

A Novel Method for Obstacle Detection in Front of Vehicles Based on the Local Spatial Features of Point Cloud


Abstract
1. Introduction
- An Obstacle Detection method based on the Plane Normal Vector (OD-PNV) is proposed. Compared with the traditional obstacle detection method, based on a geometric structure, this method does not need to establish the road surface model, so the detection results are not affected by the road surface fitting accuracy. At the same time, as the method detects each superpixel independently according to its local plane normal vector, it is less affected by conditions such as road surface inclination and unevenness.
- An Obstacle Detection method based on Superpixel Point-cloud Height (OD-SPH) is proposed. This method improves the accuracy of the road plane fitting by combining the results of the OD-PNV method. According to the fitted road plane, the height of the superpixel point cloud from the road surface can be calculated accurately, and obstacles can be detected according to the height value. This method has a good detection effect for the obstacles that protrude obviously from the road surface. It is different from the OD-PNV method in principle and in its feature information, so it plays a very good complementary role to the OD-PNV method.
2. Related Work
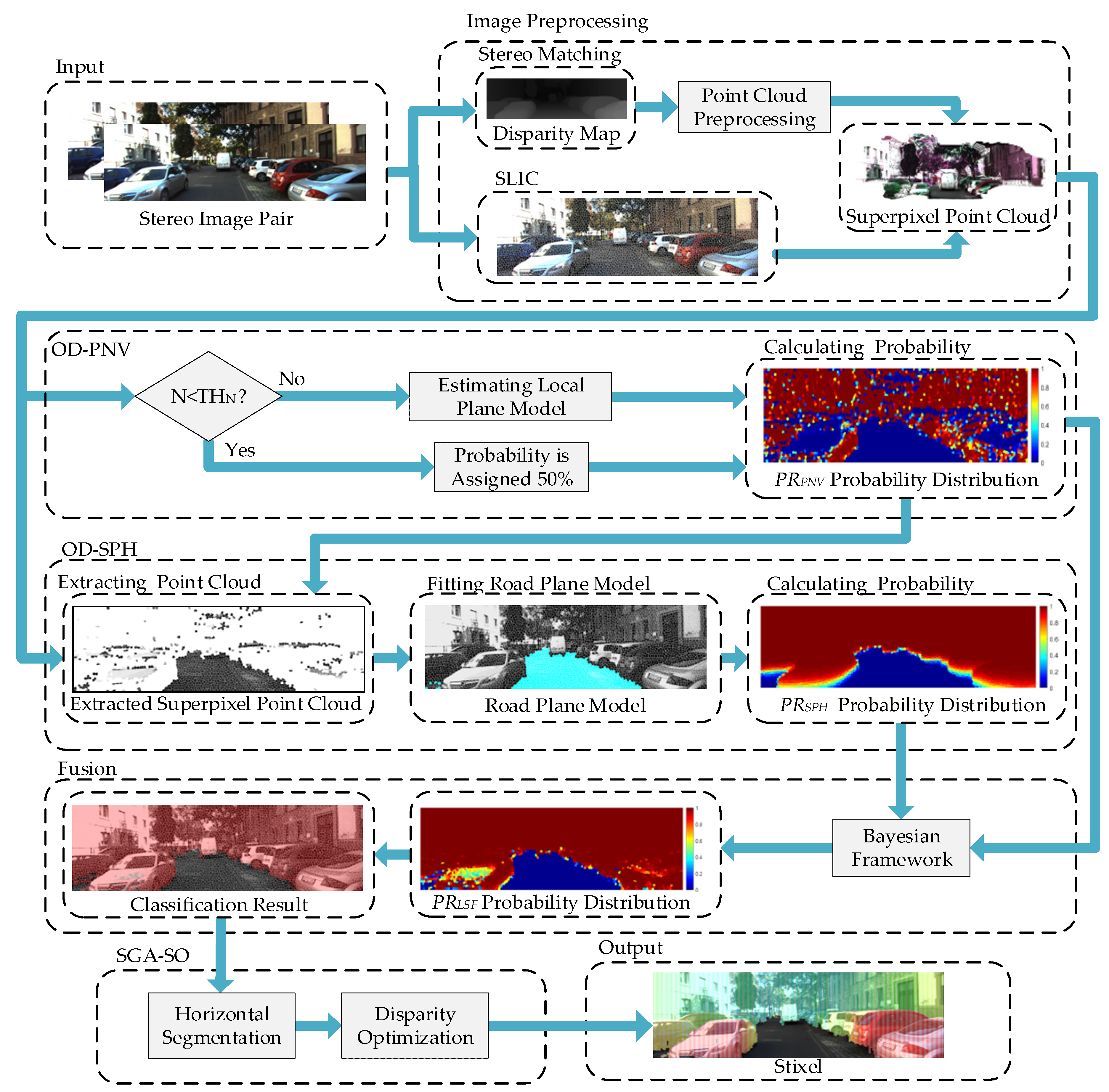
3. Proposed Methods
3.1. Image Preprocessing
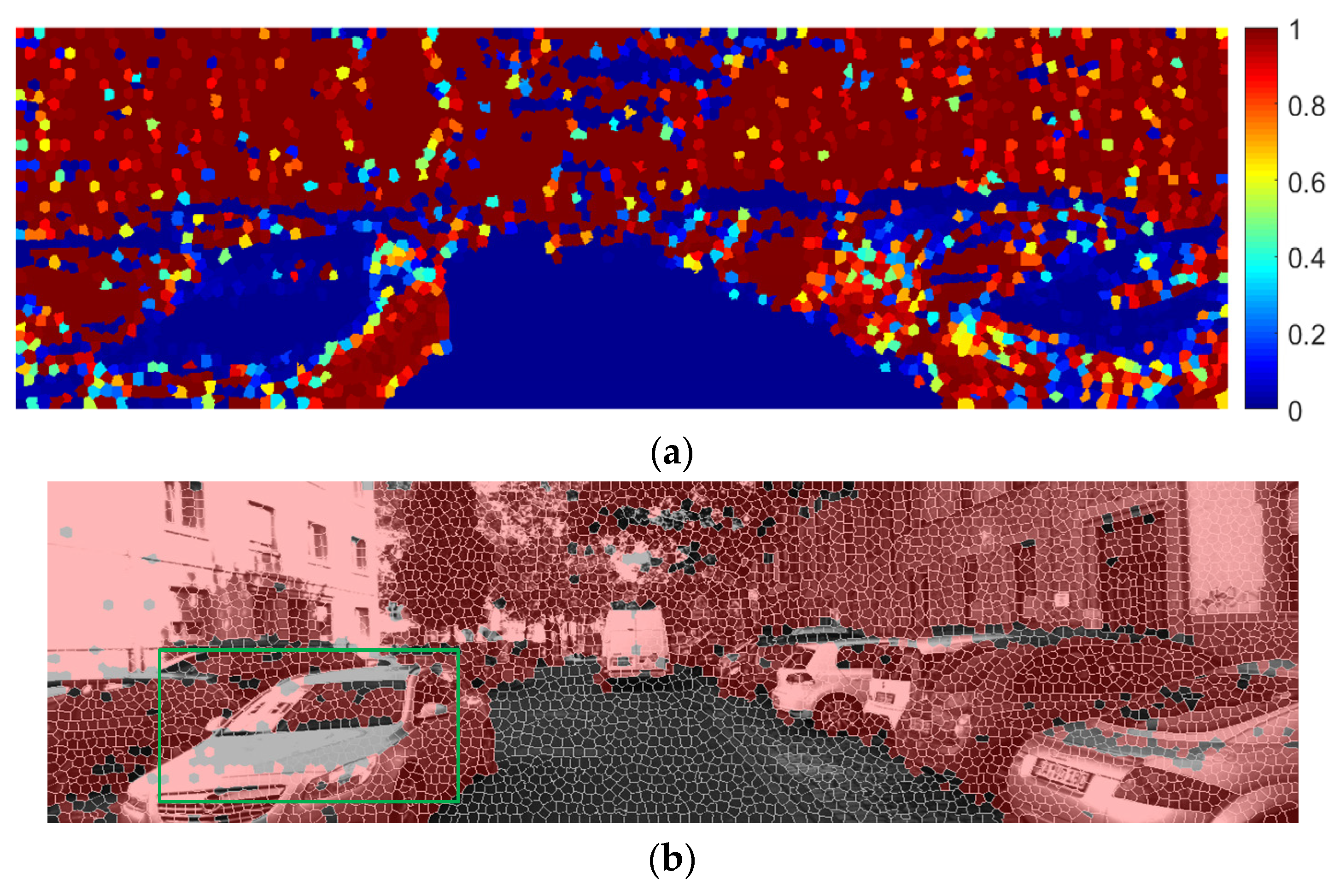
3.2. Obstacle Detection Method Based on Plane Normal Vector (OD-PNV)
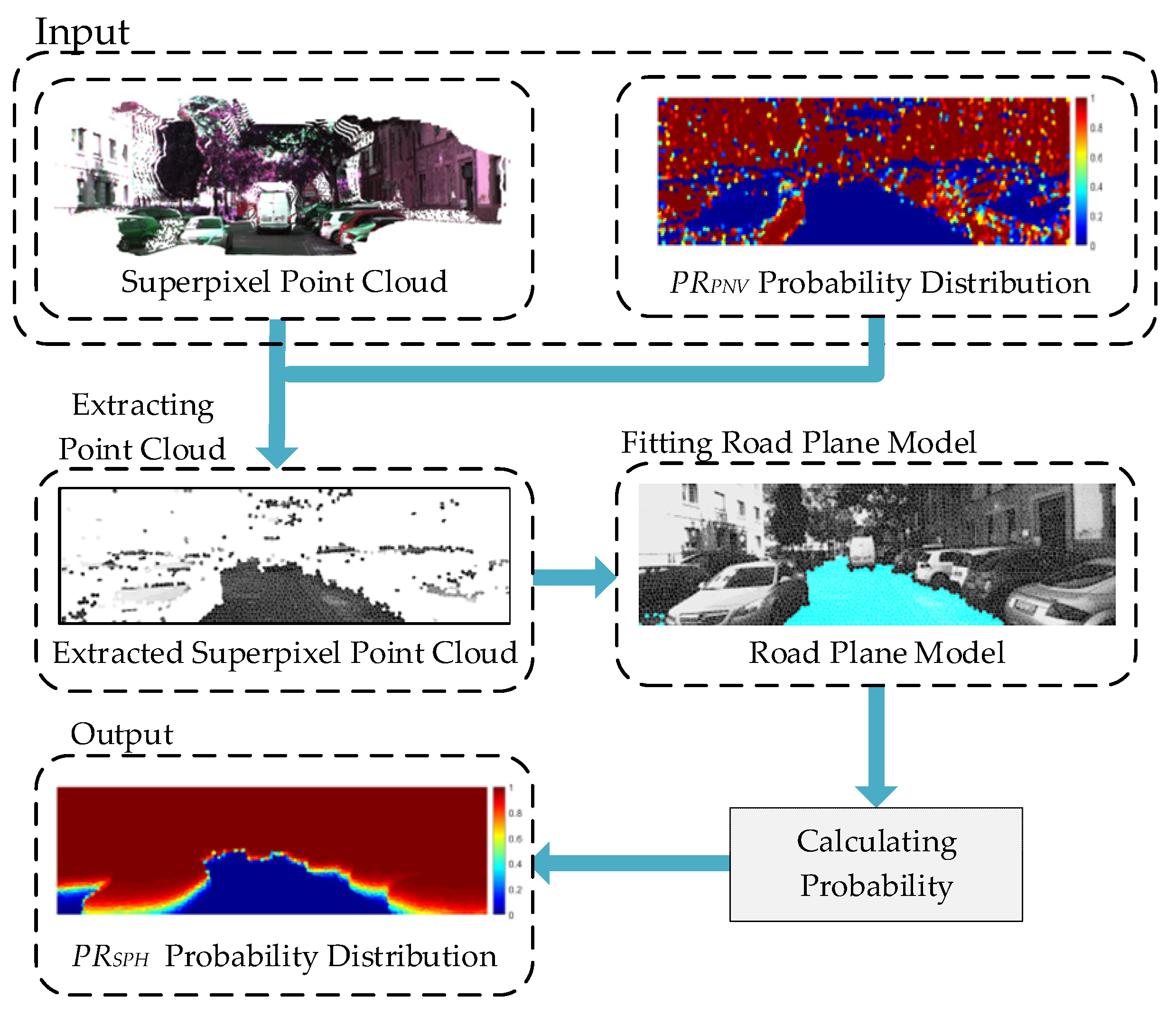
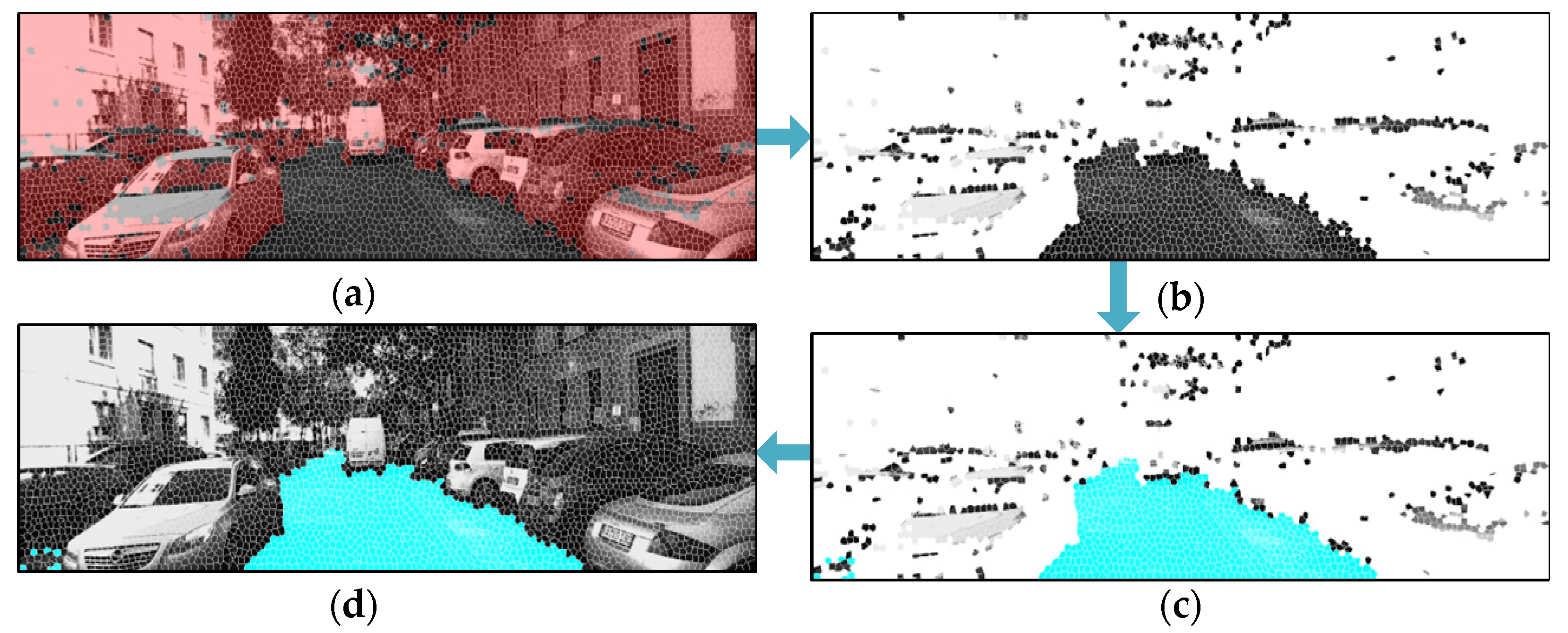
3.3. Obstacle Detection Method Based on Superpixel Point-Cloud Height (OD-SPH)
3.4. Probabilistic Fusion
3.5. Stixels Generation Algorithm Based on Segmentation and Optimization (SGA-SO)
| Algorithm 1. Horizontal Segmentation |
| Input:: Pixel-level label image of classification result; : Stixel width; : The number of rows of the input image; : The number of columns of the input image; : Extract column to column of and return Mat type data; : Segmented rectangular image; : The function is to return the data of row in ; : The function is to judge whether there is a pixel judged as an obstacle in row , and return 0 if it exists, otherwise return 1 Output: : List of |
| , , , while do =, , while do ifand , else ifand end if , end while end while |
| Algorithm 2. Disparity Optimization |
