
DDFNet-A: Attention-Based Dual-Branch Feature Decomposition Fusion Network for Infrared and Visible Image Fusion

Abstract
1. Introduction
- We propose a novel attention-based dual-branch framework for IVIF. This framework considers the characteristics of each modality during the feature processing phase, enhancing the extraction and fusion capabilities specific to these modality characteristic features.
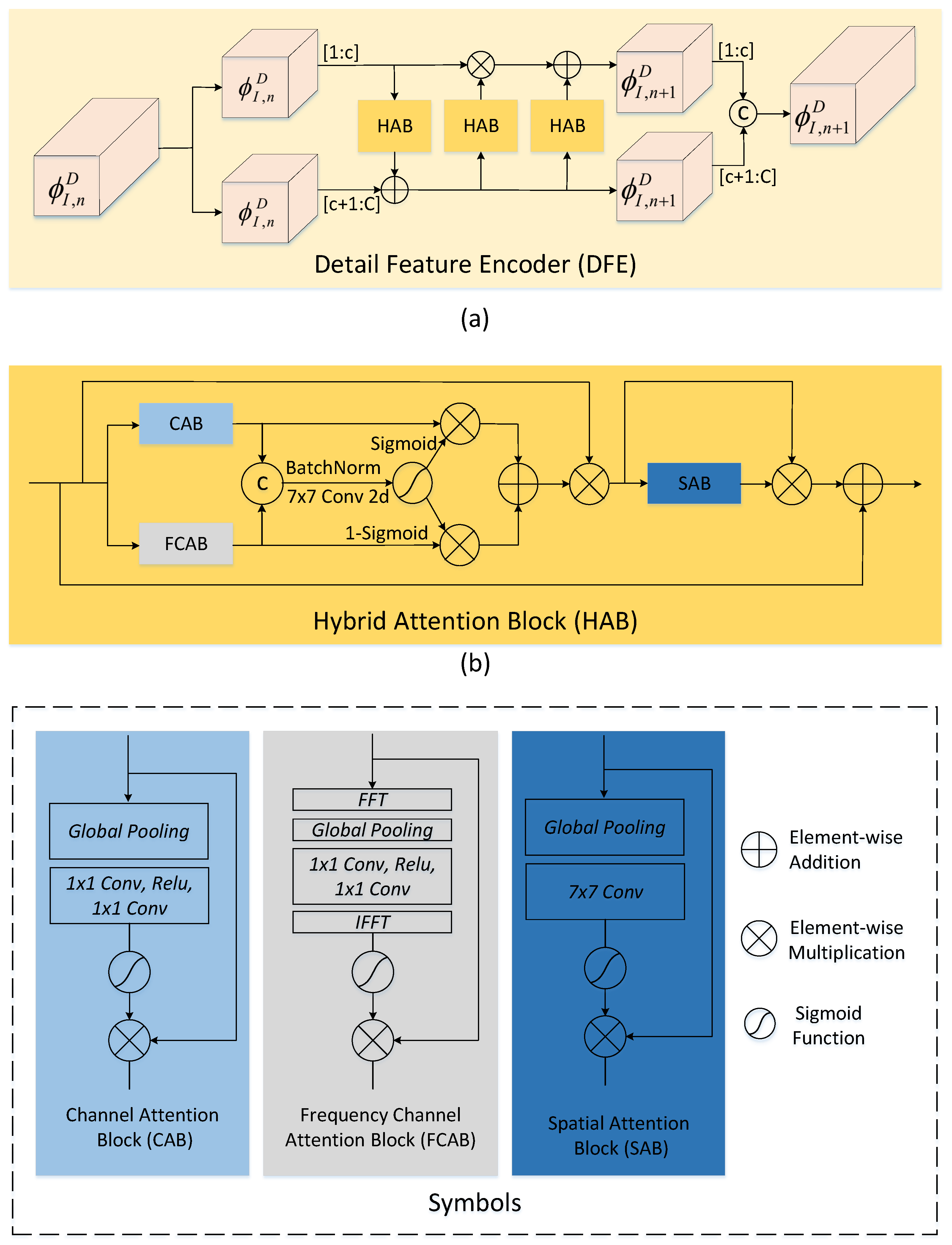
- We propose a hybrid attention block (HAB) to extract high-frequency features. This block can dynamically adjust the weights of the feature maps across the channel, frequency, and spatial dimensions based on their significance to the task.
