

A Parallel-Cascaded Ensemble of Machine Learning Models for Crop Type Classification in Google Earth Engine Using Multi-Temporal Sentinel-1/2 and Landsat-8/9 Remote Sensing Data
 ,
,  and
and 
Abstract
:
1. Introduction
- (1)
- A novel ensemble ML framework is proposed based on a Pa-Ca structure combined with PCA transformation, which integrates the outputs of MLs and multi-source satellite data for improved crop type classification.
- (2)
- Both MS and SAR RS satellite imageries (S1/2 and L8/9) were employed, and the proposed method was evaluated using the Ground Truth (GT) data of different crop types collected using extensive field surveys in Mahabad, Iran.
- (3)
- The study involved conducting a comparative analysis of multiple ML models within the proposed methodology, alongside a comparison between the proposed methodology and two conventional methods used for classifying crop types.
2. Study Area and Datasets
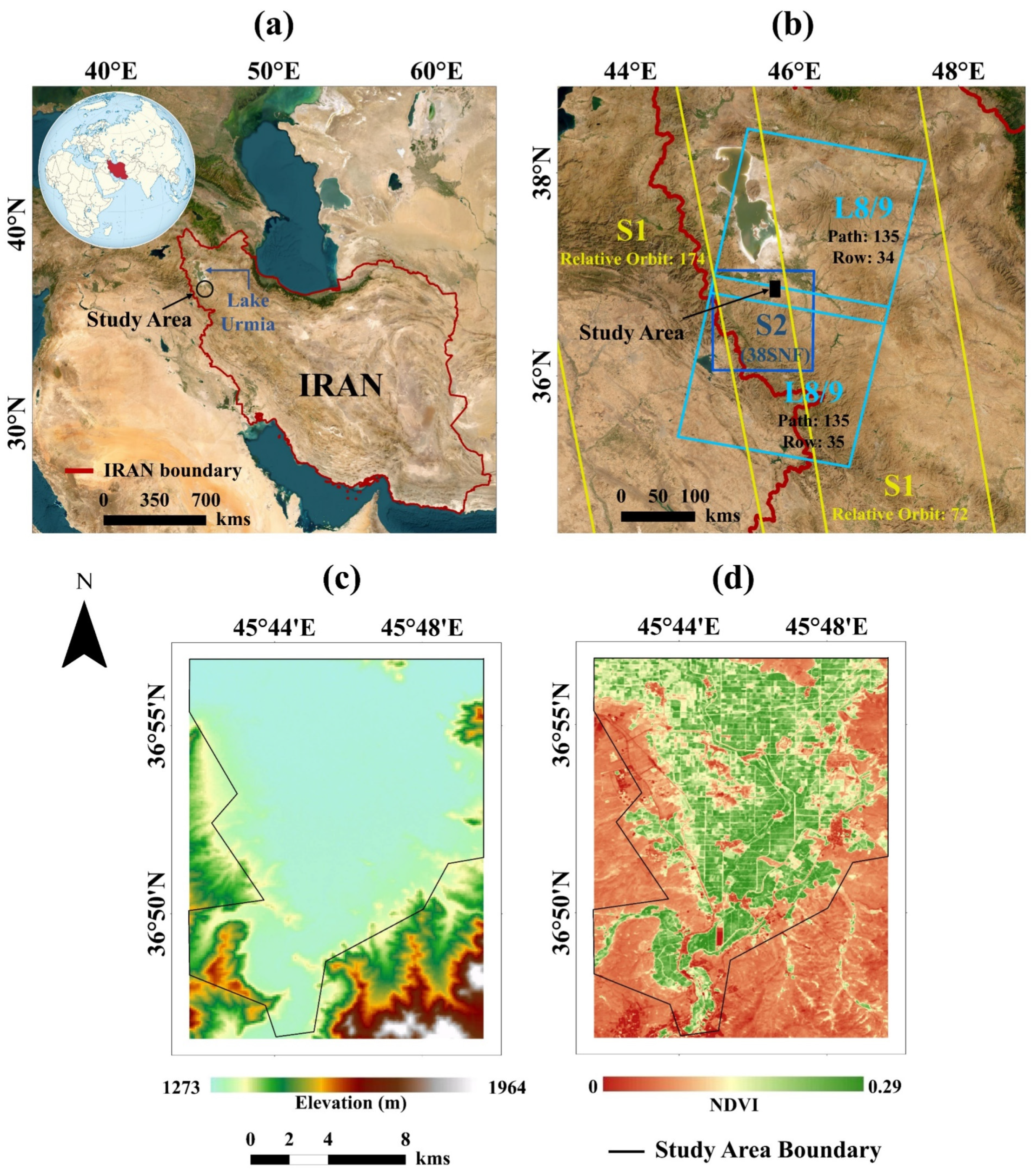
2.1. Study Area
2.2. Datasets
2.2.1. Satellite RS Data
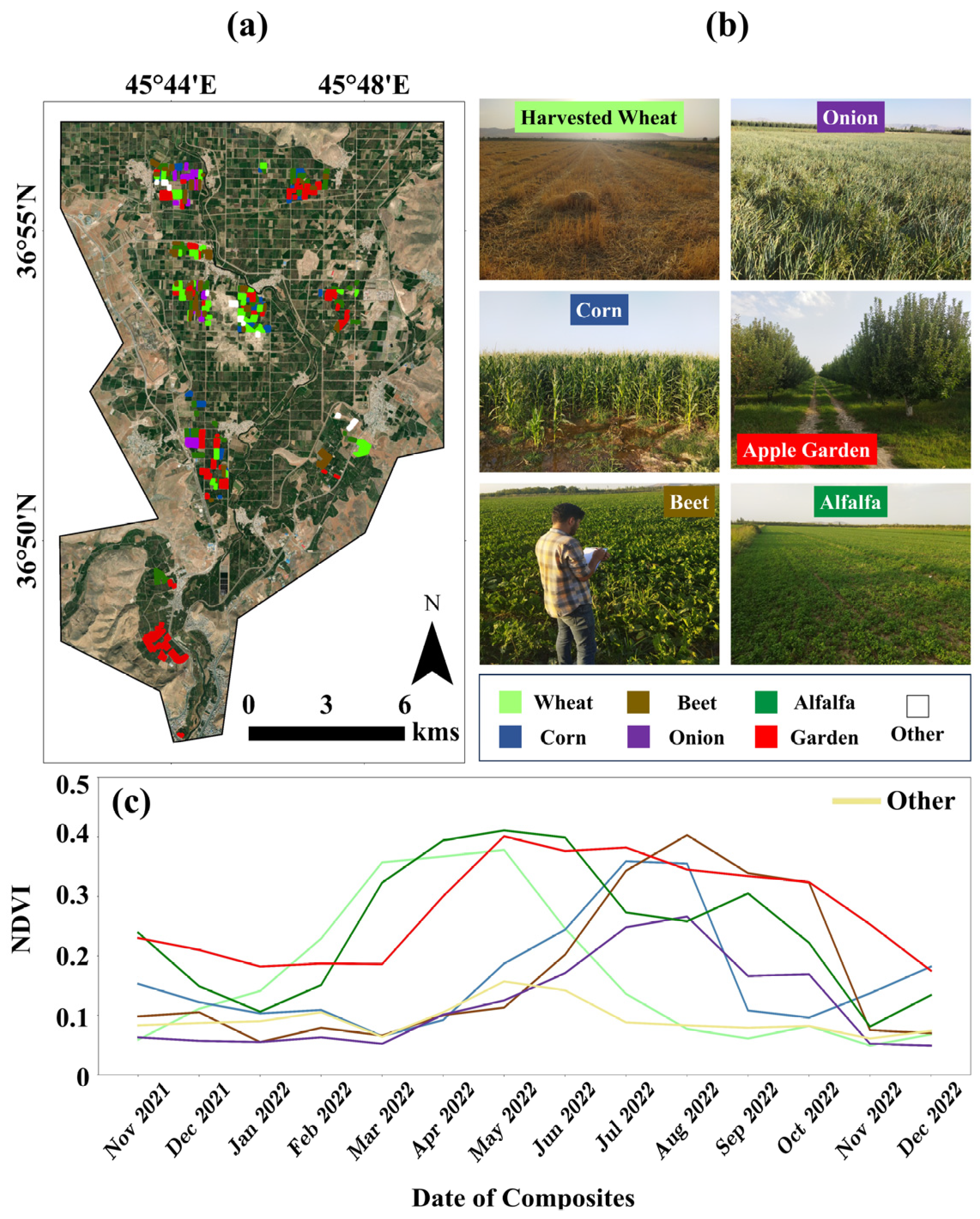
2.2.2. Reference GT Data
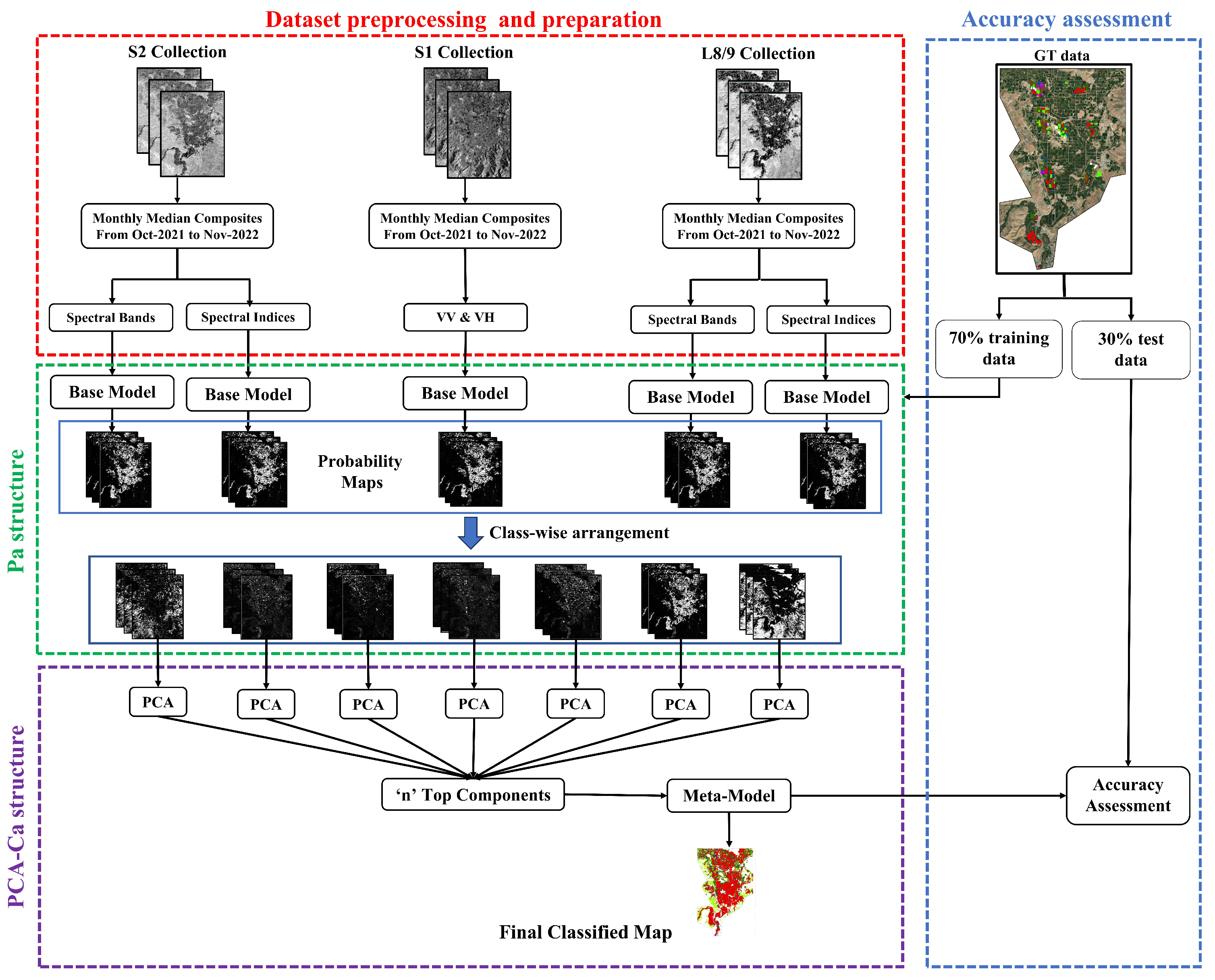
3. Proposed Framework
3.1. Dataset Preprocessing and Preparation
3.2. Pa Structure
3.3. PCA-Ca
3.4. Accuracy Assessment
4. Results
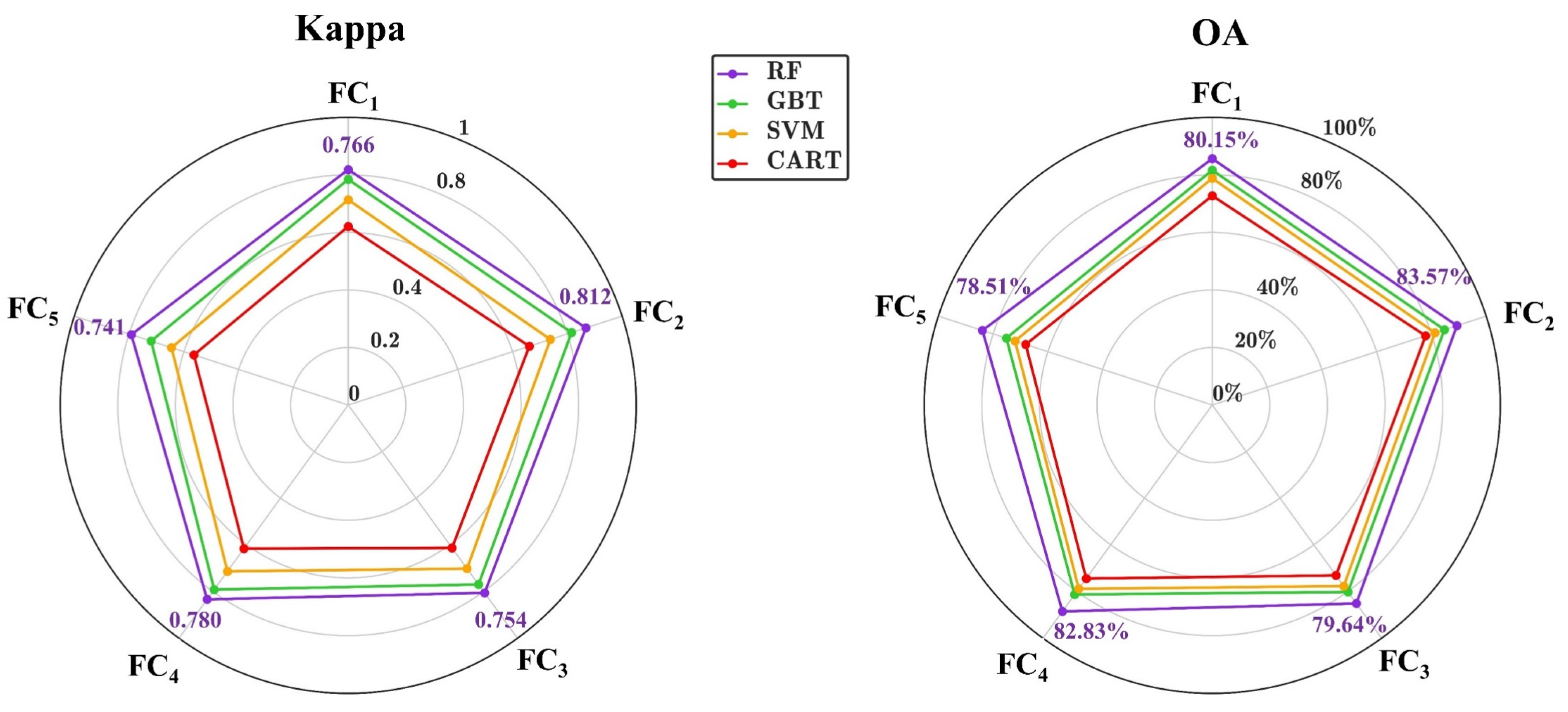
4.1. Base Model Selection in Pa Structure
4.2. Meta Model Selection in Ca Structure
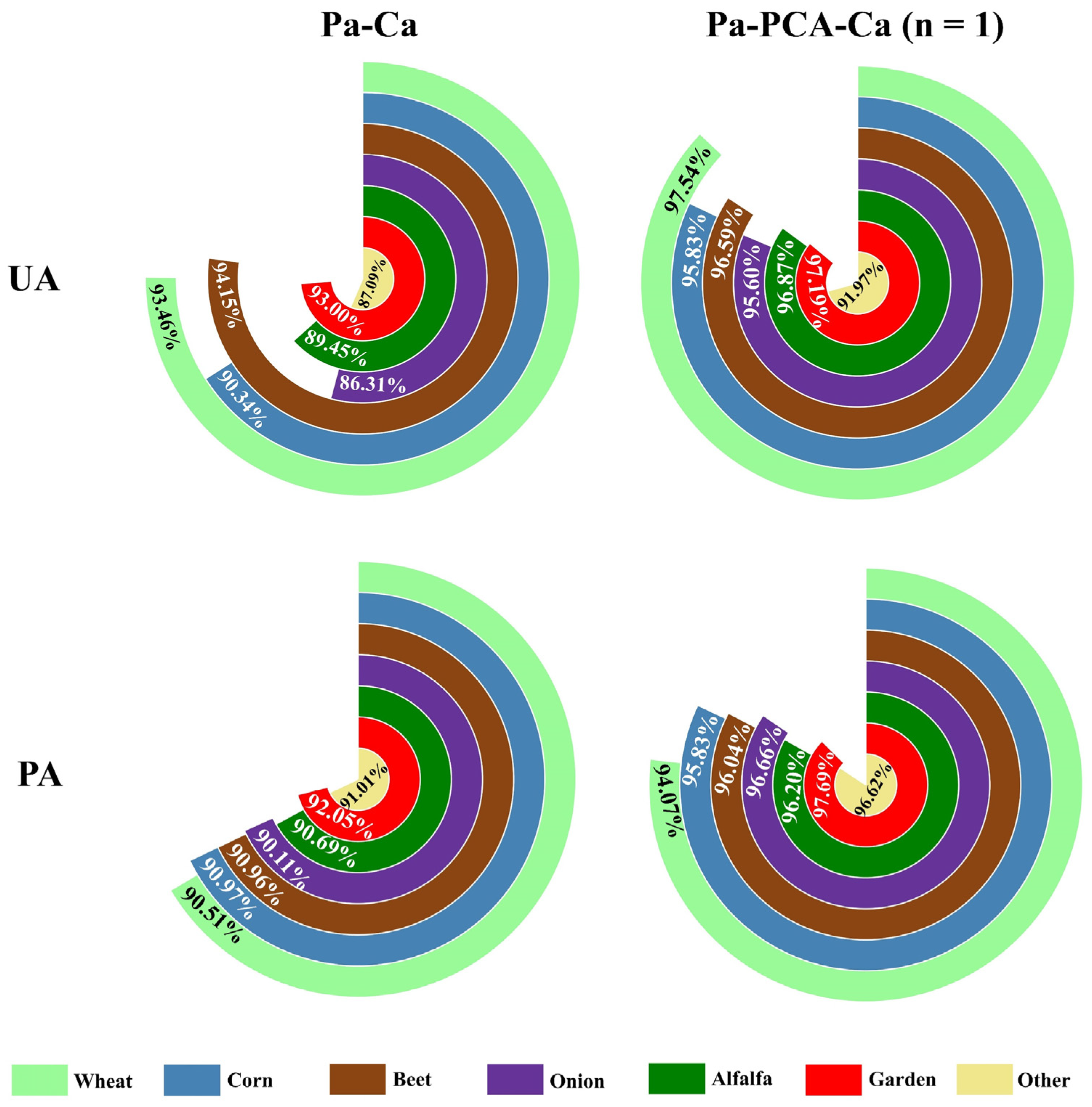
4.3. Input Data Level Ensemble in Pa-Ca Structure
4.4. Pa-PCA-Ca Structure
4.5. Comparison to Conventional Approaches
5. Discussion
5.1. Base Models and Meta-Model
5.2. Proposed Pa-PCA-Ca Structure
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Formula | Description |
|---|---|---|
| NDVI | ρNIR: SR values of NIR band in S2 or L8/9. ρRED: SR values of R band in S2 or L8/9. | |
| NDBI | ρSWIR: SR values of SWIR band in S2 or L8/9. ρNIR: SR values of NIR band in S2 or L8/9. | |
| NDWI | ρGREEN: SR values of G band in S2 or L8/9. ρNIR: SR values of NIR band in S2 or L8/9. | |
| SAVI | ρNIR: SR values of NIR band in S2 or L8/9. ρRED: SR values of R band in S2 or L8/9. Lcoef = 0.5 (soil regulation factor) [65] | |
| EVI | 2.5× | ρNIR: SR values of NIR band in S2 or L8/9. ρRED: SR values of R band in S2 or L8/9. ρBLUE: SR values of R band in S2 or L8/9. |

References
- Ortiz-Bobea, A.; Ault, T.R.; Carrillo, C.M.; Chambers, R.G.; Lobell, D.B. Anthropogenic climate change has slowed global agricultural productivity growth. Nat. Clim. Chang. 2021, 11, 306–312. [Google Scholar] [CrossRef]
