
Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images


Abstract
1. Introduction
- A new ship detection model called CSD-YOLO is proposed, with better multi-scale ship detection and ship identification capability in complex environments.
- Given the multi-scale and large-scale variation characteristics of the targets present in the SAR images of ships and the issue of missed ship detection in complex environments, we propose the SAS-FEN module in order to fuse the feature information of each layer and improve the detection effect of the model for ships of different scales while also being able to more accurately extract the scattering information of small targets and increase their detection accuracy.
- The experimental results on two datasets, SSDD and HRSID, demonstrate that CSD-YOLO has better generalizability and higher detection accuracy than various approaches, including YOLOv7, providing a better foundation for complicated projects (such as ship tracking and re-identification) and aiding in the advancement of intelligent border and sea defense construction.
2. Methodology
2.1. Overall Scheme of the CSD-YOLO
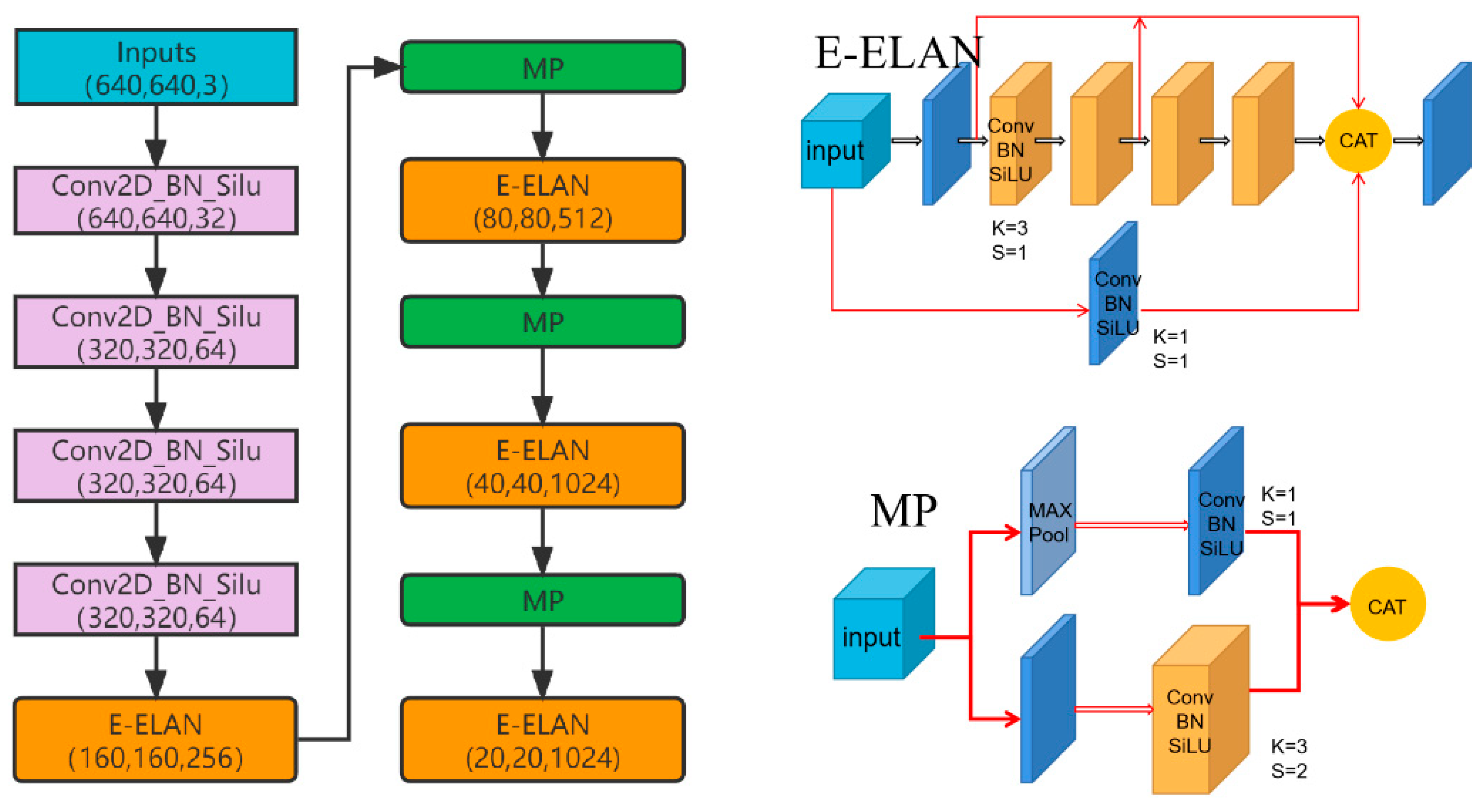
2.2. Feature Extraction Network
2.3. The Architecture of the Proposed SAS-FPN Model
2.3.1. Attention Mechanism for Small Ship
2.3.2. Multi-Scale Feature Extraction
2.4. Loss Function
- (1)
- Angle cost, defined as follows
- (2)
- Distance cost, defined as follows
- (3)
- Shape cost, defined as follows
- (4)
- IoU cost
3. Experiments and Results
3.1. Experiment Settings
3.2. Datasets
- (1)
- SSDD:
- (2)
- HRSID:
3.3. Experimental Evaluation Metrics
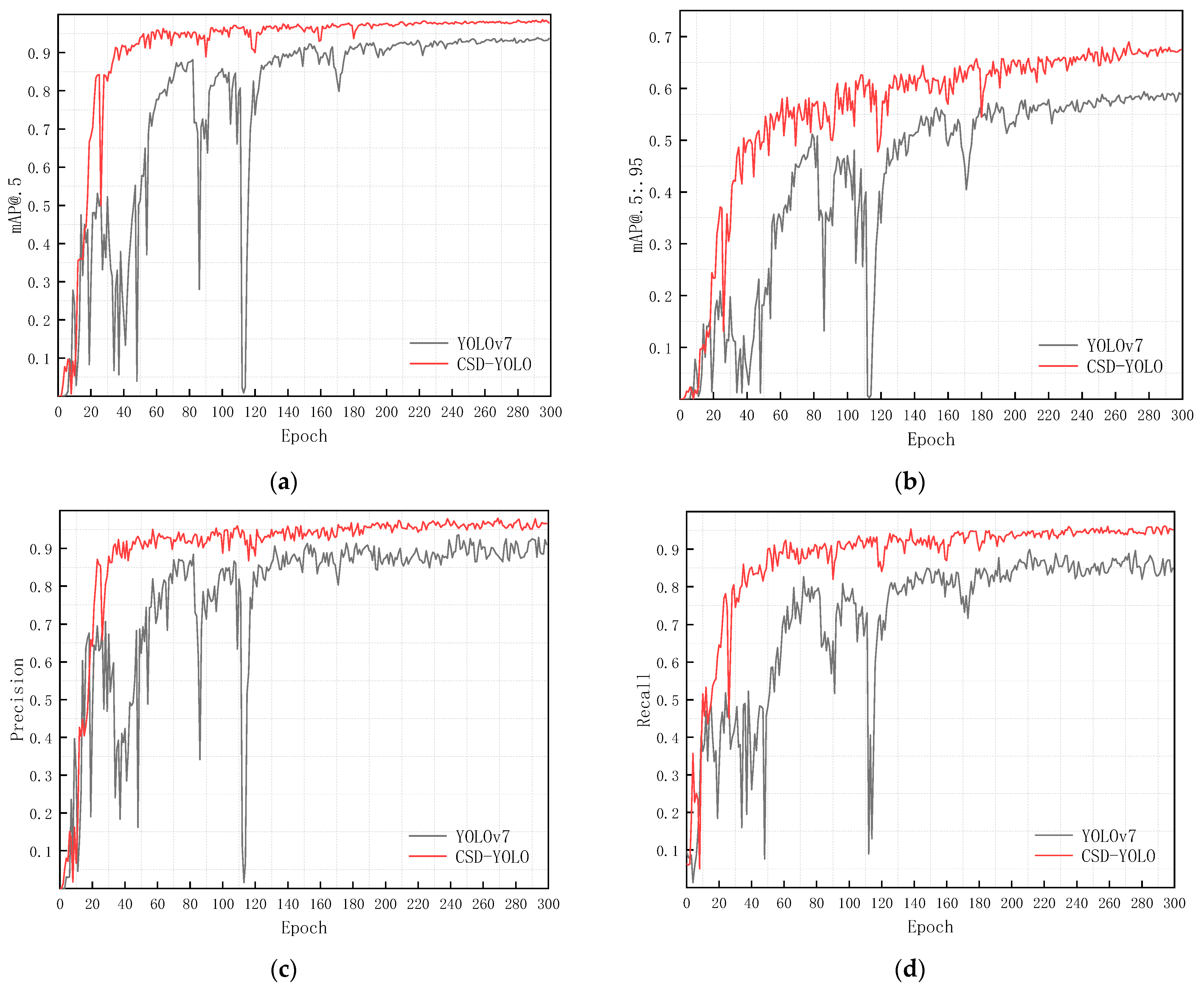
3.4. Results and Discussion
3.4.1. Ablation Study
3.4.2. Comparison with Other Methods
