Abstract
In the field of remote sensing image captioning (RSIC), mainstream methods typically adopt an encoder–decoder framework. Methods based on this framework often use only simple feature fusion strategies, failing to fully mine the fine-grained features of the remote sensing image. Moreover, the lack of context information introduction in the decoder results in less accurate generated sentences. To address these problems, we propose a two-stage feature enhancement model (TSFE) for remote sensing image captioning. In the first stage, we adopt an adaptive feature fusion strategy to acquire multi-scale features. In the second stage, we further mine fine-grained features based on multi-scale features by establishing associations between different regions of the image. In addition, we introduce global features with scene information in the decoder to help generate descriptions. Experimental results on the RSICD, UCM-Captions, and Sydney-Captions datasets demonstrate that the proposed method outperforms existing state-of-the-art approaches.
1. Introduction
Benefiting from advancements in aerospace and computer technologies, modern remote sensing technology has rapidly developed. Since the remote sensing image captioning (RSIC) task can not only identify objects and scenes in remote sensing images but also convert these visual contents into coherent sentences, it has become a research hotspot in the application field of remote sensing technology, such as environmental detection [1,2], land surveying [3,4], and traffic control [5,6]. This task involves the classification of remote sensing images along with generating their descriptions, thus allowing for intelligent interpretation from different perspectives.
Conventional RSIC methods mainly include template-based [7] methods and retrieval-based methods [8]. The former extracts words describing the main objects in an image and inserts these words into predefined sentence templates to generate captions. The latter calculates the similarity between the remote sensing image and all the sentences in the pre-collected datasets, and then selects the sentence with the highest similarity. However, template-based methods rely on fixed templates, which limits the flexibility of expression. Furthermore, retrieval-based methods are limited by pre-collected datasets, which affects the accuracy of matching when no sentences exist in the datasets. Recently, most RSIC tasks have adopted an encoder–decoder framework [9,10,11,12,13], such as the combination of a convolutional neural network (CNN) and long short-term memory (LSTM) [14]. This is an end-to-end framework that generates sentences directly from remote sensing images. Methods based on this framework have surpassed conventional methods in terms of sentence diversity and semantic matching accuracy. Due to the significant scale differences of various objects, methods based on this framework typically employ multi-scale feature fusion algorithms to enhance features, such as scaling and concatenating feature maps of different scales. These feature enhancement approaches are implemented during the feature extraction stage of the encoder, where they synchronously merge features of different scales directly. Therefore, they are referred to as single-stage feature enhancement algorithms.
Despite the capability of single-stage feature enhancement algorithms, they still have limitations in some aspects. For example, existing single-stage feature enhancement algorithms simply concatenate feature maps of different scales [11], leading to an imbalanced distribution of feature channels, which may cause the neglect of small objects. Meanwhile, they also lack the modeling of location information in remote sensing images. Although relationships between sequential elements can be learnt when architectures based on Transformer [15] are applied in the realm of remote sensing, such as the Vision Transformer (ViT) [16], these algorithms introduce the flattening of feature maps, which disrupts the structural information in remote sensing images.
Additionally, calculating the correlation for every pair of elements in a sequence will significantly increase the consumption of computational resources, which may lead to difficulties in converging the model’s loss function. Therefore, single-stage feature enhancement alone cannot meet the requirements for obtaining multi-scale information and modeling object position relationships in the RSIC task. As a result, we consider two-stage feature enhancement to further explore the positional relationships based on the acquisition of multi-scale features.
Another challenge is the insufficient extraction of global features in the RSIC task. Obtaining global features by global average pooling (GAP) is currently the dominant method. Global features capture the overall semantic information of images and provide a macroscopic perspective for the model [17,18,19]. Thus, they are widely used in the decoder as context information to assist in description generation. In existing RSIC tasks, a common way to obtain global features is to pool the feature maps extracted from the last convolutional layer. However, single-scale global features cannot fully represent the scene information of the entire image, since remote sensing images typically contain multiple main objects with significant scale differences. Therefore, when extracting global features, integrating multi-scale information is preferred since global features provide more accurate scene information of remote sensing images. Additionally, due to the differences between image features and text features, directly merging global features obtained from images with text features can lead to semantic mismatches. Considering these issues, a more sophisticated extraction method that covers multi-scale information while considering alignment with textual features is needed.
To solve the problems mentioned above, we propose a novel two-stage feature enhancement (TSFE) for the RSIC task. In the first stage, we concatenate feature maps of different scales and then apply a channel attention mechanism to adaptively assign weights to different channels for imbalanced feature channel allocation. Then, we utilize the multi-head attention mechanism to establish connections between different regions of an image in the second stage. Considering the computational complexity of modeling the entire sequence, we compress the multi-scale features in both horizontal and vertical directions to improve efficiency. The loss of structural information caused by the multi-head attention mechanism is learnt by a local attention module to learn structural information. Furthermore, we perform GAP on multi-scale features to integrate multi-scale information into global features. Considering the inconsistency between image features and text features, we have designed a fine-tuning task to align the global features with the text features.
To summarize, the main contributions of this paper are as follows:
- We propose a TSFE model for the RSIC task, which is capable of extracting fine-grained features of remote sensing images and introduces global features in the decoder, thus enhancing the accuracy of the generated sentences;
- To obtain fine-grained features of remote sensing images, we propose an adaptive multi-scale feature fusion (AMFF) module and local feature squeeze and enhancement (LFSE) module, capable of adaptively assigning weights to features of different channels, while also establishing connections between different regions of remote sensing images;
- To integrate global features in the decoder, we propose a feature interaction decoder (FID), which synchronously fuses global image and text features in the decoder to improve the accuracy of the sentences.
