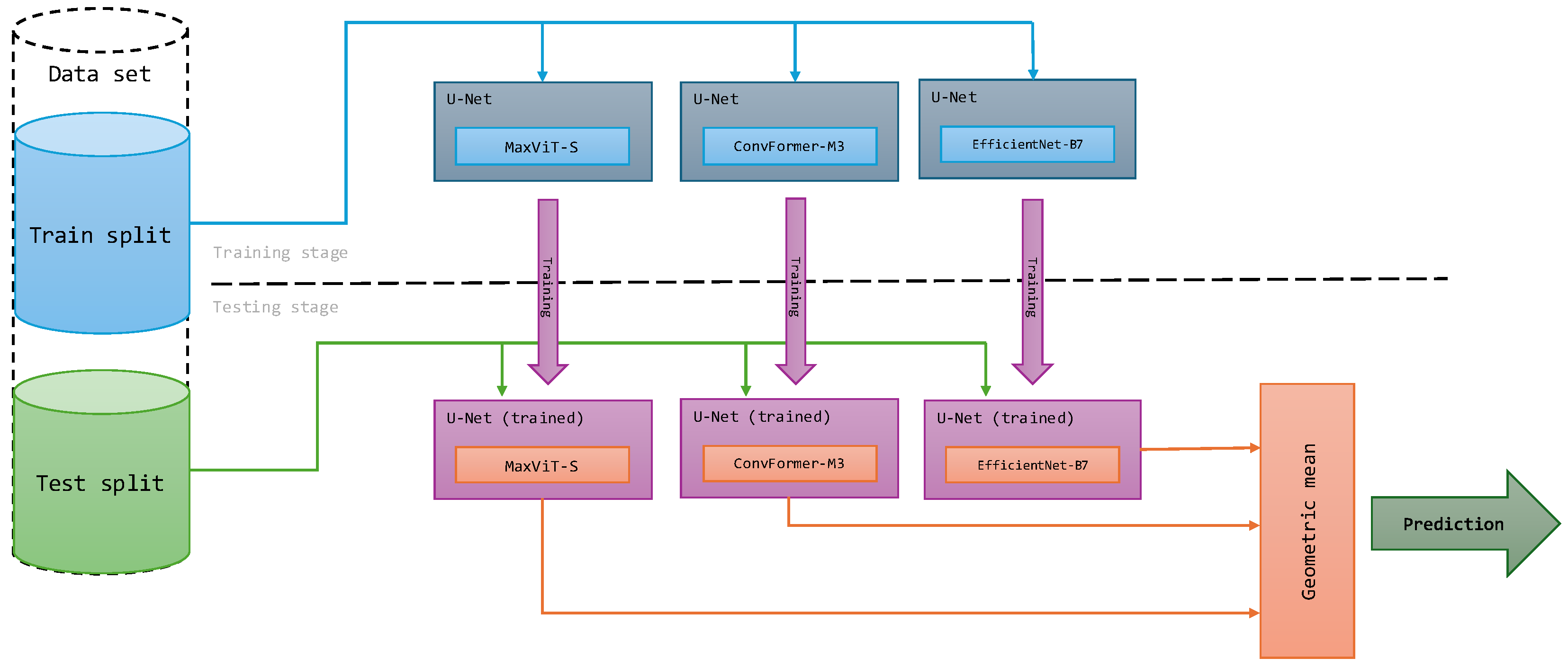
This paper examines the impact of incorporating powerful backbones into the U-Net architecture to potentially improve the semantic segmentation of remote sensing imagery. We leverage three such backbone networks: Multi-Axis Vision Transformer (MaxViT), ConvFormer, and EfficientNet. MaxViT is a hybrid vision transformer architecture, ConvFormer utilizes convolutional layers within a transformer framework, and EfficientNet is a CNN architecture known for its balance between accuracy and computational cost. We further enhance the performance by employing an ensemble learning approach. The diverse backbones within the ensemble extract complementary features from the images, leading to a richer and more comprehensive understanding of the scene. The ensemble benefits from the unique representations learned by each backbone within the U-Net architecture, leading to more robust and accurate segmentation results. To combine the base predictions, we employ a geometric mean ensemble strategy. To this end, we investigate the potential of combining backbones with different strengths to improve U-Net’s performance for remote sensing semantic segmentation tasks. By exploiting the diversity and utilizing a geometric mean ensemble strategy, we managed to achieve state-of-the-art performance over several semantic segmentation datasets for remote sensing imagery. Our research can be summarized by the following primary contributions:
Integration of three strong backbone networks within U-Net: the Multi-Axis Vision Transformer (MaxViT), ConvFormer, and EfficientNet. These models exhibit exceptionally high performance, surpassing previous models with similar model sizes.
