

TChange: A Hybrid Transformer-CNN Change Detection Network


Abstract
1. Introduction
- We propose a hybrid transformer–CNN change detection network named TChange. Under the condition of maintaining a low computational cost, the network can globally and efficiently model the features within the scale and provide a direct information exchange channel for features across scales.
- A novel MSA module named Change MSA is proposed to acquire global feature and pairwise feature information within scales. In addition, a new feature fusion method, which conducts MSA companies in the channel dimension rather than the spatial dimension by channel crossing, is proposed for change detection tasks. The offset induction of CNNs is used to enhance the local modeling ability of MSA.
- An interscale transformer module (ISTM) is proposed to build a multiscale feature exchange channel.
- A new remote sensing change detection dataset named TZ-CD is constructed by taking into account changed regions with various areas, which compensates for the lack of scenarios in the current change detection public dataset.
2. Materials and Methods
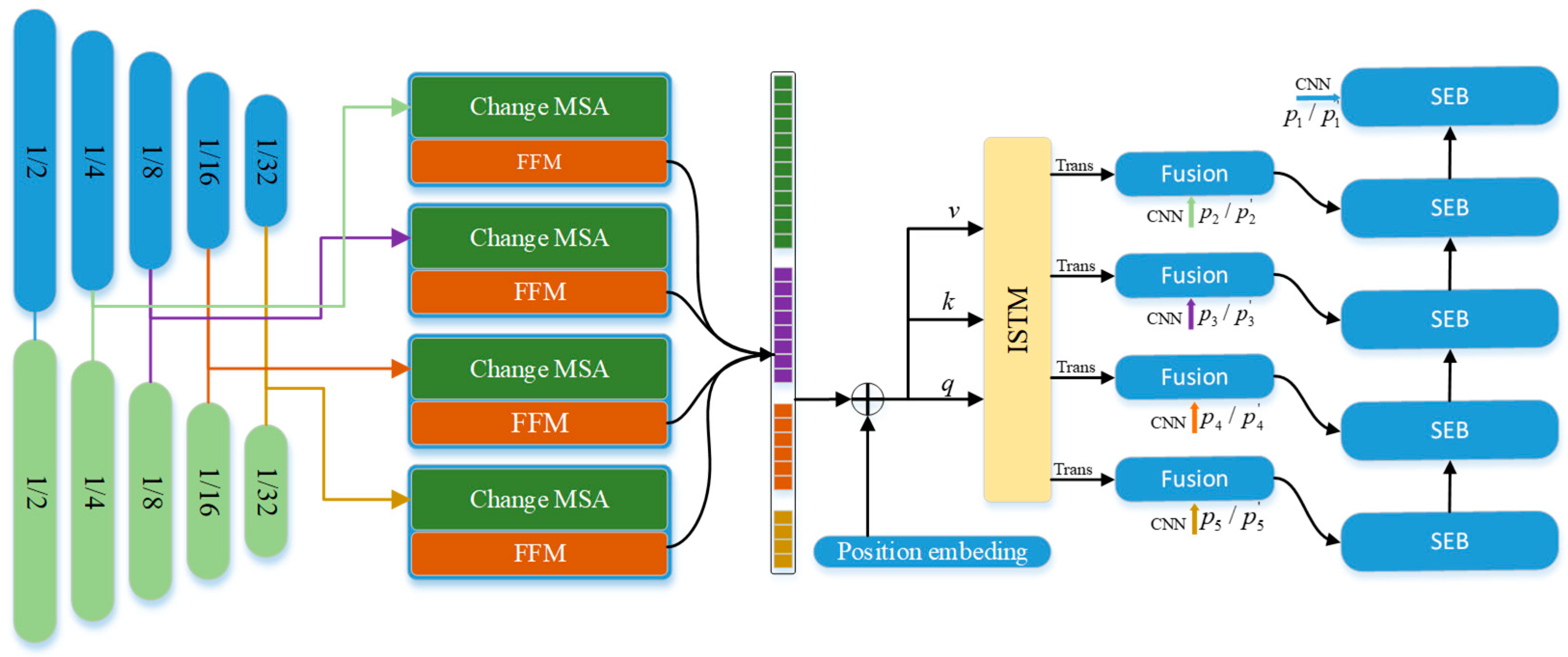
2.1. Overview
2.2. Encoder
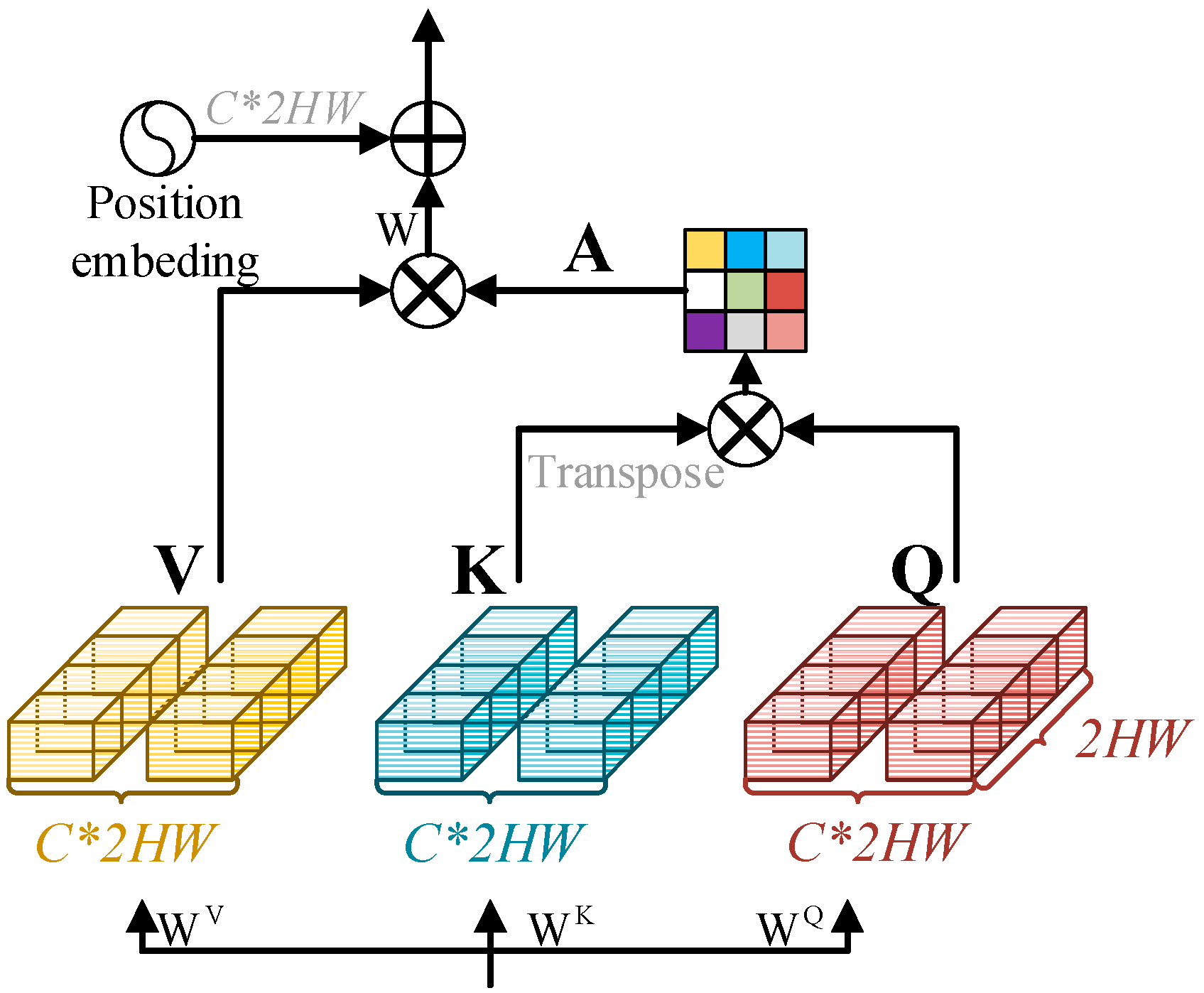
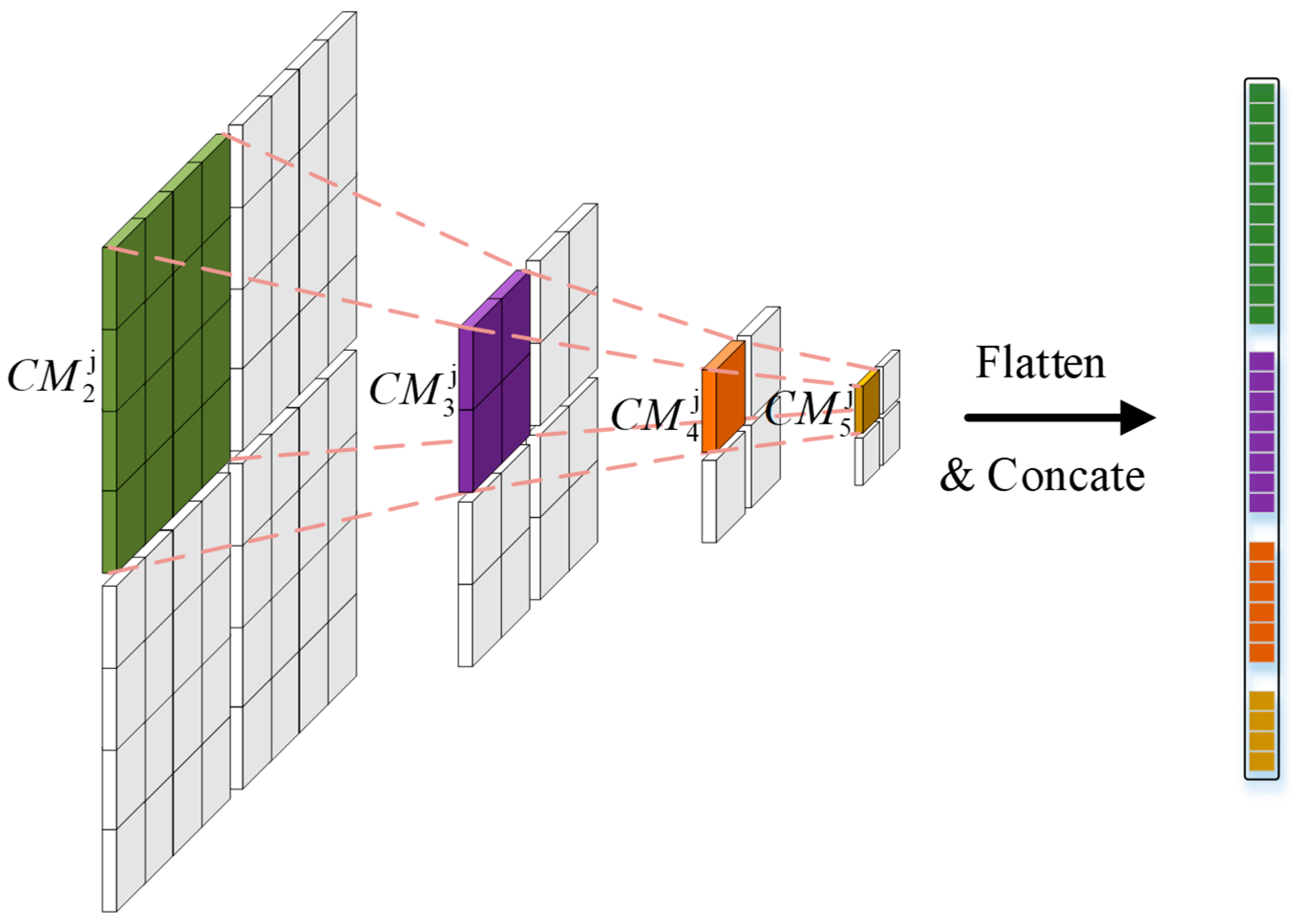
2.3. ChangMSA
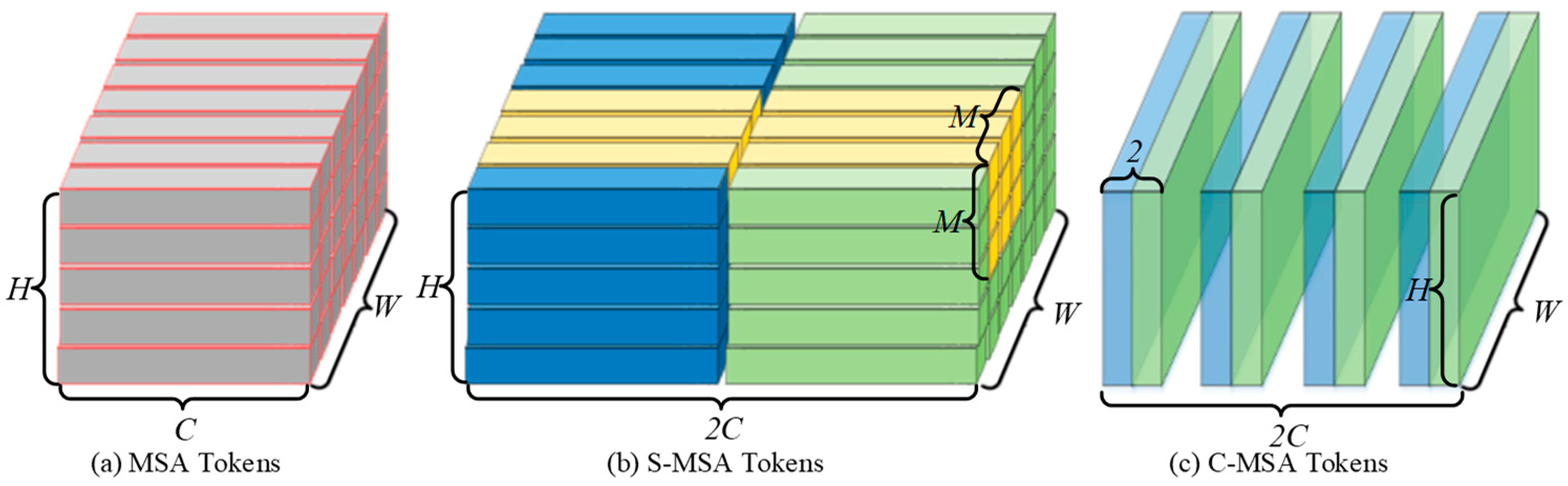
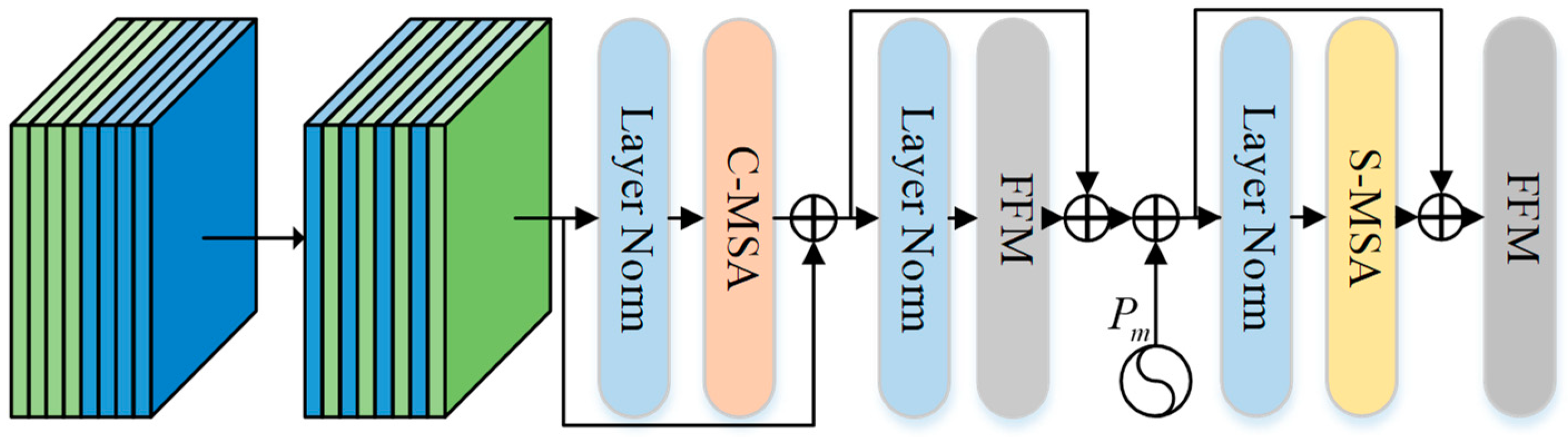