- Guo, Y.; Xia, H.; Zhao, X.; Qiao, L.; Du, Q.; Qin, Y. Early-season mapping of winter wheat and garlic in Huaihe basin using Sentinel-1/2 and Landsat-7/8 imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8809–8817. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Karthikeyan, L.; Chawla, I.; Mishra, A.K. A review of remote sensing applications in agriculture for food security: Crop growth and yield, irrigation, and crop losses. J. Hydrol. 2020, 586, 124905. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Mazzanti, P.; Mugnozza, G.S.; Bozzano, F. Coherency and phase delay analyses between land cover and climate across Italy via the least-squares wavelet software. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103241. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Tian, S. Phenology-assisted supervised paddy rice mapping with the Landsat imagery on Google Earth Engine: Experiments in Heilongjiang Province of China from 1990 to 2020. Comput. Electron. Agric. 2023, 212, 108105. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Rahmati, A.; Zoej, M.J.V.; Dehkordi, A.T. Early identification of crop types using Sentinel-2 satellite images and an incremental multi-feature ensemble method (Case study: Shahriar, Iran). Adv. Space Res. 2022, 70, 907–922. [Google Scholar] [CrossRef]
- Taheri Dehkordi, A.; Valadan Zoej, M.J. Classification of croplands using sentinel-2 satellite images and a novel deep 3D convolutional neural network (case study: Shahrekord). Iran. J. Soil Water Res. 2021, 52, 1941–1953. [Google Scholar]
- Aghdami-Nia, M.; Shah-Hosseini, R.; Rostami, A.; Homayouni, S. Automatic coastline extraction through enhanced sea-land segmentation by modifying Standard U-Net. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102785. [Google Scholar] [CrossRef]
- Arabi Aliabad, F.; Ghafarian Malmiri, H.; Sarsangi, A.; Sekertekin, A.; Ghaderpour, E. Identifying and Monitoring Gardens in Urban Areas Using Aerial and Satellite Imagery. Remote Sens. 2023, 15, 4053. [Google Scholar] [CrossRef]
- Woźniak, E.; Rybicki, M.; Kofman, W.; Aleksandrowicz, S.; Wojtkowski, C.; Lewiński, S.; Bojanowski, J.; Musiał, J.; Milewski, T.; Slesiński, P. Multi-temporal phenological indices derived from time series Sentinel-1 images to country-wide crop classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102683. [Google Scholar] [CrossRef]
- Tamiminia, H.; Homayouni, S.; McNairn, H.; Safari, A. A particle swarm optimized kernel-based clustering method for crop mapping from multi-temporal polarimetric L-band SAR observations. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 201–212. [Google Scholar] [CrossRef]