| Input:: List of ; : Number of ; : Number of current row in ; : The maximum number of rows in the current ; : The minimum number of rows in the current ; : The function to calculate mean depth of row in input ; : The function truncate at row , generates and returns new Output: : list of optimized |
| , , , , , while do while do if else if end if , end while end while |
4. Experiment and Result Analysis
4.1. Experimental Environment and Parameter Settings
4.1.1. Baseline
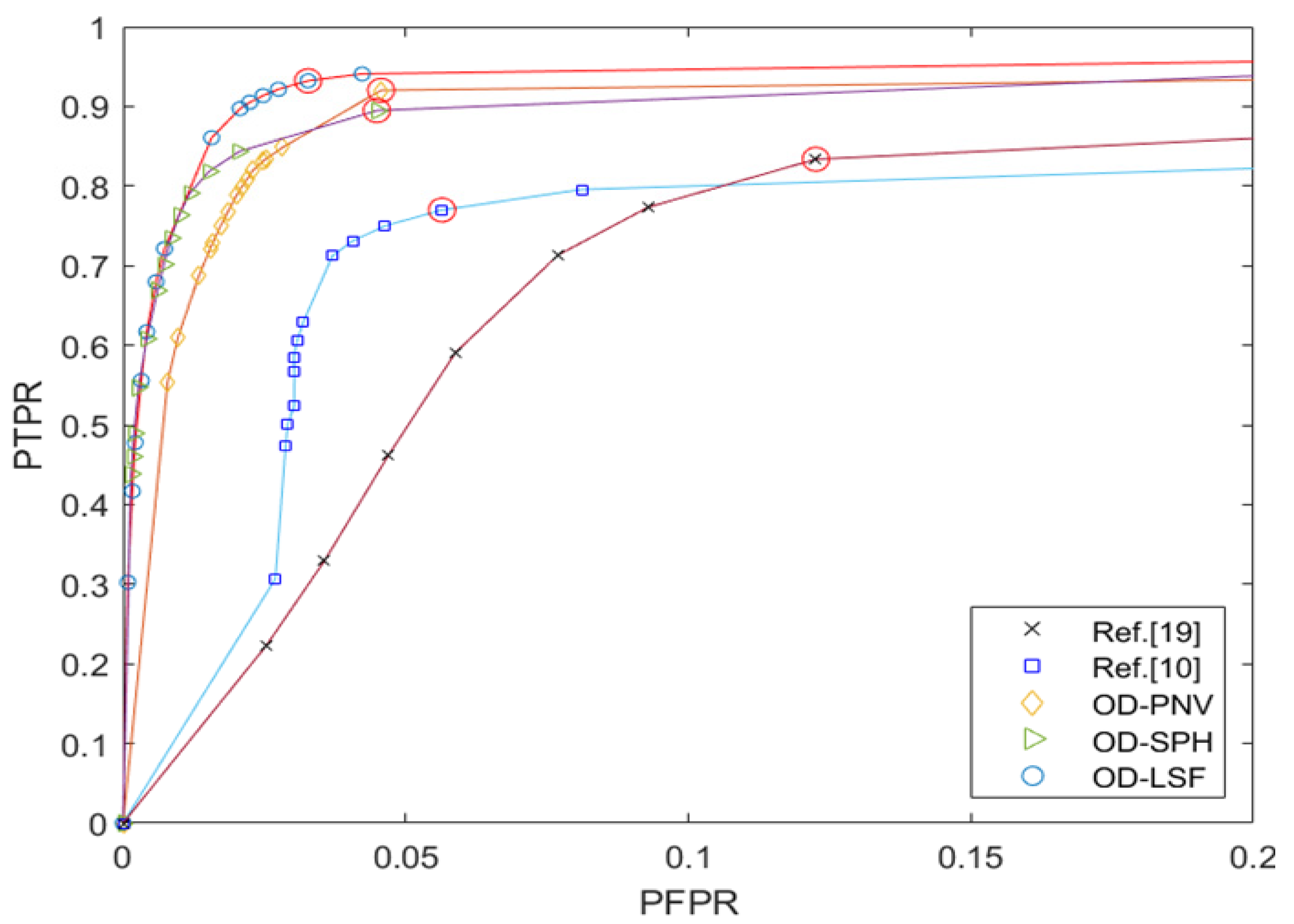
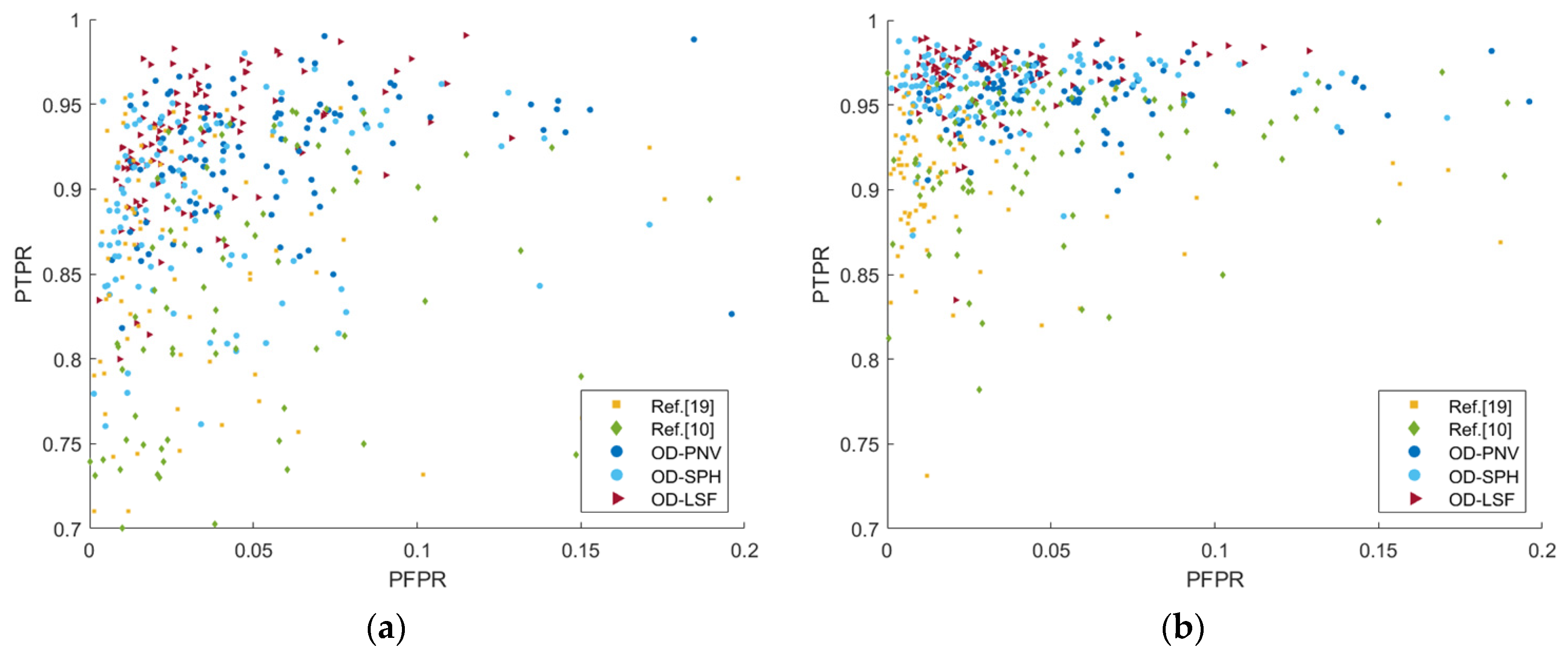
4.1.2. Evaluation Criteria
4.1.3. Dataset
4.2. Quantitative Analysis
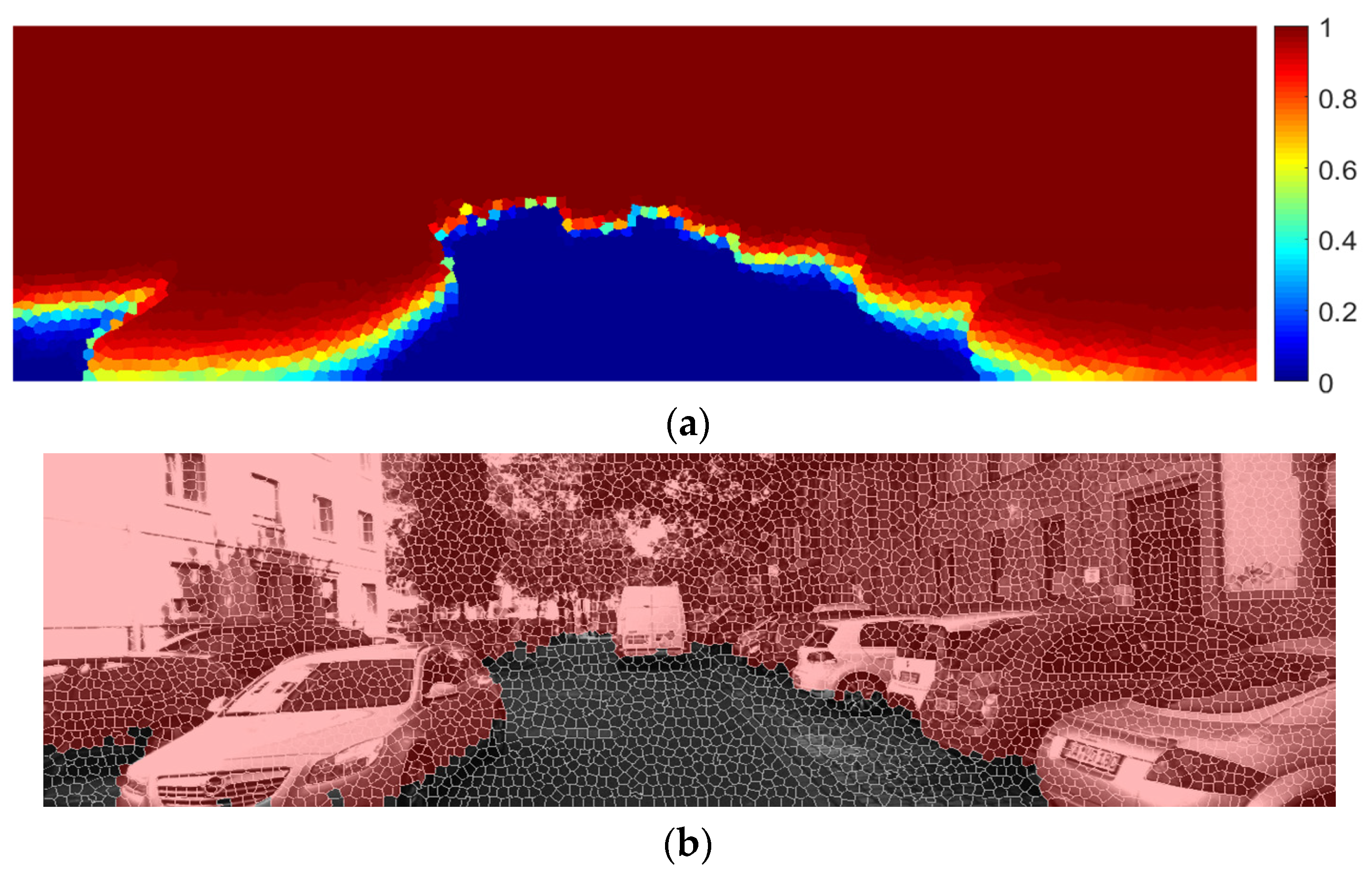
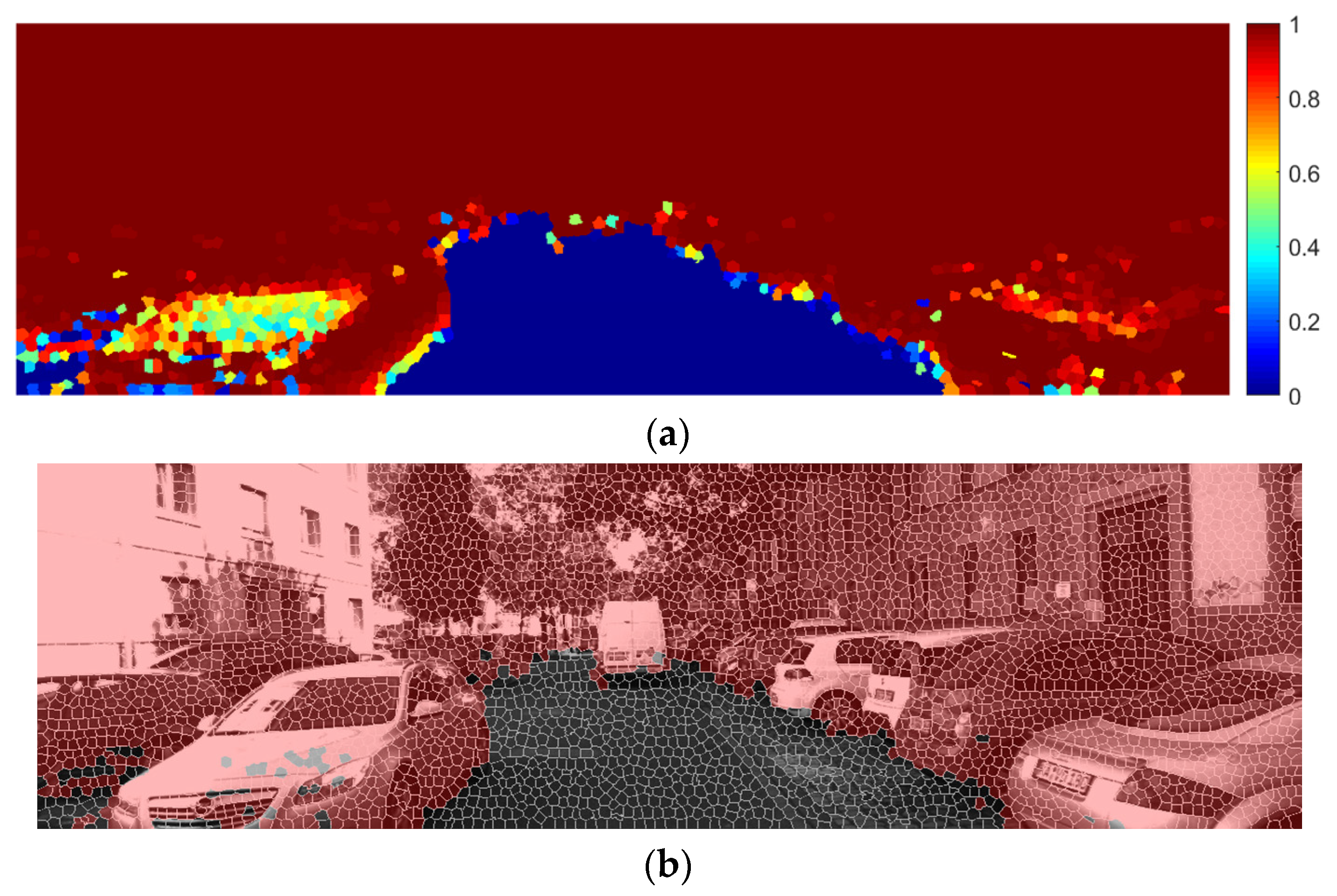
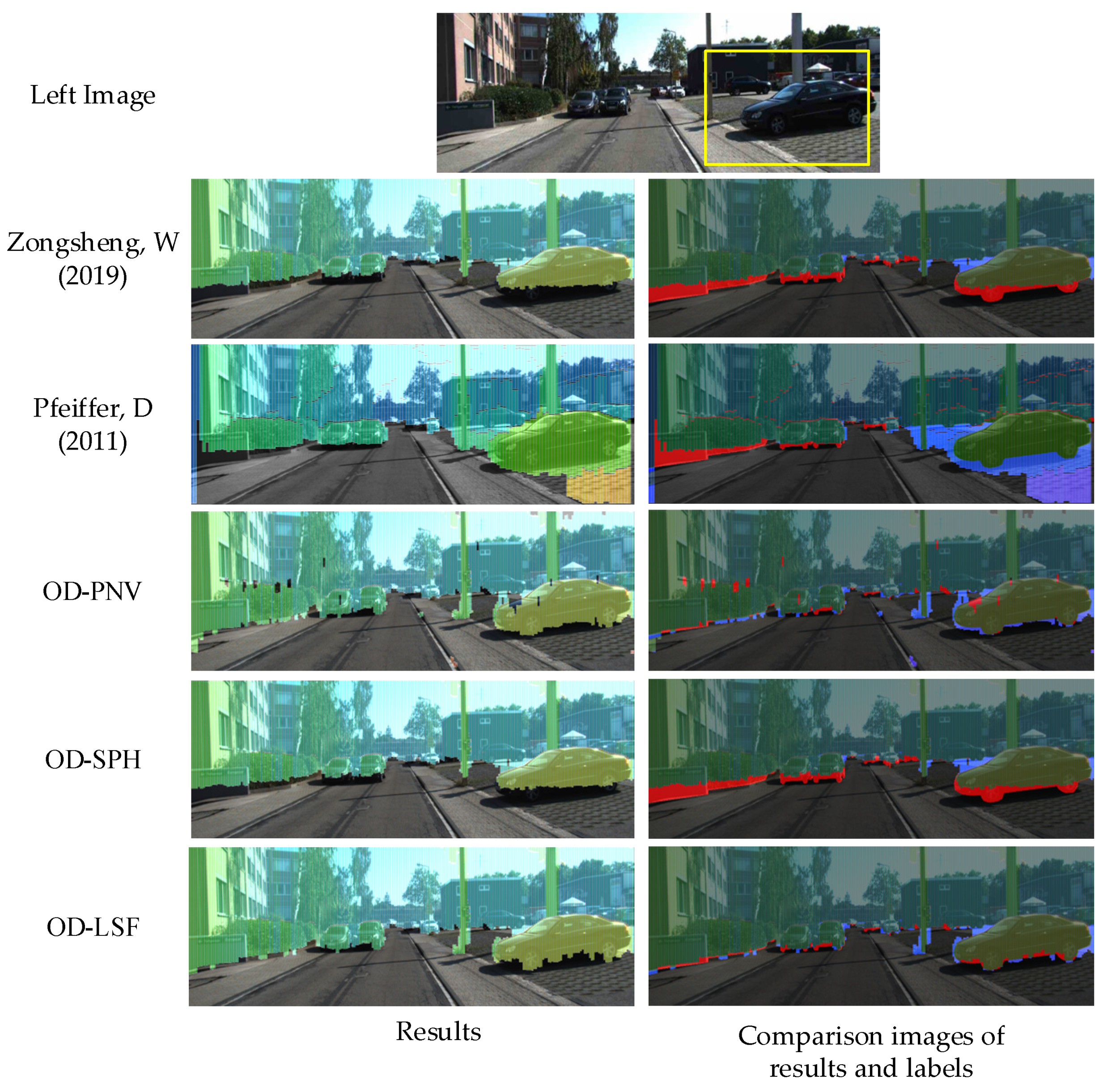
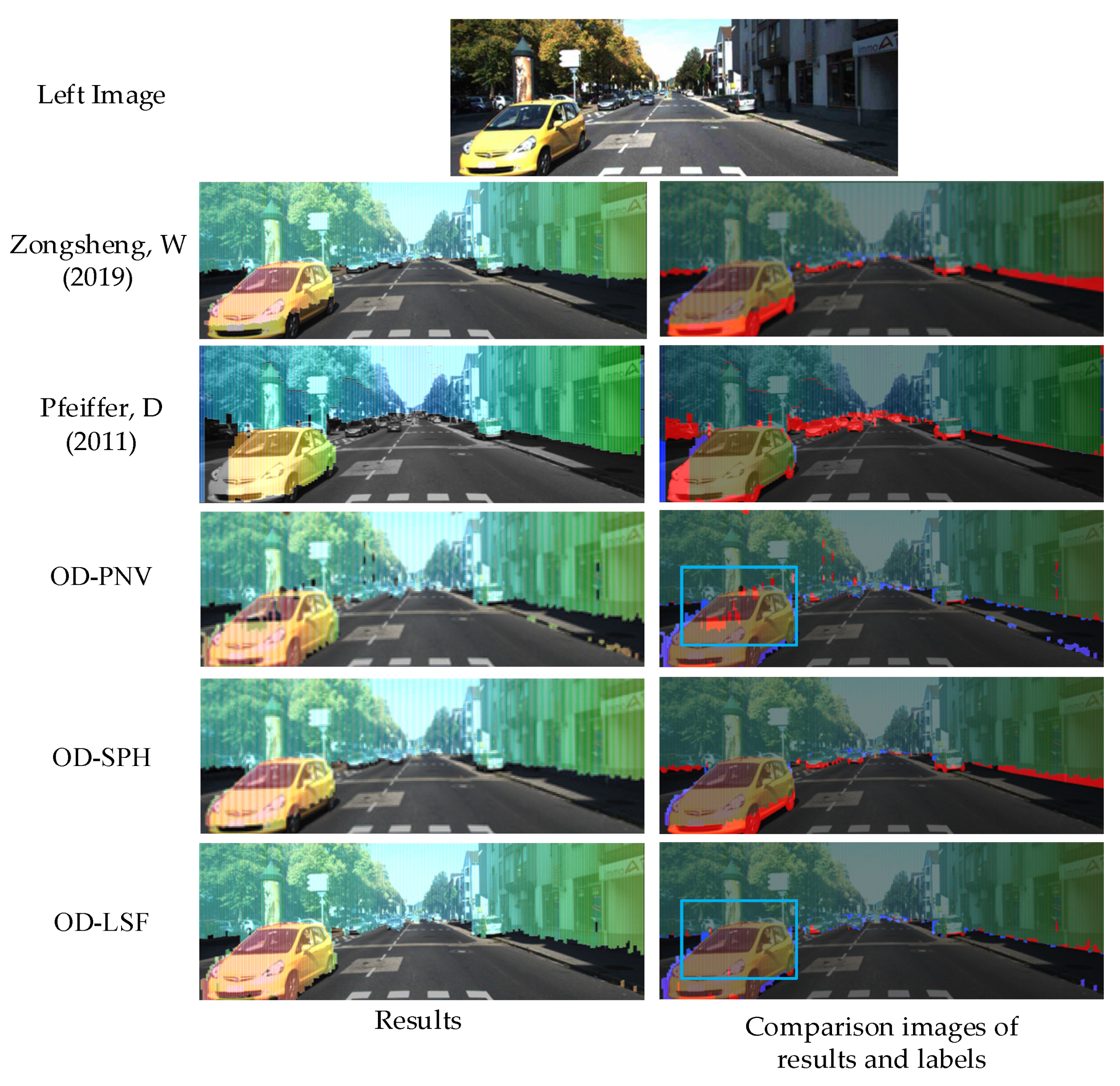
4.3. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2018: Summary (No. WHO/NMH/NVI/18.20); World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Orlovska, J.; Novakazi, F.; Lars-Ola, B.; Karlsson, M.; Wickman, C.; Söderberg, R. Effects of the driving context on the usage of Automated Driver Assistance Systems (ADAS)-Naturalistic Driving Study for ADAS evaluation. Transp. Res. Interdiscip. Perspect. 2020, 4, 100093. [Google Scholar] [CrossRef]