Introduction of an ensemble learning approach that leverages the complementary strengths of each backbone, tailored to enhance semantic segmentation of remote sensing imagery. Limiting the ensemble to three base models provides a good balance between performance gains and computational cost.
Conducting of a comprehensive comparison of our approach with existing methods on various remote sensing image datasets. The experimental results show the superior performance of our models. Visual results further validate the effectiveness of our approach by showcasing accurate segmentation maps in remote sensing images.
The subsequent sections of this paper are organized as follows: In
Section 2, we introduce the evaluation datasets, outlining their main characteristics and preprocessing steps. This section also provides insights into the selected backbones and how they are integrated into the ensemble. Additionally,
Section 2 elaborates on the experimental setup employed for conducting the experiments. Moving on to
Section 3, we present and summarize the obtained results, with detailed analyses and discussions provided. Finally,
Section 4 offers concluding remarks.
3. Results and Discussion
The summarized results of the base U-Net models and the ensemble models across the different evaluation datasets are shown in
Table 2. We report the mean intersection over union (%) and also report the rank of the models, averaged over the respective datasets. For the INRIA dataset, the provided metric is the intersection over union (%) specifically for the building label, which is a common practice in building extraction [
40]. Notably, the U-Net ensemble models ranked the best overall and achieved the best performance on six (out of the six) tasks/datasets. Among the base models, those utilizing MaxViT-S as a backbone ranked second, closely followed by the U-Net models with EfficientNet-B7 as a backbone. While the U-Net models featuring the ConvFormer-M36 backbone ranked last, they demonstrated comparable performance across all datasets.
The ensemble models consistently outperform across all datasets. For the LoveDA dataset, the achieved mIoU stands at 57.36%, marking the best result and securing the top rank on the publicly available leaderboard of the LoveDA semantic segmentation challenge. Similarly, for the UAVid dataset, the mIoU reaches 73.34%, which also represents the best reported result to date for this dataset. For the LandCover.ai datasets, the ensemble surpasses all previously reported results, achieving mIoU values of 88.02%. We analyzed the segmentation performance on the Potsdam dataset in two cases, with and without clutter (background). The label clutter is the most challenging as it can contain anything except for the five main labels defined for this dataset. Our U-Net ensemble stands out as a robust segmentation model, achieving top performance in both scenarios, with and without clutter, boasting mIoU values of 80.82% and 89.9%, respectively. Moreover, the obtained IoU value of 81.43% for the INRIA dataset aligns with the best-performing methods and reported results observed on the contest platform hosted by the dataset creators. These results strongly validate the effectiveness of our proposed ensemble approach in enhancing semantic segmentation performance on remote sensing imagery.
Table 3 presents the performance of various backbone combinations on the selected semantic segmentation datasets. While all combinations outperform the base models, the ensemble utilizing all three backbones (MaxViT, ConvFormer, EfficientNet) consistently achieves the best results.
Having established the overall effectiveness of U-Net models, both base models and ensemble models, we now examine how well they perform on each dataset. This analysis aims to identify the potential strengths and weaknesses of the models across different types of remote sensing imagery and segmentation tasks. Subsequently, we explore any notable observations or patterns based on the performance of each specific dataset. Our analysis includes per-label IoU values, confusion matrices, and sample inference masks for each dataset. These insights will aid in understanding performance fluctuations across different labels or regions within the images (e.g., urban versus rural areas) and pinpoint potential challenges such as data imbalances or complex object shapes. We also present a detailed comparison of our models performance against established methods/models for all considered remote sensing image datasets.
