Our task is to develop a Dynamic HRNet (DyHRNet) for the fine segmentation of RS objects. The task will be formulated as a NAS problem with channel-wise attention. Formally, a compact learning model with sparse regularization is developed to achieve this goal. The details are described in the following subsections.
3.1. Problem Formulation
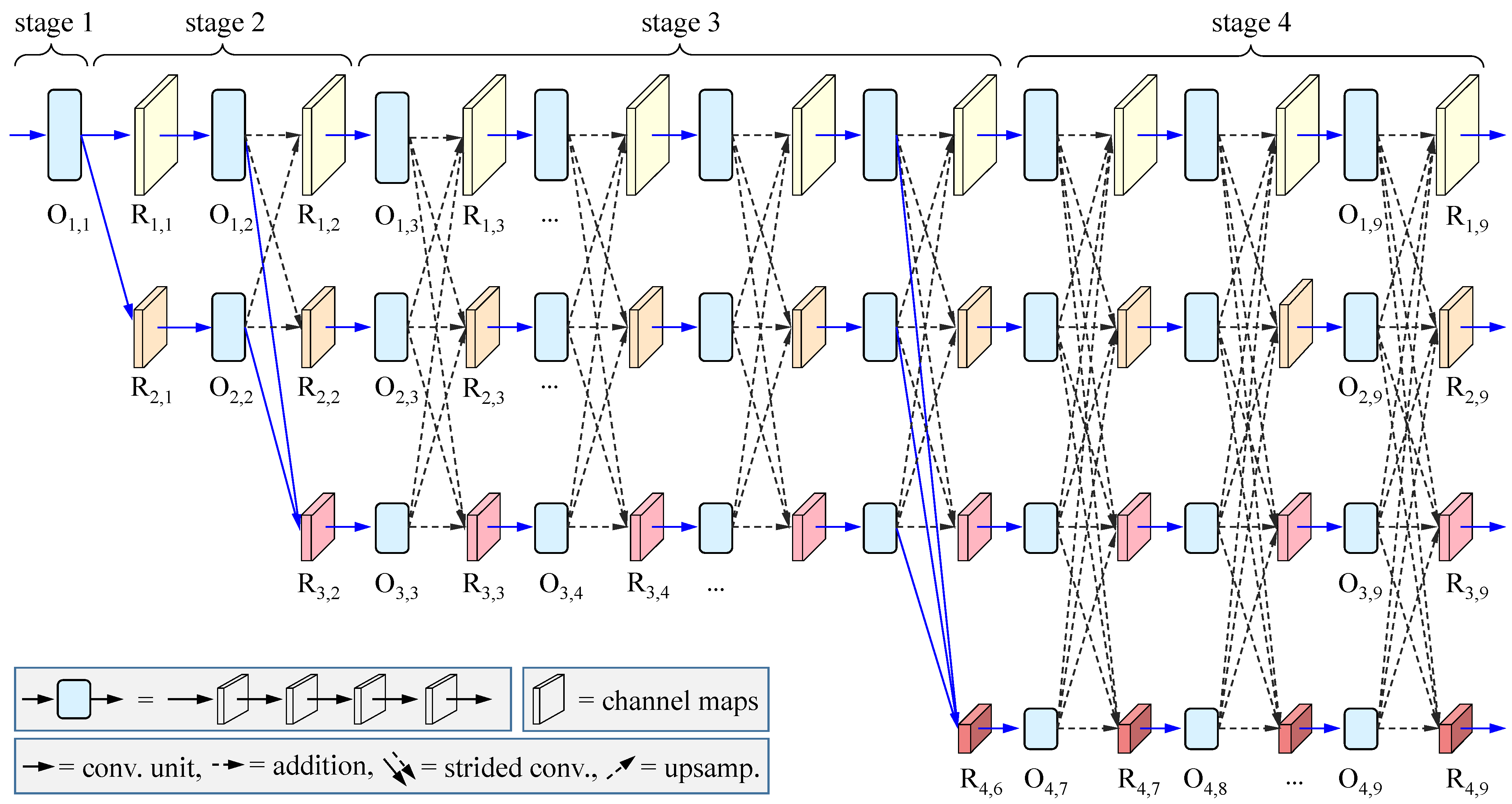
Figure 1 demonstrates the super-architecture constructed according to the rule used in the original HRNet [
21,
22]. Totally it consists of four parallel streams with different resolution representations, where each row corresponds to a stream of representations with the same resolution. It offers a new mechanism for cross-resolution interaction via dense connections between the streams at different stages. With feature mapping among different resolutions, the HRNet is enabled to capture rich multi-scale information. Therefore, such an architecture could attend well to our needs for RS images.
