4.1. Characteristics of Datasets
The datasets chosen for evaluating the proposed network’s performance can be categorized into three groups, each of which has been widely adopted as a benchmark for DL-based DTM reconstruction study. Our study aims to comprehensively analyze these datasets and evaluate the performance of our proposed method.
4.1.1. USGS
The present study aims to deliver a comprehensive insight into the USGS datasets [
37]. The USGS dataset contains four main subsets with geographical and structural information, tabulated in
Table 1. It is worth noting that SU itself has been divided into three parts: SUI, SUII, and SUIII (
Figure 3). Similarly, the KA subset has been separated into two main parts: KAI and KAII (
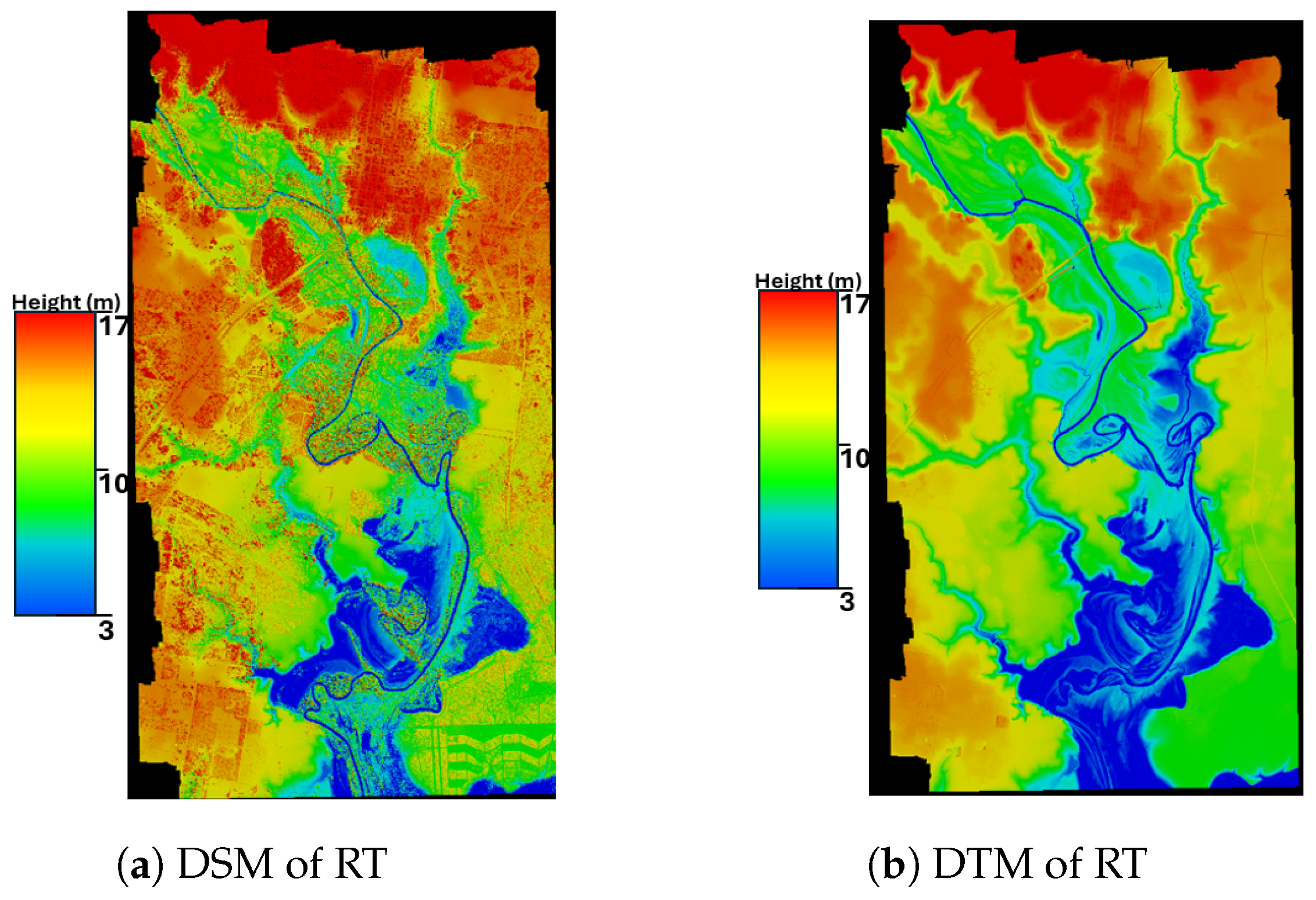
Figure 4). However, RT (
Figure 5) and KW (
Figure 6) are not divided into smaller parts.
