
HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data



Abstract
1. Introduction
- (1)
- An HGR correlation pooling fusion algorithm is developed by integrating a feature fusion method with an HGR correlation algorithm. This framework adheres to the principle of relevance correlation and segregates information based on its intrinsic relevance into distinct classification channels. It enables the derivation of loss functions for positive, zero, and negative samples. Then, a tailored overall loss function is designed for the model, which significantly enhances feature learning in multimodal images.
- (2)
- A multimodal remote sensing data recognition and classification model is proposed, which can achieve information separation under maximum utilization. The model enhances the precision and accuracy of target recognition and classification while preserving image information integrity and image quality.
- (3)
- The HGR pooling specifically addresses multimodal pairs (vectors) and intervenes in the information transmission process without changing the value of the transmitted information. It enables inversion operations on positive, zero, and negative sample data in the original signal of the framework, thereby supporting traceability for the restoration of the original signal. This advancement greatly improves the interpretability of the data.
2. Related Work
3. Methodology
3.1. Problem Definition
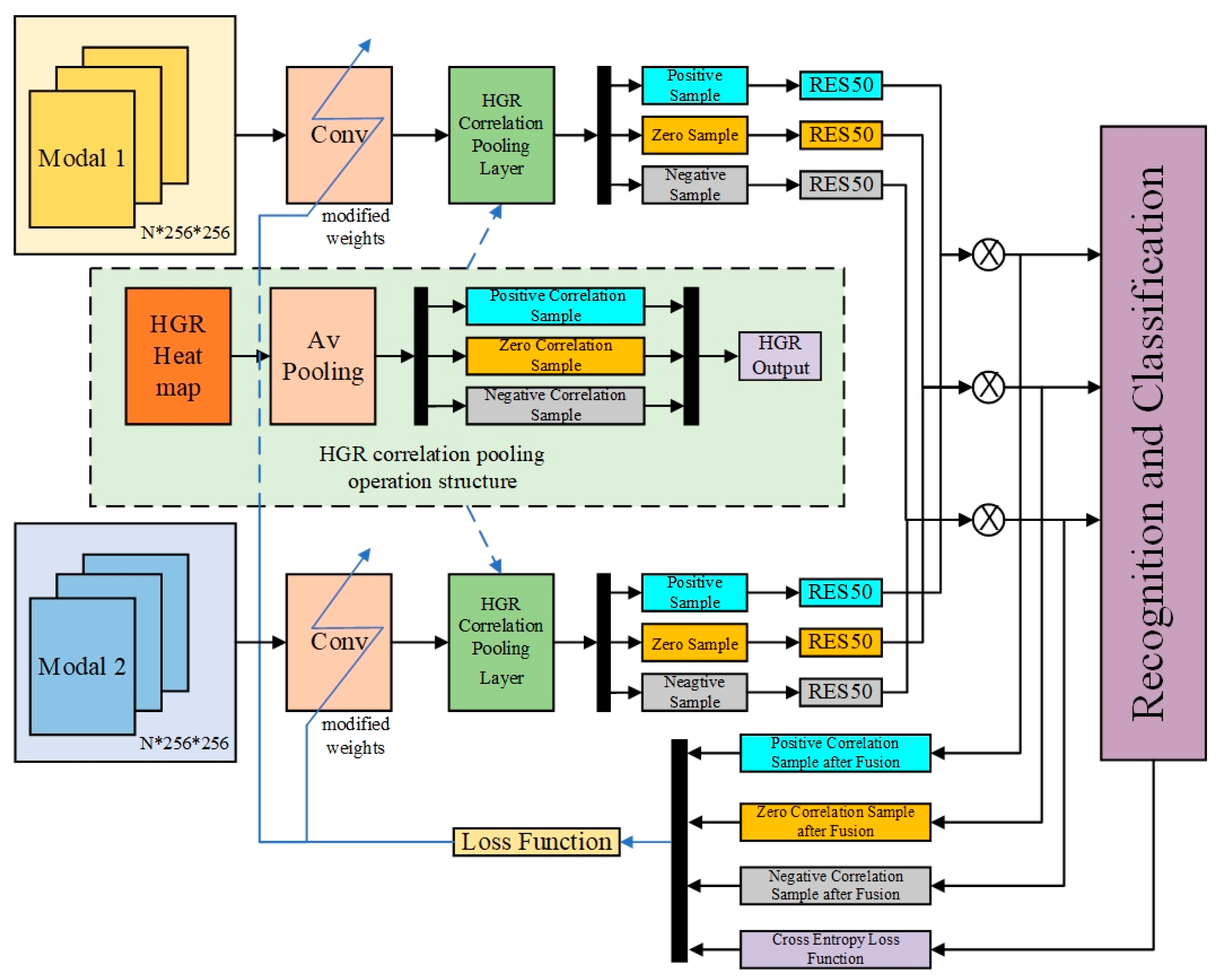
3.2. Model Overview
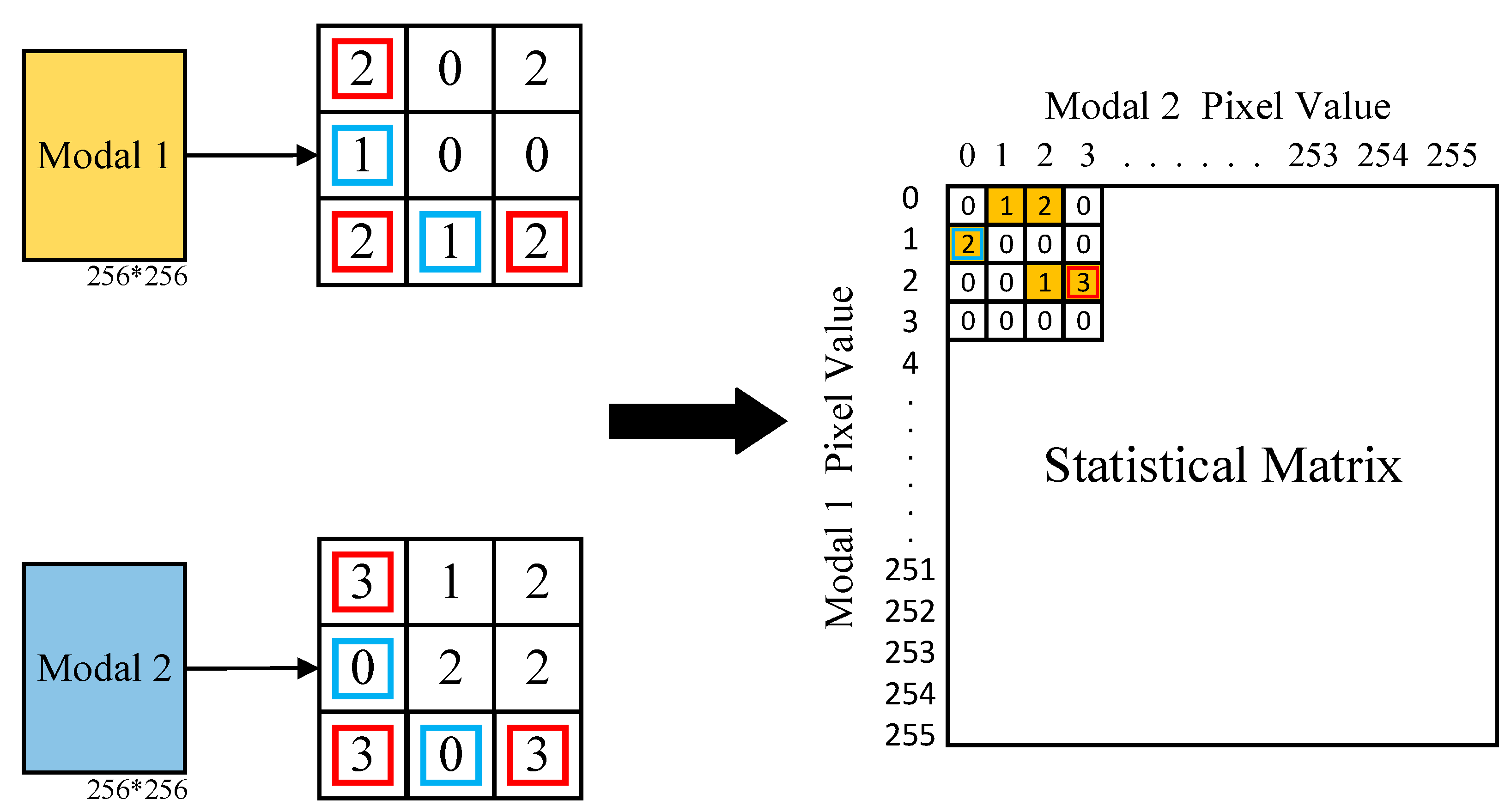
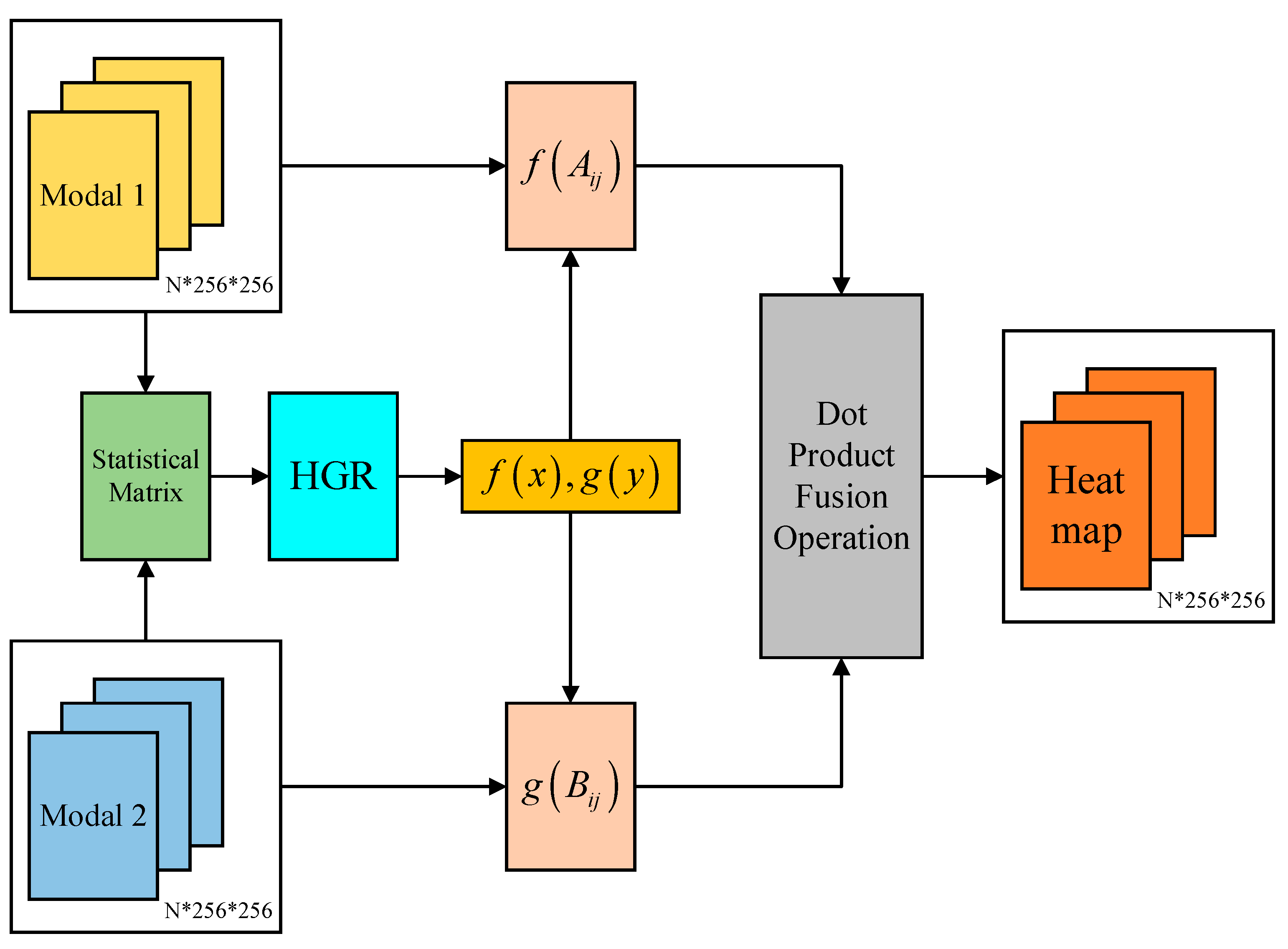
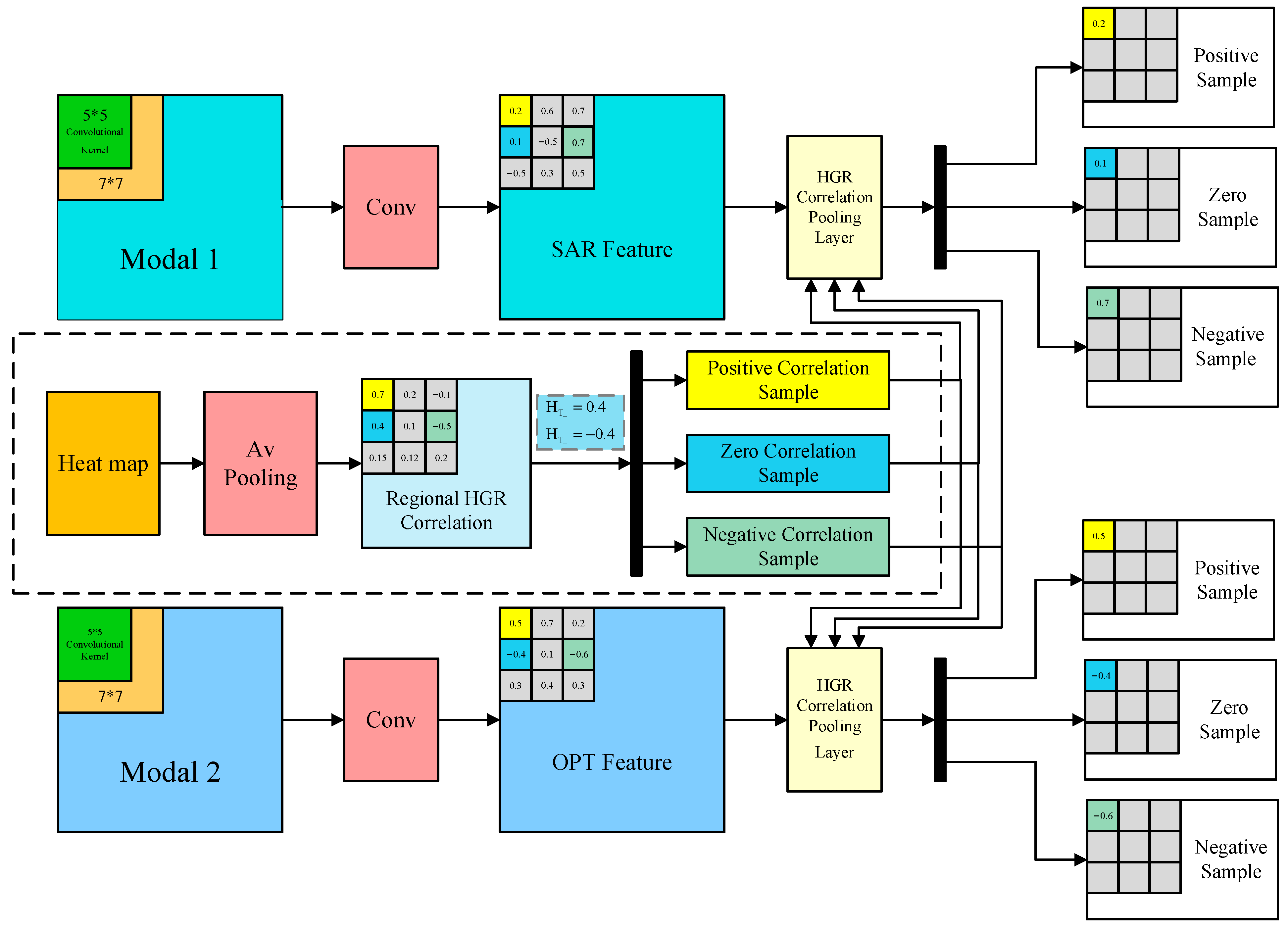
3.3. Heatmap and HGR Correlation Pooling
3.4. Learning Objective
4. Experiments and Analysis
4.1. Dataset
4.2. Data Preprocessing and Experimental Setup
4.3. Ship Recognition Experiment
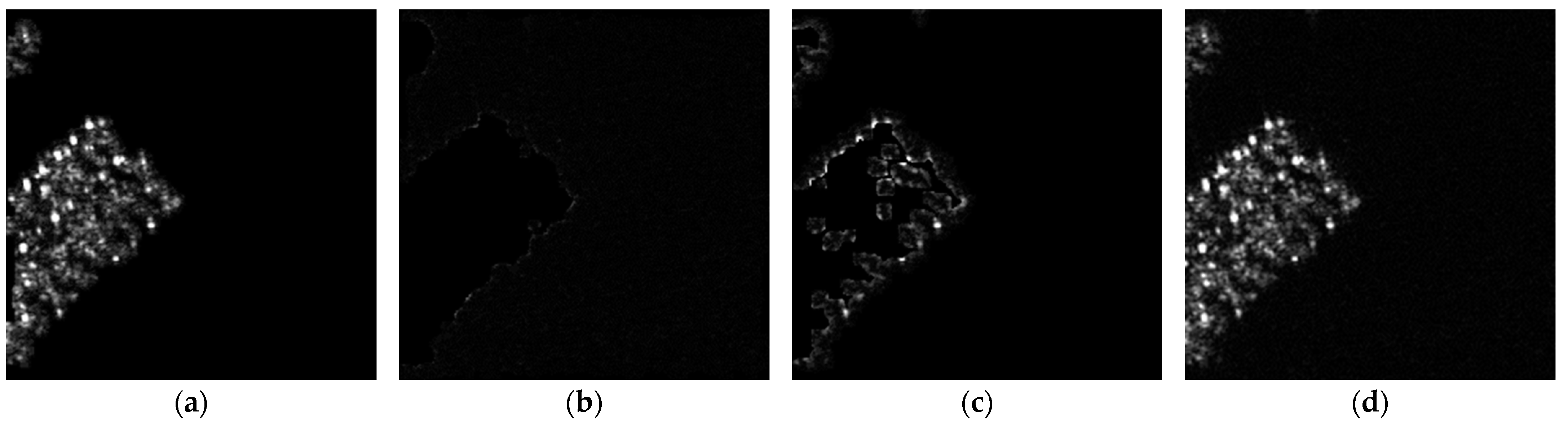
4.4. Information Traceability Experiment
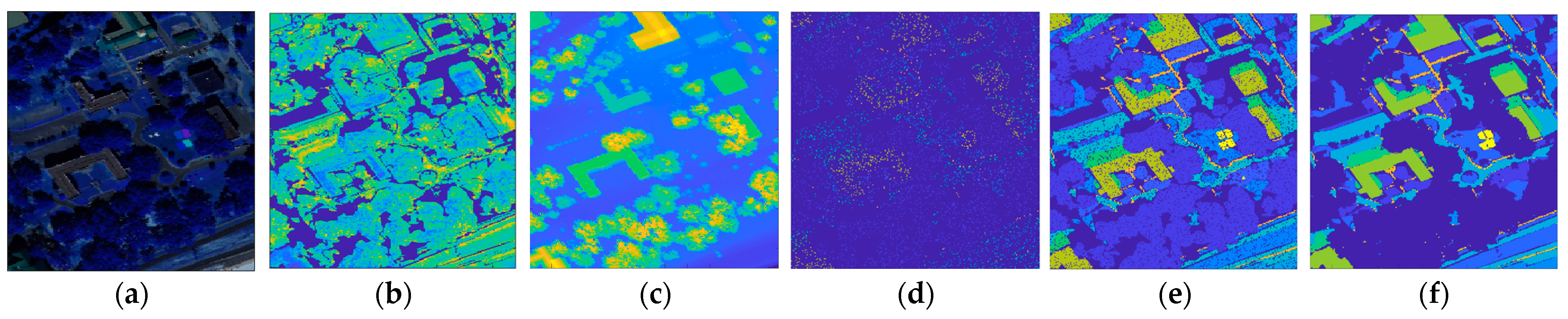
4.5. Land Cover Classification Experiment on the Houston 2013 Dataset
4.6. Land Cover Classification Experiment on the MUUFL Dataset
5. Discussion
5.1. Ablation Experiment
5.2. Analyzing the Effect of Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitem-poral data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.F.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–10. [Google Scholar] [CrossRef]
