
LPGAN: A LBP-Based Proportional Input Generative Adversarial Network for Image Fusion


Abstract
1. Introduction
- The extraction of source image feature information is incomplete. Most image fusion algorithms cannot achieve good structural similarity while retaining richly detailed features at the same time due to the incomplete extraction of feature information [26]. Specifically, when the algorithm performs better on SSIM and PSNR metrics, its performance on SD, AG, and SF metrics will be worse, such as DenseFuse [27]; the reverse is also true, such as in the cases of FusionGAN [28] and DDcGAN [29].
- The mission objectives and network structure do not match. The same network is employed to extract features while ignoring the feature distribution characteristics of different modal images, resulting in the loss of meaningful information. Infrared images and visible images have different imaging characteristics and mechanisms, and using the same feature extraction network cannot fully extract the features of different modal images, such as DenseFuse and U2Fusion [30].
- Improper loss function leads to missing features. In the previous methods, only the gradient is used as a loss to supervise the extraction of detailed features, while neglecting the extraction of lower level texture features in the source images. This makes it difficult for the network to fully utilize the feature information in the source images during the fusion process, such as FusionGAN and DDcGAN.
- (1)
- We introduce LBP into the network for the first time and design a new loss for the generator, which enables the model to make full use of different types of features in a balanced way and reduce image distortion.
- (2)
- We design a pseudo-Siamese network to extract feature information from source images. It fully considers the differences in the imaging mechanism and image features of the different source images, encouraging the generator to preserve more features in source images.
- (3)
- We propose a high-performance image fusion method (LPGAN), achieving the state-of-the-art on the TNO dataset and CVC14 dataset.