- Yu, X.; Marinov, M. A study on recent developments and issues with obstacle detection systems for automated vehicles. Sustainability 2020, 12, 3281. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Luo, G.; Chen, X.; Lin, W.; Dai, J.; Liang, P.; Zhang, C. An Obstacle Detection Algorithm Suitable for Complex Traffic Environment. World Electr. Veh. J. 2022, 13, 69. [Google Scholar] [CrossRef]
- Seo, J.; Sohn, K. Superpixel-based Vehicle Detection using Plane Normal Vector in Dispar ity Space. J. Korea Multimed. Soc. 2016, 19, 1003–1013. [Google Scholar] [CrossRef]
- Royo, S.; Ballesta-Garcia, M. An Overview of Lidar Imaging Systems for Autonomous Vehicles. Appl. Sci. 2019, 9, 4093. [Google Scholar] [CrossRef]
- Lee, Y.; Park, S. A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet). Appl. Sci. 2020, 10, 4486. [Google Scholar] [CrossRef]
- Peilin, L.; Cuiqun, H.; Zhichun, L. Comparison and analysis of eye-orientation methods in driver fatigue detection. For. Eng. 2008, 24, 35–38. [Google Scholar]
- Pfeiffer, D.; Franke, U. Towards a global optimal multi-Layer stixel representation of dense 3D data. In Proceedings of the 22nd British Machine Vision Conference(BMVC), Dundee, UK, 29 August–2 September 2011; pp. 1–12. [Google Scholar]
