1. Introduction
Flooding is a significant concern all over the world. In global disaster assessment reports, it consistently ranks among the most destructive of natural disasters. Unfortunately, flood frequency and severity are expected to increase for most of the world due to climate change [
1], with further increased human exposure due to population growth. Therefore, rapid assessments of flood extent and impacts using Earth observation satellites are of great importance. Due to their capacity to capture high-resolution images of the Earth’s surface even in stormy weather, Synthetic Aperture Radar (SAR) sensors are unrivaled in their capability to map large-scale flooding. Hence, most disaster mapping services, such as the Copernicus Emergency Management Service (CEMS) [
2], and the Sentinel Asia initiative [
3] utilize SAR satellites for their operations. In the past, these services have delivered SAR-based flood maps only upon requests from affected areas, manually operated by human experts. This implies that flood events may be missed in the case of late or non-activation. To avoid this and improve timeliness, CEMS has recently launched a Global Flood Monitoring (GFM) service that analyses Sentinel-1 SAR data in a fully automatic fashion [
4].
In principle, mapping flood extent from SAR images is relatively straightforward given that backscatter from open water bodies is normally relatively low compared to backscatter from the surrounding land surface areas. Thus, when mapping flooded areas from individual SAR images on demand, SAR image analysts usually work with simple thresholding techniques. However, selecting a threshold value that works everywhere under all weather conditions is clearly impossible [
5,
6]. Therefore, in the fully automatic GFM service, a relatively simple problem turns into the significant scientific challenge of finding a robust flood detection model that works globally without the need for manual fine-tuning of its parameters.
A large variety of methods to map flood extent from SAR imagery has already been published, including change detection-based approaches [
7,
8], split-window or tiled thresholding techniques [
5,
9,
10,
11], Bayesian [
12,
13,
14,
15,
16] and machine learning methods [
17,
18,
19]. Most studies yielded excellent results for specific test areas, but the performance on a large scale is often not known [
20]. Moreover, while reviews and assessments of these SAR flood and inundation mapping methods are available [
21,
22,
23], it has been pointed out that direct performance comparisons are limited [
24]. However, such comparisons are crucial in designing and improving operational systems that perform at large scales, e.g., regional or global extents. Last but not least, distinct parameterizations might be required for these methods to perform at the same level in different areas. Thus, the robustness of parameterization is a crucial indicator when selecting flood mapping workflows for implementation at scale [
25,
26,
27]. Unfortunately, this aspect usually is not treated explicitly in the scientific literature so far.
For the design of robust flood detection models and their parameterization, it is highly advantageous to work with SAR backscatter data cubes that allow efficient access to the data not just in the spatial but also temporal dimension [
28,
29]. Using the Sentinel-1 backscatter data cube built up at the Earth Observation Data Centre (EODC) [
30], it has, e.g., been possible to parameterize a Bayesian flood detection model at the level of individual pixels by analyzing backscatter time series for each pixel [
27]. Another example is the Sentinel-1 data cube implementation at the Google Earth Engine [
31], which already hosts several waterbody and flood mapping workflows [
32,
33].
In this contribution, we compare the performance of four change detection models for mapping floods using Sentinel-1 SAR data (
Section 2). Compared to approaches that map floods only based on single SAR images, the parameterization of change detection models is normally less problematic, allowing to apply them over large and diverse domains. Nonetheless, even the parameterization of change detection models may involve a lot of choices that can have a strong impact on the accuracy of the derived flood maps, in particular, the choices of the no-flood reference image and the threshold for labeling an SAR pixel as flooded. Hence, in our study, we investigated how sensitive the different model are to changes in their parameterization.
As a study case, we chose a flood event that occurred in the Cagayan river basin in the Northern Philippines in November 2020. This choice was motivated by the fact that the area, which is situated in the Pacific typhoon belt, is projected to be significantly impacted by climate change, including a general rise in precipitation with an indication of higher frequency of heavy rainfall events [
34] and, consequently, a greater threat of flooding [
35]. The study region and data are described in
Section 3. The methods for intercomparing the four change detection models and assessing the robustness of their parameterizations are introduced in
Section 4, followed by the presentation of the results on parametrization and model-intercomparison in
Section 5 and
Section 6. Finally,
Section 7 contains the discussion and conclusions.
