
MF-DCMANet: A Multi-Feature Dual-Stage Cross Manifold Attention Network for PolSAR Target Recognition


Abstract
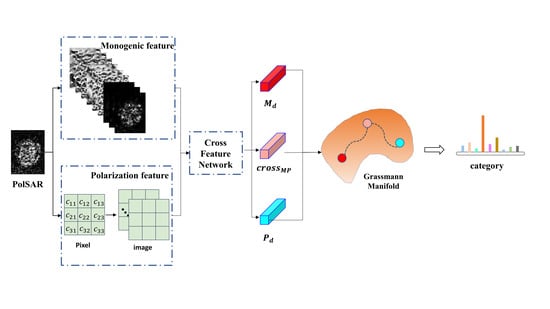
1. Introduction
- A multi-feature extraction method specifically for PolSAR images has been proposed. The multi-feature extracted by this method can describe the target stably and robustly and is not affected by the target pose, geometry, and radar parameters as much as possible;
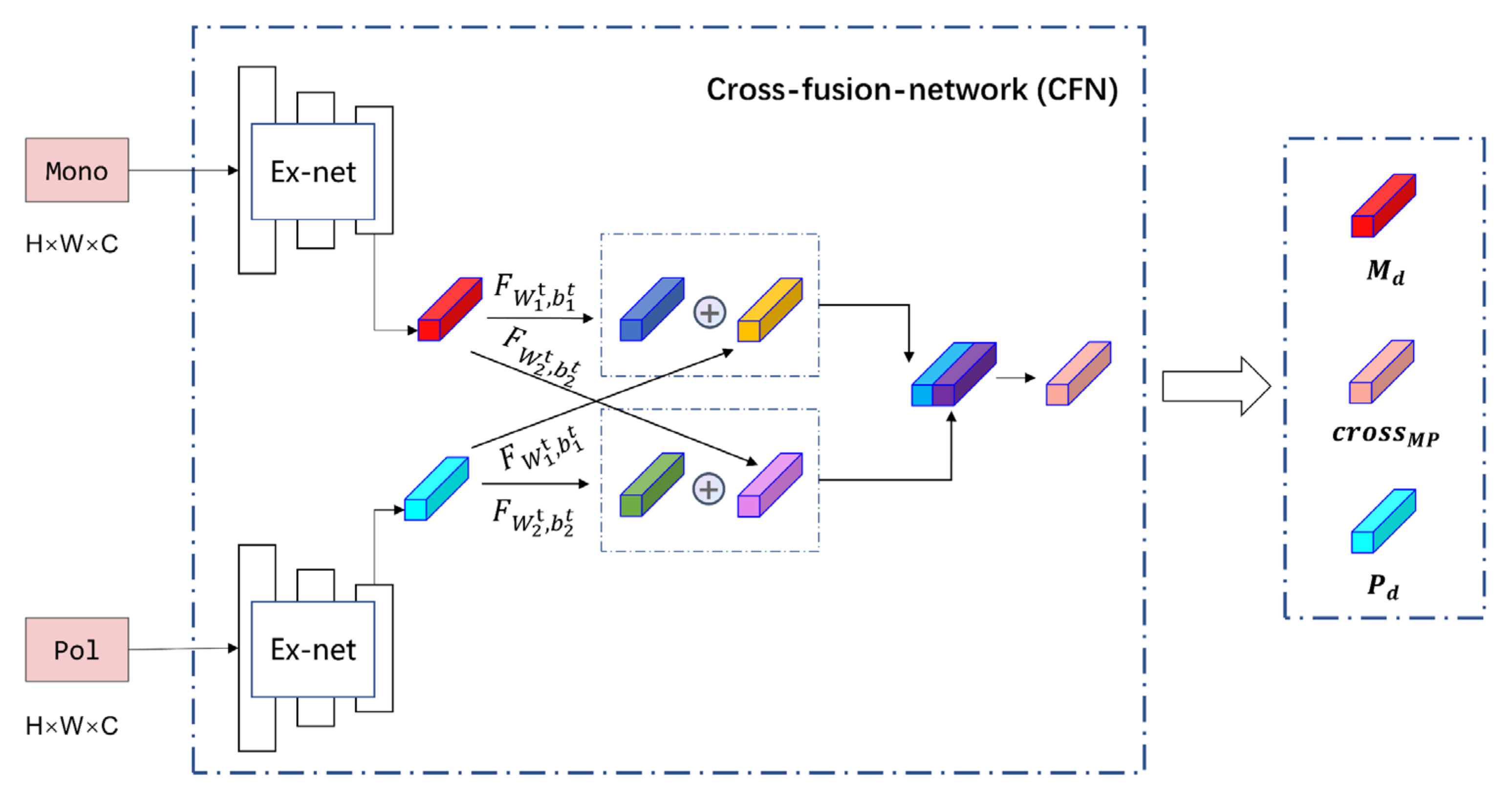
- A dual-stage feature cross-fusion representation framework is proposed, respectively named Cross-Feature Network (CFN) and Cross-Manifold Attention (CMA);
- In MF-DCMANet, handcrafted monogenic features and polarization features are combined with deep features to improve target recognition accuracy;
- By leveraging fusion techniques, the proposed MF-DCMANet enhances recognition performance and achieves the highest accuracy on the fully polarimetric GOTCHA dataset;
- It is often challenging to obtain sufficient and comprehensive samples in practical PolSAR target recognition applications. Despite this limitation, the proposed method still achieves satisfactory performance in few-shot and open-set recognition scenarios.
2. Related Works
2.1. CNN-Based Multi-Feature Target Recognition
2.2. Transformer in Target Recognition
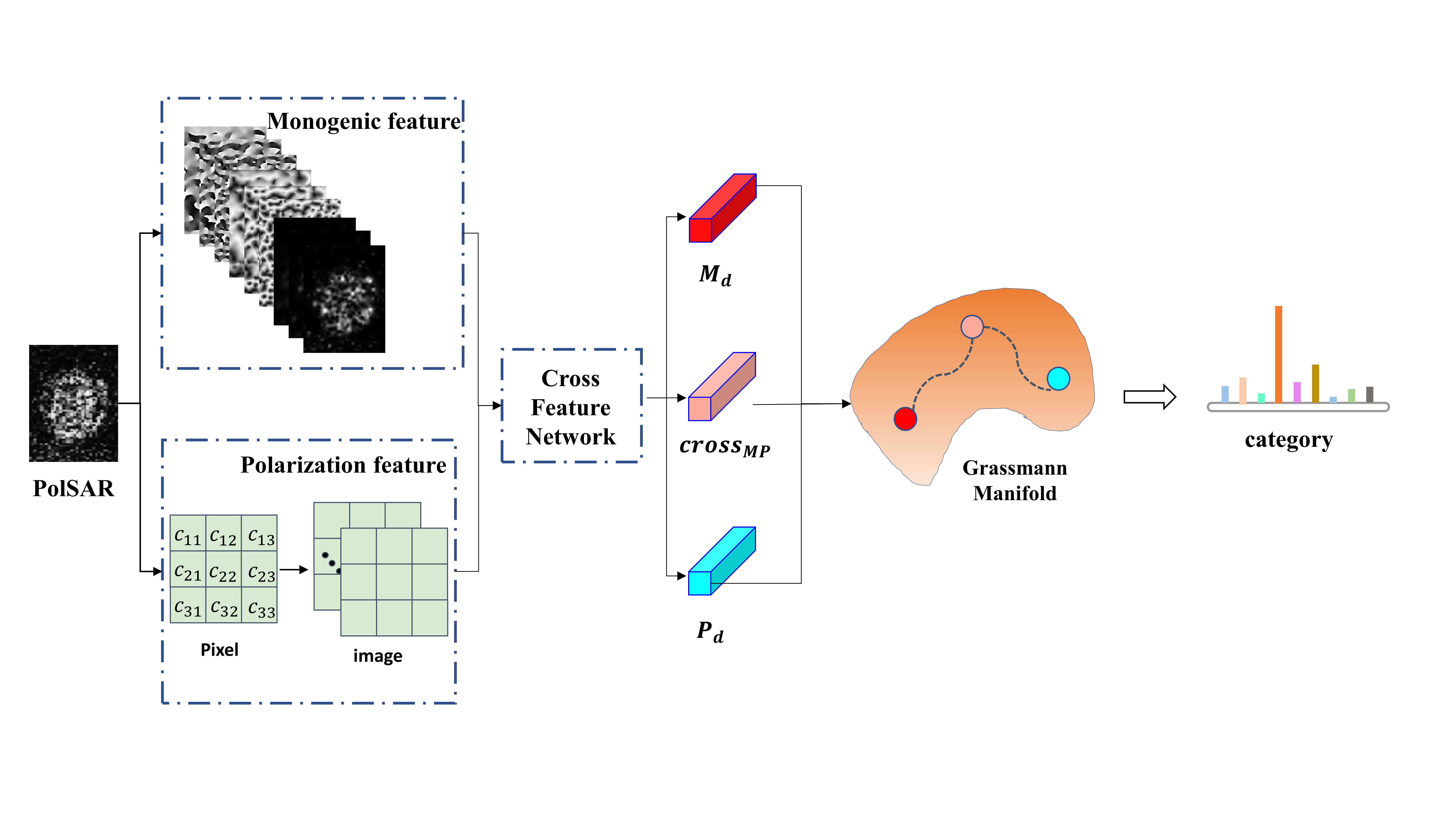
3. Methods
3.1. Problem Formulation
3.2. Multi-Feature Extraction
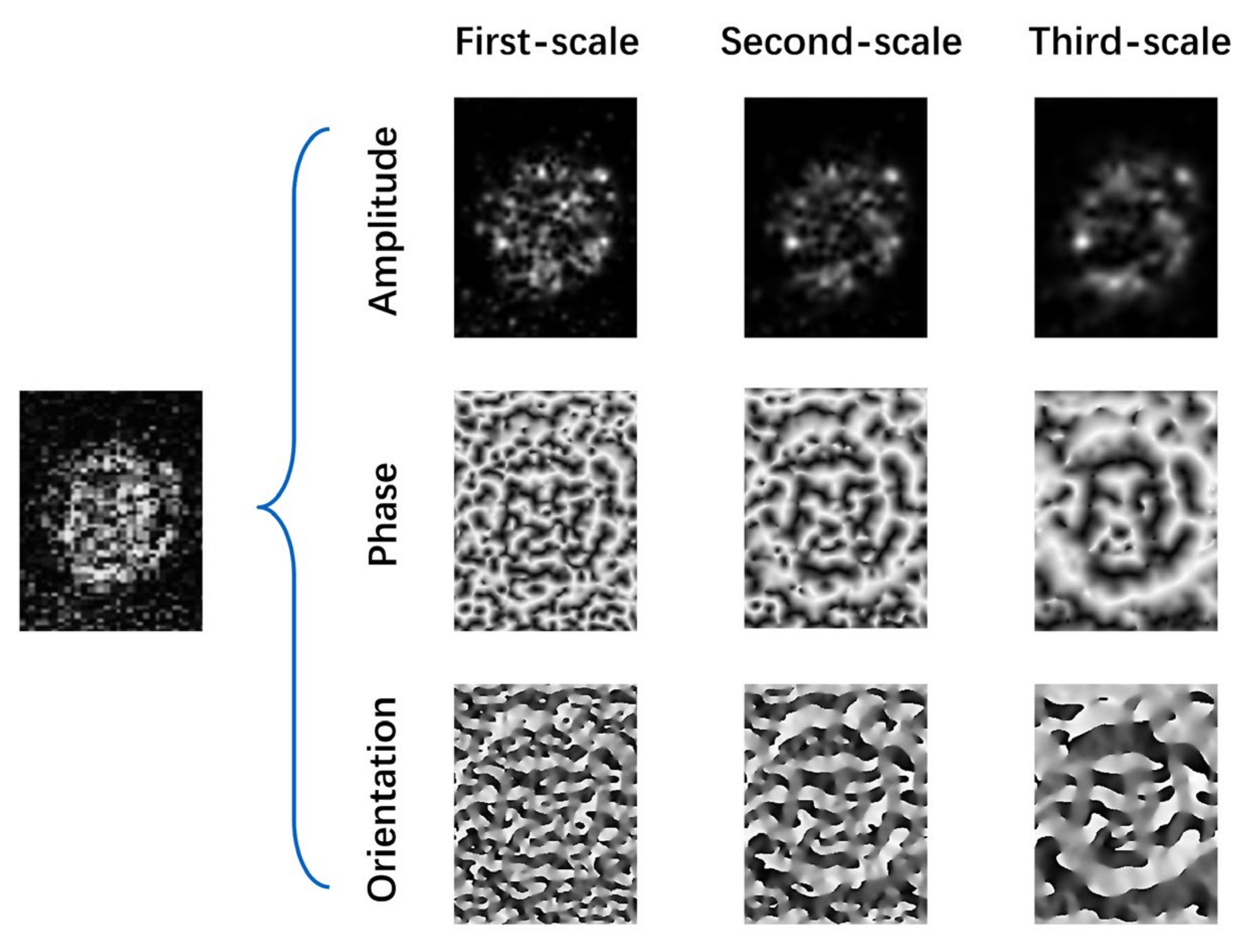
3.2.1. Monogenic Feature Extraction
3.2.2. Polarization Feature Extraction
3.3. Cross-Feature-Network (CFN)
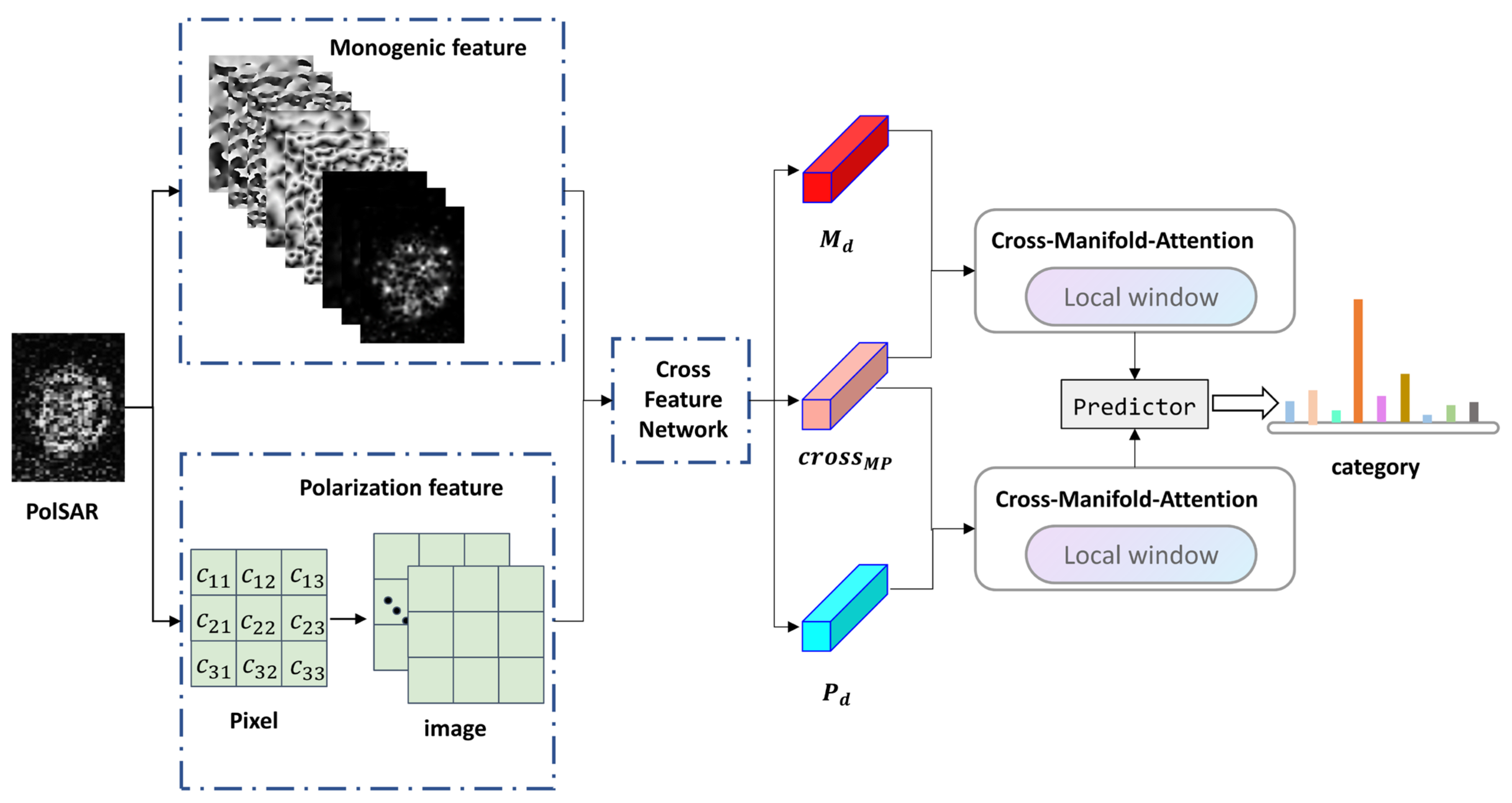
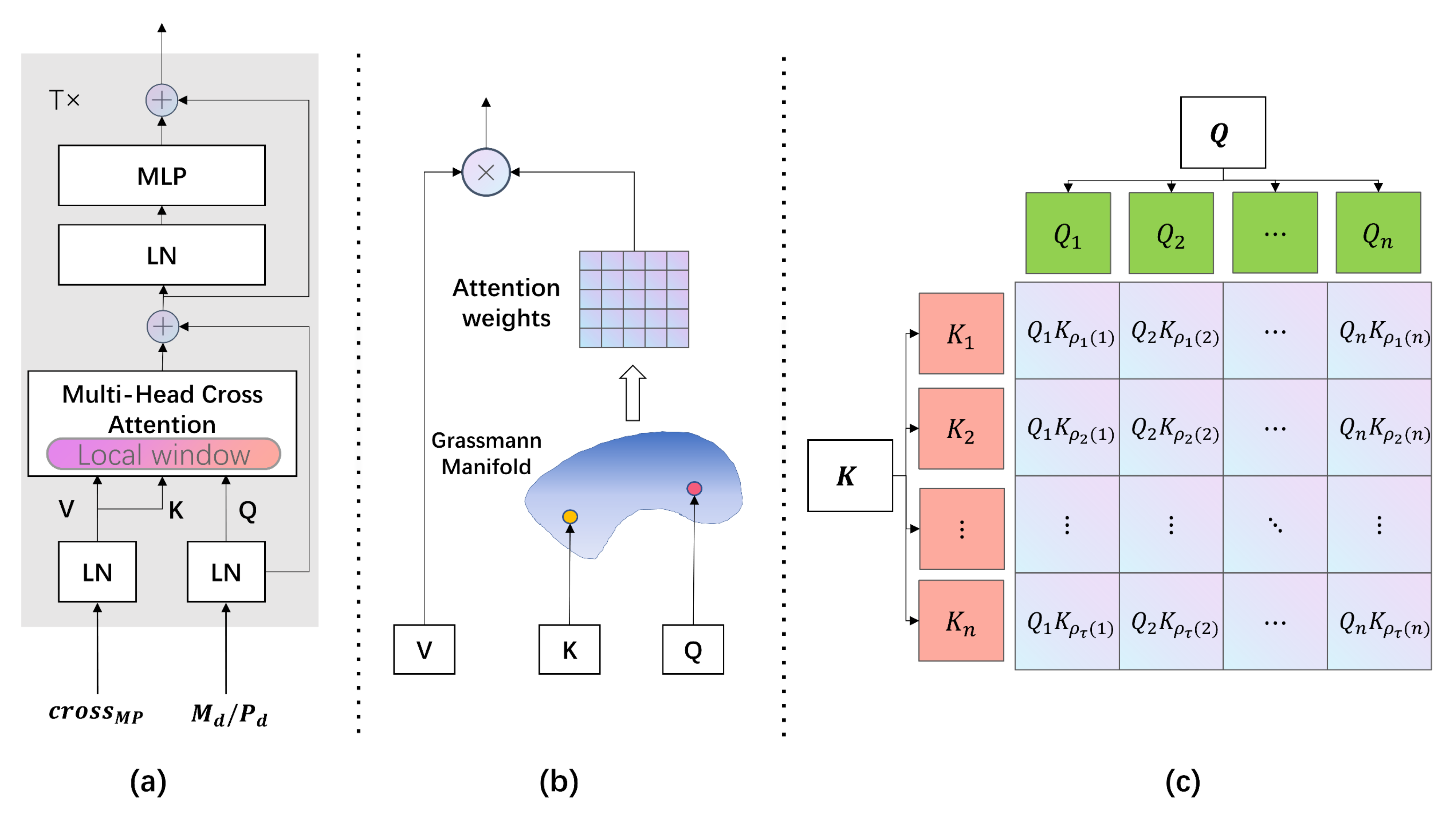
3.4. Cross-Manifold-Attention (CMA)
3.4.1. Feature Representation on Grassmann Manifold
3.4.2. Distance Metrics on Grassmann Manifold
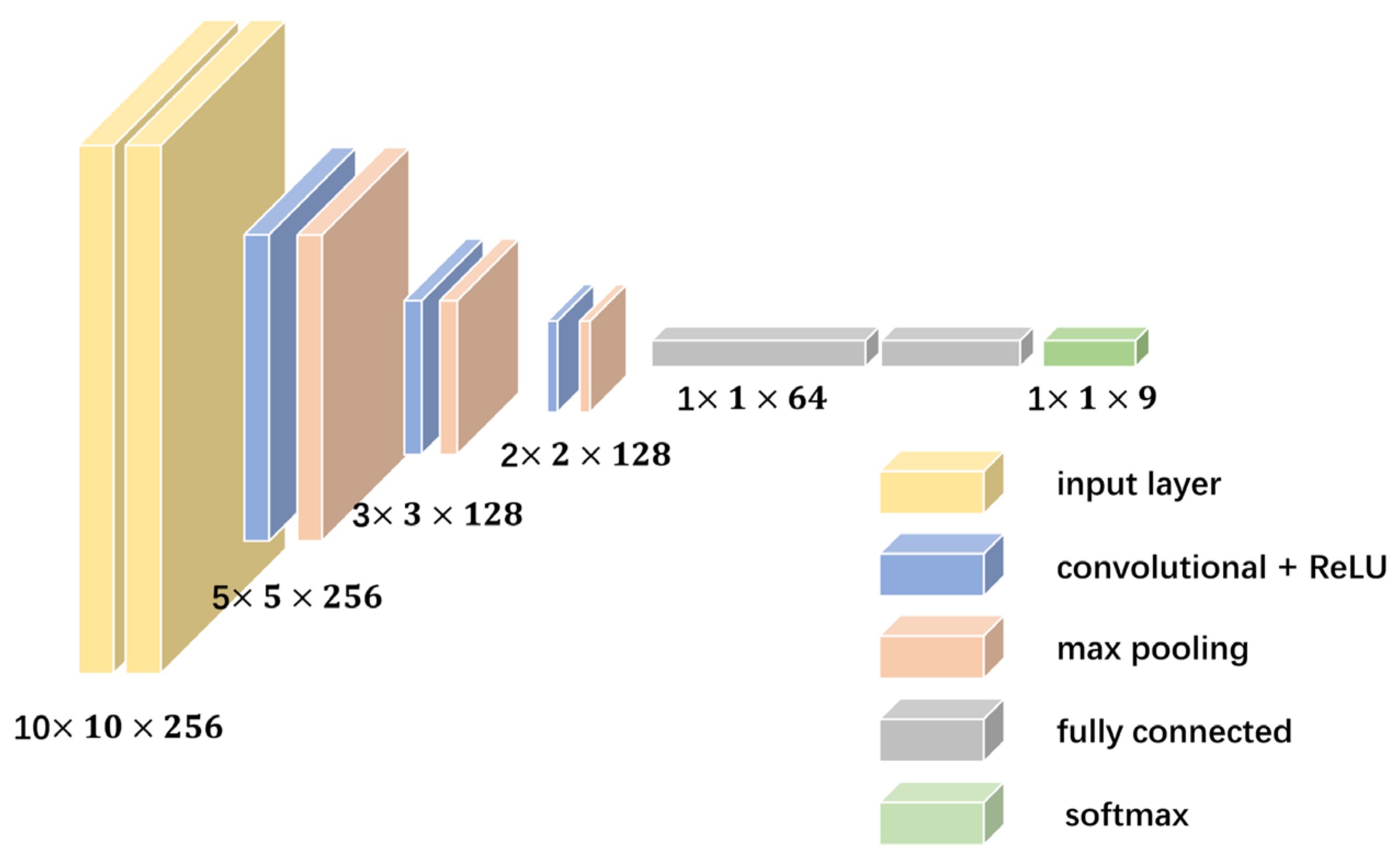
3.5. Predictor
4. Experiments
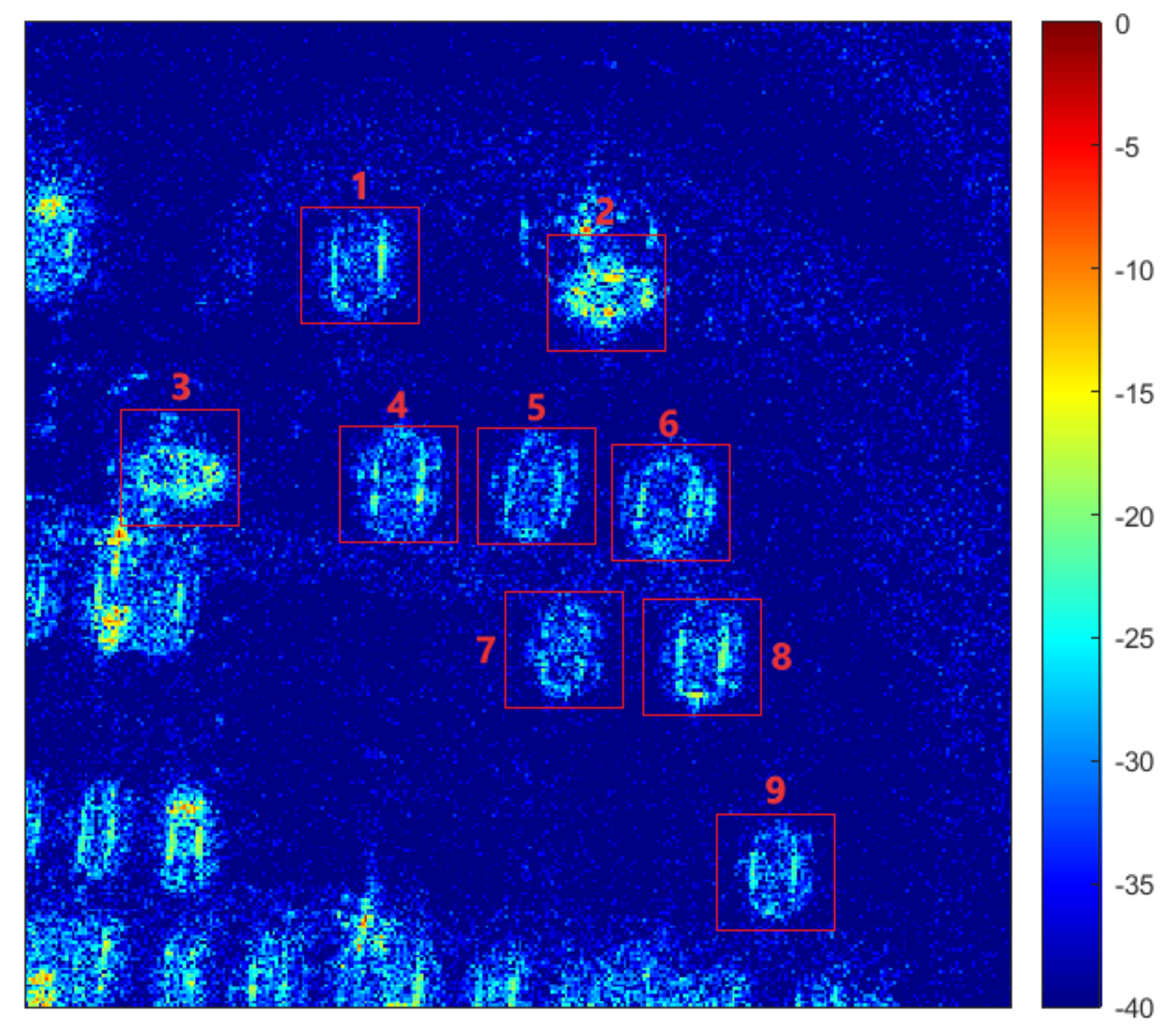
4.1. Data Description
4.2. Implementation Details
4.3. Evaluation Metrics
4.3.1. Overall Accuracy (OA)
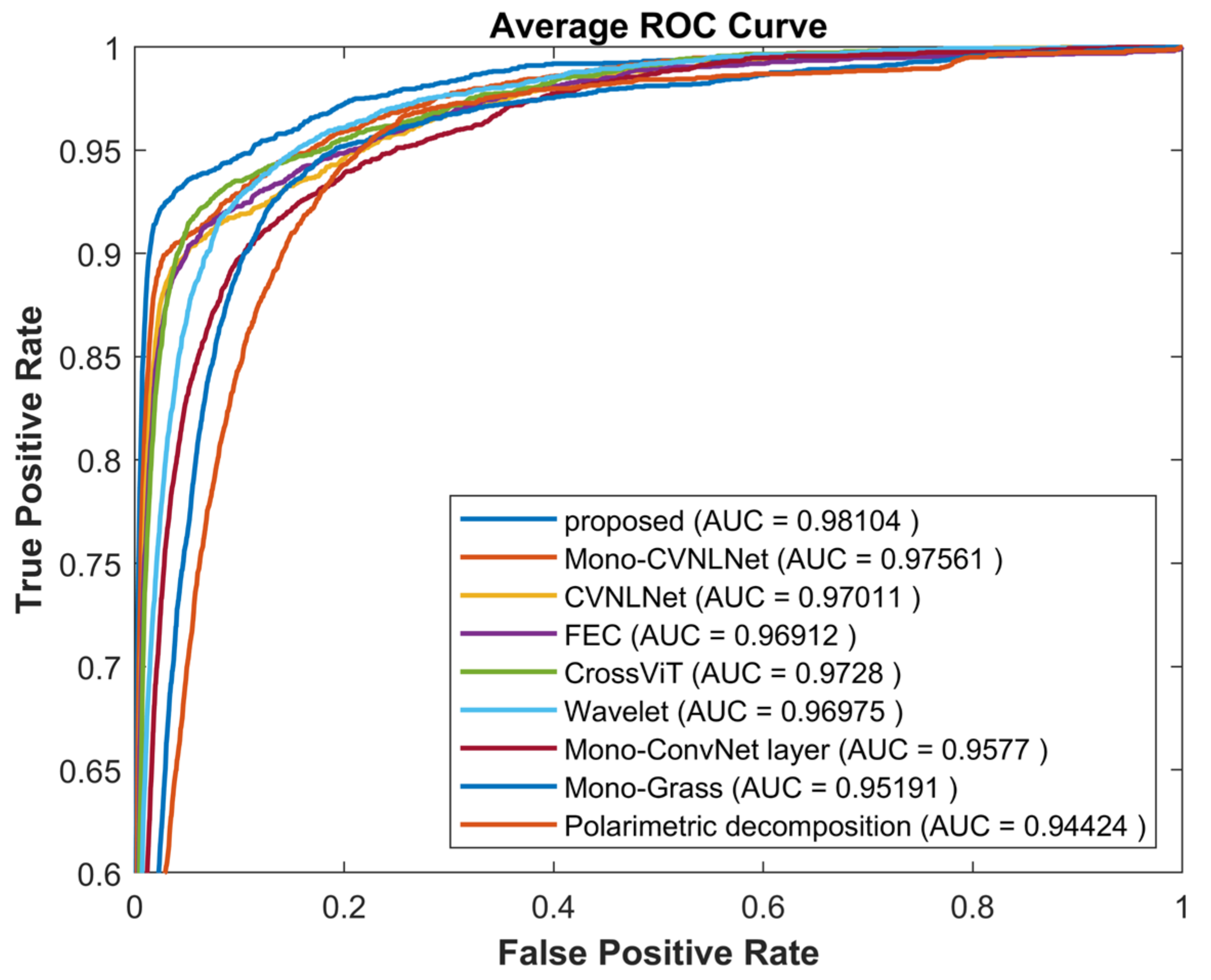
4.3.2. Receiver Operation Characteristics (ROC)
4.4. Quantitative Analysis
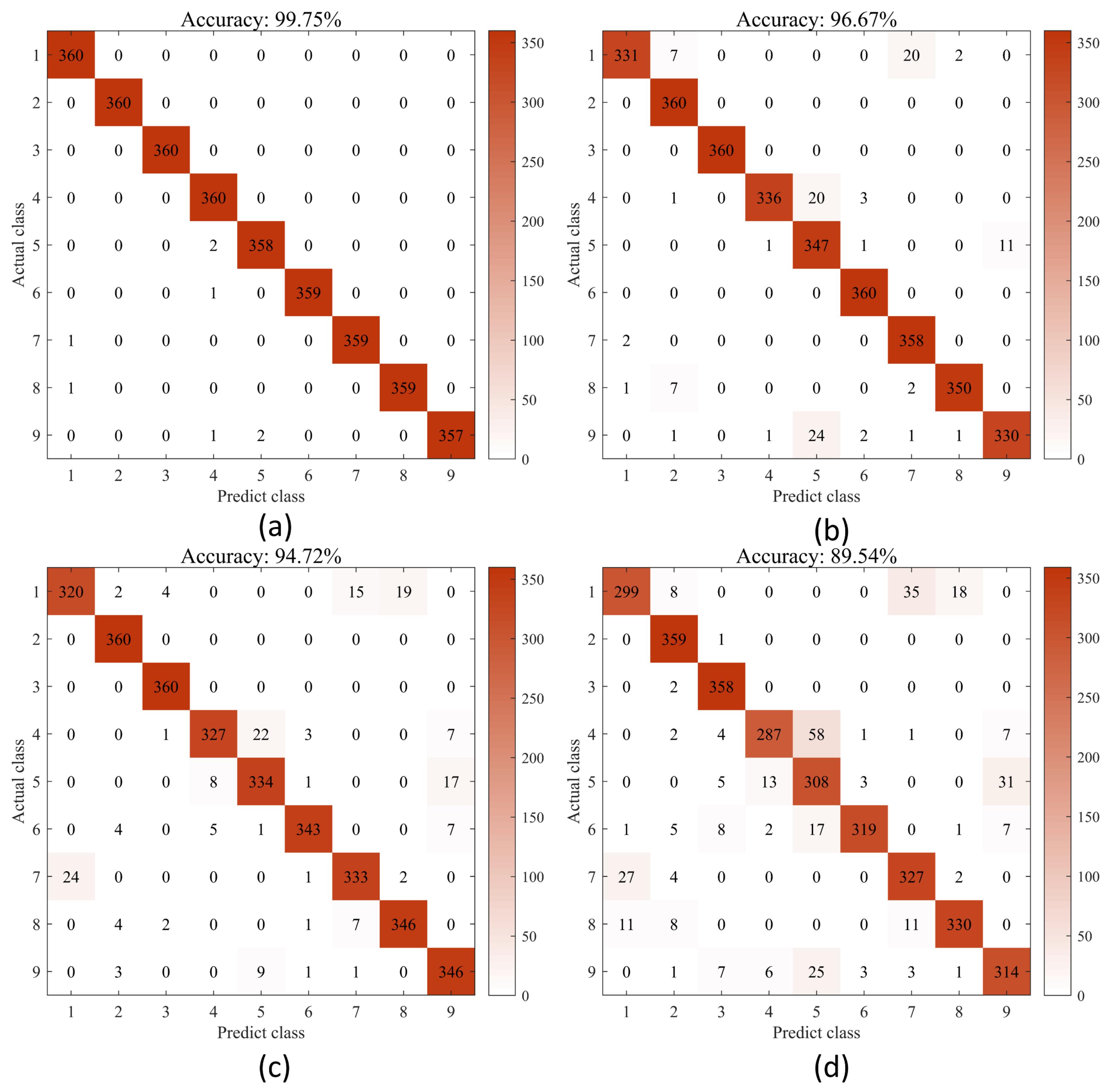
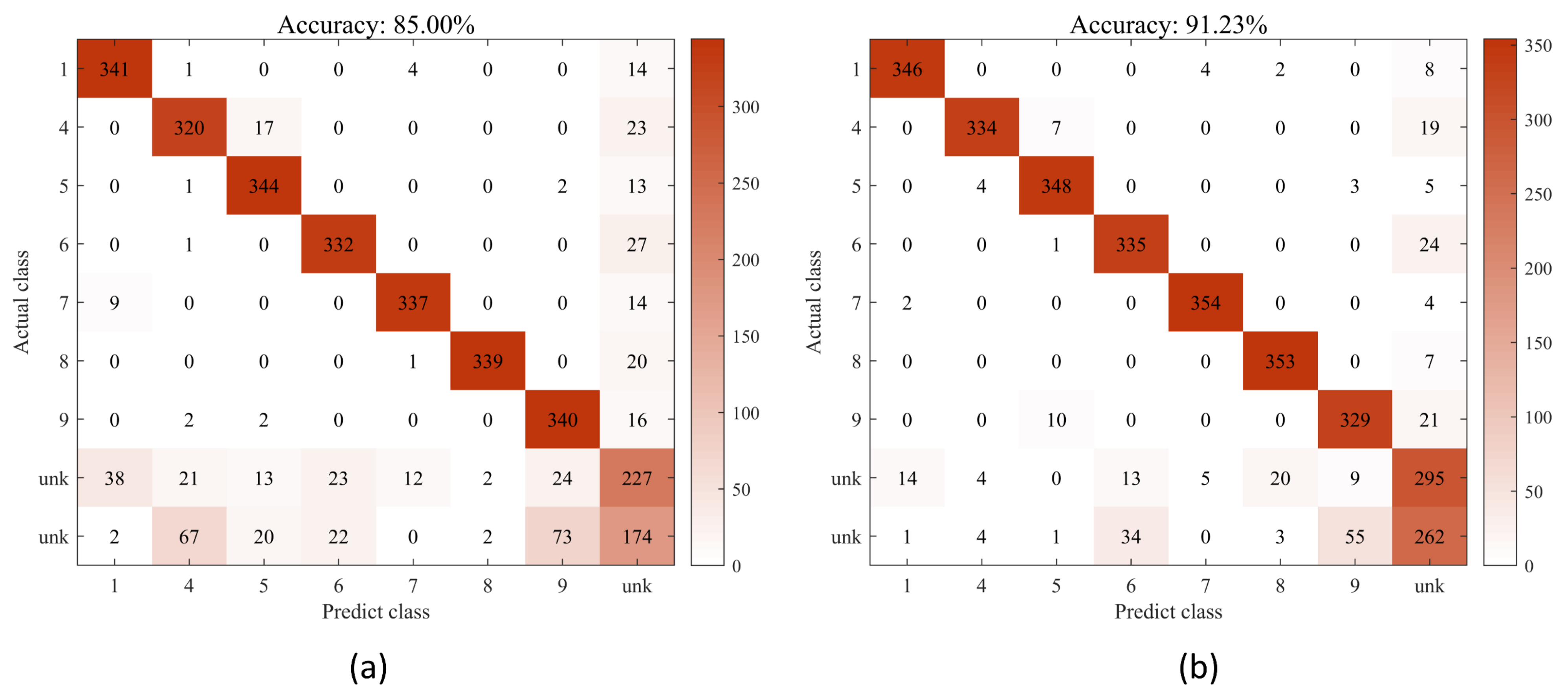
4.4.1. Classification Results and Analysis
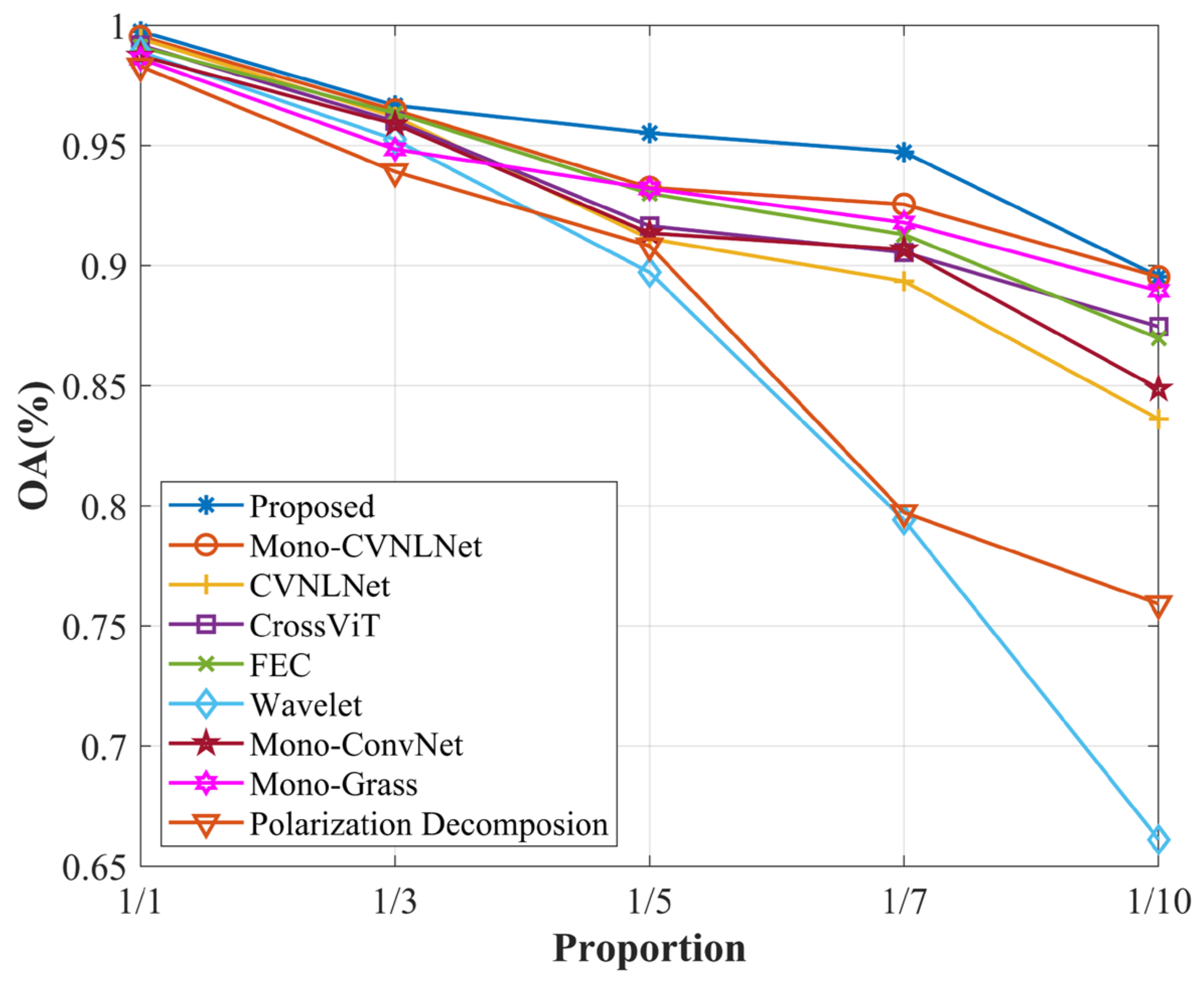
4.4.2. Classification Accuracy Evaluation under Few-Shot Recognition