- McNairn, H.; Shang, J. A Review of Multitemporal Synthetic Aperture Radar (SAR) for Crop Monitoring. In Multitemporal Remote Sensing; Ban, Y., Ed.; Remote Sensing and Digital Image Processing; Springer: Cham, Switzerland, 2016; Volume 20. [Google Scholar]
- Ustuner, M.; Balik Sanli, F. Polarimetric target decompositions and light gradient boosting machine for crop classification: A comparative evaluation. ISPRS Int. J. Geo-Inf. 2019, 8, 97. [Google Scholar] [CrossRef]
- Bégué, A.; Arvor, D.; Bellon, B.; Betbeder, J.; De Abelleyra, D.; Ferraz, R.P.D.; Lebourgeois, V.; Lelong, C.; Simões, M.; Verón, R.S. Remote sensing and cropping practices: A review. Remote Sens. 2018, 10, 99. [Google Scholar] [CrossRef]
- Forkuor, G.; Dimobe, K.; Serme, I.; Tondoh, J.E. Landsat-8 vs. Sentinel-2: Examining the added value of sentinel-2’s red-edge bands to land-use and land-cover mapping in Burkina Faso. GISci. Remote Sens. 2018, 55, 331–354. [Google Scholar] [CrossRef]
- Tariq, A.; Yan, J.; Gagnon, A.S.; Riaz Khan, M.; Mumtaz, F. Mapping of cropland, cropping patterns and crop types by combining optical remote sensing images with decision tree classifier and random forest. Geo-Spat. Inf. Sci. 2023, 26, 302–320. [Google Scholar] [CrossRef]
- Liu, X.; Xie, S.; Yang, J.; Sun, L.; Liu, L.; Zhang, Q.; Yang, C. Comparisons between temporal statistical metrics, time series stacks and phenological features derived from NASA Harmonized Landsat Sentinel-2 data for crop type mapping. Comput. Electron. Agric. 2023, 211, 108015. [Google Scholar] [CrossRef]
- Koley, S.; Chockalingam, J. Sentinel 1 and Sentinel 2 for cropland mapping with special emphasis on the usability of textural and vegetation indices. Adv. Space Res. 2022, 69, 1768–1785. [Google Scholar] [CrossRef]
- Cheng, G.; Ding, H.; Yang, J.; Cheng, Y. Crop type classification with combined spectral, texture, and radar features of time-series Sentinel-1 and Sentinel-2 data. Int. J. Remote Sens. 2023, 44, 1215–1237. [Google Scholar] [CrossRef]
- Demarez, V.; Helen, F.; Marais-Sicre, C.; Baup, F. In-season mapping of irrigated crops using Landsat 8 and Sentinel-1 time series. Remote Sens. 2019, 11, 118. [Google Scholar] [CrossRef]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Rostami, A.; Akhoondzadeh, M.; Amani, M. A fuzzy-based flood warning system using 19-year remote sensing time series data in the Google Earth Engine cloud platform. Adv. Space Res. 2022, 70, 1406–1428. [Google Scholar] [CrossRef]