- Hong, D.F.; Gao, L.R.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Li, X.; Lu, G.; Yan, J.; Zhang, Z. A survey of dimensional emotion prediction by multimodal cues. Acta Autom. Sin. 2018, 44, 2142–2159. [Google Scholar]
- Wang, C.; Li, Z.; Sarpong, B. Multimodal adaptive identity-recognition algorithm fused with gait perception. Big Data Min. Anal. 2021, 4, 10. [Google Scholar] [CrossRef]
- Zhou, W.J.; Jin, J.H.; Lei, J.S.; Hwang, J.N. CEGFNet: Common Extraction and Gate Fusion Network for Scene Parsing of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Asghar, M.; Khan, M.; Fawad; Amin, Y.; Rizwan, M.; Rahman, M.; Mirjavadi, S. EEG-Based multi-modal emotion recognition using bag of deep features: An optimal feature selection approach. Sensors 2019, 19, 5218. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Wang, S.; Sun, Y.Z.; Zhang, H.; Liao, Y.; Gu, Y.; Hou, B.; Jiao, L.C. Multimodal Fusion Remote Sensing Image–Audio Retrieval. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6220–6235. [Google Scholar] [CrossRef]
- Li, H.; Wu, X. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef]
- Yang, B.; Zhong, J.; Li, Y.; Chen, Z. Multi-Focus image fusion and super-resolution with convolutional neural network. Int. J. Wavelets Multiresolution Inf. Process. 2017, 15, 1750037. [Google Scholar] [CrossRef]
- Zhang, X. Benchmarking and comparing multi-exposure image fusion algorithms. Inf. Fusion. 2021, 74, 111–131. [Google Scholar] [CrossRef]
- Song, X.; Wu, X.; Li, H. MSDNet for medical image fusion. In Proceedings of the International Conference on Image and Graphic, Nanjing, China, 22–24 September 2019; pp. 278–288. [Google Scholar]
- Cao, X.F.; Gao, S.; Chen, L.C.; Wang, Y. Ship recognition method combined with image segmentation and deep learning feature extraction in video surveillance. Multimedia Tools Appl. 2020, 79, 9177–9192. [Google Scholar] [CrossRef]
- Wang, C.; Pei, J.; Luo, S.; Huo, W.; Huang, Y.; Zhang, Y.; Yang, J. SAR ship target recognition via multiscale feature attention and adaptive-weighed classifier. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Zhang, T.; Liu, Z.Y.; Zhang, P.J.; Tu, S.S.; Li, Y.J.; Waqas, M. Fine-Grained ship image recognition based on BCNN with inception and AM-Softmax. CMC-Comput. Mater. Contin. 2022, 73, 1527–1539. [Google Scholar]