- Pinggera, P.; Ramos, S.; Gehrig, S.; Franke, U.; Rother, C.; Mester, R. Lost and found: Detecting small road hazards for self-driving vehicles. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1099–1106. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Geng, K.; Dong, G.; Yin, G.; Hu, J. Deep Dual-Modal Traffic Objects Instance Segmentation Method Using Camera and LIDAR Data for Autonomous Driving. Remote Sens. 2020, 12, 3274. [Google Scholar] [CrossRef]
- Wurm, K.M.; Hornung, A.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: A probabilistic, flexible, and compact 3D map representation for robotic systems. In Proceedings of the ICRA 2010 Workshop on Best Practice in 3D Perception and Modeling for Mobile Manipulation, Anchorage, AK, USA, 7 May 2010; pp. 403–412. [Google Scholar]
- Badino, H.; Franke, U.; Mester, R. Free space computation using stochastic occupancy grids and dynamic programming. In Proceedings of the Workshop on Dynamical Vision (ICCV), Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–12. [Google Scholar]
- Labayrade, R.; Aubert, D.; Tarel, J.-P. Real time obstacle detection in stereovision on non flat road geometry through "v-disparity" representation. In Proceedings of the Intelligent Vehicle Symposium, Versailles, France, 17–21 June 2002; pp. 646–651. [Google Scholar]
