
Monitoring Impervious Surface Area Dynamics in Urban Areas Using Sentinel-2 Data and Improved Deeplabv3+ Model: A Case Study of Jinan City, China

Abstract
1. Introduction
2. Study Area and Dataset
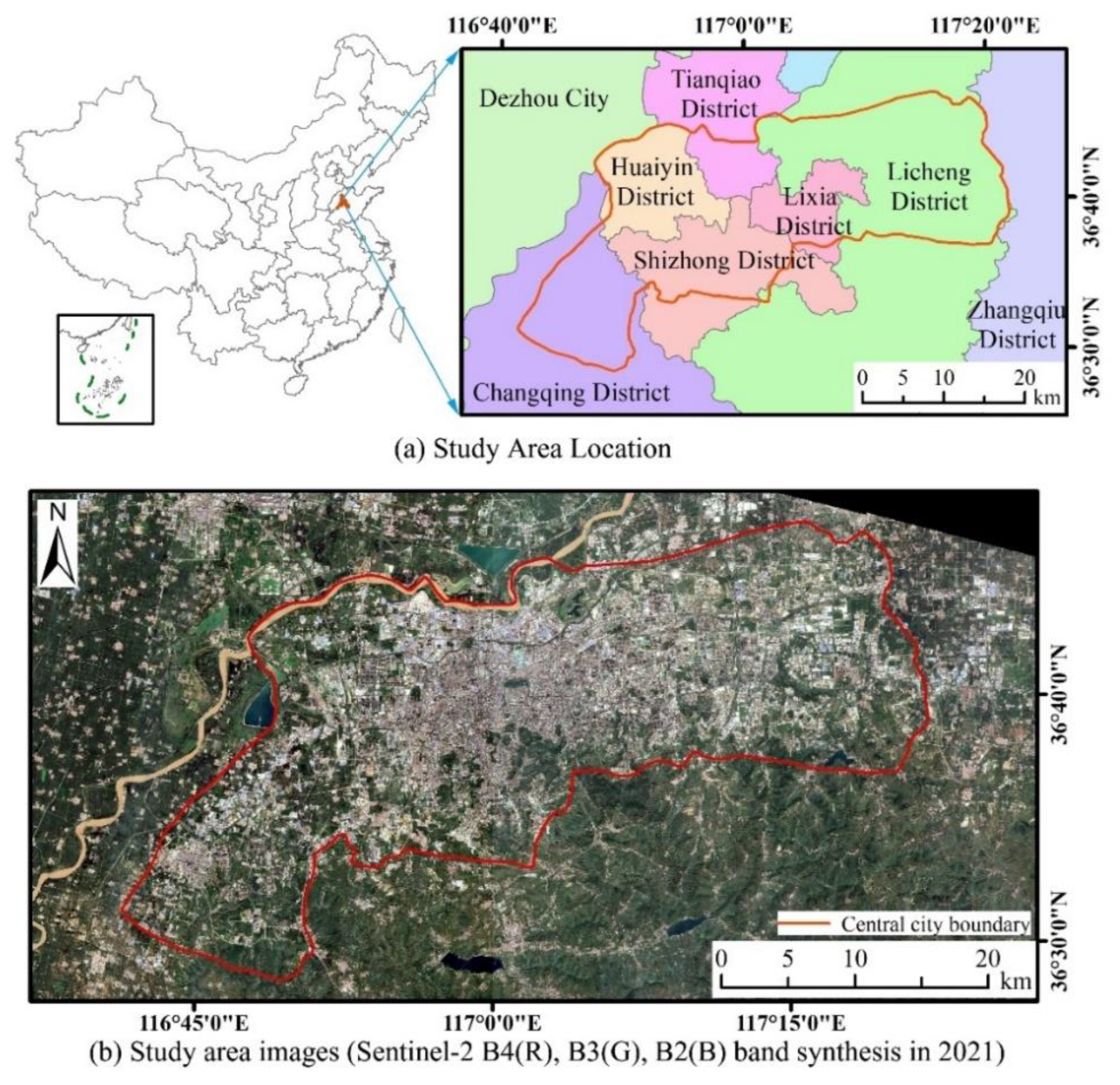
2.1. Study Area Overview
2.2. Dataset
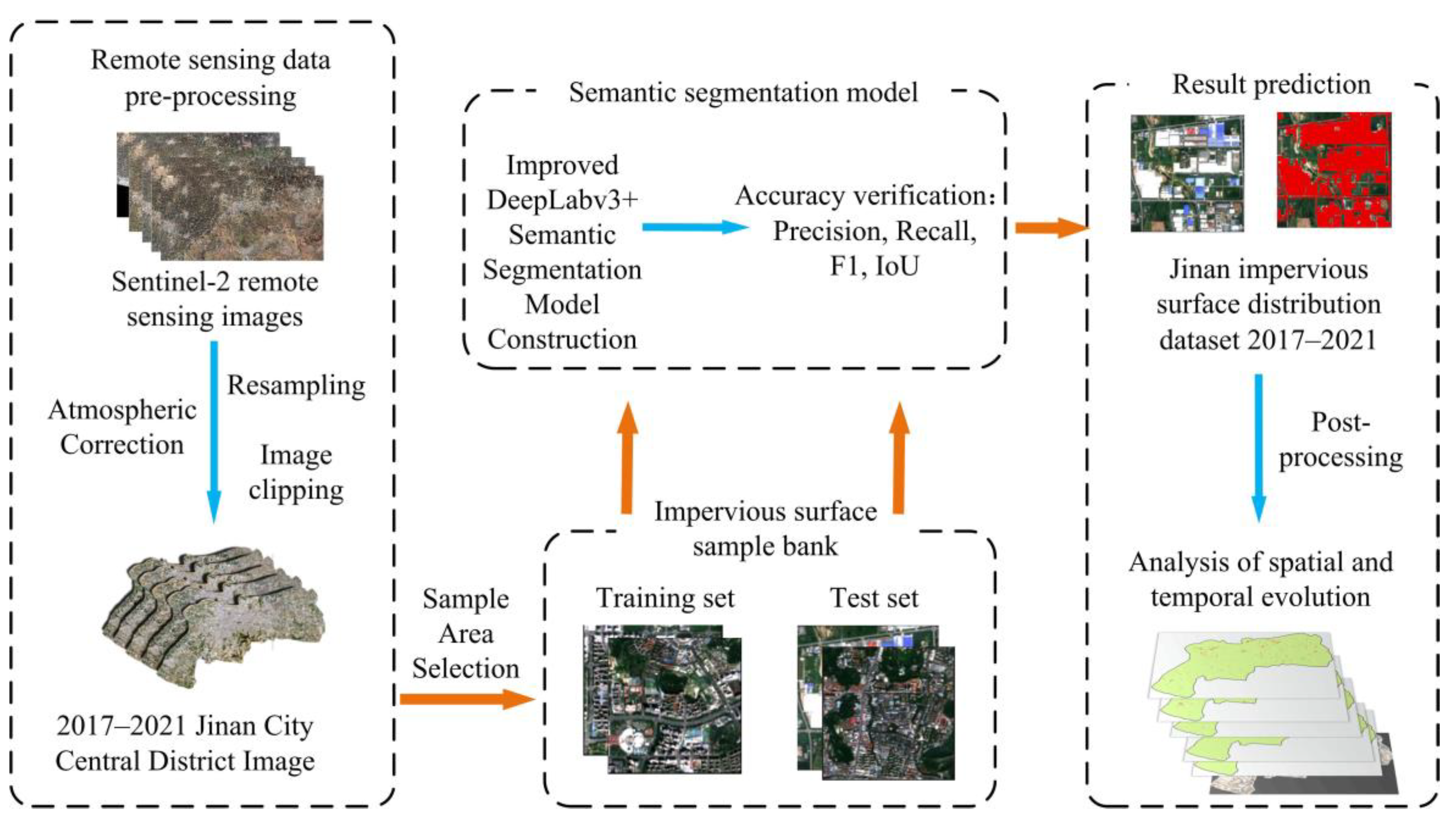
3. Methodology
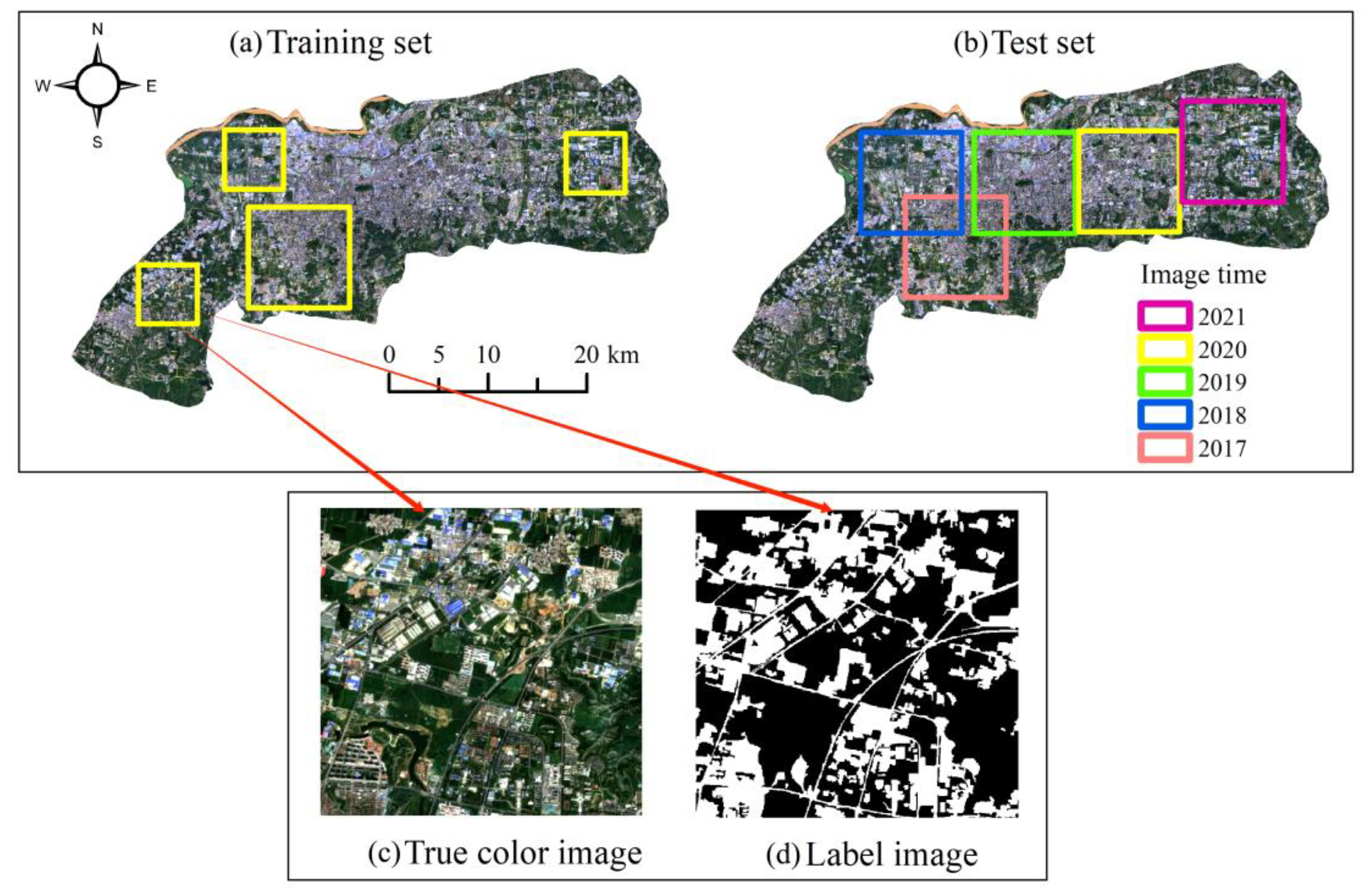
3.1. Samples
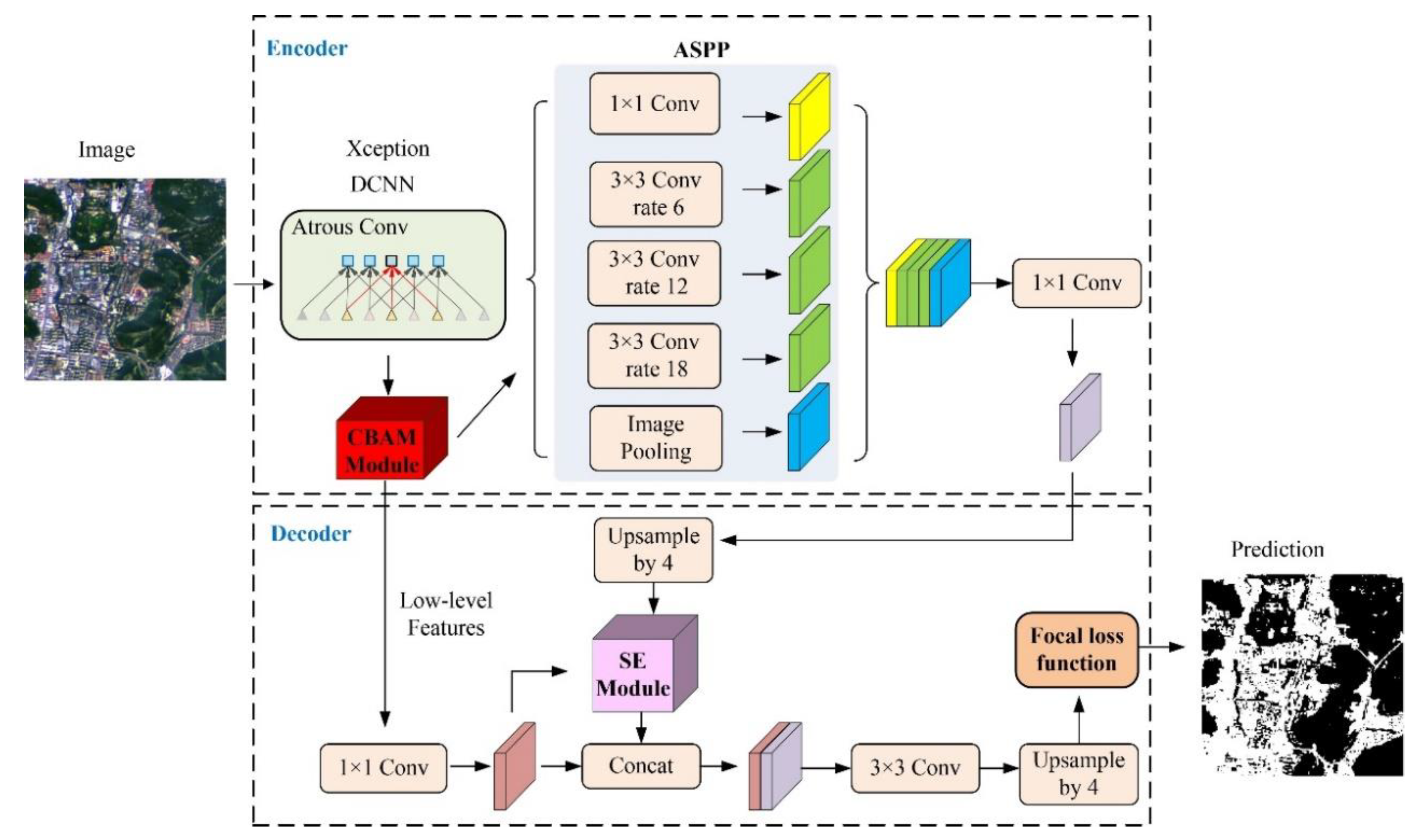
3.2. Details of Model Training
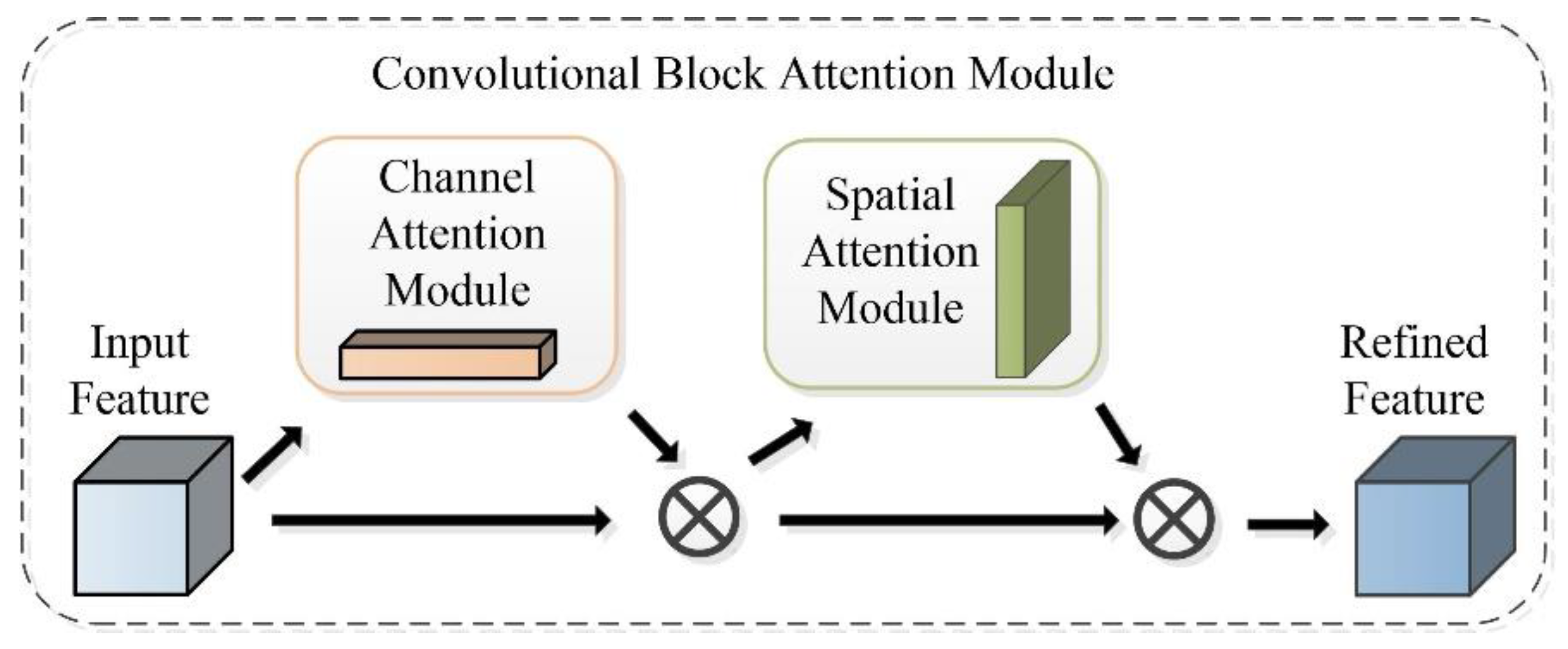
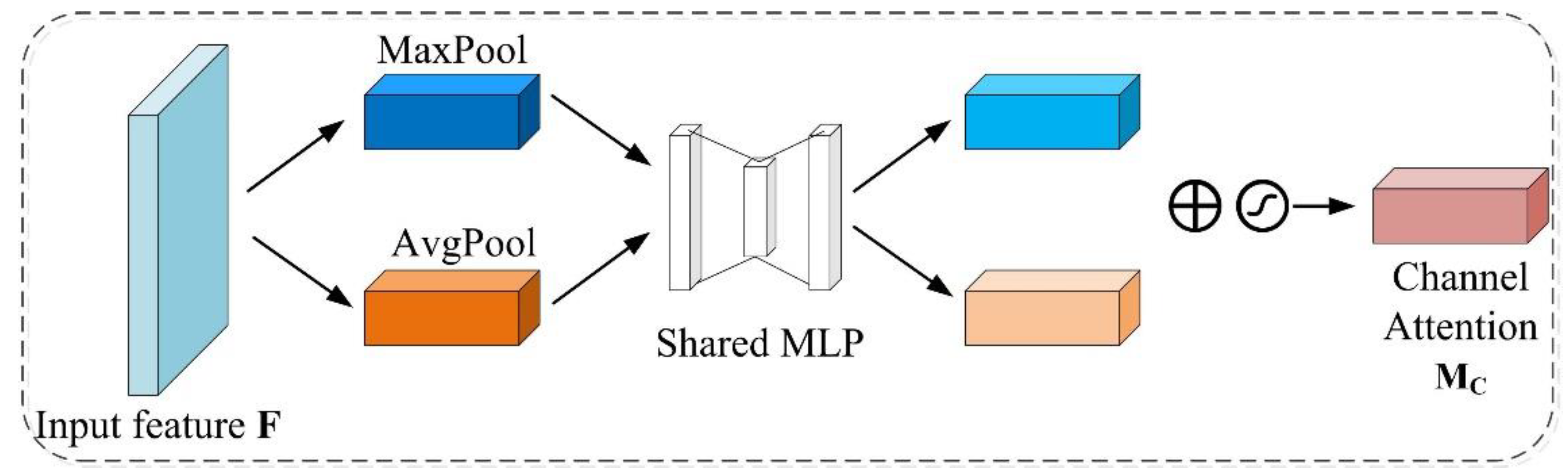
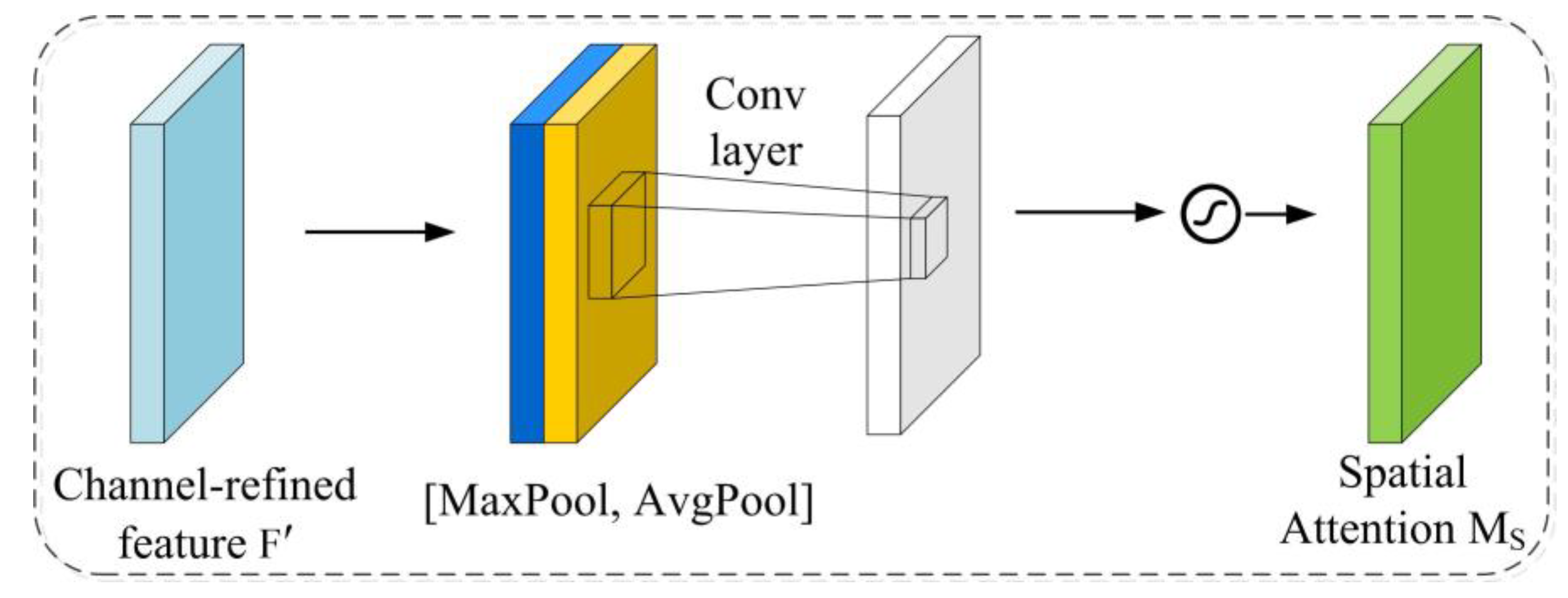
3.2.1. CBAM Module
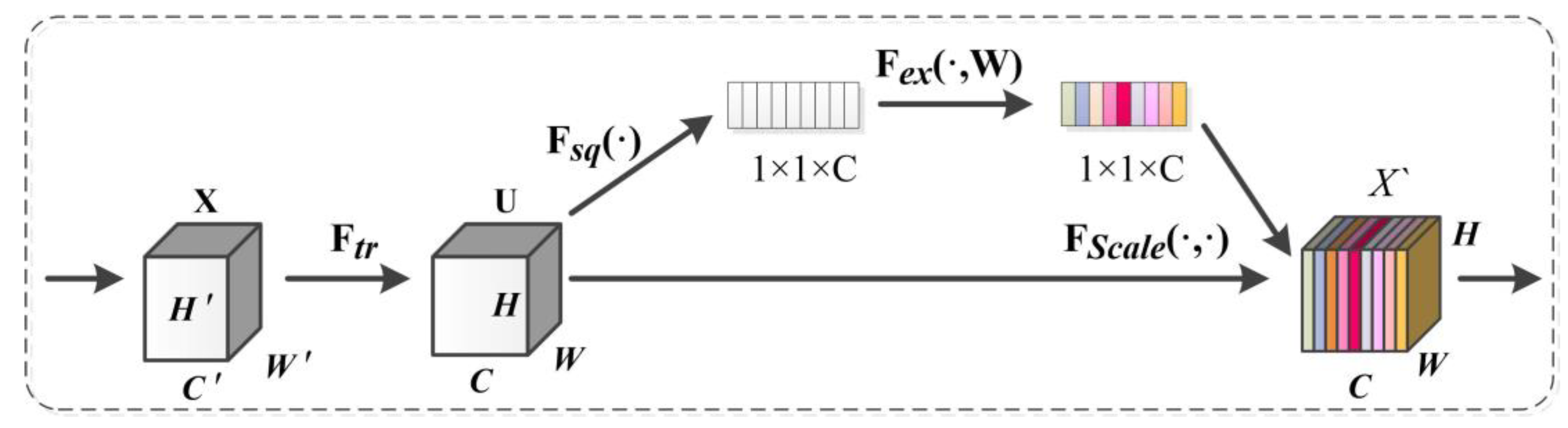
3.2.2. SE Module
3.2.3. Focal Loss Function
3.3. Accuracy Assessment
4. Results
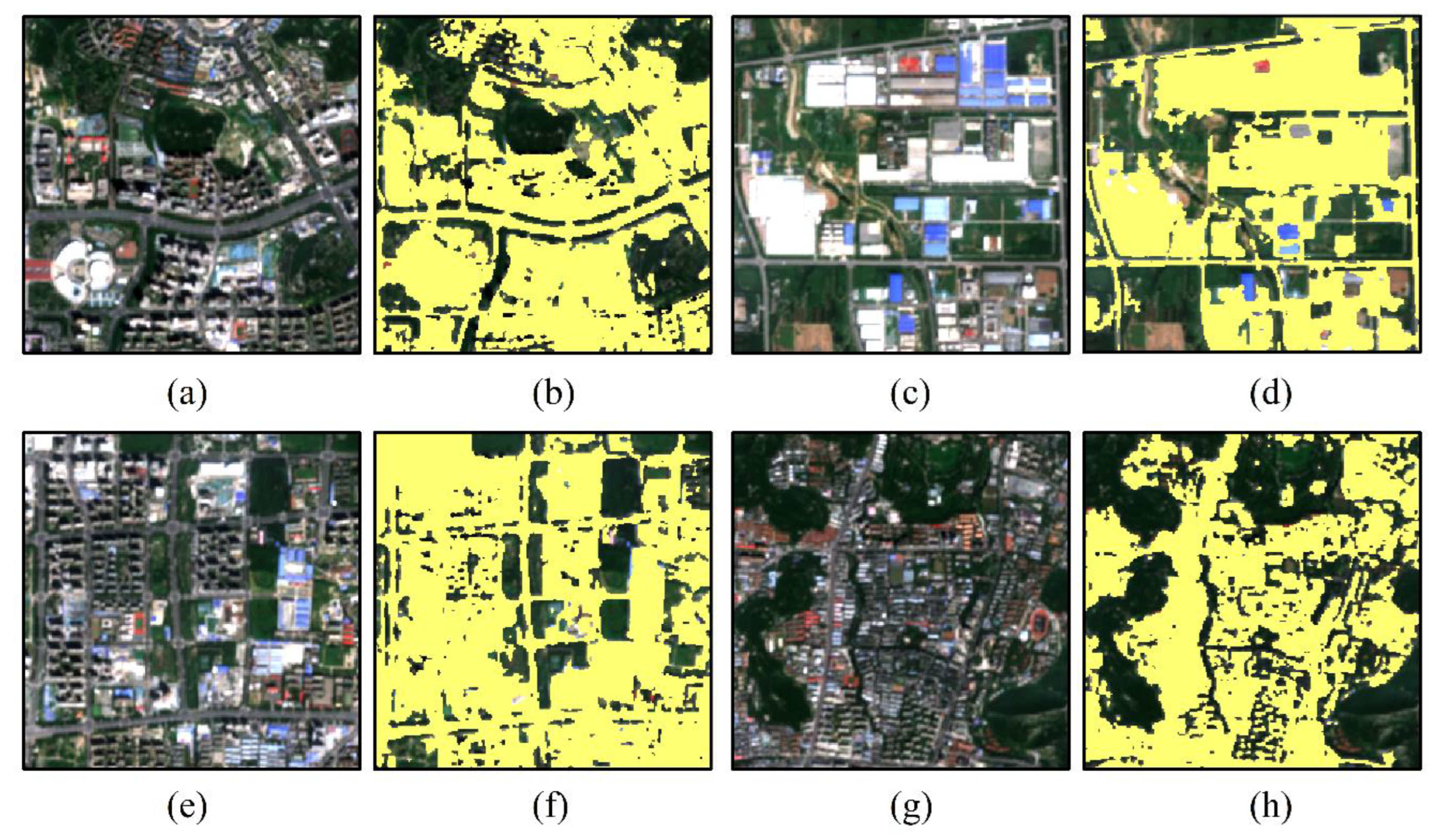
4.1. Accuracy Assessment of Result
4.2. Comparison of the Results of Traditional Classification Methods
4.3. Comparison of Different Semantic Segmentation Model
4.4. Analysis of Spatial-Temporal Variation of Impervious Surface in Jinan City
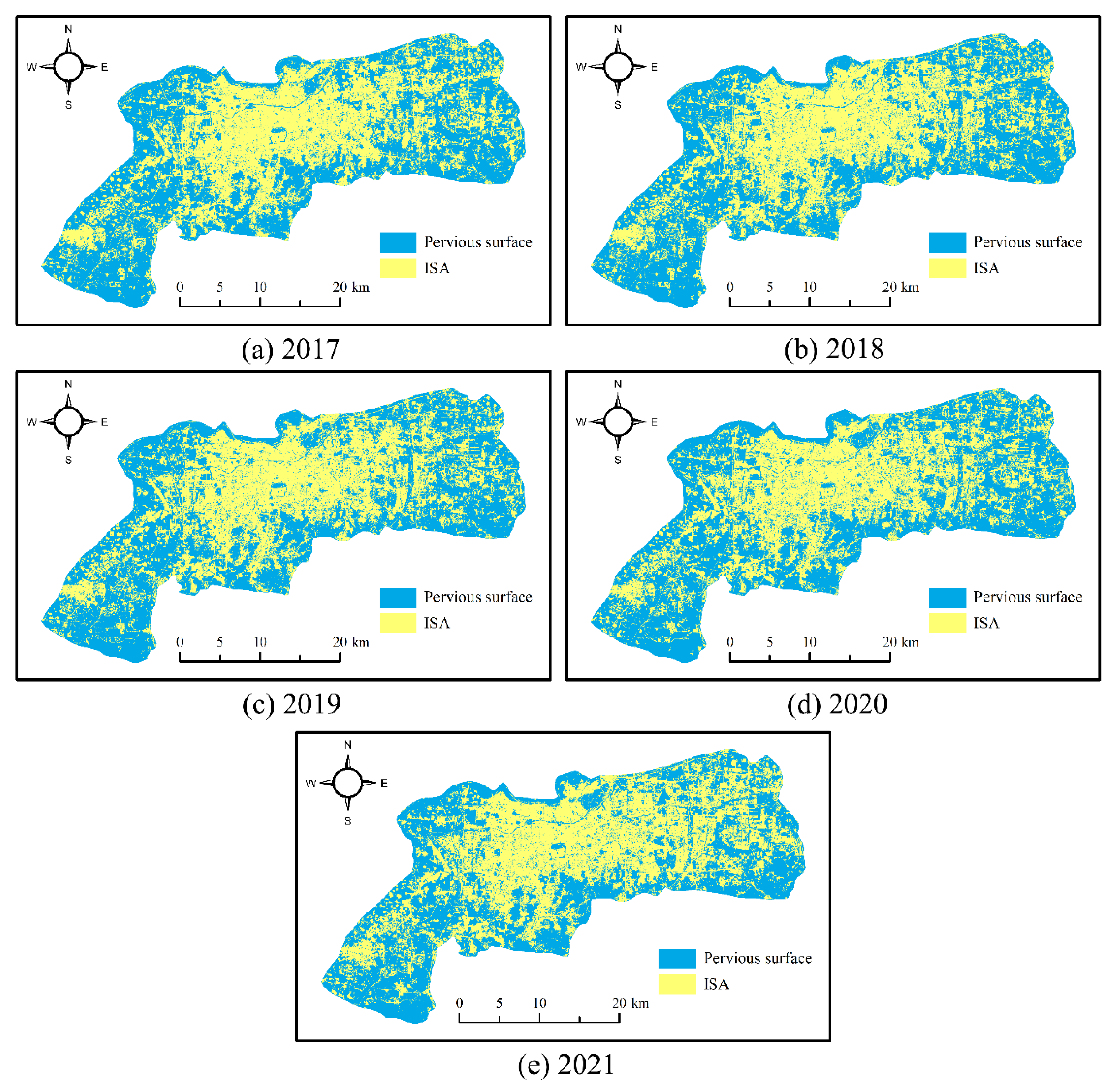
4.4.1. Time-Series ISA Mapping
4.4.2. ISA Area Change
4.4.3. Change Analysis of Landscape Pattern
5. Discussion
5.1. Impact of Including CBAM and SE Module on ISA Mapping
5.2. Comparison with Other Methods
5.3. The Reason for the Change of ISA
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Todar, S.A.S.; Attarchi, S.; Osati, K. Investigation the Seasonality Effect on Impervious Surface Detection from Sentinel-1 and Sentinel-2 Images Using Google Earth Engine. Adv. Space Res. 2021, 68, 1356–1365. [Google Scholar] [CrossRef]
- Li, W. Mapping Urban Impervious Surfaces by Using Spectral Mixture Analysis and Spectral Indices. Remote Sens. 2019, 12, 94. [Google Scholar] [CrossRef]