2. Related Work
2.1. Deep Learning-Based Image Fusion
- Due to the lack of ground-truth, the existing methods usually supervise the work of the model by adopting no-reference metrics as the loss function. However, only the gradient is used as the loss to supervise the extraction of the detailed features, and the texture information is always ignored.
- They ignore the information distribution of the source images, i.e., the visible image has more detailed information and the infrared image has more contrast information.
- These methods all use only one network to extract features from infrared images and visible images, ignoring the difference in imaging mechanisms between these two kinds of images.
2.2. Generative Adversarial Networks
2.3. Local Binary Patterns
3. Proposed Method
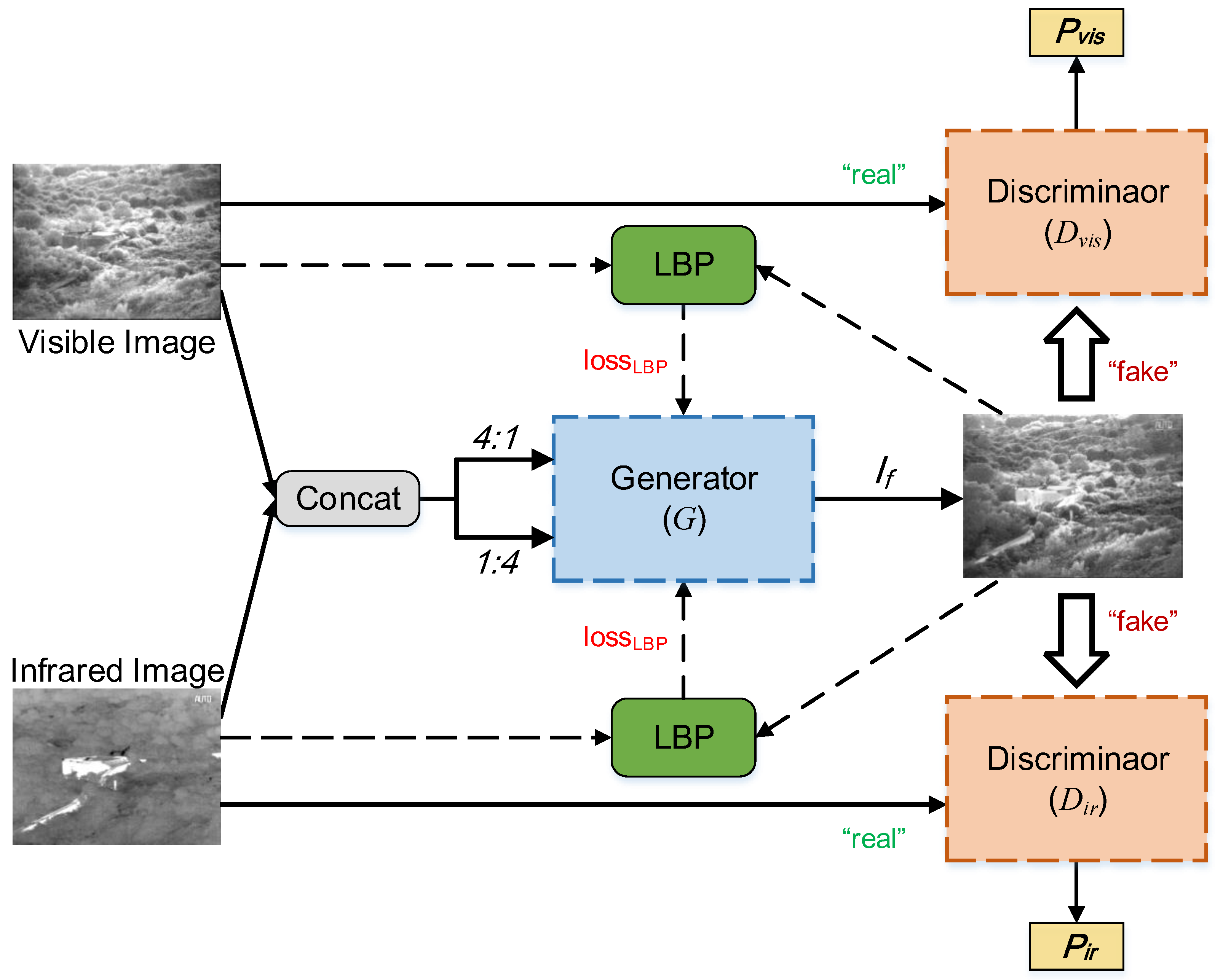
3.1. Overall Framework
3.2. Network Architecture
3.2.1. Generator Architecture
3.2.2. Discriminator Architecture
3.3. Loss Function
3.3.1. Loss Function of Generator
3.3.2. Loss Function of Discriminators
4. Experiments
4.1. Implementation
4.1.1. Dataset
4.1.2. Training Details
4.1.3. Metrics
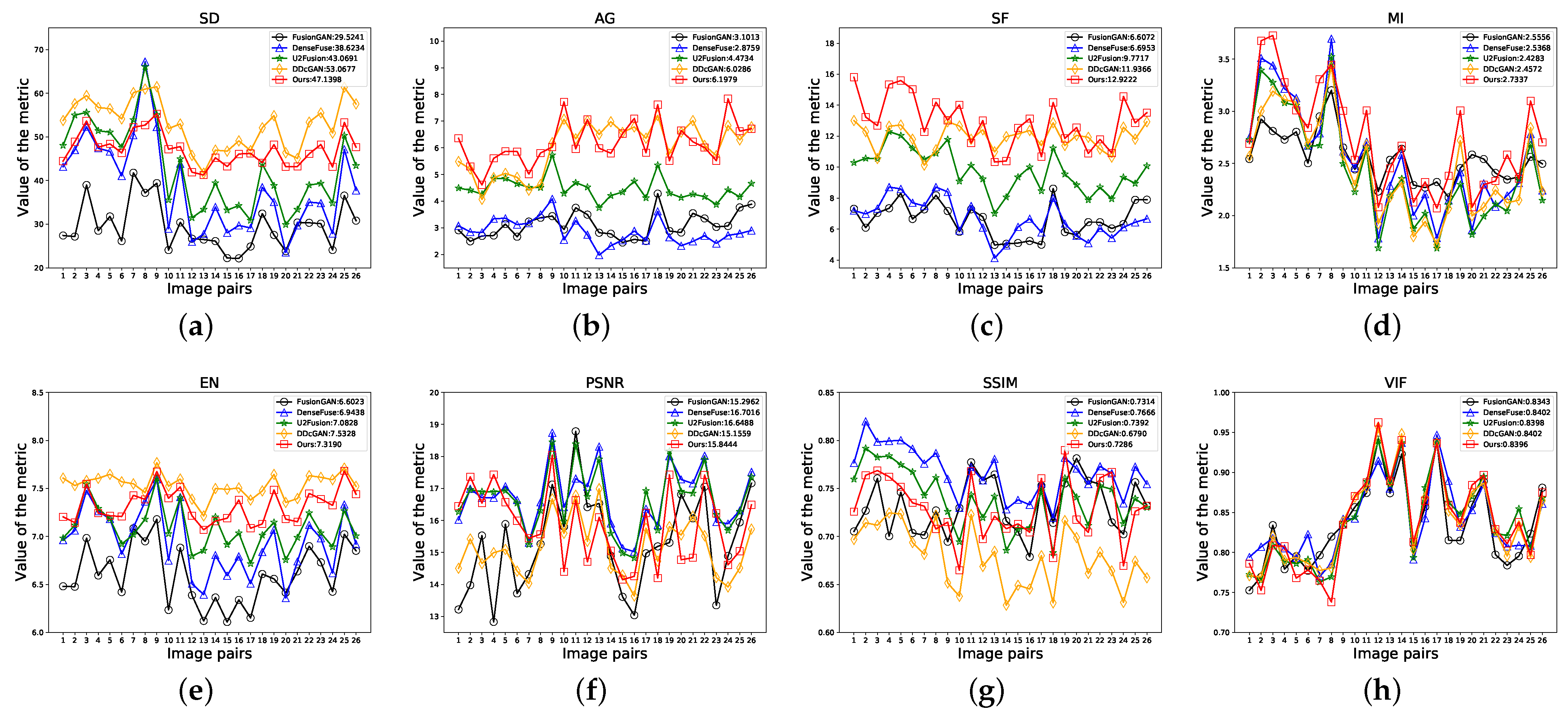
4.2. Results on the TNO Dataset
4.2.1. Qualitative Comparison
4.2.2. Quantitative Comparison
4.3. Results on the CVC14 Dataset
4.3.1. Qualitative Comparison
4.3.2. Quantitative Comparison
4.4. Ablation Study
4.4.1. The Effect of LBP
4.4.2. The Effect of Proportional Input
4.5. Additional Results for RGB Images and Infrared Images
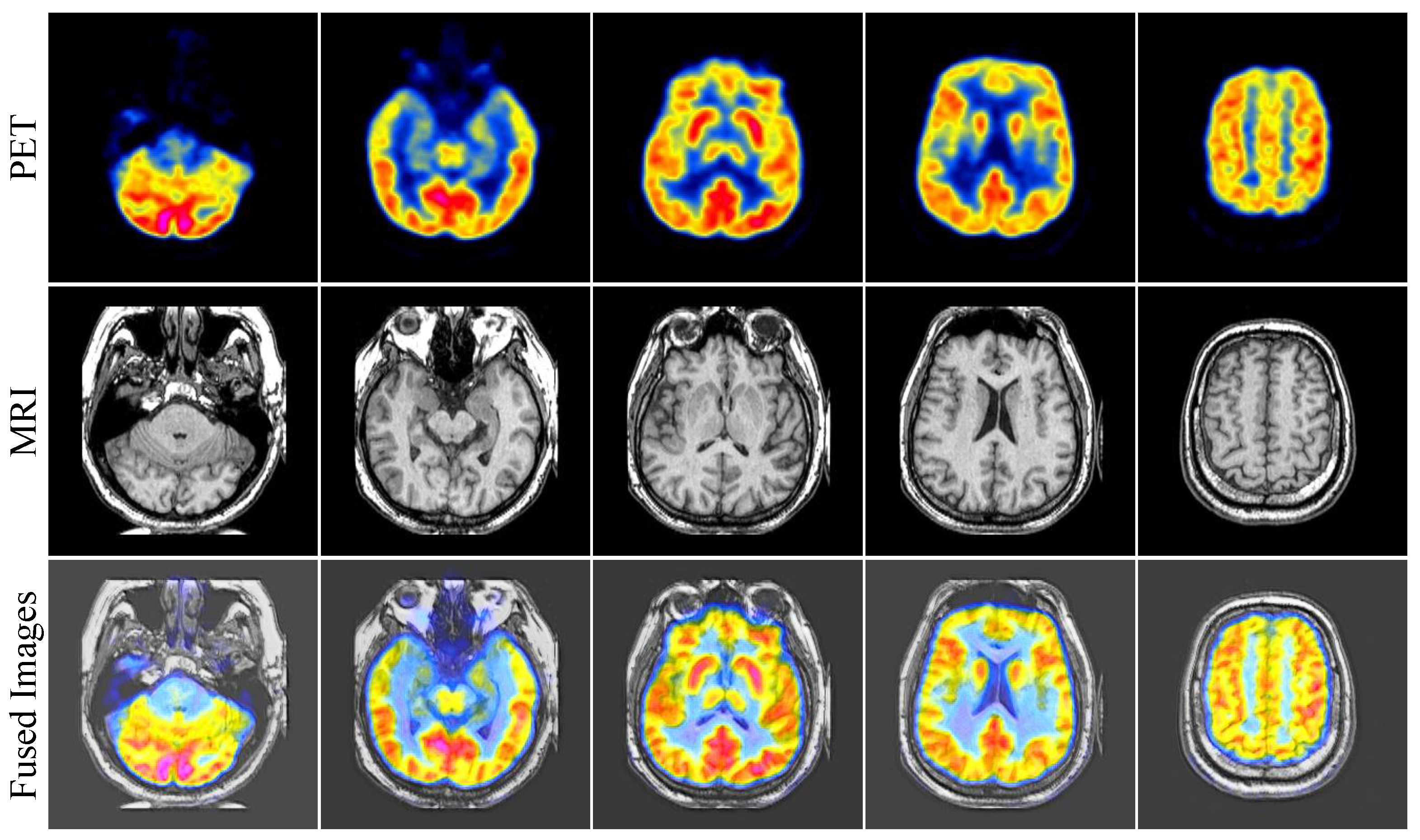
4.6. Additional Results for PET Images and MRI Images
4.7. Multi-Spectral Image Fusion Expansion Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Yang, J.; Zhao, Y.; Chan, J.C.W. Hyperspectral and Multispectral Image Fusion via Deep Two-Branches Convolutional Neural Network. Remote Sens. 2018, 10, 800. [Google Scholar] [CrossRef]
- Sun, K.; Tian, Y. DBFNet: A Dual-Branch Fusion Network for Underwater Image Enhancement. Remote Sens. 2023, 15, 1195. [Google Scholar] [CrossRef]