- Han, Y.Q.; Yang, X.Y.; Pu, T.; Peng, Z.M. Fine-Grained recognition for oriented ship against complex scenes in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Liu, J.; Chen, H.; Wang, Y. Multi-Source remote sensing image fusion for ship target detection and recognition. Remote Sens. 2021, 13, 4852. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Zhu, X.; Tuia, D.; Mou, L.; Xia, G.; Zhan, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of deep-learning approaches for remote sensing observation enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Gargees, R.S.; Scott, G.J. Deep Feature Clustering for Remote Sensing Imagery Land Cover Analysis. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1386–1390. [Google Scholar] [CrossRef]
- Tan, C.; Ewe, H.; Chuah, H. Agricultural crop-type classification of multi-polarization SAR images using a hybrid entropy decomposition and support vector machine technique. Int. J. Remote Sens. 2011, 32, 7057–7071. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Iwasaki, A. Hyperspectral image classification with canonical correlation forests. IEEE Trans. Geosci. Remote Sens. 2016, 55, 421–431. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Moham-madimanesh, F.; Homayouni, S. Bagging and boosting ensemble classifiers for classification of multispectral, hyperspectral and PolSAR data: A comparative evaluation. Remote Sens. 2021, 13, 4405. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Zhang, C.G.; Kuang, G.Y. Multimodal Semantic Consistency-Based Fusion Architecture Search for Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Cao, J.; Liu, K.; Zhuo, L.; Liu, L.; Zhu, Y.; Peng, L. Combining UAV-based hyperspectral and LiDAR data for mangrove species classification using the rotation forest algorithm. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102414. [Google Scholar] [CrossRef]
- Yu, K.; Zheng, X.; Fang, B.; An, P.; Huang, X.; Luo, W.; Ding, J.F.; Wang, Z.; Ma, J. Multimodal Urban Remote Sensing Image Registration Via Roadcross Triangular Feature. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4441–4451. [Google Scholar] [CrossRef]
- Li, W.; Gao, Y.H.; Zhang, M.M.; Tao, R.; Du, Q. Asymmetric feature fusion network for hyperspectral and SAR image classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8057–8070. [Google Scholar] [CrossRef]
- Schmitt, M.; Zhu, X. Data fusion and remote sensing: An ever-growing relationship. IEEE Geosci. Remote Sens. Mag. 2016, 4, 6–23. [Google Scholar] [CrossRef]