In
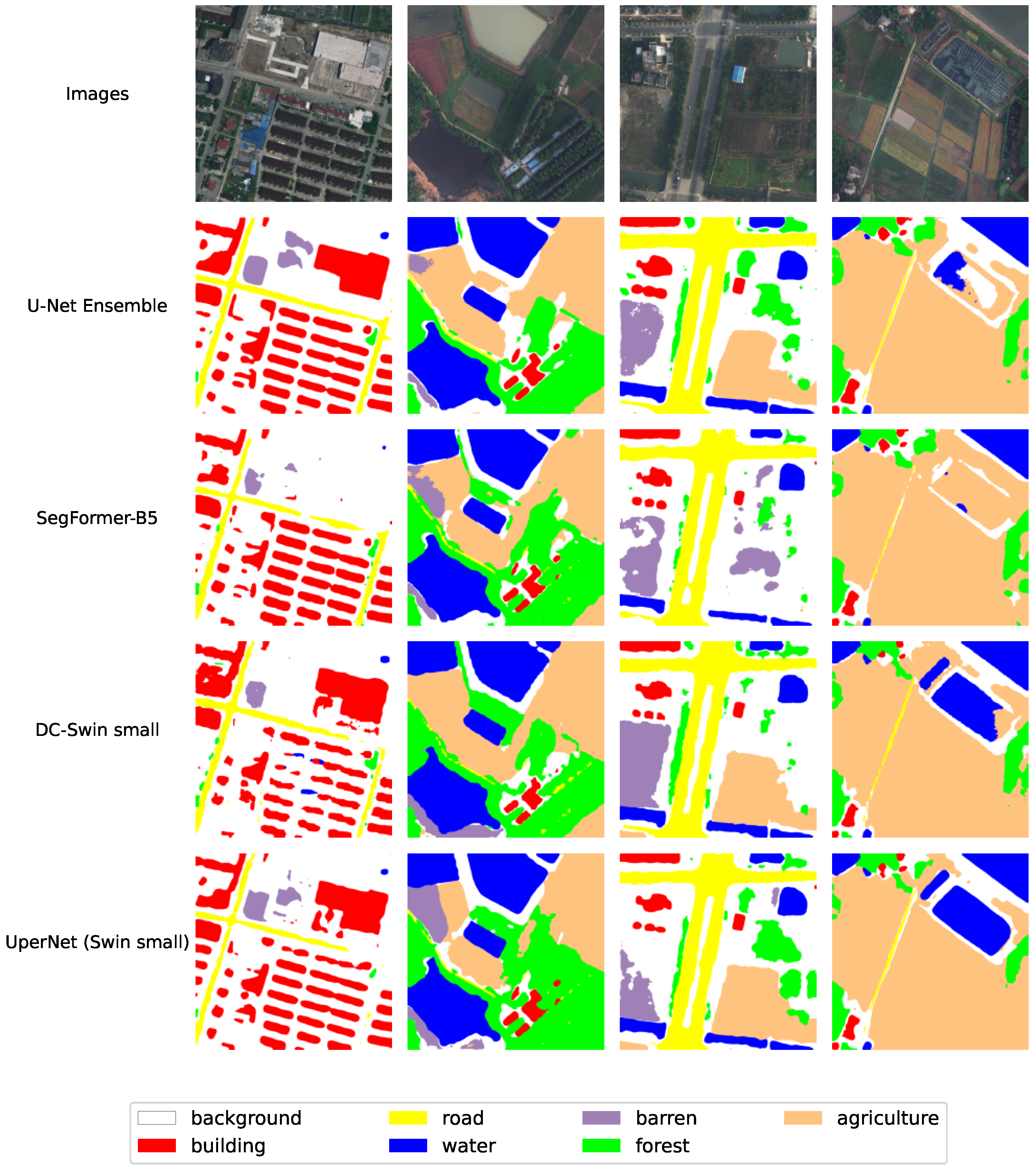
Table 4, we report performance comparisons with existing methods on the test set of the LoveDA dataset. This comparison is based on the IoU metric calculated for each semantic class/label. Our models (base and ensemble) consistently outperform existing state-of-the-art methods. Notably, this includes competitive approaches like AerialFormer-B [
38], DC-Swin [
65], multitask pretraining using the InternImage-XL model [
66], UperNet (Swin small) [
27], and the foundation model trained with UperNet and a vision transformer as a backbone [
67]. To explore the impact of encoder selection on performance, we compared our trained U-Net models to a variant equipped with a ResNet50 encoder. The U-Net model with a ResNet50 encoder achieves an mIoU value of 47.84%. Our U-Net models demonstrate significant improvements: the MaxViT backbone outperforms this result by 8.32% in mIoU, the ConvFormer by 6.96%, and EfficientNet by 7.23%. This demonstrates the effectiveness of our backbone selection.