- Taheri Dehkordi, A.; Valadan Zoej, M.J.; Ghasemi, H.; Ghaderpour, E.; Hassan, Q.K. A new clustering method to generate training samples for supervised monitoring of long-term water surface dynamics using Landsat data through Google Earth Engine. Sustainability 2022, 14, 8046. [Google Scholar] [CrossRef]
- Taheri Dehkordi, A.; Valadan Zoej, M.J.; Ghasemi, H.; Jafari, M.; Mehran, A. Monitoring Long-Term Spatiotemporal Changes in Iran Surface Waters Using Landsat Imagery. Remote Sens. 2022, 14, 4491. [Google Scholar] [CrossRef]
- Liu, H.; Gong, P.; Wang, J.; Clinton, N.; Bai, Y.; Liang, S. Annual dynamics of global land cover and its long-term changes from 1982 to 2015. Earth Syst. Sci. Data 2020, 12, 1217–1243. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Y.; Clinton, N.; Wang, J.; Wang, X.; Liu, C.; Gong, P.; Yang, J.; Bai, Y.; Zheng, Y. Mapping major land cover dynamics in Beijing using all Landsat images in Google Earth Engine. Remote Sens. Environ. 2017, 202, 166–176. [Google Scholar] [CrossRef]
- Youssefi, F.; Zoej, M.J.V.; Hanafi-Bojd, A.A.; Dariane, A.B.; Khaki, M.; Safdarinezhad, A.; Ghaderpour, E. Temporal monitoring and predicting of the abundance of Malaria vectors using time series analysis of remote sensing data through Google Earth Engine. Sensors 2022, 22, 1942. [Google Scholar] [CrossRef] [PubMed]
- Dehkordi, A.T.; Beirami, B.A.; Zoej, M.J.V.; Mokhtarzade, M. Performance Evaluation of Temporal and Spatial-Temporal Convolutional Neural Networks for Land-Cover Classification (A Case Study in Shahrekord, Iran). In Proceedings of the 2021 5th International Conference on Pattern Recognition and Image Analysis (IPRIA), Kashan, Iran, 3–4 March 2021; pp. 1–5. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Dehkordi, A.T.; Zoej, M.J.V.; Chegoonian, A.M.; Mehran, A.; Jafari, M. Improved Water Chlorophyll-A Retrieval Method Based On Mixture Density Networks Using In-Situ Hyperspectral Remote Sensing Data. In Proceedings of the IGARSS 2023—2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 3745–3748. [Google Scholar]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Fernando, W.A.M.; Senanayake, I. Developing a two-decadal time-record of rice field maps using Landsat-derived multi-index image collections with a random forest classifier: A Google Earth Engine based approach. Inf. Process. Agric. 2023, in press. [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Han, M.; Zhu, X.; Yao, W. Remote sensing image classification based on neural network ensemble algorithm. Neurocomputing 2012, 78, 133–138. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Mohammadimanesh, F.; Homayouni, S. Bagging and boosting ensemble classifiers for classification of multispectral, hyperspectral and PolSAR data: A comparative evaluation. Remote Sens. 2021, 13, 4405. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Ensemble classifiers in remote sensing: A review. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 1148–1152. [Google Scholar]
