

IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer


Abstract
1. Introduction
- We propose an infrared and visible image fusion method, IFormerFusion, which can efficiently learn features from source images in a wide frequency range. IFormerfusion can sufficiently retain texture details and maintain the structure of the source images.
- We designed the IFormer mixer, which consists of convolution/max-pooling paths and a criss-cross attention path. The convolution/max-pooling can learn high-frequency information, while the criss-cross attention path can learn low-frequency information.
- The cross-domain frequency fusion can trade high-frequency information between the source images to sufficiently learn comprehensive features and strengthen the capability to retain texture.
- Experiments conducted using the TNO, OSU, and Road Scene datasets show that IFormerFusion obtains better results in both visual quality evaluation and quantitatively evaluation.
2. Related Works
2.1. Vision Transformer
2.2. Deep Learning-Based Image Fusion Methods
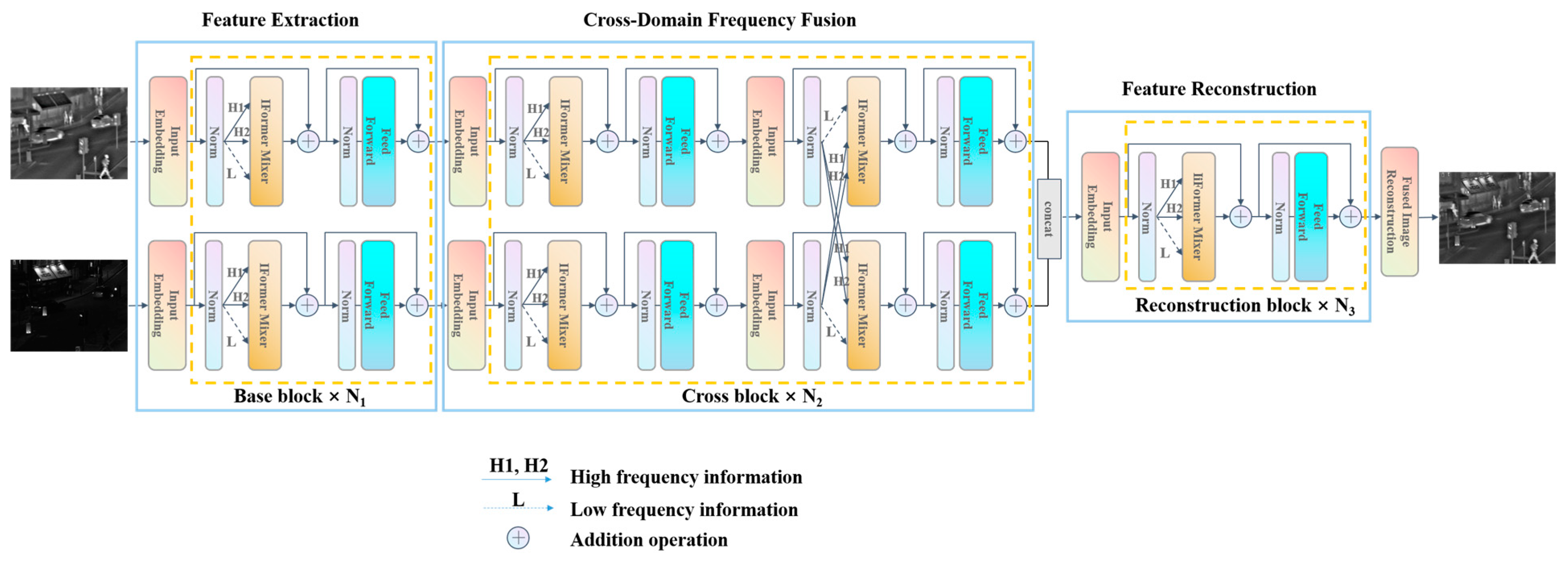
3. Methodology
3.1. Overall Framework
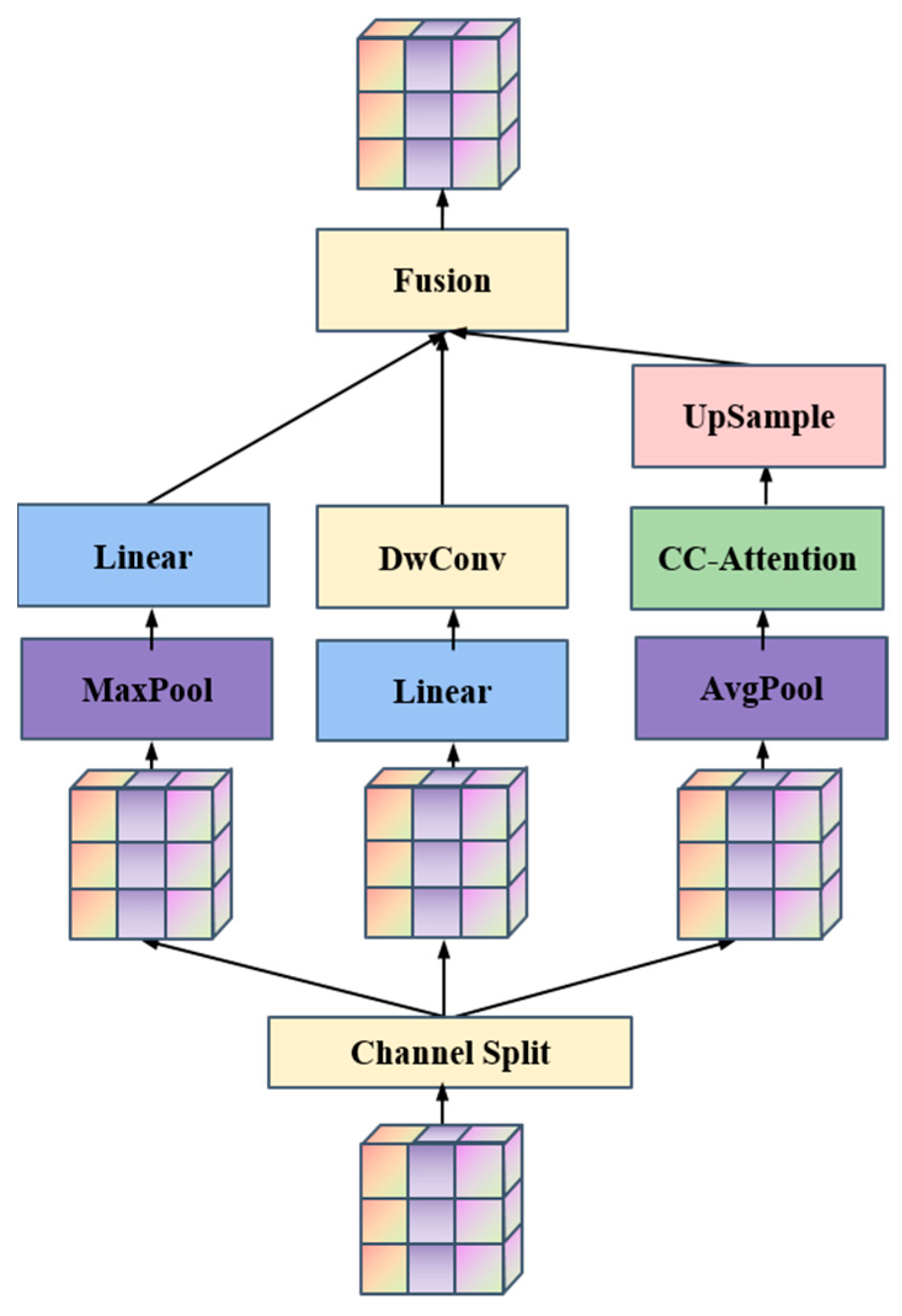
3.2. IFormer Mixer
3.3. Loss Function
4. Experimental Results and Analysis
4.1. Experiment Setup
4.2. Evaluation Metrics
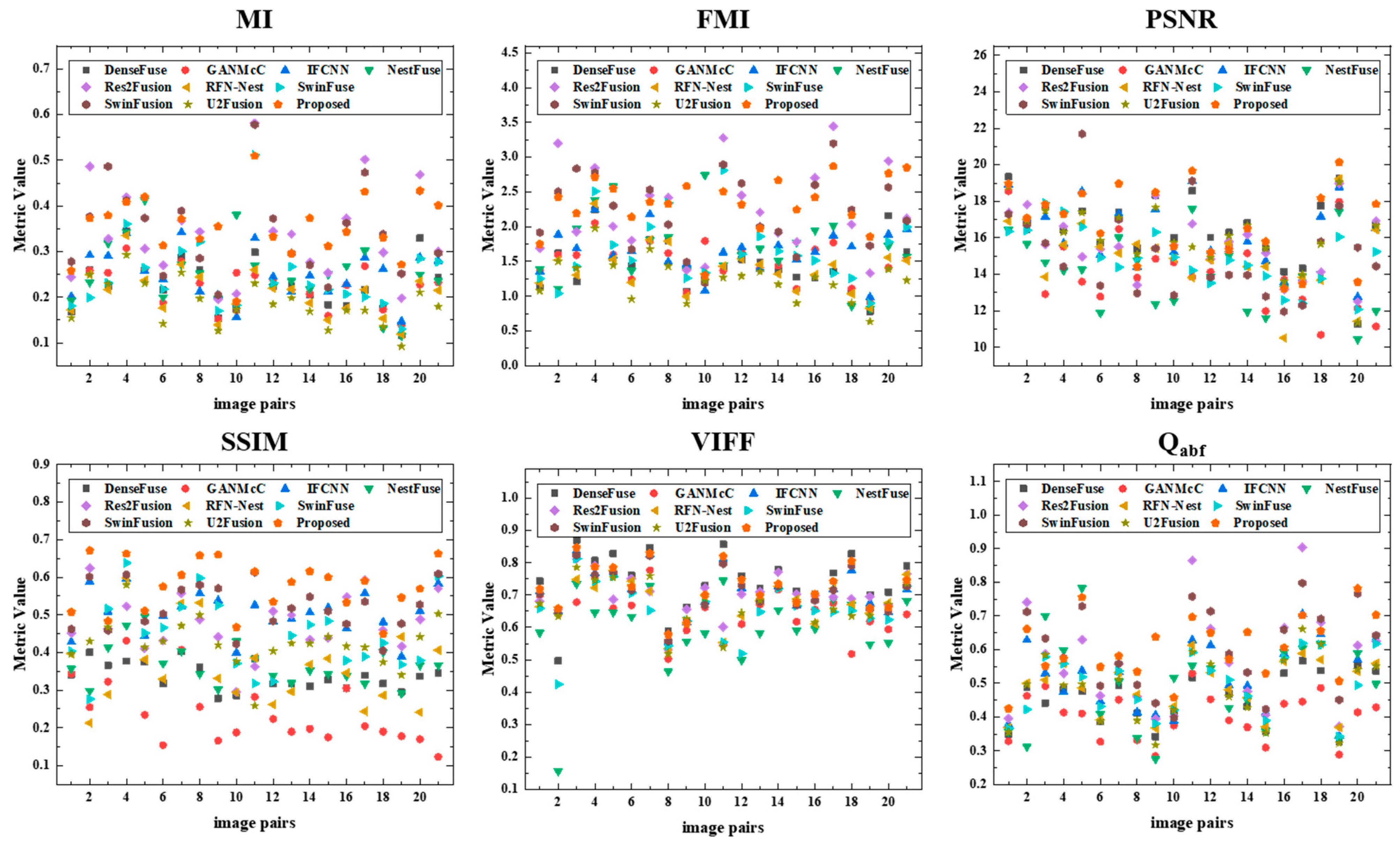
4.3. Results on the TNO Dataset
4.4. Results on the OSU Dataset
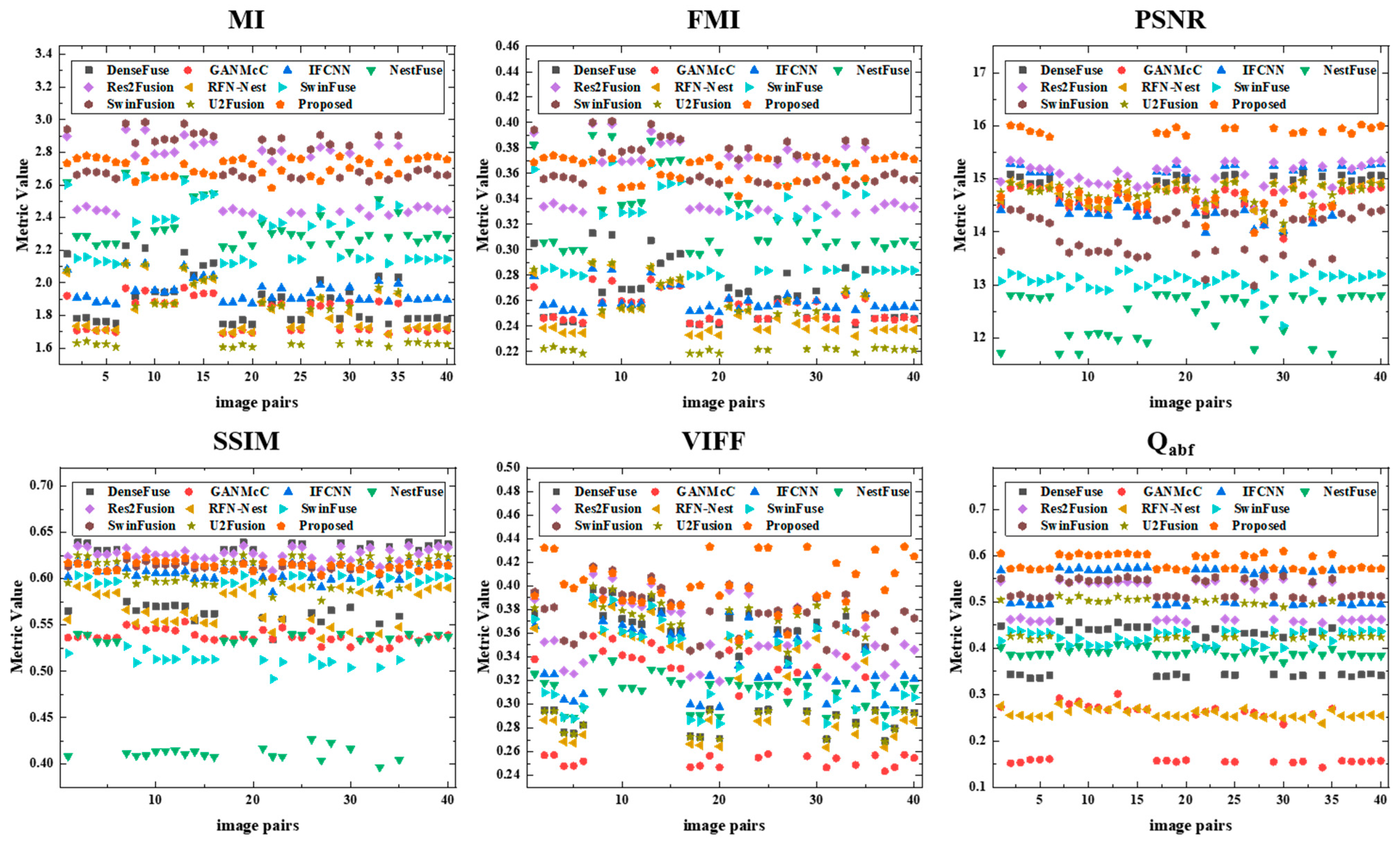
4.5. Results on the Road Scene Dataset
4.6. Computation Efficiency