For clarity, the architecture can be further divided into four stages. The first stage is at the highest resolution. It contains four convolutional layers, which are recorded together by block
for simplicity. The next three stages cover different streams with high, medium, and low resolutions. More specifically, the second stage contains one group of dense connections, shown as the dash lines between the representations
,
,
, and
in
Figure 1. In addition, there are four and three groups of dense connections, respectively, in the third and fourth stages (Architecturally, one can set any number of groups of dense connections if needed in practice. Without loss of generality, here we take them as those suggested by the original HRNet). Clearly, with these dense connections, multi-scale features are fused. Thus, such an architecture is suitable for segmenting RS images, where objects with different scales locate here and there in the image.
We denote the representation (namely the output of the four convolutional layers) at the
i-th row and
j-th column in
Figure 1 by
, and the result of the feature fusion at the same position by
. In the original HRNet,
is computed as follows:
where ReLU stands for the rectified linear unit,
are the transformation functions and
P is the number of streams with different resolutions, which changes within different stages. More specifically, as shown in
Figure 1, in the second stage,
,
and
; in the third stage,
,
, and
; and in the fourth stage,
,
, and
. In addition, for the function
, in the case of
, it is an identity mapping; in the case of
, it is a
convolution with stride 2; and in the case of
, it is a bilinear up-sampling operation with
convolution for feature alignment.
As can be seen from Equation (
1), the representations in
are all equally treated without considering their importance. In other words, there is a lack of a mechanism to evaluate the contributions of the dense connections. Therefore, we cast this task in the NAS framework, which allows us to select those useful connections. Then, Equation (
1) is reformulated as follows:
where
are the selection parameters to be optimized. Technically, in the case of
, the candidate link between
and
will be selected; and in the case of
, the candidate link is useless, and will be discarded. This formulation attends to the task of link search in the NAS work setting. However, it is an NP-hard problem.
To solve this problem, we relax the search space to be a continuous one by allowing each
as a non-negative scaling factor. Then, it turns out that
where
are the continuous weighting parameters to be learned, the inequality constraint is introduced to force the sparsity of connections, and
controls the amount of shrinkage for the sparse estimation. That is, a small
will force sparser. Algorithmically, the formulation in Equation (
3) is a convex relaxing to that in Equation (
2).
Please note that the formulation in Equation (
3) exhibits another flexible mechanism in that the channel-wise importance can be evaluated jointly. By considering the contributions of channels in each
, it can be rewritten as follows:
where
is a weighting vector with a length equal to the number of the channels in
, and ⊗ stands for the channel-wise product. Technically, channel-wise attention will be designed to fulfill this task (see
Section 3.3).
In Equation (
4), the weights in
are learned via the NAS trick, and those in
are evaluated via the channel attention. All these weights are positive, which will be modulated by data-driven learning. They may be very small or even zero. In particular, after model training, the cross-resolution connections with zero
and the channels with zero
will be deleted for prediction.
Now, we can explain the term “dynamic” in our work. In the literature, dynamic models could be developed at different levels of model adaptability in a way of data-driven learning, e.g., at the levels of input data [
58], lightweight structures [
25], adaptive weights of operations [
26], and so on. By contrast, in our work setting, here we first explain its meaning given neural architecture design. The operation in Equation (
1) indicates that the neural architecture will remain unchanged before and after training in the original HRNet. With the implementation guided by Equation (
4), the connections could be maintained or cut dynamically during and after training. After the model is well trained under the NAS framework, the connections with
will be deleted from the original structure, yielding a new architecture for segmenting RS images. Then, we explain its meaning given channel-wise importance. The operator “⊗” in Equation (
4) will be performed channel by channel with different weights. In this way, the dynamic merit will be demonstrated in the use of channel-wise importance, which will be learned to modulate its contribution. As a whole, the NAS trick and the channel-wise attention will be combined via Equation (
4) to develop a dynamic HRNet.