- Zhang, Y.; Liu, J.; Shen, W. A review of ensemble learning algorithms used in remote sensing applications. Appl. Sci. 2022, 12, 8654. [Google Scholar] [CrossRef]
- Pham, B.T.; Tien Bui, D.; Prakash, I. Bagging based support vector machines for spatial prediction of landslides. Environ. Earth Sci. 2018, 77, 1–17. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, M. Mapping paddy rice using an adaptive stacking algorithm and Sentinel-1/2 images based on Google Earth Engine. Remote Sens. Lett. 2022, 13, 373–382. [Google Scholar] [CrossRef]
- Zheng, A.; Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Mellor, A.; Boukir, S. Exploring diversity in ensemble classification: Applications in large area land cover mapping. ISPRS J. Photogramm. Remote Sens. 2017, 129, 151–161. [Google Scholar] [CrossRef]
- Rana, V.K.; Suryanarayana, T.M.V. Performance evaluation of MLE, RF and SVM classification algorithms for watershed scale land use/land cover mapping using sentinel 2 bands. Remote Sens. Appl. Soc. Environ. 2020, 19, 100351. [Google Scholar] [CrossRef]
- Palanisamy, P.A.; Jain, K.; Bonafoni, S. Machine Learning Classifier Evaluation for Different Input Combinations: A Case Study with Landsat 9 and Sentinel-2 Data. Remote Sens. 2023, 15, 3241. [Google Scholar] [CrossRef]
- Soltani, M.; Rahmani, O.; Ghasimi, D.S.; Ghaderpour, Y.; Pour, A.B.; Misnan, S.H.; Ngah, I. Impact of household demographic characteristics on energy conservation and carbon dioxide emission: Case from Mahabad city, Iran. Energy 2020, 194, 116916. [Google Scholar] [CrossRef]
- Eimanifar, A.; Mohebbi, F. Urmia Lake (northwest Iran): A brief review. Saline Syst. 2007, 3, 5. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.L.; Goward, S.; Arvidson, T. Landsat. Photogramm. Eng. Remote Sens. 2006, 72, 1171–1178. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; García-Haro, F.J.; Martínez, B.; Izquierdo-Verdiguier, E.; Atzberger, C.; Camps-Valls, G.; Gilabert, M.A. Understanding deep learning in land use classification based on Sentinel-2 time series. Sci. Rep. 2020, 10, 17188. [Google Scholar] [CrossRef]