- Piyoosh, A.K.; Ghosh, S.K. Semi-Automatic Mapping of Anthropogenic Impervious Surfaces in an Urban/Suburban Area Using Landsat 8 Satellite Data. GISci. Remote Sens. 2017, 54, 471–494. [Google Scholar] [CrossRef]
- Chen, J.; Yang, K.; Chen, S.; Yang, C.; Zhang, S.; He, L. Enhanced Normalized Difference Index for Impervious Surface Area Estimation at the Plateau Basin Scale. J. Appl. Remote Sens. 2019, 13, 016502. [Google Scholar] [CrossRef]
- Tang, F.; Xu, H. Impervious Surface Information Extraction based on Hyperspectral Remote Sensing Imagery. Remote Sens. 2017, 9, 550. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Zhang, Y.; Liu, X. Large-Scale Impervious Surface Area Mapping and Pattern Evolution of the Yellow River Delta Using Sentinel-1/2 on the GEE. Remote Sens. 2023, 15, 136. [Google Scholar] [CrossRef]
- Shrestha, B.; Ahmad, S.; Stephen, H. Fusion of Sentinel-1 and Sentinel-2 Data in Mapping the Impervious Surfaces at City Scale. Environ. Monit. Assess. 2021, 193, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Xu, Y.; Huang, X.; Cheng, Q.; Ding, Q.; Bai, L.; Li, Y. Improving Urban Land Cover Classification with Combined Use of Sentinel-2 and Sentinel-1 Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 533. [Google Scholar] [CrossRef]
- MacLachlan, A.; Roberts, G.; Biggs, E.; Boruff, B. Subpixel Land-Cover Classification for Improved Urban Area Estimates Using Landsat. Int. J. Remote Sens. 2017, 38, 5763–5792. [Google Scholar] [CrossRef]