4. Methods
To compare the performance of the four change detection models and their sensitivity to changes in their parameterization, we follow a two step approach: In the first step, we assess for each change detection model separately how different parameterizations impact the results. As we are only interested in the relative performance of the parameterizations when applying the models to Sentinel-1 data, the benchmark in this step is the Sentinel-1 flood map produced by the experts of Sentinel Asia. In the second step, we intercompare the performance of the four change detection models with their best-performing parameterizations by assessing their accuracy against the Sentinel-2 flood map.
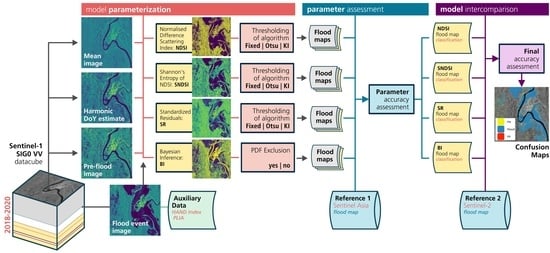
The detailed workflow is shown in
Figure 4. The starting point is the Sentinel-1 backscatter data cube from which all required VV backscatter images from relative orbit 69 and the corresponding projected local incidence angle (PLIA) are extracted. Furthermore, a common set of geomorphological and exclusion masking post-processing steps are applied to all flood maps. First, the Height Above Nearest Drainage (HAND) index is used to mask for terrain distortions in the SAR data, such as radar shadow and layover [
49] at a height above 20 m (in this case) from drainage. Second, a PLIA mask is applied to remove pixels which have PLIA outside the typical range of incidence angles for flat areas (where floods are typically appearing), following the approach by [
27]. These masks helped to reduce the number of falsely classified flood pixels over the mountainous parts of the study area—which are generally troubling SAR retrievals—thereby slightly improving the accuracy of the flood maps. Lastly,
spatial majority filters are applied as a morphological correction of salt-and-pepper-like classification coming from SAR signal components unrelated to flood conditions.
4.1. Paramterizations
To test the NDSI, SNDSI, and SR models —and their parameterizations—we computed a multitude of flood maps using different combinations of the no-flood reference and the thresholding technique to parameterize the models. Here, we show the results for the combination of three no-flood references and three different thresholds, yielding in total 3 × 3 × 3 = 27 flood maps. With respect to the no-flood reference, the three used parameterizations are:
Mean Backscatter: We computed the mean and standard deviation of per pixel over the three year long data record (2018–2020). Note that while the NDSI and SNDSI only require the mean as input, the SR requires both the mean and .
Harmonic Model: To account for seasonal signal variations, we fitted a harmonic model to the data record, yielding for each pixel and each day of year (DOY) an estimate of the expected backscatter intensity and its standard deviation, respectively. For a detailed description of this Harmonic model formulation we refer the readers to the recent work of Bauer-Marschallinger et al. [
27].
Pre-flood Image: A Sentinel-1 image acquired about two weeks before the flood event on 1 November 2020 and from the same relative orbit was selected as no-flood reference of the backscatter intensity. As the SR and BI models also require an estimate of the backscatter dynamics, we compute , similar to harmonic formulation, using the Root Mean of Square of the difference between backscatter in the time-series data record and the expected no-flood backscatter (from pre-flood image).
The three models NDSI, SNDSI, and SR require a threshold for label pixels as either flood or no-flood. In the course of finding an optimal threshold, we apply the simple pre-filtering technique applied by Schlaffer et al. [
7] using the HAND index, where the pixels of high HAND values, i.e., HAND > 20, are removed from the histogram before thresholds are determined.
We tested three different methods to determine the threshold:
Fixed: Here, we rely on published reports. Among the NDSI and SNDSI implementations, thresholds from the work of Ulloa et al. [
36] were adopted. These are −0.725 for NDSI and 0.78 for SNDSI. While for SR a fixed value of −1.5 was found by several studies to provide good results [
8].
Otsu: In the method of Otsu [
39], an assumption of bi-modality is followed by fitting two distributions by minimizing intra-class intensity variance. Hence, we determine the threshold from the intersection of the fitted distributions within our reference- and flood-images.
Kittler and Illingsworth (KI): As an alternative we also tested the KI method [
40]. Also known as the Minimum-Error thresholding method, it seeks to fit the two distributions, using the minimum error criterion, to a given model histogram. Hence, the threshold is similarly determined from the intersection of the fitted distributions as with Otsu above.
