
SSAformer: Spatial–Spectral Aggregation Transformer for Hyperspectral Image Super-Resolution

 , , and
, , and
Abstract
1. Introduction
- We propose the novel Spatial–Spectral Aggregation Transformer for HSI SR, designed to capture and integrate long-range dependencies across spatial and spectral dimensions. It features spatial and spectral attention modules that effectively extract and integrate spatial and spectral information in HSI SR tasks, significantly enhancing SR performance while maintaining linear computational complexity.
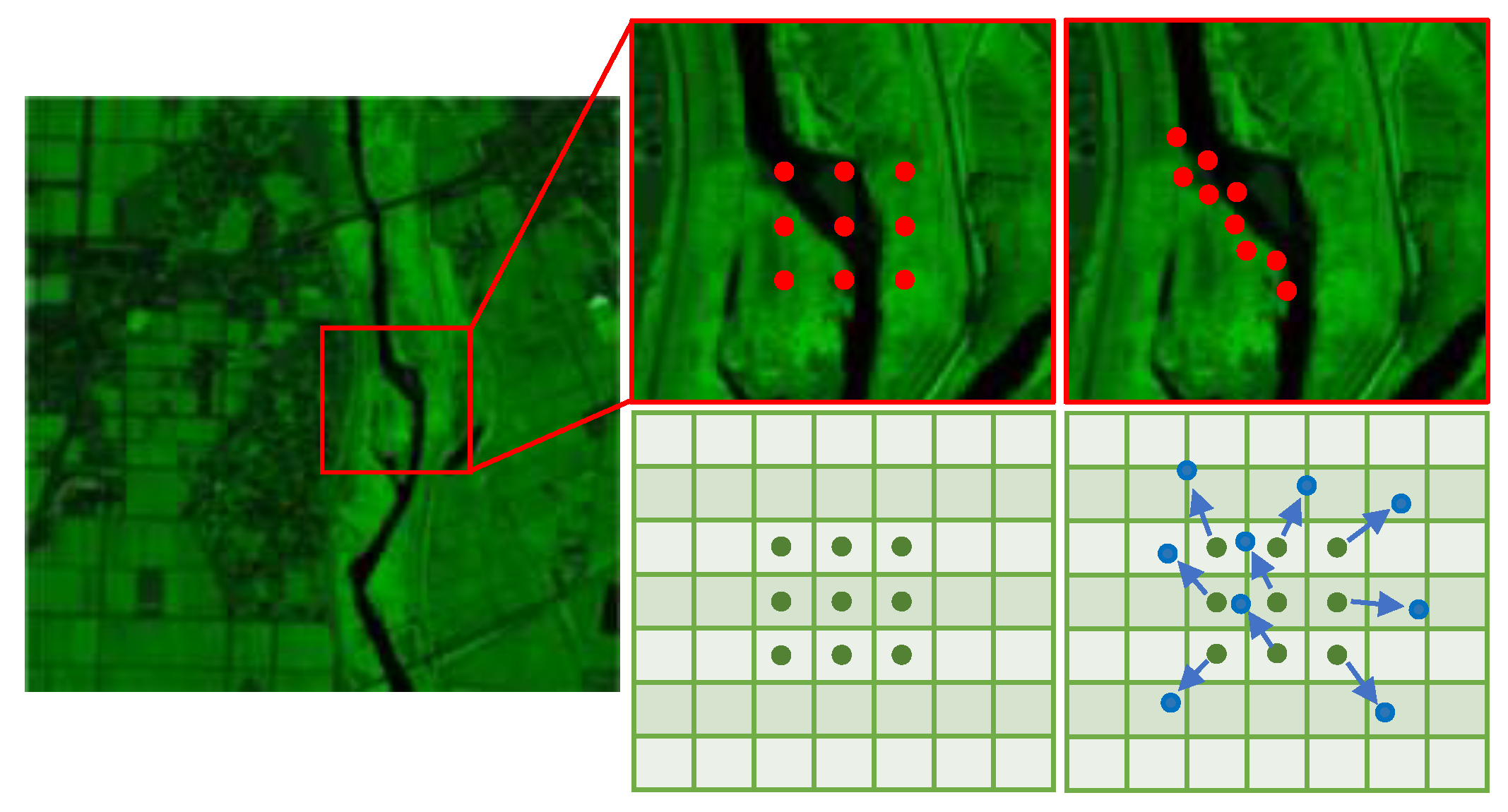
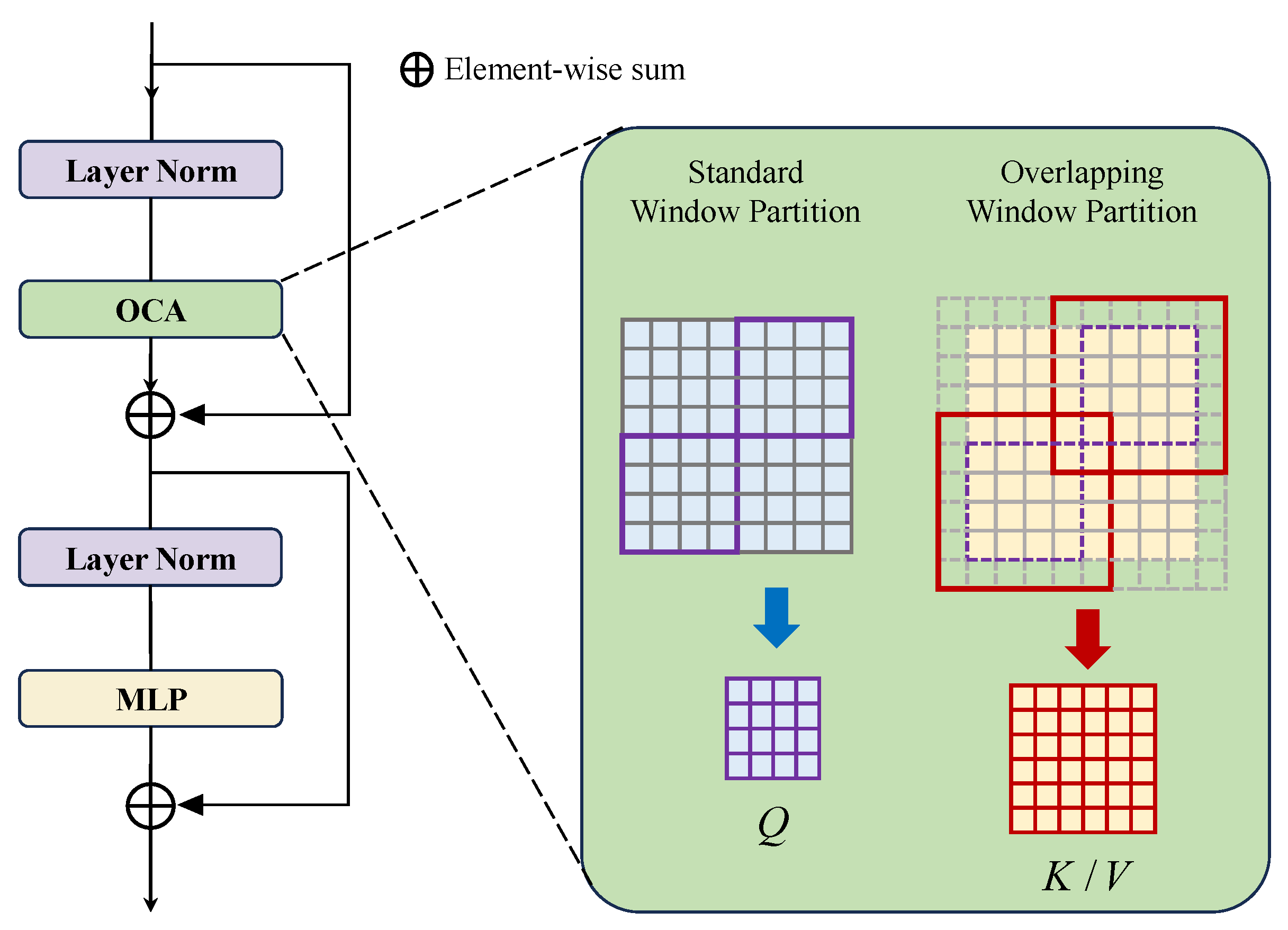
- To achieve long-range spatial dependencies, we construct spatial attention modules, utilizing cross-range spatial self-attention mechanisms