Table 2 presents the statistical characteristics of the USGS dataset. In the SUI region, the DSM and DTM datasets show minimal differences in mean and median values, with a mean of around 1519 m for both datasets. This indicates a consistent elevation profile across the region. The maximum values for DSM and DTM are nearly identical, suggesting that the highest elevation points are captured similarly in both models. The 5th and 95th percentile values are very close, indicating a less varied elevation range compared to the KW region.
For the SUII region, there’s a slight decrease in mean elevation values compared to SUI, with the DSM and DTM means around 1445 m and 1443 m, respectively. The standard deviations are lower here, indicating a more uniform elevation profile. The maximum elevation is significantly lower than in the KW and SUI regions, which could suggest a less rugged terrain.
The SUIII region presents higher mean and median values than the previous regions, with means around 1699 m. The high standard deviation indicates a wider range of elevation differences, possibly due to more varied terrain. The maximum elevation is between those of KW and SUI, suggesting a mix of terrain features.
The KA region shows moderate mean elevation values (236.53 m for DSM and 233.09 m for DTM) compared to the other regions. The standard deviations are higher than in RT but lower than in the mountainous regions, indicating a moderate variation in elevation. To provide a better understanding of the position of the network’s input (i.e., DSM) to the network’s output (i.e., DTM), the fitted normal distribution for each subset/region has been illustrated in
Figure 7 as well.
For the KW region, the DSM and DTM mean values are closely aligned at 1611.45 m and 1603.88 m, respectively, suggesting a relatively consistent elevation profile between the surface and terrain models. However, the standard deviation is slightly higher for the DTM, indicating more variation in terrain elevation compared to the surface. Notably, both models share the same maximum value of 3111.84 m, pointing to a significant elevation feature present in both datasets. The 95th percentile values are identical for both models, reinforcing the presence of high-elevation features. The RT region stands out with significantly lower mean values (11.12 m for DSM and 9.73 m for DTM), indicating a very flat region. The negative minimum value in the DSM dataset might represent an artifact or, less likely, a below-sea-level feature. The maximum values are notably lower than in other regions, emphasizing the flatness of the area.
These subsets, in total, reveal a rich tapestry of elevation profiles across different regions, from flat terrains in RT to rugged landscapes in KW. The DSM and DTM models consistently capture the elevation characteristics of each region, with slight variations that might be attributed to the models’ inherent differences in representing surface and terrain features.
4.1.2. The OpenGF Dataset
The OpenGF dataset is a comprehensive collection of ground-annotated ALS point clouds, meticulously chosen and processed to support advanced ground filtering methodologies in diverse terrains. Its creation involved selecting only high-quality ground annotations from open-access ALS point clouds, addressing inconsistencies often observed in classification quality [
38]. The dataset encompasses point clouds that represent four prime terrain types, each with its unique characteristics and challenges. These terrains include metropolia, small cities, villages, and mountains, each typified by distinct ground and vegetation features (
Table 3). Among these datasets, three tiles (
Figure 8) of that, namely S4, S8, and S9, are employed in this study—the features of each of them are shown in
Table 4.
The selection of benchmark regions—S4, S8, and S9—was guided by the need to address the gaps in existing benchmarks such as USGS and ALS2DTM. The chosen regions were identified as unique based on their distinct geographic and structural characteristics, which are not sufficiently represented in the other benchmarks. The S4 area, characterized by numerous buildings on a flat terrain, offers a unique challenge in urban planning and infrastructure modeling. On the other hand, S8 and S9, representing sparsely covered and fully vegetated mountainous areas, respectively, offer different complexities in terrain navigation and vegetation density analysis. These areas were selected to test the robustness of our models under varied and extreme environmental conditions, ensuring that our research outcomes are broadly applicable in diverse real-world scenarios. Through this approach, we aim to develop models that are effective and applicable to various scenarios, improving the reliability and usefulness of our research.
