
An Embedded-GPU-Based Scheme for Real-Time Imaging Processing of Unmanned Aerial Vehicle Borne Video Synthetic Aperture Radar


Abstract
1. Introduction
- (1)
- In response to the problems of heavy computational duty and high computational complexity in traditional ViSAR algorithms, we proposed parallel computing methods for RD and MD algorithms based on the CUDA parallel programming model. By utilizing the advantages of the embedded GPU characterized with parallel computing, we improved the processing speed of real-time ViSAR imaging.
- (2)
- We adopted a unified memory management approach which can greatly reduce data replication and communication latency between the CPU and the GPU. In order to enhance memory access efficiency, it is essential to achieve the optimal use of both global and shared memory. When using FFT functions in the algorithm, configuring a cuFFT plan only once and releasing cuFFT resources uniformly after accomplishing all Fourier transforms can improve FFT execution efficiency and reduce memory overhead. Through the above operations, the efficiency of real-time ViSAR imaging has been further improved.
- (3)
- We proposed a high-frame-rate ViSAR real-time imaging processing system based on an embedded GPU, which has the characteristics of small size, low power consumption, and high-frame-rate real-time imaging. The robustness and effectiveness of the proposed system were verified by the measured data processing results on the Jetson AGX Orin platform, satisfying the requirements of ViSAR real-time imaging processing.
2. Imaging Algorithm of the ViSAR
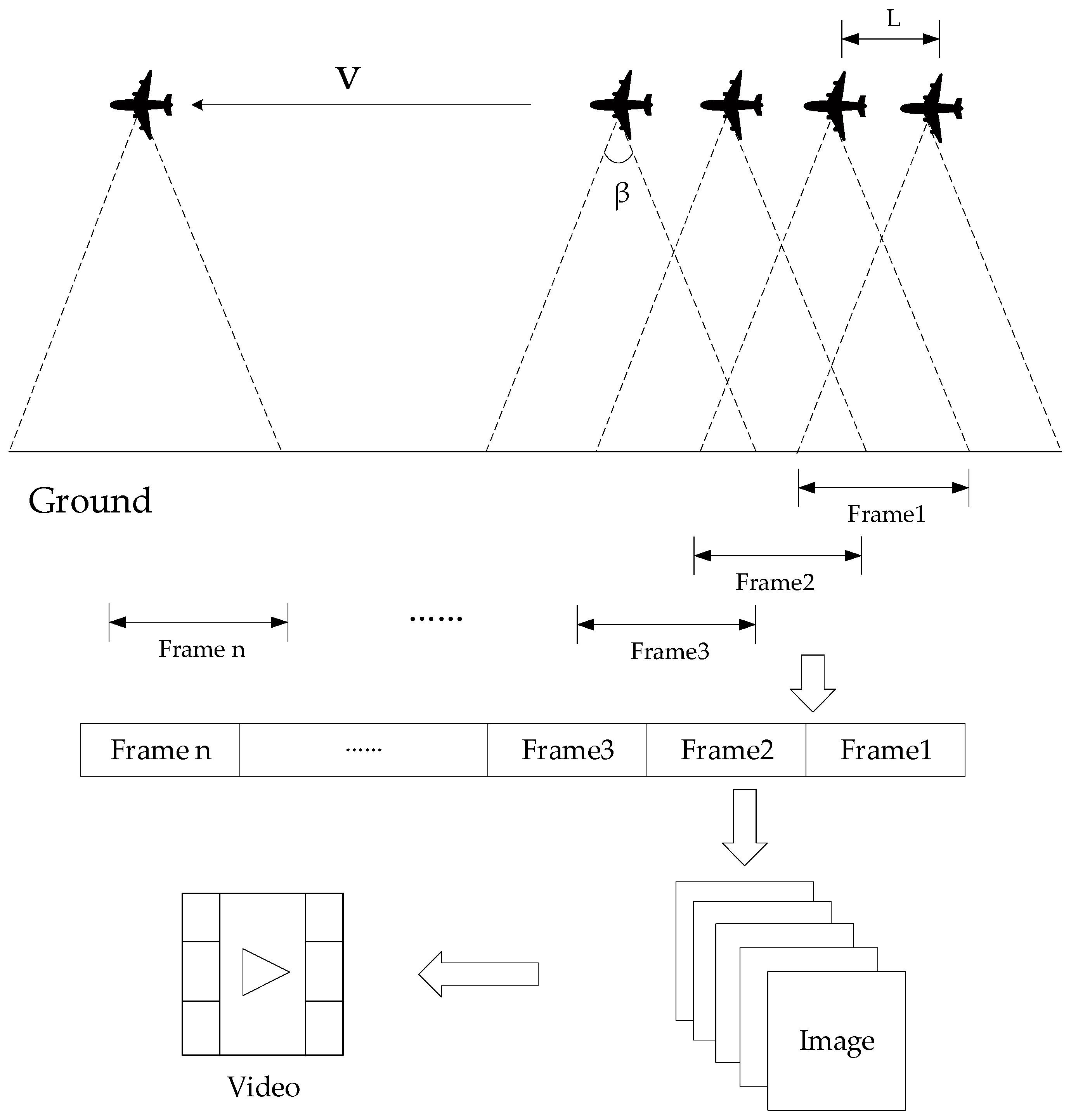
Imaging Modes of the ViSAR
3. Implementing and Optimizing the Embedded-GPU-Based ViSAR
3.1. CUDA-Implemented RD Algorithm
3.2. CUDA-Implemented MD Algorithm
3.3. Optimizing ViSAR Imaging
- (1)
- Unified memory management. It has been acknowledged that the GPU is not an independent computing platform; instead, it must collaborate with the CPU to form a heterogeneous computing architecture. As shown in Figure 6a, conventional heterogeneous computing architectures of a GPU and a CPU are generally discrete, where the GPU and the CPU have their own independent memory. They are connected through peripheral component interconnect express (PCIe), and data need to be transmitted through a PCIe bus. Conversely, the heterogeneous computing architecture of an embedded GPU is integrated, where a CPU and a GPU are integrated on a single chip and share main memory on physical addresses. As shown in Figure 6b, in the embedded GPU, the CPU and the GPU do not have independent memory, thus not requiring data transmission through a PCIe bus.