within cross-fusion windows to aggregate local and global features, effectively enhancing the model’s perception of spatial details while ensuring the integrity and continuity of spatial information.
- To address the redundancy problem in high-dimensional spectral data of HSIs and effectively capture long-range spectral dependencies, we construct spectral attention modules, combining DCs to perform spatial attention operations, reducing channel redundancy while enhancing the model’s global attention to spectral characteristics.
2. Related Work
2.1. Hyperspectral Image Super-Resolution
2.2. Traditional Methods for Single HSI SR Methods
2.3. Deep Learning Methods for Single HSI SR Methods
2.3.1. CNN-Based Single Hyperspectral Image Super-Resolution
2.3.2. Transformer-Based Single Hyperspectral Image Super-Resolution
3. Methodology
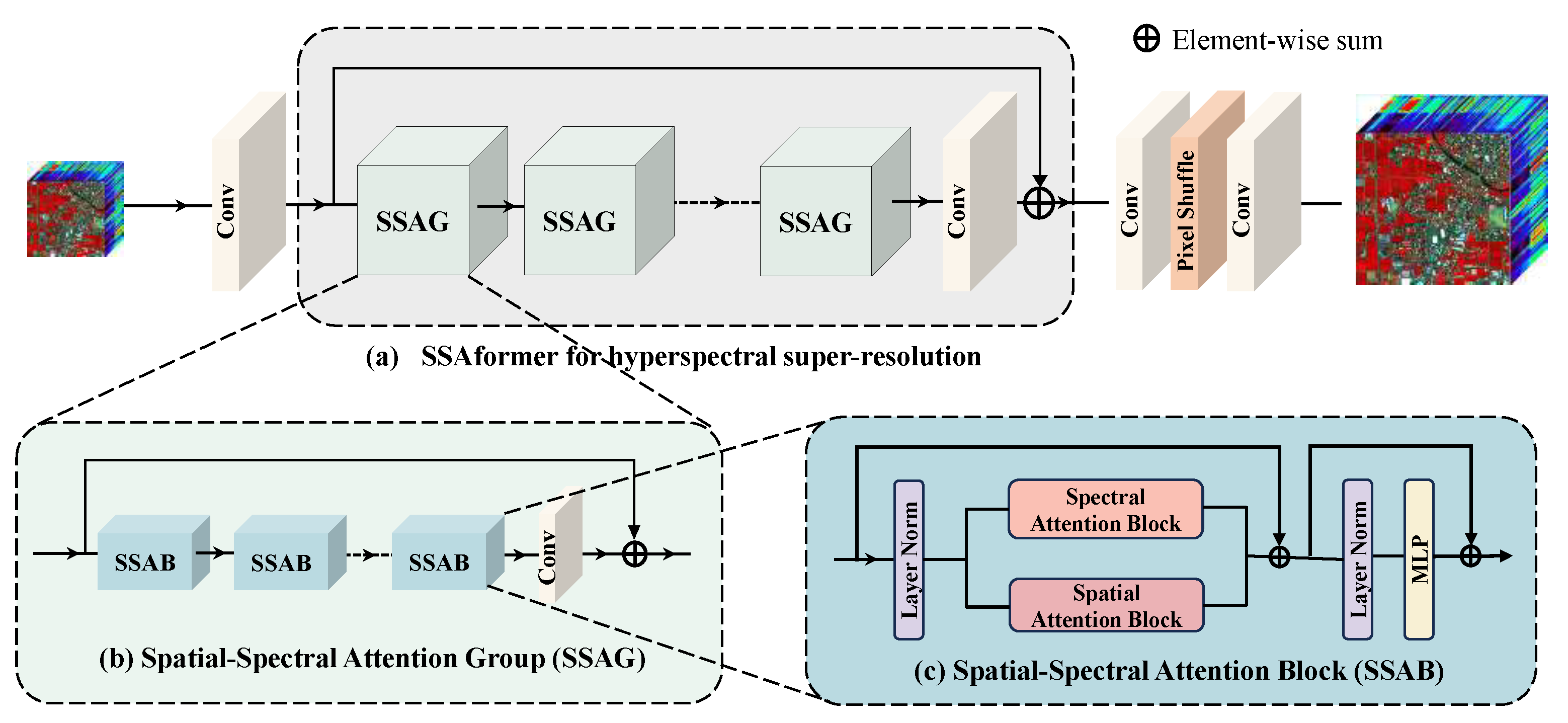
3.1. Overall Architecture
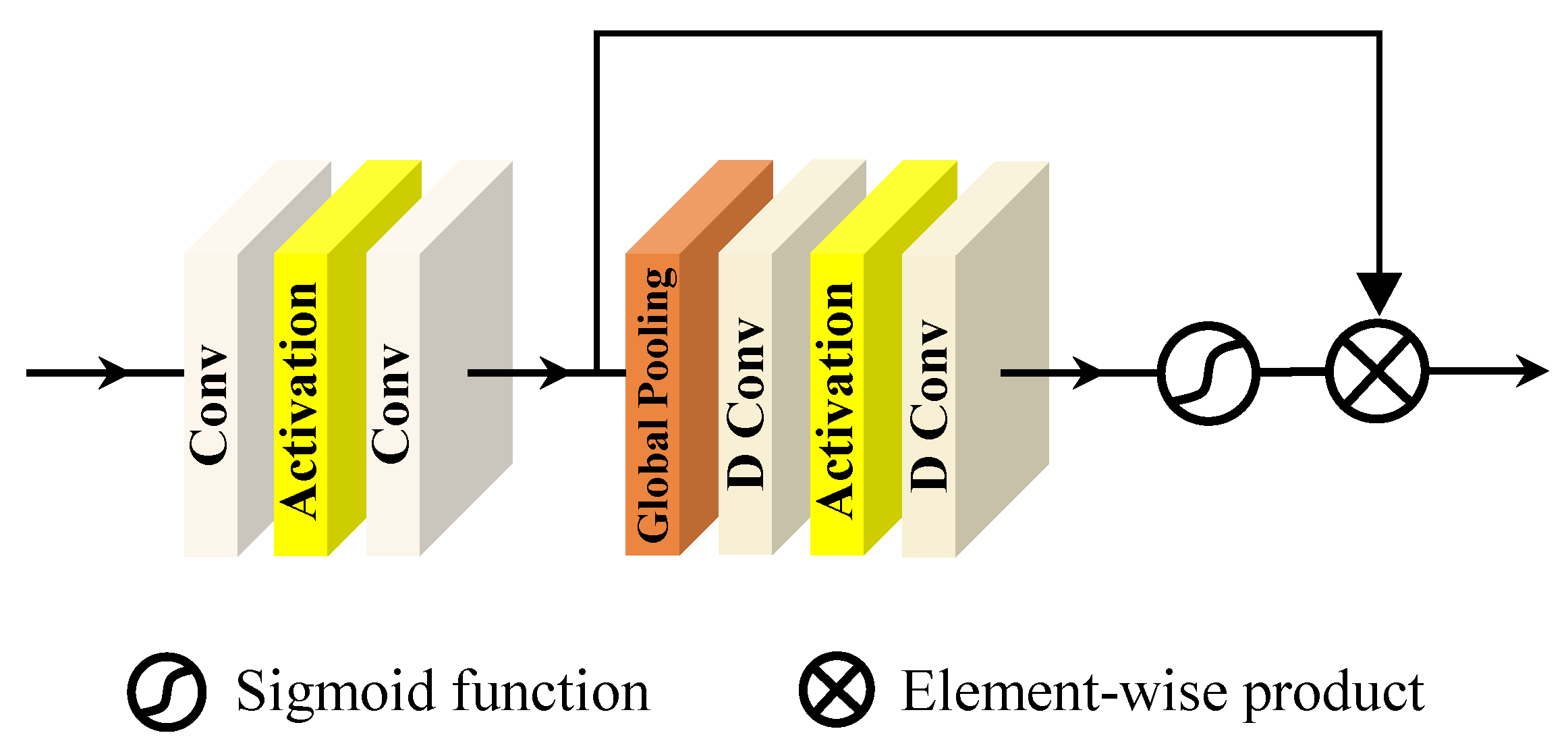
3.2. Spectral Attention Block
3.3. Spatial Attention Block
3.4. Loss Function
4. Experiments and Analysis
4.1. Datasets
- (a)
- Chikusei dataset [51]: The Chikusei dataset captures a wide array of urban and agricultural landscapes in the Chikusei area, Ibaraki Prefecture, Japan. The dataset spans a wavelength range from 363 nm to 1018 nm with 128 spectral bands. Each image boasts a high spatial resolution of 2048 × 2048 pixels. The images encompass diverse scenes, including urban areas, rice fields, forests, and roads, making it suitable for various remote sensing applications.