2. Related Work
In this section, related work in the field of RSIC will first be reviewed, and the advancements and research efforts that have been made will be explored. Following that, feature enhancement strategies and decoding strategies in the field of RSIC will be summarized.
2.1. Remote Sensing Image Captioning
Different from other tasks in remote sensing, such as object detection [20,21], classification [22,23], and segmentation [24,25], the RSIC task involves identifying the main objects and understanding the relationships of these objects within specific scenes simultaneously. Inspired by natural image captioning (NIC) [26,27], the existing RSIC approaches follow the general architecture of the encoder–decoder framework. Qu et al. [28] proposed a structure that combined a CNN and RNN/LSTM to generate sentences and disclosed two RSIC datasets (i.e., UCM-captions and Sydney-captions). Lu et al. [29] introduced the soft attention mechanism where the model can dynamically adjust its focus on different regions of the image, thereby leading to more accurate sentences. Li et al. [30] proposed a multi-level attention (MLA) model, which contains a three-level structure representing the attention to different image regions, the attention to different words, and the attention to visual and semantic structures. This structure enables the more efficient learning of visual and semantic features. Zhang et al. [31] proposed a model with an attribute attention mechanism, which can readjust the weights of image features based on attribute information to enhance the focus on objects in the image. Zhang et al. [32] proposed a label-attention mechanism (LAM) that employed a pre-trained image classification network to import labels to optimize the weight allocation in attention layers. Wang et al. [9] proposed a new explainable word–sentence framework for RSIC decomposing RSIC into word classification and word ordering tasks, which aligned more with human intuitive understanding. Zhao et al. [33] proposed a fine-grained, structured attention-based method (Structured-Attention) for remote sensing image captioning. This method targets the structural characteristics of semantic content in remote sensing images and can generate precise pixel-level segmentation masks. Shen et al. [34] proposed a variational autoencoder and reinforcement learning-based two-stage multi-task learning model (VRTMM). In the first stage, a variational autoencoder is used to jointly fine-tune the CNN. In the second stage, text descriptions are generated based on the transformer, utilizing spatial and semantic features. Li et al. [35] introduced an end-to-end trainable semantic concept extractor (SCE) and also proposed consensus exploitation (CE) block to integrate high-level relational features between visual and semantic aspects for acquiring more comprehensive knowledge. However, the above methods lack the mining of spatial information between different regions in the remote sensing images and the introduction of contextual information in the decoder to assist in generating sentences. These limit the model’s ability to generate accurate descriptions.
2.2. Feature Enhancement Strategies
One significant problem in remote sensing images is that small-scale objects may be overlooked during the feature extraction process because of the significant scale differences among diverse objects. Zhang et al. [36] proposed a data enhancement strategy to extract multi-scale visual features through multi-scale image cropping and training, which enriches the visual understanding of the model. Ye et al. [10] proposed a global visual feature-guided attention (GVFGA) mechanism that fuses global and local features of remote sensing images and utilizes an attention gate to filter out redundant information. Yuan et al. [37] proposed a multi-scale visual self-attention module that first captures the multi-scale features through a multi-scale feature fusion network and then filters out the redundant features through a filtering network. Liu et al. [11] proposed a multi-scale feature fusion strategy, which concatenates feature maps from different layers of the encoder after scaling to obtain multi-scale features. Li et al. [38] proposed a recurrent attention and semantic gate (RASG) framework that integrates competitive visual features and a recurrent attention mechanism. This framework is capable of extracting high-level attention maps from encoded features and non-visual features, which assist the decoder in recognizing and focusing on the effective information necessary for understanding the complex content of remote sensing images. Although these feature enhancement methods can improve the representational capability, they have not established associations between different regions of the remote sensing images, leading to inaccurate descriptions of positional information among objects.
2.3. Decoding Strategies
In the RSIC task, effective decoding strategies are essential to produce coherent and meaningful descriptions. Wang et al. [39] proposed an attention-based global–local captioning model (GLCM), which can utilize self-attention to break through the time-step limit. Zhang et al. [40] proposed a multi-source interactive stair attention mechanism (MSISA) where a two-layer LSTM structure is used in the decoding stage. The first layer LSTM is dedicated to receiving and integrating information from multiple sources, while the second layer LSTM synthesizes the image features with the output of the first layer LSTM to generate descriptions. This design enhances the generalization of the model. Liu et al. [11] proposed a multi-layer aggregated Transformer (MLAT) framework, which employs LSTM as a connector to aggregate features from each layer of the Transformer. Then, the aggregated features are sent to every decoding layer. This structure significantly enhances the model’s performance in terms of sentence accuracy and diversity. Ren et al. [16] proposes a mask-guided Transformer network with a topic token (MGTN). In the decoding stage, this network employs two specialized multi-head attention modules. The first module enhances the key and value vectors with topic semantic features, thereby infusing global semantic context into the model. The second module is tailored to emphasize the connections between lexical elements and image attributes, facilitating the generation of accurate captions based on the specific image features provided. Remote sensing images usually contain multiple objects, and a single label is often insufficient to represent the overall characteristics of the image. Therefore, it is necessary to introduce more appropriate contextual information into the decoder to assist in sentence generation.