- Zhang, Z.; Vosselman, G.; Gerke, M.; Persello, C.; Tuia, D.; Yang, M. Detecting Building Changes between Airborne Laser Scanning and Photogrammetric Data. Remote Sens. 2019, 11, 2417. [Google Scholar] [CrossRef]
- Schmitt, M.; Tupin, F.; Zhu, X. Fusion of SAR and optical remote sensing data–challenges and recent trends. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Kulkarni, S.; Rege, P. Pixel level fusion recognition for SAR and optical images: A review. Inf. Fusion. 2020, 59, 13–29. [Google Scholar] [CrossRef]
- Rényi, A. On measures of dependence. Acta Math. Hung. 1959, 3, 441–451. [Google Scholar] [CrossRef]
- Huang, S.; Xu, X. On the sample complexity of HGR maximal correlation functions for large datasets. IEEE Trans. Inf. Theory 2021, 67, 1951–1980. [Google Scholar] [CrossRef]
- Liang, Y.; Ma, F.; Li, Y.; Huang, S. Person recognition with HGR maximal correlation on multimodal data. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 25 August 2021. [Google Scholar]
- Wang, L.; Wu, J.; Huang, S.; Zheng, L.; Xu, X.; Zhang, L.; Huang, J. An efficient approach to informative feature extraction from multimodal data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5281–5288. [Google Scholar]
- Ma, F.; Li, Y.; Ni, S.; Huang, S.; Zhang, L. Data augmentation for audio-visual emotion recognition with an efficient multimodal conditional GAN. Appl. Sci.-Basel. 2022, 12, 527. [Google Scholar]
- Pande, S.; Banerjee, B. Self-Supervision assisted multimodal remote sensing image classification with coupled self-looping convolution networks. Neural Netw. 2023, 164, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion. 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Pan, J.; He, Z.; Li, Z.; Liang, Y.; Qiu, L. A review of multimodal emotion recognition. CAAI Trans. Int. Syst. 2020, 15, 633–645. [Google Scholar]
- Pedergnana, M.; Marpu, P.; Dalla, M.; Benediktsson, J.; Bruzzone, L. Classification of remote sensing optical and LiDAR data using extended attribute profiles. IEEE J. Sel. Top. Signal Process. 2012, 6, 856–865. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, H.; Provost, E. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26 May 2013. [Google Scholar]
- Kim, S.; Song, W.; Kim, S. Double weight-based SAR and infrared sensor fusion for automatic ground target recognition with deep learning. Remote Sens. 2018, 10, 72. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 January 2016. [Google Scholar]