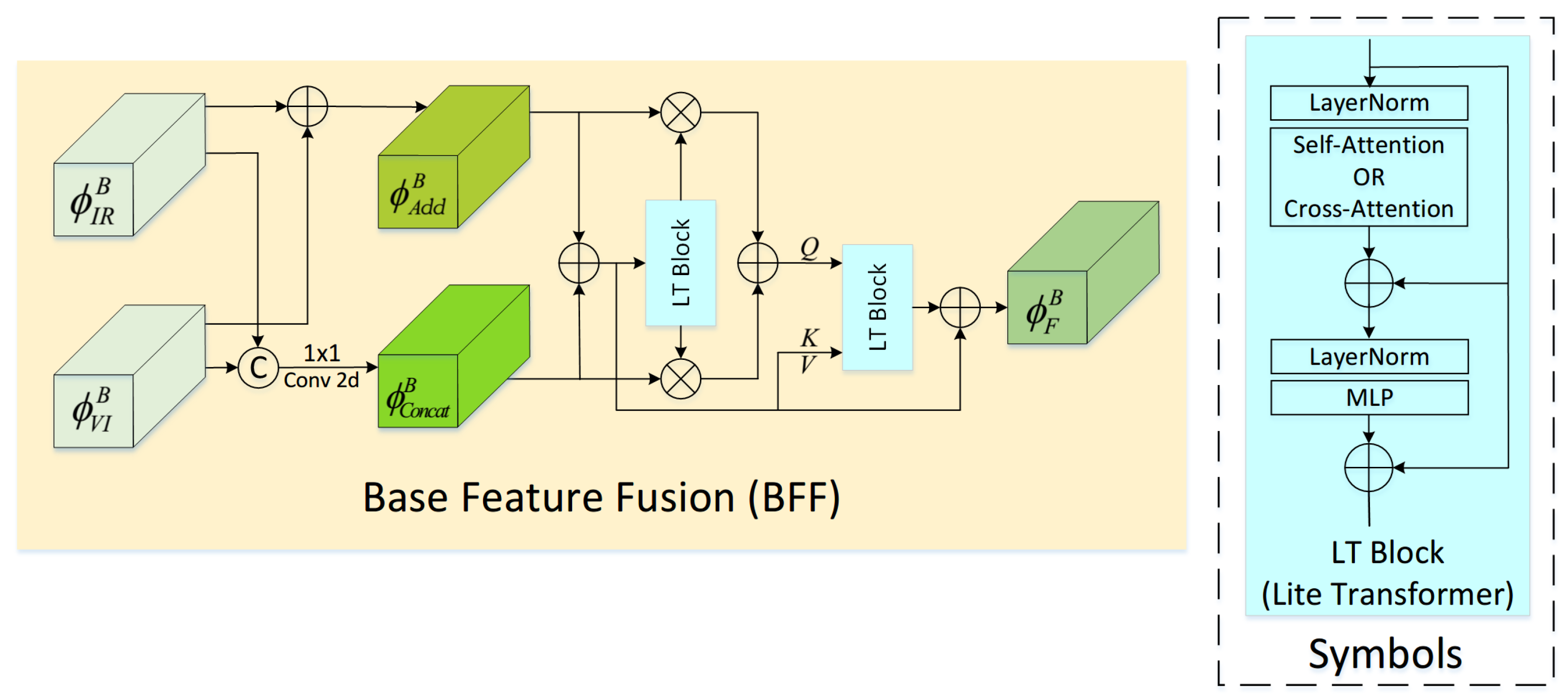
- We propose a base feature fusion (BFF) module to fuse low-frequency features. This module utilizes three-stage fusion strategies to integrate the features of the cross-modality global dependencies.
