Abstract
The aim of infrared (IR) and visible image fusion is to generate a more informative image for human observation or some other computer vision tasks. The activity-level measurement and weight assignment are two key parts in image fusion. In this paper, we propose a novel IR and visible fusion method based on the principal component analysis network (PCANet) and an image pyramid. Firstly, we use the lightweight deep learning network, a PCANet, to obtain the activity-level measurement and weight assignment of IR and visible images. The activity-level measurement obtained by the PCANet has a stronger representation ability for focusing on IR target perception and visible detail description. Secondly, the weights and the source images are decomposed into multiple scales by the image pyramid, and the weighted-average fusion rule is applied at each scale. Finally, the fused image is obtained by reconstruction. The effectiveness of the proposed algorithm was verified by two datasets with more than eighty pairs of test images in total. Compared with nineteen representative methods, the experimental results demonstrate that the proposed method can achieve the state-of-the-art results in both visual quality and objective evaluation metrics.
1. Introduction
An infrared (IR) sensor reflects the temperature or thermal radiation differences in a scene and captures thermal radiation objects in the dark or in smoke. However, IR images suffer from inconspicuous details, low contrast, and poor visibility. On the contrary, visible images can clearly show the detailed information of objects and have higher spatial resolution under great lighting conditions. For objects in poor lighting conditions or behind smoke, visible images barely capture useful information. Therefore, the purpose of IR and visible image fusion is to fuse the complementary features of two different modal images to generate an image with clear IR objects and a pleasing background, helping people understand the comprehensive information of the scene. The fusion of IR and visible images has many applications in military and civilian settings, such as video surveillance, object recognition, tracking, and remote sensing [1,2].
In recent years, the fusion of IR and visible images has become an active topic in the field of image processing. Various image-fusion methods have been proposed one after another, which are mainly divided into multi-scale transform (MST) methods, sparse representation (SR) methods, saliency methods, and deep-learning methods.
For MST methods, the source images are firstly decomposed in multiple scales and then fused by artificially designed fusion rules in different scales, and finally, the fused image is obtained via reconstruction. An MST fusion method can decompose the source images into different scales and extract more information to represent the source images. The disadvantage of an MST is that it often relies on artificially designed complex fusion rules. The representative examples are the Laplacian pyramid (LP) [3], multi-resolution singular value decomposition (MSVD) [4], discrete wavelet transform (DWT) [5], dual-tree complex wavelet transform (DTCWT) [6], curvelet transform (CVT) [7], and target-enhanced multiscale transform decomposition (TE-MST) [8].
The SR method firstly learns an over-complete dictionary, then performs sparse coding on each sliding window block in the image to obtain sparse representation coefficients, and finally, reconstructs the image through the over-complete dictionary. The SR methods are robust to noise but usually have low computational efficiency. The representative examples are joint sparsity model (JSM) [9], joint sparse representation (JSR) [10], and joint sparse representation based on saliency detection (JSRSD) [11].
The saliency-based methods mainly perform fusion and reconstruction by extracting weights in salient regions of the image, such as weighted least squares (WLS) [12] and classification saliency-based rule for fusion (CSF) [13]. The advantage of saliency fusion methods is highlighting salient regions in the fused image, and the disadvantage is that saliency-based fusion rules are usually complicated.
In recent years, deep learning has been used for fusion tasks due to its powerful feature extraction capability. In [14], CNN was first used for multi-focus image fusion. Subsequently, in [15,16], a CNN was applied for IR and visible-image fusion, and for IR and medical-image fusion. For these two CNN-based fusion methods, the authors designed fusion rules based on three different situations. In addition, Li [17] et al. proposed a deep-learning method based on a pre-trained VGG-19, and adopted the fusion rules of the -norm and weighted averages. In [18], Li et al. developed a fusion method based on a pre-trained ResNet and applied the fusion rules of zero-phase component analysis (ZCA) and the -norm. Recently, more and more deep-learning fusion methods based on generative adversarial networks have been proposed. Ma et al. [19] proposed a fusion model, FusionGAN, based on a generative adversarial network, and applied a discriminator to continuously optimize the generator to generate the fusion result. The authors [20] presented a generative adversarial network with a dual-discriminator conditional, named DDcGAN, which aims to keep the thermal radiation in the IR image and the texture details in the visible image at the same time. Ma et al. [21] developed a generative adversarial network with multi-classification constraints (GANMcC) to transform the fusion problem into a multi-distribution estimation problem. Although these fusion algorithms have achieved good fusion results, they cannot effectively extract and combine the complementary features of IR and visible images.
Therefore, we propose a novel IR and visible fusion method based on a principal component analysis network (PCANet) [22] and an image pyramid [3,23]. The PCANet is trained to encode a direct mapping from source images to the weight maps. In this way, weight assignment can be obtained by performing activity-level measurement via the PCANet. Since the human visual system processes information in a multi-resolution way [24], a fusion method based on multi-resolution can produce fewer undesirable artifacts and make the fusion process more consistent with human visual perception [15]. Therefore, we used an image-pyramid-based framework to fuse IR and visible images. Compared with other MST methods, the running time of image-pyramid decomposition is short, which can improve the computational efficiency of the entire method [8].