The S4 datasets exhibit the lowest variability among the presented datasets, as indicated by their standard deviations (4.76 for DSM and 2.96 for DTM). This low variability is beneficial for achieving consistent and reliable measurements. The mean values of DSM (359.56) and DTM (356.78) are relatively close, with the DSM dataset having a slightly higher average. Both datasets’ maximum and minimum values are close, indicating a consistent range of values.
The S8 datasets show significant variability, evident in their standard deviations (46.41 for DSM and 49.87 for DTM). This high variability suggests a diverse set of measurements, which could indicate the heterogeneous nature of the samples or the measurement process itself. The means of the DSM (365.45) and DTM (360.37) datasets are relatively close. However, the DTM dataset shows a slightly lower mean. The ranges of the datasets are broad, emphasizing the spread of values in both cases. Interestingly, the maximum values are nearly identical (451.40 for DSM and 451.37 for DTM). However, the minimum value for DTM (224.83) is significantly lower than that for DSM (235.42).
For the S9 datasets, both DSM and DTM present similar statistical profiles with slight differences. The mean value of the DSM dataset is 638.30, slightly higher than the DTM’s 630.69, indicating a marginally higher average measurement in the DSM dataset. The standard deviation for DSM (33.60) and DTM (33.88) are nearly identical, suggesting a similar level of variability within both datasets. As expected, the maximum value is higher in the DSM dataset (753.49) than in the DTM dataset (733.79). Conversely, the minimum value is slightly lower in the DTM dataset, showing a broader range in the DSM dataset. In
Figure 9, the normal distribution that was fitted for each subset/region has been depicted to help comprehend the position of the network’s input (DSM) with regard to the network’s output (DTM).
4.1.3. ALS2DTM Datasets
The ALS2DTM project employs two distinct subsets of ALS point clouds, known as the DALES and NB datasets (see
Figure 10). These datasets are integral to the development and evaluation of algorithms for generating DTM from ALS data [
31].
The DALES dataset is designed for ongoing research in ALS point clouds and enriched with reference DTM data, thus proving valuable for training CNNs for DTM generation. It represents a uniform terrain type, aiding in the development of models capable of effectively processing ALS point cloud data.
In contrast, the NB dataset, collected from the New Brunswick region, encompasses a wider range of elevations, including urban, rural, forested, and mountainous areas. This diversity introduces additional complexity, crucial for assessing the robustness and adaptability of DTM generation algorithms. The Aerial Laser Scanner (ALS) point clouds in the NB dataset are meticulously produced and processed, ensuring high data integrity and quality.
The characteristics of these datasets are encapsulated in
Table 5, while their semantic information is shown in
Table 6.
For the DALES dataset, we observe that the DSM statistics exhibit a slightly higher mean (56.51) compared to the DTM and last-return, which have means of 53.14 and 54.68, respectively. This indicates that, on average, the surface elevation values in the DSM are slightly higher than those in the DTM and last-return datasets. The standard deviation is fairly consistent across all three, suggesting similar variability in elevation values. The maximum value is significantly higher in the DSM (196.89) compared to the DTM, yet it is almost equal to the last-return maximum. The DSM shows a slightly less negative minimum value, which suggests the presence of fewer extremely low elevation values. The minimum values in both cases are within a comparable range. The medians are close, with the DSM’s median being the highest, which aligns with its higher mean. In terms of the 95th and 5th percentiles, the DSM again shows higher values, suggesting that while the bulk of its data is similar to the other two datasets, it has higher extreme values (
Table 7).
