




R-PCR: Recurrent Point Cloud Registration Using High-Order Markov Decision


Abstract
1. Introduction
- We introduce R-PCR, a novel deep network architecture for point cloud registration that effectively fuses independent global features and integrates high-order Markov decision into iterative point registration.
- We propose a simple yet effective cross-concatenation module and large-receptive network to enhance the feature fusion between pairwise point clouds, improving the expression ability of global features. This allows more accurate registration, particularly for noise-afflicted data, and ensures stable convergence.
- R-PCR shows superior performance on several standard point cloud registration datasets, including synthetic and real data, as well as large urban data. Our method outperforms global-based registration baselines by a large margin.
2. Related Work
2.1. Point Cloud Registration
2.2. Iterative Refinement
2.3. Recurrent Neural Networks
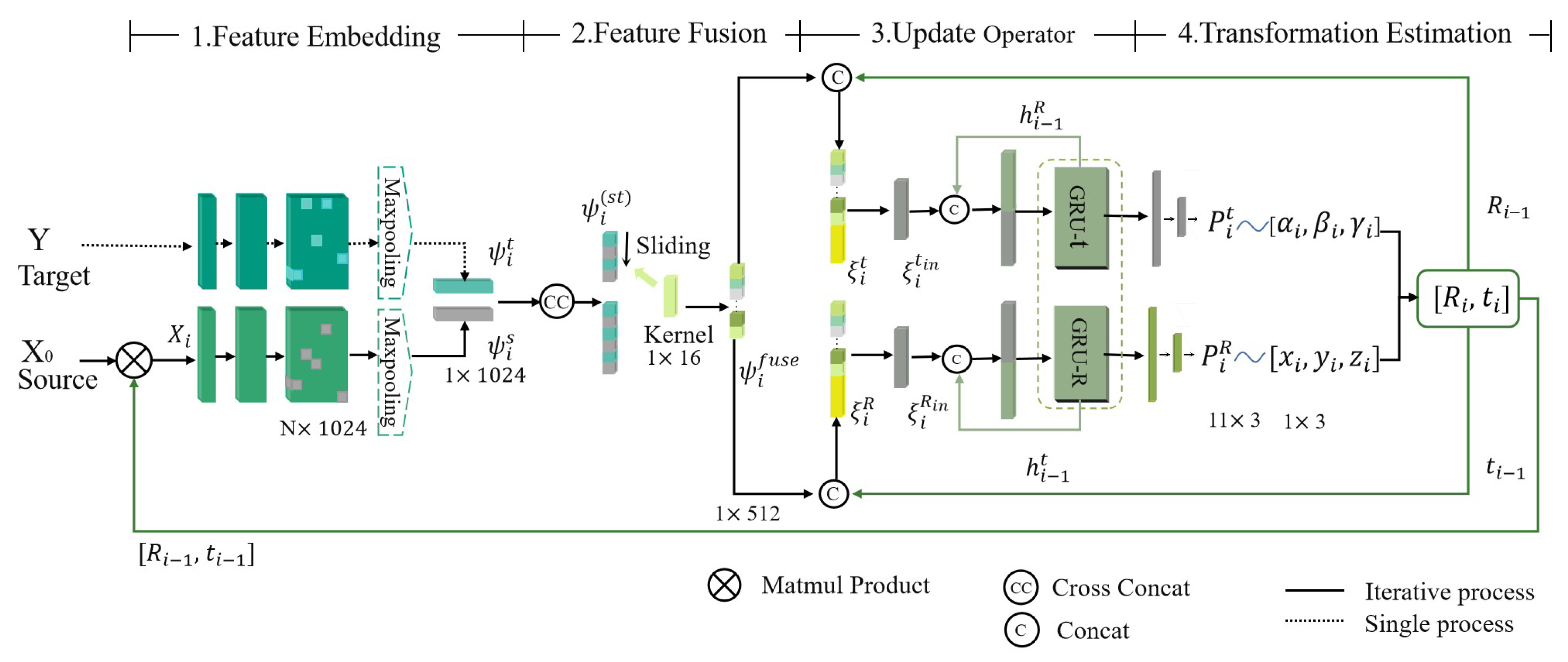
3. Approach
3.1. Preliminaries
3.2. Feature Embedding
3.3. Feature Fusion
3.4. Recurrent Refinement
3.4.1. Disentangled Transformation
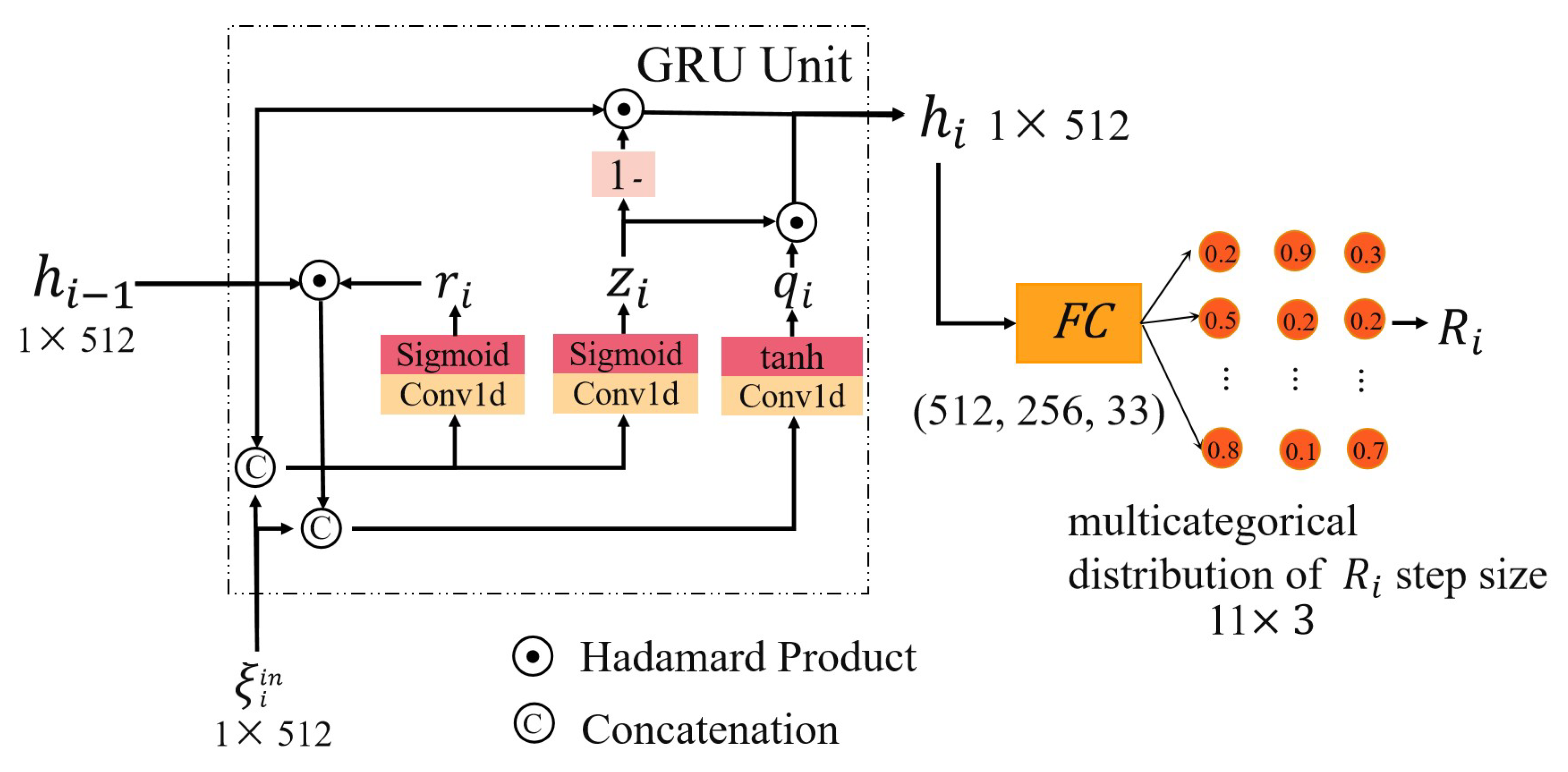
3.4.2. Update Operator
3.4.3. Transformation Estimation
4. Experiments
4.1. Datasets
4.2. Implement Detail
4.3. Baseline Methods
4.4. Metrics