2. Related Work
2.1. Deep Learning Based IVIF Methods
2.2. Vision Attention Methods
3. Methodology
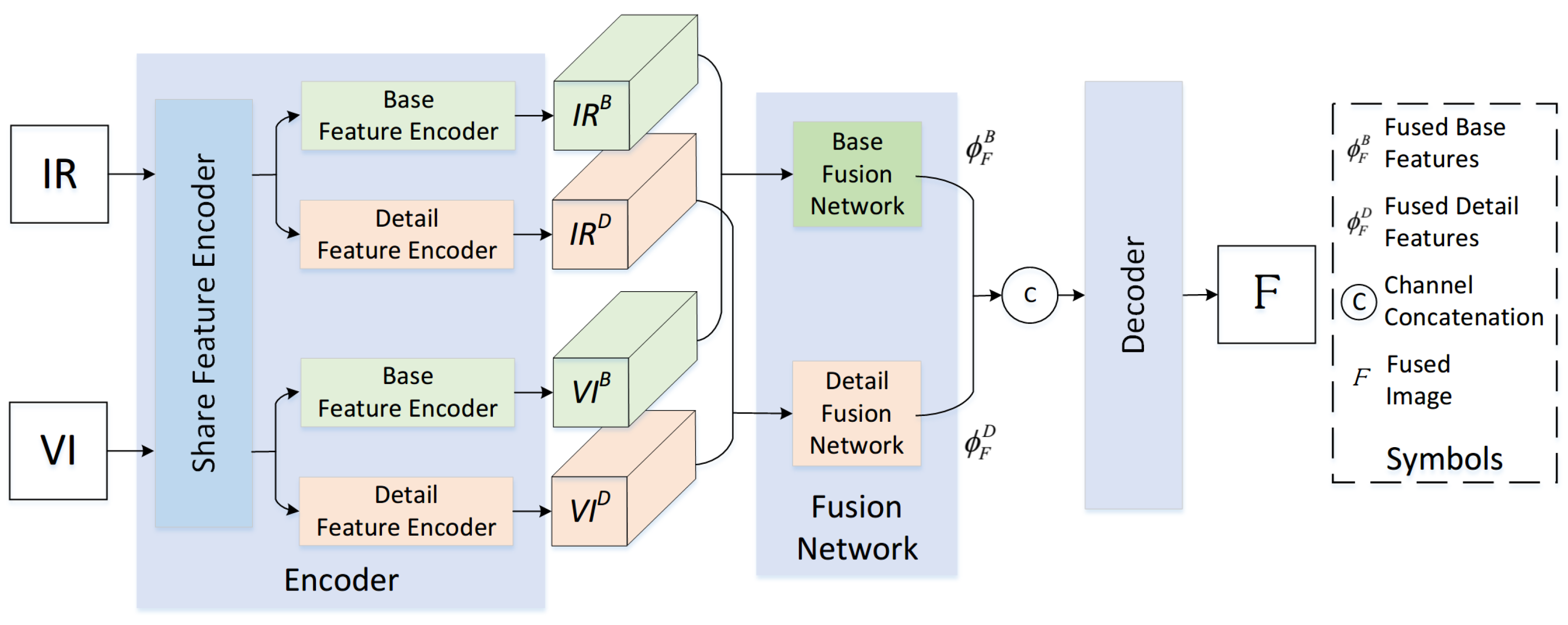
3.1. Overview
3.2. Encoder
3.2.1. Share Feature Encoder
3.2.2. Base Feature Encoder
3.2.3. Detail Feature Encoder
3.3. Fusion Network
3.3.1. Base Feature Fusion
3.3.2. Detail Feature Fusion
3.4. Decoder
3.5. Loss Function
4. Experimental Results and Analysis
4.1. Experiment Setup
4.2. Dataset
4.3. Evaluation Metrics
4.4. Ablation Study
4.5. Comparative Experiments and Analysis
4.5.1. Results on the MSRS Dataset
4.5.2. Results on the TNO Dataset
4.5.3. Results on the VIFB Dataset
4.6. Computational Efficiency Analysis
5. Discussion
6. Generalization Experiments on Multi-Focus Image Fusion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, H.-M.; Wu, J.; Li, B.; Guo, Q.; Zheng, J. An Adaptive Fusion Algorithm for Visible and Infrared Videos Based on Entropy and the Cumulative Distribution of Gray Levels. IEEE Trans. Multimedia 2017, 19, 2706–2719. [Google Scholar] [CrossRef]
- Zhao, W.; Lu, H.; Wang, D. Multisensor Image Fusion and Enhancement in Spectral Total Variation Domain. IEEE Trans. Multimed. 2018, 20, 866–879. [Google Scholar] [CrossRef]
- Rajah, P.; Odindi, J.; Mutanga, O. Feature Level Image Fusion of Optical Imagery and Synthetic Aperture Radar (SAR) for Invasive Alien Plant Species Detection and Mapping. Remote Sens. Appl. Soc. Environ. 2018, 10, 198–208. [Google Scholar] [CrossRef]
- Liu, W.; Yang, J.; Zhao, J.; Guo, F. A Dual-Domain Super-Resolution Image Fusion Method with SIRV and GALCA Model for PolSAR and Panchromatic Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Qiao, D.; Zhao, J.; Peng, S.; Xiao, G. Object Fusion Tracking Based on Visible and Infrared Images Using Fully Convolutional Siamese Networks. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and Cross-Scale Adaptive Fusion Network for Detecting Salient Objects in RGB-D Images. IEEE Trans. Multimed. 2021, 24, 2192–2204. [Google Scholar] [CrossRef]
- He, W.; Feng, W.; Peng, Y.; Chen, Q.; Gu, G.; Miao, Z. Multi-level image fusion and enhancement for target detection. Optik 2015, 126, 1203–1208. [Google Scholar] [CrossRef]
- Schnelle, S.R.; Chan, A.L. Enhanced target tracking through infrared-visible image fusion. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- Bhatnagar, G.; Wu, Q.J.; Raman, B. Navigation and surveillance using night vision and image fusion. In Proceedings of the 2011 IEEE Symposium on Industrial Electronics and Applications, Langkawi, Malaysia, 25–28 September 2011; pp. 342–347. [Google Scholar]
- Bhatnagar, G.; Liu, Z. A novel image fusion framework for night-vision navigation and surveillance. Signal Image Video Process. 2015, 9, 165–175. [Google Scholar] [CrossRef]