The proposed algorithm has the following contributions:
- We propose a novel IR and visible image fusion method based on a PCANet and image pyramid, aiming to perform activity-level measurement and weight assignment through the lightweight deep learning model PCANet. The activity-level measurement obtained by the PCANet has a strong representation ability by focusing on IR target perception and visible-detail description.
- The effectiveness of the proposed algorithm was verified by 88 pairs of IR and visible images in total and 19 competitive methods, demonstrating that the proposed algorithm can achieve state-of-the-art performance in both visual quality and objective evaluation metrics.
The rest of the paper is arranged as follows: Section 2 briefly reviews PCANet, image pyramids, and guided filters. The proposed IR and visible image fusion method is depicted in Section 3. The experimental results and analyses are shown in Section 4. Finally, this article is concluded in Section 5.
2. Related Work
In this section, for a comprehensive review of some algorithms most relevant to this study, we focus on reviewing PCANet, the image pyramid, and the guided filter.
2.1. Principal Component Analysis Network (PCANet)
A principal component analysis network (PCANet) [22] is a lightweight, unsupervised deep learning neural network mainly used for extracting features in images, and it can also be considered as a simplified version of a CNN. In a PCANet, the critical task is the training of PCA filter, which will be specifically introduced in the next section. A PCANet consists of three components: cascaded two-stage PCA, binary hashing, and block histograms:
(1) Cascaded two-stage PCA: We assume that the filter bank in the first stage of the PCANet includes filters , and the filter bank in the second stage contains filters . Firstly, the input sample I is convolved with the l-th filter of the first stage:
where * represents the convolution operation. Then, is convolved with the r-th filter of the second stage:
where represents the output of I and stands for the amount of output images.
(2) Binary hashing: Next, will be binarized, and then these binary matrices are converted to decimal matrices as:
where is the l-th decimal matrix for I, and is a Heaviside step function, whose value is one for positive entries and zero otherwise.
(3) Block histograms: In this part, each is split into B blocks, and we compute the histograms of the decimal values in each block and concatenate whole B histograms into one vector . Following this encoding process, the input image I is transformed into a set of block-wise histograms. We ultimately acquire the feature vectors as:
where f is the network output.
The advantages of a PCANet are twofold:
- In the training stage, the PCANet obtains the convolution kernel through PCA auto-encoding does not need to iterate calculations of the convolution kernel like other deep learning methods.
- As a lightweight network, PCANet has only a few hyperparameters to be trained.
These two advantages make PCANet more efficient. PCANet has a wide range of applications in various fields, such as image recognition [22], object detection [25,26], image fusion [27], and signal classification [28,29].
2.2. Image Pyramids
An image pyramid [3,23] is a collection of images that consists of multiple sub-images of different resolutions of an image. In an image pyramid, the top-layer image has the lowest resolution, and the bottom-layer images have the highest resolution. Image pyramids include Gaussian pyramid and Laplacian pyramid [3].
In the Gaussian pyramid, we use I to represent the original image, that is, the 0-th layer Gaussian pyramid . We perform Gaussian filtering and interlaced subsampling on to obtain the first layer of the Gaussian pyramid, . Repeat the above operations to obtain (where is the h-th layer of the Gaussian pyramid).
The Gaussian pyramid can be expressed as:
where represents the coordinates in the image, , , and . N is the number of layers of Gaussian pyramid decomposition; and are the numbers of rows and columns of the h-th layer of the Gaussian pyramid, respectively; and is a 2D separable window function. By combining Equations (5) and (6), we can get the Gaussian pyramid image sequence , and the upper layer is four times smaller than the lower layer.
On the other hand, we apply interpolation to enlarge the h-th layer Gaussian pyramid to obtain the image :
where the size of is the same as that of . can be denoted as:
where , , . When and are non-integers:
The expansion sequence can be obtained by Equations (7)–(9).
The Laplacian pyramid can be expressed as:
where represent Laplacian pyramid images, and is the top layer.
The inverse Laplacian pyramid transform (reconstruction) process can be obtained as follows:
where I is the reconstructed image.
2.3. Guided Filter
A guided filter [30] is an edge filter based on a local linear model which does not need to perform convolution directly like most other filtering methods, and has simplicity, fast speed, and great edge-preservation. We define that filter output q is a linear transform of guidance image in a window centered on pixel k:
where and are the linear coefficients in .
To determine and , we minimize the difference between the filter output q and the filter input p, i.e., the cost function:
where is a regularization parameter that serves to prevent from being too large. With the above equation, we can enable the local linear model maximally similar to the input image p in .
and can be obtained by the following:
In the above equations, and are the mean and variance of in , is the number of pixels in , and is the mean of p in .
We employ this linear model to all the local windows of the input image, but these windows are overlapped, and their centers are located in . Thus, the filter output is averaged over all possible values by:
where and are the mean coefficients acquired from whole the overlapped windows, including pixel i.