- (b)
- Houston2018 dataset [52]: The Houston2018 dataset presents hyperspectral urban images collected over the University of Houston campus and the neighboring urban area. This dataset was captured by the ITRES CASI-1500 (ITRES Research Limited, Calgary, Alberta, Canada) hyperspectral sensor, covering a spectral range from 380 nm to 1050 nm across 48 bands. The spatial resolution of the images is 4172 × 1202 pixels. Each image in this collection has a spatial resolution of 1 m per pixel.
- (c)
- Pavia Centre dataset [53]: The Pavia Centre dataset was acquired over the urban center of Pavia, northern Italy, through the Reflective Optics System Imaging Spectrometer (ROSIS). The HSIs in this dataset cover a wavelength range of 430 nm to 860 nm, divided into 102 bands after removing noisy bands. The spatial resolution of the dataset is 1.3 m per pixel, with image dimensions of 1096 × 1096 pixels.
4.2. Implementation Details
4.3. Evaluation Metrics
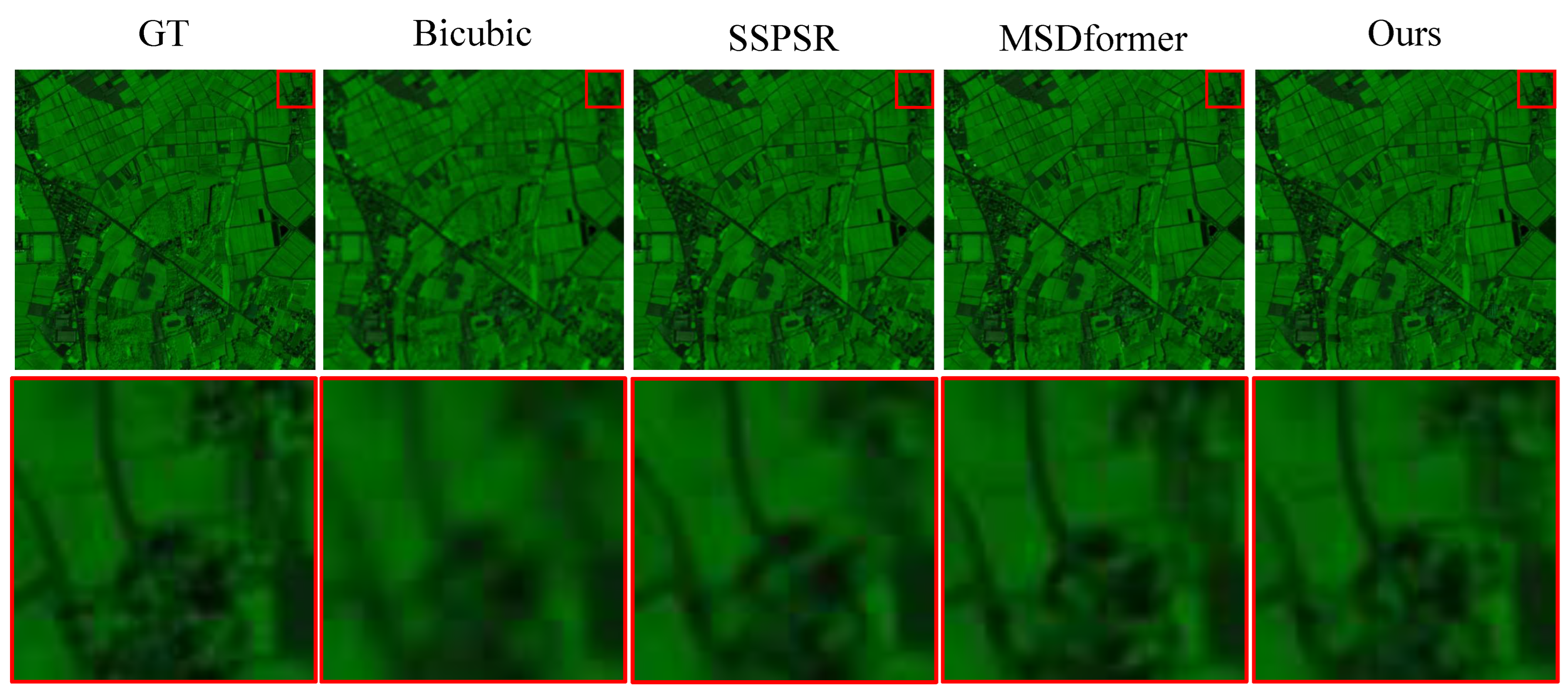
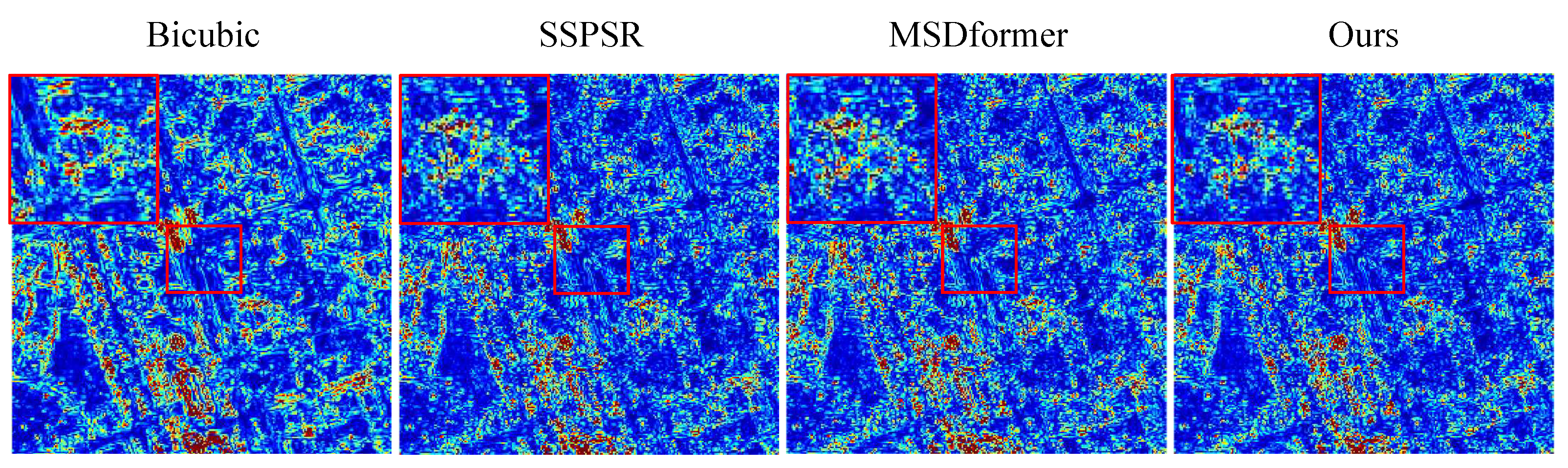
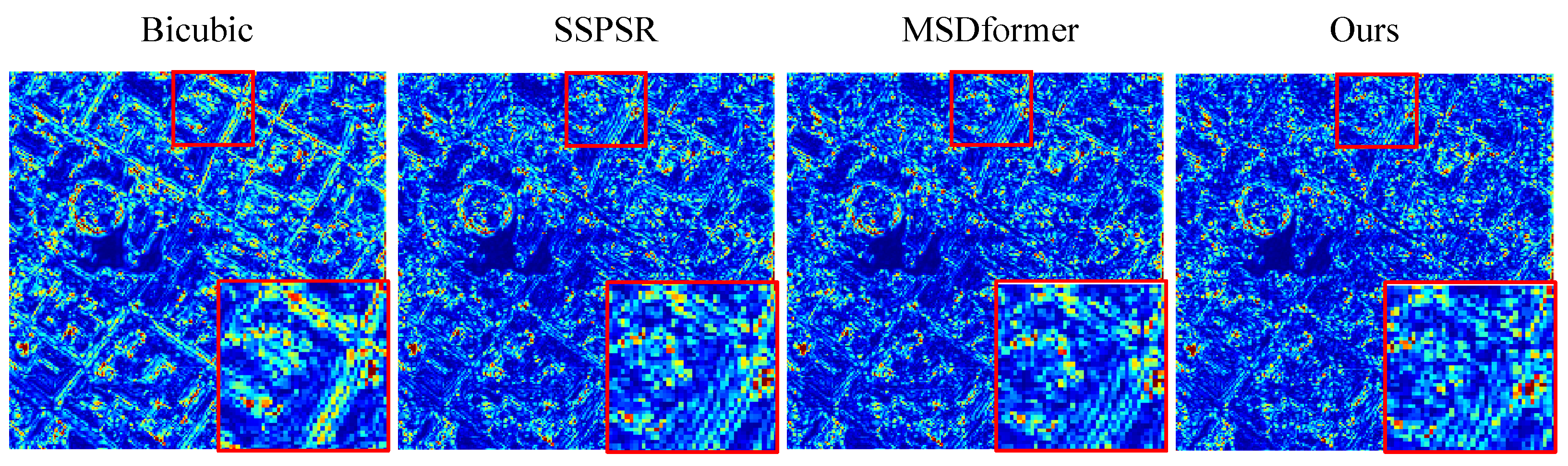
4.4. Comparison with State-of-the-Art SR Methods
4.4.1. Experiments on the Chikusei Datasets
4.4.2. Experiments on the Houston Dataset
4.4.3. Experiments on the Pavia Datasets
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral image |
| SR | Super-resolution |
| HR | High resolution |
| LR | Low resolution |
| CNN | Convolutional neural network |
| SSAformer | Spatial–Spectral Aggregation Transformer |
| DC | Deformable convolution |
| SOTA | State of the art |
| SSAG | Spatial–spectral attention group |
| SSAB | Spatial–spectral attention block |
| MLP | Multilayer perceptron |
| OCA | Overlapping cross-attention |
| SAB | Spatial attention block |
| SEB | Spectral attention block |
| PSNR | Peak signal-to-noise ratio |
| SSIM | Structural similarity index measure |
| SAM | Spectral angle mapper |
| CC | Cross correlation |
| RMSE | Root mean squared error |
| ERGAS | Erreur relative global adimensionnelle de synthèse |
References
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral Imaging for Military and Security Applications: Combining Myriad Processing and Sensing Techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Zhang, Q.; Willmott, M.B. Review of Hyperspectral Imaging in Environmental Monitoring Progress and Applications. Acad. J. Sci. Technol. 2023, 6, 9–11. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Poojary, N.; D’Souza, H.; Puttaswamy, M.R.; Kumar, G.H. Automatic target detection in hyperspectral image processing: A review of algorithms. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1991–1996. [Google Scholar]
- Jiao, L.; Zhang, X.; Liu, X.; Liu, F.; Yang, S.; Ma, W.; Li, L.; Chen, P.; Feng, Z.; Guo, Y.; et al. Transformer Meets Remote Sensing Video Detection and Tracking: A Comprehensive Survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1–45. [Google Scholar] [CrossRef]
- Vivone, G. Multispectral and hyperspectral image fusion in remote sensing: A survey. Inf. Fusion 2022, 89, 405–417. [Google Scholar] [CrossRef]
- Wang, X.; Hu, Q.; Cheng, Y.; Ma, J. Hyperspectral Image Super-Resolution Meets Deep Learning: A Survey and Perspective. IEEE/CAA J. Autom. Sin. 2023, 10, 1668–1691. [Google Scholar] [CrossRef]