- Paramanandham, N.; Rajendiran, K. Multi sensor image fusion for surveillance applications using hybrid image fusion algorithm. Multimed. Tools Appl. 2018, 77, 12405–12436. [Google Scholar] [CrossRef]
- Li, H.; Ding, W.; Cao, X.; Liu, C. Image registration and fusion of visible and infrared integrated camera for medium-altitude unmanned aerial vehicle remote sensing. Remote Sens. 2017, 9, 441. [Google Scholar] [CrossRef]
- Han, L.; Wulie, B.; Yang, Y.; Wang, H. Direct fusion of geostationary meteorological satellite visible and infrared images based on thermal physical properties. Sensors 2015, 15, 703–714. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and Visible Image Fusion Based on Target-Enhanced Multiscale Transform Decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Visible and NIR Image Fusion Using Weight-Map-Guided Laplacian–Gaussian Pyramid for Improving Scene Visibility. Sādhanā 2017, 42, 1063–1082. [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.S.; Han, J.; Tao, D. Sparse Representation Based Multi-Sensor Image Fusion for Multi-Focus and Multi-Modality Images: A Review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A Novel Multi-Modality Image Fusion Method Based on Image Decomposition and Sparse Representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-Sensor Image Fusion Based on Fourth Order Partial Differential Equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A General Image Fusion Framework Based on Convolutional Neural Network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network Based on Proportional Maintenance of Gradient and Intensity. Proc. Aaai Conf. Artif. Intell. 2020, 34, 12797–12804. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Zhao, Z.; Bai, H.; Zhang, J.; Zhang, Y.; Xu, S.; Lin, Z.; Timofte, R.; Van Gool, L. CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canad, 17–24 June 2023; pp. 5906–5916. [Google Scholar]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83–84, 79–92. [Google Scholar] [CrossRef]
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A visible and infrared image fusion benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 104–105. [Google Scholar]
- Xu, H.; Gong, M.; Tian, X.; Huang, J.; Ma, J. CUFD: An Encoder–Decoder Network for Visible and Infrared Image Fusion Based on Common and Unique Feature Decomposition. Comput. Vis. Image Underst. 2022, 218, 103407. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wu, Y.; Xu, J.; Zhang, X. UNFusion: A Unified Multi-Scale Densely Connected Network for Infrared and Visible Image Fusion. IEEE Trans. Circ. Syst. Video Technol. 2022, 32, 3360–3374. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zhang, C.; Liu, J.; Zhang, J.; Li, P. DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7 January 2021; p. 976. [Google Scholar]
- Li, H.; Wu, X. CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach. Inf. Fuison. 2024, 103, 102147. [Google Scholar] [CrossRef]