3. Method
In this section, we introduce our proposed model, as shown in Figure 1, which consists of three modules: the adaptive multi-scale feature fusion module (AMFF), the local feature squeeze and enhancement module (LFSE), and the feature interaction decoder (FID). In the AMFF module, we fuse feature maps from different layers and utilize a channel attention mechanism to adaptively assign weights to features in different channels. In the LFSE module, we adopt a multi-head attention mechanism to establish correlations between image sequences, while using a local attention module to compensate for lost structural information. We utilize the FID module in the decoder to introduce global features aligned with text features to generate accurate descriptions. We provide details of each module as follows.
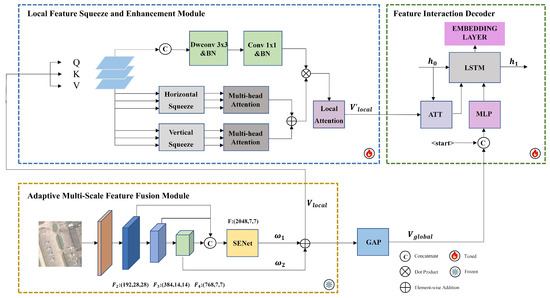
Figure 1.
The overview of our proposed TSFE model for remote sensing image captioning. It consists of the adaptive multi-scale feature fusion module, local feature squeeze and enhancement module, and feature interaction decoder.
3.1. Adaptive Multi-Scale Feature Fusion Module
Remote sensing images usually contain multiple objects, with a high diversity in size. As a result, capturing the information of all the objects through only one scale image feature is difficult. Shallow features are more suitable for recognizing small objects, whereas deep features are preferred for large objects, since deeper features mean a larger receptive field and more advanced semantic information. Therefore, it is necessary to fuse different scale features of remote sensing images.
We chose Swin Transformer [41], which has excellent performance in processing complex images, to extract image features. The specific features of different convolutional blocks are represented as
where I represents the input remote sensing image, represents the parameters of Swin Transformer, and is the output feature map of each block.
Considering that contains more low-level semantic information, we only focus on the three scales of , , and . By superposing these three scales of features in the channel dimension, we obtain the multi-scale feature F. The above process is formulated as
where F is the extracted multi-scale feature, and c denotes the concatenation operation in the channel dimension.
Multi-scale features obtained by direct cascading may fail to fully exploit the complementarity between features of different scales, because they have diverse numbers of channels in the channel dimension. This may result in the unbalanced contribution of scale features to the overall features after fusion. Therefore, we used SENet [42] to adjust the weights of the features according to the importance of the feature channels to improve the quality of multi-scale features after fusion. This process can be represented as
where represents the output of SENet and represents the parameters of SENet.
To further enhance the feature representation capacity, we introduce two trainable parameters and with an initial value of 1, which are updated with backpropagation during training. Thus, we construct a linear relationship of the multi-scale features and with the larger receptive field through these two parameters to obtain the final feature , as
where and represent two trainable parameters. represents the extracted local feature.
We obtain global semantic features through the GAP layer based on , as
where represents the extracted global feature.
It should be noted that obtained in this way can also contain the semantics of multiple scene objects because contains multi-scale features.
3.2. Local Feature Squeeze and Enhancement Module
Most of the existing RSIC methods directly use the image features extracted by the encoder to generate sentences, which overlooks the complex associations between different objects in remote sensing images. Therefore, we propose the LFSE module to establish associations between different regions in the image, which performs a second-stage feature enhancement based on multi-scale features.
where . denotes the squeeze operation. represents the implementation of horizontal squeeze, and represents the implementation of vertical squeeze.
We utilized the multi-head attention mechanism to establish associations among various image regions. Specifically q, k, and v are linear projection of , where , . According to Equation (6), we first implement horizontal squeezing by taking the average of the feature mappings in the horizontal direction to obtain and . Similarly, we achieve compression in the vertical direction to obtain and . These compressed features are then fed into the multi-head attention network for processing, and the results are summed up to obtain . The above process is expressed as
where represents the weight value and represents the transpose operation.
By performing squeezing operations in both horizontal and vertical directions, we avoid modeling the entire sequence, thus significantly enhancing computational efficiency. While the squeezing operation effectively extracts global semantic information, it sacrifices local details. Therefore, we utilized an auxiliary convolution-based kernel to enhance spatial details. We first concatenate the linear projections q, k, and v obtained from , then pass them through a module containing a depthwise separable convolution and batch normalization. By using a convolution, auxiliary local details can be aggregated from q, k, and v. Subsequently, a linear projection layer along with batch normalization is used to compress the dimensions and generate detail-enhancing weights. Finally, these enhanced features are fused with the features obtained through the squeezing operation. This process can be represented as
where and represent depthwise separable convolution and 1 × 1 convolution, respectively. and are the intermediate and the image feature after multi-head attention, respectively.
Due to the multi-head attention mechanism, the inevitable serialization of images loses some structural information, such as the spatial structural correlations between sequences at long distances. Therefore, we design a local attention module to recover some of these details. Specifically, we apply N soft attention for in the local attention module to generate multiple local feature vectors. We first need to construct N attention weighting maps with the spatial size of . The weight coefficients for each pixel position are computed by the following formula:
where and are the intermediate and scaled weighting maps, respectively. is a learned parameter.
After that, we utilize the GAP to aggregate each weighting map and to obtain . The kth element in the nth vector of is calculated by
where represents the refined local features.
