1. Introduction
Hyperspectral (HS) imaging boasts superior spectral resolution, thereby offering richer spectral information and conferring a unique advantage in surface environmental change detection (CD) [
1,
2]. HS image CD aims to obtain dynamic information on land surface changes by comparing two HS images collected at different times before and after covering the same scene. It generally includes three steps: preprocessing of HS images, application of CD algorithms and evaluation of the results [
3]. Of these, selecting an appropriate CD methodology profoundly influences detection accuracy. Feature extraction and change region identification constitute pivotal stages within CD methodologies. Feature extraction entails extracting pertinent attributes such as the color, texture, and spatial relationships of ground objects, laying a robust groundwork for subsequent analysis. Change region identification focuses on employing algorithms to conduct intricate analysis of extracted features, aiming for precise delineation of changing regions.
Early researchers focused on studying the differences in features. Change vector analysis (CVA) [
4] is a typical algebraic operation CD method, which treats each spectral curve as a vector and achieves CD by calculating the difference between the vectors. Deng et al. [
5] enhanced change information based on principal component analysis (PCA) and combined supervised and unsupervised methods to accurately identify change areas. Celik et al. [
6] used PCA to process data and create feature vector spaces for subsequent CD tasks. Wu et al. [
7] used adaptive cosine estimation to detect the target change regions in stacked images. Erturk et al. [
8] used an HS image CD technique based on spectral unmixing. They compared the abundance differences of the same region in images obtained at different times by using differential operations to identify the regions where changes occurred. Hou et al. [
9] proposed a new method for HS image CD using multi-modal profiles. Traditional methods for HS-CD are characterized by their straightforward implementation and comprehensibility. However, these approaches place stringent requirements on the accuracy of multi-temporal HS image registration. Additionally, they demonstrated the limitations in effectively utilizing both spectral and geometric features, which present challenges in attaining reliable detection accuracy.
Recently, with the continuous progress of deep learning (DL) technology, its application in HS-CD has become a hot research topic, and various DL-based methods have emerged one after another [
10]. Compared with traditional mathematical models limited to extracting superficial features, DL techniques garner considerable interest, owing to their pronounced efficacy in addressing high-dimensional challenges and performing intricate feature extraction. DL approaches inherently discern and assimilate profound semantic insights from image datasets via intricate network structures. In the field of HS-CD, effective implementation not only enhances processing efficiency but also offers robust solutions for the intricate analysis of multi-temporal hyperspectral images [
11]. Wang et al. [
12] proposed a 2D convolutional neural network (CNN) framework (GETNET) which trains deep networks in an unsupervised manner. However, the limitation of this method is that it relies on the pseudo training set generated by other CD methods, which not only increases the complexity of the algorithm but may also affect model accuracy due to the presence of noise. Zhan et al. [
13] proposed a 3D spectral-spatial convolutional network (TDSSC) which extracts image features from three dimensions using three-dimensional convolution. Mostafa et al. [
14] proposed a new CD method which utilizes U-Net neural networks to effectively learn and restore the details of the input images and utilizes attention to highlight key information, thereby effectively determining the region of change. Zhan et al. [
15] proposed a spectral-spatial convolution neural network with a Siamese architecture (SSCNN-S) for HS-CD. Song et al. [
16] integrated iterative active learning and affinity graph learning into a unified framework. They built an HS-CD network based on active learning. In recent years, owing to the widespread adoption of attention mechanisms within computer vision, researchers have naturally extended their application to HS-CD tasks [
17,
18,
19]. Wang et al. [
20] proposed a dual-branch framework based on spatiotemporal joint graph attention and complementary strategies (CSDBF). Song et al. [
21] proposed a new cross-temporal interactive symmetric attention network (CSANet) which can effectively extract and integrate the spatial-spectral temporal joint features of HS images while enhancing the ability to distinguish the features of changes. In addition to CNNs, other network frameworks have also been applied to CD tasks and have achieved certain results, such as the GNN [
22], GRU [
23], and Transformer [
24].