- Guo, W.; Lu, D.; Wu, Y.; Zhang, J. Mapping Impervious Surface Distribution with Integration of SNNP VIIRS-DNB and MODIS NDVI Data. Remote Sens. 2015, 7, 12459–12477. [Google Scholar] [CrossRef]
- Wu, C.; Murray, A.T. Estimating Impervious Surface Distribution by Spectral Mixture Analysis. Remote Sens. Environ. 2003, 84, 493–505. [Google Scholar] [CrossRef]
- Zhang, L.; Weng, Q.; Shao, Z. An Evaluation of Monthly Impervious Surface Dynamics by Fusing Landsat and MODIS Time Series in the Pearl River Delta, China, from 2000 to 2015. Remote Sens. Environ. 2017, 201, 99–114. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Ai, B.; Li, X.; Shi, Q. A Normalized Urban Areas Composite Index (NUACI) Based on Combination of DMSP-OLS and MODIS for Mapping Impervious Surface Area. Remote Sens. 2015, 7, 17168–17189. [Google Scholar] [CrossRef]
- Liu, J.; Liu, C.; Feng, Q.; Ma, Y. Subpixel Impervious Surface Estimation in the Nansi Lake Basin Using Random Forest Regression Combined with GF-5 Hyperspectral Data. J. Appl. Remote Sens. 2020, 14, 034515. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Wu, C.; Chen, X.; Gao, Y.; Xie, S.; Zhang, B. Development of a Global 30 m Impervious Surface Map Using Multisource and Multitemporal Remote Sensing Datasets with the Google Earth Engine Platform. Earth Syst. Sci. Data 2020, 12, 1625–1648. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, J.; Gu, H.; Yang, Y.; Zhang, H.; Li, H. Research Process and Trend of High-Resolution Remote Sensing Imagery Intelligent Interpretation. Natl. Remote Sens. Bull. 2021, 25, 2198–2210. [Google Scholar]
- McGlinchy, J.; Johnson, B.; Muller, B.; Joseph, M.; Diaz, J. Application of UNet Fully Convolutional Neural Network to Impervious Surface Segmentation in Urban Environment from High Resolution Satellite Imagery. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3915–3918. [Google Scholar]