3. The Proposed Method
We propose a novel IR and visible fusion method based on PCANet and an image pyramid. The activity-level measurement and weight assignment are two key parts of image fusion. We used PCANet to perform activity-level measurement and weight assignment because PCANet has stronger representation ability by focusing on IR target perception and visible detail description. Due to the human visual system processing information in a multi-resolution way [24], we apply an image pyramid to decompose and merge the images at multiple scales in order to make the fused image details appear more suitable for human visual perception.
3.1. Overview
The proposed algorithm is exhibited in Figure 1. Our method consists of four steps: PCANet initial weight map generation, spatial consistency, image-pyramid decomposition and fusion, and reconstruction. In the first step, we feed the two source images into PCANet and get the initial weight maps. In the second step, we take advantage of the spatial consistency to improve the quality of initial weight maps. The third step is image-pyramid decomposition and fusion. On the one hand, the source images are multi-scale transformed through the Laplacian pyramids. On the other hand, the initial weight maps are decomposed into multiple scales through Gaussian pyramids, and the softmax operation is performed on each scale to obtain the weight maps of each layer. Then, the fused image of each scale is obtained through a weighted-average strategy. In the last step, the final fusion image is obtained by reconstructing the Laplacian pyramid.

Figure 1.
Schematic diagram of the proposed method.
3.2. PCANet Design
In our study, IR and visible image fusion is treated as a two-class classification problem. For each pixel from the same position of the source images, a scalar from 0 to 1 is output through PCANet to represent the probability of coming from different source images in the fused image. Standard PCANet contains cascaded two-stage PCA, binary hashing, and block histograms, where the role of the latter two components is to extract sparse features of images. If the network includes binary hashing and block histograms, the output sparse features have only two values of zero and one, and the size of the features are inconsistent with the source images. In our fusion task, in order to obtain more accurate probability values of the same position pixel from two source images and perform the fusion task faster, we only use cascaded two-stage PCA. The network design of PCANet is shown in Figure 2. In PCANet, the most important component is the PCA filter. In the next section, we describe the training process of the PCA filter in detail. In the PCANet framework, firstly, the input image is convolved with the first-stage PCA filter bank to obtain a series of feature maps. Then, these feature maps are convolved with the second-stage PCA filter bank to obtain more feature maps. These feature maps represent the details of the input image on different objects. Particularly, the second-stage filters can extract more advanced features. Two-stage PCA is usually sufficient to obtain a great effect, and a deeper architecture does not necessarily lead to further improvements [22], so we selected cascaded two-stage PCA for our experiments.
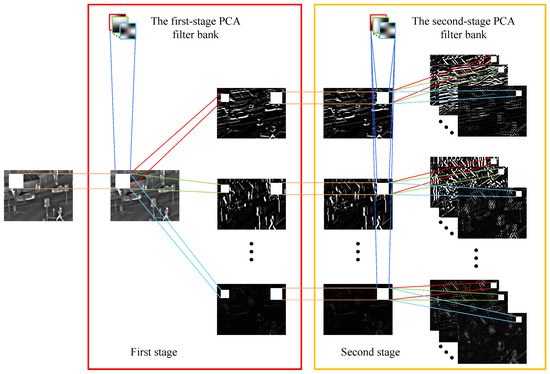
Figure 2.
The PCANet model used in the proposed fusion method.
3.3. Training
The training of PCANet is essentially computing the PCA filter. PCA can be viewed as the simplest class of an auto-encoder, which minimizes reconstruction error [22]. We selected N images in the MS-COCO [31] database for training. In our experiments, we set N to 40,000. Considering that the size of each image in the MS-COCO database is different, each training image was converted into a grayscale image. The training process of PCANet consisted of calculating two-stage PCA filter banks, and we assume that each filter size was in both stages. In the following, we describe the training process of each stage in detail.
- The First Stage
In order to facilitate the convolution operation, each training image is preprocessed. Preprocessing contains two steps: (1) Each sliding patch in the i-th training image was converted into a column of , where , , . (2) The patch mean is subtracted from each column in to obtain .
After the above preprocessing, we perform the same operation on N training images to obtain . Then, we compute the covariance matrix of X:
Next, by calculating the eigenvalue and eigenvector of the covariance matrix , we can obtain:
where is a diagonal matrix with eigenvalues on the diagonal. Each column in indicates an eigenvector corresponding to the eigenvalue in , that is, the PCA filter. Particularly, the larger the eigenvalue, the more important the corresponding principal component. Therefore, we select the eigenvectors corresponding to the top largest eigenvalues as the PCA filters. Accordingly, the l-th PCA filter can be expressed as . Clearly, the PCA filter bank of the first stage is denoted as:
Actually, the role of the PCA filter bank is to capture the main changes in the input image [22]. Next, we zero-pad the height and width boundaries of the i-th image with size and size , respectively, so that the convolution outputs have the same size as the source image. Then, is preprocessed to obtain . The is convolved with the l-th PCA filter in the first stage to obtain:
where * represents the convolution operation and indicates an input sample of the second stage.