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, Z.; Lai, J.; Xie, X. Learning Modality-Specific Representations for Visible-Infrared Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ye, P.; Qiao, D.; Zhao, J.; Peng, S.; Xiao, G. Object Fusion Tracking Based on Visible and Infrared Images Using Fully Convolutional Siamese Networks. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An Unsupervised Pan-Sharpening Method for Remote Sensing Image Fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Rajah, P.; Odindi, J.; Mutanga, O. Feature Level Image Fusion of Optical Imagery and Synthetic Aperture Radar (SAR) for Invasive Alien Plant Species Detection and Mapping. Remote Sens. Appl. Soc. Environ. 2018, 10, 198–208. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and Cross-Scale Adaptive Fusion Network for Detecting Salient Objects in RGB-D Images. IEEE Trans. Multimed. 2021, 24, 2192–2204. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image Fusion With Guided Filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [CrossRef]
- Budhiraja, S.; Sharma, R.; Agrawal, S.; Sohi, B.S. Infrared and Visible Image Fusion Using Modified Spatial Frequency-Based Clustered Dictionary. Pattern Anal. Appl. 2020, 24, 575–589. [Google Scholar] [CrossRef]
- Yin, M.; Duan, P.; Liu, W.; Liang, X. A Novel Infrared and Visible Image Fusion Algorithm Based on Shift-Invariant Dual-Tree Complex Shearlet Transform and Sparse Representation. Neurocomputing 2017, 226, 182–191. [Google Scholar] [CrossRef]
- Yin, M.; Liu, W.; Zhao, X.; Yin, Y.; Guo, Y. A Novel Image Fusion Algorithm Based on Nonsubsampled Shearlet Transform. Optik 2014, 125, 2274–2282. [Google Scholar] [CrossRef]
- Zhang, P.; Yuan, Y.; Fei, C.; Pu, T.; Wang, S. Infrared and Visible Image Fusion Using Co-Occurrence Filter. Infrared Phys. Technol. 2018, 93, 223–231. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. Infrared and Visible Image Fusion Using a Deep Learning Framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Beijing, China, 2018; pp. 2705–2710. [Google Scholar]