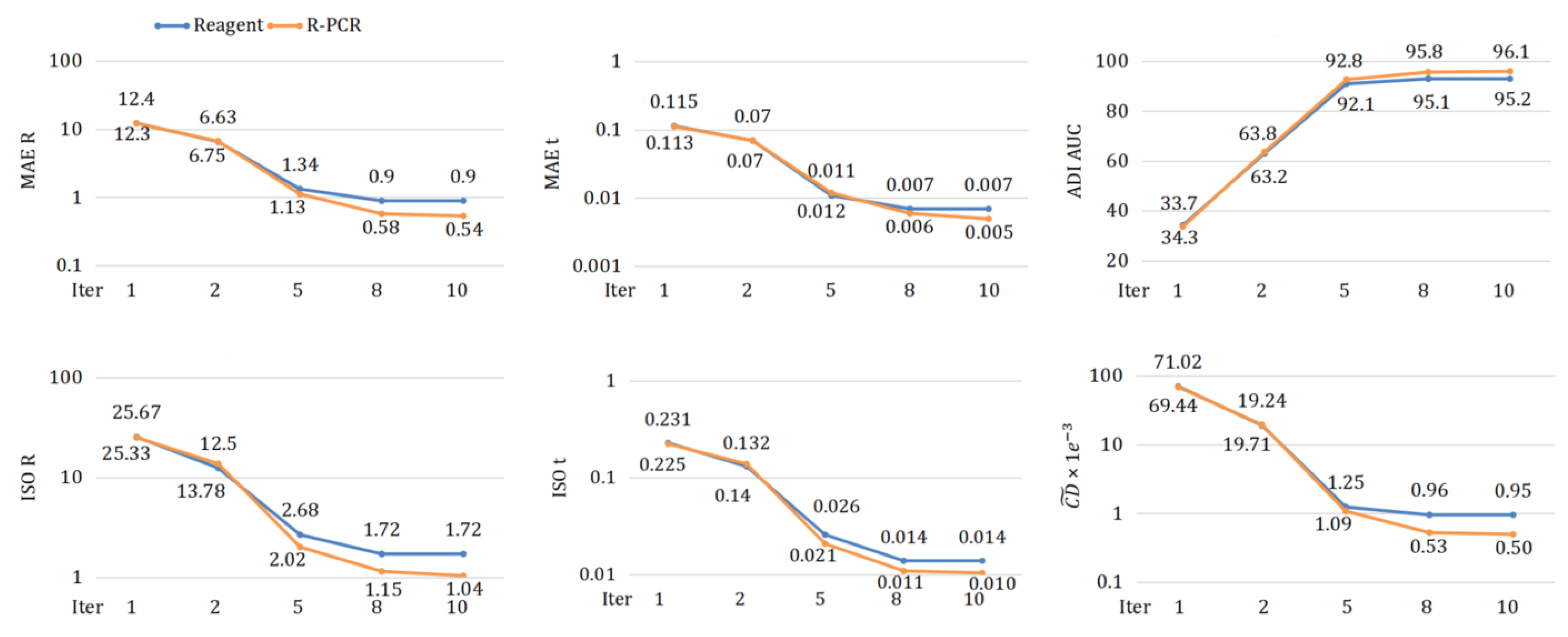
4.5. Results
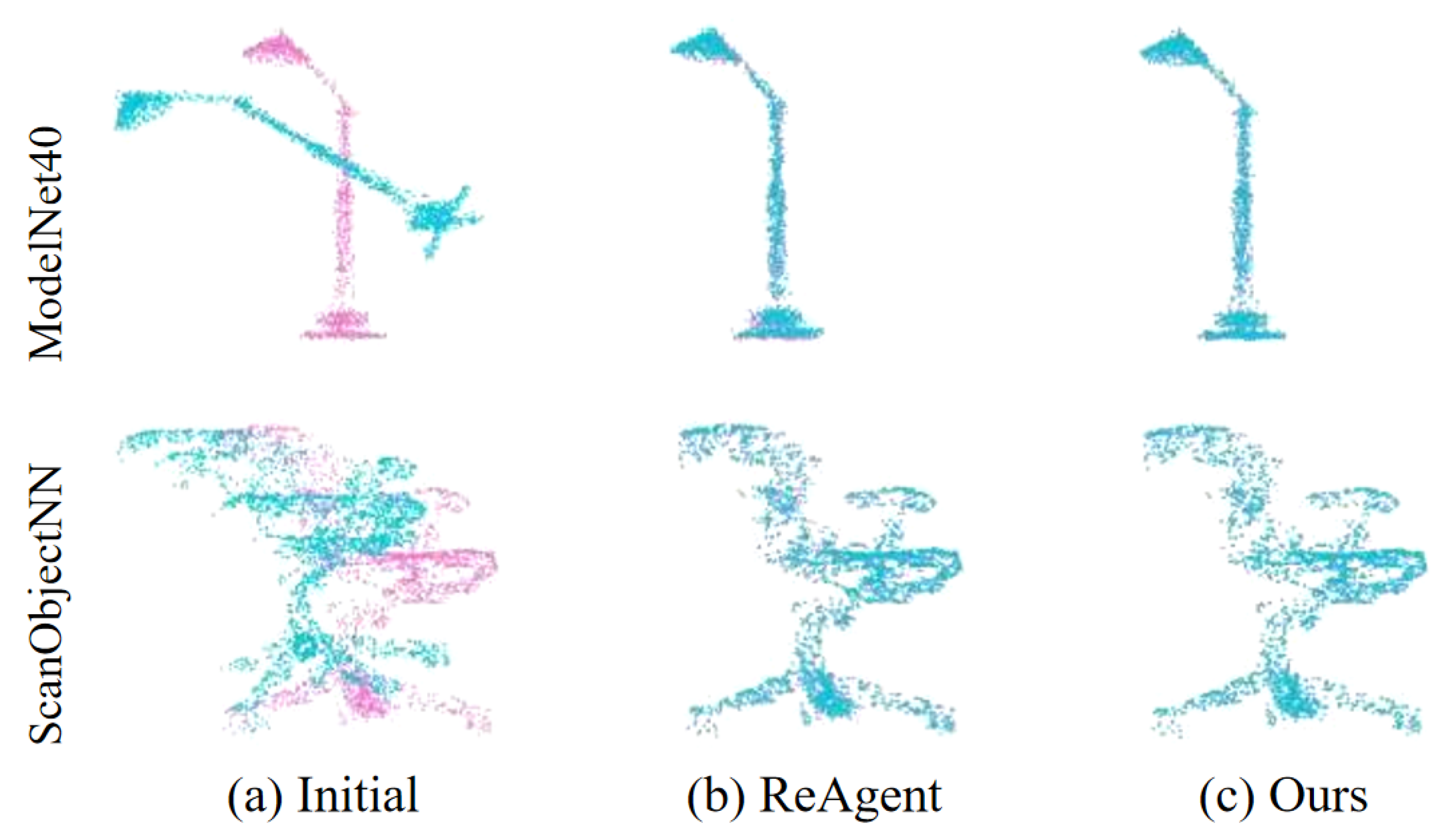
4.5.1. Synthetic Dataset (ModelNet40)
4.5.2. Indoor Dataset (ScanObjectNN)
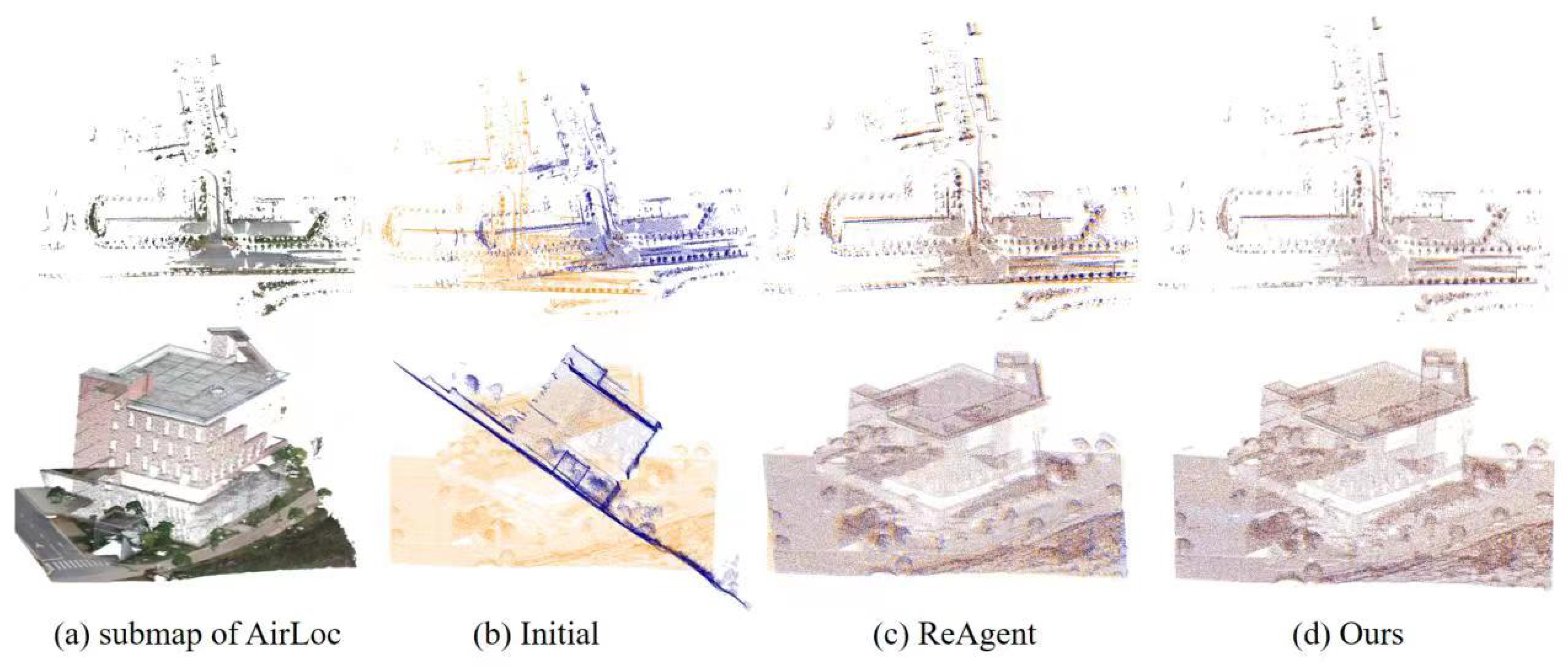
4.5.3. Outdoor Dataset (AirLoc)
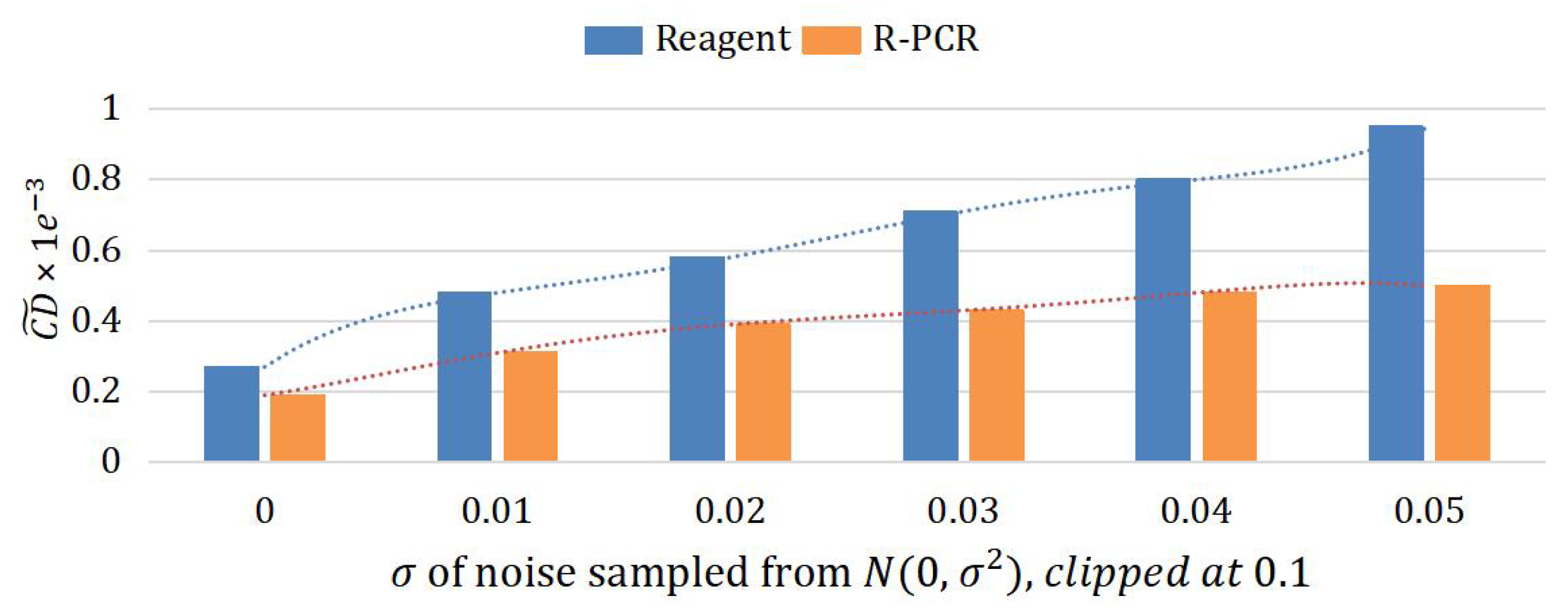
4.6. Ablation
4.6.1. Recurrent Architecture
4.6.2. Feature Fusion Module
4.6.3. Global Feature Encoding
4.6.4. Sliding Window Size
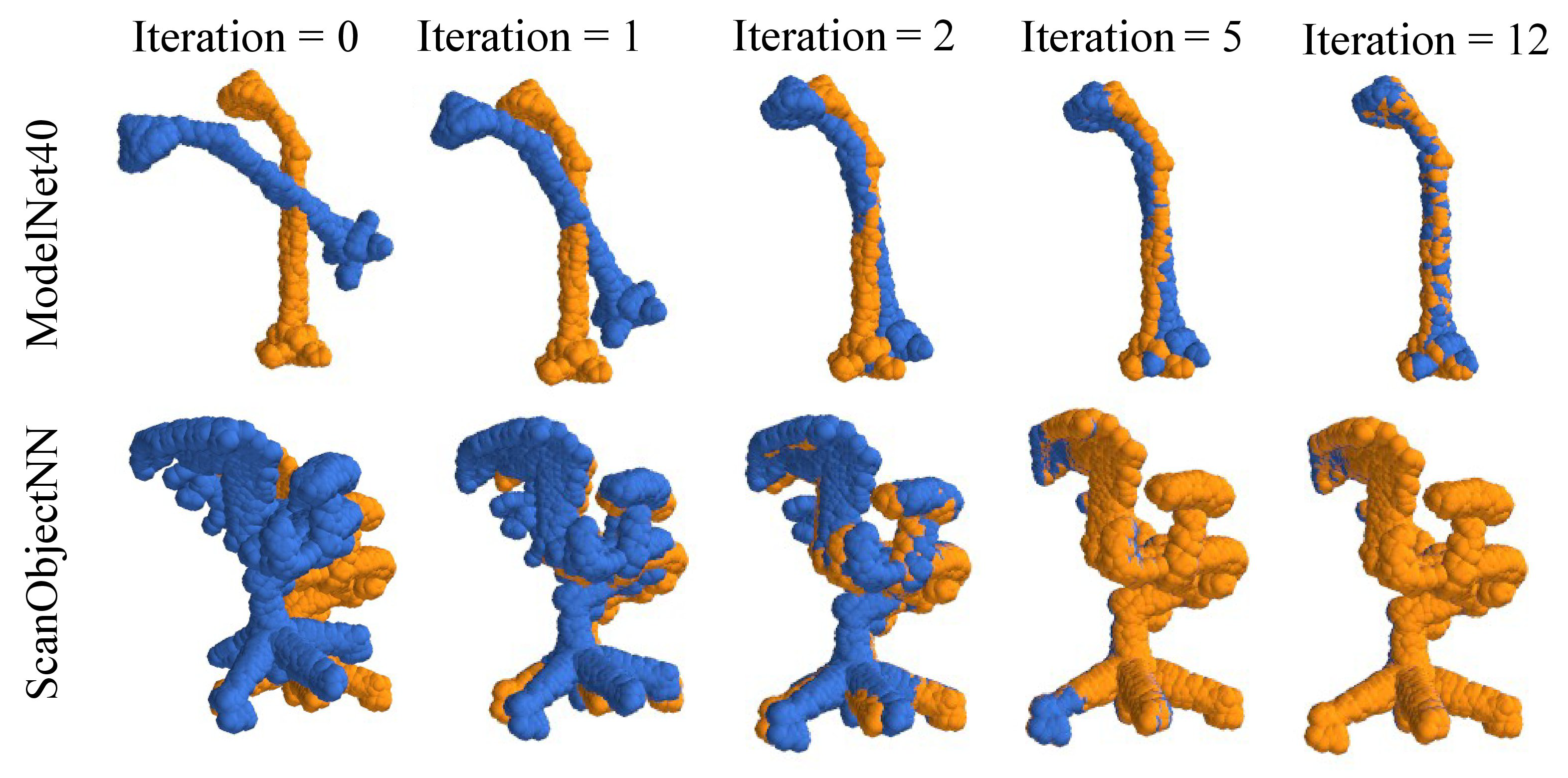
4.6.5. Iterative Updates
5. Discussion
- Efficient feature extraction: R-PCR efficiently fuses independent global features using a PointNet network as an embedding function, which extracts global geometry information by a Siamese structure for source and target point clouds separately. Based on a powerful extractor, our model could learn the feature representations and transformation parameters jointly in an end-to-end fashion.