To test the BI model, we employ the same three no-flood reference parameterizations to derive the full conditional probability function
. While BI does not rely on parameterized thresholds, we test the application (and non-application) of distribution-based masking methods introduced in the previous work of Bauer-Maschallinger et al. [
27]. Accordingly, the BI method is improved by excluding pixels with high classification uncertainty, either from very similar a priori distributions for flood and no-flood, or from actual observation values that fall in-between the two. Consequently, the significant Probability Density Function (PDF) overlap between flooded and non-flooded classes, and in this paper, we refer to this as PDF exclusion mask. Hence, for BI we test 1 × 3 × 2 = 6 parameterizations, and finally obtain a set of 33 flood maps for our experiment.
4.2. Accuracy Assessment
The flood maps are evaluated by comparing them to the two reference flood maps described in
Section 3.3. Given that these two expert-produced reference maps also do not represent an absolute “truth”, the computed accuracy metrics must be interpreted with some caution. Nonetheless, as we are mostly interested in understanding the relative performances of the algorithms and their parameterizations, they represent a good benchmark.
We computed traditional land cover classification metrics: Overall Accuracy (OA), Producer’s Accuracy (PA), and User’s Accuracy (UA). OA was selected over chance agreement corrected metric, i.e., Kappa coefficient, from recommendation in the literature [
50,
51]. In addition, we calculate the Critical Success Index (CSI), which is often used in data science and flood mapping work to address the inequality of the classes. CSI has been specifically found to provide good insights for flood mapping accuracy assessments at the same scale [
24]. All of these metrics were computed from a binary confusion matrix and its four elements: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN), among classified pixels, according to the following formulas:
Following good practice examples and sampling size determination equations from Foody’s work [
52], we acquired a total of 5000 random samples. Independent random samples per change detection model were taken to remove possible bias in the application of model-dependent exclusion masks. From this, we surmise that a difference greater than 2% in OA implies a consequential distinction between the results.
5. Model Parameter Assessment
In this section, we analyze the sensitivity of the four change detection models to changes in their parameterization by comparing the derived flood maps to the Sentinel-1 reference flood map produced by Sentinel Asia (
Section 5.1,
Section 5.2,
Section 5.3 and
Section 5.4). Furthermore, we select the best performing parameterizations for each method to be subject of our model inter-comparison in
Section 6.
To allow a well-founded interpretation of the performance of the four models, we first examine their statistical bases used for the distinction between flood and no flood.
Figure 5 shows the histograms and maps of the observed backscatter
together with the calculated NDSI, SNDSI, SR, and BI with, as an example, the mean image as no-flood reference. From this compilation, it can be observed that the histograms of the model values allow in most cases an improved distinction between flooded and non-flooded sections, compared with the initial flooded
image. Generally, the decrease in backscatter during floods is highlighted, and the change detection models show—as expected—increased image contrast and more distributed histograms. The SR map (
Figure 5m–p), however, appears to highlight different signatures within the observed
image while not transforming the shape of the histogram. Another observation is that particularly the SR and BI data manage to register the pattern from the permanent water surfaces along the river, thus supporting the delineation against flood bodies.
For the whole area, NDSI (
Figure 5e–h) provides the most considerable increase in the relative spread of values. The SNDSI (
Figure 5i–l) shows less improvement in this regard, but reduces the spatial dispersion of these values compared with NDSI, which structurally features a noise-like spatial pattern (see e.g., in
Figure 5h). Meanwhile, SR shows the least gain in contrast, and we would argue that there is no significant effect on the separability of the classes in its histogram (see in
Figure 5m). This is most apparent in permanent low backscatter areas, such as the river pixels, that are not as well delineated as for the other methods (see in
Figure 5p).
Concerning the threshold parameters (indicated by colored lines in the histograms of
Figure 5), speciffically for SR and
, we observe that the respective Otsu and KI thresholds follow the same characteristics described by [
24]. The results show more liberal flood labeling for Otsu’s method and more conservative labeling using KI. Meanwhile, the NDSI and SNDSI indicate significant variance and instability when it comes to finding the respective thresholds. This could be attributed to the seemingly non-Gaussian distributions of the non-flood class and flood class (as observed in
Figure 5e,i), noting that these thresholding algorithms assume Gaussian distributions.
