1. Introduction
Due to the extraordinary advancement of hyperspectral remote sensors, hundreds of tiny and continuous spectral bands are feasible to acquire from the electromagnetic (EM) spectrum, which typically spreads in the ranges 0.4 μm to 2.5 μm and includes visible to the near-infrared region of the EM spectrum [
1]. For example, with an exceptional spectral resolution of 0.01 μm, the airborne visible/infrared imaging spectrometer (AVIRIS) sensor effectively captures 224 spectral images for the Indian Pines (IP) hyperspectral image (HSI) scene [
2]. Due to the superior spectral resolution, ground objects are becoming a more commonly used research topic [
3]. Every single spectral channel is recognized as a feature for classification in this context, as long as it contains distinct ground surface responses [
4]. An HSI is represented by a 3D data cube, from which we can extract 2D spatial information corresponding to the HSI’s height and width and 1D spectral information corresponding to the HSI’s total number of spectral bands. Due to the enormous amount of data made available by HSIs, traditional HSIs pose significant challenges during image processing processes such as classification [
5]. The reasons are as follows: (i) There is a strong correlation between the input image bands; (ii) Not all spectral bands have the same amount of information to convey, and some of it is noisy [
6]; (iii) The spectral bands are collected in a continuous range by hyperspectral sensors, which means that certain spectral bands might reveal unusual information about the surface of the earth [
7]; (iv) The increased spectral resolution of hyperspectral images improves classification techniques but limits computational capacity. Additionally, because there are few training examples, this high-dimensional data cube’s classification accuracy is relatively unsatisfactory; (v) The ratio of the amount of input HSI features to training samples is not balanced. The test data classification accuracy steadily degrades as a result, a phenomenon known as the Hughes phenomenon or the curse of the dimensionality effect [
8]. To increase classification accuracy, it is crucial to condense the high-dimensional HSI data to a useful subspace of informative features. Therefore, the fundamental goal of this study was to use a constructive approach to reduce the HSI dimensions for improved classification.
The HSI high-dimensional data may be reduced into a lower dimension using various feature reduction techniques. Feature extraction, feature selection, or a combination of the two can be used for this [
9,
10]. By utilizing a linear or nonlinear transformation, feature extraction converts the original images from the original space of
S dimensionality to a new space of
P dimensionality, where
P <<
S. However, because HSIs are noisy data, the noise must be removed [
11]. Feature extraction strategies for data subsets might be supervised or unsupervised [
12]. Known data classes are used in supervised algorithms. To infer class separability, these approaches require datasets containing labeled samples. The most used supervised methods include linear discriminant analysis (LDA) [
13], nonparametric weighted feature extraction (NWFE) [
14], and genetic algorithms [
15]. The fundamental drawback of these approaches is the need for labeled samples to reduce dimensionality. The unavailability of labelled data is addressed via unsupervised dimensionality reduction approaches. Minimum noise fraction (MNF) is an extremely popular unsupervised technique and is used to evaluate extracting features. Even though principal component analysis (PCA) is used to extract features from HSI data in many analyses, PCA did not accurately show the ratio of noise in the HSI data [
16,
17,
18]. In this case, PCA only considers the HSI’s global variance to uncorrelate the data [
19]. For such noisy data, the image quality is ignored when applying a variance because of the lack of consideration for the original signal-to-noise ratio (SNR) [
20]. Therefore, MNF is introduced as a better approach for feature extraction in terms of image quality. In MNF, the components are ordered according to their SNR values, regardless of how noise appears in bands [
21]. Some studies have shown that even though feature extraction moves the original data to a newly generated space, ranking the extracted features is still important [
13,
22,
23]. MNF is unsupervised and takes SNR into account exclusively; therefore, there is a chance that some classes will negatively impact accuracy and that the first few features would not be used.