- Effective global feature fusion: The proposed lightweight cross-concatenation module and large-receptive network merge information between pairwise point clouds, improving the expression ability of global features and introducing possible implicit correspondence, which leads robustness to noise, missing data and could handle a wide range of scenarios.
- High-order Markov decision integration: R-PCR integrates high-order Markov decision into iterative point registration using a recurrent GRU-based update operator. This operator brings high-order state from the previous movement, and the interrelated constraints between substeps model the high-dimensional state and action spaces, making the approach more expressive and better able to model complex registration tasks, particularly noise-afflicted data.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Komorowski, J.; Wysoczanska, M.; Trzcinski, T. EgoNN: Egocentric Neural Network for Point Cloud Based 6DoF Relocalization at the City Scale. IEEE Robot. Autom. Lett. 2021, 7, 722–729. [Google Scholar] [CrossRef]
- Mahmood, B.; Han, S.; Lee, D.E. BIM-based registration and localization of 3D point clouds of indoor scenes using geometric features for augmented reality. Remote. Sens. 2020, 12, 2302. [Google Scholar] [CrossRef]
- Takimoto, R.Y.; Tsuzuki, M.d.S.G.; Vogelaar, R.; de Castro Martins, T.; Sato, A.K.; Iwao, Y.; Gotoh, T.; Kagei, S. 3D reconstruction and multiple point cloud registration using a low precision RGB-D sensor. Mechatronics 2016, 35, 11–22. [Google Scholar] [CrossRef]
- Bai, X.; Luo, Z.; Zhou, L.; Fu, H.; Quan, L.; Tai, C.L. D3Feat: Joint Learning of Dense Detection and Description of 3D Local Features. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6358–6366. [Google Scholar] [CrossRef]
- Ao, S.; Hu, Q.; Yang, B.; Markham, A.; Guo, Y. Spinnet: Learning a general surface descriptor for 3d point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11753–11762. [Google Scholar]
- Huang, S.; Gojcic, Z.; Usvyatsov, M.; Wieser, A.; Schindler, K. PREDATOR: Registration of 3D Point Clouds with Low Overlap. Comput. Vis. Pattern Recognit. 2020, 4267–4276. [Google Scholar]
- Choy, C.; Park, J.; Koltun, V. Fully convolutional geometric features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8958–8966. [Google Scholar]
- Wang, H.; Liu, X.; Kang, W.; Yan, Z.; Wang, B.; Ning, Q. Multi-features guidance network for partial-to-partial point cloud registration. Neural Comput. Appl. 2022, 34, 1623–1634. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, H.; Wang, C.; Guo, Y.; Peng, Y.; Xu, K. Geometric transformer for fast and robust point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11143–11152. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Yew, Z.J.; Lee, G.H. RPM-Net: Robust Point Matching Using Learned Features. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11821–11830. [Google Scholar] [CrossRef]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. Pcrnet: Point cloud registration network using pointnet encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. PointNetLK: Robust & Efficient Point Cloud Registration Using PointNet. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7156–7165. [Google Scholar] [CrossRef]
- Xu, H.; Liu, S.; Wang, G.; Liu, G.; Zeng, B. OMNet: Learning Overlapping Mask for Partial-to-Partial Point Cloud Registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 3132–3141. [Google Scholar]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Dhagat, A.; Srivatsan, R.A.; Lucey, S.; Choset, H. One Framework to Register Them All: PointNet Encoding for Point Cloud Alignment. arXiv Comput. Vis. Pattern Recognit. 2019, arXiv:1912.05766. [Google Scholar]
- Li, X.; Pontes, J.K.; Lucey, S. Deterministic PointNetLK for Generalized Registration. arXiv 2020, arXiv:2008.09527. [Google Scholar]
- Yuan, W.; Held, D.; Mertz, C.; Hebert, M. Iterative Transformer Network for 3D Point Cloud. arXiv Comput. Vis. Pattern Recognit. 2018, arXiv:1811.11209. [Google Scholar]
- Bauer, D.; Patten, T.; Vincze, M. Reagent: Point cloud registration using imitation and reinforcement learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14586–14594. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Boston, MA, USA, 12–15 November 1992; Spie: Paris, France, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Censi, A. An ICP variant using a point-to-line metric. Int. Conf. Robot. Autom. 2008.