In the BI model data (
Figure 5q–t), most of the visually perceived flooded areas were successfully assigned with high flood probability. Overall, the Bayes probability values show intriguing results, as the river pixels show a low flood probability in spite of the locally significant distribution overlaps coming from the river/water signature. While this is a positive result, this behavior could easily swing from non-flooded and flooded classes, as seen in the salt and pepper appearance of probability values along the river (see in
Figure 5t). This similar noise-like appearance is also apparent in the probability values found in agricultural areas.
5.1. Parameterization of NDSI Model
We now examine the NDSI model and the performance of its different parameterizations. As shown in
Table 2, the harmonic approach performs best of the no-flood references, while KI performs best of the threshold methods. Consequently, the combination of these two (represented by parameterization no. 6) builds the favored parametrization. This combination features a CSI value larger than 85%. One can observe the significant variance in the UA, ranging from moderate (59%) to excellent performance (97%). In contrast, the PA has smaller differences, with most showing excellent results above 90%. This suggests that the models favor, in general, overestimation. Thus, KI thresholding is a proper method to dampen this effect. One can also notice the erratic performance of the tested thresholding methods for the NDSI model. We attribute this to the fact that the NDSI histogram does not form a Gaussian distribution, a precondition leading to previous findings as e.g., by [
36].
5.2. SNDSI Parameterization
Similar to NDSI, the harmonic no-flood reference leads to the best performance (see
Table 3), followed by the pre-flood and the mean reference. The best-performing parameterization combines the harmonic reference and KI thresholding method. However, Otsu’s method appears to be the most stable among the thresholding methods, probably due to the fact that SNDSI shows no propensity towards overestimation as the NDSI does. Moreover, using Shannon’s entropy appears to be an effective spatial morphological filter to reduce noise-like classification.
5.3. Standardized Residuals Parameterization
In general, aside from UA, SR shows a similar large variance in accuracy metrics of the parameterizations (see
Table 4). Concerning no-flood reference parameterization, also here, the harmonic outperforms mean and pre-flood references. The pre-flood reference does not perform well for this method because of the larger standard deviations in the temporal model for the three-year period we tested. The fixed
threshold shows the best performance for this model in this study site. It shows a slightly better performance compared to Otsu’s method, while KI underperforms in this model. Overall, the model leans towards improving UA rather than PA values. The reported propensity towards underestimation by KI’s method is apparent for the SR model, as indicated by the lower PA results.
5.4. Bayes Inference Parameterization
In the case of the BI method, no threshold needs to be found, and the general rule of labeling is based on higher probability, i.e., >50.0%. Instead,
Table 5 includes the PDF exclusion (see
Section 5) as an option. One can see that there are minimal variations in the accuracy metrics for the BI method compared to the other change detection methods. The BI consistently performed very well in terms of UA; almost no non-flooded pixels are labeled as a flood and slightly lower PA indicates minor underestimation. Furthermore, all parametrizations reached a high CSI larger than 80%. Overall, the best-performing parameterization No. 4 uses the harmonic no-flood reference and the PDF-based exclusion masks from the Bayes model.
Based on the nominal values of OA and CSI, the BI method using harmonic reference slightly outperforms the other no-flood references. It should be noted that these differences are too marginal to conclude a significant distinction. Unlike in other methods, the pre-flood image performs similarly well as the mean and harmonic no-flood reference. It is also noticeable that the introduction of PDF exclusion masking consistently improves the BI model, albeit by small margins in CSI and OA. This, however, comes at the cost of masking some areas that could not be reliably classified.
5.5. Parameterization Summary
Table 6 collects the best-performing parameterization for each change detection model. All four models perform best with the harmonic model for the no-flood reference. The mean and pre-flood no-flood references performed variably depending on the other parameters. Concerning threshold method, KI’s method performed the best for NDSI and SNDSI. Despite KI’s method being found to be more conservative in thresholding [
24], it performs best for certain instances due to improved separability of flood and non-flood pixels in the models (see histograms in
Figure 5). For the SR model; however, the fixed threshold was found to provide consistently good results for this study site, while KI and Otsu depend on the no-flood reference. While Otsu’s method is not present within the collection of best-performing parameterizations, it shows less variance in performance compared to KI. This result is consistent with reports of Otsu’s performance [
24]; here, significant flooding is apparent in the study site. Thus, its propensity to overestimate floods is not as pronounced. Lastly, the application PDF Exclusion step consistently improves the accuracy metrics for BI, albeit by only small percentage points.