3.4.3. Generalization Ability Test
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Hao, Y. A Survey of SAR Image Target Detection Based on Convolutional Neural Networks. Remote Sens. 2022, 14, 6240. [Google Scholar] [CrossRef]
- Eldhuset, K. An Automatic Ship and Ship Wake Detection System for Spaceborne SAR Images in Coastal Regions. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1010–1019. [Google Scholar] [CrossRef]
- Moreira, A.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.; Younis, M.; Lopez-Dekker, P.; Huber, S.; Villano, M.; Pardini, M.; Eineder, M.; et al. Tandem-L: A Highly Innovative Bistatic SAR Mission for Global Observation of Dynamic Processes on the Earth’s Surface. IEEE Geosci. Remote Sens. Mag. 2015, 3, 8–23. [Google Scholar] [CrossRef]
- Feng, S.; Fan, Y.; Tang, Y.; Cheng, H.; Zhao, C.; Zhu, Y.; Cheng, C. A Change Detection Method Based on Multi-Scale Adaptive Convolution Kernel Network and Multimodal Conditional Random Field for Multi-Temporal Multispectral Images. Remote Sens. 2022, 14, 5368. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, J.; Huang, Z.; Luo, H.; Wu, B.; Li, Y. HRLE-SARDet: A Lightweight SAR Target Detection Algorithm Based on Hybrid Representation Learning Enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5203922. [Google Scholar] [CrossRef]
- Yoshida, T.; Ouchi, K. Detection of Ships Cruising in the Azimuth Direction Using Spotlight SAR Images with a Deep Learning Method. Remote Sens. 2022, 14, 4691. [Google Scholar] [CrossRef]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; van Schie, B. Ship Surveillance With TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1092–1103. [Google Scholar] [CrossRef]