- (2)
- Aligned and pinned memory access. Global memory is the largest and most commonly used memory in the GPU, and most of the GPU applications are limited to memory bandwidth. Therefore, maximizing the utilization of global memory bandwidth is the key to optimizing kernel function performance. Using aligned and pinned memory access to the largest extent can maximize the efficiency of memory access and achieve optimal performance when reading and writing data. The former refers to the fact that the first address of a memory transaction is an even multiple of the cache line size used for transaction services (32 bytes of L2 cache or 128 bytes of L1 cache). The latter refers to all threads in a thread warp accessing a contiguous block of threads. It can be observed from Figure 7 that the aligned and pinned memory access only requires one data transfer to complete data access.

- (3)
- Shared memory. Shared memory is one of the important types of memory space for the GPU, which also functions as a critical tool for optimizing CUDA programs. The two key attributes to measuring the optimization of memory performance is the delay and bandwidth. Compared to global memory, shared memory has a latency reduction of approximately 20 to 30 times and a bandwidth increase of approximately 10 times. Therefore, it can be used to prevent global memory latency and bandwidth from being degraded on memory performance. When each thread block starts execution, certain amounts of shared memory are allocated and the address space of this shared memory is shared by all threads in the thread block. Accessing shared memory can be categorized into the following three modes:
- (a)
- Parallel access: accessing multiple banks from multiple addresses.
- (b)
- Broadcast access: a single address reads a single bank.
- (c)
- Serial access: multiple addresses access the same bank.
- (4)
- FFT operation. In RD and MD algorithms, multiple FFT/IFFT operations need to be executed to accomplish compression in the azimuth direction and the range direction. Based on CUDA implementation, the cuFFT library provides highly optimized Fourier transforms. Using the cuFFT library for FTs not only improves the computation speed, but also saves the development time of algorithms. The configuration of the cuFFT library is accomplished through an FFT plan, which defines a single transformation operation to be performed. When calling the cuFFT library, a plan is configured first. The cuFFT library uses the plan to obtain memory allocation, memory transfer, and kernel startup to execute transformation requests. After FT operations are completed, cuFFT resources need to be released.