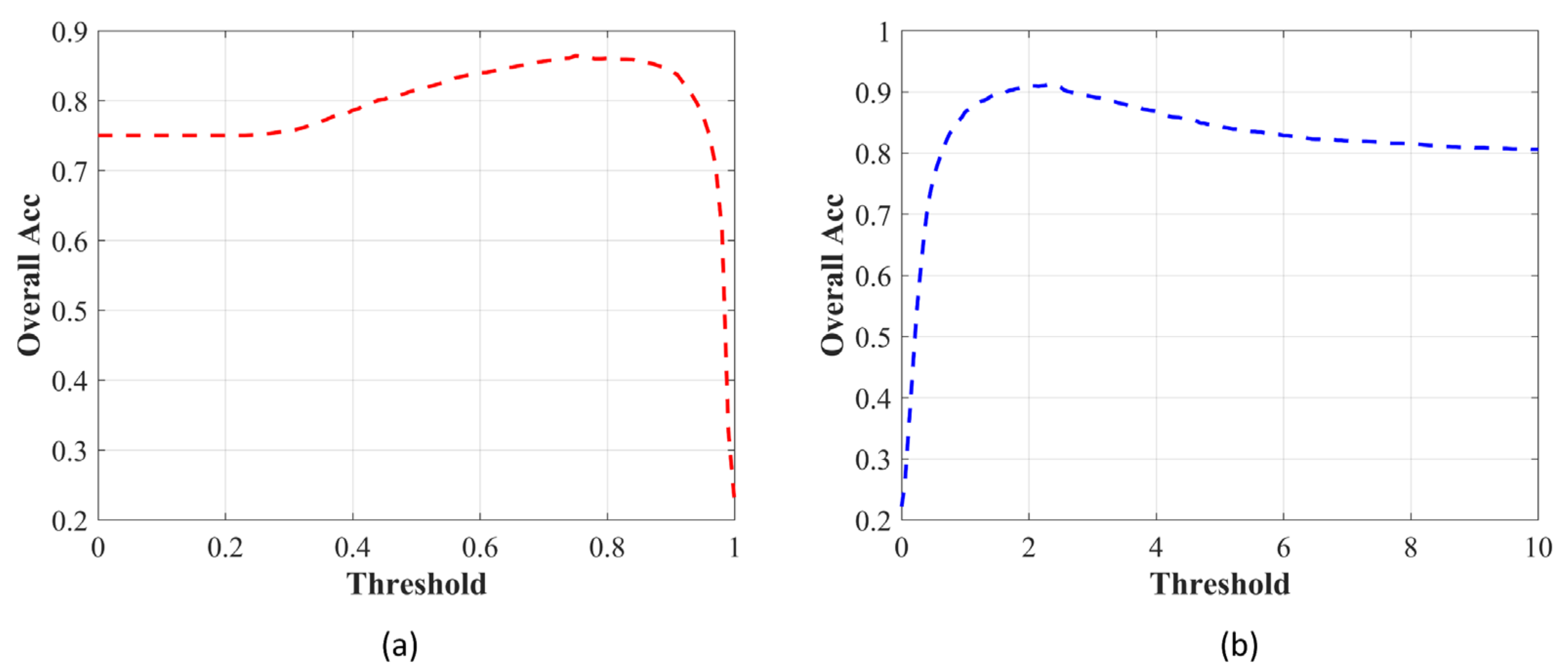
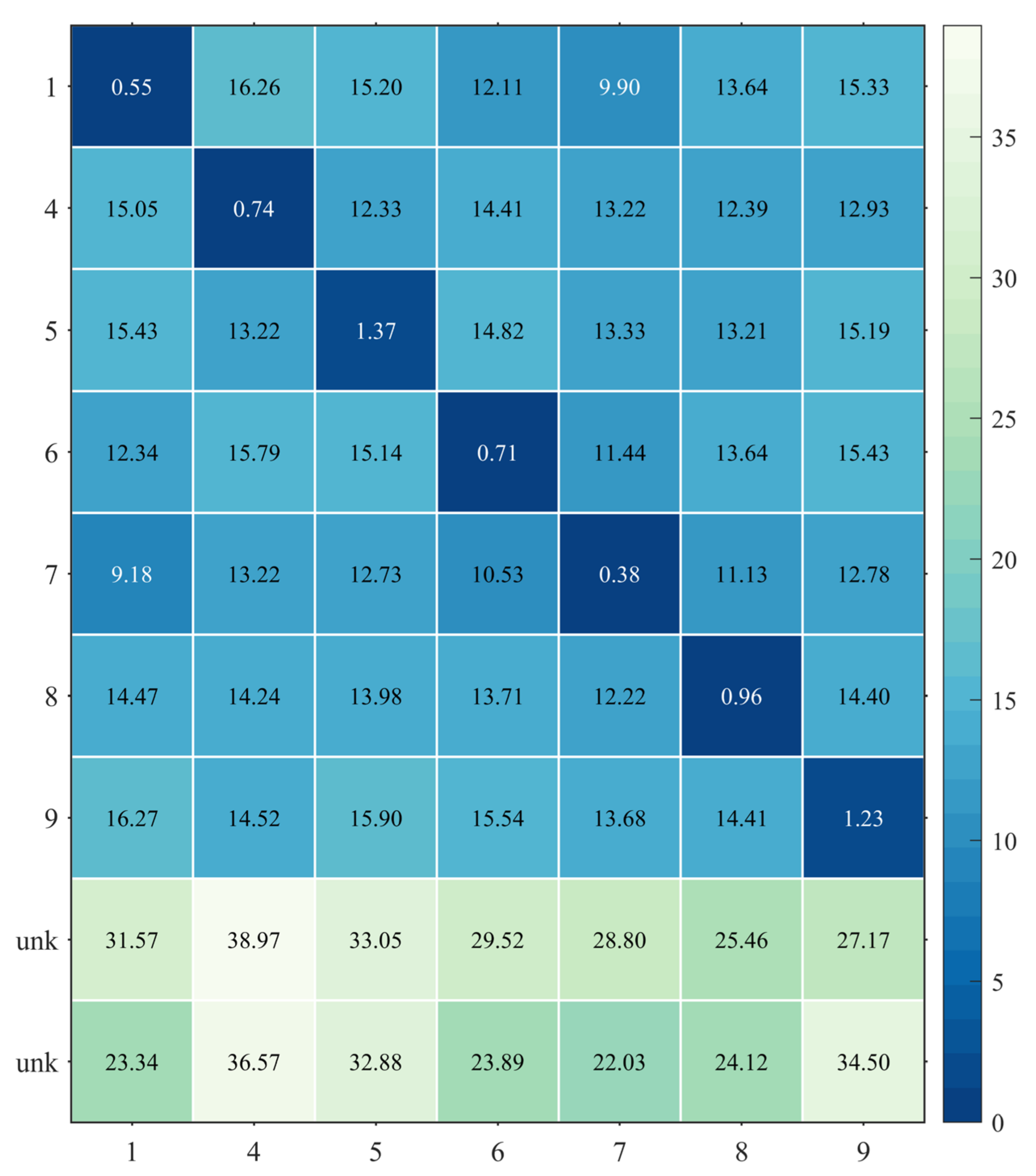
4.4.3. Classification Accuracy Evaluation under Open Set Recognition
4.4.4. Ablation Study
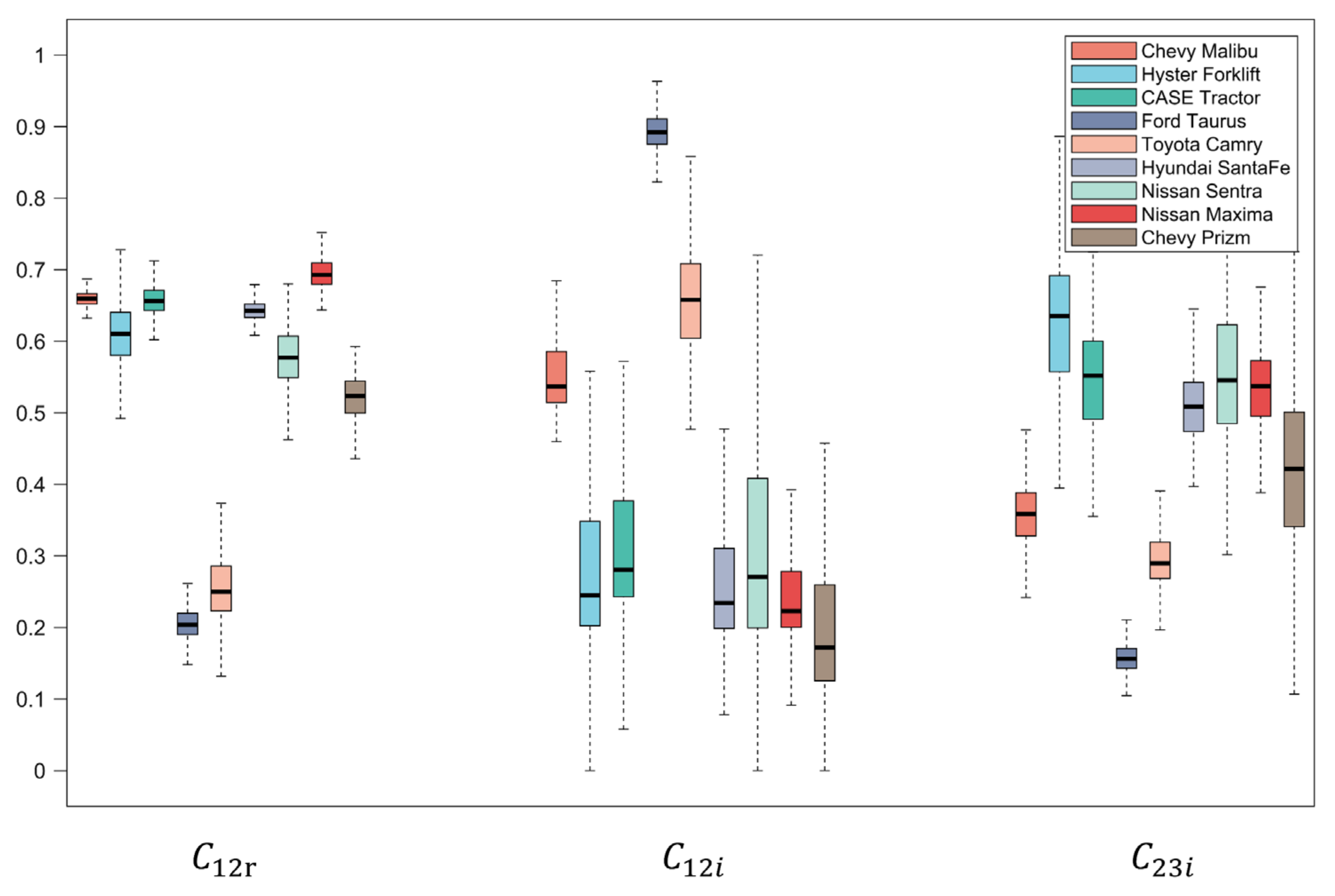
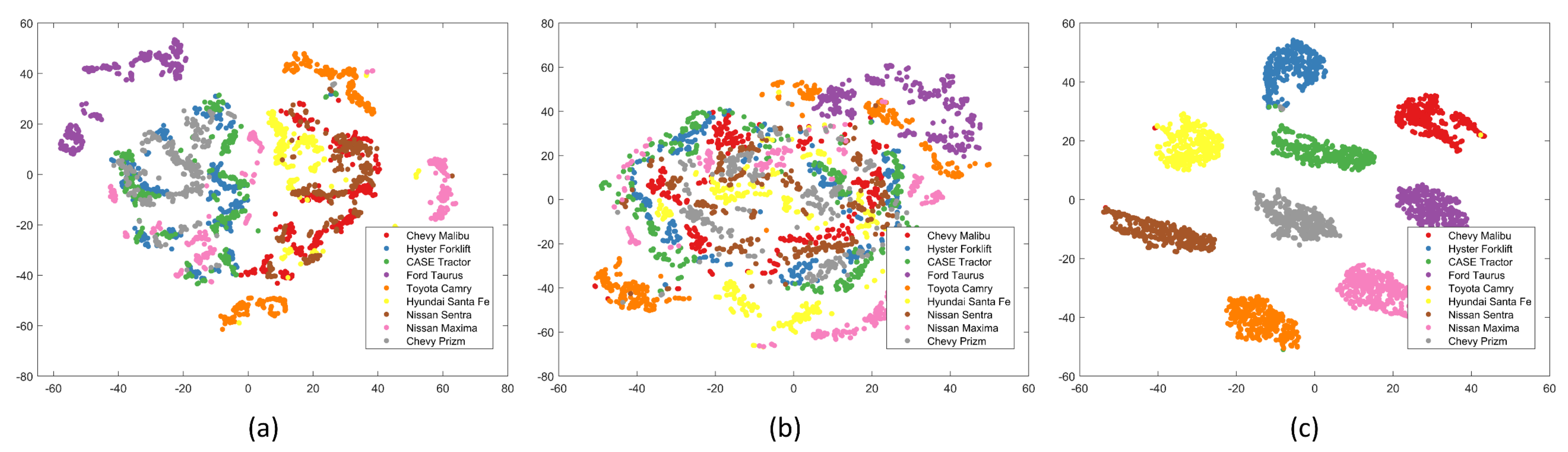
4.5. Qualitative Analysis
4.5.1. CFN Module Analysis
4.5.2. CMA Module Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- El-Darymli, K.; Gill, E.W.; McGuire, P.; Power, D.; Moloney, C. Automatic target recognition in synthetic aperture radar imagery: A state-of-the-art review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Parikh, H.; Patel, S.; Patel, V. Classification of SAR and PolSAR images using deep learning: A review. Int. J. Ournal Ournal Ournal Ournal Ournal 2020, 2020, 1–32. [Google Scholar] [CrossRef]
- Lee, S.; Pottier, E. Polarimetric Radar Imaging: From Basics to Applications; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimegic SAR image classification using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Zhang, W.-T.; Zheng, S.-D.; Li, Y.-B.; Guo, J.; Wang, H. A Full Tensor Decomposition Network for Crop Classification with Polarization Extension. Remote. Sens. 2022, 15, 56. [Google Scholar] [CrossRef]
- Kechagias-Stamatis, O.; Aouf, N. Automatic Target Recognition on Synthetic Aperture Radar Imagery: A Survey. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 56–81. [Google Scholar] [CrossRef]
- Blasch, E.; Majumder, U.; Zelnio, E.; Velten, V. Review of recent advances in AI/ML using the MSTAR data. Algorithms Synth. Aperture Radar Imag. XXVII 2020, 11393, 53–63. [Google Scholar]
- Zhang, J.; Xing, M.; Xie, Y. FEC: A feature fusion framework for SAR target recognition based on electromagnetic scattering features and deep CNN features. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2174–2187. [Google Scholar]
- Shi, J. SAR target recognition method of MSTAR data set based on multi-feature fusion. In Proceedings of the 2022 International Conference on Big Data, Information and Computer Network (BDICN), Sanya, China, 20–22 January 2022; pp. 626–632. [Google Scholar] [CrossRef]
- Li, F.; Yi, M.; Zhang, C.; Yao, W.; Hu, X.; Liu, F. POLSAR Target Recognition Using a Feature Fusion Framework Based On Monogenic Signal and Complex-Valued Non-Local Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 1–14. [Google Scholar] [CrossRef]