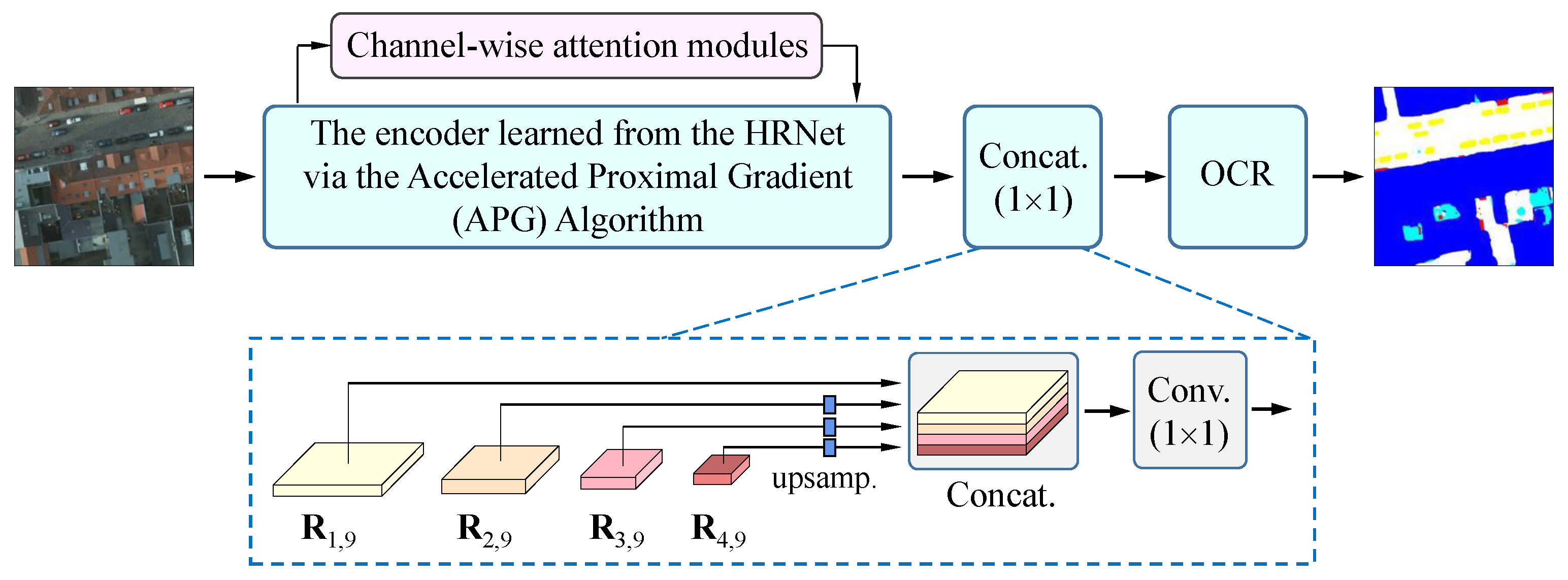
The structure in
Figure 1 will be employed as a candidate backbone for architecture optimization. Thus, it is necessary to contain a head module to output semantic segmentation results. Accordingly, our DyHRNet has four groups of parameters to be optimized. The first group collects the parameters in all of the convolution kernels in
Figure 1, which are recorded together by variable
. The second group consists of those in the channel-wise attention module used to estimate
, which are collected into variable
. The third group includes those in the head part (namely the decoder module), which are collected into variable
. The fourth group collects all
in Equation (
3), which are collected orderly into vector
. Then, we have the following optimization problem for segmenting RS objects:
where
is the loss calculated on the training samples,
shrinks together all the controlling factors
in Equation (
4), and set
collects the triples
according to the dash-line links in
Figure 1.