- Huang, M.; Xu, Y.; Qian, L.; Shi, W.; Zhang, Y.; Bao, W.; Wang, N.; Liu, X.; Xiang, X. The QXS-SAROPT dataset for deep learning in SAR-optical data fusion. arXiv 2021, arXiv:2103.08259. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; Van Kasteren, T.; Liao, W.; Bellens, R.; Pizurica, A.; Gautama, S. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Gader, P.; Zare, A.; Close, R.; Aitken, J.; Tuell, G. MUUFL Gulfport Hyperspectral and Lidar Airborne Data Set; University of Florida: Gainesville, FL, USA, 2013. [Google Scholar]
- Du, X.; Zare, A. Technical Report: Scene Label Ground Truth Map for MUUFL Gulfport Data Set; University of Florida: Gainesville, FL, USA, 2017. [Google Scholar]
- Hong, D.; Hu, J.; Yao, J.; Chanussot, J.; Zhu, X. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model. ISPRS J. Photogramm. Remote Sens. 2021, 178, 68–80. [Google Scholar] [CrossRef] [PubMed]
- Bao, W.; Huang, M.; Zhang, Y.; Xu, Y.; Liu, X.; Xiang, X. Boosting ship detection in SAR images with complementary pretraining techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8941–8954. [Google Scholar] [CrossRef]
- Qian, L.; Liu, X.; Huang, M.; Xiang, X. Self-Supervised pre-training with bridge neural network for SAR-optical matching. Remote Sens. 2022, 14, 2749. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Rasti, B.; Plaza, A.; Chanussot, J. Multimodal fusion transformer for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–20. [Google Scholar] [CrossRef]
- Franco, A.; Oliveira, L. Convolutional covariance features: Conception, integration and performance in person re-identification. Pattern Recognit. 2017, 61, 593–609. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X. CoSpace: Common subspace learning from hyperspectral-multispectral correspondences. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4349–4359. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Ghamisi, P.; Hong, D.; Xia, G.; Liu, Q. Classification of hyperspectral and LiDAR data using coupled CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4939–4950. [Google Scholar] [CrossRef]
- Mohla, S.; Pande, S.; Banerjee, B.; Chaudhuri, S. FusAtNet: Dual attention based SpectroSpatial multimodal fusion network for hyperspectral and lidar classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 14 June 2020. [Google Scholar]