However, extant CD methodologies encounter challenges during the feature extraction phase. Owing to the susceptibility to detail loss during network downsampling, prevailing models struggle to accurately identify intricate spectral characteristics. Moreover, these approaches frequently overlook the incorporation of multi-scale information during feature extraction, thereby impeding satisfactory extraction of local features. HS image has tens to hundreds of bands, and each band contains rich spectral information. Traditional methods exhibit a lack of emphasis on these issues, thereby exerting a certain degree of impact on model performance. To effectively capture the complex spectral features in HS images, it is necessary to combine multi-scale features, comprehensively consider the importance of spectral features, and extract more representative features for CD and analysis.
To this end, we present a multi-scale fusion network based on dynamic spectral features for multi-temporal HS-CD (MsFNet). We proposed a dual-branch network architecture tailored for feature extraction across distinct multi-temporal phases. To accurately capture complex spectral features and consider them at multiple scales, a dynamic convolution module based on a spectral attention mechanism is used to adaptively adjust the features of different bands. Utilizing a multi-scale feature fusion module enhances the model’s capacity for local information perception by amalgamating multi-scale feature extraction and fusion mechanisms. The primary innovations presented in this article can be summarized as follows:
(1) A multi-scale fusion network based on dynamic spectral features for multi-temporal HS-CD (MsFNet) is proposed, which uses a dual-branch network to extract features from multi-temporal phases and fuse them to capture complex spectral features and perceive local information, improving the accuracy of CD.
(2) A spectral dynamic feature extraction module is proposed, which utilizes the dynamic convolution module to dynamically select features. At the same time, the attention module in the original dynamic convolution is improved to achieve adaptive adjustment of features in different bands, making the network more flexible when focusing on important bands.
(3) A multi-scale feature extraction and fusion module is proposed, which effectively solves the problem of losing detailed information in the downsampling process of convolutional networks by considering features at multiple scales and enhances the model’s perception ability of local information.
(4) Experiments are performed on three multi-temporal HS image CD datasets, yielding outcomes which outstrip certain state-of-the-art (SOTA) methods. Findings indicate that the proposed approach demonstrates notable superiority in performance when juxtaposed with contemporary SOTA CD methods.