According to the relationship between the shrinkage constraints and the regularization representation for
used in LASSO [
59], Problem (
5) can be reformulated as follows:
where
denotes the
norm of
.
In Problem (
6), there are two subtasks that should be solved iteratively. One is to optimize
,
and
, given
; and another is to optimize
, given
,
and
. The former can be learned by the algorithm of back propagation of gradients. The latter is difficult to deal with because of the term of
. In the following subsections, we will describe how to solve
and how to design the channel-wise attention module to calculate
in Equation (
4).
3.2. Solving the Sparse Regularization Subproblem with Accelerated Proximal Gradient Algorithm
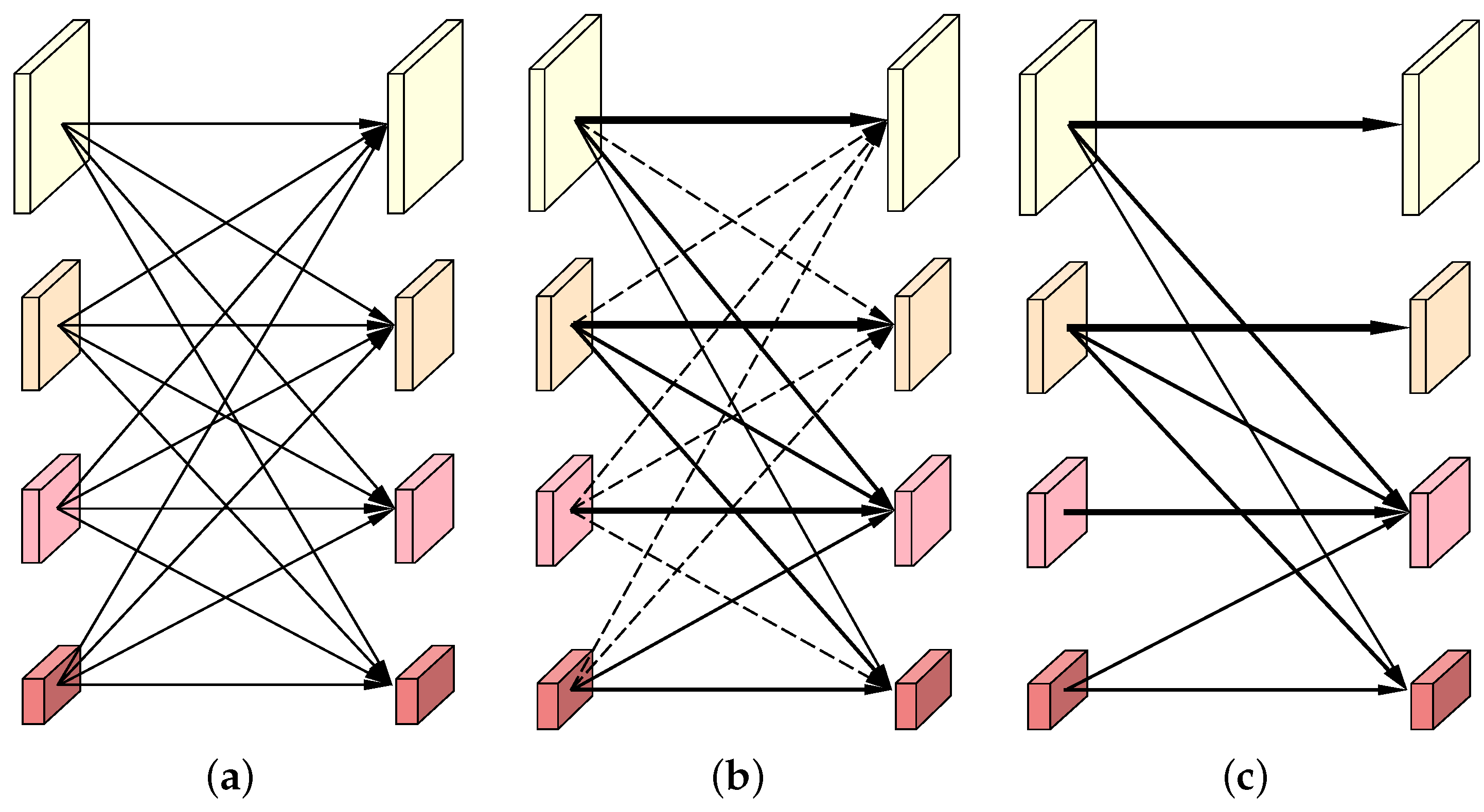
