
Automatic Extraction of Urban Impervious Surface Based on SAH-Unet



Abstract
:
1. Introduction
2. Materials and Method
2.1. Data Collection and Processing
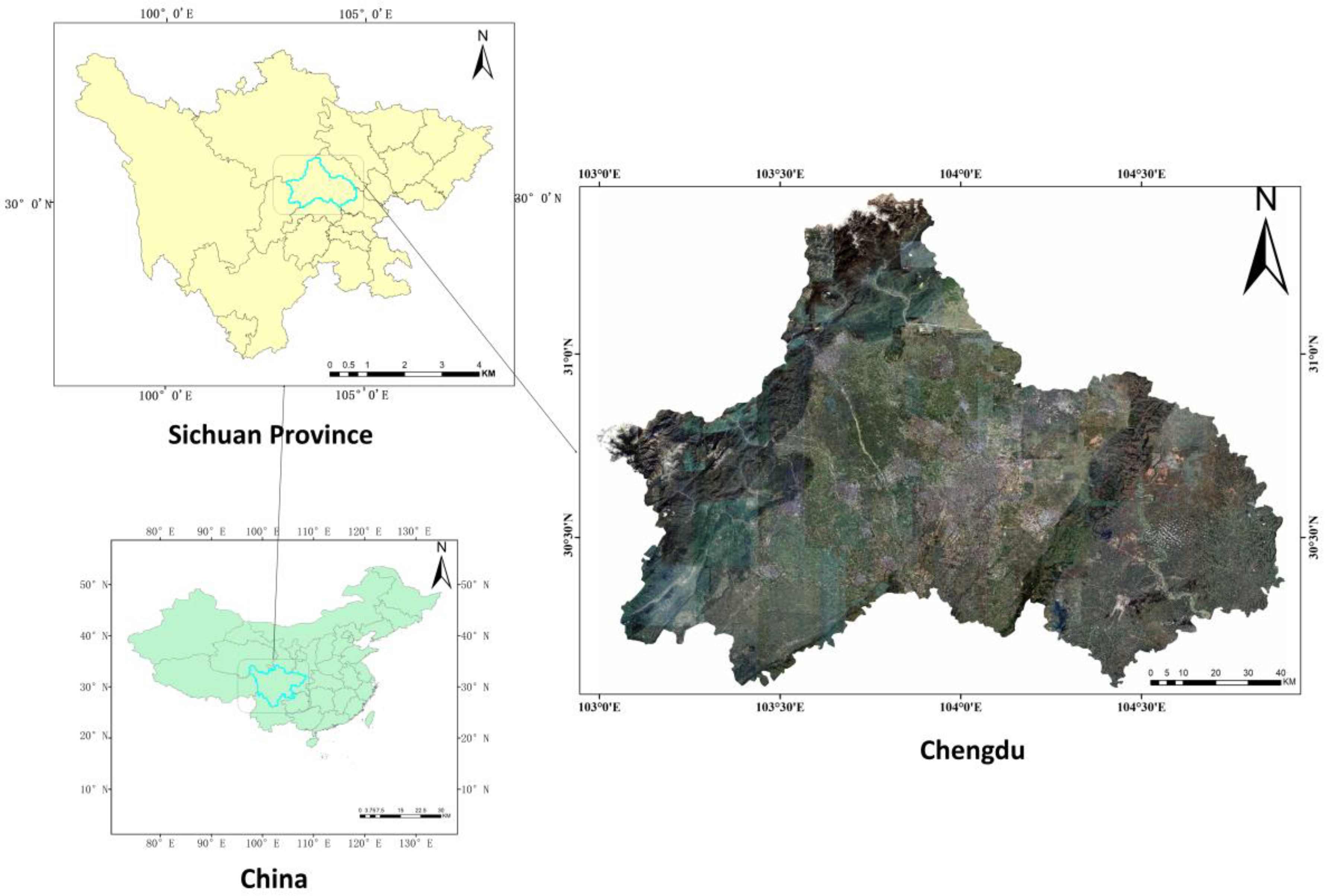
2.1.1. Study Area
2.1.2. Data Sources
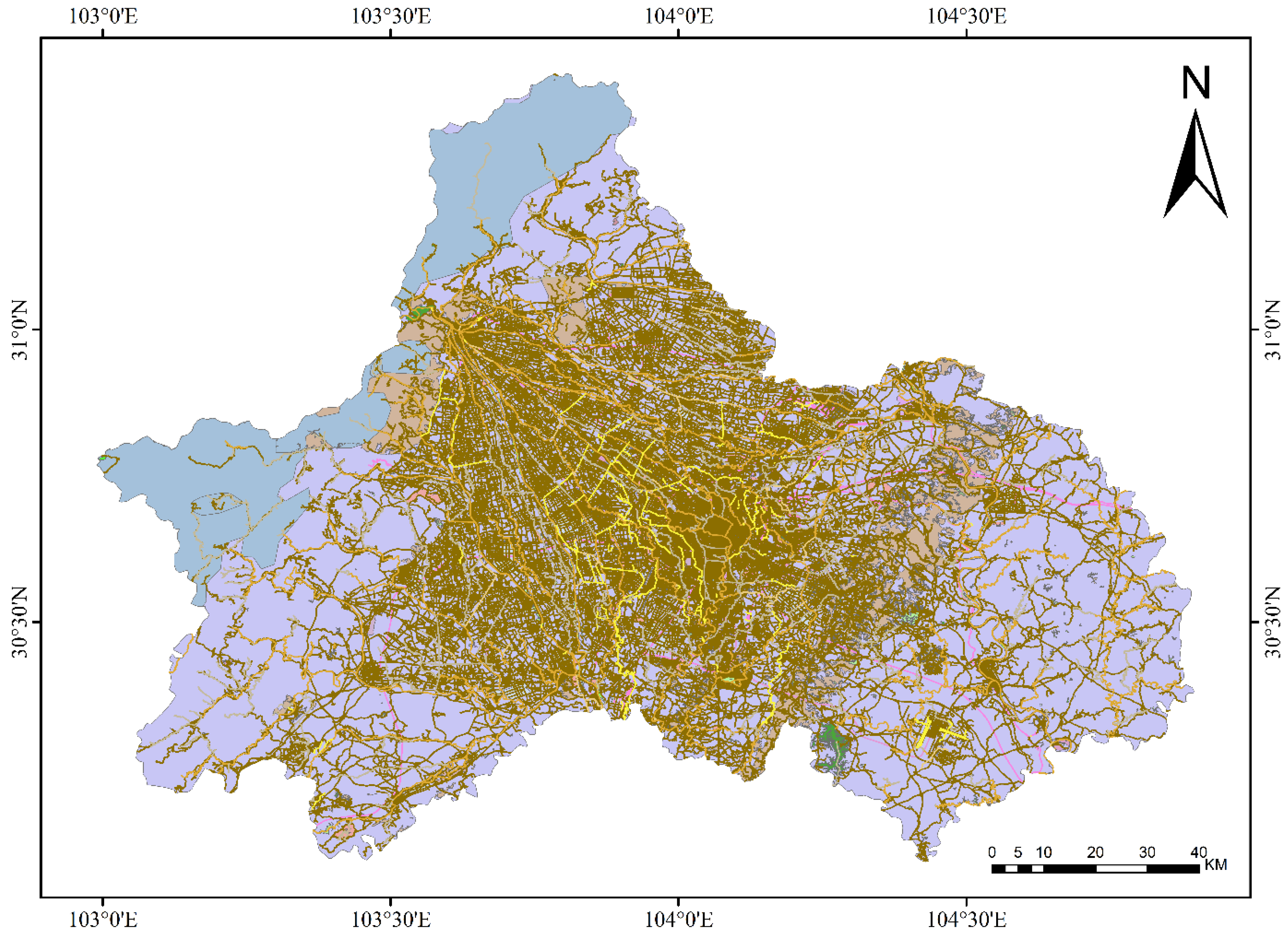
2.1.3. Dataset Construction
2.2. Methodology
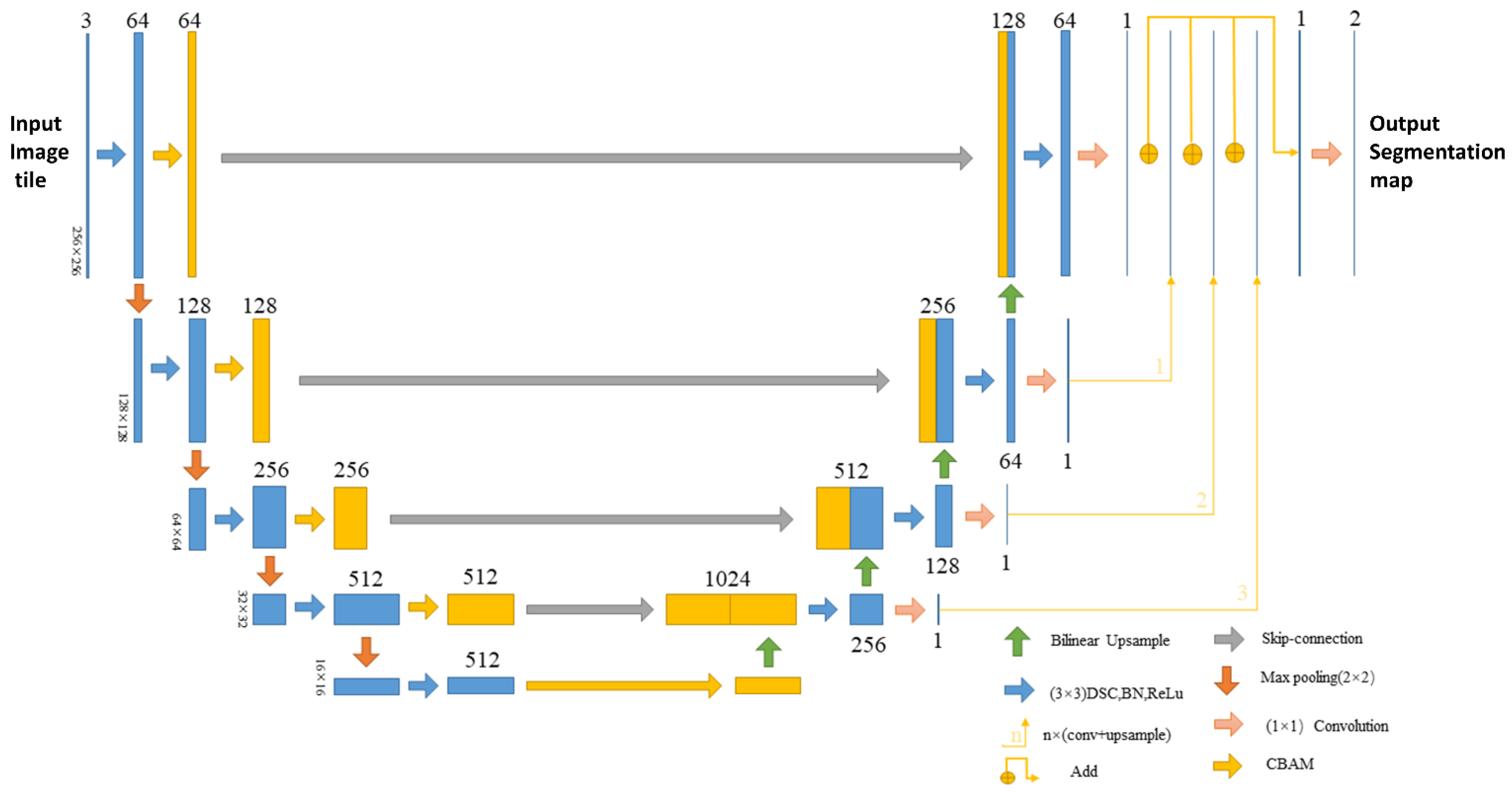
2.2.1. SAH-Unet
2.2.2. CBAM Attention Mechanism
2.2.3. Multi-Scale Feature Fusion Mechanism
2.2.4. Depthwise-Separable Convolutions
2.2.5. Model Training and Evaluation
2.2.6. Model Evaluation
3. Results
3.1. Training and Validation Results
3.2. Metric Results
3.3. Visualization Results
3.4. Generalization Results
3.5. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| Avgpool | average-pooling |