- Felsberg, M.; Sommer, G. The monogenic signal. IEEE Trans. Signal Process. 2001, 49, 3136–3144. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G.; Zhong, J.; Ma, C.; Yang, X. A robust similarity measure for attributed scattering center sets with application to SAR ATR. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3334–3347. [Google Scholar] [CrossRef]
- Dong, G.; Kuang, G. Classification on the Monogenic Scale Space: Application to Target Recognition in SAR Image. IEEE Trans. Image Process. 2015, 24, 2527–2539. [Google Scholar] [CrossRef] [PubMed]
- Dong, G.; Kuang, G. SAR Target Recognition Via Sparse Representation of Monogenic Signal on Grassmann Manifolds. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2016, 9, 1308–1319. [Google Scholar] [CrossRef]
- Dong, G.; Kuang, G.; Wang, N.; Wang, W. Classification via Sparse Representation of Steerable Wavelet Frames on Grassmann Manifold: Application to Target Recognition in SAR Image. IEEE Trans. Image Process. 2017, 26, 2892–2904. [Google Scholar] [CrossRef]
- Pei, H.; Owari, T.; Tsuyuki, S.; Zhong, Y. Application of a Novel Multiscale Global Graph Convolutional Neural Network to Improve the Accuracy of Forest Type Classification Using Aerial Photographs. Remote. Sens. 2023, 15, 1001. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, D.; Qiu, X.; Li, F. Scattering-Point-Guided RPN for Oriented Ship Detection in SAR Images. Remote. Sens. 2023, 15, 1411. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.-Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Zhang, X.; Xiang, H.; Xu, N.; Ni, L.; Ni, L.; Huo, C.; Pan, H. MsIFT: Multi-Source Image Fusion Transformer. Remote Sens. 2022, 14, 4062. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, X. HOG-ShipCLSNet: A Novel Deep Learning Network with HOG Feature Fusion for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–22. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, Y.; Xie, W.; Li, L. A Convolutional Neural Network Combined with Attributed Scattering Centers for SAR ATR. Remote Sens. 2021, 13, 5121. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. A polarization fusion network with geometric feature embedding for SAR ship classification. Pattern Recognit. 2022, 123, 108365. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Squeeze-and-excitation Laplacian pyramid network with dual-polarization feature fusion for ship classification in sar images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Injection of traditional hand-crafted features into modern CNN-based models for SAR ship classification: What, why, where, and how. Remote Sens. 2021, 13, 2091. [Google Scholar] [CrossRef]