The top-performing model is the U-Net ensemble, achieving an mIoU value of 57.36%, marking a substantial improvement of 2.81% over existing state-of-the-art methods. This result also secures the highest rank on the publicly available leaderboard of the LoveDA semantic segmentation challenge. Notably, the U-Net ensemble outperforms the existing methods by 2.33% IoU for the road label, 2.26% IoU for the barren label, 1.39% IoU for the forest label, 1.82% IoU for the agriculture label, 0.11% IoU for the water label, and 1.29% IoU for the background label. The U-Net ensemble model exhibits a lower IoU value only for the building label, with a decrease of 1.48% compared to existing methods.
A confusion matrix was not calculated for this dataset as the ground-truth masks for the test images are not publicly accessible.
Figure 6 displays sample images alongside the inference masks generated by the U-Net ensemble, the best-performing model, and other models for comparison. The mIoU value of 57.36% for this dataset indicates its high level of difficulty. The regions labeled as background exhibit significant intraclass variance due to the complexity of the scenes, leading to substantial false alarms. Identifying small-scale objects like buildings and scattered trees poses challenges. Additionally, distinguishing between forest and agricultural labels is difficult due to their similar spectra. However, the water label achieves the highest IoU value, suggesting good recognition performance for this label.
Table 5 presents a performance comparison of the UAVid dataset test set, evaluated using the intersection over union (IoU) metric for each semantic class/label. Our ensemble model surpasses existing state-of-the-art methods such as EMNet [
68], DCDNet [
69], and UperNet (Swin small) [
27], while our base U-Net models achieve competitive results. We investigated the influence of encoder selection on performance by comparing our U-Net models to a variant equipped with a ResNet50 encoder. This baseline U-Net achieved an mIoU value of 67.22%. However, even stronger results were obtained by employing more powerful backbones within the U-Net architecture. The MaxViT backbone significantly outperformed the ResNet50 by 4.66% in mIoU, while ConvFormer and EfficientNet also achieved improvements of 3.57% and 4.2%, respectively. These findings demonstrate the effectiveness of our backbone selection strategy in boosting U-Net’s performance for remote sensing semantic segmentation tasks. Our top-performing U-Net ensemble achieves a state-of-the-art mIoU of 73.34%, exceeding the methods presented in
Table 5 and the best results of 73.21% mIoU from the public UAVid competition,
https://competitions.codalab.org/competitions/25224 (accessed on 5 June 2024).