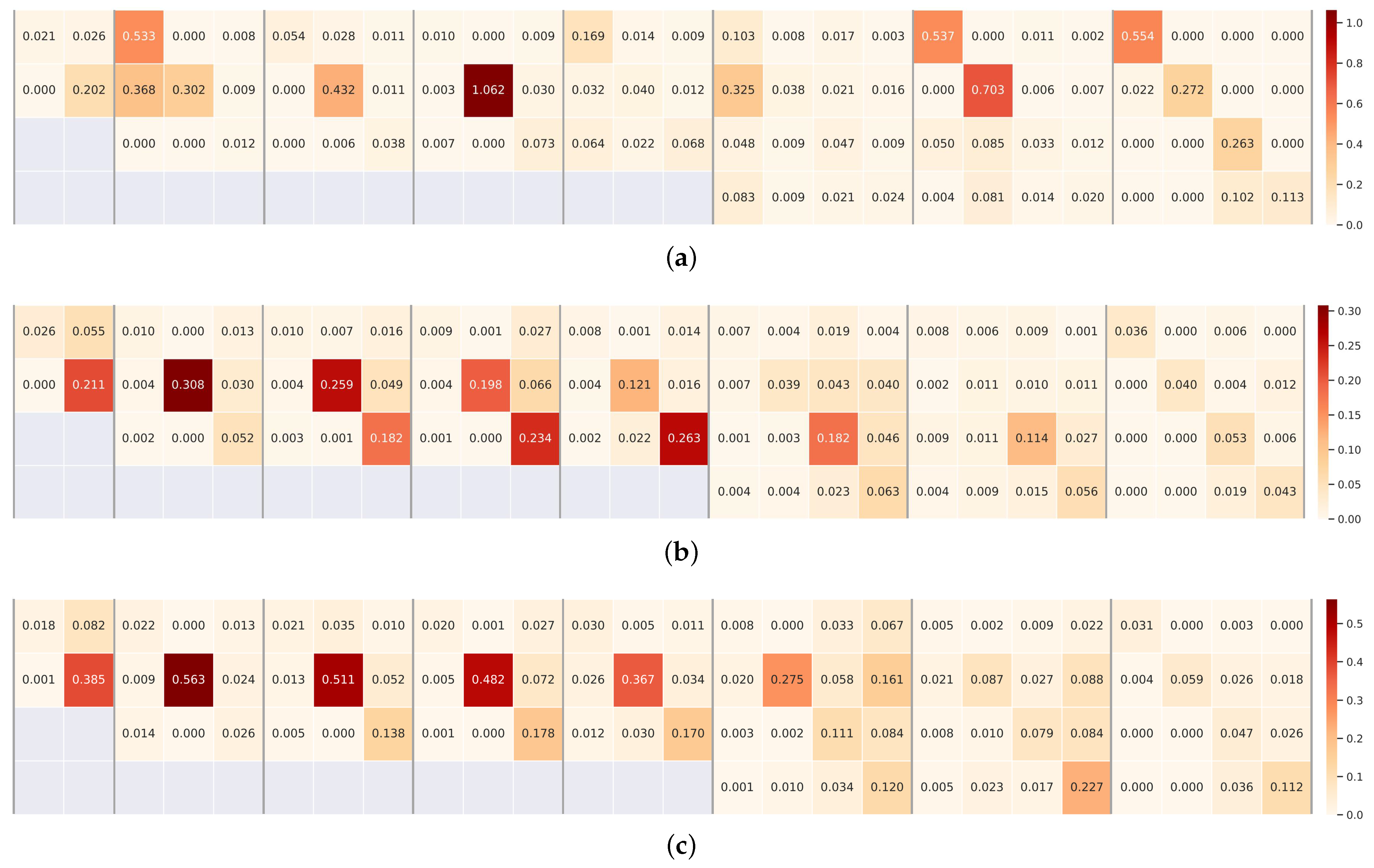
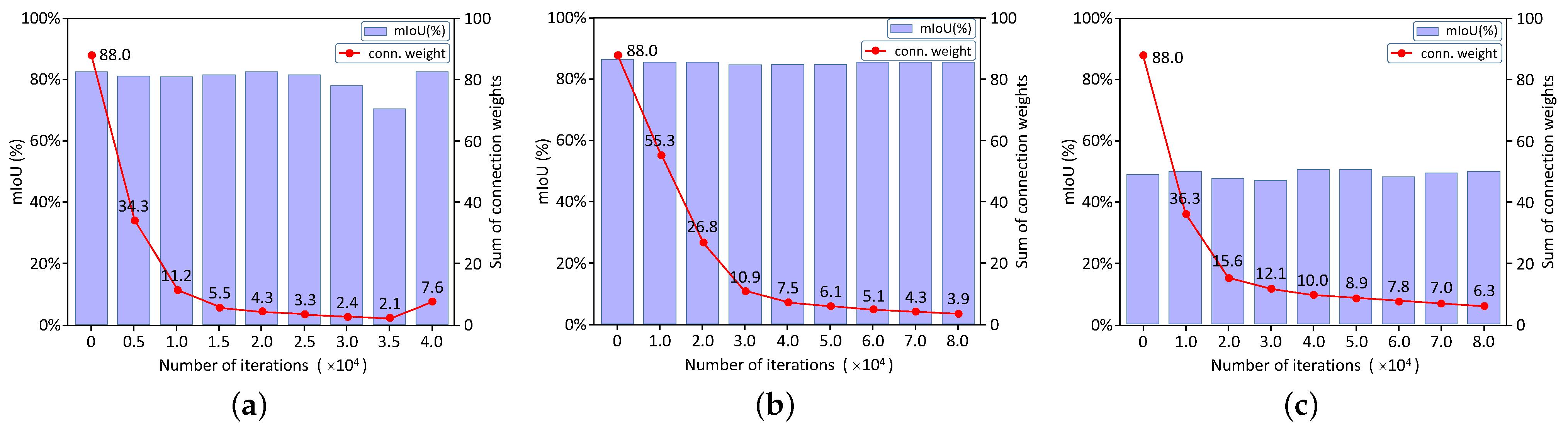
In this subsection, we use one of the dense connection units at stage 4 of HRNet to illustrate the whole sparse optimization process in the order from
Figure 2a–c. To be more specific,
Figure 2a depicts the dense cross-resolution connections of the original HRNet, which are also the candidates to be selected by the APG algorithm. At the beginning of the training stage, the weights of these connections are all set to 1.0 to guarantee that all of them have an equal probability to be selected.
Figure 2b visualizes a group of learned weights using a solid line and a dashed line. The thicker the solid line is, the greater the weight is and the more important the connection is. In particular, the dashed lines indicate those connections are of zero importance, which could be directly cut off.
Figure 2c shows the finally selected connections, which will be used at the inference stage of DyHRNet.
Unfortunately, solving the variable
in Problem (
6) is a challenging task due to the sparse regularization term. One natural selection is to employ the traditional LASSO algorithm [
59] to solve it. However, it is uneasy to unfold the mapping function
for deduction since it is a hierarchically composite function along the architecture of the DyHRNet. In addition, this could be more difficult since the loss function is defined on all the training samples, and the learning is data-driven in the stochastic work setting.
