


Synergistic Application of Multiple Machine Learning Algorithms and Hyperparameter Optimization Strategies for Net Ecosystem Productivity Prediction in Southeast Asia



 ,
,
Abstract
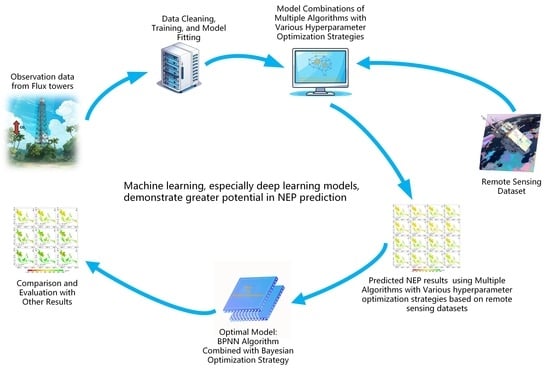
:
1. Introduction
2. Data and Methods
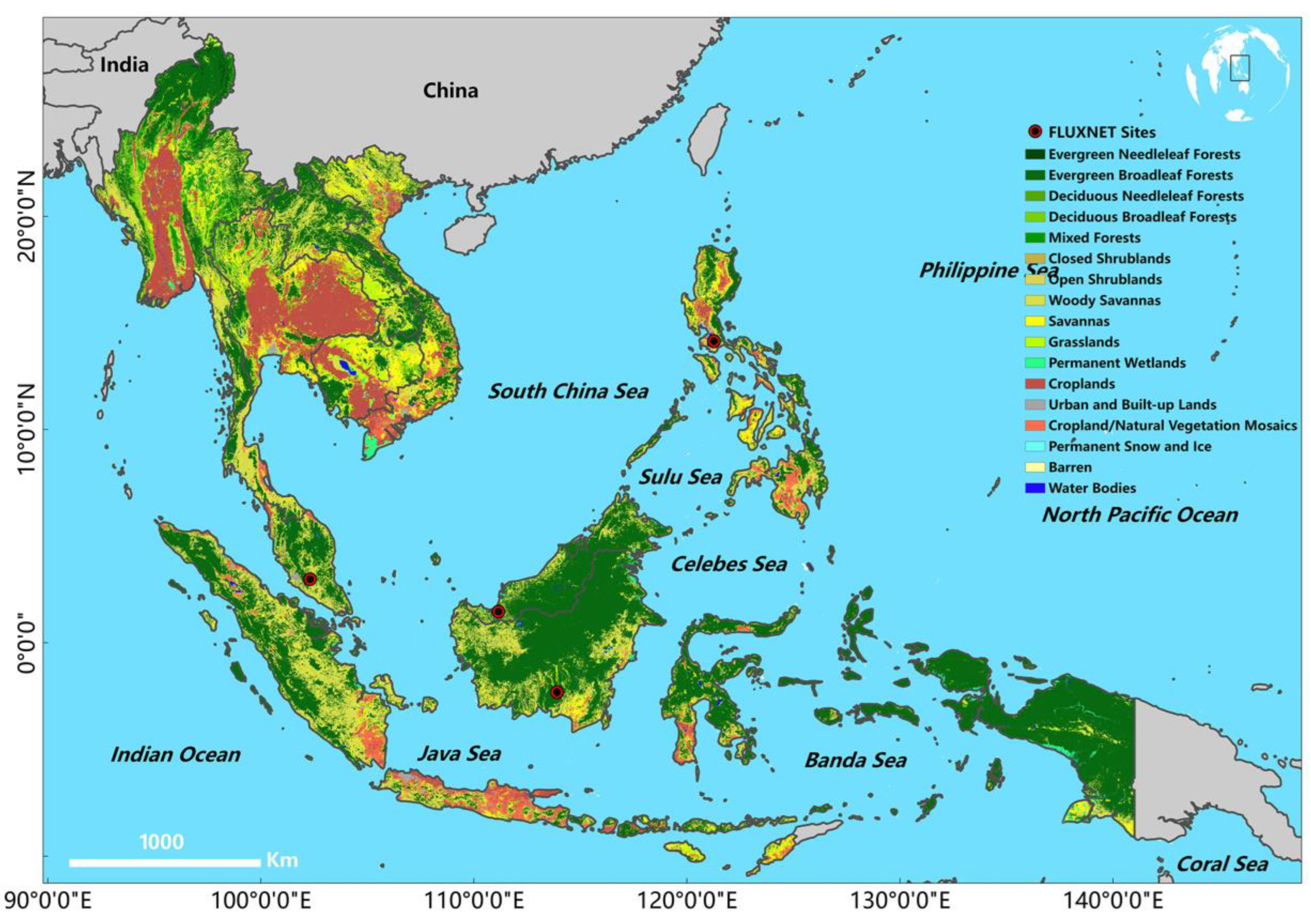
2.1. Study Area Overview
2.2. Data and Pre-Processing
2.3. Methods
2.3.1. Random Forest Algorithm (RF)
2.3.2. Support Vector Regression (SVR)
2.3.3. Backpropagation Neural Network (BPNN)
2.3.4. Convolutional Neural Network (CNN)
2.3.5. Hyperparameter-Optimization Strategy
3. Results
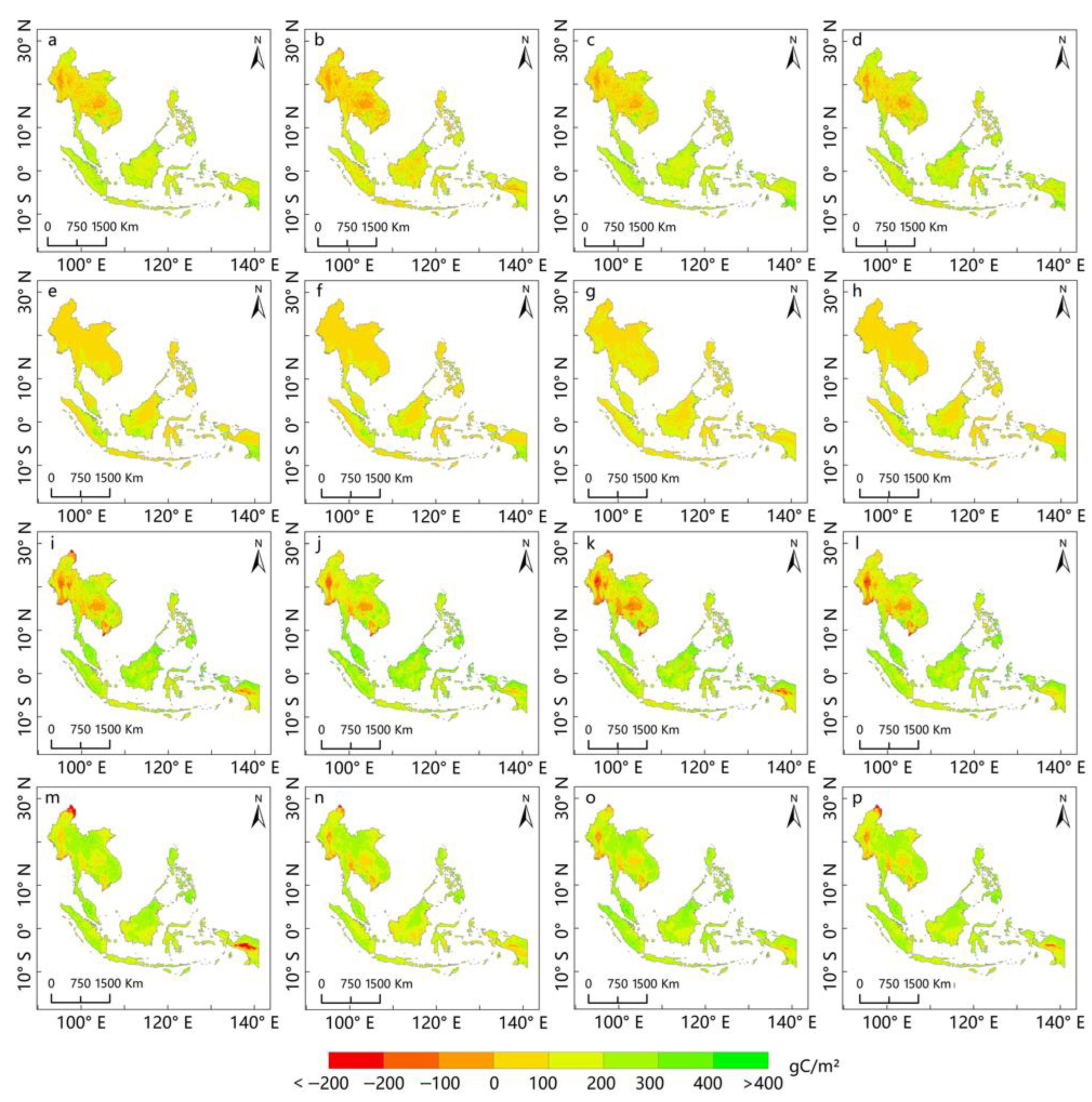
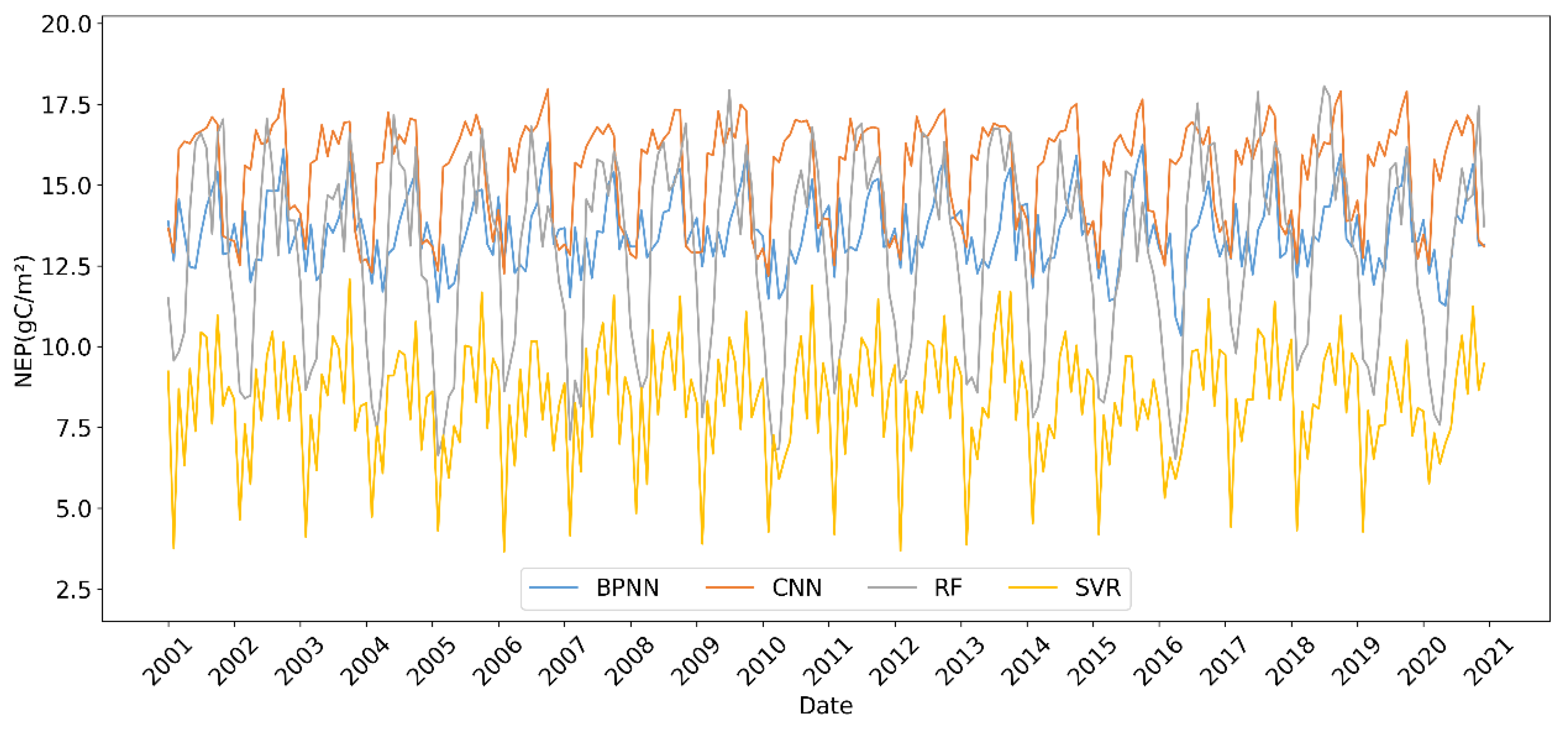
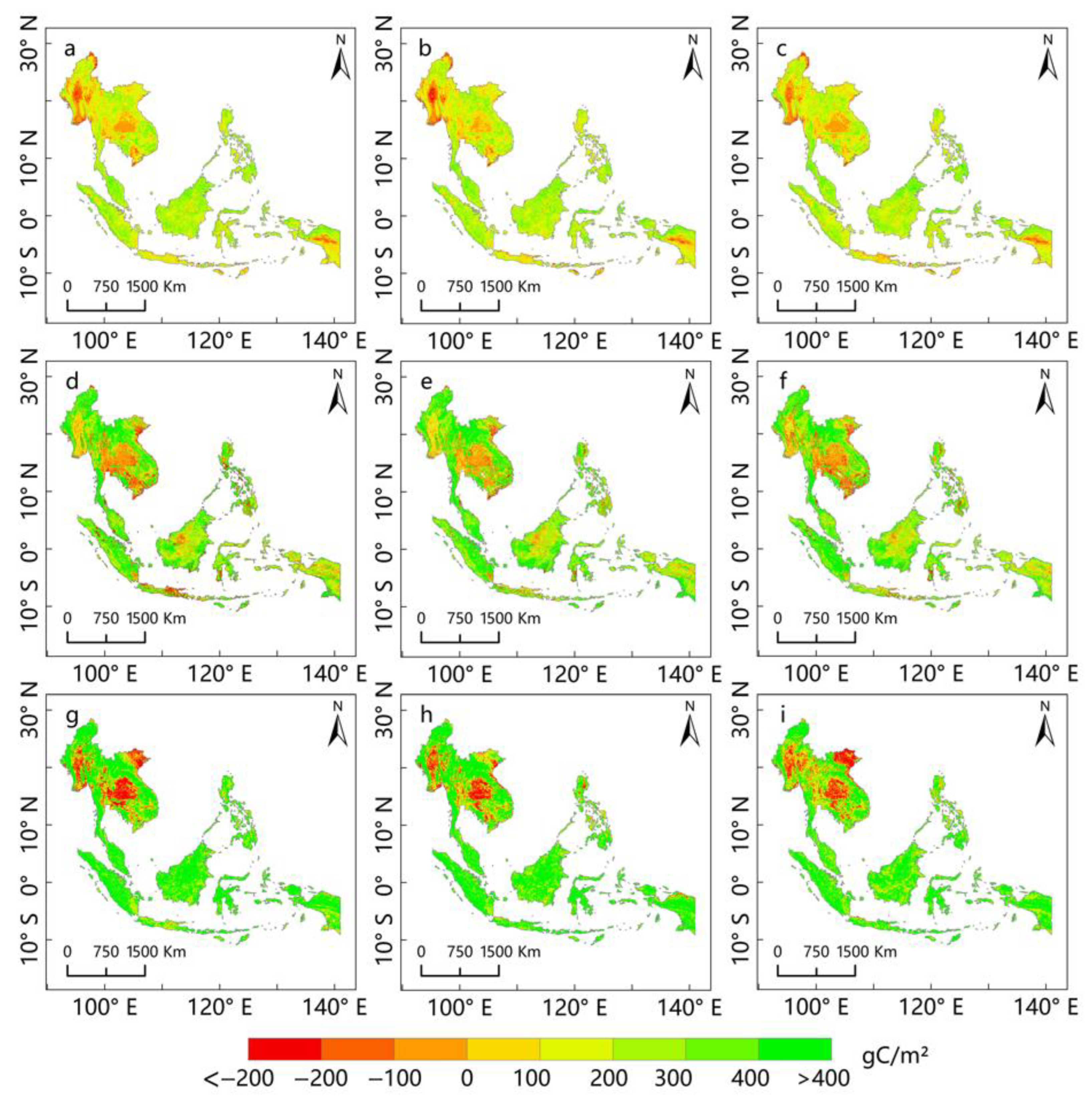
3.1. Application of Multi-Algorithm Predictions for Annual NEP in Southeast Asia
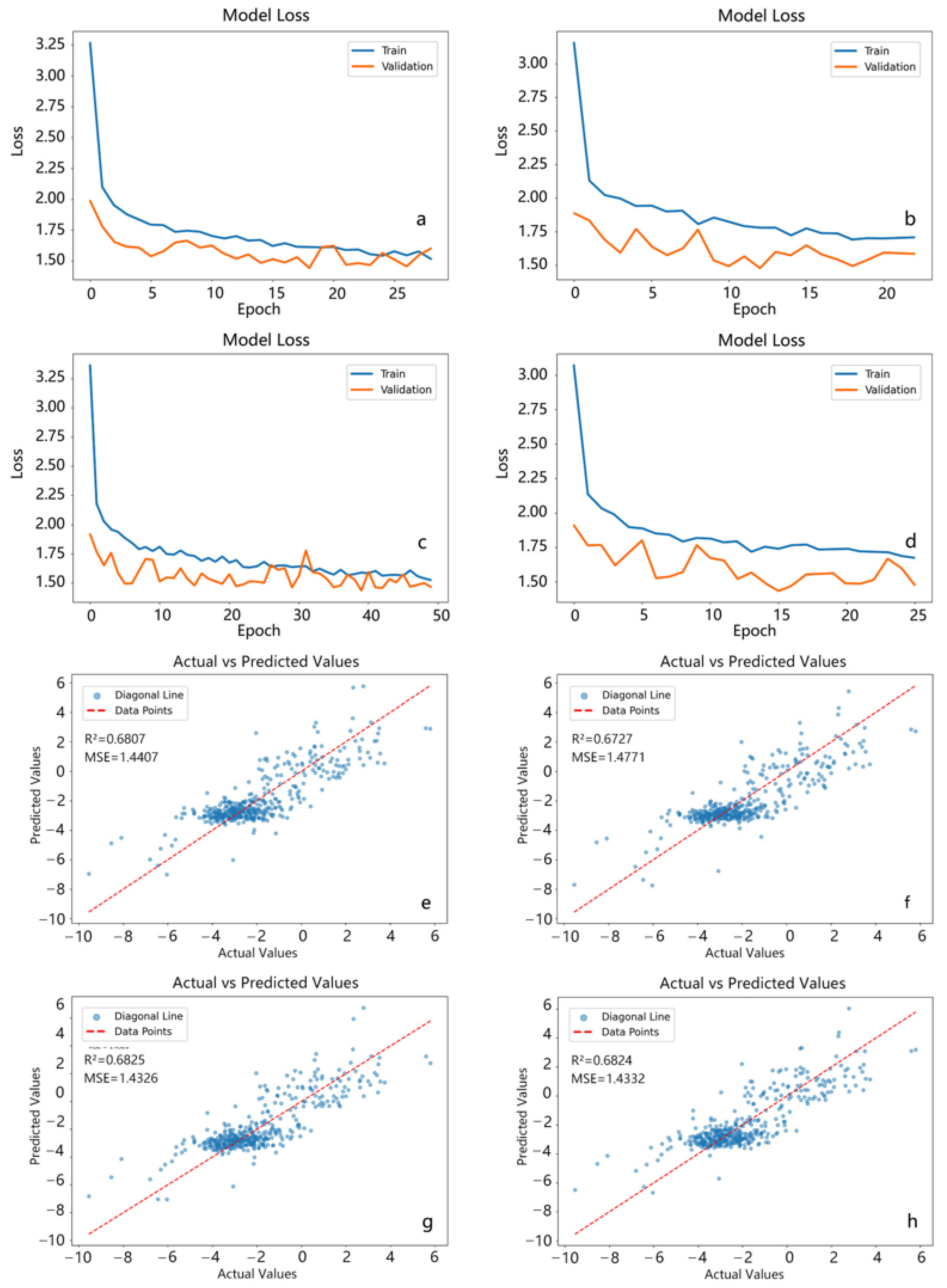
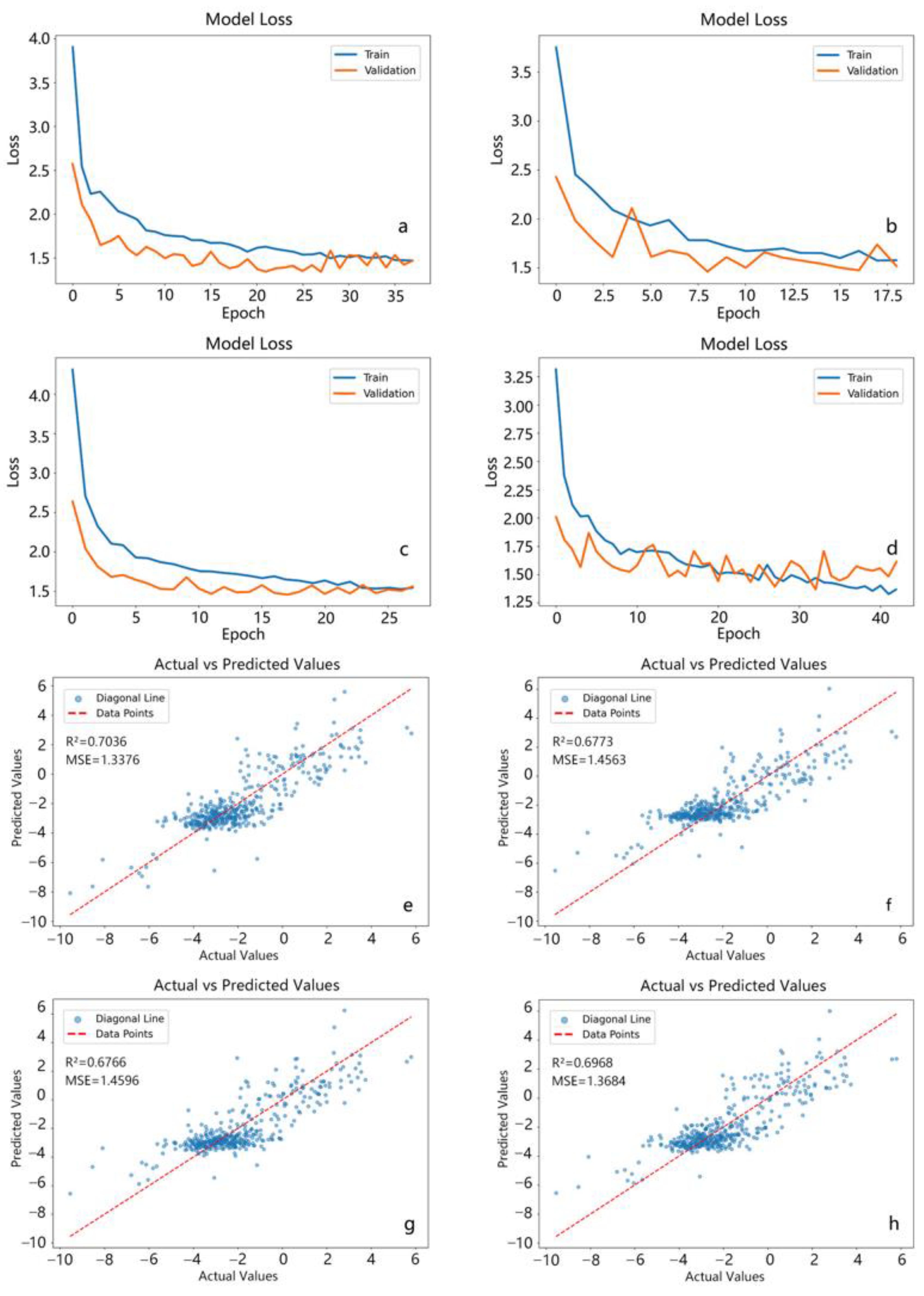
3.1.1. Results of Random Forest Algorithm
3.1.2. Results of the Support Vector Regression Algorithm
3.1.3. Results of the BP Neural Network Algorithm
3.1.4. Results of the Convolutional Neural Network Algorithm
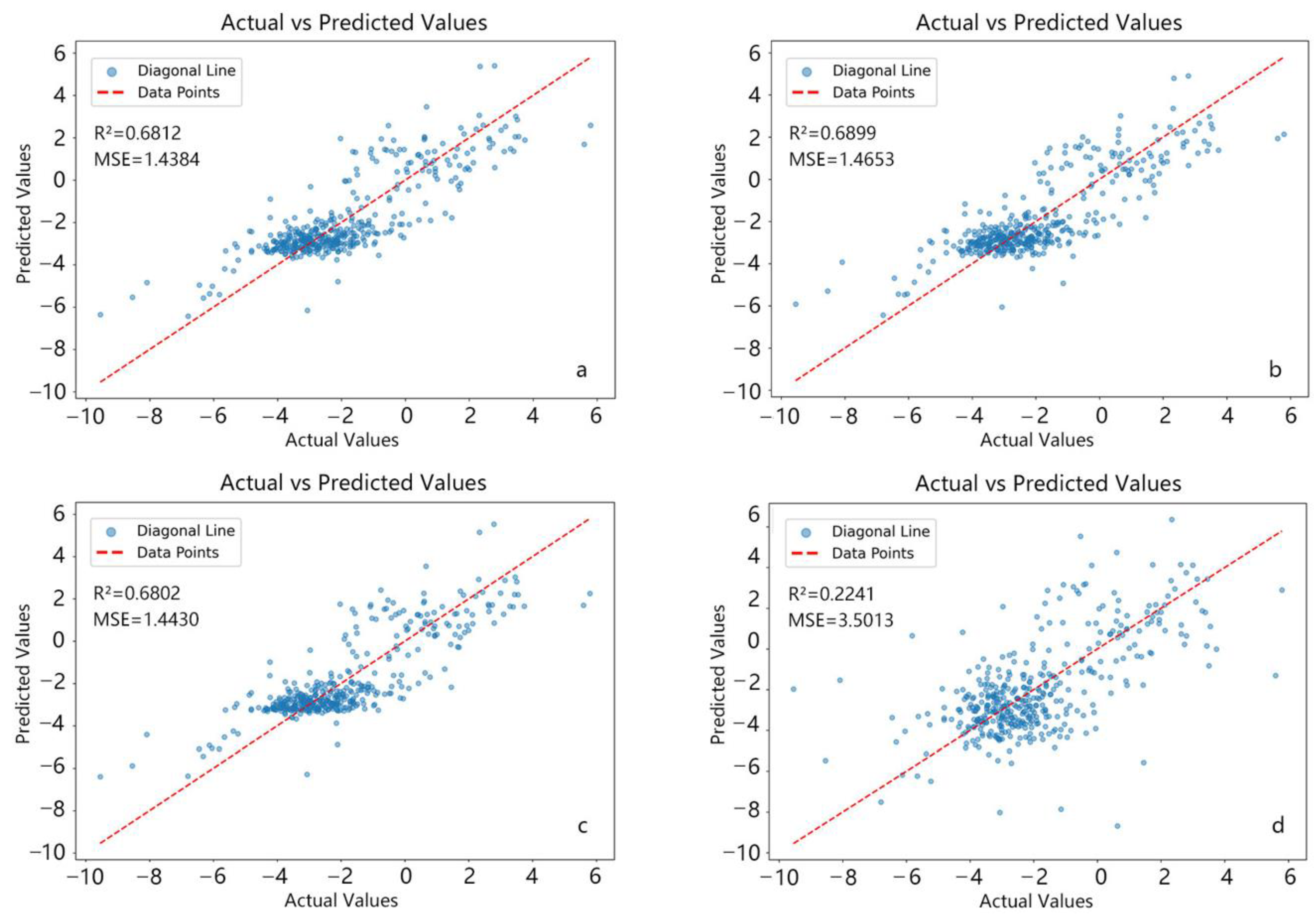
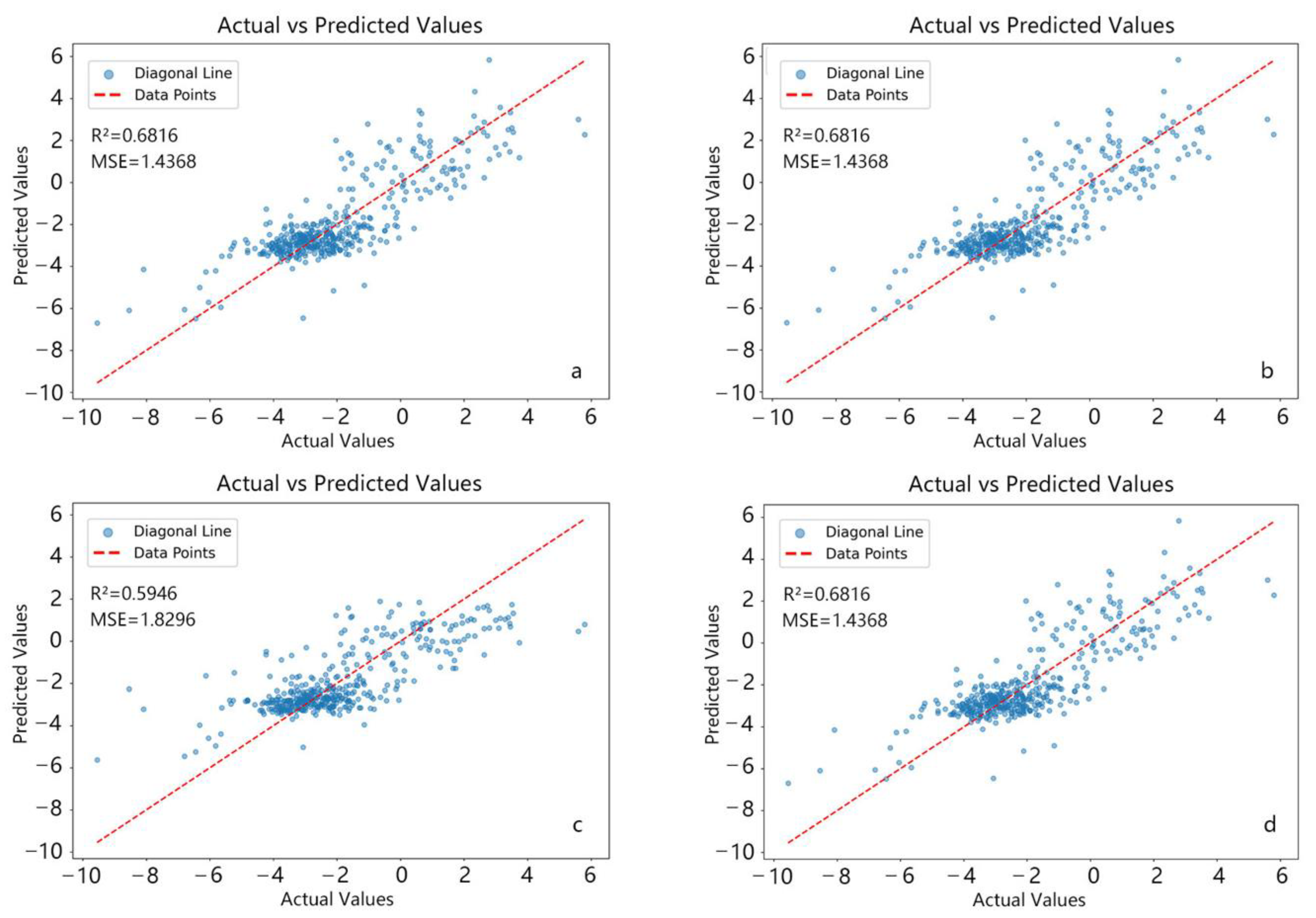
3.2. Selection of the Optimal Prediction Model for Southeast Asia’s NEP
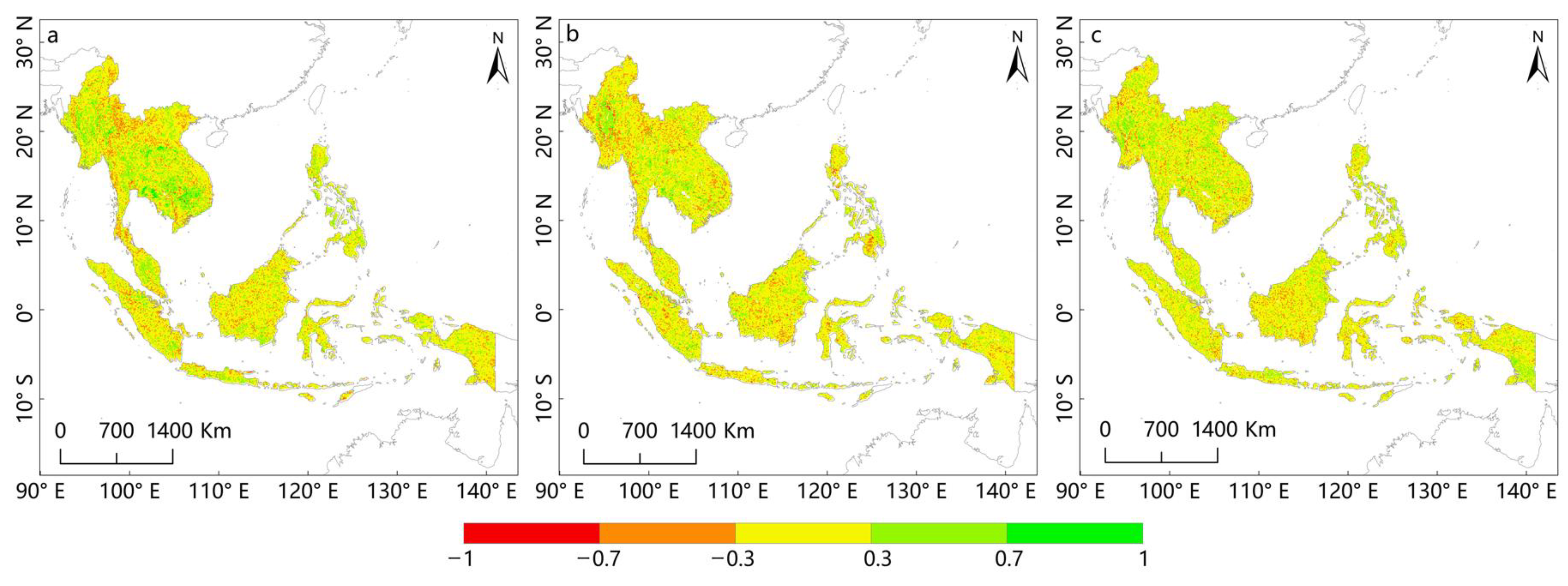
3.3. Validation of the Rationality of the Optimal Prediction Model for NEP in Southeast Asia
4. Discussion
4.1. Comparison of the Performance of Different Machine-Learning Algorithms
4.2. Comparison of Multiple Hyperparameter-Optimization Methods
4.3. Integrating Machine Learning and Ecological Process Models for a New Perspective in NEP Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Breakdown of the NEP Prediction Workflow
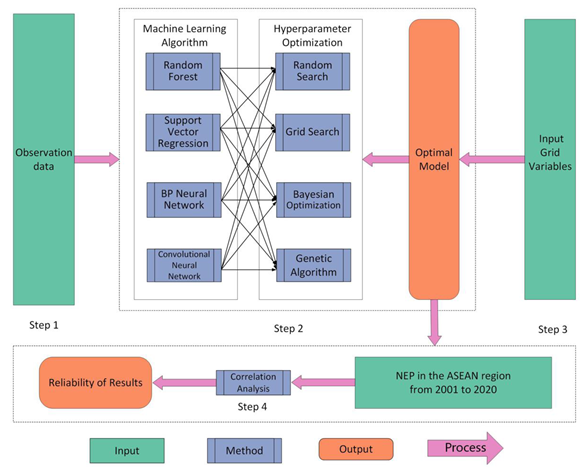
References
- Woodwell, G.M.; Whittaker, R.H.; Reiners, W.A.; Likens, G.E.; Delwiche, C.C.; Botkin, D.B. The Biota and the World Carbon Budget: The Terrestrial Biomass Appears to Be a Net Source of Carbon Dioxide for the Atmosphere. Science 1978, 199, 141–146. [Google Scholar] [CrossRef] [PubMed]
- Fang, J.Y.; Tang, Y.H.; Lin, J.D.; Jiang, G.M. Global Ecology: Climate Change and Ecological Responses. In Changing Global Climates; Chinese Higher Education Press: Beijing, China; Springer: Heidelberg, Germany, 2000; pp. 1–24. [Google Scholar]
- Xu, C.; McDowell, N.G.; Fisher, R.A.; Wei, L.; Sevanto, S.; Christoffersen, B.O.; Weng, E.; Middleton, R.S. Increasing Impacts of Extreme Droughts on Vegetation Productivity under Climate Change. Nat. Clim. Chang. 2019, 9, 948–953. [Google Scholar] [CrossRef]