- Kramm, S.; Bensrhair, A. Obstacle detection using sparse stereovision and clustering techniques. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Madrid, Spain, 3–7 June 2012; pp. 760–765. [Google Scholar]
- Zongsheng, W.; Hong, L.; Gaining, H. Probability detection of road obstacles combining with stereo vision and superpixels Technology. Mech. Sci. Technol. Aerosp. Eng. 2019, 38, 277–282. [Google Scholar]
- Badino, H.; Franke, U.; Pfeiffer, D. The stixel world-a compact medium level representation of the 3d-world. In Proceedings of the Joint Pattern Recognition Symposium, Jena, Germany, 9–11 September 2009; pp. 51–60. [Google Scholar]
- Oniga, F.; Nedevschi, S. Processing dense stereo data using elevation maps: Road surface, traffic isle, and obstacle detection. IEEE Trans. Veh. Technol. 2010, 59, 1172–1182. [Google Scholar] [CrossRef]
- Lee, J.-K.; Yoon, K.-J. Temporally consistent road surface profile estimation using stereo vision. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1618–1628. [Google Scholar] [CrossRef]
- Gallazzi, B.; Cudrano, P.; Frosi, M.; Mentasti, S.; Matteucci, M. Clothoidal Mapping of Road Line Markings for Autonomous Driving High-Definition Maps. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 1631–1638. [Google Scholar]