The structure of the remaining sections is as follows.
Section 2 presents a literature review on multi-temporal remote sensing (RS) image CD based on feature fusion and multi-scale learning.
Section 3 describes the proposed framework and novel modules.
Section 4 delineates the experimental configuration, analysis of results, and ablation experiment, while
Section 5 provides our conclusions.
3. Methodology
3.1. Overall Architecture
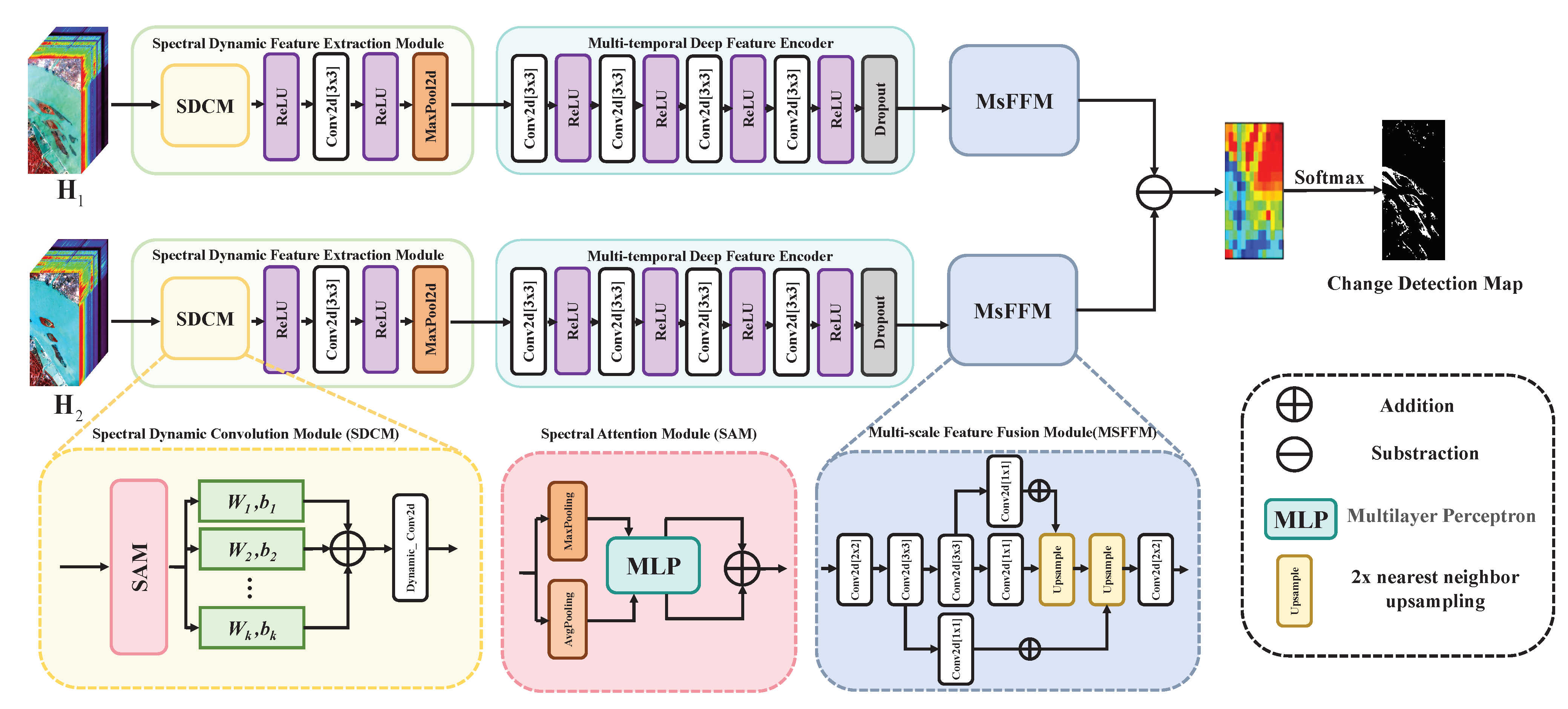
This paper presents a multi-scale fusion network based on dynamic spectral features for multi-temporal HS image CD (MsFNet).
Figure 1 illustrates the complete framework. A spectral dynamic feature extraction module is employed to dynamically adapt the receptive field based on the characteristics of distinct spectral bands. Compared with the attention mechanism employed in the original dynamic convolution, MsFNet prioritizes inter-band relationships through spectral attention. This approach enhances the network’s flexibility in emphasizing critical bands, thereby aiding the model in discerning and distinguishing band-specific changes. Consequently, this refinement bolsters the model’s acuity in perceiving and capturing intricate spectral features within an HS image. Additionally, the multi-scale feature fusion module extracts varied scale features from deep feature maps and integrates them to enrich local information within the feature map, thereby augmenting the model’s capability to perceive local details.
3.2. Spectral Dynamic Feature Extraction Module (SDFEM)
As a novel CNN operator design, the dynamic convolution has a stronger nonlinear representation ability than traditional static convolution [
42]. The latter usually uses a single convolution kernel for each convolution layer, which results in a static computed graph which cannot flexibly adapt to changes in the input data. On the basis of dynamic convolution, a parallel convolution kernel is introduced, and the network realizes flexible adjustment of the convolution parameters through a dynamic aggregation convolution kernel so as to better adapt to different inputs.
HS images encompass multiple bands, with each capturing distinct spectral features with spatially varying characteristics across the dataset. Learning and effectively capturing these complex spectral features are crucial for HS-CD tasks. To address these features, a dynamic convolution module based on spectral attention is proposed, which is integrated into the early stages of the network without increasing its depth. Unlike the attention mechanism in traditional dynamic convolution, this module prioritizes inter-band relationships through spectral attention, thereby enhancing the model’s capacity to perceive and capture intricate spectral nuances [
43].