In contrast, the NB dataset shows a different trend. The DSM’s mean (144.38) is notably higher than that of the DTM (136.77) and the last return (137.49), indicating a greater average elevation in the DSM data. The standard deviations are quite high across all datasets, indicating a wide range of elevation values, with the DSM showing the highest variability. The maximum elevation values are again highest for the DSM, reinforcing the idea that it captures higher elevation points more frequently than the DTM and last-return. The minimum values show that the DSM dataset contains an extremely low elevation value (−18.02), which could be an outlier or indicate a wider range of elevation data captured. The median values are relatively close, with the DSM having the highest, aligning with its higher mean and suggesting a higher central tendency in elevation. The 95th and 5th percentiles for the DSM are also the highest among the three datasets, indicating that its elevation values are skewed higher both at the upper and lower ends of the dataset (
Table 7).
To have a better understanding of each of the two, the fitted normal distributions of them are illustrated in
Figure 11.
4.1.4. Consolidated Analysis of Datasets
In order to gain a comprehensive understanding of the relationship between different datasets, a thorough examination of all datasets is carried out collectively. To facilitate this analysis,
Figure 12 and
Figure 13 are presented, which graphically illustrate the distribution of DSMs and DTMs of USGS and ALS2DTM datasets, respectively.
Figure 14 provides a detailed summary of the mean value of DSM and DTM of all datasets, along with their respective standard deviations. To facilitate a better understanding of the distinction between DSM and DTM,
Figure 15 illustrates this difference. Additionally, the distribution of RT and KW datasets, which are different from others, are separately depicted in
Figure 16. These illustrations provide a clear and concise overview of the datasets’ characteristics, enabling researchers to draw meaningful conclusions.
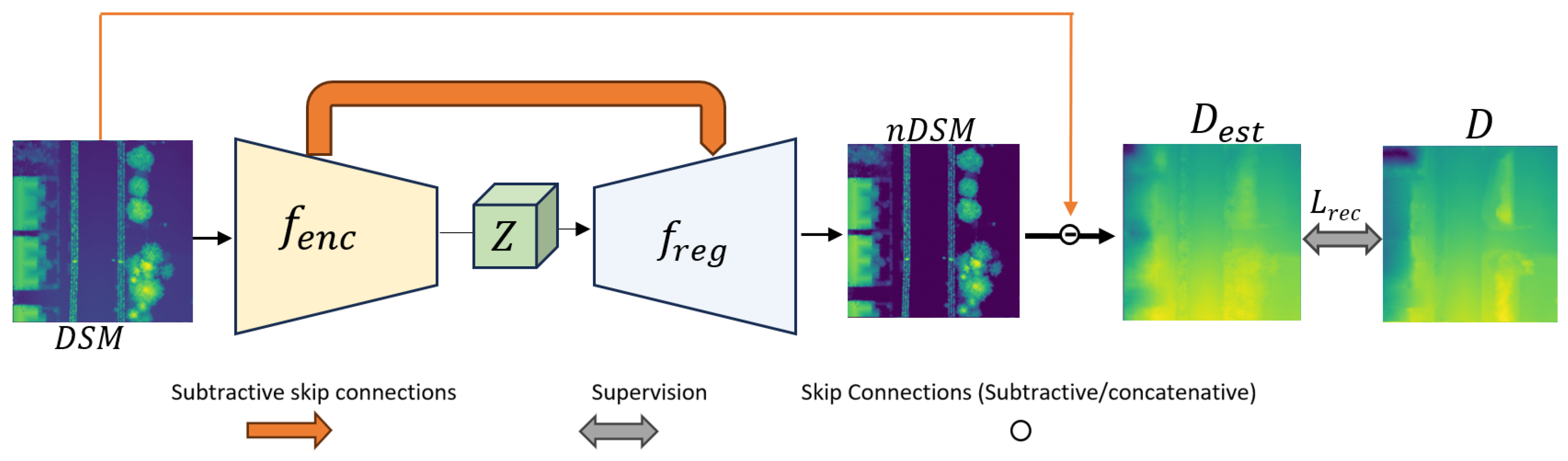
4.3. Quality Assessment Criteria
Our study employs a widely used framework for quality assessment, which is based on estimated values. This category is central to understanding the accuracy of our predictions. It includes traditional metrics like the Root Mean Squared Error (RMSE), Equation (
6), the Mean Absolute Error (MAE), Equation (
7), and AbsRel as relative error, Equation (
8). RMSE measures the square root of the average squared differences between predictions and actual values, while MAE calculates the average of the absolute differences [
39].
where
T is the total number of observations, and
and
are the predicted and ground truth values, respectively. To offer a comprehensive measure of system performance by integrating key dimensions into a single indicator, a performance index (PI) is used. This index is crucial for evaluating and enhancing the reliability and efficiency of various systems, as it provides a holistic view that incorporates both consistency and accuracy of performance.