After comparing different parameterizations for each change detection method, we infer the robustness of the methods for this study site given by the variability of the resulting accuracy metrics. The highest robustness is shown by the BI method. We suspect that the use of statistical distributions instead of a particular threshold is responsible for the superior robustness.
6. Model Intercomparison
The optimal parameterizations for each of the four change detection methods are identified in
Section 5 and are summarized in
Table 6. These are considered in the subsequent step, where the accuracy assessment metrics are computed against the Sentinel-2 flood map (see
Table 7).
After parameter optimization, there are generally few false positive pixels in the SAR-based flood maps, as all selected flood maps show User’s Accuracy (UA) values greater than 87%. The Bayes method used has the highest value of 95.9%. As expected, the PA of all methods is significantly lower than UA. The PA results range from SNDSI with 77.0% to SR with 69.8%. Based on our assumption that there is no significant difference in the flood extent due to little time lag between the Sentinel-1 observation and the Sentinel-2-based reference map, this result can be attributed to the limitation of SAR-based methods over certain land cover types. As reported already by Bauer-Marschallinger et al. [
27], the SAR-based flood mapping is challenged in densely vegetated and urban areas, where optical systems such as Sentinel-2 can detect floods under good circumstances and in the absence of clouds.
The OA results indicate good or excellent general agreement between the tested flood maps and the reference maps, which is also promoted by the overall large area and the relatively large flooding event. Among the selected parameterizations, the Bayes method shows the highest OA value with 85.3%, while the last-ranked method SR has only a difference of 3.5%. Based on the little differences in OA, it can be said that BI has the only noteworthy difference from the other methods tested based on 2% difference criteria we established in
Section 4.2. When examining the Critical Success Index (CSI) results, the Bayes method is also ranked best with 72.3%, followed by the SNDSI with 69.5%, NDSI with 68.2%, and SR with the lowest result at 65.7%. Only the BI method has CSI greater than 70.0%, while all others are rated closely. However, in reflection of the underlying differences in flood mapping mechanisms between optical and SAR-based maps, we consider all methods to perform well.
It should be noted that the above statistical metrics show a generalized performance description for the whole scene. Therefore, we have a closer look at the qualitative differences for some selected areas. PA and UA relate to classification pixels of false negatives (omission errors) and false positives (commission errors), which describe (dis-) agreement well when zoomed in on particular areas of interest.
Figure 6 and
Figure 7 show representative subsets and their confusion maps between the tested model’s flood maps and the Sentinel-2 reference map. These maps highlight the area near the city of Tuguegarao with its meandering river channel and surrounding agricultural areas, respectively.
The four methods successfully remove non-water areas of permanent low backscatter, such as the Cagayan airport shown in the upper right edge of the maps in
Figure 6, fully exploiting the strength of the change detection concept. Moreover, the BI method shows an excellent delineation of the permanent river courses, being excluded in the flood result through the PDF exclusion approach. The SR method shows suitable results for permanent water exclusion but could be improved by further morphological operators as only small patches are observed. The NDSI-based results, show poor performance in this regard.
In contrast to the other models, SNDSI shows larger patches of false positives over the built-up areas in the center and east of the zoom-in (
Figure 6). In this area, high backscatter from double bounce effects are clustered, which results in low entropy values that lead to erroneous labeling. The observed improvement in the NDSI and SNDSI in parameter transformation for thresholding does not significantly improve these methods compared to the other tested methods. This degraded performance could be attributed to the limitation of the parameter formulation to account for false positives, which are clearly seen in the confusion maps. For example, low SNDSI values mainly refer to swaths of water in an image, but are also likely for radar shadows which may have been missed by the post-processing masks. Another observation is the NDSI, and SNDSI results have more overestimation in flooded agricultural areas (
Figure 7), while the SR and BI methods are less prone to this type of commission error.
As also seen in
Table 7, SR has notably more false negatives. These are generally observed in agricultural areas, as exemplified in
Figure 7, and can be attributed to the higher temporal variance from agricultural activities (in the historical time series), which dampens the SR parameter. Surprisingly, the BI method performs better than the other methods, considering that agricultural areas were recognized in need of improvement for the BI method presented by [
27].