- Khan, A.; Raufu, Z.; Sohail, A.; Khan, A.R.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56, 2917–2970. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, G.; Jiang, X.; Zhou, Y.; Li, S.; Liu, X.; Lin, P. Robust land cover classification with multimodal knowledge distillation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Class Name | Training Set | Testing Set |
|---|---|---|---|
| 1 | Healthy grass | 198 | 1053 |
| 2 | Stressed grass | 190 | 1064 |
| 3 | Synthetic grass | 192 | 505 |
| 4 | Trees | 188 | 1056 |
| 5 | Soil | 186 | 1056 |
| 6 | Water | 182 | 143 |
| 7 | Residential | 196 | 1072 |
| 8 | Commercial | 191 | 1053 |
| 9 | Road | 193 | 1059 |
| 10 | Highway | 191 | 1036 |
| 11 | Railway | 181 | 1054 |
| 12 | Parking lot 1 | 192 | 1041 |
| 13 | Parking lot 2 | 184 | 285 |
| 14 | Tennis court | 181 | 247 |
| 15 | Running track | 187 | 473 |
| Total | 2832 | 12,197 | |
| Percentage | 18.84% | 81.16% |
| No | Class Name | Training Set | Testing Set |
|---|---|---|---|
| 1 | Trees | 1166 | 22,080 |
| 2 | Grass-Pure | 222 | 4048 |
| 3 | Grass-Groundsurface | 356 | 6526 |
| 4 | Dirt-and-Sand | 86 | 1740 |
| 5 | Road-Materials | 315 | 6372 |
| 6 | Water | 30 | 436 |
| 7 | Buildings’-Shadow | 93 | 2140 |
| 8 | Buildings | 302 | 5938 |
| 9 | Sidewalk | 74 | 1311 |
| 10 | Yellow-Curb | 9 | 174 |
| 11 | ClothPanels | 16 | 253 |
| Total | 2669 | 51,018 | |
| Percentage | 4.97% | 95.03% |
| Model | Accuracy (Acc) | Precision (P) | Recall (R) | F1-Score |
|---|---|---|---|---|
| NP-BNN + ResNet50 | 0.831 | 0.750 | 0.990 | 0.853 |
| NP-BNN + Darknet53 | 0.826 | 0.761 | 0.980 | 0.857 |
| IP-BNN + ResNet50 | 0.829 | 0.748 | 0.993 | 0.853 |
| IP-BNN + Darknet53 | 0.828 | 0.746 | 0.995 | 0.853 |
| MoCo-BNN + ResNet50 | 0.873 | 0.808 | 0.995 | 0.892 |
| MoCo-BNN + Darknet53 | 0.871 | 0.809 | 0.997 | 0.893 |
| CCR-Net | 0.854 | 0.883 | 0.963 | 0.894 |
| MFT | 0.876 | 0.892 | 0.980 | 0.934 |
| HGRPool (ours) | 0.898 | 0.908 | 0.988 | 0.946 |
| Class | CCF | CoSpace | Co- CNN | FusAt- Net | ViT | S2FL | Spectral- Former | CCR- Net | MFT | DIMNet | HGRPool (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OA (%) | 83.46 | 82.14 | 87.23 | 88.69 | 85.05 | 85.07 | 86.14 | 88.15 | 89.15 | 91.47 | 92.23 |
| AA (%) | 85.95 | 84.54 | 88.82 | 90.29 | 86.83 | 86.11 | 87.48 | 89.82 | 90.56 | 92.48 | 93.55 |