- Forstner, W.; Khoshelham, K. Efficient and accurate registration of point clouds with plane to plane correspondences. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2165–2173. [Google Scholar]
- Iglesias, J.P.; Olsson, C.; Kahl, F. Global optimality for point set registration using semidefinite programming. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8287–8295. [Google Scholar]
- Liang, L. Precise iterative closest point algorithm for RGB-D data registration with noise and outliers. Neurocomputing 2020, 399, 361–368. [Google Scholar] [CrossRef]
- Ramalingam, S.; Taguchi, Y. A Theory of Minimal 3D Point to 3D Plane Registration and Its Generalization. Int. J. Comput. Vis. 2013, 102, 73–90. [Google Scholar] [CrossRef]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Wieser, A. The Perfect Match: 3D Point Cloud Matching With Smoothed Densities. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5540–5549. [Google Scholar] [CrossRef]
- Deng, H.; Birdal, T.; Ilic, S. PPFNet: Global Context Aware Local Features for Robust 3D Point Matching. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 195–205. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Huang, X.; Mei, G.; Zhang, J. Feature-metric Registration: A Fast Semi-supervised Approach for Robust Point Cloud Registration without Correspondences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhu, M.; Ghaffari, M.; Peng, H. Correspondence-Free Point Cloud Registration with SO(3)-Equivariant Implicit Shape Representations. arXiv Comput. Vis. Pattern Recognit. 2021. [Google Scholar]
- Luo, S.; Mou, W.; Althoefer, K.; Liu, H. Iterative closest labeled point for tactile object shape recognition. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3137–3142. [Google Scholar]
- Peters, M.E.; Ammar, W.; Bhagavatula, C.; Power, R. Semi-supervised sequence tagging with bidirectional language models. arXiv 2017, arXiv:1705.00108. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention is all you need in speech separation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, OT, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 21–25. [Google Scholar]
- Fan, H.; Zhu, L.; Yang, Y. Cubic LSTMs for video prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8263–8270. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3595–3603. [Google Scholar]
- Alley, E.C.; Khimulya, G.; Biswas, S.; AlQuraishi, M.; Church, G.M. Unified rational protein engineering with sequence-based deep representation learning. Nat. Methods 2019, 16, 1315–1322. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 402–419. [Google Scholar]
- Villegas, R.; Yang, J.; Zou, Y.; Sohn, S.; Lin, X.; Lee, H. Learning to generate long-term future via hierarchical prediction. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Westminster, UK, 2017; pp. 3560–3569. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Uy, M.A.; Pham, Q.H.; Hua, B.S.; Nguyen, T.; Yeung, S.K. Revisiting Point Cloud Classification: A New Benchmark Dataset and Classification Model on Real-World Data. Int. Conf. Comput. Vis. 2019. [Google Scholar]
- Yan, S.; Cheng, X.; Liu, Y.; Zhu, J.; Wu, R.; Liu, Y.; Zhang, M. Render-and-Compare: Cross-View 6 DoF Localization from Noisy Prior. arXiv 2023, arXiv:2302.06287. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. CoRR 2017, abs/1711.05101. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 766–782. [Google Scholar]
- Wang, Y.; Solomon, J. Deep Closest Point: Learning Representations for Point Cloud Registration. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3522–3531. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 548–562. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Held-Out Models | Held-Out Categories | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE (↓) | ISO (↓) | ADI (↑) | MAE (↓) | ISO (↓) | ADI (↑) | (↓) | ||||||