- Field, C.B.; Behrenfeld, M.J.; Randerson, J.T.; Falkowski, P. Primary Production of the Biosphere: Integrating Terrestrial and Oceanic Components. Science 1998, 281, 237–240. [Google Scholar] [CrossRef] [PubMed]
- Cramer, W.; Bondeau, A.; Woodward, F.I.; Prentice, I.C.; Betts, R.A.; Brovkin, V.; Cox, P.M.; Fisher, V.; Foley, J.A.; Friend, A.D. Global Response of Terrestrial Ecosystem Structure and Function to CO2 and Climate Change: Results from Six Dynamic Global Vegetation Models. Glob. Chang. Biol. 2001, 7, 357–373. [Google Scholar] [CrossRef]
- Bondeau, A.; Smith, P.C.; Zaehle, S.; Schaphoff, S.; Lucht, W.; Cramer, W.; Gerten, D.; Lotze-Campen, H.; Müller, C.; Reichstein, M. Modelling the Role of Agriculture for the 20th Century Global Terrestrial Carbon Balance. Glob. Chang. Biol. 2007, 13, 679–706. [Google Scholar] [CrossRef]
- Huang, C.; Sun, C.; Nguyen, M.; Wu, Q.; He, C.; Yang, H.; Tu, P.; Hong, S. Spatio-Temporal Dynamics of Terrestrial Net Ecosystem Productivity in the ASEAN from 2001 to 2020 Based on Remote Sensing and Improved CASA Model. Ecol. Indic. 2023, 154, 110920. [Google Scholar] [CrossRef]
- Zhang, J.; Hao, X.; Hao, H.; Fan, X.; Li, Y. Climate Change Decreased Net Ecosystem Productivity in the Arid Region of Central Asia. Remote Sens. 2021, 13, 4449. [Google Scholar] [CrossRef]
- Zaehle, S.; Friend, A.D. Carbon and Nitrogen Cycle Dynamics in the O-CN Land Surface Model: 1. Model Description, Site-Scale Evaluation, and Sensitivity to Parameter Estimates. Glob. Biogeochem. Cycles 2010, 24, GB100. [Google Scholar] [CrossRef]
- Cao, M.; Woodward, F. Net Primary and Ecosystem Production and Carbon Stocks of Terrestrial Ecosystems and Their Responses to Climate Change. Glob. Chang. Biol. 1998, 4, 185–198. [Google Scholar] [CrossRef]
- Zhan, W.; Yang, X.; Ryu, Y.; Dechant, B.; Huang, Y.; Goulas, Y.; Kang, M.; Gentine, P. Two for One: Partitioning CO2 Fluxes and Understanding the Relationship between Solar-Induced Chlorophyll Fluorescence and Gross Primary Productivity Using Machine Learning. Agric. For. Meteorol. 2022, 321, 108980. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Prabhat Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Jung, M.; Reichstein, M.; Margolis, H.A.; Cescatti, A.; Richardson, A.D.; Arain, M.A.; Arneth, A.; Bernhofer, C.; Bonal, D.; Chen, J. Global Patterns of Land-atmosphere Fluxes of Carbon Dioxide, Latent Heat, and Sensible Heat Derived from Eddy Covariance, Satellite, and Meteorological Observations. J. Geophys. Res. Biogeosci. 2011, 116, G00J07. [Google Scholar] [CrossRef]