- The Second Stage
Firstly, almost the same as the first stage, the input image is preprocessed to obtain , and then the i-th input image is represented as . Performing the same for all N input images, we obtain . Next, similar to the first stage, we compute the covariance matrix of Y:
where denotes the eigenvalues of the second stage, and represents the eigenvectors of the second stage. We select the eigenvectors corresponding to the top largest eigenvalues as the filter bank of the second stage. Therefore, the r-th PCA filter in the second stage can be denoted as . The PCA filter bank of the second stage is indicated as:
Up till this point, the two-stage filter banks and of PCANet have been obtained. The difference between the filters of the two stages is that the second-stage filters can extract higher-level features than the first-stage.
3.4. Detailed Fusion Scheme
3.4.1. PCANet Initial Weight Map Generation
Let the input image A indicate an IR image and B represent a visible image, and they are pre-registered images with the same size. Assume that each PCA filter size is in both stages. Firstly, we zero-pad the height and width boundaries of A and B with size and size , respectively, so that the convolution outputs have the same size as the source images. Next, the input image S, , takes advantage of the preprocessing to obtain . The is convolved with the l-th PCA filter in the first stage:
Through the first-stage filter bank , the first-stage PCANet outputs a total of feature maps .
The second stage is similar to the first stage. Firstly, zero-padding is performed in each , and then preprocessing is taken to obtain . Next, is convolved with the r-th PCA filter in the second stage:
The second-stage PCANet outputs a total of feature maps .
Next, we define the initial weight maps for IR image A and visible image B as and :
where x and y represent the coordinates of the pixels in the image. Particularly, and are the same size as the source images.
3.4.2. Spatial Consistency
Spatial consistency means that two adjacent pixels with similar brightness or color will have a greater probability of having similar weights [32]. The initial weight maps are in general noisy, which may create artifacts on the fused image. To improve the performance of fusion, the initial weight maps need to be further processed. Specifically, we utilize a guided filter [30] to improve the quality of the initial weight maps. The guided filter is a very effective edge-preserving filter which can transform the structural information of the guided image into the filtering result of the input image [30]. We adopt the source image S as the guidance image to guide the absolute value of the initial weight map for filtering:
where A and B represent guidance images. In guided filter, we experimentally set the local window radius to 50 and the regularization parameter to 0.1.
3.4.3. Image-Pyramid Decomposition and Fusion
We perform n-layer Gaussian pyramid decomposition [3,23] on and to obtain and according to Equations (5) and (6). Each pyramid decomposition layer is set to the value , where is the spatial size of source images and denotes the flooring operation. Then, and are fed into a 2-way softmax layer, which produces probability values for two classes, denoting the outcome of each weight assignment:
The values of and are between zero and one, indicating the probabilities that A and B take values at the same position pixel point. After the above operations, the network can autonomously learn the features in the image and calculate the weight of each pixel, avoiding the complexity and subjectivity of manually designing the fusion rules.
In addition, we conduct n-layer Laplacian pyramid decomposition [3,23] on A and B to obtain and according to Equations (10) and (11). The number of the Laplacian pyramid’s decomposition layers is the same as that of the Gaussian pyramid. It is noteworthy that and are the same sizes as and . Then, the fused image on each layer is obtained by the weighted-average rule:
3.4.4. Reconstruction
Finally, we reconstruct the Laplacian pyramid to obtain the fused image F according to Equation (12). The main steps of the proposed IR and visible image fusion method are summarized in Algorithm 1.
| Algorithm 1 The proposed IR and visible image fusion algorithm. |
Training phase 1. Initialize PCANet; Testing (fusion) phase Part 1: PCANet initial weight map generation 1. Feed IR image A and visible image B into PCANet to obtain the initial weight maps according to Equations (26)–(29); Part 2: Spatial consistency 2. Perform guided filtering on the absolute values of and according to Equations (30) and (31); Part 3: image-pyramid decomposition and fusion 3. Perform n-layer Gaussian pyramid decomposition on and to generate the results and according to Equations (5) and (6); 4. Perform softmax operation at each layer to obtain and according to Equations (32) and (33); 5. Perform n-layer Laplacian pyramid decomposition on A and B to obtain and according to Equations (10) and (11); 6. Apply the weighted-average rule on each layer to generate the result according to Equation (34); Part 4: Reconstruction 7. Reconstruct the Laplacian pyramid to obtain the fused image F according to Equation (12). |
4. Experiments and Discussions
In this section, the two experimental datasets and thirteen objective quality metrics are introduced. Secondly, the effects of different sizes and various number of filters in our method are discussed. Thirdly, we verify the effectiveness of our algorithm through two ablation studies. Fourthly, the proposed algorithm is evaluated by using visual quality and objective evaluation metrics. We selected nineteen state-of-the-art fusion methods to compare with our algorithm. Finally, we show the computational efficiency of different algorithms. All our experiments were performed on Intel (R) Core (TM) i7-11700, 64 GB RAM, and MATLAB R2019a.