- Ji, C.; Zhou, W.; Lei, J.; Ye, L. Infrared and Visible Image Fusion via Multiscale Receptive Field Amplification Fusion Network. IEEE Signal Process. Lett. 2023, 30, 493–497. [Google Scholar] [CrossRef]
- Luo, X.; Wang, J.; Zhang, Z.; Wu, X. A full-scale hierarchical encoder-decoder network with cascading edge-prior for infrared and visible image fusion. Pattern Recogn. 2024, 148, 110192. [Google Scholar] [CrossRef]
- Wang, H.; Shu, C.; Li, X.; Fu, Y.; Fu, Z.; Yin, X. Two-Stream Edge-Aware Network for Infrared and Visible Image Fusion with Multi-Level Wavelet Decomposition. IEEE Access. 2024, 12, 22190–22204. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An Infrared and Visible Image Fusion Network Based on Salient Target Detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image Fusion in the Loop of High-Level Vision Tasks: A Semantic-Aware Real-Time Infrared and Visible Image Fusion Network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Li, J.; Liu, J.; Zhou, S.; Zhang, Q.; Kasabov, N. Infrared and visible image fusion based on residual dense network and gradient loss. Infrared Phys. Technol. 2023, 128, 104486. [Google Scholar] [CrossRef]
- Pan, Z.; Ouyang, W. An Efficient Network Model for Visible and Infrared Image Fusion. IEEE Access. 2023, 11, 86413–86430. [Google Scholar] [CrossRef]
- Yang, C.; He, Y.; Sun, C.; Chen, B.; Cao, J.; Wang, Y.; Hao, Q. Multi-scale convolutional neural networks and saliency weight maps for infrared and visible image fusion. J. Vis. Commun. Image Represent. 2024, 98, 104015. [Google Scholar] [CrossRef]
- Tang, H.; Liu, G.; Qian, Y.; Wang, J.; Xiong, J. EgeFusion: Towards Edge Gradient Enhancement in Infrared and Visible Image Fusion with Multi-Scale Transform. IEEE Trans. Comput. Imaging 2024, 10, 385–398. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A Generative Adversarial Network for Infrared and Visible Image Fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and Visible Image Fusion via Detail Preserving Adversarial Learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Rao, Y.; Wu, D.; Han, M.; Wang, T.; Yang, Y.; Lei, T.; Zhou, C.; Bai, H.; Xing, L. AT-GAN: A generative adversarial network with attention and transition for infrared and visible image fusion. Inf. Fusion 2023, 92, 336–349. [Google Scholar] [CrossRef]
- Huang, S.; Song, Z.; Yang, Y.; Wan, W.; Kong, X. MAGAN: Multiattention Generative Adversarial Network for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2023, 72, 1–14. [Google Scholar] [CrossRef]