- De Kauwe, M.G.; Lin, Y.-S.; Wright, I.J.; Medlyn, B.E.; Crous, K.Y.; Ellsworth, D.S.; Maire, V.; Prentice, I.C.; Atkin, O.K.; Rogers, A. A Test of the ‘One-point Method’ for Estimating Maximum Carboxylation Capacity from Field-measured, Light-saturated Photosynthesis. New Phytol. 2016, 210, 1130–1144. [Google Scholar] [CrossRef] [PubMed]
- Fisher, R.A.; Muszala, S.; Verteinstein, M.; Lawrence, P.; Xu, C.; McDowell, N.G.; Knox, R.G.; Koven, C.; Holm, J.; Rogers, B.M.; et al. Taking off the Training Wheels: The Properties of a Dynamic Vegetation Model without Climate Envelopes, CLM4.5(ED). Geosci. Model Dev. 2015, 8, 3593–3619. [Google Scholar] [CrossRef]
- Medlyn, B.E.; Zaehle, S.; De Kauwe, M.G.; Walker, A.P.; Dietze, M.C.; Hanson, P.J.; Hickler, T.; Jain, A.K.; Luo, Y.; Parton, W.; et al. Using Ecosystem Experiments to Improve Vegetation Models. Nat. Clim. Chang. 2015, 5, 528–534. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Crisci, C.; Ghattas, B.; Perera, G. A Review of Supervised Machine Learning Algorithms and Their Applications to Ecological Data. Ecol. Model. 2012, 240, 113–122. [Google Scholar] [CrossRef]
- Knudby, A.; Brenning, A.; LeDrew, E. New Approaches to Modelling Fish–Habitat Relationships. Ecol. Model. 2010, 221, 503–511. [Google Scholar] [CrossRef]
- Huang, N.; Wang, L.; Zhang, Y.; Gao, S.; Niu, Z. Estimating the Net Ecosystem Exchange at Global FLUXNET Sites Using a Random Forest Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9826–9836. [Google Scholar] [CrossRef]
- Zeng, J. A Data-Driven Upscale Product of Global Gross Primary Production, Net Ecosystem Exchange and Ecosystem Respiration, Ver.2020.2. Cent. Glob. Environ. Res. 2020. [Google Scholar] [CrossRef]
- Besnard, S. Controls of Forest Age and Ecological Memory Effects on Biosphere-Atmosphere CO2 Exchange; Wageningen University and Research: Wageningen, The Netherlands, 2019. [Google Scholar]
- Zeng, J.; Matsunaga, T.; Tan, Z.-H.; Saigusa, N.; Shirai, T.; Tang, Y.; Peng, S.; Fukuda, Y. Global Terrestrial Carbon Fluxes of 1999–2019 Estimated by Upscaling Eddy Covariance Data with a Random Forest. Sci. Data 2020, 7, 313. [Google Scholar] [CrossRef] [PubMed]
- Chuan, G.K. The Climate of Southeast Asia. In The Physical Geography of Southeast Asia; Oxford University Press: Oxford, UK, 2005; ISBN 978-0-19-924802-5. [Google Scholar]
- Rodda, S.R.; Thumaty, K.C.; Jha, C.S.; Dadhwal, V.K. Seasonal Variations of Carbon Dioxide, Water Vapor and Energy Fluxes in Tropical Indian Mangroves. Forests 2016, 7, 35. [Google Scholar] [CrossRef]