2.3.1. C-MSA
2.3.2. S-MSA
2.3.3. FFM
2.3.4. Change MSA Summary
2.4. The Inter-Scale Transformer Module
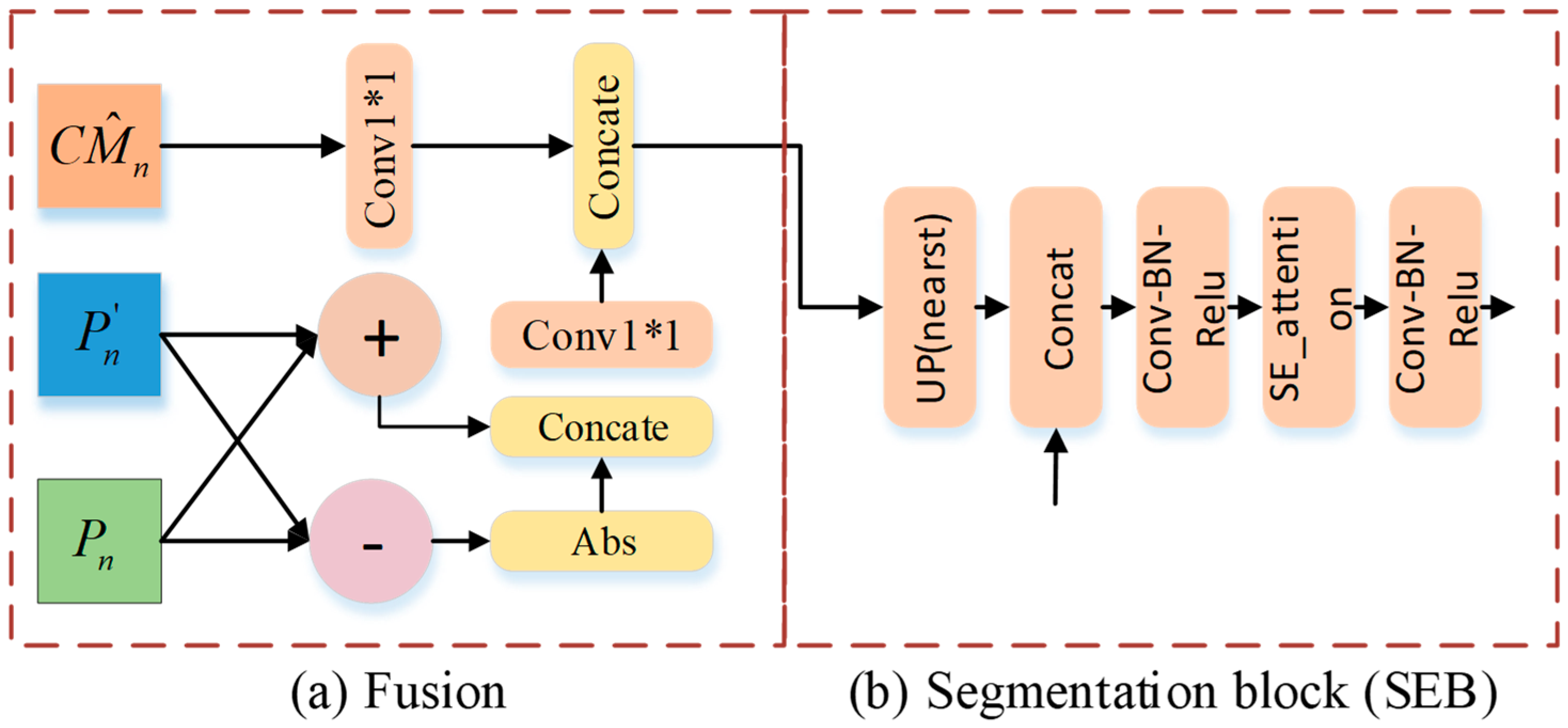
2.5. The CNN Decoder
2.6. Output and Deep Edge Supervision
3. Datasets
3.1. The Pubilc Dataset
3.2. The TZ-CD Dataset
4. Experiments
4.1. Evaluation
4.2. Implementation Details
4.3. Ablation Studies
4.4. Comparative Method
- FC-EF, FC-conc and FC-diff [15]: FC-EF follows the semantic segmentation scheme. First, the pre-image and post-image are overlapped. Second, the images are input to the encoder for encoding. Third, the segmentation result is obtained by the decoder. FC-conc replaces the single encoder in FC-EF with a twin encoder, the pairwise features are merged by a simple concatenation operation, and then the region change result is decoded by the decoder. FC-diff replaces the concatenate operator with diff for the pairwise feature fusion part based on FC-EF.