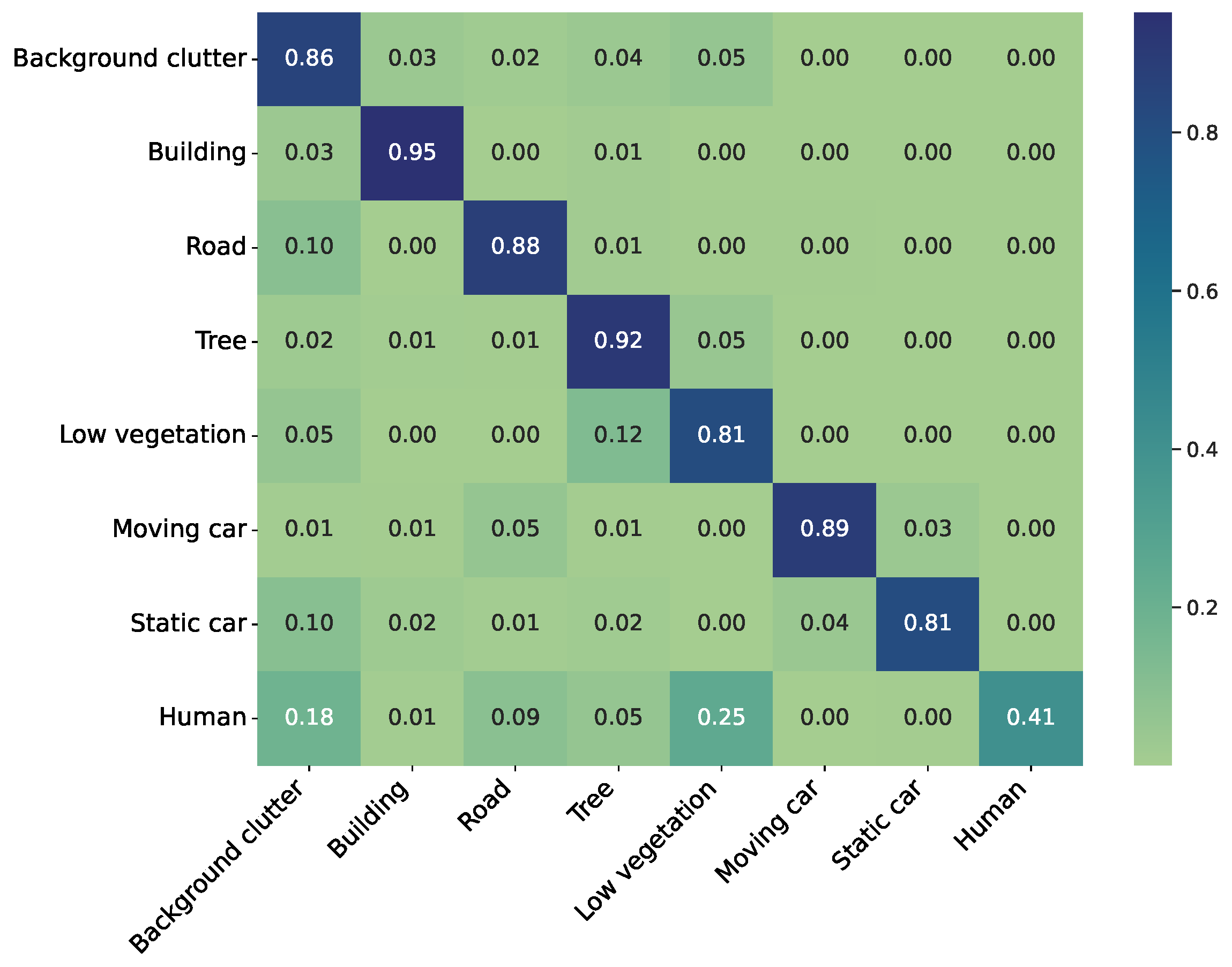
Examining the IoU values, it becomes evident that the most accurate predictions are achieved for the building label. Moreover, satisfactory results are obtained for the road, tree, and moving car labels. The label human exhibits the lowest performance. The confusion matrix calculated for the U-Net ensemble as the best-performing model is visualized in
Figure 7. The confusion matrix reveals the frequent misclassifications by the model. Notably, it tends to confuse the labels moving car and static car, as well as tree and low vegetation. This is rather expected given the semantic similarity between these labels. Additionally, there is a tendency to misclassify the human label as the low vegetation label, likely a result of pixel overlap between these two labels. There are misclassifications with the background clutter label for nearly all labels, as expected. This is because diverse objects and regions not belonging to any specific label are designated with the background clutter label.
Figure 8 shows example images and ground-truth masks from the UAVid dataset. Additionally, it presents the inference masks generated by the U-Net ensemble model. Despite the high scene complexity, characterized by the number of objects and varied object configurations in the UAVid dataset, the U-Net ensemble model demonstrates excellent performance.