- Kuppel, S.; Peylin, P.; Maignan, F.; Chevallier, F.; Kiely, G.; Montagnani, L.; Cescatti, A. Model–Data Fusion across Ecosystems: From Multisite Optimizations to Global Simulations. Geosci. Model Dev. 2014, 7, 2581–2597. [Google Scholar] [CrossRef]
- Casas-Ruiz, J.P.; Bodmer, P.; Bona, K.A.; Butman, D.; Couturier, M.; Emilson, E.J.S.; Finlay, K.; Genet, H.; Hayes, D.; Karlsson, J.; et al. Integrating terrestrial and aquatic ecosystems to constrain estimates of land-atmosphere carbon exchange. Nat. Commun. 2023, 14, 1571. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Casanovas, N.; Matamala, R.; Cook, D.R.; Gonzalez-Meler, M.A. Net ecosystem exchange modifies the relationship between the autotrophic and heterotrophic components of soil respiration with abiotic factors in prairie grasslands. Glob. Chang. Biol. 2012, 18, 2532–2545. [Google Scholar] [CrossRef]
- Dobrokhotov, A.V.; Maksenkova, I.L.; Kozyreva, L.V.; Sándor, R. Model-Based Assessment of Spatial Distribution of Stomatal Conductance in Forage Herb Ecosystems. Agric. Biol. 2017, 52, 446–453. [Google Scholar] [CrossRef]
- Fu, Z.; Stoy, P.C.; Poulter, B.; Gerken, T.; Zhang, Z.; Wakbulcho, G.; Niu, S. Maximum Carbon Uptake Rate Dominates the Interannual Variability of Global Net Ecosystem Exchange. Glob. Chang. Biol. 2019, 25, 3381–3394. [Google Scholar] [CrossRef] [PubMed]
- Paschalis, A.; Fatichi, S.; Pappas, C.; Or, D. Covariation of Vegetation and Climate Constrains Present and Future T/ET Variability. Environ. Res. Lett. 2018, 13, 104012. [Google Scholar] [CrossRef]
- Burns, S.P.; Blanken, P.D.; Turnipseed, A.A.; Hu, J.; Monson, R.K. The Influence of Warm-Season Precipitation on the Diel Cycle of the Surface Energy Balance and Carbon Dioxide at a Colorado Subalpine Forest Site. Biogeosciences 2015, 12, 7349–7377. [Google Scholar] [CrossRef]
- Gaveau, D.L.A.; Salim, M.A.; Hergoualc’h, K.; Locatelli, B.; Sloan, S.; Wooster, M.; Marlier, M.E.; Molidena, E.; Yaen, H.; DeFries, R.; et al. Major Atmospheric Emissions from Peat Fires in Southeast Asia during Non-Drought Years: Evidence from the 2013 Sumatran Fires. Sci. Rep. 2014, 4, 6112. [Google Scholar] [CrossRef]
- Wilcove, D.S.; Koh, L.P. Addressing the Threats to Biodiversity from Oil-Palm Agriculture. Biodivers. Conserv. 2010, 19, 999–1007. [Google Scholar] [CrossRef]
- Scornet, E.; Biau, G.; Vert, J.-P. Consistency of Random Forests. Ann. Stat. 2015, 43, 1716–1741. [Google Scholar] [CrossRef]