- Parekh, J.R.; Poortinga, A.; Bhandari, B.; Mayer, T.; Saah, D.; Chishtie, F. Automatic Detection of Impervious Surfaces from Remotely Sensed Data Using Deep Learning. Remote Sens. 2021, 13, 3166. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban Land-Use Mapping Using a Deep Convolutional Neural Network with High Spatial Resolution Multispectral Remote Sensing Imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Liu, J.; Feng, Q.; Wang, Y.; Batsaikhan, B.; Gong, J.; Li, Y.; Liu, C.; Ma, Y. Urban Green Plastic Cover Mapping Based on VHR Remote Sensing Images and a Deep Semi-Supervised Learning Framework. ISPRS Int. J. Geo-Inf. 2020, 9, 527. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zeng, X.; Wang, Z.; Sun, X.; Chang, Z.; Gao, X. DENet: Double-Encoder Network with Feature Refinement and Region Adaption for Terrain Segmentation in Polsar Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Li, R.; Duan, C.; Zheng, S.; Zhang, C.; Atkinson, P.M. MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, C.; Atkinson, P.M.; George, C.; Wen, Z.; Diazgranados, M.; Gerard, F. Identifying and Mapping Individual Plants in a Highly Diverse High-Elevation Ecosystem Using UAV Imagery and Deep Learning. ISPRS J. Photogramm. Remote Sens. 2020, 169, 280–291. [Google Scholar] [CrossRef]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-Optical Fusion for Crop Type Mapping Using Deep Learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Seydi, S.T.; Akhoondzadeh, M.; Amani, M.; Mahdavi, S. Wildfire Damage Assessment over Australia Using Sentinel-2 Imagery and MODIS Land Cover Product within the Google Earth Engine Cloud Platform. Remote Sens. 2021, 13, 220. [Google Scholar] [CrossRef]