Therefore, feature selection is necessary to prioritize the features generated by the feature extraction method which contain the most spatial information. In order to obtain a blend approach that performs better than either feature extraction or feature selection alone, it is common practice at the moment to combine existing feature extraction and feature selection methods to obtain an approach that performs better than either feature extraction or feature selection alone [
10]. Combining feature extraction and selection is advantageous for the reason that feature extraction performed prior to feature selection can fully utilize the spectral information to generate new features, whereas feature selection performed after feature extraction can generate new features. In the following step, feature selection approaches are utilized to select the appropriate bands based on a set of predefined criteria. Due to combinatorial explosion from local minima and excessive computation, search-based feature selection typically fails [
24]. Mutual information (MI)-based feature selection is one example of an information-theoretic approach that can be used to uncover non-linear as well as linear correlations between input image bands and ground-truth labels [
10]. However, it is conditional on the marginal and joint probabilities of the outcomes. Due to the exponential increase in the estimation of marginal and joint probability distributions with dimensionality, it is incapable of successfully selecting features from high-dimensional data [
25]. In the suggested approach, we select a subset of informative features by lowering the number of features using cross-cumulative residual entropy (CCRE). The CCRE method is applied as a feature selection technique that quantifies the similarity of information between two images. A significant advantage over MI is that CCRE is more robust and has significantly greater immunity to