- Cai, J.; Xu, K.; Zhu, Y.; Hu, F.; Li, L. Prediction and Analysis of Net Ecosystem Carbon Exchange Based on Gradient Boosting Regression and Random Forest. Appl. Energy 2020, 262, 114566. [Google Scholar] [CrossRef]
- Josalin, J.J.; Nelson, J.D.; Lantin, R.S.; Venkatesh, P. Proposing a Hybrid Genetic Algorithm Based Parsimonious Random Forest Regression (H-GAPRFR) Technique for Solar Irradiance Forecasting with Feature Selection and Parameter Optimization. Earth Sci. Inf. 2022, 15, 1925–1942. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Heddam, S.; Zounemat-Kermani, M.; Kisi, O.; Li, B. Least Square Support Vector Machine and Multivariate Adaptive Regression Splines for Streamflow Prediction in Mountainous Basin Using Hydro-Meteorological Data as Inputs. J. Hydrol. 2020, 586, 124371. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Shirzadi, A.; Shahabi, H.; Singh, S.K.; Al-Ansari, N.; Clague, J.J.; Jaafari, A.; Chen, W.; Miraki, S.; Dou, J. Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms. Int. J. Environ. Res. Public Health 2020, 17, 2749. [Google Scholar] [CrossRef]
- Xie, M.; Wang, D.; Xie, L. One SVR Modeling Method Based on Kernel Space Feature. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 168–174. [Google Scholar] [CrossRef]
- Gouravaraju, S.; Narayan, J.; Sauer, R.A.; Gautam, S.S. A Bayesian Regularization-Backpropagation Neural Network Model for Peeling Computations. J. Adhes. 2023, 99, 92–115. [Google Scholar] [CrossRef]
- Yu, W.; Xu, X.; Jin, S.; Ma, Y.; Liu, B.; Gong, W. BP Neural Network Retrieval for Remote Sensing Atmospheric Profile of Ground-Based Microwave Radiometer. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhao, W.; Zhou, C.; Zhou, C.; Ma, H.; Wang, Z. Soil Salinity Inversion Model of Oasis in Arid Area Based on UAV Multispectral Remote Sensing. Remote Sens. 2022, 14, 1804. [Google Scholar] [CrossRef]
- Ilesanmi, A.E.; Ilesanmi, T.O. Methods for Image Denoising Using Convolutional Neural Network: A Review. Complex Intell. Syst. 2021, 7, 2179–2198. [Google Scholar] [CrossRef]
- Zhong, Z.; Carr, T.R.; Wu, X.; Wang, G. Application of a Convolutional Neural Network in Permeability Prediction: A Case Study in the Jacksonburg-Stringtown Oil Field, West Virginia, USA. Geophysics 2019, 84, B363–B373. [Google Scholar] [CrossRef]
- Miao, S.; Wang, Z.J.; Liao, R. A CNN Regression Approach for Real-Time 2D/3D Registration. IEEE Trans. Med. Imaging 2016, 35, 1352–1363. [Google Scholar] [CrossRef] [PubMed]