- Liu, L.; Xiao, X.; Qin, Y.; Wang, J.; Xu, X.; Hu, Y.; Qiao, Z. Mapping cropping intensity in China using time series Landsat and Sentinel-2 images and Google Earth Engine. Remote Sens. Environ. 2020, 239, 111624. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Mullissa, A.; Vollrath, A.; Odongo-Braun, C.; Slagter, B.; Balling, J.; Gou, Y.; Gorelick, N.; Reiche, J. Sentinel-1 sar backscatter analysis ready data preparation in Google Earth Engine. Remote Sens. 2021, 13, 1954. [Google Scholar] [CrossRef]
- Hu, Y.; Zeng, H.; Tian, F.; Zhang, M.; Wu, B.; Gilliams, S.; Li, S.; Li, Y.; Lu, Y.; Yang, H. An interannual transfer learning approach for crop classification in the Hetao Irrigation district, China. Remote Sens. 2022, 14, 1208. [Google Scholar] [CrossRef]
- Topaloğlu, R.H.; Sertel, E.; Musaoğlu, N. Assessment of classification accuracies of Sentinel-2 and Landsat-8 data for land cover/use mapping. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 1055–1059. [Google Scholar] [CrossRef]
- Kobayashi, N.; Tani, H.; Wang, X.; Sonobe, R. Crop classification using spectral indices derived from Sentinel-2A imagery. J. Inf. Syst. Telecommun. 2020, 4, 67–90. [Google Scholar] [CrossRef]
- Zhang, J.; He, Y.; Yuan, L.; Liu, P.; Zhou, X.; Huang, Y. Machine learning-based spectral library for crop classification and status monitoring. Agronomy 2019, 9, 496. [Google Scholar] [CrossRef]
- Asgari, S.; Hasanlou, M. A Comparative Study of Machine Learning Classifiers for Crop Type Mapping Using Vegetation Indices. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 10, 79–85. [Google Scholar] [CrossRef]
- Pettorelli, N. The Normalized Difference Vegetation Index; Oxford University Press: New York, NY, USA, 2013. [Google Scholar]
- Ji, L.; Zhang, L.; Wylie, B. Analysis of dynamic thresholds for the normalized difference water index. Photogramm. Eng. Remote Sens. 2009, 75, 1307–1317. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Jiang, Z.; Huete, A.R.; Didan, K.; Miura, T. Development of a two-band enhanced vegetation index without a blue band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Sun, L.; Chen, J.; Guo, S.; Deng, X.; Han, Y. Integration of time series sentinel-1 and sentinel-2 imagery for crop type mapping over oasis agricultural areas. Remote Sens. 2020, 12, 158. [Google Scholar] [CrossRef]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Proceedings of the Annual Meeting of the Society for Academic Emergency Medicine in San Francisco, CA, USA, 22–25 May 2000. [Google Scholar]