- Long, Y.; Jia, H.; Zhong, Y.; Jiang, Y.; Jia, Y. RXDNFuse: A Aggregated Residual Dense Network for Infrared and Visible Image Fusion. Inf. Fusion 2021, 69, 128–141. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 10. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Gao, H.; Miao, Q.; Xi, Y.; Ai, Y.; Gao, D. MFST: Multi-Modal Feature Self-Adaptive Transformer for Infrared and Visible Image Fusion. Remote Sens. 2022, 14, 3233. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A Generative Adversarial Network for Infrared and Visible Image Fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A Generative Adversarial Network With Multiclassification Constraints for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5005014. [Google Scholar] [CrossRef]
- Li, J.; Zhu, J.; Li, C.; Chen, X.; Yang, B.-H. CGTF: Convolution-Guided Transformer for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2022, 71, 5012314. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-Domain Long-Range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling Vision Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1204–1213. [Google Scholar]
- Ding, M.; Xiao, B.; Codella, N.C.F.; Luo, P.; Wang, J.; Yuan, L. DaViT: Dual Attention Vision Transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision Transformer Adapter for Dense Predictions. arXiv 2022, arXiv:2201.10147. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution 2022. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K. Rethinking Transformer-Based Set Prediction for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2020; pp. 3591–3600. [Google Scholar]