- Feng, Q.; Yang, J.; Zhu, D.; Liu, J.; Guo, H.; Bayartungalag, B.; Li, B. Integrating Multitemporal Sentinel-1/2 Data for Coastal Land Cover Classification Using a Multibranch Convolutional Neural Network: A Case of the Yellow River Delta. Remote Sens. 2019, 11, 1006. [Google Scholar] [CrossRef]
- Zhang, T.; Su, J.; Xu, Z.; Luo, Y.; Li, J. Sentinel-2 Satellite Imagery for Urban Land Cover Classification by Optimized Random Forest Classifier. Appl. Sci. 2021, 11, 543. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, H.; Li, Y.; Zhang, Y.; Fang, C. Mapping Urban Impervious Surface with Dual-Polarimetric SAR Data: An Improved Method. Landsc. Urban Plan. 2016, 151, 55–63. [Google Scholar] [CrossRef]
- Yanqiong, B.; Yufu, Z.; Hong, T. Semantic Segmentation Method of Road Scene Based on Deeplabv3+ and Attention Mechanism. J. Meas. Sci. Instrum. 2021, 12, 412–421. [Google Scholar]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention deeplabv3+: Multi-level Context Attention Mechanism for Skin Lesion Segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 251–266. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Feng, Q.; Zhu, D.; Yang, J.; Li, B. Multisource Hyperspectral and Lidar Data Fusion for Urban Land-Use Mapping Based on a Modified Two-Branch Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2019, 8, 28. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Y.; Cui, W.-G.; Guo, Y.-Z.; Huang, H.; Hu, Z.