- Hu, Y.; Li, X.; Gu, Y.; Jacob, M. Hyperspectral Image Recovery Using Nonconvex Sparsity and Low-Rank Regularizations. IEEE Trans. Geosci. Remote Sens. 2020, 58, 532–545. [Google Scholar] [CrossRef]
- Bodrito, T.; Zouaoui, A.; Chanussot, J.; Mairal, J. A Trainable Spectral-Spatial Sparse Coding Model for Hyperspectral Image Restoration. arXiv 2021, arXiv:2111.09708. [Google Scholar]
- Zhang, M.; Sun, X.; Zhu, Q.; Zheng, G. A Survey of Hyperspectral Image Super-Resolution Technology. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4476–4479. [Google Scholar]
- Chen, C.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z. A Review of Hyperspectral Image Super-Resolution Based on Deep Learning. Remote. Sens. 2023, 15, 2853. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y.R. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. arXiv 2018, arXiv:1807.02758. [Google Scholar]
- Jiang, J.; Sun, H.; Liu, X.; Ma, J. Learning Spatial-Spectral Prior for Super-Resolution of Hyperspectral Imagery. IEEE Trans. Comput. Imaging 2020, 6, 1082–1096. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, L.; Zhang, L. MSDformer: Multiscale Deformable Transformer for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale Residual Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lu, T.; Wang, J.; Zhang, Y.; Wang, Z.; Jiang, J. Satellite Image Super-Resolution via Multi-Scale Residual Deep Neural Network. Remote Sens. 2019, 11, 1588. [Google Scholar] [CrossRef]
- Wang, Y.; Shao, Z.; Lu, T.; Wu, C.; Wang, J. Remote Sensing Image Super-Resolution via Multiscale Enhancement Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5000905. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral Image Spatial Super-Resolution via 3D Full Convolutional Neural Network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution. Remote Sens. 2020, 12, 1660. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored Multiscale Fusion of High-resolution MS and Pan Imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A. Bayesian sparse representation for hyperspectral image super resolution. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 1–7 June 2015; pp. 3631–3640. [Google Scholar]
- Sun, W.; Liu, C.; Li, J.; Lai, Y.M.; Li, W. Low-rank and sparse matrix decomposition-based anomaly detection for hyperspectral imagery. J. Appl. Remote Sens. 2014, 8, 083641. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral Image Restoration Via Total Variation Regularized Low-Rank Tensor Decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1227–1243. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, L.; Tian, C.; Ding, C.; Zhang, Y.; Wei, W. Hyperspectral image super-resolution extending: An effective fusion based method without knowing the spatial transformation matrix. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1117–1122. [Google Scholar]
- Bauschke, H.H.; Borwein, J.M. On Projection Algorithms for Solving Convex Feasibility Problems. SIAM Rev. 1996, 38, 367–426. [Google Scholar] [CrossRef]
- Liu, C.; Fan, Z.; Zhang, G. GJTD-LR: A Trainable Grouped Joint Tensor Dictionary With Low-Rank Prior for Single Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5537617. [Google Scholar] [CrossRef]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral Image Super-Resolution Using Deep Feature Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6055–6067. [Google Scholar] [CrossRef]