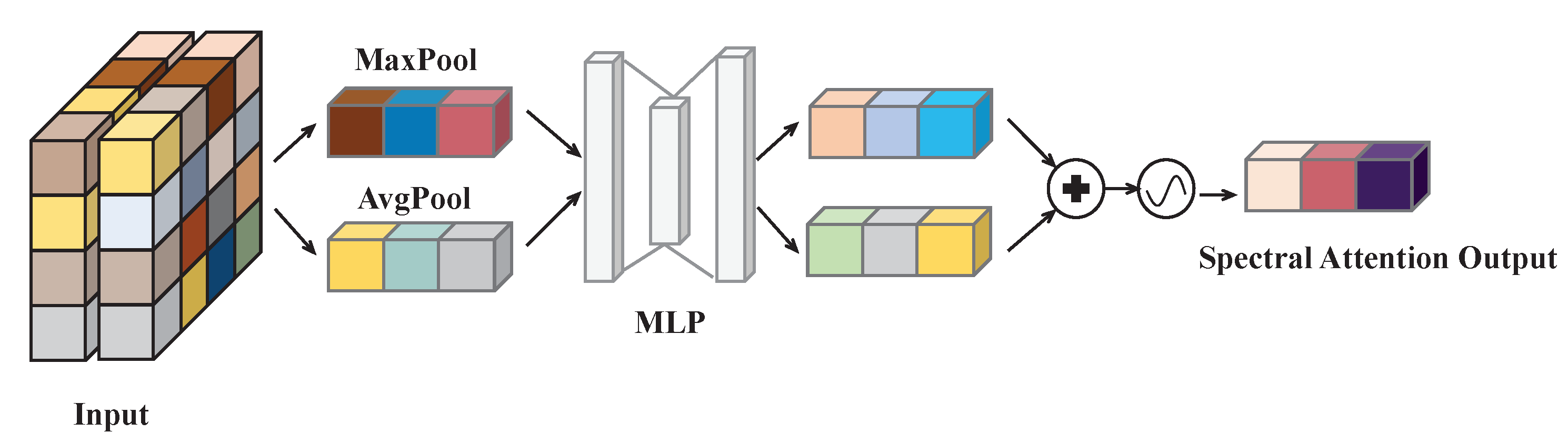
Figure 2 illustrates the architecture of the proposed spectral attention module within the framework of the dynamic convolution.
For the input feature map
x, first, maxpooling and avgpooling operations are performed to obtain the maximum and average responses to spectral features. A multi-layer perceptron (MLP) structure is used which includes two convolutional layers to process the results, obtaining
and
. Then,
and
are summed to obtain
. Subsequently, the preliminary integration of features is completed through a fully connected layer. Subsequently, the attention weight
is obtained through the ReLU layer, fully connected layer, and SoftMax layer. The specific calculation method is
where
and
are are two fully connected layers with different weight parameters.
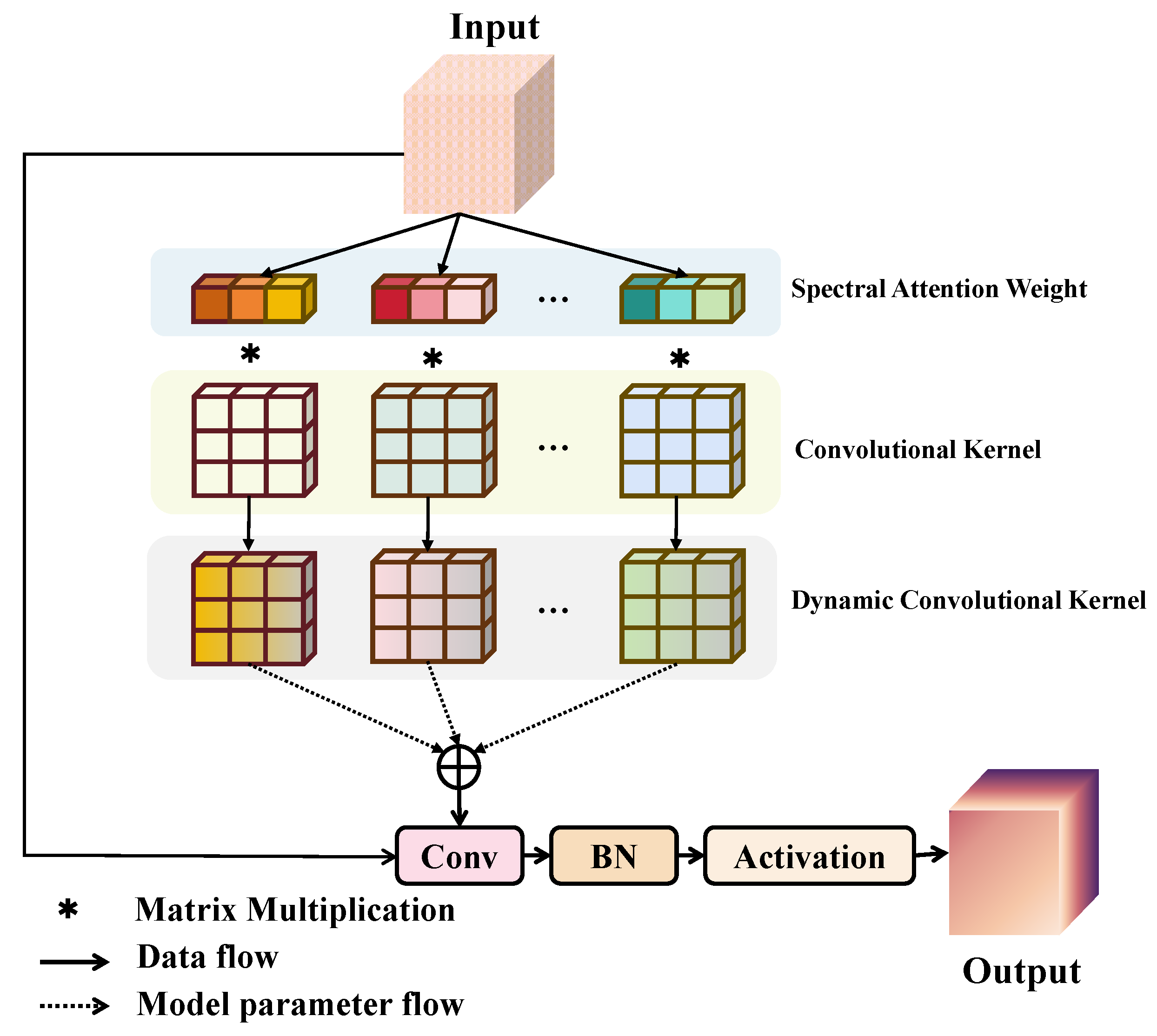
The spectral dynamic convolution layer is obtained through aggregation of the obtained attention weight
and the convolution kernel as shown in
Figure 3:
where
Here, represents the kth linear function . The attention weight of x varies depending on the input x. Therefore, given the input, the dynamic perceptron represents the optimal linear function combination for that input. Because the model is nonlinear, the dynamic perceptron has a stronger representation ability. For the time branch , an HS image is passed through the spectral dynamic convolution module, which captures more local features.
The dynamic convolution based on spectral attention can not only adjust the receptive field size adaptively according to the features of different bands but also capture more local micro features. The addition of spectral attention can make the network more flexible in focusing on more important bands and better capture and distinguish the changes between different bands. Therefore, the adaptability and expression ability of the CD algorithm for an HS image can be improved.
3.3. Multi-Temporal Deep Feature Encoder
Multi-temporal HS images have rich spatial and spectral information. Employing a dual-branch input mechanism, as opposed to traditional differential images, enables a more comprehensive depiction of the multidimensional features present within HS data, thereby effectively mitigating information loss and enhancing CD accuracy. For this purpose, we designed two time branches and to extract features from HS images.