-Y. Epileptic Seizure Detection in EEG Signals Using a Unified Temporal-Spectral Squeeze-and-Excitation Network. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 782–794. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Nam, H.; Ha, J.-W.; Kim, J. Dual Attention Networks for Multimodal Reasoning and Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 299–307. [Google Scholar]
- Fu, J.; Liu, J.; Jiang, J.; Li, Y.; Bao, Y.; Lu, H. Scene Segmentation with Dual Relation-Aware Attention Network. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2547–2560. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.-S.; Li, J.; Wong, A. Squeeze-and-Attention Networks for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13065–13074. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gu, X.; Gao, X.; Ma, H.; Shi, F.; Liu, X.; Cao, X. Comparison of Machine Learning Methods for Land Use/Land Cover Classification in the Complicated Terrain Regions. Remote Sens. Technol. Appl. 2019, 34, 57–67. [Google Scholar]
- Wu, Q.; Zhong, R.; Zhao, W.; Song, K.; Du, L. Land-Cover Classification Using GF-2 Images and Airborne Lidar Data Based on Random Forest. Int. J. Remote Sens. 2019, 40, 2410–2426. [Google Scholar] [CrossRef]
- Singh, S.K.; Srivastava, P.K.; Szabó, S.; Petropoulos, G.P.; Gupta, M.; Islam, T. Landscape Transform and Spatial Metrics for Mapping Spatiotemporal Land Cover Dynamics Using Earth Observation Data-Sets. Geocarto Int. 2017, 32, 113–127. [Google Scholar] [CrossRef]
- Aksu, G.A.; Tağıl, Ş.; Musaoğlu, N.; Canatanoğlu, E.S.; Uzun, A. Landscape Ecological Evaluation of Cultural Patterns for the Istanbul Urban Landscape. Sustainability 2022, 14, 16030. [Google Scholar] [CrossRef]