noise. As CCRE is not bound to [0, 1], we propose to normalize CCRE and apply the extracted image by MNF and the available class tackling the minimum redundancy and maximum relevance (mRMR) criteria. Consequently, the informative characteristics are ordered, and a feature subset that can be employed for classification is exposed. Therefore, the proposed method to generate the subset of features is termed as MNF-nCCRE
mRMR. A kernel support vector machine (KSVM) was used to classify the data and is compared with other methods to determine its reliability. Below is a summary of this paper’s significant contributions.
In addition to MNF and CCRE, we propose a hybrid feature reduction technique.
To avoid selecting redundant features, we propose a normalized CCRE-based mRMR feature selection approach over the extracted features.
We organize the rest of the paper as follows. In
Section 2, we first describe conventional feature reduction methods such as PCA, MNF, MI, and CCRE. In
Section 3, the proposed hybrid subset detection method, MNF-nCCRE
mRMR, according to mRMR, is comprehensively described. In
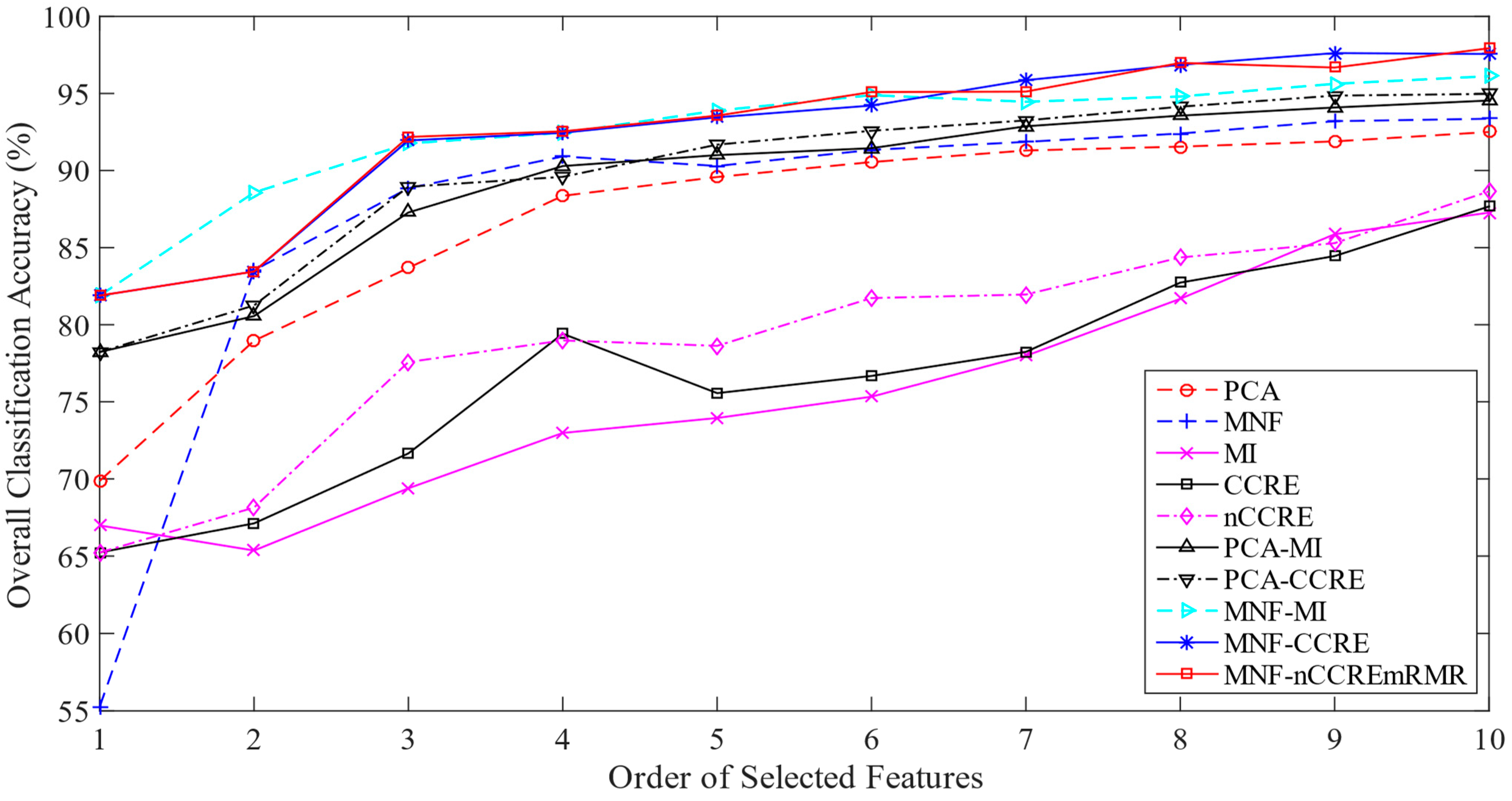
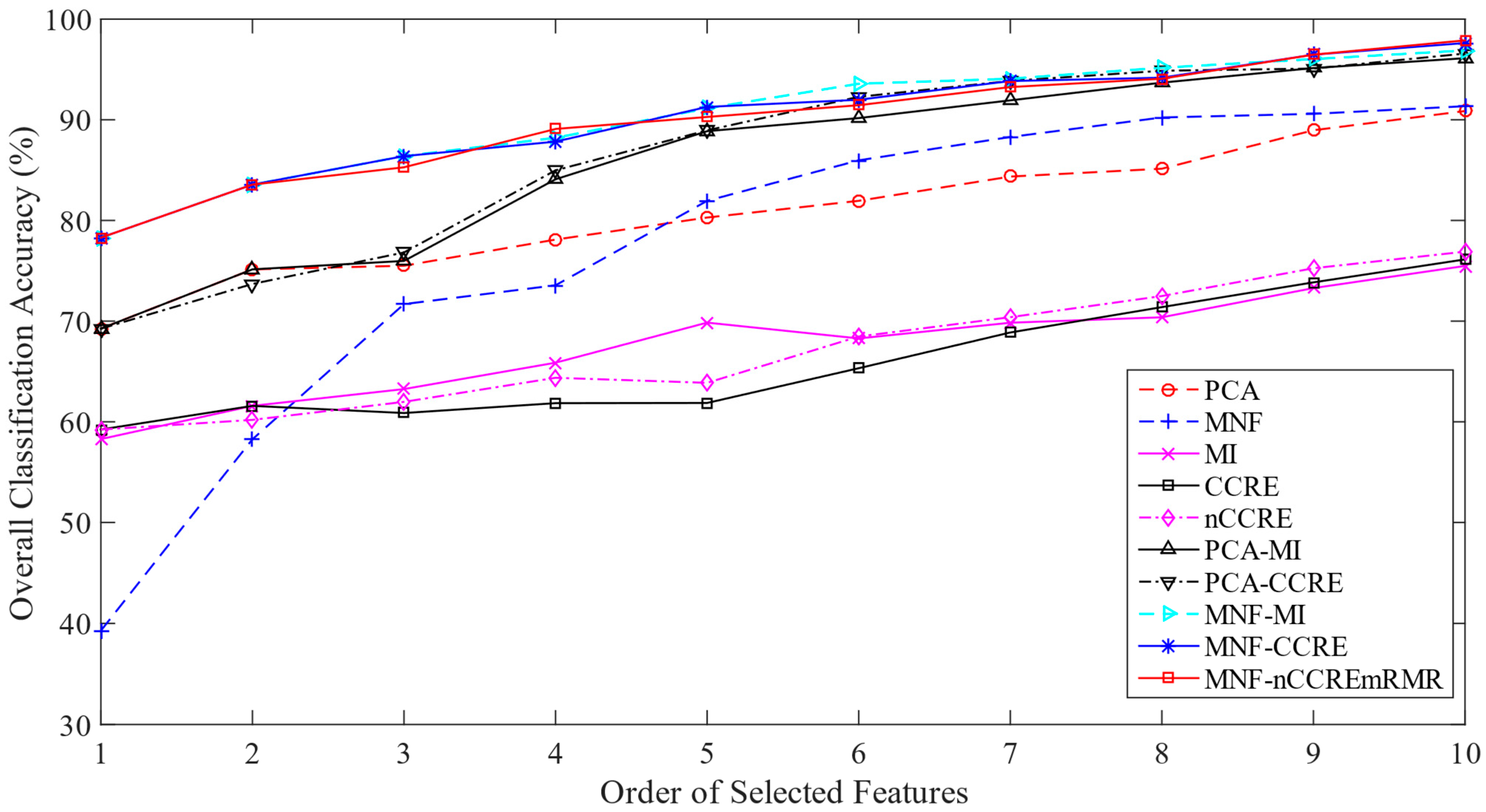
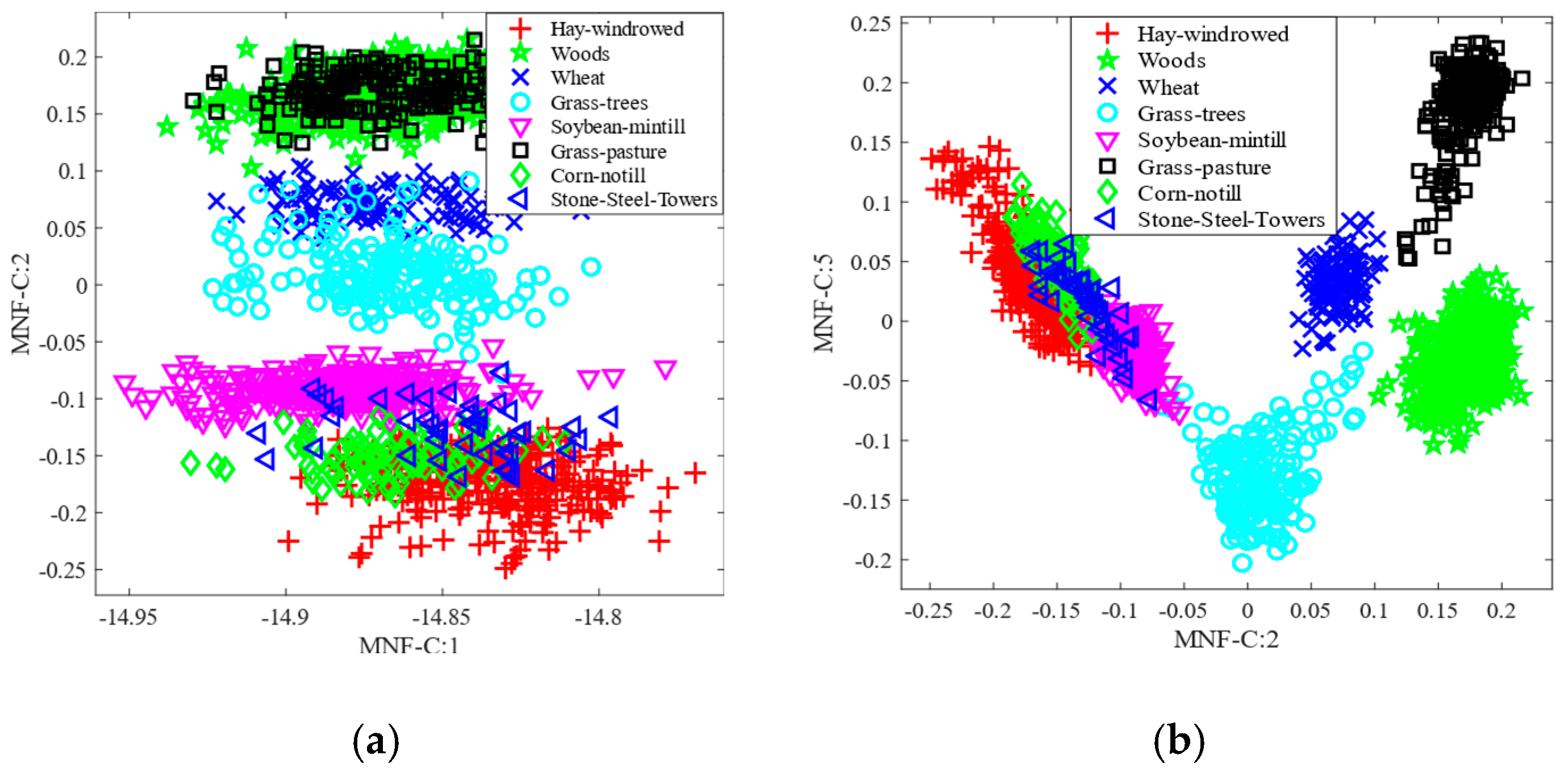
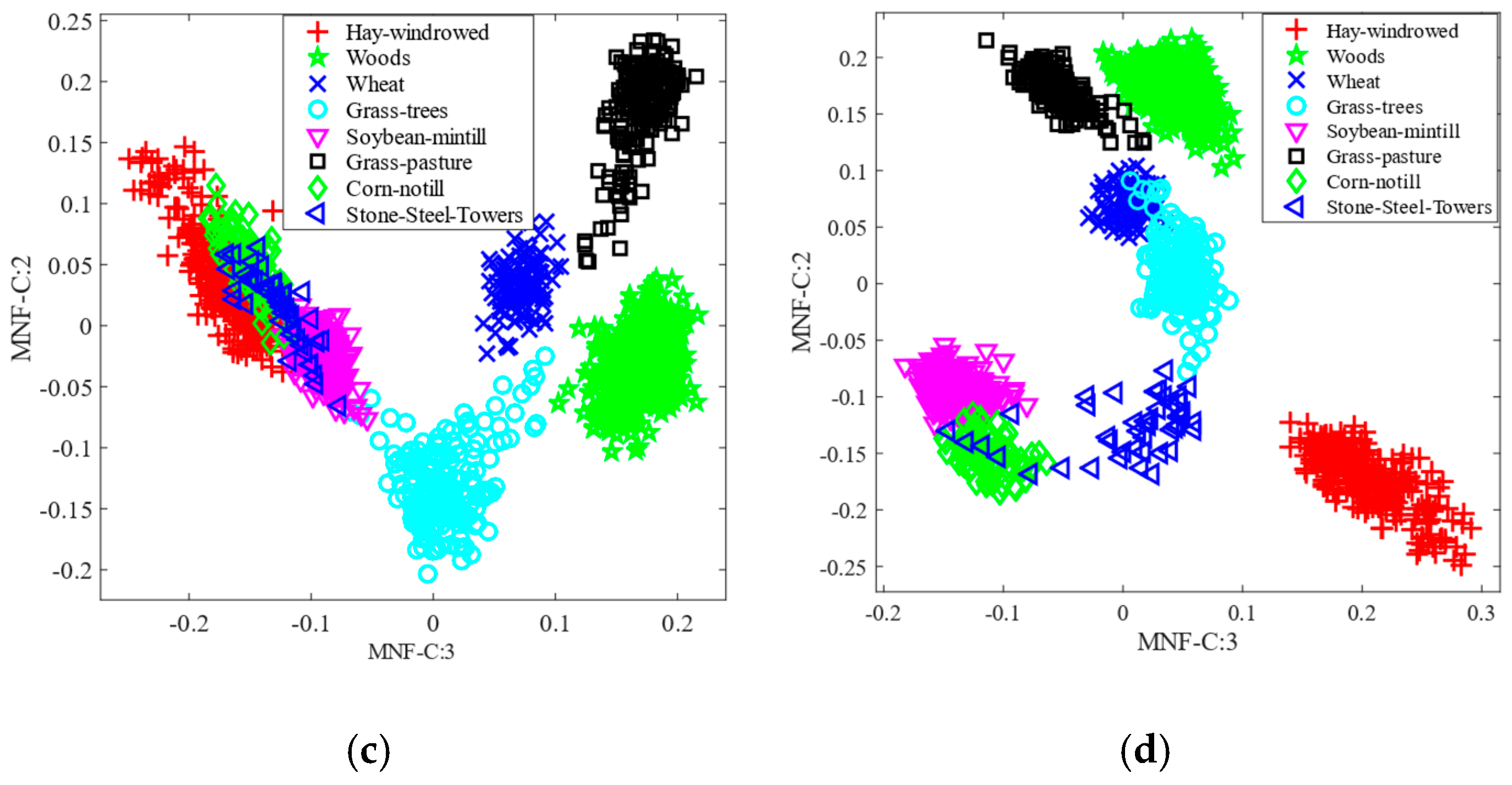