It is worth noting that the local attention module constructs attention weighting maps with specific spatial dimensions and uses a soft attention mechanism to restore the long-distance spatial structural correlations that may be lost due to the serialization process of multi-head attention mechanisms. In contrast, the convolution-based kernel enhancement technology focuses on enhancing the local spatial details of images through depthwise separable convolution and batch normalization. In our research, we simultaneously used these two methods to restore the detailed information of the remote sensing images.
By combining the multi-head attention mechanism with image detail enhancement, we established correlations between sequences while preserving the structural information of the remote sensing images. This design can further explore the positional association between different regions of remote sensing images based on multi-scale features, thus further improving the accuracy of the generated descriptions.
3.3. Feature Interaction Decoder
The decoder applies LSTM in our proposed model, which is suitable for sequential data processing. We input the , obtained from the LFSE, into the LSTM for decoding and use the same attention mechanism as [43] in the decoding process to determine which parts of the image to focus on when generating each word. Specifically, we assign weights to the image by measuring the similarity between the outputs of each step of the LSTM and , and then generate the next word based on these weights. The above process is expressed as
where W is a learned parameter, d is the dimensionality of the image features , are the attention weights for each image region, and is the image feature after the attention mechanism.
Although this strategy can guide the decoder to focus on different areas of the image, it primarily focuses on the utilization of local features rather than the global information of the image. If such information is insufficient in the decoder, the generated sentences may lack semantic coherence and produce words irrelevant to the scene. So, we fuse the global features with the previously generated words and feed them into the LSTM with the local features for decoding. After obtaining from the AMFF module, we combine with the embedding of the words generated in the previous step and enhance the interaction between the image and text features through a multi-layer perceptron (MLP). The above process is expressed as
where M represents a multi-layer perceptron, and represents the word information generated at the previous time step. is the LSTM input vector and is the output vector. , , , and are the input gate, forget gate, cell state, and output gate of the LSTM, respectively. and tanh are the logistic sigmoid activation and hyperbolic tangent activation, respectively. ⊙ represents element-wise multiplication.
3.4. Objective Functions
Our objective functions are divided into two parts: training for the fine-tuning task and training for the overall model. Initially, it is essential to provide an overview of the fine-tuning task. The Swin Transformer was pre-trained on the ImageNet dataset [44]. However, the ImageNet dataset mainly contains natural images, which are highly different from remote sensing images. Additionally, due to the differences between visual and text features, directly fusing the global features obtained from multi-scale features through GAP with text features can cause semantic mismatches. Therefore, we specifically designed a fine-tuning task and used and the GloVe embedding of the sentence to fine-tune the AMFF module on the remote sensing dataset, as shown in Figure 2.
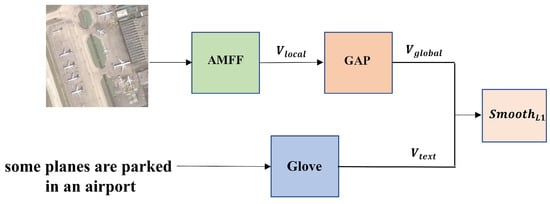
Figure 2.
The fine-tuning task.
For the fine-tuning task, we used loss for training. The loss is also called Huber loss, which penalizes linearly when the absolute difference between the prediction and the target is very high and penalizes quadratically when the difference is close to zero. So, the loss function can deal with large and small prediction errors in a balanced way. When comparing embedding vectors, we take the average over the different vector dimensions. The equation for comparing two values x and y is expressed as
where x represents the predicted embedding value, and y represents the true embedding value.
According to [43], a continuous output model is superior in capturing the global semantic similarity between captions and images. Therefore, for the overall model, we removed the softmax layer from the LSTM unit, allowing the model to directly output a continuous embedding rather than a probability distribution. Then, by using these generated continuous embeddings alongside the target embeddings, we proceeded to apply the loss function at both word and sentence levels during training.
where represents the predicted embedding value, and represents the target embedding value. T represents the length of the sentence.
4. Experiments
In this section, we first introduce the publicly available datasets used in the experiments as well as the commonly used evaluation metrics in this field. Following that, we provide experimental details, including model configuration and training procedures. Additionally, we conducted a series of ablation experiments, qualitative analyses, and visualization analyses to validate the effectiveness of our proposed method and compared its performance with state-of-the-art approaches.
4.1. Datasets
We evaluated the performance of our method using three publicly available datasets: RSICD, UCM-Captions, and Sydney-Captions. The details of the three datasets are provided in the following.
4.1.1. RSICD
The RSICD dataset [29] is the largest dataset in the RSIC domain, containing 10,921 images, each of which is 224 × 224 pixels in size and each of which has five manually labeled descriptive statements. All the images are captured by satellites or high-altitude drones, covering 30 scenarios such as cities, rivers, and airports.
4.1.2. UCM-Captions
The UCM-Captions dataset was improved from the UC Merced Land-Use dataset [45], which was initially used for a scene classification task and consisted of 21 categories with 100 images per category for a total of 2100 images, each of which was 256 × 256 pixels. The current UCM-Captions dataset was updated by Qu et al. [28] by adding five descriptive sentences for each image.
4.1.3. Sydney-Captions
Sydney-Captions dataset [28] is constructed from the Sydney dataset [46], which consists of 613 images in seven categories. Each image is 500 × 500 pixels in size, and each image includes five descriptive statements.