- Eslami, M.; Mohammadzadeh, A. Developing a Spectral-Based Strategy for Urban Object Detection From Airborne Hyperspectral TIR and Visible Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1808–1816. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Liu, Y.; Hu, J.; Xiao, X.; Liu, B. AI-TFNet: Active Inference Transfer Convolutional Fusion Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 1292. [Google Scholar] [CrossRef]
- Wang, Z.; Ziou, D.; Armenakis, C.; Li, D.; Li, Q. A comparative analysis of image fusion methods. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1391–1402. [Google Scholar] [CrossRef]
- Fu, X.; Jia, S.; Xu, M.; Zhou, J.; Li, Q. Fusion of Hyperspectral and Multispectral Images Accounting for Localized Inter-image Changes. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5517218. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Hu, H.M.; Wu, J.; Li, B.; Guo, Q.; Zheng, J. An adaptive fusion algorithm for visible and infrared videos based on entropy and the cumulative distribution of gray levels. IEEE Trans. Multimed. 2017, 19, 2706–2719. [Google Scholar] [CrossRef]
- He, K.; Zhou, D.; Zhang, X.; Nie, R.; Wang, Q.; Jin, X. Infrared and visible image fusion based on target extraction in the nonsubsampled contourlet transform domain. J. Appl. Remote. Sens. 2017, 11, 015011. [Google Scholar] [CrossRef]
- Bin, Y.; Chao, Y.; Guoyu, H. Efficient image fusion with approximate sparse representation. Int. J. Wavelets Multiresolut. Inf. Process. 2016, 14, 1650024. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.S.; Han, J.; Tao, D. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: A review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Naidu, V. Hybrid DDCT-PCA based multi sensor image fusion. J. Opt. 2014, 43, 48–61. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y.; Huang, S.; Zuo, Y.; Sun, J. Infrared and visible image fusion using visual saliency sparse representation and detail injection model. IEEE Trans. Instrum. Meas. 2020, 70, 1–15. [Google Scholar] [CrossRef]