- Jebens, M.; White, R. Remote Sensing and Artificial Intelligence in the Mine Action Sector. J. Conv. Weapons Destr. 2021, 25, 28. [Google Scholar]
- Jebens, M.; Sawada, H. To What Extent Could the Development of an Airborne Thermal Imaging Detection System Contribute to Enhance Detection? J. Conv. Weapons Destr. 2020, 24, 14. [Google Scholar]
- Fardoulis, J.; Depreytere, X.; Gallien, P.; Djouhri, K.; Abdourhmane, B.; Sauvage, E. Proof: How Small Drones Can Find Buried Landmines in the Desert Using Airborne IR Thermography. J. Conv. Weapons Destr. 2020, 24, 15. [Google Scholar]
- Baur, J.; Steinberg, G.; Nikulin, A.; Chiu, K.; de Smet, T.S. Applying Deep Learning to Automate UAV-Based Detection of Scatterable Landmines. Remote Sens. 2020, 12, 859. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 12–14 May 2021. [Google Scholar]
- Si, C.; Yu, W.; Zhou, P.; Zhou, Y.; Wang, X.; Yan, S. Inception Transformer. arXiv 2022, arXiv:2205.12956. [Google Scholar]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Attention Models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification Saliency-Based Rule for Visible and Infrared Image Fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Wang, J.; Xu, J.; Shao, W. Res2Fusion: Infrared and Visible Image Fusion Based on Dense Res2net and Double Nonlocal Attention Models. IEEE Trans. Instrum. Meas. 2022, 71, 5011410. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Rao, D.; Wu, X.; Xu, T. TGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network. arXiv 2022, arXiv:2201.10147. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Boston, MA, USA, 2015; pp. 1–9. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 1800–1807. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Shi, H.