Alternatively, we employ the Accelerated Proximal Gradient (APG) algorithm [
14,
60] to optimize
. This algorithm has a theoretically sound foundation defined by the proximal algorithms. For convenience, a new function
is introduced to denote the objective function in Problem (
6):
where
Please note that, based on Equation (
4),
is a differentiable function with respect to
. Now, we make a quadratic approximation to
around current
. Then, it follows that
where
is the gradient vector of function
at
, and
v is a positive factor. Thus, based on Equation (
9), the task of minimizing
is now updated as
Equivalently, the optimum to Problem (
10) can be obtained via the following problem:
where
, which is known at current iteration. In addition, here “
” is known as the proximal operator [
60] and gives the optimum to Problem (
10).
By further introducing the soft-thresholding operator [
60], it turns out that
where
stands for the
m-th entity of the vector and
is the
m-th entity of
.
Now the original function
in Equation (
7) can be minimized iteratively. With a momentum term to obtain a smooth solution path, we have
in which
where the superscript
indicates the
t-th iteration,
is a learning ratio and
is a contribution factor for historical solution. According to the suggestion given in [
60],
can be taken as
. As the number of iterations increases, it tends to be 1. Thus,
is fixed as 0.9 during iteration in our work.
In the first two iterations, both
and
are set to be a vector with all entities equal to 1. This means that all the connections in
Figure 1 will be initially considered. When
is iteratively solved, all the connections will be assigned different weights to indicate their contributions to the final task.
3.3. Channel-Wise Attention for Feature Aggregation
As mentioned in
Section 3.1, we introduce a channel-wise weighting operation in Equation (
4) to develop the mechanism of the dynamic channel and enhance the flexibility of feature aggregation. Intrinsically, this can be addressed as an attention mechanism, which has been widely used in deep neural networks [
61,
62]. A similar idea has also been applied to the dynamic lightweight HRNet for pose estimation [
25]. In this way, channel-wise attention can give larger weights to those important channels and lower weights to those unnecessary ones.
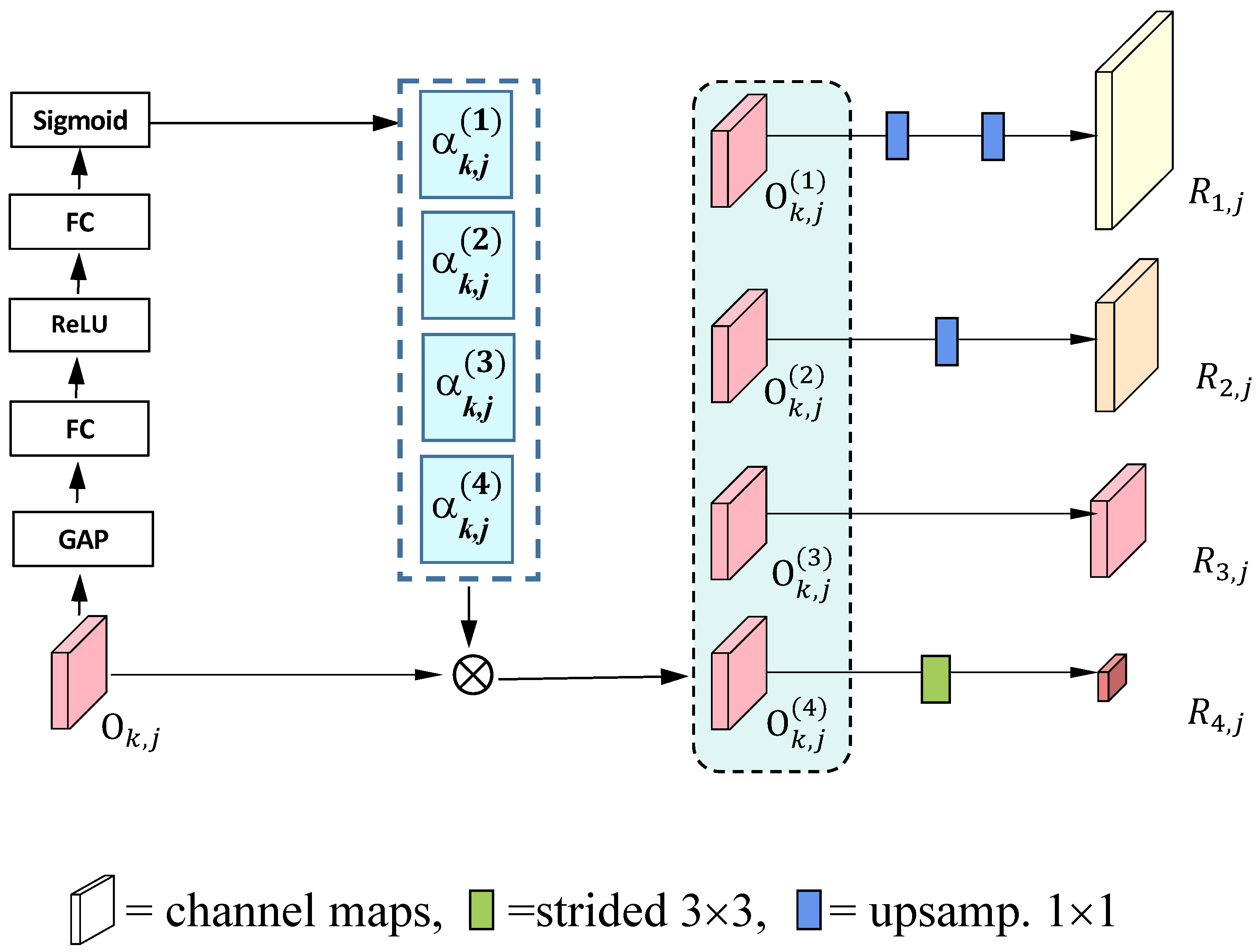
The main task here is to construct the modules to estimate the weighting vectors
in Equation (
4). Motivated by the kernel aggregation used in [
25], our module will be constructed on the representations
for dense links.
Without loss of generality, we take one group of dense connections in the fourth stage in
Figure 1 as an example to explain how to design the attention module.
Figure 3 illustrates the detailed layers. Given the representation