- Yin, M.; Duan, P.; Liu, W.; Liang, X. A novel infrared and visible image fusion algorithm based on shift-invariant dual-tree complex shearlet transform and sparse representation. Neurocomputing 2017, 226, 182–191. [Google Scholar] [CrossRef]
- Fu, D.; Chen, B.; Wang, J.; Zhu, X.; Hilker, T. An Improved Image Fusion Approach Based on Enhanced Spatial and Temporal the Adaptive Reflectance Fusion Model. Remote Sens. 2013, 5, 6346–6360. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, J.; Chen, C.; Fan, F.; Ma, J. Infrared and visible image fusion using total variation model. Neurocomputing 2016, 202, 12–19. [Google Scholar] [CrossRef]
- Xiang, T.; Yan, L.; Gao, R. A fusion algorithm for infrared and visible images based on adaptive dual-channel unit-linking PCNN in NSCT domain. Infrared Phys. Technol. 2015, 69, 53–61. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-Exposure Image Fusion Techniques: A Comprehensive Review. Remote Sens. 2022, 14, 771. [Google Scholar] [CrossRef]
- Yang, D.; Zheng, Y.; Xu, W.; Sun, P.; Zhu, D. A Generative Adversarial Network for Image Fusion via Preserving Texture Information. In International Conference on Guidance, Navigation and Control; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Harwood, D. Performance evaluation of texture measures with classification based on Kullback discrimination of distributions. In Proceedings of the 12th International Conference on Pattern Recognition, Jerusalem, Israel, 9–13 October 1994; Volume 1, pp. 582–585. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network based on Proportional Maintenance of Gradient and Intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2020, 70, 5005014. [Google Scholar] [CrossRef]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and visible image fusion via detail preserving adversarial learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Liu, Q.; Zhou, H.; Xu, Q.; Liu, X.; Wang, Y. PSGAN: A generative adversarial network for remote sensing image pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10227–10242. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 10 March 2023).