4.2. Evaluation Metrics
In this paper, multiple evaluation metrics were used to assess the quality of image descriptions, including bilingual evaluation understudy (BLEU) [47], recall-oriented understudy for gisting evaluation-l (ROUGE-L) [48], the metric for evaluation of translation with explicit ordering (METEOR) [49], and consensus-based image description evaluation (CIDEr) [50]. BLEU is commonly used for machine translation and other natural language generation tasks. ROUGE-L is similar to BLEU, except that ROUGE-L is calculated based on the recall rate of the longest common subsequence L. METEOR is obtained by n-gram computation of the average of the reconciliation of precision and recall between candidate and reference utterances. CIDEr is specifically designed for image description tasks and the metric assigns higher weights to visually relevant words.
4.3. Implementation Details
In our experiments, Swin Transformer was used to extract image features. We fine-tuned Swin Transformer on the task of predicting captioning embeddings. We used the training set from the RSIC dataset for fine-tuning tasks and used the validation set to adjust early stopping. The encoder output two features, where the number of dimensions in the local feature channel was 2048 and the global feature size was 300. After that, the local features were refined by multi-head attention and local attention. Regarding the decoder, the hidden state dimension of LSTM was 512, and the final output size of LSTM was 300. We used the Adam optimizer [51] for training, where the parameters of the encoder were fixed at the end of the fine-tuning task and the rest of the components were trained together. The different loss weighting terms were learned using GradNorm [52]. The model was implemented on PyTorch 1.12.1 and trained on the NVIDIA GeForce RTX 3090 GPU.
4.4. Compared Models
To provide a comprehensive evaluation of our model, we compared it with several other state-of-the-art approaches. We first briefly review these methods in the following.
- (1)
- Up–Down [53]: This approach introduces a mechanism that combines bottom-up and top-down visual attention, allowing the model to dynamically select and weigh various regions in the image.
- (2)
- SAT [54]: This method extracts visual features using a pre-trained CNN, applies spatial attention to obtaining context vectors, and converts them to natural language using LSTM.
- (3)
- MLA [30]: In the multi-level attention model (MLA), a multi-level attention mechanism is designed to choose whether to apply images or sequences as the main information to generate new words.
- (4)
- Structured-Attention [33]: It employs a fine-grained and structured attention mechanism to extract nuanced segmentation features from specific regions within an image.
- (5)
- RASG [38]: The method introduces a cyclic attention mechanism and semantic gates to fuse visual features with attentional features with higher precision, thus assisting the decoder in understanding the semantic content more comprehensively.
- (6)
- MSISA [40]: This method uses a two-layer LSTM for decoding. The first layer integrates multi-source information, while the second layer uses the output of the first layer and image features to generate the sentences.
- (7)
- VRTMM [34]: This method utilizes a variational autoencoder mode to extract image features and also uses a Transformer instead of LSTM as the decoder for higher performance.
- (8)
- CASK [35]: This method can extract corresponding semantic concepts from images and utilize the Consensus Exploitation (CE) block to integrate image features and semantic concepts.
- (9)
- MGTN [16]: This approach proposes a mask-guided Transformer network with a topic token, which is added to the encoder as a priori knowledge to focus on the global semantic information.
4.5. Comparisons with State of the Art
We compared our proposed method with other state-of-the-art RSIC methods in three different datasets: RSICD, UCM-Captions, and Sydney-Captions. Table 1, Table 2 and Table 3 detail the performance of our model and other models on the RSICD, UCM-Captions, and Sydney-Captions datasets with the best scores marked in bold. Our model has a superior performance over the compared models in almost all of the metrics.

Table 1.
Comparison of our method and other state-of-the-art methods on the RSICD datasets.
Table 2.
Comparison of our method and other state-of-the-art methods on the UCM-Captions datasets.
Table 3.
Comparison of our method and other state-of-the-art methods on the Sydney-Captions datasets.
On the RSICD dataset, our proposed method achieves the highest scores on all BLEU metrics, which fully demonstrates its superiority and accuracy in word selection and phrase construction. On the CIDEr metric, our method has a 2.45% improvement compared to the MGTN method. Meanwhile, the presented method also maintains a high level in terms of METEOR and ROUGE-L. Since RSICD is the largest RSIC dataset, its experimental results are more generalizable and credible.
On the UCM-Captions dataset, our method achieves 0.55%, 0.75%, and 0.86% improvement in BLEU1–BLEU3 metrics and a greater improvement in ROUGE-L metrics (2.5% higher) compared to the MGTN method. In addition, our method also maintains a high level in all other evaluation metrics.
On the Sydney-Captions dataset, the experimental results are similar to those on the UCM-Captions dataset, achieving higher results in almost all BLEU metrics compared to MGTN and maintaining a high level in the remaining metrics. It is worth mentioning that the size of the Sydney-Captions dataset is much smaller than that of RSICD and UCM-Captions datasets. Therefore, even with limited data, our method can achieve excellent performance, indicating that our method has strong generalization and is thus applicable for remote sensing datasets of different scales and scenarios.
Although both our approach and MGTN fine-tune the encoder through a pre-training task, we incorporated a multi-scale feature fusion module into the fine-tuning task, which ensures that the information of different objects from the remote sensing images is accurately captured. In addition, because a remote sensing image usually contains multiple labels, we employed the average of the GloVe embeddings to fine-tune the model, in contrast to the single-label fine-tuning task of MGTN, which may limit its accuracy. Therefore, our strategy clearly demonstrates stronger generalization.