4.1. Datasets
In order to comprehensively verify the effectiveness of our algorithm, we selected two datasets of different scenes for experiments, namely, the TNO dataset [33] and the RoadScene [34] dataset. The TNO dataset consists of several hundred pairs of pre-registered IR and visible images, mainly including military-related scenes, such as camps, helicopters, fighter jets, and soldiers. We chose 44 pairs of images in TNO dataset as test images. Figure 3 exhibits eight pairs of testing images of the TNO dataset, where the top row represents the IR images and the bottom row denotes the visible images.

Figure 3.
Illustrations of 8 pairs of testing images of the TNO dataset.
Differently from the TNO dataset, the RoadScene dataset has 221 pairs of road-related IR and visible pre-registered images, mainly including scenes of rural roads, urban roads, and night roads. We selected 44 pairs of images in the RoadScene dataset as test images. Figure 4 exhibits eight pairs of testing images of the RoadScene dataset, where the top row indicates the IR images and the bottom row denotes the visible images.

Figure 4.
Illustrations of 8 pairs of testing images of the RoadScene dataset.
4.2. Objective Image Fusion Quality Metrics
In order to verify the fusion effect of our algorithm, we selected 13 objective evaluation metrics to conduct experiments. In what follows, we precisely describe various evaluation metrics:
- Yang’s metric [35]: is a fusion metric based on structural information, which aims to calculate the degree to which structural information is transferred from the source images into the fused image;
- Gradient-based metric [36]: provides a fusion metric of image gradient, which reflects the degree of edge information of the source images preserved in the fusion image;
- Structural similarity index measure [37]: is a fusion index based on structural similarity, which mainly calculates the structural similarity between the fusion result and the source images;
- , and [38] calculate wavelet features, discrete cosine, and feature mutual information (FMI), respectively;
- Modified fusion artifacts measure [39]: provides a fusion index that introduces noise or artifacts in the fused image, reflecting the proportion of noise or artifacts generated in the fused image;
- Piella’s three metrics , , [40]: Piella’s three measures are on the basis of the structural similarity between source images and the fused image;
- Phase-congruency-based metric [41]: calculates the degree to which salient features in the source images are transferred to the fused image, and it is based on the absolute measure of image features;
- Chen–Varshney metric [42]: The metric is based on the human vision system and can fit the results of human visual inspection well;
- Chen–Blum metric [43]: is a fusion metric based on human visual perception quality.
In the above metrics, except and , the larger the values, the better the fusion performance. On the contrary, the smaller the values of and , the better the fusion effect. Among all the metrics, , , and are the most important.
4.3. Analysis of Free Parameters
PCANet is a lightweight network with only three free parameters: the number of first-stage filters , the number of second-stage filters , and the size of the filter. We set the filter sizes of the two stages to be the same. We used the 44 pairs of images in TNO dataset to perform parameter setting experiments. The fusion performance is calculated by the average values of 13 fusion metrics, and the best values are indicated in red.
4.3.1. The Effect of the Number of Filters
We discuss the effect of the number of filters on fusion performance. As shown in Table 1, we fixed the PCA filter size to , and then the number of first-stage filters and the number of second-stage filters were set to vary from 3 to 8. In PCANet, the number of and affects the feature extraction of input samples. A higher number of filters means that the model extracts more features. Table 1 shows the influences of different numbers of and on the fusion performance. When = = 8, the model obtains 10 best values. If the values of and are greater than eight, the model will take more time, and the value of may be lower. We should keep the model as simple as possible, so we set = = 8.

Table 1.
The effect of the number of filters. and denote the numbers of first-stage and second-stage filters, respectively.
4.3.2. The Influence of Filter Size
In this experiment, we discuss the impact of filter size on fusion performance. In Table 2, we fixed = = 8, and then the sizes of PCA filters were set to , , , , and , respectively. In PCANet, different filter sizes affect receptive field and feature extraction. A larger filter size means that the model extracts more features. Table 2 exhibits the influence of different filter size on the fusion performance. One can see that the fusion performance is the best when the size of the PCA filter is .
Table 2.
The effect of filter size.
Therefore, we set = = 8, and the PCA filter size was .
4.4. Ablation Study
In this part, we conducted two ablation studies to verify the effectiveness of the image pyramid and guided filter.
4.4.1. The Ablation Study of the Image Pyramid
Figure 5 shows the results of image pyramid ablation experiment. We compared the model with and without image pyramids regarding the fusion results. The first column represents the IR image, the second column denotes the visible image, the third column indicates the model without the image pyramid, and the fourth column represents the model with the image pyramid. Except the image pyramid, other parameters were the same. For the four examples, the fusion results for the model with the image pyramid are better than the fusion results for the model without the image pyramid. The fusion results for without the pyramid introduce some artifacts and noises, and the model with the pyramid almost eliminated these artifacts and the noise through multi-scale decomposition (see the red boxes in Figure 5).

Figure 5.
The ablation study of the image pyramid. The first column has IR images, the second column has visible images, the third column has images without the use of the image pyramid, and the fourth column has images with the use of the image pyramid.
We used the 44 pairs of images in the TNO dataset to verify the effect of the model with and without image pyramids. Table 3 shows the average value of each evaluation index and the fusion time for 44 pairs of images. The best values are indicated in red. The running times of the two models were almost the same, and the model with image pyramid obtained eight optimal values. Combined with visual quality and objective evaluation metrics, it is proved that the algorithm with the image pyramid is better.