- Rodrigues, R.T.; Tsiogkas, N.; Aguiar, A.P.; Pascoal, A. B-spline surfaces for range-based environment mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10774–10779. [Google Scholar]
- Huang, Y.; Fu, S.; Thompson, C. Stereovision-based object segmentation for automotive applications. EURASIP J. Adv. Signal Process. 2005, 14, 2322–2329. [Google Scholar] [CrossRef]
- Franke, U.; Heinrich, S. Fast obstacle detection for urban traffic situations. IEEE Trans. Intell. Transp. Syst. 2002, 3, 173–181. [Google Scholar] [CrossRef]
- Sun, T.; Pan, W.; Wang, Y.; Liu, Y. Region of Interest Constrained Negative Obstacle Detection and Tracking With a Stereo Camera. IEEE Sens. J. 2022, 22, 3616–3625. [Google Scholar] [CrossRef]
- Wei, Y.; Yang, J.; Gong, C.; Chen, S.; Qian, J. Obstacle detection by fusing point clouds and monocular image. Neural Process. Lett. 2019, 49, 1007–1019. [Google Scholar] [CrossRef]
- Chang, J.-R.; Chen, Y.-S. Pyramid stereo matching network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Han, X.-F.; Jin, J.S.; Wang, M.-J.; Jiang, W.; Gao, L.; Xiao, L. A review of algorithms for filtering the 3D point cloud. Signal Process. Image Commun. 