- Guo, Y.; Du, L.; Li, C.; Chen, J. SAR Automatic Target Recognition Based on Multi-Scale Convolutional Factor Analysis Model with Max-Margin Constraint. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3605–3608. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Jia, L.; Xing, M. SAR Target Classification Using the Multikernel-Size Feature Fusion-Based Convolutional Neural Network. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Zeng, Z.; Zhang, H.; Sun, J. A Novel Target Feature Fusion Method with Attention Mechanism for SAR-ATR. In Proceedings of the 2022 IEEE 17th Conference on Industrial Electronics and Applications (ICIEA), Chengdu, China, 16–19 December 2022; pp. 522–527. [Google Scholar] [CrossRef]
- Zhai, Y.; Deng, W.; Lan, T.; Sun, B.; Ying, Z.; Gan, J.; Mai, C.; Li, J.; Labati, R.D.; Piuri, V.; et al. MFFA-SARNET: Deep Transferred Multi-Level Feature Fusion Attention Network with Dual Optimized Loss for Small-Sample SAR ATR. Remote. Sens. 2020, 12, 1385. [Google Scholar] [CrossRef]
- Zhao, X.; Lv, X.; Cai, J.; Guo, J.; Zhang, Y.; Qiu, X.; Wu, Y. Few-Shot SAR-ATR Based on Instance-Aware Transformer. Remote Sens. 2022, 14, 1884. [Google Scholar] [CrossRef]
- Wang, C.; Huang, Y.; Liu, X.; Pei, J.; Zhang, Y.; Yang, J. Global in Local: A Convolutional Transformer for SAR ATR FSL. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, S.; Pan, Z.; Hu, Y. Multi-Aspect Convolutional-Transformer Network for SAR Automatic Target Recognition. Remote Sens. 2022, 14, 3924. [Google Scholar] [CrossRef]
- Dong, N.; Wang, N.; Kuang, G. Sparse Representation of Monogenic Signal: With Application to Target Recognition in SAR Images. IEEE Signal Process. Lett. 2014, 21, 952–956. [Google Scholar]
- Felsberg, M.; Duits, R.; Florack, L. The monogenic scale space on a rectangular domain and its features. Int. J. Comput. Vis. 2005, 64, 187–201. [Google Scholar] [CrossRef]