Table 3.
The average value of with and without image pyramids on the TNO dataset (unit: seconds).
4.4.2. The Ablation Study of the Guided Filter
Figure 6 shows the results of the guided-filter ablation experiment. We compare the model with and without guided filtering. The first column has IR images, the second column has visible images, the third column has images produced without guided filtering, and the fourth column has images produced with guided filtering. All other parameter settings were the same. There are some obvious artifacts and noise in the red boxes in the third column of Figure 6. After guided filtering, these artifacts and the noise were eliminated. It can be seen in the figure that the fusion effect with guided filtering is better.

Figure 6.
The ablation study of the guided filter. The first column has IR images, the second column has visible images, the third column has images produced without guided filtering, and the fourth column has images produced with guided filtering.
4.5. Experimental Results and Discussion
4.5.1. Comparison with State-of-the-Art Competitive Algorithms on the TNO Dataset
We used the TNO dataset to verify the performance of our algorithm. The competitive algorithms numbered 19: MST methods (MSVD [4], DWT [5], DTCWT [6], CVT [7], MLGCF [44], and TE-MST [8]), SR methods (JSM [9], JSR [10], and JSRSD [11]), deep learning methods (FusionGAN [19], GANMcC [21], PMGI [45], RFN-Nest [46], CSF [13], DRF [47], FusionDN [34], and DDcGAN [20]), and other methods (GTF [48] and DRTV [49]). In particular, the comparative algorithms based on deep learning have been proposed in the last three years. The corresponding parameter settings in the comparison algorithms were set to the default values given by their authors.
In our approach, we set the filter size to for both stages, and the number of filters to eight for both stages. The number of image-pyramid decomposition layers was n, , where represents the size of the source images and denotes the flooring operation. We set the radius of the guided filter to 50 and the regularization parameter to 0.1. The fusion performance of the proposed method was evaluated by comparing the visual quality and objective evaluation metrics.
Figure 7 and Figure 8 show two representative examples. For better comparison, some regions in the fused images are marked with rectangular boxes. Figure 7 shows the fusion results of “Queen Road” source images. The described nighttime scene includes rich content, containing pedestrians, cars, street lights, and shops. IR images exhibit thermal radiation information of pedestrians, vehicles, and street lights, while visible images provide clearer details, especially the details of the plate of storefront. The ideal fusion result of this example is to preserve the thermal radiation information in the IR image while extracting the details in the visible image. Pedestrians in the MSVD, DTCWT, and CVT methods suffer from low brightness and contrast (see red and orange boxes in Figure 7c,e,f). The DWT-based method introduces undesired small rectangular blocks (see three boxes in Figure 7d). Although the MLGCF algorithm can extract the thermal objects well, the whole image is too dark. The TE-MST technique has high fusion quality, but it introduces too much of the infrared spectrum to the plate of storefront, resulting in an unnatural visual experience (see the green box in Figure 7h). The plate of storefront in the JSM fusion result is clearly blurred (see the green box in Figure 7i). Although JSR and JSRSD schemes achieve a great fusion effect, their backgrounds lack some details. Both GTF and DRTV methods suffer from low fusion performance, especially the lack of details on the plate of storefront (see green boxes in Figure 7l,m). Among the deep-learning-based algorithms, the FusionGAN, GANMcC, PMGI, and RFN-Nest methods cannot extract the details of the plate of storefront well due to introducing too much of the infrared spectrum (see the green boxes in Figure 7n,o,p,q). The CSF technique cannot extract thermal radiation information well (see the red and orange boxes in Figure 7r). The DRF, FusionDN, and DDcGAN methods appear overexposed and introduce some undesired noise (see Figure 7s,t,u). Our algorithm can well extract thermal radiation objects in the IR image and details in the visible image with a more natural visual experience (see Figure 7v). Our algorithm has the stronger representation ability by focusing on IR target perception and visible detail description compared with other methods.

Figure 7.
Fusion results of the “Queen Road” source images.

Figure 8.
Fusion results of the “Kaptein” source images.
Figure 8 shows the fusion results of the “Kaptein” source images, which exhibit a person standing at a door. On the one hand, IR images mainly capture the thermal radiation information of person. On the other hand, the visible images clearly show the details of buildings, trees in the distance, and grass. The person after MSVD, DWT, DTCWT, and CVT methods suffers from low brightness and contrast. In particular, the DWT, DTCWT, and CVT algorithms produce some artifacts around the people. The MLGCF and TE-MST methods cannot well extract the details of the ground textures (see the orange boxes in Figure 8g,h). The JSM fusion result is blurry, and JSR and JSRSD schemes introduced some noise. The GTF and DRTV methods introduce artifacts around distant trees. Regarding the deep learning algorithms, the man after application of the FusionGAN and DDcGAN methods is blurry, and the person after the RFN-Nest and DRF methods has low brightness. These fusion results constitute an unnatural visual experience. In addition, the GANMcC, PMGI, and CSF methods cannot well capture the details of the sky and ground (see the orange and green boxes in Figure 8o,p,r). The FusionDN technique achieves high fusion performance. Compared to other methods, our method obtains better perceptual quality for the sky (see green box in Figure 8v), higher brightness of the thermal radiation objects (see red box in Figure 8v), and clearer ground textures (see orange box in Figure 8v).