2017, 57, 103–112. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Derpanis, K.G. Overview of the RANSAC algorithm. Image Rochester NY 2010, 4, 2–3. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–12 June 2012; pp. 3354–3361. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ci, W.; Xu, T.; Lin, R.; Lu, S.; Wu, X.; Xuan, J. A Novel Method for Obstacle Detection in Front of Vehicles Based on the Local Spatial Features of Point Cloud. Remote Sens. 2023, 15, 1044. https://doi.org/10.3390/rs15041044
Ci W, Xu T, Lin R, Lu S, Wu X, Xuan J. A Novel Method for Obstacle Detection in Front of Vehicles Based on the Local Spatial Features of Point Cloud. Remote Sensing. 2023; 15(4):1044. https://doi.org/10.3390/rs15041044
Chicago/Turabian StyleCi, Wenyan, Tie Xu, Runze Lin, Shan Lu, Xialai Wu, and Jiayin Xuan. 2023. "A Novel Method for Obstacle Detection in Front of Vehicles Based on the Local Spatial Features of Point Cloud" Remote Sensing 15, no. 4: 1044. https://doi.org/10.3390/rs15041044
APA StyleCi, W., Xu, T., Lin, R., Lu, S., Wu, X., & Xuan, J. (2023). A Novel Method for Obstacle Detection in Front of Vehicles Based on the Local Spatial Features of Point Cloud. Remote Sensing, 15(4), 1044. https://doi.org/10.3390/rs15041044