In terms of spatial cohesion of the flood maps, as inferred from the confusion maps in
Figure 6 and
Figure 7, the SNDSI and BI method show more cohesive overall results. For the area of Tuguegarao,
Figure 6, the NDSI map shows noisy or patchy results in terms of higher rates of both FP and FN, while SR has the same concern to a lesser degree in the specific regions. At the same time,
Figure 7 show much noise in all methods, including the BI result illustrating the challenges of such areas in flood mapping. It could be argued that NDSI and SR methods could further be improved with better morphological filtering during a post-processing step. Alternatively, by use of Shannon’s entropy as in the SNDSI, a filter-like improvement is achieved, which slightly improves the overall result for this case study.
However, notable in the BI result in
Figure 7 are the patches of excluded areas. While in most cases, these coincide with misclassifications in the other maps, thus highlighting the PDF exclusion’s effectiveness. For example, some areas such as the old river meander in the lower left corner of the BI map in
Figure 6 were excluded rather than labeled being as flood. Despite this and other things considered, the BI method generally performs better than the other methods tested in this study.
7. Conclusions
This study tested and compared four automated SAR-based change detection flood mapping methods and their parameterization against Sentinel-1-based expert data for the case study in the northern Philippines. Our parameterization experiments comprise the testing of different threshold and masking options, as well as the suitability of three different methods to generate the no-flood-reference map, which is crucial to any change detection approach. We further carried out an inter-comparison of the four best-performing model parameterizations, with accuracy assessment against a Sentinel-2-based flood map specifically generated for this study.
In our assessment of the model parameterizations against the semi-manual results from Sentinel Asia (using Sentinel-1), the Bayes Inference (BI) method showed the most consistent performance, regardless of the input no-flood reference. The BI model was found to be robust in the sense that it does not require tailor-fitting, whereas the other change detection methods were found to be more significantly impacted by one’s choice of input non-flood reference and the thresholding method. Focusing on the latter, Otsu’s method was found to work well with the SR and SNDSI methods. In contrast, KI’s method showed a better result for NDSI and SNDSI, albeit showing highly variable results when the input no-flood reference is changed. The published threshold of also showed a good result for this study area. Lastly, considering that we applied a HAND-based prefiltering before thresholding and the obtained variability of the results, it is recommended to explore spatial prefiltering techniques with these models, which are driven by temporal parameters.
Concerning the no-flood-reference parameterization, the harmonic model lead to the best results for all four change detection models, apparently profiting from the good fit of the seasonally expected backscatter. The missing consideration of the backscatter’s seasonal variability causes the lower performance of the mean. The pre-flood image is generally observed close to the flood event and hence is expected to represent actual conditions such as vegetation state or soil moisture most accurately. Nevertheless, results from the pre-flood-parameterized models are less consistent compared to the harmonic model. We found that the pre-flood image—as an actual single-time observation—still holds speckle that leads to noise-like classifications, which is effectively removed in no-flood references made from temporal aggregations. Therefore, we recommended that the datacube-derived no-flood reference are further investigated, such as other time-series models, e.g., exponential filters, or parameter tuning through, e.g., modulating the length of the contributing time-series.
The evaluation of the best-performing model parameterizations against the optical-derived Sentinel-2 reference showed that the BI method performed best. Considering the parameterization results and this final comparison suggest that the BI core concept is generally more robust and possibly more adaptable to other study sites. Albeit computationally more demanding, the BI approach of taking the sample’s full distribution into account proves to be more adaptive than the discrete thresholding in the other methods.
All tested datacube flood mapping methods show meaningful agreement with the reference flood maps from Sentinel-2 and a semi-automatic expert product by Sentinel Asia. The best-performing methods all achieved good to excellent results based on OA and CSI. The four tested change detection methods show very satisfying User’s Accuracies, mainly through a correct classification of permanent low backscatter areas. The Producer’s Accuracies, on the other hand, also had reasonable performance but exhibit well-known SAR-related deficiencies over challenging land covers.
To summarize, this study represents one of the first efforts to inter-compare several SAR change-detection-based flood mapping methods and their parameterizations, with a view on the feasibility of applying them in an operational fashion over large areas. Overall, all four change detection models performed reasonably well considering that their input parameters were neither locally optimized nor adapted by a human operator. Nonetheless, the sensitivity of the NSDI, SNSRI, and SR models to parameterizations suggests the need for further localized tests. On the other hand, the Bayesian Inference model coupled with the harmonic model as no-flood reference seems to be relatively stable in its performance, which is an important prerequisite for (global) automatic operations.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}