
Global Multi-Attention UResNeXt for Semantic Segmentation of High-Resolution Remote Sensing Images

Abstract

1. Introduction
- 1.
- A novel attention mechanism named GAG is proposed to generate attention for the uppermost part of the neural network by capturing the potential interdependencies of the context contained in each layer of the encoder–decoder architecture from a global perspective.
- 2.
- We propose GMAUResNeXt based on ResNeXt-101 [25] and GAG to make full use of the multi-scale features by connecting each global attention gate with the uppermost layer of the decoder part, thus simultaneously utilizing the texture features and semantic features.
- 3.
- Our GMAUResNeXt reduces the problem of false segmentation and miss-segmentation in high-resolution remote sensing images by exploring interdependencies of the context and fully utilizing the multi-scale features.
2. Related Work
2.1. Neural Network for Semantic Segmentation
2.1.1. FCN-Based Architectures
2.1.2. Encoder–Decoder-Based Architectures
2.2. Attention Mechanism
2.2.1. Focused Attention
2.2.2. Gating Mechanisms
3. Methods
3.1. Global Multi-Attention UResNeXt
3.2. Global Attention Gate
3.3. Non-Local Block
4. Experiment
4.1. Datasets
4.1.1. ISPRS Potsdam Dataset
4.1.2. Gaofen Image Dataset
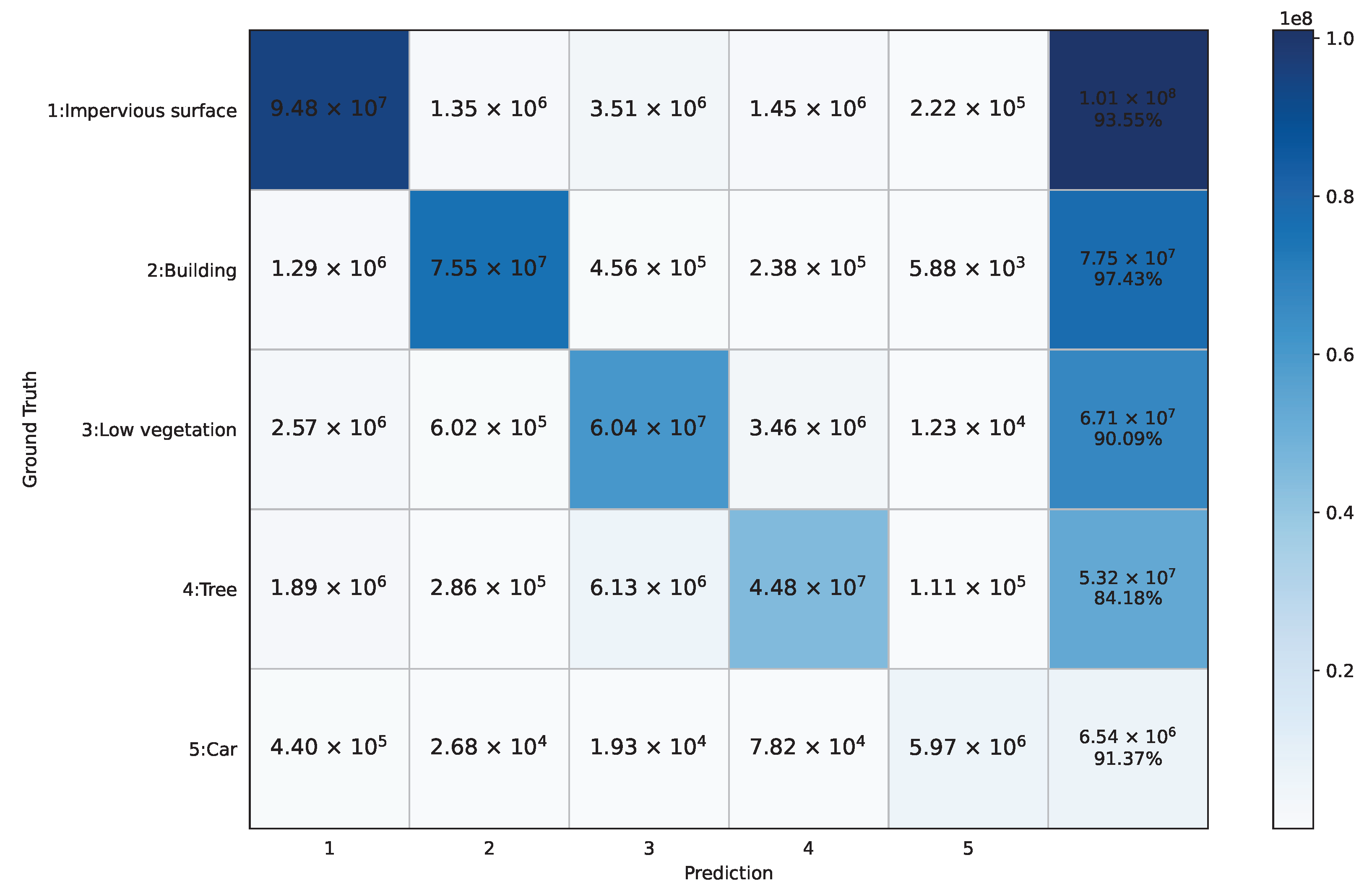
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Results on the Potsdam Dataset
4.5. Results on the GID Dataset
4.6. Comparison of Complexity
5. Discussion
5.1. Ablation Study of GAG
5.2. Visualization of GAG
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yuan, X.; Sarma, V. Automatic Urban Water-Body Detection and Segmentation From Sparse ALSM Data via Spatially Constrained Model-Driven Clustering. IEEE Geosci. Remote Sens. Lett. 2011, 8, 73–77. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, L.; Yao, F. Improved maize cultivated area estimation over a large scale combining MODIS–EVI time series data and crop phenological information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Yang, S.; Chen, Q.; Yuan, X.; Liu, X. Adaptive Coherency Matrix Estimation for Polarimetric SAR Imagery Based on Local Heterogeneity Coefficients. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6732–6745. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Granada, Spain, 20 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Yu, W.; Yang, K.; Yao, H.; Sun, X.; Xu, P. Exploiting the complementary strengths of multi-layer CNN features for image retrieval. Neurocomputing 2017, 237, 235–241. [Google Scholar] [CrossRef]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked Attention Networks for Image Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yu, Y.; Ji, Z.; Fu, Y.; Guo, J.; Pang, Y.; Zhang, Z.M. Stacked Semantics-Guided Attention Model for Fine-Grained Zero-Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Sinha, A.; Dolz, J. Multi-Scale Self-Guided Attention for Medical Image Segmentation. IEEE J. Biomed. Health Inform. 2021, 25, 121–130. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic Segmentation of Large-Size VHR Remote Sensing Images Using a Two-Stage Multiscale Training Architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Miech, A.; Laptev, I.; Sivic, J. Learnable pooling with context gating for video classification. arXiv 2017, arXiv:1706.06905. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2021, 13, 71. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-Scale Context Aggregation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-Alone Self-Attention in Vision Models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.; Chen, L.C. Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 108–126. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, Y.; Liang, B.; Ding, M.; Li, J. Dense Semantic Labeling with Atrous Spatial Pyramid Pooling and Decoder for High-Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 20. [Google Scholar] [CrossRef]
- Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [CrossRef]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Gardiner, A.; Hare, J.; Atkinson, P.M. VPRS-Based Regional Decision Fusion of CNN and MRF Classifications for Very Fine Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4507–4521. [Google Scholar] [CrossRef]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]










{kind=link}
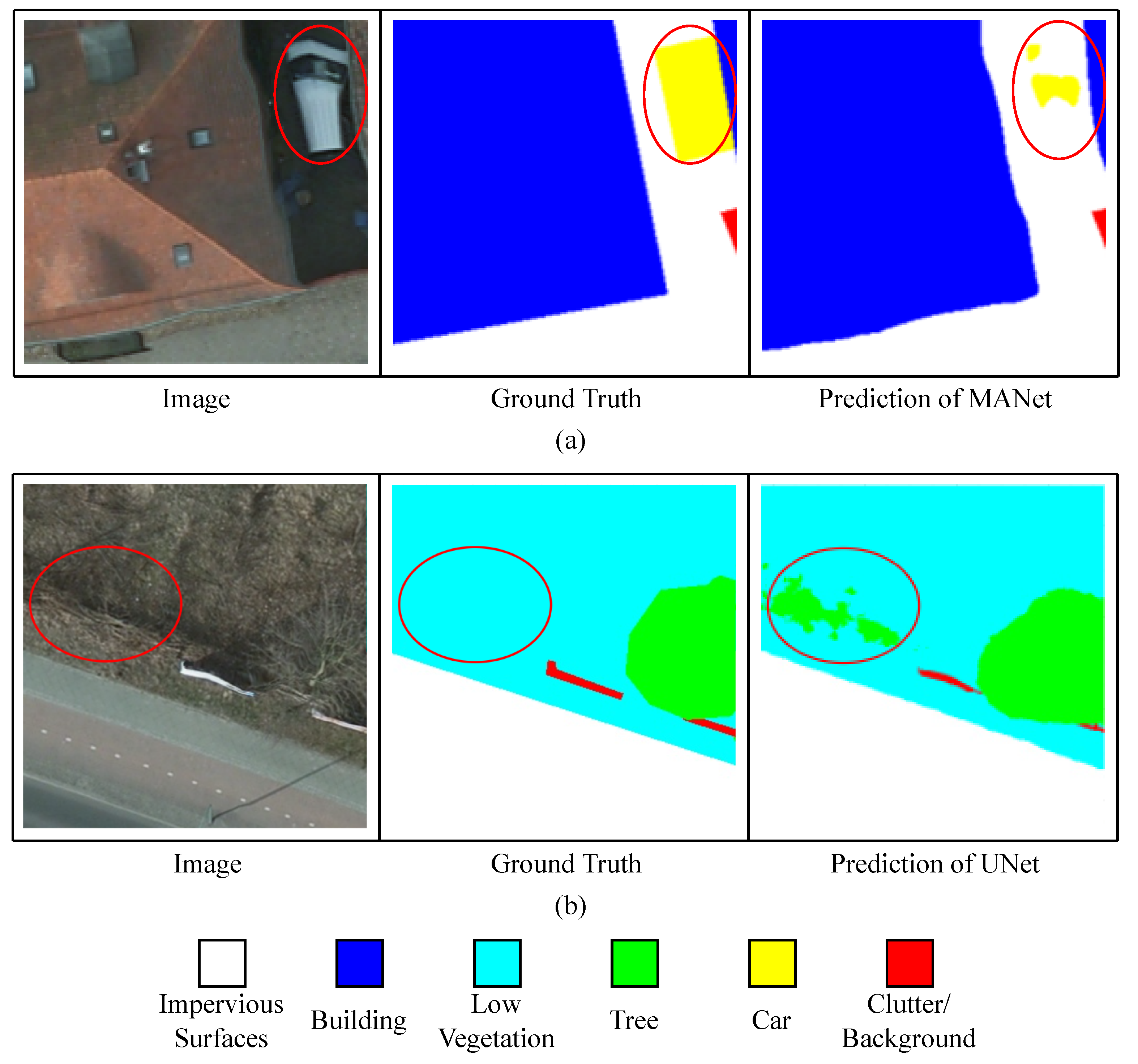{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Per-Class F1 Score | avg.F1 | OA | ||||
|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | |||
| Unet [12] | 88 | 93.52 | 77.76 | 73.43 | 78.18 | 82.18 | 82.81 |
| DeepLabv3+ [9] | 70.36 | 94.85 | 89.08 | 87.84 | 96.62 | 87.75 | 86.87 |
| PSPNet [47] | 70.04 | 95.02 | 88.62 | 87.91 | 96.46 | 87.61 | 87.57 |
| UResNeXt | 93.07 | 96.96 | 86.81 | 86.38 | 92.03 | 91.05 | 90.75 |
| MANet [11] | - | - | - | - | - | 89.07 | 88.76 |
| MDCNN [22] | 92.91 | 97.13 | 87.03 | 87.26 | 95.16 | 91.9 | 90.64 |
| HRCNet [31] | - | - | - | - | - | 90.20 | 89.50 |
| GMAUResNeXt_v1 | 93.48 | 96.85 | 87.39 | 87.13 | 92.47 | 91.46 | 91.05 |
| GMAUResNeXt_v2 | 93.71 | 97.26 | 87.82 | 86.78 | 92.88 | 91.69 | 91.32 |
| Method | OA | mIoU | F1 |
|---|---|---|---|
| UNet [12] | 86.29 | 78.88 | 87.56 |
| AttUNet [24] | 85.47 | 78.19 | 87.17 |
| UResNeXt | 87.88 | 79.68 | 88.22 |
| DeepLabv3+ [9] | 85.00 | 74.88 | 84.69 |
| FastFCN [48] | 81.23 | 72.15 | 82.58 |
| PSPNet [47] | 82.79 | 74.61 | 84.57 |
| MANet [11] | 86.51 | 78.33 | 87.14 |
| GMAUResNeXt_v2 | 89.70 | 83.22 | 90.51 |
| Method | Params (M) | GFLOPs (320) | GFLOPs (640) | GFLOPs (960) | Training Time |
|---|---|---|---|---|---|
| UNet [12] | 31.03 | 75.52 | 302.07 | 679.66 | 13.98 |
| DeepLabv3+ [9] | 59.47 | 37.57 | 150.27 | 338.1 | 11.04 |
| PSPNet [47] | 65.71 | 89.29 | 357.18 | 803.59 | 14.18 |