Table 4 shows the averages of 13 objective evaluation metrics for the TNO dataset, and the best values are indicated in red. As can be seen in Table 4, except and , our algorithm obtained the best results for all metrics, indicating that our algorithm has excellent fusion performance.
Table 4.
The average values of different methods on the TNO dataset.
4.5.2. Further Comparison on the RoadScene Dataset
In order to verify the fusion performance in different scenes, we employed the RoadScene dataset for experiments. Figure 9 and Figure 10 show two representative examples. Figure 9 exhibits the fusion results of “FLIR04602” source images. The scene shows a pedestrian standing on the side of the road and a car parked on the road during the daytime. The IR images mainly capture the thermal radiation information of pedestrian and car, and visible images show the details of buildings and trees. The pedestrian and car in the MSVD method lost brightness and contrast. The DWT method introduces undesired “small rectangles” (see car and buildings in Figure 9d). The trees in the DTCWT, CVT, MLGCF, and TE-MST methods introduce too many “small black spots” from the infrared spectrum, resulting in unnatural visual experience (see green boxes in Figure 9e–h). The fusion result of JSM method is noticeably blurry. The JSR and JSRSD results appear overexposed. In particular, the JSRSD method introduces a certain amount of noise. The pedestrian and car became blurry by the GTF and DRTV methods. Regarding deep-learning-based methods, the fusion results of FusionGAN, DDcGAN, and DRF appear blurry. Specifically, the pedestrian and car through FusionGAN and DDcGAN methods were blurred, and trees and buildings through the DRF method were blurred. Since this example is a daytime scene, most of the visible image details are required. Although GANMcC, PMGI, RFN-Nest, CSF, and FusionDN methods achieved a good fusion effect, too many “small black dots” from IR images were introduced into the trees, resulting in an unnatural visual experience (see green boxes in Figure 9o–r,t). Compared with other algorithms, our algorithm can extract the pedestrian and car in the IR images well, and the results look more natural.

Figure 9.
Fusion results of the “FLIR04602” source images.

Figure 10.
Fusion results of the “FLIR08835” source images.
Figure 10 shows the fusion results of “FLIR08835” source images. The described scene contains rich content, including pedestrians, a street, and buildings. On the one hand, the IR image mainly extracts the thermal radiation information of the pedestrians to better display the locations of pedestrians. On the other hand, visible image provides clearer background details. The MSVD algorithm cannot extract thermal radiation information well. The DWT, DTCWT, CVT, TE-MST, and MLGCF fusion results all introduce some noise. The JSM fusion result is blurry, and JSR and JSRSD methods appear overexposed. The GTF method achieved great fusion performance, and the background areas in the DRTV algorithm’s images are obviously blurry (see the green box in Figure 10m). The pedestrians in the FusionGAN, DRF, RFN-Nest and DDcGAN algorithms’ images are blurry (see red and orange boxes in Figure 10n,s,q,u). The CSF method introduced some noise into the background. The GANMcC, PMGI, and FusionDN schemes achieved high fusion performance. Based on the above observations, it is clear that our algorithm captures the thermal radiation information of pedestrians well and has a great fusion effect. It can be at least stated that our method achieves competitive performance with the GANMcC, PMGI, and FusionDN methods.
Table 5 shows the averages of 13 objective evaluation metrics for the RoadScene dataset and the best values are indicated in red. It can be seen in Table 5 that, except for , , , and , the proposed fusion method achieved the best results for all other metrics.
Table 5.
The average values of different methods on the RoadScene dataset.
Overall, it was found that the 19 competitive algorithms all suffer from some defects. Considering the above comparisons in relation to visual quality and objective evaluation metrics together, our algorithm can generally outperform other methods, leading to state-of-the-art fusion performance.
4.6. Computational Efficiency
To compare the computational efficiency, we ran all deep learning algorithms on the TNO dataset 10 times and took the average running time. It is worth noting that our experimental hardware environment was an Intel (R) Core (TM) i7-11700 with 64 GB RAM, but the experimental environments for various algorithms were different. The FusionGAN, GANMcC, PMGI, CSF, DRF, FusionDN, and DDcGAN methods used TensorFlow (CPU version). The RFN-Nest method used Pytorch (CPU version). Our algorithm was implemented in Matlab. All parameters in the comparison algorithms were the default values given by their authors. Table 6 shows the average time of 10 operations, and the optimal value is shown in red font. The running time of our algorithm achieved fourth place, namely, 255.6642 s, behind PMGI, FusionGAN, and RFN-Nest methods. Although the running time of our algorithm obtained fourth place, our fusion effect is state of the art.
Table 6.
The average running time of different methods for the TNO dataset (unit: seconds).