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Durugkar, I.; Gemp, I.; Mahadevan, S. Generative Multi-Adversarial Networks. arXiv 2016, arXiv:1611.01673. [Google Scholar]
- Wang, L.; Sindagi, V.; Patel, V. High-quality facial photo-sketch synthesis using multi-adversarial networks. In Proceedings of the 13th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 83–90. [Google Scholar]
- Aghakhani, H.; Machiry, A.; Nilizadeh, S.; Kruegel, C.; Vigna, G. Detecting deceptive reviews using generative adversarial networks. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24–24 May 2018; pp. 89–95. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed]
- Maturana, D.; Mery, D.; Soto, Á. Face Recognition with Local Binary Patterns, Spatial Pyramid Histograms and Naive Bayes Nearest Neighbor Classification. In Proceedings of the 2009 International Conference of the Chilean Computer Science Society, Santiago, Chile, 10–12 November 2009; pp. 125–132. [Google Scholar]
- Tapia, J.E.; Perez, C.A.; Bowyer, K.W. Gender Classification from Iris Images Using Fusion of Uniform Local Binary Patterns. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; pp. 751–763. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Li, G.; Lin, Y.; Qu, X. An infrared and visible image fusion method based on multi-scale transformation and norm optimization. Inf. Fusion 2021, 71, 109–129. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Zhang, T.; Qu, X.; Cao, D.; Cheng, B.; Li, K. Risk assessment based collision avoidance decision-making for autonomous vehicles in multi-scenarios. Transp. Res. Part Emerg. Technol. 2021, 122, 102820. [Google Scholar] [CrossRef]
- Li, G.; Li, S.E.; Cheng, B.; Green, P. Estimation of driving style in naturalistic highway traffic using maneuver transition probabilities. Transp. Res. Part Emerg. Technol. 2017, 74, 113–125. [Google Scholar] [CrossRef]
- AMPS Programme. September 1998. Available online: http://info.amps.gov:2080 (accessed on 10 March 2023).