- Akgun, T.; Altunbasak, Y.; Mersereau, R. Super-resolution reconstruction of hyperspectral images. IEEE Trans. Image Process. 2005, 14, 1860–1875. [Google Scholar] [CrossRef]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled Nonnegative Matrix Factorization Unmixing for Hyperspectral and Multispectral Data Fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- He, W.; Chen, Y.; Yokoya, N.; Li, C.; Zhao, Q. Hyperspectral Super-Resolution via Coupled Tensor Ring Factorization. Pattern Recognit. 2020, 122, 108280. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Hyperspectral Image Superresolution by Transfer Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, L.; Dingl, C.; Wei, W.; Zhang, Y. Single Hyperspectral Image Super-Resolution with Grouped Deep Recursive Residual Network. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–4. [Google Scholar]
- Jia, J.; Ji, L.; Zhao, Y.; Geng, X. Hyperspectral image super-resolution with spectral–spatial network. Int. J. Remote Sens. 2018, 39, 7806–7829. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 3–5 June 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 29 October 2019. [Google Scholar]
- Liu, Y.; Hu, J.; Kang, X.; Luo, J.; Fan, S. Interactformer: Interactive Transformer and CNN for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5531715. [Google Scholar] [CrossRef]
- Hu, J.; Liu, Y.; Kang, X.; Fan, S. Multilevel Progressive Network With Nonlocal Channel Attention for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5543714. [Google Scholar] [CrossRef]
- Wu, Y.; Cao, R.; Hu, Y.; Wang, J.; Li, K. Combining global receptive field and spatial spectral information for single-image hyperspectral super-resolution. Neurocomputing 2023, 542, 126277. [Google Scholar] [CrossRef]
- Geng, Z.; Guo, M.H.; Chen, H.; Li, X.; Wei, K.; Lin, Z. Is Attention Better Than Matrix Decomposition? arXiv 2021, arXiv:2109.04553. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Zhang, M.; Zhang, C.; Zhang, Q.; Guo, J.; Gao, X.; Zhang, J. ESSAformer: Efficient Transformer for Hyperspectral Image Super-resolution. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 22–29 October 2023; pp. 23016–23027. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Chen, X.; Wang, X.; Zhang, W.; Kong, X.; Qiao, Y.; Zhou, J.; Dong, C. HAT: Hybrid Attention Transformer for Image Restoration. arXiv 2023, arXiv:2309.05239. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Wang, X.; Ma, J.; Jiang, J. Hyperspectral Image Super-Resolution via Recurrent Feedback Embedding and Spatial–Spectral Consistency Regularization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Yokoya, N.; Iwasaki, A. Airborne Hyperspectral Data over Chikusei; The University of Tokyo: Tokyo, Japan, 2016. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hänsch, R.; Le Saux, B. Advanced Multi-Sensor Optical Remote Sensing for Urban Land Use and Land Cover Classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. A comparative study of spatial approaches for urban mapping using hyperspectral ROSIS images over Pavia City, northern Italy. Int. J. Remote Sens. 2009, 30, 3205–3221. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Yuhas, R.H.; Goetz, A.F.H.; Boardman, J.W. Discrimination among Semi-Arid Landscape Endmembers Using the Spectral Angle Mapper (SAM) Algorithm; NTRS: Chicago, IL, USA, 1992. [Google Scholar]