- Sierra-Vázquez, V.; Serrano-Pedraza, I. Application of Riesz transforms to the isotropic AM-PM decomposition of geometrical-optical illusion images. OSA A 2010, 27, 781–796. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Liu, F.; Jiao, L.; Guo, Y.; Liang, X.; Li, L.; Yang, S.; Qian, X. Polarimetric Multipath Convolutional Neural Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Belloni, C.; Balleri, A.; Aouf, N.; Le Caillec, M.; Merlet, T. Explainability of Deep SAR ATR Through Feature Analysis. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 659–673. [Google Scholar] [CrossRef]
- Zhang, X.; Huo, C.; Xu, N.; Jiang, H.; Cao, Y.; Ni, L.; Pan, C. Multitask learning for ship detection from synthetic aperture radar images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8048–8062. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wie, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS ournal of Photogrammetry and Remote Sensing 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Shao, Z.; Shi, Z.; Shi, J.; Wie, S.; Zhang, T.; Zeng, T. A Group-Wise Feature Enhancement-and-Fusion Network with Dual-Polarization Feature Enrichment for SAR Ship Detection. Remote Sens. 2022, 14, 5276. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. A mask attention interaction and scale enhancement network for SAR ship instance segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- An, T.; Zhang, X.; Huo, C.; Xue, B.; Wang, L.; Pan, C. TR-MISR: Multiimage super-resolution based on feature fusion with transformers. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1373–1388. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Y.; Huo, C.; Xu, N.; Wang, L.; Pan, C. PSNet: Perspective-sensitive convolutional network for object detection. Neurocomputing 2022, 468, 384–395. [Google Scholar] [CrossRef]
- Cherian, A.; Sra, S. Riemannian dictionary learning and sparse coding for positive definite matrices. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2859–2871. [Google Scholar] [CrossRef] [PubMed]
- Hassani, A.; Walton, S.; Li, J.; Shi, H. Neighborhood attention transformer. arXiv 2022, arXiv:2204.07143. [Google Scholar]
- Jiayao, Z.; Guangxu, Z.; Heath, R.W.R.; Kaibin, H. Grassmannian Learning: Embedding Geometry Awareness in Shallow and Deep Learning. arXiv 2018, arXiv:1808.02229. [Google Scholar]
- Edelman, A.; Arias, T.A.; Smith, S.T. The Geometry of Algorithms with Orthogonality Constraints. SIAM J. Matrix Anal. Appl. 1998, 20, 303–353. [Google Scholar] [CrossRef]