| UResNeXt | 93.78 | 42.34 | 169.35 | 381.02 | 11.00 |
| MANet [11] | 93.65 | 39.37 | 157.48 | 354.33 | - |
| MDCNN [22] | - | - | - | - | - |
| HRCNet [31] | 59.8 | - | - | - | - |
| GMAUResNeXt_v1 | 108.00 | 44.93 | 179.96 | 405.82 | 11.71 |
| GMAUResNeXt_v2 | 110.06 | 45.95 | 184.04 | 415.02 | 13.46 |
| Method | Params (M) | GFLOPs | Training Time |
| UNet [12] | 31.03 | 48.33 | 2.07 |
| AttUNet [24] | 34.88 | 66.74 | 1.65 |
| UResNeXt | 93.78 | 27.10 | 2.03 |
| DeepLabv3+ [9] | 59.47 | 24.07 | 2.12 |
| FastFCN [9] | 104.30 | 70.59 | 1.92 |
| PSPNet [47] | 65.71 | 89.29 | 2.10 |
| MANet [11] | 93.65 | 25.73 | - |
| GMAUResNeXt | 110.06 | 29.40 | 2.18 |
| Method | Per-Class F1 Score | avg.F1 | OA | ||||
|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | |||
| UResNeXt | 93.07 | 96.96 | 86.81 | 86.38 | 92.03 | 91.05 | 90.75 |
| GMAUResNeXt_1 | 93.35 | 97.18 | 87.47 | 86.83 | 92.04 | 91.37 | 90.71 |
| GMAUResNeXt_2 | 93.73 | 97.26 | 87.67 | 86.91 | 92.73 | 91.66 | 91.23 |
| GMAUResNeXt_3 | 93.81 | 97.13 | 87.49 | 86.95 | 93.16 | 91.71 | 91.44 |
| GMAUResNeXt_v2 | 93.71 | 97.26 | 87.82 | 86.78 | 92.88 | 91.69 | 91.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhao, J.; Deng, H. Global Multi-Attention UResNeXt for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1836. https://doi.org/10.3390/rs15071836
Chen Z, Zhao J, Deng H. Global Multi-Attention UResNeXt for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing. 2023; 15(7):1836. https://doi.org/10.3390/rs15071836
Chicago/Turabian StyleChen, Zhong, Jun Zhao, and He Deng. 2023. "Global Multi-Attention UResNeXt for Semantic Segmentation of High-Resolution Remote Sensing Images" Remote Sensing 15, no. 7: 1836. https://doi.org/10.3390/rs15071836
APA StyleChen, Z., Zhao, J., & Deng, H. (2023). Global Multi-Attention UResNeXt for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing, 15(7), 1836. https://doi.org/10.3390/rs15071836