- Li, C.; Cai, R.; Tian, W.; Yuan, J.; Mi, X. Land Cover Classification by Gaofen Satellite Images Based on CART Algorithm in Yuli County, Xinjiang, China. Sustainability 2023, 15, 2535. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Farmonov, N.; Amankulova, K.; Szatmári, J.; Sharifi, A.; Abbasi-Moghadam, D.; Nejad, S.M.M.; Mucsi, L. Crop type classification by DESIS hyperspectral imagery and machine learning algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1576–1588. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3149–3157. [Google Scholar]
- Ghayour, L.; Neshat, A.; Paryani, S.; Shahabi, H.; Shirzadi, A.; Chen, W.; Al-Ansari, N.; Geertsema, M.; Pourmehdi Amiri, M.; Gholamnia, M. Performance evaluation of sentinel-2 and landsat 8 OLI data for land cover/use classification using a comparison between machine learning algorithms. Remote Sens. 2021, 13, 1349. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. WIREs Comp. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]


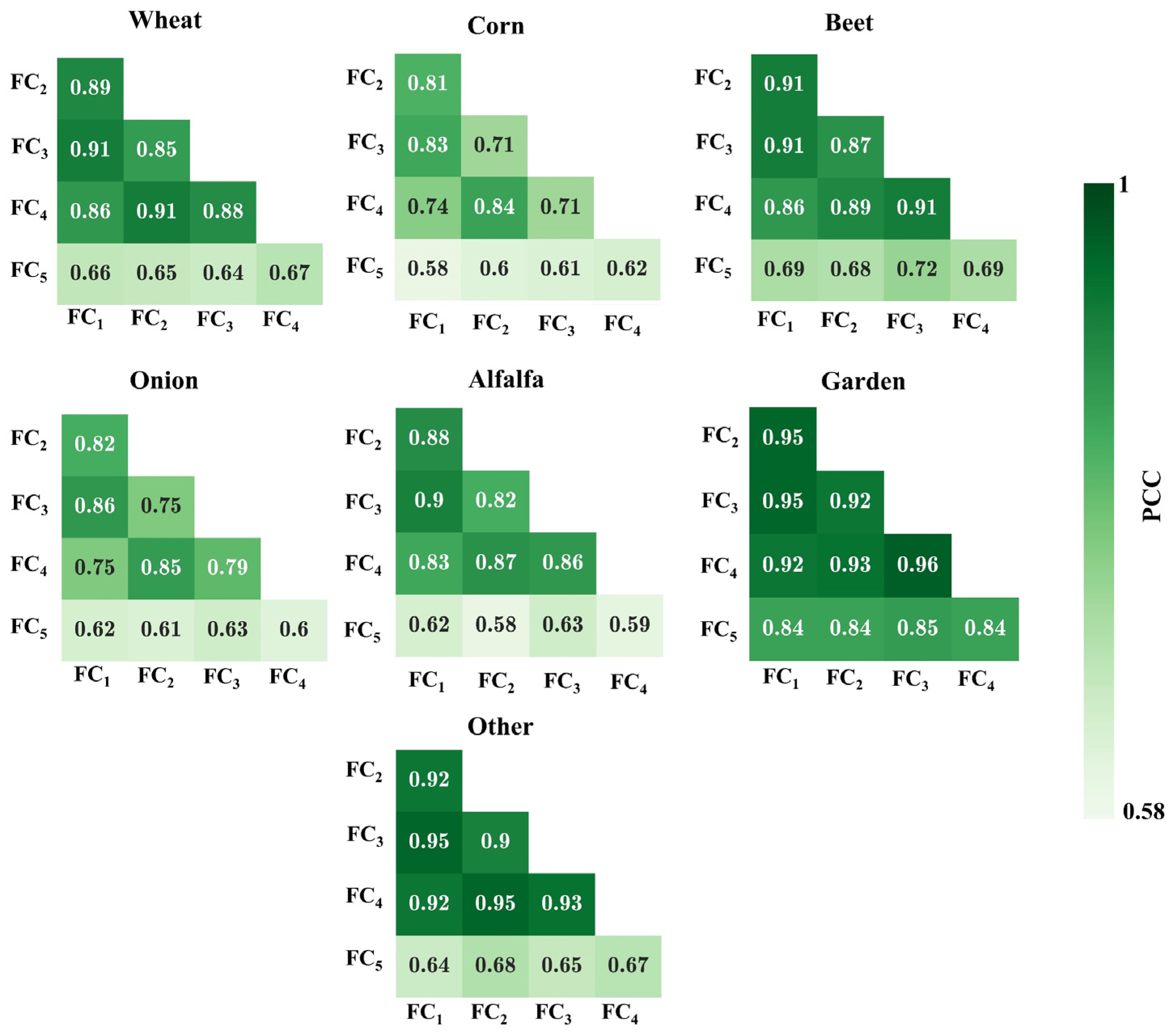


| Collection | Band Name | Wavelength (nm) | Resolution (m) | Description |
|---|---|---|---|---|
| S2 | B2 | 496.6 | 10 | Blue (B) |
| B3 | 560 | 10 | Green (G) | |
| B4 | 664.5 | 10 | Red (R) | |
| B5 | 703.9 | 20 | Red Edge 1 (RE1) | |
| B6 | 740.2 | 20 | Red Edge 2 (RE2) | |
| B7 | 782.5 | 20 | Red Edge 3 (RE3) | |
| B8 | 835.1 | 10 | NIR | |
| B8A | 864.8 | 20 | Red Edge 4 (RE4) | |
| B11 | 1613.7 | 20 | SWIR 1 | |
| B12 | 2202.4 | 20 | SWIR 2 | |
| L8/9 | B2 | 482 | 30 | Blue (B) |
| B3 | 561.5 | 30 | Green (G) | |
| B4 | 654.5 | 30 | Red (R) | |
| B5 | 865 | 30 | NIR | |
| B6 | 1608.5 | 30 | SWIR 1 | |
| B7 | 2200.5 | 30 | SWIR 2 |
| Crop Name | Training Set | Validation Set | Total |
|---|---|---|---|
| Wheat | 589 | 253 | 842 |
| Corn | 336 | 144 | 480 |
| Beet | 413 | 177 | 630 |
| Onion | 210 | 90 | 300 |
| Alfalfa | 676 | 290 | 966 |
| Garden | 911 | 390 | 1301 |
| Other | 415 | 178 | 593 |
| Total | 3550 | 1522 | 5072 |
| FC | Branch Number | Description |
|---|---|---|
| FC1 | 1 | Only S2 spectral bands, B2 to B12 (Table 1) |
| FC2 | 2 | Only S2-derived SIs: NDVI, NDBI, NDWI, SAVI, EVI (Table A1) |
| FC3 | 3 | Only L8/9 spectral bands, B2 to B7 (Table 1) |
| FC4 | 4 | Only L8/9-derived SIs: NDVI, NDBI, NDWI, SAVI, EVI (Table A1) |
| FC5 | 5 | Only VV and VH bands |
| Model | Hyper Parameters | Grid Search Space |
|---|---|---|
| CART | MN | [1–5, step = 1] |
| MLP | [1–10, step = 2] | |
| SVM | G | [1, 5, 10, 100, 1000] × |
| C | [1, 10, 100, 1000, 10,000] × | |
| RF | NT | [10, 50, 100, 200, 300] |
| MN | [1–5, step = 1] | |
| VPS | [1–5, step = 1] | |
| GBT | NT | [10, 50, 100, 200, 300] |
| MN | [1–5, step = 1] | |
| SH | [1, 10, 100, 1000] × | |
| Pa-PCA-Ca | n (number of PCA top components) | [1–5, step = 1] |