4.6. Ablation Study
The proposed TSFE model is composed of three modules, namely the adaptive multi-scale feature fusion module (AMFF), the local feature squeeze and enhancement module (LFSE), and the feature interaction decoder (FID). We compared our method with the following methods to evaluate the effectiveness of these modules:
- (1)
- “Baseline”: The image features are extracted using Swin Transformer pre-trained on ImageNet, and the decoder uses LSTM to generate captions.
- (2)
- “Baseline+Fine-tuning”: The AMFF module is used to extract multi-scale features, utilizing a fine-tuning task to adapt the encoder to the remote sensing dataset.
- (3)
- “Baseline+Fine-tuning+LFSE”: Fine-tuning and LFSE are used simultaneously for the remote sensing image captioning task.
- (4)
- “Baseline+Fine-tuning+LFSE+FID (ours)”: Our proposed TSFE model.
In Table 4, it is evident that merely utilizing the encoder pre-trained on ImageNet fails to provide an effective image representation for our task, by comparing the experimental results between “Baseline” and “Baseline+Fine-tuning”. However, with the fine-tuning scheme we have designed, a significant improvement in encoder occurs on three datasets. Specifically, for the RSICD dataset, the results of for BLEU-4, METEOR, ROUGE-L, and CIDEr under “Baseline+Fine-tuning” have risen by 9.9%, 4.4%, 4.6%, and 5.4%, respectively, compared to those under “Baseline”. Furthermore, enhancements in performance are also observed in the other two datasets. These findings highlight the importance of domain-specific fine-tuning for encoders.
Table 4.
Ablation study results on the three datasets.
The effectiveness of LFSE is demonstrated by comparing “Baseline+Fine-tuning” with “Baseline+Fine-tuning+LFSE”. For instance, on the RSICD dataset, the scores for BLEU-4, METEOR, ROUGE-L, and CIDEr are higher by 3.3%, 2.9%, 1.8%, and 5.7%, respectively. This enhancement is attributed to the limitations of previous RSIC methods, which predominantly decode extracted image features directly for sentence generation, overlooking the complex spatial information in remote sensing images. Experimental results show that our proposed LFSE can capture the positional relationships between objects in the image, thereby mining more detailed information to generate more accurate sentences.
The performance is improved after incorporating the FID module on three datasets when comparing “Baseline+Fine-tuning+LFSE” and “Ours”. Our proposed FID incorporates global semantic information into the encoding stage. Experimental results demonstrate that sentences produced by the model are more closely aligned with the image content and semantically coherent.
4.7. Qualitative Analysis
We selected some generated sentences from the dataset for qualitative analysis, as shown in Figure 3, where “GT” denotes the ground truth sentence, “Baseline” denotes the sentence generated by the baseline model, and “Ours” denotes the sentence generated by our method.

Figure 3.
Examples of the generation results by our model.
For rigorous comparative analysis, inaccuracies in descriptions are annotated in blue, while veracious statements are highlighted in red. Upon meticulous examination of the presented results, it is evident that our model consistently outperforms the baseline across various image scenarios. For instance, in the second image, the baseline model overlooks the “trees” feature, while our model recognizes both “buildings” and “trees”. Similarly, in the fourth image, the baseline model only recognized the “swimming pool”, while our model further identifies the relevant “building”. This improvement can be illustrated by the fact that our model can capture features at diverse scales, thus generating more comprehensive sentences.
In the third image, our model can accurately describe the spatial relationship that the “trees” are on the two sides of the river, but the baseline model does not recognize it correctly. Similarly, in the seventh image, our model can correctly recognize the positional relationship between “bridge” and “trees”. This suggests that our model can create associations between different regions of the image to help improve the generated sentences.
Additionally, in the first image, the baseline model has failed to recognize the quantity of “baseball fields”, while our model has accurately described the count. Furthermore, in the third image, our model has outlined the contours of the “river”. In the fifth image, the baseline model has confused “land” with “bridge”. Furthermore, in the sixth image, our model is able to describe the colors of the buildings, while the baseline model not only fails to identify the colors, but also misjudges the shapes of the buildings. This indicates that our model can capture detailed information in remote sensing images along with providing descriptions at a macro level.
Through a comparative analysis between the caption results of the baseline model and our model, it is evident that the sentences generated by our model are not only more precise in capturing image details but also encompass a more comprehensive understanding of global image information. This is particularly notable in aspects such as scene categories, object count, and object morphology.
4.8. Visualization
To further validate the effectiveness of our method, we have compared the attention weights of our model with those of the baseline model during each word generation, as in Figure 4. Darker colors refer to a higher value of attention weights.
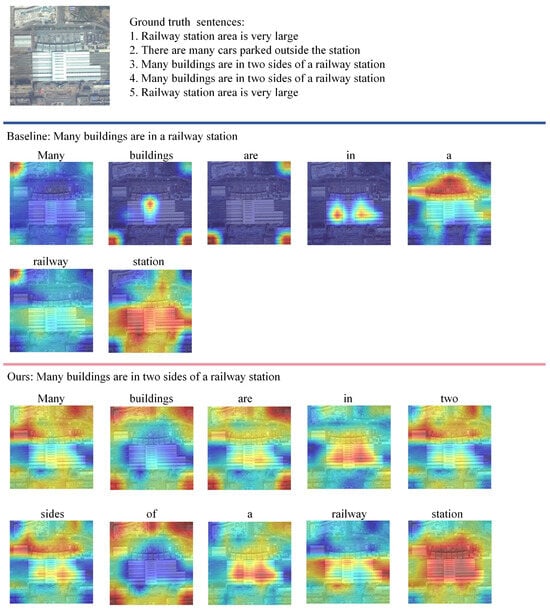
Figure 4.