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 2 November 2019. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.R.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2014, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A General Image Fusion Framework Based on Convolutional Neural Network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. RFN-Nest: An End-to-End Residual Fusion Network for Infrared and Visible Images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images. IEEE Trans. Instrum. Meas. 2022, 71, 5016412. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A Progressive Infrared and Visible Image Fusion Network Based on Illumination Aware. Inf. Fusion 2022, 83–84, 79–92. [Google Scholar] [CrossRef]
- Toet, A. TNO Image Fusion Dataset. Figshare. Dataset. 2014. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029/1 (accessed on 21 February 2023).
- Davis, J.W.; Sharma, V. Background-Subtraction Using Contour-Based Fusion of Thermal and Visible Imagery. Comput. Vis. Image Underst. 2007, 106, 162–182. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-Reference Image Fusion Metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 15–17 October 2014; pp. 1–3. [Google Scholar]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A New Image Fusion Performance Metric Based on Visual Information Fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Aslantas, V.; Bendes, E. A New Image Quality Metric for Image Fusion: The Sum of the Correlations of Differences. AEU-Int. J. Electron. Commun. 2015, 69, 1890–1896. [Google Scholar] [CrossRef]
- Zhai, G.; Min, X. Perceptual Image Quality Assessment: A Survey. Sci. China Inf. Sci. 2020, 63, 211301. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MI | FMI | PSNR | SSIM | VIFF | Qabf |