To construct the PI, a linear combination of the standard deviation (
Std) and the average error (
AE) is employed. These two metrics are fundamental in reflecting the system’s stability and accuracy. The standard deviation expresses the consistency of the system’s performance, while the average error highlights the system’s deviation from expected outcomes. This integration offers a balanced perspective on system performance, making the PI a valuable tool for system analysis [
40].
The formula for the PI is given by:
where
a and
b are coefficients that determine the relative importance of the standard deviation and the average error, respectively. These coefficients are adjustable, allowing the performance index to be customized to emphasize either consistency or accuracy based on the system’s specific requirements and objectives.
In contexts where both consistency and accuracy are equally important, setting both a and b to 1 provides a balanced approach. This equal weighting simplifies the PI to a sum of the standard deviation and the average error, offering an effective and straightforward measure of system performance. By adopting this approach, the evaluation ensures that both the system’s variability and accuracy are considered simultaneously, providing a comprehensive overview of the system’s overall stability and efficiency.
4.5. Discussion
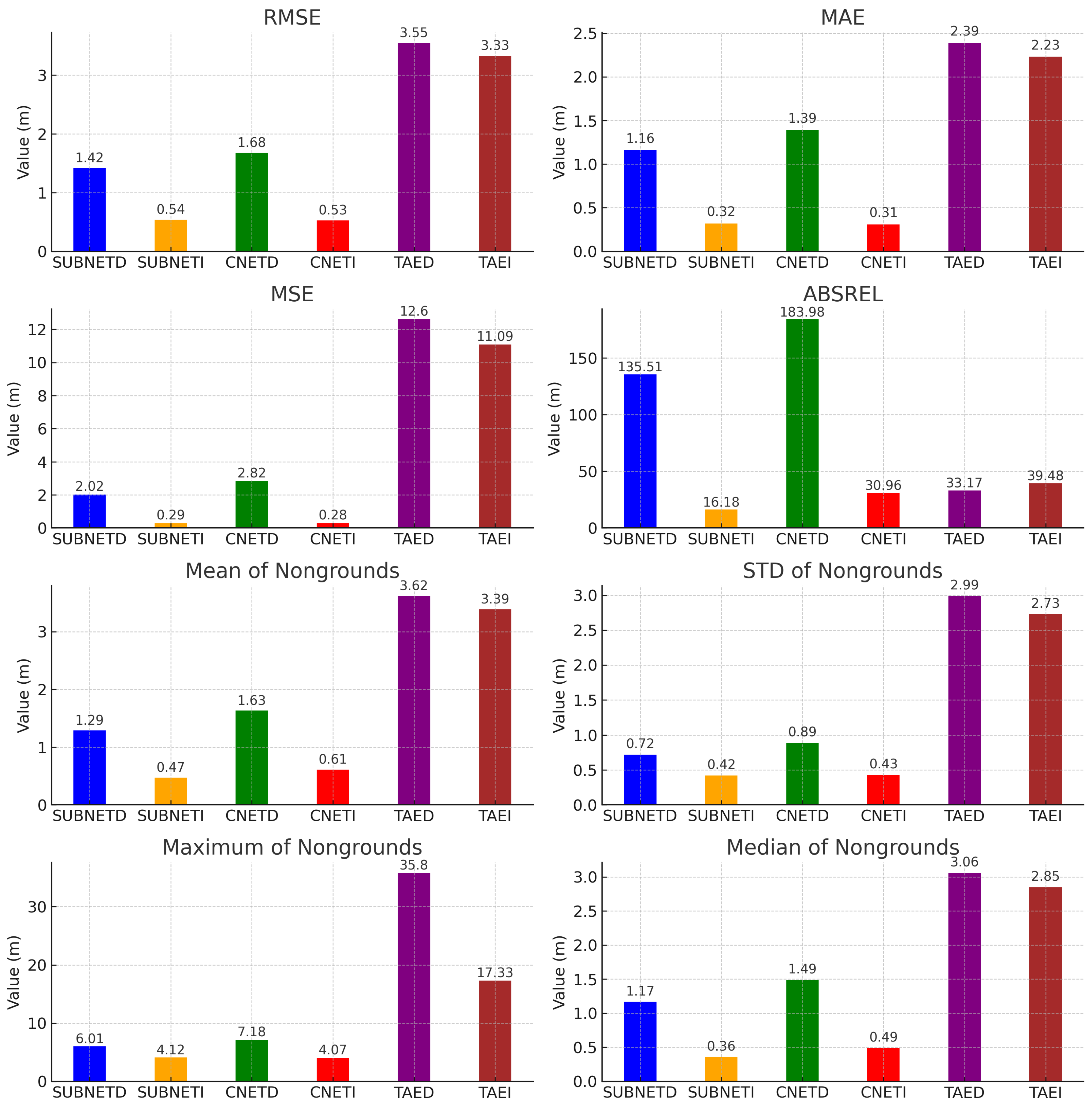
As can be seen from
Figure 17, SUBNETI emerges as the standout method, particularly excelling in minimizing RMSE, MAE, MSE, and ABSREL values (See
Section 4.3). This superiority can be attributed to its algorithmic efficiency in handling the absolute differences between the output and the target, as highlighted by the provided equations. The ABSREL metric, calculated as the mean of the absolute differences divided by the target, is significantly lower for SUBNETI, indicating its superior performance in relative error reduction. This is crucial because it demonstrates SUBNETI’s ability to maintain accuracy proportionally across varying scales of target values, making it especially reliable in applications where precision relative to the magnitude of the measurement is critical.
Conversely, TAED and TAEI show poorer performance across these metrics, with particularly high values in RMSE, MSE, and ABSREL. The elevated MSE and RMSE values suggest a greater variance in their errors, and the high ABSREL values indicate a pronounced relative error, which could be due to less effective handling of the absolute differences between the output and the target. This inefficiency is further exacerbated in complex scenarios where maintaining a proportional relationship between errors and target values is essential for accuracy.