- Steenson, B.O. Detection Performance of a Mean-Level Threshold. IEEE Trans. Aerosp. Electron. Syst. 1968, AES-4, 529–534. [Google Scholar] [CrossRef]
- Wang, S.; Gao, S.; Zhou, L.; Liu, R.; Zhang, H.; Liu, J.; Jia, Y.; Qian, J. YOLO-SD: Small Ship Detection in SAR Images by Multi-Scale Convolution and Feature Transformer Module. Remote Sens. 2022, 14, 5268. [Google Scholar] [CrossRef]
- Yu, X.; Salimpour, S.; Queralta, J.P.; Westerlund, T. General-Purpose Deep Learning Detection and Segmentation Models for Images from a Lidar-Based Camera Sensor. Sensors 2023, 23, 2936. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Y.; Chen, Z. A Small Target Detection Method Based on Deep Learning With Considerate Feature and Effectively Expanded Sample Size. IEEE Access 2021, 9, 96559–96572. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual Region-Based Convolutional Neural Network with Multilayer Fusion for SAR Ship Detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Wang, J.; Cui, Z.; Jiang, T.; Cao, C.; Cao, Z. Lightweight Deep Neural Networks for Ship Target Detection in SAR Imagery. IEEE Trans. Image Process. 2023, 32, 565–579. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Li, W.; Liu, L. R-CenterNet+: Anchor-Free Detector for Ship Detection in SAR Images. Sensors 2021, 21, 5693. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for Ship Detection and Segmentation From Remote Sensing Images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Berg, A.C.; Fu, C.Y.; Szegedy, C.; Anguelov, D.; Erhan, D.; Reed, S.; Liu, W. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A Deep Learning Dataset Dedicated to Small Ship Detection from Large-Scale Sentinel-1 SAR Images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Zhou, D.; Zeng, L.; Zhang, K. A Novel SAR Target Detection Algorithm via Multi-Scale SIFT Features. J. Northwest. Polytech. Univ. 2015, 33, 867–873. [Google Scholar]