|---|---|---|---|---|---|---|
| DenseFuse | 1.4517 | 0.2261 | 16.5174 | 0.7459 | 0.4592 | 0.3383 |
| GANMcC | 1.4796 | 0.2244 | 14.2352 | 0.6424 | 0.4012 | 0.2380 |
| IFCNN | 1.6518 | 0.2510 | 16.1784 | 0.7126 | 0.5170 | 0.5041 |
| NestFuse | 1.6923 | 0.2524 | 13.9948 | 0.5967 | 0.4933 | 0.3667 |
| Res2Fusion | 2.2548 | 0.3380 | 15.6556 | 0.6998 | 0.5707 | 0.4764 |
| RFN-Nest | 1.4050 | 0.2084 | 15.0033 | 0.6776 | 0.4881 | 0.3598 |
| SwinFuse | 1.6524 | 0.2460 | 14.9131 | 0.6492 | 0.4960 | 0.4453 |
| SwinFusion | 2.2237 | 0.3389 | 15.1855 | 0.7102 | 0.5941 | 0.5216 |
| U2Fusion | 1.2451 | 0.1865 | 16.0628 | 0.6737 | 0.4809 | 0.4249 |
| Proposed | 2.3341 | 0.3538 | 16.7712 | 0.7258 | 0.6085 | 0.5765 |
| Method | MI | FMI | PSNR | SSIM | VIFF | Qabf |
|---|---|---|---|---|---|---|
| DenseFuse | 1.8942 | 0.2634 | 14.7407 | 0.5988 | 0.3271 | 0.3906 |
| GANMcC | 1.8014 | 0.2548 | 14.6034 | 0.5377 | 0.2943 | 0.2120 |
| IFCNN | 1.9484 | 0.2602 | 14.7524 | 0.6074 | 0.3387 | 0.5322 |
| NestFuse | 2.3474 | 0.3280 | 12.4301 | 0.4739 | 0.3113 | 0.3910 |
| Res2Fusion | 2.6372 | 0.3557 | 15.0758 | 0.6268 | 0.3614 | 0.5013 |
| RFN-Nest | 1.8255 | 0.2496 | 14.6995 | 0.5699 | 0.3163 | 0.2588 |
| SwinFuse | 2.3002 | 0.3121 | 13.0634 | 0.5560 | 0.3294 | 0.4224 |
| SwinFusion | 2.7763 | 0.3693 | 13.9279 | 0.6125 | 0.3772 | 0.5296 |
| U2Fusion | 1.7818 | 0.2430 | 14.7607 | 0.6074 | 0.3300 | 0.4627 |
| Proposed | 2.7155 | 0.3636 | 15.2345 | 0.6137 | 0.4014 | 0.5865 |
| Method | MI | FMI | PSNR | SSIM | VIFF | Qabf |
| DenseFuse | 2.0284 | 0.2874 | 16.4269 | 0.7230 | 0.4263 | 0.3827 |
| GANMcC | 1.9118 | 0.2645 | 13.3721 | 0.6220 | 0.3737 | 0.3360 |
| IFCNN | 2.0323 | 0.2827 | 16.3297 | 0.6860 | 0.4570 | 0.5449 |