- BiDataNet [51]: BiDataNet is a single encoder change detection segmentation scheme that combines LSTM and UNet for better encoding of long-range information and communication of features between two different time phases.
- CDNet [52]: CDNet is a single encoder change detection network. This network is mainly utilized for road change detection, so its convolution size is modified from the commonly employed 3 * 3 to 7 * 7 to expand the receptive field.
- Unet++_MSOF [53]: Unet++_MSOF adds lateral connections to the regular Unet’s shortcut connections to provide more communication channels with different scale features.
- DDCNN [18]: DDCNN proposes a dense attention method consisting of several upsampling attention units to model the internal correlation between high-level features and low-level features.
- BIT [40]: BIT is the first change detection network with a transformer. First, the convolutional neural network provides multiscale features. Second, 2 features are obtained by the transformer decoder. Last, the change region is obtained based on the difference in the features.
- DMATNet [41]: DMATNet is a dual-feature mixed attention-based transformer network. First, the twin encoder is used for feature extraction, Then, fuse the fine and coarse features with dual-feature mixed attention (DFMA) module.
4.5. Results on the LEVIR-CD
4.6. Results on the WUH-CD
4.7. Results on the TZ-CD
4.8. Efficiency Comparison Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Asokan, A.; Anitha, J. Change detection techniques for remote sensing applications: A survey. Earth Sci. Inf. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Howarth, P.J.; Wickware, G.M. Procedures for change detection using Landsat digital data. Int. J. Remote Sens. 1981, 2, 277–291. [Google Scholar] [CrossRef]
- Ludeke, A.K.; Maggio, R.C.; Reid, L.M. An analysis of anthropogenic deforestation using logistic regression and GIS. J. Environ. Manag. 1990, 31, 247–259. [Google Scholar] [CrossRef]
- Coppin, P.R.; Bauer, M.E. Digital change detection in forest ecosystems with remote sensing imagery. Remote Sens. Rev. 1996, 13, 207–234. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Malila, W.A. Change Vector Analysis: An Approach for Detecting Forest Changes with Landsat; IEEE: Piscataway, NJ, USA, 1980; p. 385. [Google Scholar]
- Chen, J.; Gong, P.; He, C.; Pu, R.; Shi, P. Land-use/land-cover change detection using improved change-vector analysis. Photogramm. Eng. Remote Sens. 2003, 69, 369–379. [Google Scholar] [CrossRef]
- Miller, A.B.; Bryant, E.S.; Birnie, R.W. An analysis of land cover changes in the Northern Forest of New England using multitemporal Landsat MSS data. Int. J. Remote Sens. 1998, 19, 245–265. [Google Scholar] [CrossRef]
- Yuan, F.; Sawaya, K.E.; Loeffelholz, B.C.; Bauer, M.E. Land cover classification and change analysis of the Twin Cities (Minnesota) Metropolitan Area by multitemporal Landsat remote sensing. Remote Sens. Environ. 2005, 98, 317–328. [Google Scholar] [CrossRef]
- Ji, W.; Ma, J.; Twibell, R.W.; Underhill, K. Characterizing urban sprawl using multi-stage remote sensing images and landscape metrics. Comput. Environ. Urban Syst. 2006, 30, 861–879. [Google Scholar] [CrossRef]
- Cheng, H.; Wu, H.; Zheng, J.; Qi, K.; Liu, W. A hierarchical self-attention augmented Laplacian pyramid expanding network for change detection in high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 182, 52–66. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. Hdfnet: Hierarchical dynamic fusion network for change detection in optical aerial images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection; IEEE: Piscataway, NJ, USA, 2018; pp. 4063–4067. [Google Scholar]