- (1)
- The unified memory approach is used for memory management. The advantage of this approach lies in the fact that allocated space can be accessed using the same memory address (i.e., pointers) on both the CPU and the GPU, thereby avoiding the need for occupying additional space in memory and performing data copying between the CPU and the GPU.
- (2)
- In order to maximize memory access efficiency, we should fully leverage the global memory bandwidth. When accessing memory, it is advisable to use aligned memory and pinned memory to achieve the optimal performance.
- (3)
- Shared memory is reasonably used. Shared memory, compared to global memory, exhibits lower latency (approximately 20–30 times lower) and higher bandwidth (approximately 10 times higher). Therefore, in range-doppler (RD) and multi-look processing (MD) algorithms, operations involving matrix transposition and array multiplication can be optimized using shared memory within the kernel function to enhance memory access.
- (4)
- When using FFT functions in the algorithm, configuring a cuFFT plan only once and releasing cuFFT resources uniformly after accomplishing all Fourier transforms can improve FFT execution efficiency and reduce memory overhead.
4. Experimental Results and Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, J.; Pu, W.; An, H.; Huang, Y.; Yang, H.; Yang, J. Learning-based High-frame-rate SAR imaging. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5208813. [Google Scholar] [CrossRef]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR Moving Target Indication Using Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Wen, L.; Ding, J.; Loffeld, O. Video SAR Moving Target Detection Using Dual Faster R-CNN. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2984–2994. [Google Scholar] [CrossRef]
- Chen, J.; Xing, M.; Yu, H.; Liang, B.; Peng, J.; Sun, G.C. Motion Compensation/Autofocus in Airborne Synthetic Aperture Radar: A Review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 185–206. [Google Scholar] [CrossRef]
- Shang, R.H.; Liu, M.M.; Jiao, L.C.; Feng, J.; Li, Y.Y.; Stolkin, R. Region-Level SAR Image Segmentation Based on Edge Feature and Label Assistance. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5237216. [Google Scholar] [CrossRef]
- Yang, X.; Shi, J.; Zhou, Y.; Wang, C.; Hu, Y.; Zhang, X.; Wei, S. Ground Moving Target Tracking and Refocusing Using Shadow in Video-SAR. Remote Sens. 2020, 12, 3083. [Google Scholar] [CrossRef]
- Guo, P.; Wu, F.; Tang, S.; Jiang, C.; Liu, C. Implementation Method of Automotive Video SAR (ViSAR) Based on Sub-Aperture Spectrum Fusion. Remote Sens. 2023, 15, 476. [Google Scholar] [CrossRef]