- Jost, J. Riemannian Geometry and Geometric Analysis, 3rd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Harandi, M.; Sanderson, C.; Shen, C.; Lovell, B.C. Dictionary learning and sparse coding on Grassmann manifolds: An extrinsic solution. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3120–3127. [Google Scholar]
- Hamm, J.; Lee, D.D. Grassmann discriminant analysis: A unifying view on subspace-based learning. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 376–383. [Google Scholar]
- Ertin, E.; Austin, C.D.; Sharma, S.; Moses, R.L.; Potter, L.C. GOTCHA experience report: Three-dimensional SAR imaging with complete circular apertures. In Proceedings of the Algorithms for Synthetic Aperture Radar Imagery XIV, Orlando, FL, USA, 7 May 2007; pp. 9–20. [Google Scholar] [CrossRef]
- Clemente, C.; Pallotta, L.; Proudler, I.; De Maio, A. Multi-sensor full-polarimetric SAR automatic target recognition using pseudo-Zernike moments. In Proceedings of the 2014 International Radar Conference, IEEE, Lille, France, 13–17 October 2014; pp. 1–5. [Google Scholar]
- Ai, J.; Wang, F.; Mao, Y.; Luo, Q.; Yao, B.; Yan, H.; Xing, M.; Wu, Y. A Fine PolSAR Terrain Classification Algorithm Using the Texture Feature Fusion-Based Improved Convolutional Autoencoder. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Tang, X.; Sun, Q.; Zhang, D. Polarimetric Convolutional Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote. Sens. 2018, 57, 3040–3054. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Zou, B.; Moon, W.M. Fully Polarimetric SAR Image Classification via Sparse Representation and Polarimetric Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 8, 3923–3932. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, M.; Cao, Z.; Pi, Y. SAR Image Recognition with Monogenic Scale Selection-Based Weighted Multi-task Joint Sparse Representation. Remote. Sens. 2018, 10, 504. [Google Scholar] [CrossRef]
- Li, F.; Yao, W.; Li, Y.; Chen, W. SAR Target Recognition Using Improved Monogenic-Based Feature Extraction Framework. In Proceedings of the 2021 CIE International Conference on Radar (Radar), Haikou, China; 2021; pp. 1388–1391. [Google Scholar] [CrossRef]