Section 4, we provide a detailed explanation of the experiments carried out on the three real HSI datasets utilizing the proposed method compared with the current state of the art. The results are summarized in
Section 5, which also outlines the paper’s conclusion.
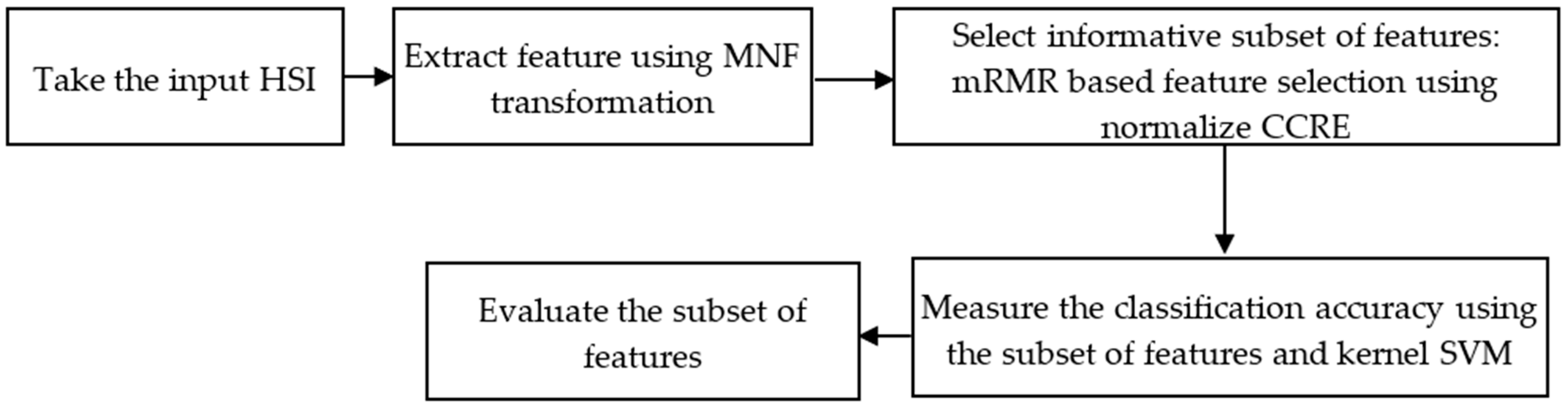
3. Proposed Methodology
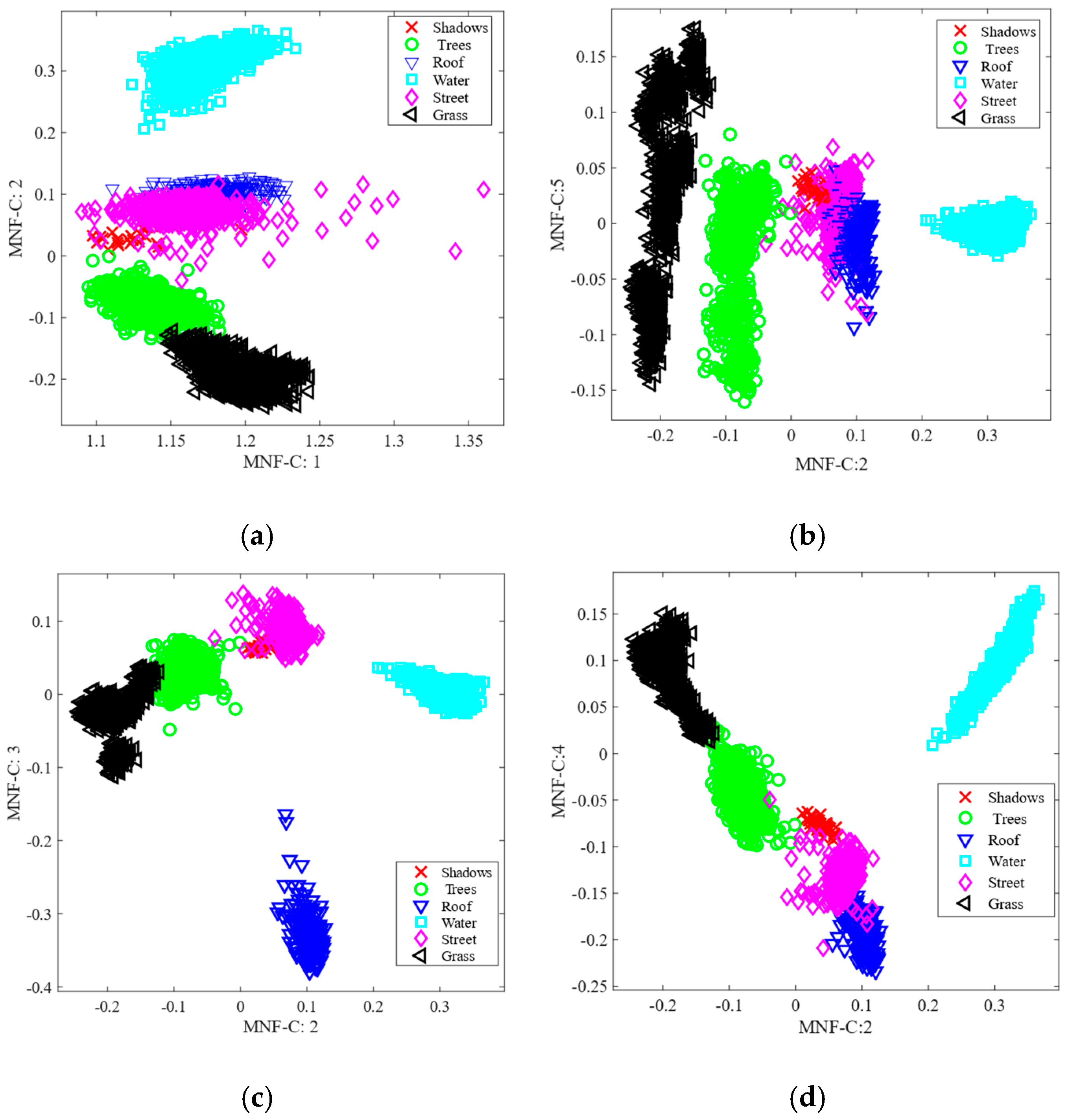
There are two primary phases in the proposed feature reduction process: (i) feature extraction through the implementation of the classical MNF on the complete HSI; and (ii) feature selection through the measurement of normalizing CCRE-based mRMR criteria on the transformed features of the HSI.