, the channel features will be extracted by the Global Averaged Pooling (GAP). In this way,
will be transformed from a tensor to be a vector with a length equal to the number of the channels in
. Then, it is pushed into the first Fully Connected (FC) layer, followed by the ReLU operation and the second FC layer. The final weighting vector with a length equal to the number of the channels in
will be output by the Sigmoid layer. Formally, we have
where
stands for the final layer with Sigmoid as its activation function.
Finally, it is worth pointing out that the above module “GAP-FC-ReLU-FC-Sigmoid” will be re-used a few times. As illustrated in
Figure 3, it will be copied four times to calculate four weighting vectors
with
, all taking
as their input. In this way, the channel importance of the feature maps is considered with adequate nonlinearity for semantic segmentation.
3.5. Training and Inference
The original RS images and their ground-truth segmentations are taken to train the model in the learning stage. For each image
and its ground-truth
, we denote the predicted segmentation by
. The loss function in Problem (
6) is defined as follows:
where
collects all of the parameters in
,
and
, “trainset” indicates the training subset,
C is the number of categories,
is the truth function,
is the
i-th pixel in image
,
is the ground-truth label of
and
is the output probability at the
k-th channel for pixel
,
w and
h are the width and height of the training images, and
n is the total number of the images in the training set.
In Problem (
6), there are two sub-problems to be solved. Technically, we solve them iteratively by fixing
or
once a time for another. Algorithm 1 lists the steps of how to train the DyHRNet. The learning rate
takes for gradient update when using the stochastic gradient descent (SGD) strategy to train the model. Except for the OCR module, there are in total more than 170 convolution operations in the DyHRNet. Batch normalization is performed after each convolution operation to guarantee convergence.
| Algorithm 1 Training algorithm for the proposed DyHRNet. |
| Input: RS images with ground-truth segmentations, regularization parameters , learning rate , and maximum number of iterations T. |
| Output: Parameter and parameter |
 |
When performing the convergence check in Step 8 in Algorithm 1, the convergence condition is that the loss of the network maintains unchanged at two adjacent iterations. After the model is trained, it can be used for RS images with sizes larger than the training images. In this case, the image will be divided into several overlapped patches for segmentation, where the class probabilities of the pixels in the overlapped regions will be averaged to make the final inference.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}