Visualization comparisons between the baseline model and our proposed method are presented. In these visualizations, regions closer to red indicate higher attention weights, whereas those nearing blue signify lower attention levels.
From the color distribution in the image, it is apparent that the model generates different words based on various regions of the image. Compared to the baseline, the heat maps produced by our model align more closely with the words, which also proves that introducing global features with scene information in the decoding process can improve the accuracy of the encoder. For instance, when generating the word “buildings”, our model precisely focuses on areas surrounded by structures, whereas the baseline model erroneously gravitates toward the station. Similarly, when generating “railroads”, our model’s attention is focused, while the baseline model’s attention is distracted. These experimental results indicate that, compared to the baseline model, our proposed method allocates attention weights to the image more reasonably when generating sentences.
5. Conclusions
In this paper, we have proposed a two-stage feature enhancement model for remote sensing image captioning tasks, which consists of three modules: the AMFF module, the LFSE module, and the FID. The AMFF module adaptively fuses features of different scales to obtain multi-scale features. The LFSE module establishes connections between different regions while preserving the structural information. Finally, the FID introduces global features aligned with text features, thereby enhancing the accuracy of the generated sentences. Experiments demonstrate that the proposed method outperforms state-of-the-art approaches on the RSICD, UCM-Captions, and Sydney-Captions datasets. In the future, we will explore the impact of auxiliary tasks such as object detection and scene classification on the remote sensing image captioning task to further improve the quality of sentence generation.
Author Contributions
J.G. and Z.L. designed the model, then implemented the model and wrote the paper. B.S. and Y.C. contributed to the supervision of the work, analysis of the method, and paper writing. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Key Research and Development Program of Shaanxi (Program No. 2023-YBGY-218), the National Natural Science Foundation of China under Grant (Nos. 62372357 and 62201424), the Fundamental Research Funds for the Central Universities (QTZX23072), and also supported by the ISN State Key Laboratory.
Data Availability Statement
The RSICD, UCM-Captions, and Sydney-Captions datasets are available for download from at https://github.com/201528014227051/RSICD_optimal (accessed on 5 March 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RSIC | Remote sensing image captioning |
| CNN | Convolutional neural networks |
| LSTM | Long short-term memory |
| GAP | Global average pooling |
| ViT | Vision Transformer |
| TSFE | Two-stage feature enhancement |
| AMFF | Adaptive multi-scale feature fusion |
| LFSE | Local feature squeeze and enhancement |
| FID | Feature interaction decoder |
| NIC | Natural image captioning |
| RNN | Recurrent neural network |
| MLA | Multi-level attention |
| LAM | Label-attention mechanism |
| GVFGA | Global visual feature-guided attention |
| GLCM | Global–local captioning model |
| MLAT | Multi-layer aggregated Transformer |
| BLEU | Biingual evaluation understudy |
| Rouge-L | Recall-oriented understudy for gisting evaluation—Longest |
| Meteor | Metric for Evaluation of translation with explicit ordering |
| CIDEr | Consensus-based image description evaluation |
| UCM | UC Merced |
| MLP | Multi-layer perceptron |
| Up–Down | Bottom-up and top-down attention |
| RASG | Recurrent attention and semantic gate |
| VRTMM | Variational autoencoder and reinforcement learning- |
| based two-stage multitask learning model | |
| MGTN | Mask-guided Transformer network |
| SENet | Squeeze and excitation network |
| I | The input remote sensing image |
| The output from each block of the Swin Transformer | |
| c | The operation of concatenation in the channel dimension |
| F | Concatenation features |
| The output of SENet | |
| H | The height of the feature map |
| W | The width of the feature map |
| C | The channel dimension of the feature map |
| The local feature | |
| The global feature | |
| The intermediate weighting maps | |
| The scaled weighting maps | |
| The refined local feature | |
| The visual features of the input LSTM | |
| The generated word at time | |
| The features of the input LSTM | |
| The input gate of the LSTM | |
| The forget gate of the LSTM | |
| The cell state of the LSTM | |
| The output gate of the LSTM | |
| The output vector of the LSTM at time t |
References
- Liu, Q.; Ruan, C.; Zhong, S.; Li, J.; Yin, Z.; Lian, X. Risk assessment of storm surge disaster based on numerical models and remote sensing. Int. J. Appl. Earth Obs. 2018, 68, 20–30. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, L. Geological disaster recognition on optical remote sensing images using deep learning. Procedia Comput. Sci. 2016, 91, 566–575. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Q.; Li, X. Denoising-based multiscale feature fusion for remote sensing image captioning. IEEE Geosci. Remote Sens. Lett. 2020, 18, 436–440. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Li, X. Latent semantic minimal hashing for image retrieval. IEEE Trans. Image Process. 2016, 26, 355–368. [Google Scholar] [CrossRef]
- Recchiuto, C.T.; Sgorbissa, A. Post-disaster assessment with unmanned aerial vehicles: A survey on practical implementations and research approaches. J. Field Robot. 2018, 35, 459–490. [Google Scholar] [CrossRef]
- Liu, L.; Gao, Z.; Luo, P.; Duan, W.; Hu, M.; Mohd Arif Zainol, M.R.R.; Zawawi, M.H. The influence of visual landscapes on road traffic safety: An assessment using remote sensing and deep learning. Remote Sens. 2023, 15, 4437. [Google Scholar] [CrossRef]