Regarding nonground area statistics, SUBNETI again leads with the lowest mean, STD, and very competitive median values. These statistics are critical for evaluating the methods’ ability to closely approximate the ground truth in nonground areas, with a particular emphasis on consistency and reliability as reflected by the Std and median values. The superior performance of SUBNETI in these criteria suggests a methodological advantage in minimizing variations and biases in nonground area estimations, likely due to more sophisticated processing of spatial data and an effective balancing of sensitivity to outliers, as evidenced by its optimal maximum of nonground and minimum of nonground values.
CNETI follows SUBNETI in performance, offering a balanced profile that, while not achieving the lowest values in every criterion, demonstrates robustness across both ground and nonground area analyses. This suggests that CNETI, similar to SUBNETI, employs effective strategies for error minimization and consistency in its estimations but may have slight limitations in either its handling of outliers or its adaptability to varying scales of target values, as indicated by its ABSREL performance.
On the other end, TAED’s performance is notably less effective, especially in nonground area statistics, where it records the highest values across mean, STD, and maximum. This indicates a significant deviation from the ground truth, possibly due to the method’s lower sensitivity to fine-grained spatial variations or a propensity to be influenced by outliers, as suggested by its high maximum of nonground values. Such characteristics might stem from algorithmic constraints or less optimized processing techniques for spatial data, leading to increased variability and less accuracy in representing nonground areas.
The analysis underscores the importance of method selection based on specific needs and contexts. For applications requiring high relative accuracy and consistency in both ground and nonground areas, SUBNETI is clearly the preferred choice. However, for contexts where a balance between performance and possibly other considerations, such as computational efficiency or ease of implementation, is needed, CNETI presents a viable alternative. The lesser performance of TAED and TAEI, particularly in nonground area statistics, highlights the challenges in optimizing for both accuracy and consistency, emphasizing the need for further development or application-specific adjustments to these methods.