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef] [PubMed]
- Tian, X.; Zhang, M.; Yang, C.; Ma, J. Fusionndvi: A computational fusion approach for high-resolution normalized difference vegetation index. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5258–5271. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | SD | AG | SF | MI | EN | PSNR | SSIM | VIF |
|---|---|---|---|---|---|---|---|---|
| 1:2 w/o LBP | 34.6916 | 7.2434 | 13.0421 | 1.6990 | 7.0477 | 14.4241 | 0.6287 | 0.8831 |
| 1:2 w/ LBP | 47.8106 | 7.7136 | 14.1130 | 2.1066 | 7.3885 | 14.0895 | 0.6167 | 0.8744 |
| 1:3 w/o LBP | 36.5414 | 7.7551 | 13.9280 | 1.7276 | 7.0850 | 13.8040 | 0.5578 | 0.8758 |
| 1:3 w/ LBP | 37.1527 | 8.4237 | 15.2863 | 1.7129 | 7.1475 | 14.4447 | 0.6134 | 0.8834 |
| 1:4 w/o LBP | 44.6710 | 7.5059 | 13.7169 | 1.9475 | 7.3457 | 14.4303 | 0.6035 | 0.8785 |
| 1:4 w/ LBP | 48.6349 | 7.7745 | 14.3483 | 2.2591 | 7.4292 | 14.1420 | 0.6213 | 0.8777 |
| Algorithms | SD | AG | SF | EN | MI | PSNR | SSIM | CC |
|---|---|---|---|---|---|---|---|---|
| FusionGAN | 30.2032 | 5.3697 | 11.0368 | 6.4712 | 2.2562 | 15.3458 | 0.6251 | 0.6553 |
| DenseFuse | 40.3449 | 8.2281 | 16.5689 | 6.8515 | 2.5893 | 16.3808 | 0.6899 | 0.7651 |
| U2Fusion | 43.3423 | 10.7603 | 21.3030 | 6.9693 | 2.3393 | 16.5555 | 0.6664 | 0.7496 |
| DDcGAN | 52.1831 | 10.8181 | 21.0603 | 7.4602 | 2.1890 | 14.2005 | 0.5887 | 0.6688 |
| Ours | 43.3589 | 11.4636 | 22.6095 | 7.1701 | 2.4498 | 15.8229 | 0.6741 | 0.7499 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Zheng, Y.; Xu, W.; Sun, P.; Zhu, D. LPGAN: A LBP-Based Proportional Input Generative Adversarial Network for Image Fusion. Remote Sens. 2023, 15, 2440. https://doi.org/10.3390/rs15092440
Yang D, Zheng Y, Xu W, Sun P, Zhu D. LPGAN: A LBP-Based Proportional Input Generative Adversarial Network for Image Fusion. Remote Sensing. 2023; 15(9):2440. https://doi.org/10.3390/rs15092440
Chicago/Turabian StyleYang, Dongxu, Yongbin Zheng, Wanying Xu, Peng Sun, and Di Zhu. 2023. "LPGAN: A LBP-Based Proportional Input Generative Adversarial Network for Image Fusion" Remote Sensing 15, no. 9: 2440. https://doi.org/10.3390/rs15092440
APA StyleYang, D., Zheng, Y., Xu, W., Sun, P., & Zhu, D. (2023). LPGAN: A LBP-Based Proportional Input Generative Adversarial Network for Image Fusion. Remote Sensing, 15(9), 2440. https://doi.org/10.3390/rs15092440