| NestFuse | 2.6735 | 0.3685 | 11.9909 | 0.5784 | 0.3880 | 0.3754 |
| Res2Fusion | 2.4273 | 0.3338 | 14.1526 | 0.6634 | 0.4782 | 0.5135 |
| RFN-Nest | 1.9242 | 0.2640 | 13.9858 | 0.6344 | 0.4048 | 0.3129 |
| SwinFuse | 2.2021 | 0.2977 | 14.3088 | 0.6566 | 0.4464 | 0.5066 |
| SwinFusion | 2.3399 | 0.3339 | 14.3191 | 0.6932 | 0.4660 | 0.4611 |
| U2Fusion | 1.9364 | 0.2654 | 15.7728 | 0.6701 | 0.4409 | 0.5221 |
| Proposed | 2.2308 | 0.3158 | 17.0110 | 0.7052 | 0.4818 | 0.5490 |
| Method | TNO | OSU | RoadScene |
|---|---|---|---|
| DenseFuse | 0.0060 | 0.0079 | 0.0060 |
| GANMcC | 1.8520 | 1.0068 | 0.5242 |
| IFCNN | 0.0160 | 0.0132 | 0.0119 |
| NestFuse | 0.0167 | 0.0213 | 0.0144 |
| Res2Fusion | 10.208 | 0.919 | 2.937 |
| RFN-Nest | 0.2687 | 0.0510 | 0.1752 |
| SwinFuse | 0.1229 | 0.1248 | 0.1929 |
| SwinFusion | 8.6211 | 2.2020 | 5.1209 |
| U2Fusion | 2.3107 | 1.2639 | 0.6492 |
| Proposed | 0.3479 | 0.2678 | 0.2488 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Z.; Zhang, X.; Hu, Q.; Han, H. IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer. Remote Sens. 2023, 15, 1352. https://doi.org/10.3390/rs15051352
Xiong Z, Zhang X, Hu Q, Han H. IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer. Remote Sensing. 2023; 15(5):1352. https://doi.org/10.3390/rs15051352
Chicago/Turabian StyleXiong, Zhang, Xiaohui Zhang, Qingping Hu, and Hongwei Han. 2023. "IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer" Remote Sensing 15, no. 5: 1352. https://doi.org/10.3390/rs15051352
APA StyleXiong, Z., Zhang, X., Hu, Q., & Han, H. (2023). IFormerFusion: Cross-Domain Frequency Information Learning for Infrared and Visible Image Fusion Based on the Inception Transformer. Remote Sensing, 15(5), 1352. https://doi.org/10.3390/rs15051352