- Wang, W.; Cao, T.; Liu, S.; Tu, E. Remote Sensing Image Automatic Registration on Multi-Scale Harris-Laplacian. J. Indian Soc. Remote Sens. 2015, 43, 501–511. [Google Scholar] [CrossRef]
- Zhu, H.; Xie, Y.; Huang, H.; Jing, C.; Rong, Y.; Wang, C. DB-YOLO: A Duplicate Bilateral YOLO Network for Multi-Scale Ship Detection in SAR Images. Sensors 2021, 21, 8146. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Zhou, K.; Zhang, M.; Wang, H.; Tan, J. Ship Detection in SAR Images Based on Multi-Scale Feature Extraction and Adaptive Feature Fusion. Remote Sens. 2022, 14, 755. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A Novel YOLO-Based Method for Arbitrary-Oriented Ship Detection in High-Resolution SAR Images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Liang, T.; Chu, X.; Liu, Y.; Wang, Y.; Tang, Z.; Chu, W.; Chen, J.; Ling, H. CBNet: A Composite Backbone Network Architecture for Object Detection. IEEE Trans. Image Process. 2022, 31, 6893–6906. [Google Scholar] [CrossRef]
- Zhuang, L.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Yang, Q.-L.Z.Y.-B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A High-Resolution SAR Images Dataset for Ship Detection and Instance Segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
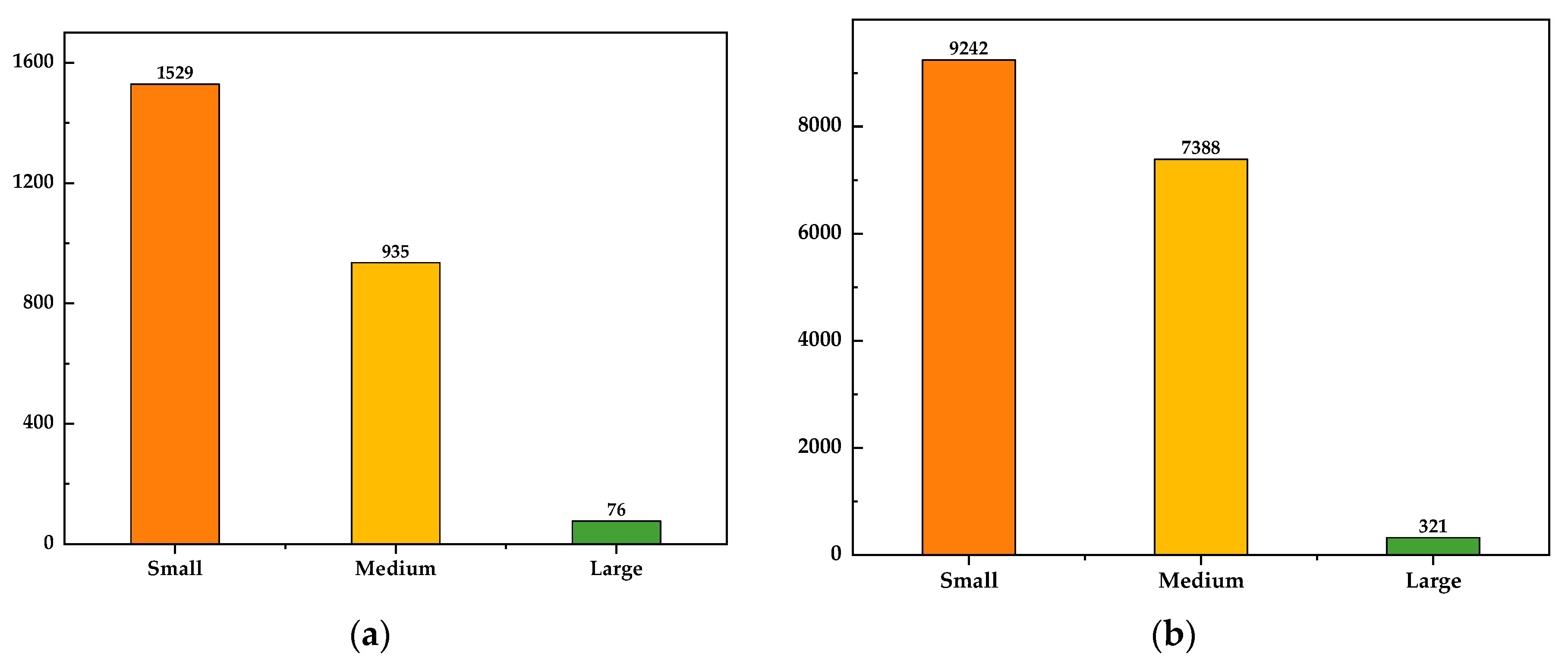{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | SSDD | HRSID |
|---|---|---|
| Polarization | HH, HV, VV, VH | HH, HV, VV |
| Image number | 1160 | 5640 |
| Ship number | 2551 | 16,965 |
| Image size (pixel) | 500 × 500, etc. | 800 × 800 |
| Resolution (m) | 1–15 | 0.5, 1, 3 |