- Loncan, L.; de Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simões, M.; et al. Hyperspectral Pansharpening: A Review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef]
- Wald, L. Data Fusion. Definitions and Architectures—Fusion of Images of Different Spatial Resolutions; Presses des MINES: Paris, France, 2002. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | PSNR↑ | SSIM↑ | SAM↓ | CC↑ | RMSE↓ | ERGAS↓ |
|---|---|---|---|---|---|---|---|
| Bicubic | 43.2125 | 0.9721 | 1.7880 | 0.9781 | 0.0082 | 3.5981 | |
| 3DFCNN [19] | 45.4477 | 0.9828 | 1.5550 | 0.9854 | 0.0064 | 2.9235 | |
| GDRRN [34] | 46.4286 | 0.9869 | 1.3911 | 0.9885 | 0.0056 | 2.6049 | |
| SSPSR [14] | 47.4073 | 0.9893 | 1.2035 | 0.9906 | 0.0051 | 2.3177 | |
| MSDformer [15] | 47.0868 | 0.9882 | 1.1843 | 0.9899 | 0.0054 | 2.3359 | |
| Ours | 47.5984 | 0.9899 | 1.1710 | 0.9908 | 0.0049 | 2.2926 | |
| Bicubic | 37.6377 | 0.8954 | 3.4040 | 0.9212 | 0.0156 | 6.7564 | |
| 3DFCNN [19] | 38.1221 | 0.9079 | 3.3927 | 0.9276 | 0.0147 | 6.4453 | |
| GDRRN [34] | 39.0864 | 0.9265 | 3.0536 | 0.9421 | 0.0130 | 5.7972 | |
| SSPSR [14] | 39.5565 | 0.9331 | 2.5701 | 0.9482 | 0.0125 | 5.4019 | |
| MSDformer [15] | 39.5323 | 0.9344 | 2.5354 | 0.9479 | 0.0126 | 5.4152 | |
| Ours | 39.6955 | 0.9370 | 2.5122 | 0.9490 | 0.0122 | 5.3754 | |
| Bicubic | 34.5049 | 0.8069 | 5.0436 | 0.8314 | 0.0224 | 9.6975 | |
| 3DFCNN [19] | 34.7274 | 0.8142 | 4.9514 | 0.8379 | 0.0218 | 9.4706 | |
| GDRRN [34] | 34.7395 | 0.8199 | 5.0967 | 0.8381 | 0.0213 | 9.6464 | |
| SSPSR [14] | 35.1643 | 0.8299 | 4.6911 | 0.8560 | 0.0206 | 9.0504 | |
| MSDformer [15] | 35.2742 | 0.8357 | 4.4971 | 0.8594 | 0.0207 | 8.7425 | |
| Ours | 35.3241 | 0.8402 | 4.3572 | 0.8599 | 0.0201 | 8.8235 |
| Method | Scale | PSNR↑ | SSIM↑ | SAM↓ | CC↑ | RMSE↓ | ERGAS↓ |
|---|---|---|---|---|---|---|---|
| Bicubic | 49.4735 | 0.9915 | 1.2707 | 0.9940 | 0.0040 | 1.3755 | |
| 3DFCNN [19] | 50.7939 | 0.9941 | 1.2168 | 0.9949 | 0.0034 | 1.1722 | |
| GDRRN [34] | 51.5205 | 0.9949 | 1.1241 | 0.9957 | 0.0031 | 1.0723 | |
| SSPSR [14] | 52.5061 | 0.9958 | 1.0101 | 0.9965 | 0.0028 | 0.9608 | |
| MSDformer [15] | 51.9265 | 0.9952 | 1.0600 | 0.9963 | 0.0030 | 1.0223 | |
| Ours | 52.5905 | 0.9960 | 0.9668 | 0.9968 | 0.0027 | 0.9475 | |
| Bicubic | 43.0272 | 0.9613 | 2.5453 | 0.9741 | 0.0086 | 2.9085 | |
| 3DFCNN [19] | 43.2680 | 0.9669 | 2.6128 | 0.9661 | 0.0079 | 2.8698 | |
| GDRRN [34] | 44.2964 | 0.9730 | 2.5347 | 0.9760 | 0.0069 | 2.4700 | |
| SSPSR [14] | 45.5987 | 0.9779 | 1.8828 | 0.9850 | 0.0063 | 2.1377 | |
| MSDformer [15] | 45.6412 | 0.9782 | 1.8582 | 0.9852 | 0.0062 | 2.1279 | |
| Ours | 45.6457 | 0.9788 | 1.8553 | 0.9850 | 0.0061 | 2.1141 | |
| Bicubic | 38.1083 | 0.8987 | 4.6704 | 0.9177 | 0.0152 | 5.1229 | |
| 3DFCNN [19] | 38.0152 | 0.9030 | 4.7085 | 0.9093 | 0.0146 | 5.0865 | |
| GDRRN [34] | 38.2592 | 0.9085 | 4.9045 | 0.9138 | 0.0140 | 4.9135 | |
| SSPSR [14] | 39.2844 | 0.9164 | 4.2673 | 0.9346 | 0.0130 | 4.4212 | |
| MSDformer [15] | 39.2683 | 0.9165 | 4.0515 | 0.9354 | 0.0131 | 4.4383 | |