- Li, S.; Kulkarni, G.; Berg, T.; Berg, A.; Choi, Y. Composing simple image descriptions using web-scale n-grams. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 220–228. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 2, 3104–3112. [Google Scholar]
- Wang, Q.; Huang, W.; Zhang, X.; Li, X. Word–Sentence framework for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10532–10543. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, W.; Yan, M.; Gao, X.; Fu, K.; Sun, X. Global visual feature and linguistic state guided attention for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5615216. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Shi, Z. Remote-sensing image captioning based on multilayer aggregated transformer. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506605. [Google Scholar] [CrossRef]
- Cheng, Q.; Huang, H.; Xu, Y.; Zhou, Y.; Li, H.; Wang, Z. NWPU-captions dataset and MLCA-net for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5629419. [Google Scholar] [CrossRef]
- Fu, K.; Li, Y.; Zhang, W.; Yu, H.; Sun, X. Boosting memory with a persistent memory mechanism for remote sensing image captioning. Remote Sens. 2020, 12, 1874. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Proc. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A mask-guided transformer network with topic token for remote sensing image captioning. Remote Sens. 2022, 14, 2939. [Google Scholar] [CrossRef]
- Jia, J.; Pan, M.; Li, Y.; Yin, Y.; Chen, S.; Qu, H.; Chen, X.; Jiang, B. GLTF-Net: Deep-Learning Network for Thick Cloud Removal of Remote Sensing Images via Global–Local Temporality and Features. Remote Sens. 2023, 15, 5145. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Hu, W.; Zhang, G.; Wu, J.; Li, X. TCM-Net: Mixed Global–Local Learning for Salient Object Detection in Optical Remote Sensing Images. Remote Sens. 2023, 15, 4977. [Google Scholar] [CrossRef]
- Ye, F.; Wu, K.; Zhang, R.; Wang, M.; Meng, X.; Li, D. Multi-Scale Feature Fusion Based on PVTv2 for Deep Hash Remote Sensing Image Retrieval. Remote Sens. 2023, 15, 4729. [Google Scholar] [CrossRef]
- Liu, S.; Zou, H.; Huang, Y.; Cao, X.; He, S.; Li, M.; Zhang, Y. ERF-RTMDet: An Improved Small Object Detection Method in Remote Sensing Images. Remote Sens. 2023, 15, 5575. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, F.; Zhou, J.; Lu, J.; Zhao, Z.; Qian, Y. Material-Guided Multiview Fusion Network for Hyperspectral Object Tracking. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5509415. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Jia, S.; Wang, Y.; Jiang, S.; He, R. A Center-masked Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5510416. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Huang, X.; Gao, Z.; Li, S.; He, T.; Zhang, Y. MFVNet: A deep adaptive fusion network with multiple field-of-views for remote sensing image semantic segmentation. Sci. China Inform. Sci. 2023, 66, 140305. [Google Scholar] [CrossRef]
- Ghamisi, P.; Couceiro, M.S.; Martins, F.M.; Benediktsson, J.A. Multilevel image segmentation based on fractional-order Darwinian particle swarm optimization. IEEE Trans. Geosci. Remote Sens. 2013, 52, 2382–2394. [Google Scholar] [CrossRef]
- Jiang, W.; Ma, L.; Chen, X.; Zhang, H.; Liu, W. Learning to guide decoding for image captioning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting image captioning with attributes. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4904–4912. [Google Scholar]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems, Istanbul, Turkey, 16–18 December 2016; pp. 1–5. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef]
- Li, Y.; Fang, S.; Jiao, L.; Liu, R.; Shang, R. A multi-level attention model for remote sensing image captions. Remote Sens. 2020, 12, 939. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef]
- Zhang, Z.; Diao, W.; Zhang, W.; Yan, M.; Gao, X.; Sun, X. LAM: Remote sensing image captioning with label-attention mechanism. Remote Sens. 2019, 11, 2349. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, Z.; Zou, Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603814. [Google Scholar] [CrossRef]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Cheng, X.; Tang, X.; Jiao, L. Learning consensus-aware semantic knowledge for remote sensing image captioning. Pattern Recognit. 2024, 145, 109893. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Q.; Chen, S.; Li, X. Multi-scale cropping mechanism for remote sensing image captioning. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium(IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 10039–10042. [Google Scholar]
- Yuan, Z.; Zhang, W.; Fu, K.; Li, X.; Deng, C.; Wang, H.; Sun, X. Exploring a fine-grained multiscale method for cross-modal remote sensing image retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4404119. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Gu, J.; Li, C.; Wang, X.; Tang, X.; Jiao, L. Recurrent attention and semantic gate for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5608816. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, W.; Zhang, X.; Li, X. GLCM: Global–local captioning model for remote sensing image captioning. IEEE Trans. Cybern. 2022, 53, 6910–6922. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Li, Y.; Wang, X.; Liu, F.; Wu, Z.; Cheng, X.; Jiao, L. Multi-Source Interactive Stair Attention for Remote Sensing Image Captioning. Remote Sens. 2023, 15, 579. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Ramos, R.; Martins, B. Using neural encoder-decoder models with continuous outputs for remote sensing image captioning. IEEE Access 2022, 10, 24852–24863. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, Z.; Badrinarayanan, V.; Lee, C.Y.; Rabinovich, A. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 794–803. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).