Following a comparative analysis of various states of our proposed method, this study compares SUBNETI with its competitor, CNETI the results of which have been brought in
Table 9. In order to determine the stability of the two methods, a comparison was made between them. To achieve this, a five-fold cross-validation was conducted for both methods, and the results were documented in tables.
The stability of a system can be measured by its Std and the PI values, which is a linear combination of Std and the average error (see
Section 4.3). A lower value of Std and PI indicates a more reliable performance. When it comes to stability, SUBNETI outperforms other systems, as it generally exhibits lower Std values for metrics, including RMSE, MAE, MSE, ABSREL, mean, and median.
Efficiency can be inferred from the MSE and RMSE values, metrics that quantify the error magnitude in predictions. SUBNETI and CNETI show comparable performance in terms of MAE. However, SUBNETI edges slightly in RMSE, suggesting it is more efficient at minimizing squared errors, a crucial aspect when high error magnitudes are significantly penalized. The lower PI values for SUBNETI across most metrics further support its efficiency, indicating it performs well on average and does so with more excellent reliability.
Accuracy is often assessed through metrics like RMSE, MAE, and ABSREL, which directly measure error magnitude and relative error. SUBNETI’s marginally better RMSE and significantly better ABSREL values suggest it is more accurate in capturing the actual signal with fewer and less severe errors, particularly in relative terms. This is essential when accuracy relative to the magnitude of the target values is critical, as in many geospatial applications where the range of expected values can vary widely. While SUBNETI and CNETI have almost similar maximum values, the former yields more favorable outcomes overall. This is primarily due to its higher median, mean, and PI values, which indicate a more balanced and consistent performance. Consequently, SUBNETI is deemed to provide better and more reliable results compared to CNETI.
Subsequent analysis entails evaluating each dataset’s performance by comparing the RMSE, maximum error, and distribution of median error between the two. The RMSE comparison plot,
Figure 18, immediately highlights the superior performance of SUBNETI across all datasets. This superiority is particularly noteworthy in datasets with high variability, such as S8 and KW, where the standard deviation in both DSM and DTM is significant. The ability of SUBNETI to achieve lower RMSE values in these contexts suggests it is better equipped to handle the complexity introduced by terrain variability. This is crucial in applications where accurate ground-level estimation is paramount, as it indicates a consistent ability to closely match the ground truth DTM, even in challenging environments.
When considering the maximum error comparison plot alongside the dataset characteristics,
Figure 19, we gain insight into each method’s ability to manage outliers and extreme values. For example, the S8 dataset, characterized by its high DSM and DTM standard deviations, presents a challenging scenario for DTM estimation. The plot reveals that SUBNETI generally produces lower maximum errors compared to CNETI, indicating its robustness against extreme terrain variations. This aspect of performance is crucial for applications where even rare, extreme errors can have significant consequences, affirming the value of SUBNETI’s approach in maintaining accuracy across various conditions.
The median error along with std, brought in
Table 9, provide a representation of the variability and central tendency of errors for both methods. In datasets like RT and SUII, which exhibit lower variability in their DSM and DTM characteristics, SUBNETI not only maintains lower median errors but also demonstrates a tighter distribution of errors, as evidenced by the smaller interquartile ranges and the standard deviation represented by the vertical dashed lines. This tighter error distribution underscores SUBNETI’s precision and reliability, showcasing its effectiveness in providing consistent DTM estimations across different terrains.
Integrating the the above-mentioned results with the DSM and DTM characteristics, highlighted in
Figure 14, allows for a more comprehensive assessment of the methods. The variability and complexity captured in the dataset characteristics illuminate why SUBNETI’s performance is particularly commendable. Its ability to handle datasets with high variability (e.g., S8 and KW) while still minimizing RMSE and maximum errors highlights its robustness and adaptability. Conversely, its precision in datasets with lower variability (e.g., RT and SUII) showcases its reliability and consistency, making it a versatile tool for DTM estimation. Moreover, the plots serve as a visual testament to these findings, with the RMSE and Max (m) comparisons directly reflecting SUBNETI’s superior performance across a range of conditions and the box plots for Median (m) with Std Deviation offering a granular view of the methods’ error distributions.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}