| No | Model | Description |
|---|---|---|
| 1 | Pa-Ca | This is a special case of the proposed framework of this paper without employing PCA (Figure 3). The best models as base models in Pa branches and a Meta-model in Ca structure were identified first. Additionally, various combinations of input FCs (FC1–FC5) were tested for this specific architecture. |
| 2 | Pa-PCA-Ca | This is the proposed framework of this paper (using the same base models and Meta-models as in Model No. 1), as PCA is applied prior to Ca structure. FC1–FC5 were utilized in this model. |
| 3 | Statcked Features without PCA | In this model, all of the FCs (FC1–FC5) are stacked together without employing the PCA technique before classification using a single ML model. |
| 4 | Statcked Features with PCA | This model is similar to Model No. 3, employing PCA before feeding the entire FCs (FC1–FC5) to a single ML model for classification. The optimum number of components was found to be six using five-fold cross validation using training data. |
| n | 1 | 1–2 | 1–3 | 1–4 | 1–5 | Pa-Ca |
|---|---|---|---|---|---|---|
| OA (%) | 97.44 | 95.32 | 93.88 | 92.18 | 90.73 | 92.56 |
| Kappa | 0.961 | 0.937 | 0.915 | 0.909 | 0.887 | 0.911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdali, E.; Valadan Zoej, M.J.; Taheri Dehkordi, A.; Ghaderpour, E. A Parallel-Cascaded Ensemble of Machine Learning Models for Crop Type Classification in Google Earth Engine Using Multi-Temporal Sentinel-1/2 and Landsat-8/9 Remote Sensing Data. Remote Sens. 2024, 16, 127. https://doi.org/10.3390/rs16010127
Abdali E, Valadan Zoej MJ, Taheri Dehkordi A, Ghaderpour E. A Parallel-Cascaded Ensemble of Machine Learning Models for Crop Type Classification in Google Earth Engine Using Multi-Temporal Sentinel-1/2 and Landsat-8/9 Remote Sensing Data. Remote Sensing. 2024; 16(1):127. https://doi.org/10.3390/rs16010127
Chicago/Turabian StyleAbdali, Esmaeil, Mohammad Javad Valadan Zoej, Alireza Taheri Dehkordi, and Ebrahim Ghaderpour. 2024. "A Parallel-Cascaded Ensemble of Machine Learning Models for Crop Type Classification in Google Earth Engine Using Multi-Temporal Sentinel-1/2 and Landsat-8/9 Remote Sensing Data" Remote Sensing 16, no. 1: 127. https://doi.org/10.3390/rs16010127
APA StyleAbdali, E., Valadan Zoej, M. J., Taheri Dehkordi, A., & Ghaderpour, E. (2024). A Parallel-Cascaded Ensemble of Machine Learning Models for Crop Type Classification in Google Earth Engine Using Multi-Temporal Sentinel-1/2 and Landsat-8/9 Remote Sensing Data. Remote Sensing, 16(1), 127. https://doi.org/10.3390/rs16010127