| CART | classification and regression tree |
| CBAM | convolutional block attention module |
| CNNs | Convolutional neural networks |
| DSC | depthwise-separable convolutions |
| FCN | fully convolution neural network |
| FN | false negative |
| FP | false positive |
| FPN | Feature Pyramid Network |
| GEE | Google Earth Engine |
| MAnet | multi-scale attention network |
| Maxpool | max-pooling |
| MFAB | Multi-scale Fusion Attention Block |
| MFF | multi-scale feature fusion |
| MLP | multi-layer perceptron |
| OSM | OpenStreetMap |
| PAB | Position-wise Attention Block |
| PAN | Pixel Aggregation Network |
| PSPNet | Pyramid Scene Parsing Network |
| SAH-Unet | Small Attention Hybrid Unet |
| SDGs | sustainable development goals |
| TN | true negative |
| TP | true positive |
| USGS | United States Geological Survey |
References
- Elmqvist, T.; Andersson, E.; Frantzeskaki, N.; McPhearson, T.; Olsson, P.; Gaffney, O.; Takeuchi, K.; Folke, C. Sustainability and resilience for transformation in the urban century. Nat. Sustain. 2019, 2, 267–273. [Google Scholar] [CrossRef]
- United Nations Department of Economic and Social Affairs (UN DESA). Commission on Population and Development, Fifty-Sixth Session. 2023. Available online: https://www.un.org/development/desa/pd/events/CPD56 (accessed on 1 September 2022).
- Parekh, J.R.; Poortinga, A.; Bhandari, B.; Mayer, T.; Saah, D.; Chishtie, F. Automatic detection of impervious surfaces from remotely sensed data using deep learning. Remote Sens. 2021, 13, 3166. [Google Scholar] [CrossRef]
- Mohajerani, A.; Bakaric, J.; Jeffrey-Bailey, T. The urban heat island effect, its causes, and mitigation, with reference to the thermal properties of asphalt concrete. J. Environ. Manag. 2017, 197, 522–538. [Google Scholar] [CrossRef] [PubMed]
- Shrestha, B.; Ahmad, S.; Stephen, H. Fusion of Sentinel-1 and Sentinel-2 data in mapping the impervious surfaces at city scale. Environ. Monit. Assess. 2021, 193, 556. [Google Scholar] [CrossRef] [PubMed]
- United Nations Department of Economic and Social Affairs (UN DESA). Sustainable Development Goals Report 2017. Available online: https://www.un.org/en/desa/sustainable-development-goals-report-2017 (accessed on 1 November 2022).