- Wassan, S.; Xi, C.; Jhanjhi, N.Z.; Binte-Imran, L. Effect of Frost on Plants, Leaves, and Forecast of Frost Events Using Convolutional Neural Networks. Int. J. Distrib. Sens. Netw. 2021, 17, 155014772110537. [Google Scholar] [CrossRef]
- Fernandez-Beltran, R.; Baidar, T.; Kang, J.; Pla, F. Rice-Yield Prediction with Multi-Temporal Sentinel-2 Data and 3D CNN: A Case Study in Nepal. Remote Sens. 2021, 13, 1391. [Google Scholar] [CrossRef]
- Florea, A.; Andonie, R. Weighted Random Search for Hyperparameter Optimization. Int. J. Comput. Commun. Control 2019, 14, 154–169. [Google Scholar] [CrossRef]
- Alibrahim, H.; Ludwig, S.A. Hyperparameter Optimization: Comparing Genetic Algorithm against Grid Search and Bayesian Optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Krakow, Poland, 28 June–1 July 2021; pp. 1551–1559. [Google Scholar]
- Basuki, I.; Kauffman, J.B.; Peterson, J.T.; Anshari, G.Z.; Murdiyarso, D. Land Cover and Land Use Change Decreases Net Ecosystem Production in Tropical Peatlands of West Kalimantan, Indonesia. Forests 2021, 12, 1587. [Google Scholar] [CrossRef]
- Qie, L.; Lewis, S.L.; Sullivan, M.J.P.; Lopez-Gonzalez, G.; Pickavance, G.C.; Sunderland, T.; Ashton, P.; Hubau, W.; Abu Salim, K.; Aiba, S.-I.; et al. Long-Term Carbon Sink in Borneo’s Forests Halted by Drought and Vulnerable to Edge Effects. Nat. Commun. 2017, 8, 1966. [Google Scholar] [CrossRef]
- Adachi, M.; Ito, A.; Ishida, A.; Kadir, W.R.; Ladpala, P.; Yamagata, Y. Carbon Budget of Tropical Forests in Southeast Asia and the Effects of Deforestation: An Approach Using a Process-Based Model and Field Measurements. Biogeosciences 2011, 8, 2635–2647. [Google Scholar] [CrossRef]
- Kumara, T.K.; Kandpal, A.; Pal, S. A Meta-Analysis of Economic and Environmental Benefits of Conservation Agriculture in South Asia. J. Environ. Manag. 2020, 269, 110773. [Google Scholar] [CrossRef]
- Wassmann, R.; Lantin, R.S.; Neue, H.U.; Buendia, L.V.; Corton, T.M.; Lu, Y. Characterization of Methane Emissions from Rice Fields in Asia. III. Mitigation Options and Future Research Needs. Nutr. Cycl. Agroecosyst. 2000, 58, 23–36. [Google Scholar] [CrossRef]
- Erden, C.; Demir, H.I.; Kokccam, A.H. Enhancing Machine Learning Model Performance with Hyper Parameter Optimization: A Comparative Study. arXiv 2023, arXiv:2302.11406. [Google Scholar]
- Candelieri, A.; Archetti, F. Global Optimization in Machine Learning: The Design of a Predictive Analytics Application. Soft Comput. 2019, 23, 2969–2977. [Google Scholar] [CrossRef]