Figure 1 illustrates the practical steps of our proposed method.
3.1. mRMR-Driven CCRE-Based Feature Selection
When deciding which features are most useful, the CCRE value in Equation (12) is taken into account. Using a comparison between the newly generated features from MNF component,
Zi, and the available training class labels,
C, CCRE is able to isolate the subset of features that were most important. Therefore, the feature that is calculated to be the most informative is as [
31]:
where
V is the most informative classification feature (maximum CCRE value) that was given to S (the number of features that were chosen). This ranked the MNF components, with the possibility that the first few components are the most useful for classification. However, there may be redundancy in the features chosen using Equation (14). Overall, the selected features should be as relevant as possible while being as redundant as possible. The greedy strategy can be utilized to select the (
k + 1)
th feature; then, it can be assigned to the subsets that have already been chosen. As such, the mRMR algorithm can be used to determine the model that was picked for subspace detection as:
In Equation (15), S represent the subset of selected feature, Zi is the current features extracted from MNF, k denotes the number of features to be selected for the feature space S, C signifies the ground truth image of the HSI, and Zj represents the already selected feature in the feature space, S.
3.2. Improved Feature Selection
(i)
Using normalized CCRE: The values of CCRE are not constrained to a particular limit. Direct application of the
in the aforementioned method is complicated by the fact that it is sensitive to the entropy of two variables and does not have a fixed range of validity. The quality of a given CCRE value is evaluated by comparing it to the range [0, 1] [
32,
33]. The normalized CCRE can be defined as:
We propose nCCRE
mRMR, utilizing the normalized CCRE in Equation (16). Accordingly, the subset of features using our proposed method can be defined as:
The observation is made that the (k + 1)th feature to be added to the target subspace of features, S, should have the largest value of .
(ii) Discard Negative values: Using Equation (17), the largest value of the difference might be less than zero, resulting in the chosen features being different from the previously picked characteristics, which is undesirable. As a result, in this study, was assumed to be positive, i.e., . If the greatest difference value is not positive, it might mean that there are no longer any desirable characteristics, and that the informative subspace has grown to its specified width.
(iii)
Remove the noisy features: The formula described in Equation (17) is likely to be used to choose undesirable features. The selected features are thus only weakly related to the target when the largest difference value derives from two tiny values. The user-defined threshold (
T) is introduced as a means of avoiding complications (if
, remove
Zi). The preprocessing stage applies the user-defined threshold,
T, to condense the searching space for the greedy technique and eliminate the noisy feature. An outline of the suggested hybrid feature reduction method’s algorithm is provided below. Now, the selected set
S contains the most informative features. The proposed feature reduction methodology is illustrated in Algorithm 1.
| Algorithm 1 MNF-nCCREmRMR |
(Y is the original HSI data, Z represents the transform MNF components, C is the ground truth image, T defines a user-defined threshold, and S represents the final subsets of n number of features.)
- i.
Start (: the projected data matrix of original HSI, Y) - ii.
Evaluate (Zi, C) and utilize T, if (Zi, C) < T - iii.
Set, = {Ф} - iv.
Set, where is first feature utilizing Equations (14) and (16) - v.
Apply steps (vi) and (vii) until the S contains n features - vi.
Update by utilizing Equation (17) - vii.
OutputS as the subsets of effective features
|


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}