| Ours | 39.2320 | 0.9187 | 3.9154 | 0.9439 | 0.0129 | 4.4146 |
| Method | Scale | PSNR↑ | SSIM↑ | SAM↓ | CC↑ | RMSE↓ | ERGAS↓ |
|---|---|---|---|---|---|---|---|
| Bicubic | 32.0583 | 0.9139 | 4.5419 | 0.9491 | 0.0256 | 4.1526 | |
| 3DFCNN [19] | 33.3797 | 0.9369 | 4.6173 | 0.9596 | 0.0219 | 3.6197 | |
| GDRRN [34] | 33.8949 | 0.9428 | 4.7006 | 0.9641 | 0.0206 | 3.4179 | |
| SSPSR [14] | 34.8724 | 0.9525 | 4.0143 | 0.9706 | 0.0185 | 3.0734 | |
| MSDformer [15] | 35.4400 | 0.9601 | 3.5041 | 0.9746 | 0.0173 | 2.9166 | |
| Ours | 35.7317 | 0.9608 | 3.5048 | 0.9760 | 0.0167 | 2.8263 | |
| Bicubic | 27.3222 | 0.7151 | 6.3660 | 0.8493 | 0.0451 | 7.0292 | |
| 3DFCNN [19] | 27.7103 | 0.7546 | 6.5670 | 0.8582 | 0.0429 | 6.7438 | |
| GDRRN [34] | 27.9602 | 0.7695 | 7.1670 | 0.8664 | 0.0414 | 6.5732 | |
| SSPSR [14] | 28.4757 | 0.7911 | 5.7867 | 0.8848 | 0.0392 | 6.2282 | |
| MSDformer [15] | 28.5032 | 0.7929 | 5.7907 | 0.8853 | 0.0390 | 6.2197 | |
| Ours | 28.6199 | 0.7988 | 5.7369 | 0.8883 | 0.0384 | 6.1420 | |
| Bicubic | 24.3714 | 0.4531 | 7.8903 | 0.6763 | 0.0646 | 9.8142 | |
| 3DFCNN [19] | 24.3173 | 0.4532 | 8.1556 | 0.6675 | 0.0647 | 9.8779 | |
| GDRRN [34] | 24.5468 | 0.4777 | 8.4873 | 0.6842 | 0.0630 | 9.6256 | |
| SSPSR [14] | 24.6641 | 0.4942 | 8.3048 | 0.6946 | 0.0620 | 9.4980 | |
| MSDformer [15] | 24.8418 | 0.5097 | 7.8021 | 0.7126 | 0.0608 | 9.4031 | |
| Ours | 24.8468 | 0.5111 | 7.6729 | 0.7134 | 0.0607 | 9.3920 |
| Variant | Params. () | PSNR↑ | SSIM↑ | SAM↓ | CC↑ | RMSE↓ | ERGAS↓ |
|---|---|---|---|---|---|---|---|
| w/o SAB | 13.1866 | 27.9711 | 0.7669 | 6.2027 | 0.8696 | 0.0414 | 6.6139 |
| w/o SEB | 17.7417 | 27.9644 | 0.7663 | 6.1848 | 0.8694 | 0.0415 | 6.6173 |
| w/o DC | 22.4694 | 27.9685 | 0.7665 | 6.1796 | 0.8694 | 0.0415 | 6.6157 |
| Ours | 22.5856 | 28.6199 | 0.7988 | 5.7369 | 0.8883 | 0.0384 | 6.1420 |
| Number (N) | Params. () | PSNR↑ | SSIM↑ | SAM↓ | CC↑ | RMSE↓ | ERGAS↓ |
|---|---|---|---|---|---|---|---|
| N = 3 | 17.1682 | 27.9207 | 0.7647 | 6.3097 | 0.8681 | 0.0417 | 6.6536 |
| N = 4 | 22.5856 | 28.6199 | 0.7988 | 5.7369 | 0.8883 | 0.0384 | 6.1420 |
| N = 5 | 28.0030 | 28.0214 | 0.7695 | 6.1053 | 0.8712 | 0.0412 | 6.5752 |
| N = 6 | 33.4204 | 28.5423 | 0.7941 | 5.8771 | 0.8861 | 0.0387 | 6.2022 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zhang, Q.; Peng, T.; Xu, Z.; Cheng, X.; Xing, Z.; Li, T. SSAformer: Spatial–Spectral Aggregation Transformer for Hyperspectral Image Super-Resolution. Remote Sens. 2024, 16, 1766. https://doi.org/10.3390/rs16101766
Wang H, Zhang Q, Peng T, Xu Z, Cheng X, Xing Z, Li T. SSAformer: Spatial–Spectral Aggregation Transformer for Hyperspectral Image Super-Resolution. Remote Sensing. 2024; 16(10):1766. https://doi.org/10.3390/rs16101766
Chicago/Turabian StyleWang, Haoqian, Qi Zhang, Tao Peng, Zhongjie Xu, Xiangai Cheng, Zhongyang Xing, and Teng Li. 2024. "SSAformer: Spatial–Spectral Aggregation Transformer for Hyperspectral Image Super-Resolution" Remote Sensing 16, no. 10: 1766. https://doi.org/10.3390/rs16101766
APA StyleWang, H., Zhang, Q., Peng, T., Xu, Z., Cheng, X., Xing, Z., & Li, T. (2024). SSAformer: Spatial–Spectral Aggregation Transformer for Hyperspectral Image Super-Resolution. Remote Sensing, 16(10), 1766. https://doi.org/10.3390/rs16101766