- Vincent, A.M.; Jidesh, P. An improved hyperparameter optimization framework for AutoML systems using evolutionary algorithms. Sci. Rep. 2023, 13, 4737. [Google Scholar] [CrossRef] [PubMed]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Performance evaluation and hyperpa-rameter tuning of statistical and machine-learning models using spatial data. arXiv 2018, arXiv:1803.11266. [Google Scholar] [CrossRef]
- Luo, Y.; Weng, E.; Wu, X.; Gao, C.; Zhou, X.; Zhang, L. Parameter Identifiability, Constraint, and Equifinality in Data Assimilation with Ecosystem Models. Ecol. Appl. 2009, 19, 571–574. Available online: https://www.jstor.org/stable/27645995 (accessed on 21 September 2023). [CrossRef]
- Clark, D.B.; Mercado, L.M.; Sitch, S.; Jones, C.D.; Gedney, N.; Best, M.J.; Pryor, M.; Rooney, G.G.; Essery, R.L.H.; Blyth, E.; et al. The Joint UK Land Environment Simulator (JULES), model description—Part 2: Carbon fluxes and vegetation dynamics. Geosci. Model Dev. 2011, 4, 701–722. [Google Scholar] [CrossRef]
- Friedlingstein, P.; Cox, P.; Betts, R.; Bopp, L.; von Bloh, W.; Brovkin, V.; Cadule, P.; Doney, S.; Eby, M.; Fung, I.; et al. Climate–Carbon Cycle Feedback Analysis: Results from the C4MIP Model Intercomparison. J. Clim. 2006, 19, 3337–3353. [Google Scholar] [CrossRef]
- Zhang, Z.; Xin, Q.; Li, W. Machine Learning-Based Modeling of Vegetation Leaf Area Index and Gross Primary Productivity Across North America and Comparison with a Process-Based Model. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002802. [Google Scholar] [CrossRef]
- Shen, C.; Appling, A.P.; Gentine, P.; Bandai, T.; Gupta, H.; Tartakovsky, A.; Baity-Jesi, M.; Fenicia, F.; Kifer, D.; Li, L.; et al. Differentiable modelling to unify machine learning and physical models for geosciences. Nat. Rev. Earth Env. 2023, 4, 552–567. [Google Scholar] [CrossRef]
- Simon, S.M.; Glaum, P.; Valdovinos, F.S. Interpreting random forest analysis of ecological models to move from prediction to explanation. Sci. Rep. 2023, 13, 3881. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Data Type | Original Spatial Resolution (m) | Data Type |
|---|---|---|---|
| NEE, H, LE, SW, LW, VPD, PA, TA, P, WS | CSV | / | FLUXNET2015 Dataset 1 |
| NDVI | CSV | / | MCD43A4.061 2 |
| NEE, H, LE, SW, LW, VPD, PA, TA, P, WS | tif | 11,132 | ERA5 Monthly Aggregates 3 |
| NDVI | tif | 11,132 | MCD43A4.061 2 |
| NEP | tif | / | NIES 4 |
| NEP | tif | / | National Earth System Science Data Center National Science and Technology Infrastructure of China 5 |
| Optimization Strategy | Trees | Depth | Min split | Min leaf | N_ITER | CV | PS |