- Ding, B.; Wen, G.; Huang, X.; Ma, C.; Yang, X. Target Recognition in Synthetic Aperture Radar Images via Matching of Attributed Scattering Centers. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2017, 10, 3334–3347. [Google Scholar] [CrossRef]
- Yu, L.; Hu, Y.; Xie, X.; Lin, Y.; Hong, W. Complex-Valued Full Convolutional Neural Network for SAR Target Classification. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 1752–1756. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification With Transformers. IEEE Trans. Geosci. Remote. Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Wang, R.; Wu, X.-J.; Kittler, J. SymNet: A Simple Symmetric Positive Definite Manifold Deep Learning Method for Image Set Classification. IEEE Trans. Neural Networks Learn. Syst. 2021, 33, 2208–2222. [Google Scholar] [CrossRef] [PubMed]
- Ulises Moya-Sánchez, E.; Xambo-Descamps, S.; Sanchez, A.; Salazar-Colores, S.; Cortes, U. A trainable monogenic ConvNet layer robust in front of large contrast changes in image classification. arXiv 2021, arXiv:2109.06926. [Google Scholar]
- Giusti, E.; Ghio, S.; Oveis, A.H.; Martorlla, M. Proportional Similarity-Based Openmax Classifier for Open Set Recognition in SAR Images. Remote Sens. 2022, 14, 4665. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, DC, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
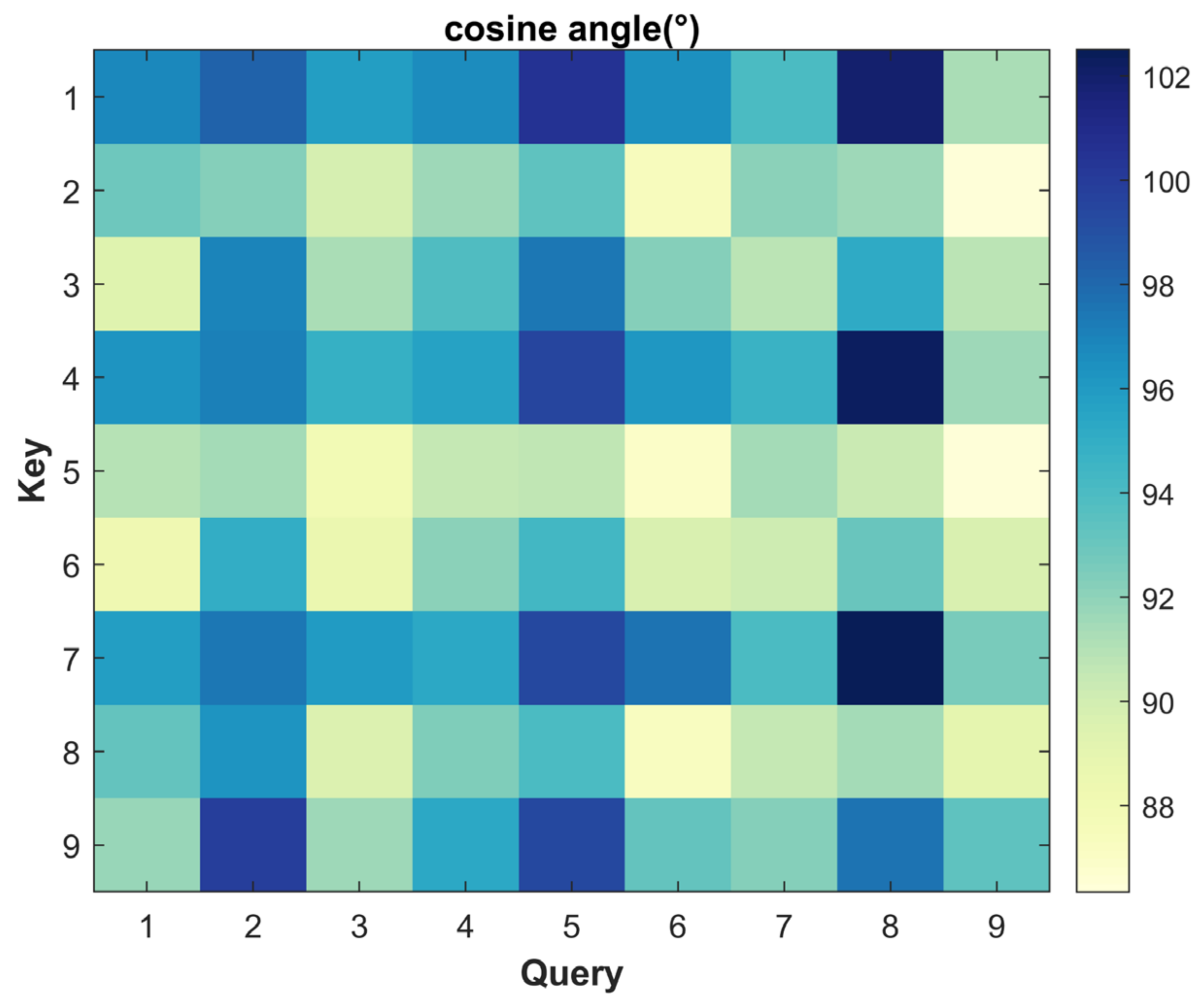{kind=link}
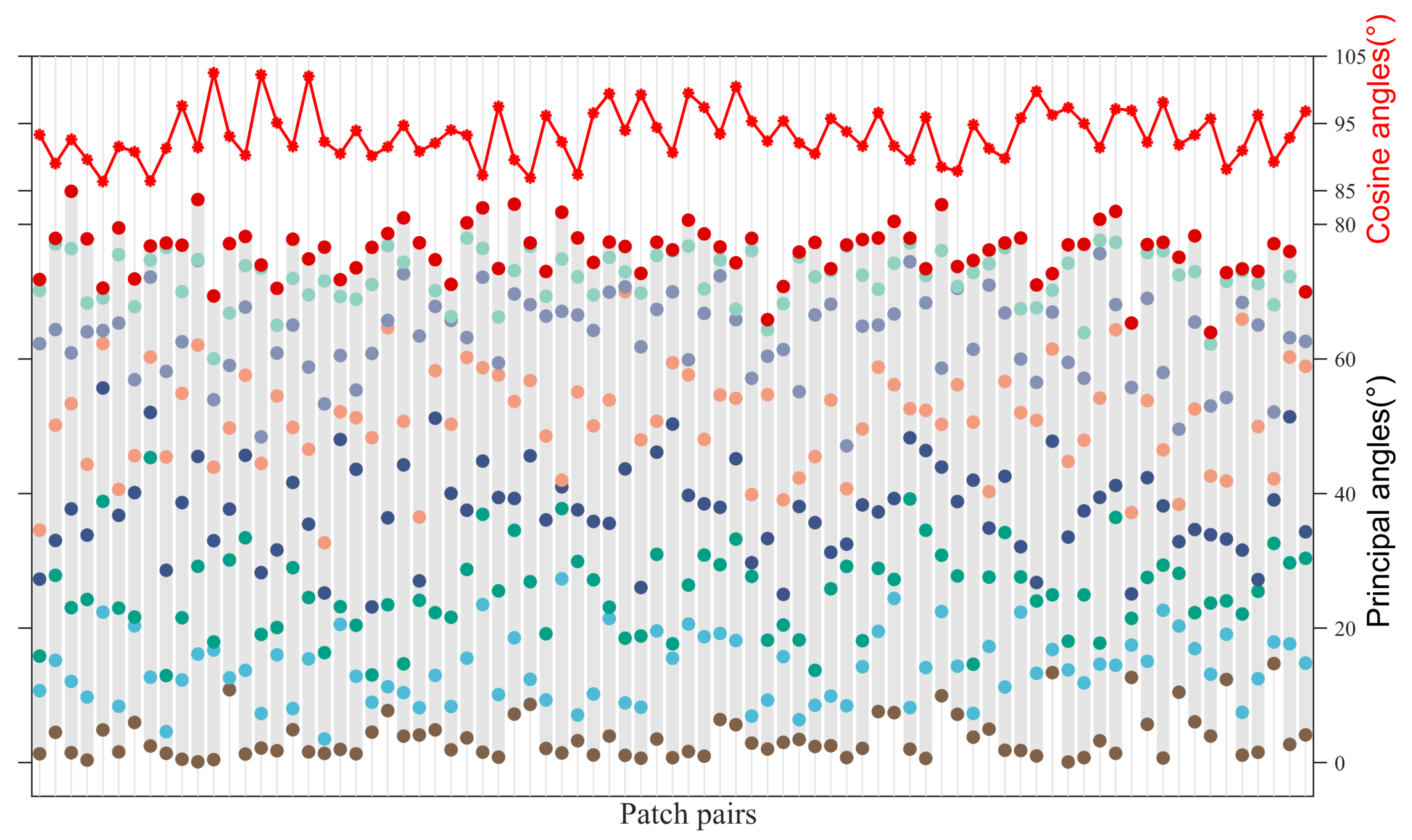{kind=link}
| Input | Ex-Net | Fu-Net | |||
|---|---|---|---|---|---|
| Block1 | Block2 | Block3 | Block4 | Block5 | |
| 5 × 5 Conv | 5 × 5 Conv | 5 × 5 Conv | 5 × 5 Conv | 1 × 1 Conv | |
| BN | BN | BN | BN | BN | |
| 20 × 20 × d | Relu | Relu | Relu | Relu | Relu |
| 2 × 2 MP | |||||
| 20 × 20 × 16 | 10 × 10 × 32 | 10 × 10 × 64 | 10 × 10 × 128 | 10 × 10 × 128 | |
| Dataset | Category | Pass | Number |
|---|---|---|---|
| Training set | 1~9 | 1, 3, 5, 7 | 360 × 9 |
| Test set | 1~9 | 2, 4, 6, 8 | 360 × 9 |
| Batch size | 64 |
| Optimizer | Adam |
| Initialized learning rate | 0.01 |
| Learning Rate Decay | Exponential-decay |
| Momentum | 0.9 |
| Weight decay | 0.0001 |
| Epochs | 100 |
| Input | Method | Classifier | OA (%) | FPS | |
|---|---|---|---|---|---|
| Handcrafted features | Mono-based | Mono | SRC | 97.72 | 83.08 |
| Mono-HOG | SVM | 98.15 | 58.65 | ||
| Mono-BoVW | SVM | 98.02 | 19.11 | ||
| Mono-Grass | SRC | 98.61 | 24.23 | ||
| Pol-based | Polarimetric decomposition | SVM | 98.30 | 32.65 | |