- United Nations. Transforming Our World: The 2030 Agenda for Sustainable Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Hu, D.; Chen, S.; Qiao, K.; Cao, S. Integrating CART algorithm and multi-source remote sensing data to estimate sub-pixel impervious surface coverage: A case study from Beijing Municipality, China. Chin. Geogr. Sci. 2017, 27, 614–625. [Google Scholar] [CrossRef]
- Yang, L.; Huang, C.; Homer, C.G.; Wylie, B.K.; Coan, M.J. An approach for mapping large-area impervious surfaces: Synergistic use of Landsat-7 ETM+ and high spatial resolution imagery. Can. J. Remote Sens. 2003, 29, 230–240. [Google Scholar] [CrossRef]
- Coseo, P.; Larsen, L. Accurate characterization of land cover in urban environments: Determining the importance of including obscured impervious surfaces in urban heat island models. Atmosphere 2019, 10, 347. [Google Scholar] [CrossRef]
- Bau, D.; Zhu, J.-Y.; Strobelt, H.; Lapedriza, A.; Zhou, B.; Torralba, A. Understanding the role of individual units in a deep neural network. Proc. Natl. Acad. Sci. USA 2020, 117, 30071–30078. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Learning deep features to recognise speech emotion using merged deep CNN. IET Signal Process. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chaurasia, A.; CulurcielloLinknet, E. Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface water mapping by deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Khankeshizadeh, E.; Mohammadzadeh, A.; Moghimi, A.; Mohsenifar, A. FCD-R2U-net: Forest change detection in bi-temporal satellite images using the recurrent residual-based U-net. Earth Sci. Inform. 2022, 15, 2335–2347. [Google Scholar] [CrossRef]
- Cai, B.; Wang, S.; Wang, L.; Shao, Z. Extraction of urban impervious surface from high-resolution remote sensing imagery based on deep learning. J. Geo-Inf. Sci. 2019, 21, 1420–1429. [Google Scholar]
- Pang, B.; Huang, Z.; Lu, Y. Mapping of Impervious Surface Extraction of High Resolution Remote Sensing Imagery Based on Improved Fully Convolutional Neural Network. Remote Sens. Inf. 2020, 35, 47–55. [Google Scholar]
- Sun, Z.; Zhao, X.; Wu, M.; Wang, C. Extracting urban impervious surface from worldView-2 and airborne LiDAR data using 3D convolutional neural networks. J. Indian Soc. Remote Sens. 2019, 47, 401–412. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, K.; Shen, Z.; Deng, J.; Gan, M.; Liu, X.; Lu, D.; Wang, K. Mapping impervious surfaces in town–rural transition belts using China’s GF-2 imagery and object-based deep CNNs. Remote Sens. 2019, 11, 280. [Google Scholar] [CrossRef]
- Zhang, H.; Wan, L.; Wang, T.; Lin, Y.; Lin, H.; Zheng, Z. Impervious surface estimation from optical and polarimetric SAR data using small-patched deep convolutional networks: A comparative study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2374–2387. [Google Scholar] [CrossRef]
- McGlinchy, J.; Muller, B.; Johnson, B.; Joseph, M.; Diaz, J. Fully Convolutional Neural Network for Impervious Surface Segmentation in Mixed Urban Environment. Photogramm. Eng. Remote Sens. 2021, 87, 117–123. [Google Scholar] [CrossRef]
- Jia, J.; Liang, X.; Ma, G. Political hierarchy and regional economic development: Evidence from a spatial discontinuity in China. J. Public Econ. 2021, 194, 104352. [Google Scholar] [CrossRef]
- Global Times. Another Turkish Consulate General Approved to be Set Up in Chengdu. 2021. Available online: https://www.globaltimes.cn/page/202107/1228068.shtml (accessed on 1 September 2022).
- Guo, S.; Deng, X.; Ran, J.; Ding, X. Spatial and Temporal Patterns of Ecological Connectivity in the Ethnic Areas, Sichuan Province, China. Int. J. Environ. Res. Public Health 2022, 19, 12941. [Google Scholar] [CrossRef] [PubMed]
- Figueira, A.R. Rupturas e continuidades no padrão organizacional e decisório do Ministério das Relações Exteriores. Rev. Bras. Polít. Int. 2010, 53, 05–22. [Google Scholar] [CrossRef]
- Hamama, I.; Yamamoto, M.-Y.; ElGabry, M.N.; Medhat, N.I.; Elbehiri, H.S.; Othman, A.S.; Abdelazim, M.; Lethy, A.; El-Hady, S.M.; Hussein, H. Investigation of near-surface chemical explosions effects using seismo-acoustic and synthetic aperture radar analyses. J. Acoust. Soc. Am. 2022, 151, 1575–1592. [Google Scholar] [CrossRef] [PubMed]
- Wiki, O. Slippy Map Tilenames. Available online: https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames (accessed on 1 September 2022).