|---|---|---|---|---|---|---|---|
| RS | 200 | 20 | 5 | 1 | 100 | 3 | / |
| GS | 500 | 40 | 10 | 4 | / | 3 | / |
| BO | 122 | 12 | 2 | 1 | 100 | 3 | / |
| GA | 100 | None | 2 | 1 | 50 | / | 20 |
| Optimization Strategy | Kernel | Epsilon | C | N_ITER | CV | PS |
|---|---|---|---|---|---|---|
| RS | RBF | 1.0 | 10.0 | 100 | 3 | / |
| GS | RBF | 1.0 | 10.0 | / | 3 | / |
| BO | RBF | 1 × 10−6 | 0.2208 | 100 | 3 | / |
| GA | RBF | 1.0 | 10.0 | 50 | / | 10 |
| Optimization Strategy | UH | DR | LR | Act | Opt | MT | ES |
|---|---|---|---|---|---|---|---|
| RS | 128 | 0.1 | 0.004 | ReLU | Adam | 100 | 10 |
| GS | 64 | 0.4 | 0.0078 | ReLU | Adam | 200 | 10 |
| BO | 96 | 0.3 | 0.006 | ReLU | Adam | 200 | 10 |
| GA | 64 | 0.4 | 0.0078 | ReLU | Adam | 200 | 10 |
| Optimization Strategy | UH | DR | LR | Act | Opt | MT | ES |
|---|---|---|---|---|---|---|---|
| RS | 32 | 0.1 | 0.0038 | ReLU | Adam | 50 | 10 |
| GS | 64 | 0.3 | 0.006 | ReLU | Adam | 200 | 10 |
| BO | 128 | 0.4 | 0.001 | ReLU | Adam | 50 | 10 |
| GA | 32 | 0.3 | 0.0071 | ReLU | Adam | 200 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Chen, B.; Sun, C.; Wang, Y.; Zhang, J.; Yang, H.; Wu, S.; Tu, P.; Nguyen, M.; Hong, S.; et al. Synergistic Application of Multiple Machine Learning Algorithms and Hyperparameter Optimization Strategies for Net Ecosystem Productivity Prediction in Southeast Asia. Remote Sens. 2024, 16, 17. https://doi.org/10.3390/rs16010017
Huang C, Chen B, Sun C, Wang Y, Zhang J, Yang H, Wu S, Tu P, Nguyen M, Hong S, et al. Synergistic Application of Multiple Machine Learning Algorithms and Hyperparameter Optimization Strategies for Net Ecosystem Productivity Prediction in Southeast Asia. Remote Sensing. 2024; 16(1):17. https://doi.org/10.3390/rs16010017
Chicago/Turabian StyleHuang, Chaoqing, Bin Chen, Chuanzhun Sun, Yuan Wang, Junye Zhang, Huan Yang, Shengbiao Wu, Peiyue Tu, MinhThu Nguyen, Song Hong, and et al. 2024. "Synergistic Application of Multiple Machine Learning Algorithms and Hyperparameter Optimization Strategies for Net Ecosystem Productivity Prediction in Southeast Asia" Remote Sensing 16, no. 1: 17. https://doi.org/10.3390/rs16010017
APA StyleHuang, C., Chen, B., Sun, C., Wang, Y., Zhang, J., Yang, H., Wu, S., Tu, P., Nguyen, M., Hong, S., & He, C. (2024). Synergistic Application of Multiple Machine Learning Algorithms and Hyperparameter Optimization Strategies for Net Ecosystem Productivity Prediction in Southeast Asia. Remote Sensing, 16(1), 17. https://doi.org/10.3390/rs16010017