| Kappa coefficient | 0.8214 | 0.8062 | 0.8619 | 0.8772 | 0.8384 | 0.8378 | 0.8497 | 0.8719 | 0.8822 | 0.9077 | 0.9157 |
| Healthy grass | 83.10 | 81.96 | 83.1 | 96.87 | 82.59 | 80.06 | 83.48 | 83 | 82.72 | 83.00 | 83.00 |
| Stressed grass | 83.93 | 83.27 | 84.87 | 82.42 | 82.33 | 84.49 | 95.58 | 84.87 | 85.09 | 84.68 | 98.87 |
| Synthetic grass | 100.00 | 100.00 | 99.8 | 100.00 | 97.43 | 98.02 | 99.60 | 100.00 | 98.55 | 99.01 | 100.00 |
| Trees | 92.42 | 94.22 | 92.42 | 91.95 | 92.93 | 87.31 | 99.15 | 92.14 | 95.99 | 91.38 | 98.58 |
| Soil | 98.77 | 99.34 | 99.24 | 97.92 | 99.84 | 100.00 | 97.44 | 99.81 | 99.78 | 99.62 | 92.90 |
| Water | 99.30 | 99.30 | 95.8 | 90.91 | 84.15 | 83.22 | 95.10 | 95.8 | 97.20 | 95.10 | 100.00 |
| Residential | 84.42 | 81.44 | 95.24 | 92.91 | 87.84 | 73.32 | 88.99 | 95.34 | 86.32 | 92.91 | 98.50 |
| Commercial | 52.90 | 66.1 | 81.86 | 89.46 | 79.93 | 74.84 | 73.31 | 81.39 | 81.16 | 87.27 | 79.58 |
| Road | 76.02 | 69.97 | 85.08 | 82.06 | 82.94 | 78.38 | 71.86 | 84.14 | 87.76 | 88.01 | 88.22 |
| Highway | 67.18 | 48.94 | 61.1 | 66.60 | 52.93 | 83.30 | 87.93 | 63.22 | 74.71 | 93.82 | 86.50 |
| Railway | 84.44 | 88.61 | 83.87 | 80.36 | 80.99 | 81.69 | 80.36 | 90.32 | 93.71 | 88.80 | 91.46 |
| Parking lot 1 | 92.80 | 88.57 | 91.26 | 92.41 | 91.07 | 95.10 | 70.70 | 93.08 | 96.16 | 96.54 | 97.50 |
| Parking lot 2 | 76.49 | 68.07 | 88.77 | 92.63 | 87.84 | 72.63 | 71.23 | 88.42 | 92.51 | 90.53 | 90.88 |
| Tennis court | 99.60 | 100.00 | 91.09 | 100.00 | 100.00 | 100.00 | 98.79 | 96.36 | 100.00 | 96.76 | 100.00 |
| Running track | 97.89 | 98.31 | 98.73 | 97.89 | 99.65 | 99.37 | 98.73 | 99.37 | 86.82 | 99.79 | 100.00 |
| Class | CCF | CoSpace | Co- CNN | FusAt- Net | ViT | S2FL | Spectral- Former | CCR- Net | MFT | HGRPool (Ours) |
|---|---|---|---|---|---|---|---|---|---|---|
| OA(%) | 88.22 | 87.55 | 90.93 | 91.48 | 92.15 | 72.49 | 88.25 | 90.39 | 94.34 | 94.99 |
| AA(%) | 71.76 | 71.63 | 77.18 | 78.58 | 78.50 | 79.23 | 68.47 | 76.31 | 81.48 | 88.13 |
| Kappa | 0.8441 | 0.8353 | 0.8822 | 0.8865 | 0.8956 | 0.6581 | 0.8440 | 0.8603 | 0.9251 | 0.9339 |
| Trees | 96.50 | 95.89 | 98.90 | 98.10 | 97.85 | 72.40 | 97.30 | 96.78 | 97.90 | 97.98 |
| Grass-Pure | 77.17 | 66.65 | 78.60 | 71.66 | 76.06 | 75.97 | 69.35 | 83.99 | 92.11 | 92.45 |
| Grass-Groundsurface | 74.80 | 85.24 | 90.66 | 87.65 | 87.58 | 54.72 | 78.48 | 84.16 | 91.80 | 89.86 |