- Li, K.; Liu, G.; Gu, X.; Tang, H.; Xiong, J.; Qian, Y. DANT-GAN: A dual attention-based of nested training network for infrared and visible image fusion. Digit. Signal Process. 2024, 145, 104316. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2014), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Baur, J.; Steinberg, G.; Nikulin, A.; Chiu, K.; de Smet, T.S. Applying Deep Learning to Automate UAV-Based Detection of Scatterable Landmines. Remote Sens. 2020, 12, 859. [Google Scholar] [CrossRef]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite Transformer with Long-Short Range Attention. arXiv 2020, arXiv:2004.11886. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The Reversible Residual Network: Backpropagation without Storing Activations. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Roberts, J.W.; van Aardt, J.A.; Ahmed, F.B. Assessment of Image Fusion Procedures Using Entropy, Image Quality, and Multispectral Classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Qu, D.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 1–2. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrović, V. Objective Image Fusion Performance Measure. Electron. Lett. 2000, 36, 308. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail Preserved Fusion of Visible and Infrared Images Using Regional Saliency Extraction and Multi-Scale Image Decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. A Non-Reference Image Fusion Metric Based on Mutual Information of Image Features. Comput. Electr. Eng. 2011, 37, 744–756. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A New Quality Metric for Image Fusion. In Proceedings of the 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. III-173. [Google Scholar]
- Liang, P.; Jiang, J.; Liu, X.; Ma, J. Fusion from Decomposition: A Self-Supervised Decomposition Approach for Image Fusion. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 719–735. [Google Scholar]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef]
- Huang, Z.; Liu, J.; Fan, X.; Liu, R.; Zhong, W.; Luo, Z. ReCoNet: Recurrent correction network for fast and efficient multi-modality image fusion. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 539–555. [Google Scholar]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion. Int. J. Comput. Vis. 2021, 129, 2761–2785. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Yuan, J.; Le, Z.; Liu, W. RFNet: Unsupervised Network for Mutually Reinforcing Multi-Modal Image Registration and Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 19679–19688. [Google Scholar]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-Aware Dual Adversarial Learning and a Multi-Scenario Multi-Modality Benchmark To Fuse Infrared and Visible for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Tang, H.; Qian, Y.; Xing, M.; Cao, Y.; Liu, G. MPCFusion: Multi-scale parallel cross fusion for infrared and visible images via convolution and vision Transformer. Opt. Lasers Eng. 2024, 176, 108094. [Google Scholar] [CrossRef]