- Kim, C.K.; Azim, M.T.; Singh, A.K.; Park, S.O. Doppler Shifting Technique for Generating Multi-Frames of Video SAR via Sub-Aperture Signal Processing. IEEE Trans. Signal Process. 2020, 68, 3990–4001. [Google Scholar] [CrossRef]
- Yang, C.; Chen, Z.; Deng, Y.; Wang, W.; Wang, P.; Zhao, F. Generation of Multiple Frames for High Resolution Video SAR Based on Time Frequency Sub-Aperture Technique. Remote Sens. 2023, 15, 264. [Google Scholar] [CrossRef]
- Cheng, Y.; Ding, J.; Sun, Z. Processing of airborne video SAR data using the modified back projection algorithm. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5238013. [Google Scholar] [CrossRef]
- Fu, C.; Li, B.; Ding, F.; Lin, F.; Lu, G. Correlation Filters for Unmanned Aerial Vehicle-Based Aerial Tracking: A Review and Experimental Evaluation. IEEE Geosci. Remote Sens. Mag. 2022, 10, 125–160. [Google Scholar] [CrossRef]
- Osco, L.P.; Marcato Junior, J.; Marques Ramos, A.P.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Xiao, Z.; Zhu, L.; Liu, Y.; Yi, P.; Zhang, R.; Xia, X.G.; Schober, R. A Survey on Millimeter-Wave Beamforming Enabled UAV Communications and Networking. IEEE Commun. Surv. Tutor. 2021, 24, 557–610. [Google Scholar] [CrossRef]
- Yang, Z.; Nie, X.; Xiong, W.; Niu, X.; Tian, W. Real time imaging processing of ground-based SAR based on multicore DSP. In Proceedings of the 2017 IEEE International Conference on Imaging Systems and Techniques (IST), Beijing, China, 18–20 October 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Wang, J.; Zhang, X. Algorithm/Hardware Codesign for Real-Time On-Satellite CNN-Based Ship Detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5226018. [Google Scholar] [CrossRef]
- Zou, L.; Zhang, J.; Zhu, D. FPGA Implementation of Polar Format Algorithm for Airborne Spotlight SAR Processing. In Proceedings of the 2013 IEEE International Conference on Dependable, Autonomic and Secure Computing (DASC), Chengdu, China, 21–22 December 2013; pp. 143–147. [Google Scholar] [CrossRef]
- Cao, Y.; Guo, S.; Jiang, S.; Zhou, X.; Wang, X.; Luo, Y.; Yu, Z.; Zhang, Z.; Deng, Y. Parallel Optimisation and Implementation of a Real-Time Back Projection (BP) Algorithm for SAR Based on FPGA. Sensors 2022, 22, 2292. [Google Scholar] [CrossRef]
- Wielage, M.; Cholewa, F.; Fahnemann, C.; Pirsch, P.; Blume, H. High Performance and Low Power Architectures: GPU vs. FPGA for Fast Factorized Backprojection. In Proceedings of the 2017 Fifth International Symposium on Computing and Networking (CANDAR), Aomori, Japan, 19–22 November 2017; pp. 351–357. [Google Scholar] [CrossRef]