- Chen, H.; Wu, C.; Du, B.; Zhang, L. Deep Siamese Multi-Scale Convolutional Network for Change Detection in Multi-Temporal VHR Images; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- Hou, B.; Liu, Q.; Wang, H.; Wang, Y. From W-Net to CDGAN: Bitemporal change detection via deep learning techniques. IEEE Trans. Geosci. Remote Sens. 2019, 58, 1790–1802. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical remote sensing image change detection based on attention mechanism and image difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P. Looking for change? Roll the dice and demand attention. Remote Sens. 2021, 13, 3707. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar] [CrossRef]
- Chen, P.; Li, C.; Zhang, B.; Chen, Z.; Yang, X.; Lu, K.; Zhuang, L. A Region-Based Feature Fusion Network for VHR Image Change Detection. Remote Sens. 2022, 14, 5577. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, B.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101. [Google Scholar] [CrossRef]
- Mao, Z.; Tong, X.; Luo, Z.; Zhang, H. MFATNet: Multi-Scale Feature Aggregation via Transformer for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 5379. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building Change Detection in Remote Sensing Images Based on Dual Multi-Scale Attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyska, M.J.; Huo, Y. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef]
- Yao, T.; Qu, C.; Liu, Q.; Deng, R.; Tian, Y.; Xu, J.; Jha, A.; Bao, S.; Zhao, M.; Fogo, A.B. Compound Figure Separation of Biomedical Images with Side Loss; Springer: Berlin/Heidelberg, Germany, 2021; pp. 173–183. [Google Scholar]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction is What You Need for Change Detection. arXiv 2022, arXiv:2209.08290. [Google Scholar]
- Feng, S.; Fan, Y.; Tang, Y.; Cheng, H.; Zhao, C.; Zhu, Y.; Cheng, C. A Change Detection Method Based on Multi-Scale Adaptive Convolution Kernel Network and Multimodal Conditional Random Field for Multi-Temporal Multispectral Images. Remote Sens. 2022, 14, 5368. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, A.; Zhang, L.; Zhong, Y. Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery; IEEE: Piscataway, NJ, USA, 2021; pp. 15193–15202. [Google Scholar]
- Deng, Y.; Chen, J.; Yi, S.; Yue, A.; Meng, Y.; Chen, J.; Zhang, Y. Feature Guided Multitask Change Detection Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9667. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Shi, Z. Adversarial Instance Augmentation for Building Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image Transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-Attention Mask Transformer for Universal Image Segmentation; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1290–1299. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows; ICCV: Santiago, Chile, 2021; pp. 10012–10022. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Zhang, L.; Ni, L.M.; Shum, H.-Y. Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation. arXiv 2022, arXiv:2206.02777. [Google Scholar]
- Wu, Y.; Liao, K.; Chen, J.; Wang, J.; Chen, D.Z.; Gao, H.; Wu, J. D-former: A u-shaped dilated transformer for 3d medical image segmentation. Neural Computing and Applications Neural Comput. Appl. 2022, 35, 1931–1944. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. Remote Sensing Image Change Detection Transformer Network Based on Dual-Feature Mixed Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure transformer network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.-S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Asymmetric siamese networks for semantic change detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. In Proceedings of the ICLR 2018 Conference, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Papadomanolaki, M.; Verma, S.; Vakalopoulou, M.; Gupta, S.; Karantzalos, K. Detecting urban changes with recurrent neural networks from multitemporal Sentinel-2 data. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 214–217. [Google Scholar]