For a time branch
, chunk processing is performed on HS images
and
. The corresponding patch block of an HS image is first input into the dynamic convolution block module to obtain a feature map
, which captures more local features. Afterward, features are extracted from the multi-temporal HS images using the following formula:
where
represents the
eth features extracted by the encoder block of an HS image,
is the weights and biases for the encoder parts of two source datasets,
is the ReLU nonlinear activation function, and
represents the batch normalization (BN) layer. Its function is to accelerate parameter learning and avoid gradient vanishing during the training process [
44].
3.4. Multi-Scale Feature Fusion Module (MsFFM)
Currently, many DL networks primarily utilize single-scale features in CD tasks. However, for some fine features, pixel information is relatively small and is easily lost during the downsampling process of CNNs. In current CNNs, the latter stages are typically configured to maintain the spatial dimensions of the input, aiming to preserve the scale of the output feature map. However, this approach often leads to insufficient capturing of detailed local information within deep feature maps. To mitigate this issue, MsFNet introduces a multi-scale feature fusion module which operates on the deep features of the network. The deep features in the MsFFM refer to the multi-scale feature extraction method through the deep learning network, the use of shallow-to-deep convolution levels to gradually extract abstract and high-level information, and the integration of features of different scales. These levels can capture more global and semantic features of the ground objects, such as the overall shape of the ground objects, spatial relations, and context information. This module extracts and integrates multi-scale features from the deep feature map, enriching the local information content of the feature map and thereby enhancing the model’s capability to perceive detailed local features. The architectural configuration of the multi-scale feature fusion module is illustrated in
Figure 4. By processing the deep feature map, this module effectively amalgamates information across different scales, facilitating more comprehensive comprehension and processing of input features by the model.