Figure 9 showcases a cropped region of an example image along with its corresponding ground-truth mask, featuring the labels human and moving cars. The predicted mask, shown as the last image in
Figure 9, is generated by the U-Net ensemble model. A comparison between the ground-truth mask and the predicted mask reveals segments where the model misclassifies moving cars as static cars. In this particular scenario, distinguishing between these two labels is challenging because, for instance, the cars are stationary, waiting at the pedestrian crossing. Additionally, there is a lack of fine-grained segmentation for the human label due to overlapping and dense objects/segments marked with this label in the ground-truth mask.
In
Table 6, we report performance comparisons with existing methods on the test set of the LandCover.ai dataset. This comparison is based on the IoU metric calculated for each semantic class/label. Our models (base and ensemble) consistently outperform existing state-of-the-art methods. Notably, this includes competitive approaches like DC-Swin small [
65], UperNet (Swin small), and SegFormer-B5 [
33]. In the comparison for this dataset, we also included a U-Net model with ResNet50 as the backbone, achieving an mIoU value of 85.66%. Compared to this result, our U-Net models show notable improvements with different backbones: a 1.75% mIoU gain for MaxViT, a 1.98% gain for ConvFormer, and a 1.4% gain for EfficientNet. These results underscore the advantages of our chosen backbones. Our top-performing model is the U-Net ensemble, achieving an mIoU value of 88.02%, marking an improvement of 0.64% over existing state-of-the-art methods.
The IoU values for the labels road and building are lower compared to the other labels. These labels are more challenging in the context of semantic segmentation because they are usually narrow, in the case of roads, or often small, in the case of buildings. Additionally, they are sometimes obscured by other objects, such as trees.
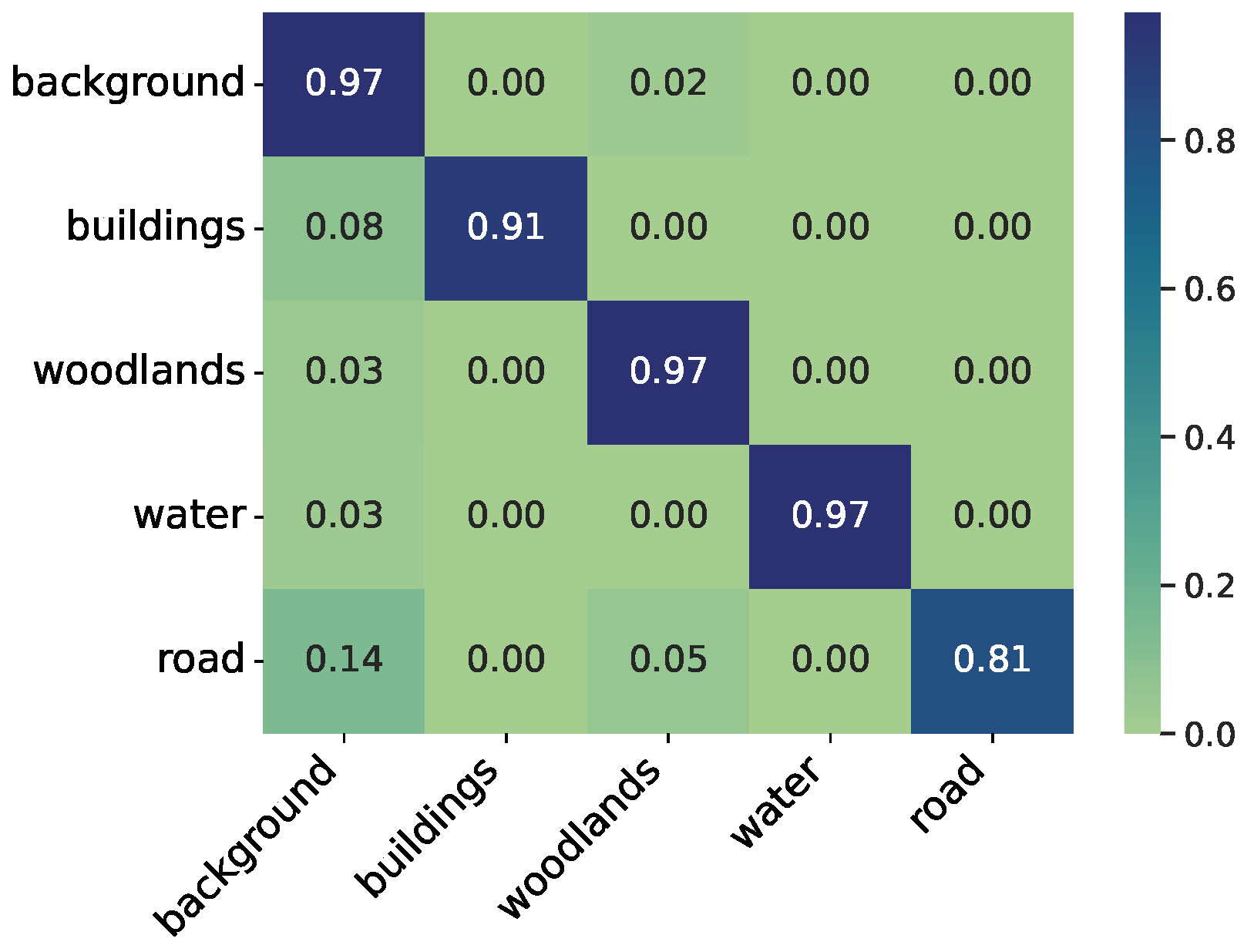