- Qian, Y.; Liu, G.; Tang, H.; Xing, M.; Chang, R. BTSFusion: Fusion of infrared and visible image via a mechanism of balancing texture and salience. Opt. Lasers Eng. 2024, 173, 107925. [Google Scholar] [CrossRef]
- Zafar, R.; Farid, M.S.; Khan, M.H. Multi-Focus Image Fusion: Algorithms, Evaluation, and a Library. J. Imaging 2020, 6, 60. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Ilyas, A.; Farid, M.S.; Khan, M.H.; Grzegorzek, M. Exploiting Superpixels for Multi-Focus Image Fusion. Entropy 2021, 23, 247. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EN | MI | VIFF | AG | FMI | SSIM | |||
|---|---|---|---|---|---|---|---|---|
| w/o HAB | 6.6047 | 2.7698 | 0.9791 | 0.6623 | 3.6369 | 0.8564 | 0.9288 | 1.4446 |
| w/o BFF | 6.5675 | 2.9265 | 0.9821 | 06729 | 3.6299 | 0.8629 | 0.9301 | 1.4548 |
| DDFNet-A | 6.6169 | 3.0101 | 1.0098 | 0.6804 | 3.6803 | 0.8742 | 0.9313 | 1.4497 |
| EN | MI | VIFF | AG | FMI | SSIM | |||
|---|---|---|---|---|---|---|---|---|
| DeFusion | 6.3508 | 2.1585 | 0.7475 | 0.5149 | 2.5959 | 0.8496 | 0.9191 | 1.4709 |
| DenseFuse | 6.1895 | 1.8692 | 0.7713 | 0.4988 | 2.5033 | 0.8230 | 0.9232 | 1.4559 |
| FusionGAN | 5.4314 | 1.3084 | 0.4422 | 0.1401 | 1.4463 | 0.6280 | 0.9098 | 1.2248 |
| ReCoNet | 4.2337 | 1.5821 | 0.4902 | 0.4039 | 2.9897 | 0.3705 | 0.9116 | 0.6120 |
| SwinFuse | 4.2364 | 1.2340 | 0.3599 | 0.1790 | 1.9313 | 0.2649 | 0.9150 | 0.6393 |
| SDNet | 5.2450 | 1.1835 | 0.4984 | 0.3768 | 2.6720 | 0.6858 | 0.9097 | 1.2180 |
| RFN-Nest | 6.1958 | 1.7010 | 0.6558 | 0.3904 | 2.1074 | 0.7591 | 0.9199 | 1.4031 |
| TarDAL | 6.2079 | 1.8307 | 0.6264 | 0.4116 | 2.9350 | 0.6622 | 0.9079 | 1.0784 |
| U2Fusion | 5.2131 | 1.3781 | 0.5161 | 0.3856 | 2.5062 | 0.7537 | 0.9128 | 1.3556 |
| FSFusion | 6.4183 | 1.9874 | 0.6533 | 0.3978 | 2.4405 | 0.8155 | 0.9101 | 1.4411 |
| MPCFusion | 6.6015 | 1.6065 | 0.6849 | 0.5207 | 4.5313 | 0.8230 | 0.9157 | 1.3699 |
| BTSFusion | 6.2913 | 1.5767 | 0.5675 | 0.4899 | 4.4716 | 0.7854 | 0.9096 | 1.2907 |
| DDFNet-A | 6.6169 | 3.0101 | 1.0098 | 0.6804 | 3.6803 | 0.8742 | 0.9313 | 1.4497 |
| EN | MI | VIFF | AG | FMI | SSIM | |||
|---|---|---|---|---|---|---|---|---|
| DeFusion | 6.5821 | 1.7573 | 0.5528 | 0.3590 | 2.6747 | 0.7871 | 0.9025 | 1.4698 |
| DenseFuse | 6.7783 | 1.6345 | 0.6309 | 0.4449 | 3.4395 | 0.8045 | 0.9071 | 1.4574 |
| FusionGAN | 6.4803 | 1.6277 | 0.4182 | 0.2244 | 2.3625 | 0.6539 | 0.8893 | 1.2785 |
| ReCoNet | 6.6775 | 1.7181 | 0.5307 | 0.3728 | 3.3534 | 0.7182 | 0.8944 | 1.3202 |
| SwinFuse | 6.9037 | 1.6749 | 0.6394 | 0.4275 | 4.7493 | 0.6851 | 0.8921 | 1.2621 |
| SDNet | 6.6401 | 1.5157 | 0.5569 | 0.4374 | 4.6379 | 0.7803 | 0.8997 | 1.3794 |
| RFN-Nest | 6.8919 | 1.5043 | 0.5414 | 0.3363 | 2.6452 | 0.7417 | 0.9035 | 1.3849 |
| TarDAL | 6.7409 | 1.9312 | 0.5522 | 0.4051 | 3.9971 | 0.7551 | 0.8775 | 1.3681 |
| U2Fusion | 6.6527 | 1.3600 | 0.5633 | 0.4465 | 4.1954 | 0.7976 | 0.8918 | 1.4169 |