- Ozcan, O.; Aksu, G.A.; Erten, E.; Musaoglu, N.; Çetin, M. Degradation Monitoring in Silvo-Pastoral Systems: A Case Study of the Mediterranean Region of Turkey. Adv. Space Res. 2019, 63, 160–171. [Google Scholar] [CrossRef]
- Leitao, A.B.; Ahern, J. Applying Landscape Ecological Concepts and Metrics in Sustainable Landscape Planning. Landsc. Urban Plan. 2002, 59, 65–93. [Google Scholar] [CrossRef]
- Chen, B.; Feng, Q.; Niu, B.; Yan, F.; Gao, B.; Yang, J.; Gong, J.; Liu, J. Multi-Modal Fusion of Satellite and Street-View Images for Urban Village Classification Based on a Dual-Branch Deep Neural Network. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102794. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imaging Date | Imaging Satellite | Product Level | Cloud Volume/% |
|---|---|---|---|
| 7 September 2017 | S2B | L1C | 0 |
| 7 September 2018 | S2A | L1C | 0 |
| 18 August 2019 | S2B | L2A | 0.72 |
| 1 September 2020 | S2B | L2A | 0.95 |
| 11 September 2021 | S2A | L2A | 0.88 |
| Method | Precision (%) | Recall (%) | IoU (%) | F1 (%) |
|---|---|---|---|---|
| The proposed model | 82.24 | 92.38 | 77.01 | 87 |
| Method | Precision (%) | Recall (%) | IoU (%) | F1 (%) |
|---|---|---|---|---|
| The proposed model | 82.24 | 92.38 | 77.01 | 87 |
| RF | 79 | 70 | 59.16 | 74 |
| SVM | 82 | 65 | 57.02 | 73 |
| Method | Precision/% | Recall/% | F1 | IoU/% |
|---|---|---|---|---|
| FCN8 | 83.46 | 84.47 | 0.84 | 72.36 |
| U-Net | 84.33 | 84.66 | 0.84 | 73.15 |
| Deeplabv3+ | 82.06 | 89.08 | 0.85 | 74.56 |
| Improved Deeplabv3+ | 82.24 | 92.38 | 0.87 | 77.01 |
| Year | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|