| Polarimetric scattering coding | SVM | 97.65 | 39.94 | ||
| others | Steerable Wavelet | SVM | 98.89 | 38.54 | |
| ASC | SVM | 98.46 | 15.49 | ||
| Deep features | CNN-based | A-ConvNet | Softmax | 97.99 | 442 |
| CV-CNN | Softmax | 98.46 | 403.91 | ||
| CV-FCNN | Softmax | 98.98 | 341.89 | ||
| CVNLNet | Softmax | 99.44 | 320.46 | ||
| RVNLNet | Softmax | 98.52 | 431.71 | ||
| Transformer-based | ViT | Softmax | 98.77 | 389.2 | |
| SpectralFormer | Softmax | 98.12 | 376.27 | ||
| CrossViT | Softmax | 99.17 | 363.07 | ||
| others | SymNet | KNN | 97.28 | 263.28 | |
| Monogenic ConvNet layer | Softmax | 98.73 | 308.70 | ||
| Multi-features | FEC | Softmax | 99.10 | 195.06 | |
| Mono-CVNLNet | Softmax | 99.54 | 227.96 | ||
| Proposed | Softmax | 99.75 | 322.93 | ||
| Method | Known Target Accuracy (%) | Unknown Target Accuracy (%) | Overall Target Accuracy (%) |
|---|---|---|---|
| Mono-Grass | 89.96 | 67.64 | 85.00 |
| Mono-ConvNet | 88.89 | 72.78 | 85.31 |
| Wavelet | 92.30 | 70.00 | 87.35 |
| CrossViT | 92.78 | 71.11 | 87.96 |
| CVNLNet | 93.97 | 69.58 | 88.55 |
| FEC | 93.29 | 73.19 | 88.83 |
| Mono-CVNLNet | 93.81 | 75.14 | 89.66 |
| Proposed | 95.20 | 77.36 | 91.23 |
| Method | M-DSMANet | P-DSMANet | MF-DCMANet |
| OA (%) | 98.58 | 97.84 | 99.75 |
| Method | Concat | Parallel | En-De | CFN |
| OA (%) | 98.55 | 98.73 | 95.68 | 99.75 |
| Method | Euclidean | Grassmann |
| OA (%) | 98.64 | 99.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Zhang, C.; Zhang, X.; Li, Y. MF-DCMANet: A Multi-Feature Dual-Stage Cross Manifold Attention Network for PolSAR Target Recognition. Remote Sens. 2023, 15, 2292. https://doi.org/10.3390/rs15092292
Li F, Zhang C, Zhang X, Li Y. MF-DCMANet: A Multi-Feature Dual-Stage Cross Manifold Attention Network for PolSAR Target Recognition. Remote Sensing. 2023; 15(9):2292. https://doi.org/10.3390/rs15092292
Chicago/Turabian StyleLi, Feng, Chaoqi Zhang, Xin Zhang, and Yang Li. 2023. "MF-DCMANet: A Multi-Feature Dual-Stage Cross Manifold Attention Network for PolSAR Target Recognition" Remote Sensing 15, no. 9: 2292. https://doi.org/10.3390/rs15092292
APA StyleLi, F., Zhang, C., Zhang, X., & Li, Y. (2023). MF-DCMANet: A Multi-Feature Dual-Stage Cross Manifold Attention Network for PolSAR Target Recognition. Remote Sensing, 15(9), 2292. https://doi.org/10.3390/rs15092292