| Dirt-and-Sand | 91.94 | 68.45 | 90.60 | 86.42 | 92.05 | 82.20 | 82.63 | 93.05 | 91.59 | 91.81 |
| Road-Materials | 93.45 | 94.52 | 96.90 | 95.09 | 94.73 | 71.26 | 87.91 | 91.37 | 95.60 | 95.13 |
| Water | 95.05 | 96.10 | 75.98 | 90.73 | 82.02 | 94.42 | 58.77 | 81.88 | 88.19 | 99.28 |
| Buildings’-Shadow | 79.82 | 84.91 | 73.54 | 74.27 | 87.11 | 77.34 | 85.87 | 76.54 | 90.27 | 93.25 |
| Buildings | 98.21 | 91.19 | 96.66 | 97.55 | 97.60 | 86.19 | 95.60 | 94.58 | 97.26 | 97.83 |
| Sidewalk | 0.52 | 9.69 | 64.93 | 60.44 | 57.83 | 59.21 | 53.52 | 43.02 | 61.35 | 78.14 |
| Yellow-Curb | 0.00 | 0.00 | 19.47 | 09.39 | 31.99 | 98.91 | 08.43 | 00.00 | 17.43 | 46.25 |
| ClothPanels | 81.89 | 95.26 | 62.76 | 93.02 | 58.72 | 98.88 | 35.29 | 94.70 | 72.79 | 87.45 |
| Methods | Accuracy (Acc) | Precision (P) | Recall (R) | F1-Score |
|---|---|---|---|---|
| Without HGRPool | 0.722 | 0.803 | 0.877 | 0.838 |
| Partially using HGRPool (positive/zero sample) | 0.789 | 0.834 | 0.937 | 0.883 |
| Partially using HGRPool (positive /negative sample) | 0.810 | 0.849 | 0.947 | 0.895 |
| HGRPool | 0.898 | 0.908 | 0.988 | 0.946 |
| Methods | Houston 2013 Dataset | MUUFL Dataset | ||||
|---|---|---|---|---|---|---|
| OA (%) | AA (%) | Kappa | OA (%) | AA (%) | Kappa | |
| Without HGRPool | 89.64 | 90.26 | 0.8851 | 92.72 | 80.94 | 0.9040 |
| Partially using HGRPool (positive/zero sample) | 90.20 | 91.05 | 0.8937 | 93.24 | 84.41 | 0.9106 |
| Partially using HGRPool (positive/negative sample) | 90.81 | 91.46 | 0.9013 | 93.79 | 85.07 | 0.9180 |
| HGRPool | 92.23 | 93.55 | 0.9157 | 94.99 | 88.13 | 0.9339 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Huang, S.-L.; Kuruoglu, E.E. HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data. Remote Sens. 2024, 16, 1708. https://doi.org/10.3390/rs16101708
Zhang H, Huang S-L, Kuruoglu EE. HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data. Remote Sensing. 2024; 16(10):1708. https://doi.org/10.3390/rs16101708
Chicago/Turabian StyleZhang, Hongkang, Shao-Lun Huang, and Ercan Engin Kuruoglu. 2024. "HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data" Remote Sensing 16, no. 10: 1708. https://doi.org/10.3390/rs16101708
APA StyleZhang, H., Huang, S.-L., & Kuruoglu, E. E. (2024). HGR Correlation Pooling Fusion Framework for Recognition and Classification in Multimodal Remote Sensing Data. Remote Sensing, 16(10), 1708. https://doi.org/10.3390/rs16101708