| FSFusion | 6.9534 | 1.8630 | 0.5531 | 0.3256 | 2.8183 | 0.7315 | 0.8978 | 1.3615 |
| MPCFusion | 6.9778 | 1.4407 | 0.5226 | 0.4249 | 6.0147 | 0.7727 | 0.8927 | 1.3103 |
| BTSFusion | 6.8489 | 1.2582 | 0.5008 | 0.4167 | 6.0484 | 0.7707 | 0.8838 | 1.3054 |
| DDFNet-A | 7.1217 | 2.1620 | 0.7739 | 0.5426 | 4.8858 | 0.8129 | 0.9079 | 1.3894 |
| EN | MI | VIFF | AG | FMI | SSIM | |||
|---|---|---|---|---|---|---|---|---|
| DeFusion | 6.5712 | 2.0439 | 0.5787 | 0.3682 | 3.1811 | 0.7697 | 0.8996 | 1.4831 |
| DenseFuse | 6.9296 | 2.0730 | 0.6406 | 0.4794 | 4.0765 | 0.7994 | 0.8991 | 1.4572 |
| FusionGAN | 6.2852 | 1.6805 | 0.4352 | 0.2348 | 2.7183 | 0.6738 | 0.8911 | 1.3499 |
| ReCoNet | 7.0985 | 2.2150 | 0.6187 | 0.4861 | 4.5147 | 0.7842 | 0.8933 | 1.3841 |
| SwinFuse | 7.0740 | 2.4317 | 0.7428 | 0.5702 | 5.4986 | 0.7829 | 0.8988 | 1.3411 |
| SDNet | 6.5485 | 1.6131 | 0.5380 | 0.5132 | 5.2860 | 0.8019 | 0.8917 | 1.4379 |
| RFN-Nest | 7.0950 | 2.0691 | 0.5941 | 0.4030 | 3.4578 | 0.7766 | 0.8969 | 1.4195 |
| TarDAL | 6.8719 | 2.3674 | 0.5782 | 0.4302 | 4.0870 | 0.7762 | 0.8788 | 1.4267 |
| U2Fusion | 6.8950 | 1.8828 | 0.6270 | 0.5422 | 4.9646 | 0.8195 | 0.8906 | 1.4350 |
| FSFusion | 6.8351 | 2.1459 | 0.5816 | 0.3803 | 3.3717 | 0.7604 | 0.8967 | 1.4549 |
| MPCFusion | 7.0837 | 1.7712 | 0.5859 | 0.5553 | 6.8123 | 0.7979 | 0.8932 | 1.3536 |
| BTSFusion | 6.9426 | 1.7026 | 0.5133 | 0.5042 | 7.1100 | 0.7818 | 0.8775 | 1.3430 |
| DDFNet-A | 7.0925 | 2.4334 | 0.7701 | 0.6423 | 5.6351 | 0.8376 | 0.9095 | 1.4538 |
| Method | DeFusion | DenseFuse | FusionGAN | ReCoNet | SwinFuse | SDNet |
| (unit: seconds) | 15.5950 | 14.2975 | 16.9250 | 68.5425 | 9.8625 | 7.2975 |
| RFN-Nest | TarDAL | U2Fusion | FSFusion | MPCFusion | BTSFusion | DDFNet-A |
| 7.5425 | 14.7625 | 18.7800 | 9.4050 | 16.3950 | 5.8000 | 14.9650 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Q.; Liu, Y.; Jiang, X.; Zhang, B.; Su, Q.; Yu, M. DDFNet-A: Attention-Based Dual-Branch Feature Decomposition Fusion Network for Infrared and Visible Image Fusion. Remote Sens. 2024, 16, 1795. https://doi.org/10.3390/rs16101795
Wei Q, Liu Y, Jiang X, Zhang B, Su Q, Yu M. DDFNet-A: Attention-Based Dual-Branch Feature Decomposition Fusion Network for Infrared and Visible Image Fusion. Remote Sensing. 2024; 16(10):1795. https://doi.org/10.3390/rs16101795
Chicago/Turabian StyleWei, Qiancheng, Ying Liu, Xiaoping Jiang, Ben Zhang, Qiya Su, and Muyao Yu. 2024. "DDFNet-A: Attention-Based Dual-Branch Feature Decomposition Fusion Network for Infrared and Visible Image Fusion" Remote Sensing 16, no. 10: 1795. https://doi.org/10.3390/rs16101795
APA StyleWei, Q., Liu, Y., Jiang, X., Zhang, B., Su, Q., & Yu, M. (2024). DDFNet-A: Attention-Based Dual-Branch Feature Decomposition Fusion Network for Infrared and Visible Image Fusion. Remote Sensing, 16(10), 1795. https://doi.org/10.3390/rs16101795