| R | t | R | t | AUC | R | t | R | t | AUC | |||
| ICP | 3.59 | 0.028 | 7.81 | 0.063 | 90.6 | 3.49 | 3.41 | 0.024 | 7.00 | 0.051 | 90.5 | 3.84 |
| FGR+ | 2.52 | 0.016 | 4.37 | 0.034 | 92.1 | 1.59 | 1.68 | 0.011 | 2.94 | 0.024 | 92.7 | 1.24 |
| DCP-v2 | 3.48 | 0.025 | 7.01 | 0.052 | 85.8 | 2.52 | 4.51 | 0.031 | 8.89 | 0.064 | 82.3 | 3.74 |
| PNLK | 1.64 | 0.012 | 3.33 | 0.026 | 93.0 | 1.03 | 1.61 | 0.013 | 3.22 | 0.028 | 91.6 | 1.51 |
| ReAgent | 1.46 | 0.011 | 2.82 | 0.023 | 94.5 | 0.75 | 1.38 | 0.010 | 2.59 | 0.020 | 93.5 | 0.95 |
| Ours | 0.65 | 0.007 | 2.06 | 0.016 | 96.1 | 0.66 | 0.53 | 0.006 | 1.65 | 0.013 | 96 | 0.72 |
| ScanObjectNN | ||||||
|---|---|---|---|---|---|---|
| MAE (↓) | ISO (↓) | ADI (↑) | (↓) | |||
| R | t | R | t | AUC | ||
| ICP | 5.34 | 0.036 | 10.47 | 0.076 | 88.1 | 2.99 |
| DCP-v2 | 7.42 | 0.050 | 14.93 | 0.102 | 72.4 | 4.93 |
| PNLK | 0.90 | 0.010 | 1.74 | 0.020 | 92.5 | 1.09 |
| ReAgent | 0.77 | 0.006 | 1.33 | 0.012 | 95.7 | 0.30 |
| Ours | 0.19 | 0.002 | 0.36 | 0.004 | 97.9 | 0.02 |
| AirLoc | ||||||
|---|---|---|---|---|---|---|
| MAE (↓) | ISO (↓) | ADI (↑) | (↓) | |||
| R | t | R | t | AUC | ||
| ICP | 9.59 | 0.061 | 19.47 | 0.146 | 70.1 | 5.40 |
| DCP-v2 | 9.34 | 0.053 | 18.76 | 0.133 | 73.5 | 4.77 |
| PNLK | 1.43 | 0.012 | 2.38 | 0.020 | 90.3 | 1.29 |
| ReAgent | 1.09 | 0.008 | 1.74 | 0.014 | 93.2 | 0.75 |
| Ours | 0.54 | 0.005 | 1.04 | 0.010 | 96.1 | 0.50 |
| Method | Held-Out Models | Held-Out Categories | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE (↓) | ISO (↓) | ADI (↑) | (↓) | MAE (↓) | ISO (↓) | ADI (↑) | (↓) | ||||||
| R | t | R | t | AUC | R | t | R | t | AUC | ||||
| Baseline | 1.46 | 0.011 | 2.82 | 0.023 | 94.5 | 0.75 | 3.41 | 0.024 | 7.00 | 0.051 | 90.5 | 3.84 | |
| recurrent refinement module | 1.37 | 0.009 | 2.69 | 0.019 | 95.5 | 0.72 | 1.68 | 0.011 | 2.94 | 0.024 | 92.7 | 1.24 | |
| Cross concatenation operation | 1.17 | 0.008 | 2.28 | 0.018 | 95.7 | 0.68 | 0.95 | 0.007 | 1.88 | 0.014 | 95.2 | 0.79 | |
| skip connection module | 0.99 | 0.007 | 2.06 | 0.016 | 96.1 | 0.66 | 0.82 | 0.006 | 1.65 | 0.013 | 96.0 | 0.72 | |
| Sliding Window | 1 | 2.11 | 0.015 | 4.30 | 0.031 | 91.2 | 1.28 | 2.27 | 0.015 | 4.43 | 0.032 | 89.5 | 1.69 |
| 8 | 1.28 | 0.009 | 2.63 | 0.019 | 95.7 | 0.69 | 1.06 | 0.007 | 2.14 | 0.016 | 95.2 | 0.81 | |
| 16 | 0.99 | 0.007 | 2.01 | 0.016 | 96.1 | 0.66 | 0.75 | 0.006 | 1.52 | 0.012 | 96.3 | 0.70 | |
| 32 | 1.01 | 0.007 | 2.06 | 0.017 | 96.5 | 0.65 | 0.80 | 0.006 | 1.59 | 0.013 | 96.4 | 0.71 | |
| MLP | 1.19 | 0.009 | 2.56 | 0.019 | 95.5 | 0.71 | 1.38 | 0.010 | 2.59 | 0.020 | 93.5 | 0.95 | |
| Iterative Updates | 4 | 2.11 | 0.015 | 4.30 | 0.031 | 91.2 | 1.28 | 2.27 | 0.015 | 4.43 | 0.032 | 89.5 | 1.69 |
| 8 | 1.28 | 0.009 | 2.63 | 0.019 | 95.7 | 0.69 | 1.06 | 0.007 | 2.14 | 0.016 | 95.2 | 0.81 | |
| 12 | 0.99 | 0.007 | 2.01 | 0.016 | 96.1 | 0.66 | 0.75 | 0.006 | 1.52 | 0.012 | 96.3 | 0.70 | |
| 16 | 1.01 | 0.007 | 2.06 | 0.017 | 96.5 | 0.65 | 0.80 | 0.006 | 1.59 | 0.013 | 96.4 | 0.71 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Yan, S.; Liu, Y.; Zhang, M.; Chen, C. R-PCR: Recurrent Point Cloud Registration Using High-Order Markov Decision. Remote Sens. 2023, 15, 1889. https://doi.org/10.3390/rs15071889
Cheng X, Yan S, Liu Y, Zhang M, Chen C. R-PCR: Recurrent Point Cloud Registration Using High-Order Markov Decision. Remote Sensing. 2023; 15(7):1889. https://doi.org/10.3390/rs15071889
Chicago/Turabian StyleCheng, Xiaoya, Shen Yan, Yan Liu, Maojun Zhang, and Chen Chen. 2023. "R-PCR: Recurrent Point Cloud Registration Using High-Order Markov Decision" Remote Sensing 15, no. 7: 1889. https://doi.org/10.3390/rs15071889
APA StyleCheng, X., Yan, S., Liu, Y., Zhang, M., & Chen, C. (2023). R-PCR: Recurrent Point Cloud Registration Using High-Order Markov Decision. Remote Sensing, 15(7), 1889. https://doi.org/10.3390/rs15071889