- Balz, T.; Stilla, U. Hybrid GPU-Based Single- and Double-Bounce SAR Simulation. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3519–3529. [Google Scholar] [CrossRef]
- Shi, J.; Ma, L.; Zhang, X. Streaming BP for Non-Linear Motion Compensation SAR Imaging Based on GPU. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2035–2050. [Google Scholar] [CrossRef]
- Yu, Y.; Balz, T.; Luo, H.; Liao, M.; Zhang, L. GPU accelerated interferometric SAR processing for Sentinel-1 TOPS data. Comput. Geosci. 2019, 129, 12–25. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, C.; Li, W.; Hu, W.; Wang, P.; Li, H. A Deep Collaborative Computing Based SAR Raw Data Simulation on Multiple CPU/GPU Platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 387–399. [Google Scholar] [CrossRef]
- Hernandez-Juarez, D.; Chacón, A.; Espinosa, A.; Vázquez, D.; Moure, J.C.; López, A.M. Embedded real-time stereo estimation via semi-global matching on the GPU. Procedia Comput. Sci. 2016, 80, 143–153. [Google Scholar] [CrossRef]
- Aguilera, C.A.; Aguilera, C.; Navarro, C.A.; Sappa, A.D. Fast CNN Stereo Depth Estimation through Embedded GPU Devices. Sensors 2020, 20, 3249. [Google Scholar] [CrossRef]
- Fernandez-Sanjurjo, M.; Mucientes, M.; Brea, V.M. Real-Time Multiple Object Visual Tracking for Embedded GPU Systems. IEEE Internet Things J. 2021, 8, 9177–9188. [Google Scholar] [CrossRef]
- Farooq, M.A.; Shariff, W.; Corcoran, P. Evaluation of Thermal Imaging on Embedded GPU Platforms for Application in Vehicular Assistance Systems. IEEE Trans. Intell. Veh. 2022, 8, 1130–1144. [Google Scholar] [CrossRef]
- Chen, J.; Yu, H.; Xu, G.; Zhang, J.; Liang, B.; Yang, D. Airborne SAR Autofocus Based on Blurry Imagery Classification. Remote Sens. 2021, 13, 3872. [Google Scholar] [CrossRef]
- Fatica, M.; Phillips, E. Synthetic aperture radar imaging on a CUDA-enabled mobile platform. In Proceedings of the 2014 IEEE High Performance Extreme Computing Conference, Waltham, MA, USA, 9–11 September 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Radecki, K.; Samczynski, P.; Kulpa, K.; Drozdowicz, J. A real-time focused SAR algorithm on the Jetson TK1 board. In Proceedings of the Image and Signal Processing for Remote Sensing XXII, Edinburgh, UK, 26–28 September 2016; pp. 351–358. [Google Scholar] [CrossRef]
- Hawkins, B.P.; Tung, W. UAVSAR Real-Time Embedded GPU Processor. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 545–547. [Google Scholar] [CrossRef]