5. Conclusions
In this paper, we propose a fusion method for IR and visible images based on PCANet and the image pyramid method. We use PCANet to obtain the activity-level measurement and weight assignment and apply an image pyramid to decompose and merge the images in multiple scales. The activity-level measurement obtained by PCANet has the stronger representation ability in focusing on IR target perception and visible detail description. We performed two ablation studies to verify the effectiveness of the image pyramid and the guided filter. Compared with nineteen representative methods, the experimental results demonstrated that the proposed method can achieve the state-of-the-art performance in both visual quality and objective evaluation metrics. However, we only used the results of the second stage of PCANet as image features, ignoring the useful information of the first stage. In the future research, we will explore combining features of multiple stages for fusion tasks.
Author Contributions
Conceptualization, S.L.; methodology, S.L.; software, S.L.; validation, S.L., G.W., Y.Z. and C.L.; formal analysis, S.L.; investigation, S.L.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, S.L., G.W. and Y.Z.; project administration, G.W. and Y.Z.; funding acquisition, G.W. and Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by the National Natural Science Foundation of China (62175054, 61865005, and 61762033), the Natural Science Foundation of Hainan Province (620RC554 and 617079), the Major Science and Technology Project of Haikou City (2021-002), the Open Project Program of Wuhan National Laboratory for Optoelectronics (2020WNLOKF001), the National Key Technology Support Program (2015BAH55F04 and 2015BAH55F01), the Major Science and Technology Project of Hainan Province (ZDKJ2016015), and the Scientific Research Staring Foundation of Hainan University (KYQD(ZR)1882).
Data Availability Statement
The data are not publicly available.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qi, B.; Jin, L.; Li, G.; Zhang, Y.; Li, Q.; Bi, G.; Wang, W. Infrared and Visible Image Fusion Based on Co-Occurrence Analysis Shearlet Transform. Remote Sens. 2022, 14, 283. [Google Scholar] [CrossRef]
- Gao, X.; Shi, Y.; Zhu, Q.; Fu, Q.; Wu, Y. Infrared and Visible Image Fusion with Deep Neural Network in Enhanced Flight Vision System. Remote Sens. 2022, 14, 2789. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Naidu, V. Image fusion technique using multi-resolution singular value decomposition. Defence Sci. J. 2011, 61, 479. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.; Mitra, S.K. Multisensor image fusion using the wavelet transform. Gr. Models Image Process. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, C. Texture clear multi-modal image fusion with joint sparsity model. Optik 2017, 130, 255–265. [Google Scholar] [CrossRef]
- Zhang, Q.; Fu, Y.; Li, H.; Zou, J. Dictionary learning method for joint sparse representation-based image fusion. Opt. Eng. 2013, 52, 057006. [Google Scholar] [CrossRef]
- Liu, C.; Qi, Y.; Ding, W. Infrared and visible image fusion method based on saliency detection in sparse domain. Infrared Phys. Technol. 2017, 83, 94–102. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, H.; Ma, J. Classification saliency-based rule for visible and infrared image fusion. IEEE Trans. Comput. Imaging 2021, 7, 824–836. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavel. Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–7. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th international conference on pattern recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Li, H.; Wu, X.J.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion. In Proceedings of the 15th Pacific Conference on Computer Graphics and Applications (PG’07), Seoul, Republic of Korea, 29 October–2 November 2007; pp. 382–390. [Google Scholar]
- Piella, G. A general framework for multiresolution image fusion: From pixels to regions. Inf. Fusion 2003, 4, 259–280. [Google Scholar] [CrossRef]
- Wang, S.; Chen, L.; Zhou, Z.; Sun, X.; Dong, J. Human fall detection in surveillance video based on PCANet. Multimed. Tools Appl. 2016, 75, 11603–11613. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q. Automatic change detection in synthetic aperture radar images based on PCANet. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1792–1796. [Google Scholar] [CrossRef]
- Song, X.; Wu, X.J. Multi-focus image fusion with PCA filters of PCANet. In Proceedings of the IAPR Workshop on Multimodal Pattern Recognition of Social Signals in Human–Computer Interaction, Beijing, China, 20 August 2018; pp. 1–17. [Google Scholar]
- Yang, W.; Si, Y.; Wang, D.; Guo, B. Automatic recognition of arrhythmia based on principal component analysis network and linear support vector machine. Comput. Biol. Med. 2018, 101, 22–32. [Google Scholar] [CrossRef]
- Zhang, G.; Si, Y.; Wang, D.; Yang, W.; Sun, Y. Automated detection of myocardial infarction using a gramian angular field and principal component analysis network. IEEE Access 2019, 7, 171570–171583. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/TN_Image_Fusion_Dataset/1008029 (accessed on 21 September 2022).
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12484–12491. [Google Scholar]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 15–17 October 2014; pp. 1–3. [Google Scholar]
- Shreyamsha Kumar, B. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. 173. [Google Scholar]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 2007, 3, 1433–1447. [Google Scholar]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Tan, W.; Zhou, H.; Song, J.; Li, H.; Yu, Y.; Du, J. Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 2019, 58, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Ma, J. DRF: Disentangled representation for visible and infrared image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).