| Area (km2) | 465.02 | 467.28 | 461.90 | 447.15 | 496.87 |
| Area Percentage (%) | 45.80 | 46.91 | 45.49 | 44.04 | 48.93 |
| Year | NP | PD | AREA_MN | LSI | LPI | AI | COHESION |
|---|---|---|---|---|---|---|---|
| 2017 | 7643 | 7.53 | 6.08 | 106.68 | 40.97 | 95.09 | 99.961 |
| 2018 | 7418 | 7.31 | 6.30 | 112.03 | 39.51 | 94.86 | 99.958 |
| 2019 | 8473 | 8.34 | 5.45 | 116.47 | 39.07 | 94.62 | 99.957 |
| 2020 | 7962 | 7.84 | 5.62 | 120.59 | 37.51 | 94.34 | 99.956 |
| 2021 | 7815 | 7.70 | 6.36 | 114.23 | 44.24 | 94.92 | 99.968 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Zhang, Y.; Liu, C.; Liu, X. Monitoring Impervious Surface Area Dynamics in Urban Areas Using Sentinel-2 Data and Improved Deeplabv3+ Model: A Case Study of Jinan City, China. Remote Sens. 2023, 15, 1976. https://doi.org/10.3390/rs15081976
Liu J, Zhang Y, Liu C, Liu X. Monitoring Impervious Surface Area Dynamics in Urban Areas Using Sentinel-2 Data and Improved Deeplabv3+ Model: A Case Study of Jinan City, China. Remote Sensing. 2023; 15(8):1976. https://doi.org/10.3390/rs15081976
Chicago/Turabian StyleLiu, Jiantao, Yan Zhang, Chunting Liu, and Xiaoqian Liu. 2023. "Monitoring Impervious Surface Area Dynamics in Urban Areas Using Sentinel-2 Data and Improved Deeplabv3+ Model: A Case Study of Jinan City, China" Remote Sensing 15, no. 8: 1976. https://doi.org/10.3390/rs15081976
APA StyleLiu, J., Zhang, Y., Liu, C., & Liu, X. (2023). Monitoring Impervious Surface Area Dynamics in Urban Areas Using Sentinel-2 Data and Improved Deeplabv3+ Model: A Case Study of Jinan City, China. Remote Sensing, 15(8), 1976. https://doi.org/10.3390/rs15081976