- Tian, H.; Hua, W.; Gao, H.; Sun, Z.; Cai, M.; Guo, Y. Research on Real-time Imaging Method of Airborne SAR Based on Embedded GPU. In Proceedings of the 2022 3rd China International SAR Symposium, Shanghai, China, 2–4 November 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Yang, T.; Xu, Q.; Meng, F.; Zhang, S. Distributed Real-Time Image Processing of Formation Flying SAR Based on Embedded GPUs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6495–6505. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Jetson AGX Orin | Jetson Nano | Jetson TX2 | RTX 2060 Max-Q |
|---|---|---|---|---|
| GPU | 2048-core NVIDIA Ampere | 128-core NVIDIA Maxwell | 256-core NVIDIA Pascal | 1920-core NVIDIA Turing |
| CPU | 12-core ARM A78AE@2.2 GHz | 4-core ARM A57@1.43 GHz | 2-core Denver@2.0 GHz 4-core ARM A57@2.0 GHz | 8-core Intel i7-10875H@2.30 GHz |
| Memory | 32 GB 256-bitLPDDR5 204.8 GB/s | 4 GB 64-bit LPDDR4 25.6 GB/s | 8 GB 128-bit LPDDR4 59.7 GB/s | 6 GB 192-bit GDDR6 264.0 GB/s |
| GPU Frequency | 1.3 GHz | 922 MHz | 1.3 GHz | 1185 MHz |
| Power consumption | 60 W | 5 W | 15 W | <230 W |
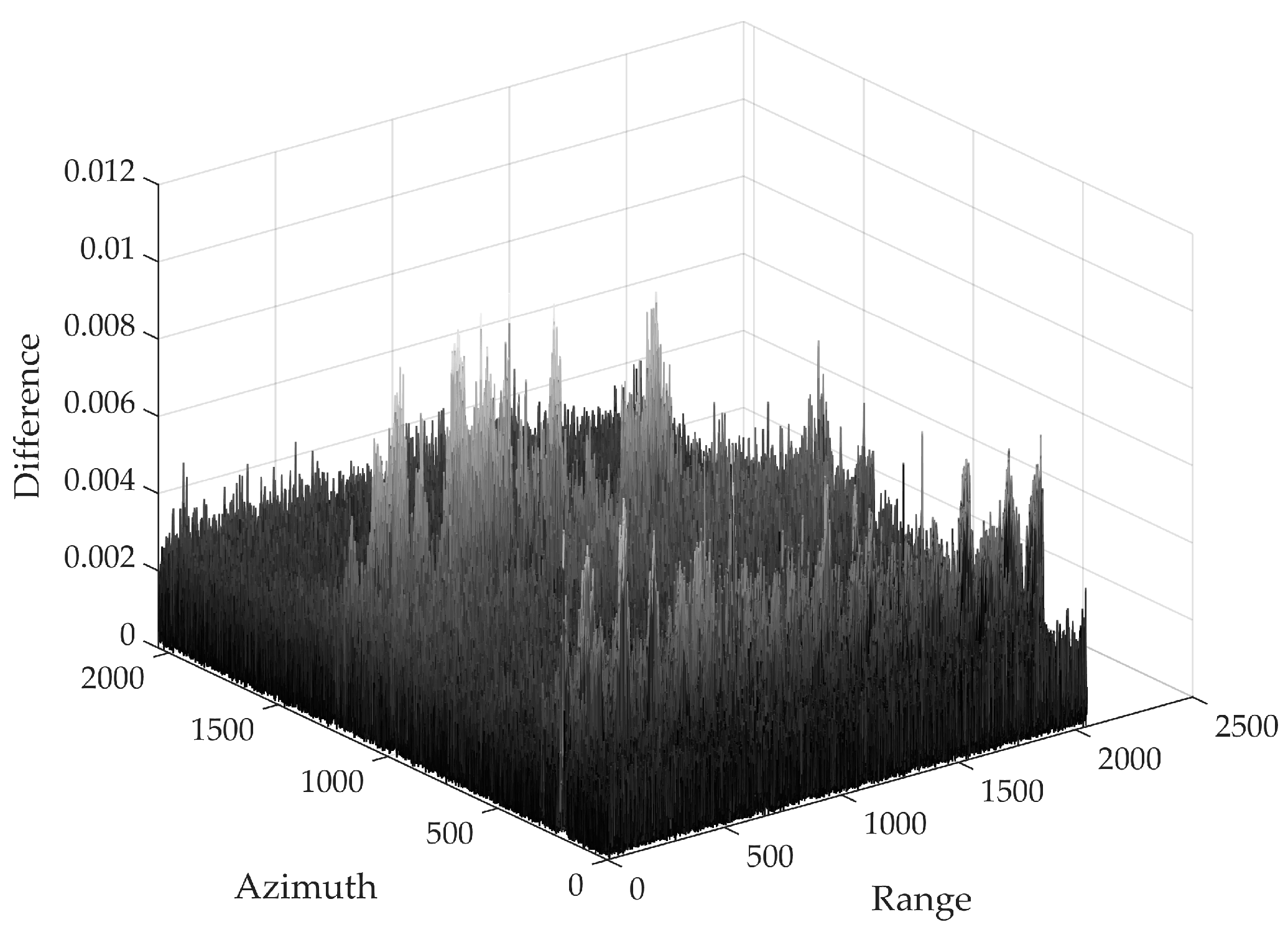
| PSNR | SSIM | |
|---|---|---|
| Image | 48.1308 dB | 0.9652 |
| Processing Platform | Jetson AGX Orin | RTX 2060 Max-Q | Jetson Nano | Jetson TX2 | Core i7-10875H CPU |
|---|---|---|---|---|---|
| Processing time required by the RD algorithm | 0.012 s | 0.014 s | 0.163 s | 0.126 s | 0.348 s |
| Processing time required by the MD algorithm | 0.123 s | 0.172 s | 1.825 s | 1.432 s | 5.022 s |
| Total time consumption | 0.135 s | 0.186 s | 1.988 s | 1.558 s | 5.370 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, T.; Zhang, X.; Xu, Q.; Zhang, S.; Wang, T. An Embedded-GPU-Based Scheme for Real-Time Imaging Processing of Unmanned Aerial Vehicle Borne Video Synthetic Aperture Radar. Remote Sens. 2024, 16, 191. https://doi.org/10.3390/rs16010191
Yang T, Zhang X, Xu Q, Zhang S, Wang T. An Embedded-GPU-Based Scheme for Real-Time Imaging Processing of Unmanned Aerial Vehicle Borne Video Synthetic Aperture Radar. Remote Sensing. 2024; 16(1):191. https://doi.org/10.3390/rs16010191
Chicago/Turabian StyleYang, Tao, Xinyu Zhang, Qingbo Xu, Shuangxi Zhang, and Tong Wang. 2024. "An Embedded-GPU-Based Scheme for Real-Time Imaging Processing of Unmanned Aerial Vehicle Borne Video Synthetic Aperture Radar" Remote Sensing 16, no. 1: 191. https://doi.org/10.3390/rs16010191
APA StyleYang, T., Zhang, X., Xu, Q., Zhang, S., & Wang, T. (2024). An Embedded-GPU-Based Scheme for Real-Time Imaging Processing of Unmanned Aerial Vehicle Borne Video Synthetic Aperture Radar. Remote Sensing, 16(1), 191. https://doi.org/10.3390/rs16010191