Figure 10 illustrates the confusion matrix for the LandCover.ai dataset calculated for the U-Net ensemble model. The confusion matrix further supports this observation, indicating that the road label is frequently misclassified as woodlands, and in general, all labels exhibit confusion with the background label, as expected due to its diverse composition, which may include fields, grass, or pavement.
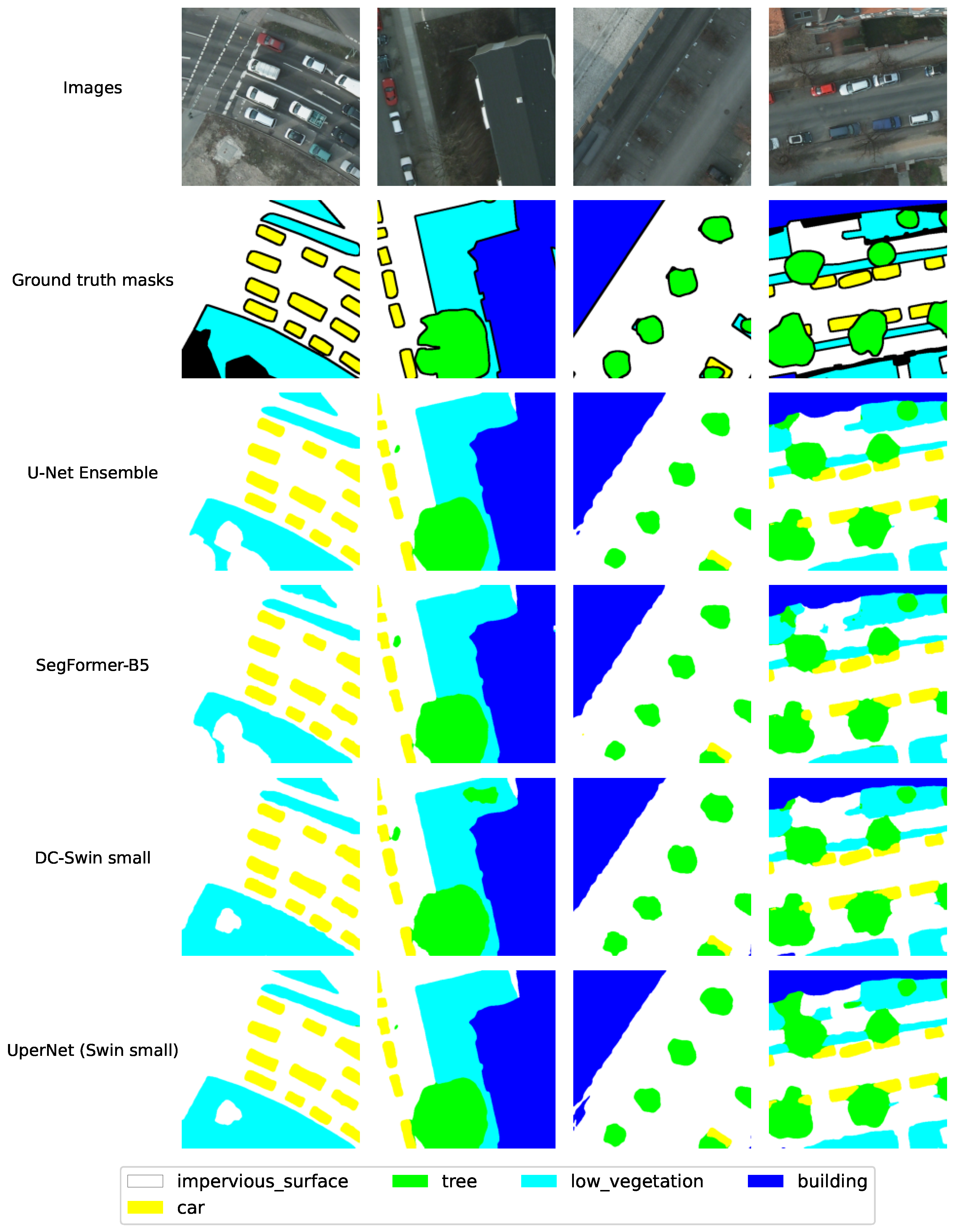
Figure 11 shows example images and ground-truth masks from the LandCover.ai dataset. Additionally, it displays the inference masks generated by the U-Net ensemble, the best-performing model, and other models for comparison. The identified regions within the inference masks typically exhibit smoother boundaries, aligning well with reality, particularly in the context of woodlands and water. However, this smoothness can lead to inaccuracies for buildings, potentially omitting smaller structures and producing slightly less defined/precise building edges/boundaries. Conversely, the model excels at identifying individual trees that might have been missed by human annotators.
We evaluate the segmentation performance on the Potsdam dataset under two conditions: with and without clutter. For this dataset, we report per-label F1 scores, mean F1 scores, and mean intersection over union (IoU). We include F1 scores in this comparison because previous studies on this dataset utilized this metric to assess predictive performance. The results for the two evaluation scenarios are presented in
Table 7 and
Table 8. In this experimental setup, the analysis indicates that U-Net (ConvFormer-M36) and the U-Net ensemble achieved the highest scores in mIoU and mF1 metrics when the clutter label was excluded from consideration. However, when the clutter label was included, U-Net (EfficientNet-B7) and the U-Net ensemble emerge as the top performers. Interestingly, the exclusion of clutter seems to reduce ambiguity among the remaining labels.