For the input feature graph , by using convolution kernels of different sizes, a feature with different sizes and numbers of channels multiplied is obtained. The main purpose of this step is to construct a feature representation with multi-scale and richer channel information while extracting the semantic information of .
Firstly, 1×1 convolution is performed on
to reduce the number of channels and obtain
. Then, 2× nearest neighbor upsampling is performed on
. The 2× nearest neighbor upsampling method is simple to implement, has a small amount of computation, is fast, and for some scenes with obvious edges, it can better maintain edge information. The utilization of 2× nearest neighbor upsampling was chosen to ensure the resultant feature map encompassed both robust spatial information and substantial semantic content. The 2× nearest neighbor upsampling process is illustrated in
Figure 5.
Next, the obtained feature map is combined with
, which also passes through a 1 × 1 convolution kernel to reduce the number of channels. The combined method uses pixel-to-pixel addition operations. The design of this step aims to integrate information from different channels and then repeat the above process on the newly obtained feature map to obtain
:
Finally, convolution is performed on
to reduce feature confusion caused by the upsampling and stacking processes to obtain the multi-scale feature
:
3.5. CD Module
In order to obtain the results of CD, the deep feature
is obtained through convolutional blocks, and the dual temporal feature maps obtained by distinguishing
and
within the group are used to obtain the feature
:
Multi-scale feature fusion is used to transfer feature maps and obtain the final feature
. Throughout the process, features of different scales are fully utilized. Compared with directly using convolution for downsampling, not only can deep features be obtained through convolution, but spatial information in shallow specialties is also preserved, making it more likely to obtain rich feature representations at different scales. This is of great significance for feature extraction. Then,
is entered into the fully connected layer to obtain
:
The feature
is then input into the SoftMax layer to obtain the final predicted probability distribution
. The formula for this is as follows:
where
k is the number of category categories and there are only two types of CD tasks—changed and unchanged—where
, with
k being the class sequence number. Meanwhile,
represents the value of the weight of the
kth column in the prediction layer, and
is the 1D matrix of the probability of changed pixels and unchanged pixels.
3.6. Network Training
The proposed MsFNet adopts an end-to-end approach during network training, directly learning feature representations and classification boundaries from raw data. Train uses training set samples, which are input in the form of . Among them, is the HS image block of the ith training sample input at different times, and represents the true label which matches the corresponding image block. N represents the number of training set samples used during the training process.
In HS image CD tasks, class imbalance usually occurs because changes in different regions or scenes may be rare, resulting in class imbalance. The weighted cross-entropy loss function can deal with this situation well and improve the performance of rare CD. In this chapter, weighted cross-entropy is chosen as the loss function:
where
is the
jth weight and
is the probability that the pixel belongs to the
jth class. This approach allowed us to assign different weights to the loss contributions from individual categories based on their respective frequencies in the training data, thereby addressing the imbalance and ensuring that the model effectively learned from all classes, regardless of their representation in the dataset. For the weights, the definition is as follows:
where
is the number of class
j in the ground truth training sample. The overall process of MsFNet is shown in Algorithm 1.
| Algorithm 1: Actions performed by the algorithm. |
- Require:
multi-temporal HS image and ; training label Y; training epochs ; - Ensure:
CD map, P; - 1:
Initialize all weights; - 2:
The input block related to H and L is derived based on the value of r; - 3:
while do: step 1: Calculate spectral attention weights with Equation ( 1); step 2: Extract multitemporal HS image features with dynamic convolution module; step 3: Extract multitemporal HS image deep features with Equation ( 4); step 4: Extract multi-scale deep features with Equations (5) and (6); step 5: Train the network to obtain the highest weight result; - 4:
Use classification function according to Equation ( 9) to obtain CD map.
|














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}