- Sakurada, K.; Okatani, T. Change Detection from a Street Image Pair using CNN Features and Superpixel Segmentation. In Proceedings of the Procedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association and Society for Pattern Recognition: Durham, UK, 2015; pp. 1–12. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| base | 80.81 | 81.73 | 81.27 | 68.45 |
| Base + C-MSA | 75.74 | 82.76 | 79.10 | 65.42 |
| Base + C-MSA + FFM | 85.72 | 80.52 | 83.05 | 71.01 |
| Base + Change MSA | 84.79 | 83.05 | 83.91 | 72.27 |
| ISTM | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| No | 84.79 | 83.05 | 83.91 | 72.27 |
| Yes | 84.46 | 84.64 | 84.55 | 73.23 |
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| Base | 80.81 | 81.73 | 81.27 | 68.45 |
| Base + deep supervision | 86.37 | 77.49 | 81.69 | 69.04 |
| Base + deep edge supervision | 81.24 | 81.97 | 81.60 | 68.92 |
| TChange | 84.46 | 84.64 | 84.55 | 73.23 |
| TChange + deep supervision | 91.18 | 80.00 | 85.21 | 74.23 |
| TChange + deep edge supervision | 90.42 | 81.11 | 85.51 | 74.70 |
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| FC-EF [15] | 79.20 | 81.72 | 80.44 | 67.27 |
| FC-conc [15] | 91.46 | 88.05 | 89.72 | 81.36 |
| FC-diff [15] | 89.92 | 89.00 | 89.45 | 80.92 |
| BiDataNet [51] | 92.50 | 87.14 | 89.74 | 81.39 |
| CDNet [52] | 90.73 | 86.82 | 88.73 | 79.75 |
| Unet++_MSOF [53] | 92.18 | 87.84 | 89.96 | 81.75 |
| DDCNN [18] | 91.85 | 88.69 | 90.24 | 82.21 |
| BIT [40] | 89.24 | 89.37 | 89.31 | 80.68 |
| DMATNet [41] | 91.56 | 89.98 | 90.75 | 84.13 |
| TChange | 93.47 | 91.94 | 92.27 | 85.65 |
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| FC-EF [15] | 85.27 | 75.11 | 79.87 | 66.49 |
| FC-conc [15] | 92.67 | 55.59 | 69.49 | 53.25 |
| FC-diff [15] | 88.76 | 66.40 | 75.97 | 61.25 |
| BiDataNet [51] | 93.44 | 87.66 | 90.46 | 82.58 |
| CDNet [52] | 87.64 | 81.43 | 84.42 | 73.04 |
| Unet++_MSOF [53] | 93.03 | 86.29 | 89.53 | 81.05 |
| DDCNN [18] | 96.11 | 89.73 | 92.81 | 86.59 |
| BIT [40] | 86.64 | 81.48 | 83.98 | 72.39 |
| DMATNet [41] | 83.87 | 82.24 | 85.70 | 74.98 |
| TChange | 94.70 | 93.22 | 93.96 | 88.60 |
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| FC-EF [15] | 47.66 | 82.29 | 60.36 | 43.23 |
| FC-conc [15] | 78.79 | 74.16 | 76.41 | 61.82 |
| FC-diff [15] | 57.78 | 90.81 | 70.62 | 54.59 |
| BiDataNet [51] | 67.93 | 86.40 | 76.06 | 61.37 |
| CDNet [52] | 73.62 | 75.69 | 74.64 | 59.55 |
| Unet++_MSOF [53] | 79.90 | 80.11 | 80.00 | 66.68 |
| DDCNN [18] | 89.00 | 76.90 | 82.50 | 70.21 |
| BIT [40] | 73.58 | 82.04 | 77.58 | 63.37 |
| TChange | 90.42 | 81.11 | 85.51 | 74.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Meng, Y.; Chen, J.; Yue, A.; Liu, D.; Chen, J. TChange: A Hybrid Transformer-CNN Change Detection Network. Remote Sens. 2023, 15, 1219. https://doi.org/10.3390/rs15051219
Deng Y, Meng Y, Chen J, Yue A, Liu D, Chen J. TChange: A Hybrid Transformer-CNN Change Detection Network. Remote Sensing. 2023; 15(5):1219. https://doi.org/10.3390/rs15051219
Chicago/Turabian StyleDeng, Yupeng, Yu Meng, Jingbo Chen, Anzhi Yue, Diyou Liu, and Jing Chen. 2023. "TChange: A Hybrid Transformer-CNN Change Detection Network" Remote Sensing 15, no. 5: 1219. https://doi.org/10.3390/rs15051219
APA StyleDeng, Y., Meng, Y., Chen, J., Yue, A., Liu, D., & Chen, J. (2023). TChange: A Hybrid Transformer-CNN Change Detection Network. Remote Sensing, 15(5), 1219. https://doi.org/10.3390/rs15051219