Figure 12 shows example images and ground-truth masks from the Potsdam dataset. Additionally, it displays the inference masks generated by the U-Net ensemble, the best-performing model, and other models for comparison. The U-Net ensemble model exhibits remarkable resilience, achieving excellent performance despite the high scene complexity of the Potsdam dataset. The confusion matrices for the Potsdam dataset (with and without clutter) are visualized in
Figure 13. The clutter label in the Potsdam dataset presents a unique challenge as it encompasses anything outside the five main categories. This ambiguity can lead to confusion with labels like impervious_surface, low_vegetation, and building. Excluding the clutter label significantly reduces ambiguity among the remaining labels. This is evident in the F1 values exceeding 90% for all the labels when clutter is ignored. As expected, some confusion persists between tree and low_vegetation labels, likely due to their inherent similarities.
For the INRIA dataset, the provided metric is the intersection over union (%) specifically for the building label, which is a common practice in building extraction [
40]. Our model achieves a competitive IoU value of 81.43% on the building extraction task, even without incorporating postprocessing techniques for boundary refinement. While this aligns with current state-of-the-art results (the highest reported on the contest platform being 81.91%), there is room for further improvement. For instance, the UANet method [
40] achieves an IoU of 83.08% by introducing uncertainty awareness into the network. This allows UANet to maintain high confidence in predictions across diverse scales, complex backgrounds, and various building appearances. As future work, we plan to explore similar uncertainty-handling techniques to potentially boost the performance of our models.
Figure 14 showcases close-ups of the segmentation outcomes on the test set. The U-Net ensemble model adeptly identifies buildings across diverse images, showcasing its capability to detect structures of varying sizes and shapes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}