| NO. | Improvement Strategy | P | R | mAP 0.5 | mAP 0.5:0.9 |
|---|---|---|---|---|---|
| 1 | 91.05 | 84.92 | 93.68 | 59.35 | |
| 2 | +ASPP | 94.21 | 90.48 | 96.47 | 64.27 |
| 3 | +ASPP+SA | 96.8 | 93.7 | 98.36 | 67.57 |
| 4 | +ASPP+SA+SIOU | 95.9 | 95.9 | 98.60 | 69.13 |
| Model | Dataset | Precision | Recall | mAP 0.5 |
|---|---|---|---|---|
| YOLOv7 | SSDD | 91.05 | 84.92 | 93.68 |
| HRSID | 85.52 | 74.58 | 83.64 | |
| CSD-YOLO | SSDD | 95.9 | 95.9 | 98.60 |
| HRSID | 93.22 | 80.42 | 86.10 |
| Model | Dataset | Precision | Recall | mAP 0.5 |
|---|---|---|---|---|
| Faster R-CNN | SSDD | 81.63 | 85.31 | 89.63 |
| HRSID | 88.81 | 72.57 | 77.98 | |
| FCOS | SSDD | 84.15 | 92.52 | 90.61 |
| HRSID | 75.53 | 73.79 | 77.95 | |
| YOLOv3 | SSDD | 89.11 | 85.03 | 91.54 |
| HRSID | 88.73 | 69.19 | 80.59 | |
| YOLOv5s | SSDD | 95.14 | 90.01 | 96.28 |
| HRSID | 84.69 | 75.11 | 83.34 | |
| YOLOv7 | SSDD | 91.05 | 84.92 | 93.68 |
| HRSID | 85.52 | 74.58 | 83.64 | |
| CSD-YOLO | SSDD | 95.9 | 95.9 | 98.60 |
| HRSID | 93.22 | 80.42 | 86.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sens. 2023, 15, 2071. https://doi.org/10.3390/rs15082071
Chen Z, Liu C, Filaretov VF, Yukhimets DA. Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sensing. 2023; 15(8):2071. https://doi.org/10.3390/rs15082071
Chicago/Turabian StyleChen, Zhuo, Chang Liu, V. F. Filaretov, and D. A. Yukhimets. 2023. "Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images" Remote Sensing 15, no. 8: 2071. https://doi.org/10.3390/rs15082071
APA StyleChen, Z., Liu, C., Filaretov, V. F., & Yukhimets, D. A. (2023). Multi-Scale Ship Detection Algorithm Based on YOLOv7 for Complex Scene SAR Images. Remote Sensing, 15(8), 2071. https://doi.org/10.3390/rs15082071