- Google Earth. Google. Retrieved January 1. 2021. Available online: https://en.wikipedia.org/wiki/Google_Earth (accessed on 1 September 2022).
- “Openstreetmap-Website/Config/Locales at Master”. Archived from the Original on 28 February 2017. Retrieved 30 September 2019. Available online: https://github.com/openstreetmap/openstreetmap-website/tree/master/config/locales (accessed on 1 September 2022).
- “OpenStreetMapStatistics”. OpenStreetMap. OpenStreetMapFoundation. Archived from the Original on 13 August 2021. Retrieved 18 October 2022. Available online: https://planet.openstreetmap.org/statistics/data_stats.html (accessed on 1 September 2022).
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Hutchinson, M.; Samsi, S.; Arcand, W.; Bestor, D.; Bergeron, B.; Byun, C.; Houle, M.; Hubbell, M.; Jones, M.; Kepner, J. Accuracy and performance comparison of video action recognition approaches. In Proceedings of the 2020 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 22–24 September 2020; pp. 1–8. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, S.-H.; Fernandes, S.L.; Zhu, Z.; Zhang, Y.-D. AVNC: Attention-based VGG-style network for COVID-19 diagnosis by CBAM. IEEE Sens. J. 2021, 22, 17431–17438. [Google Scholar] [CrossRef]
- Chen, L.; Sun, Q.; Wang, F. Attention-adaptive and deformable convolutional modules for dynamic scene deblurring. Inf. Sci. 2021, 546, 368–377. [Google Scholar] [CrossRef]
- Canayaz, M. C+ EffxNet: A novel hybrid approach for COVID-19 diagnosis on CT images based on CBAM and EfficientNet. Chaos Solitons Fractals 2021, 151, 111310. [Google Scholar] [CrossRef]
- Du, Y.; Song, W.; He, Q.; Huang, D.; Liotta, A.; Su, C. Deep learning with multi-scale feature fusion in remote sensing for automatic oceanic eddy detection. Inf. Fusion 2019, 49, 89–99. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Frickenstein, A.; Rohit Vemparala, M.; Unger, C.; Ayar, F.; Stechele, W. DSC: Dense-sparse convolution for vectorized inference of convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Civalek, Ö. Buckling analysis of composite panels and shells with different material properties by discrete singular convolution (DSC) method. Compos. Struct. 2017, 161, 93–110. [Google Scholar] [CrossRef]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do imagenet classifiers generalize to imagenet? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5389–5400. [Google Scholar]
- Cazenave, T.; Sentuc, J.; Videau, M. Cosine Annealing, Mixnet and Swish Activation for Computer Go. In Advances in Computer Games: 17th International Conference, ACG 2021, Virtual Event, 23–25 November 2021; Revised Selected Papers; Springer International Publishing: Cham, Switzerland, 2022; pp. 53–60. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.086814. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the convergence of adam and beyond. arXiv 2019, arXiv:1904.09237. [Google Scholar]
- Yuan, Y.; Xie, J.; Chen, X.; Wang, J. Segfix: Model-agnostic boundary refinement for segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 489–506. [Google Scholar]
- Nash, W.; Drummond, T.; Birbilis, N. Quantity beats quality for semantic segmentation of corrosion in images. arXiv 2018, arXiv:1807.03138. [Google Scholar]
- Chang, Y.-T.; Wang, Q.; Hung, W.-C.; Piramuthu, R.; Tsai, Y.-H.; Yang, M.-H. Weakly-supervised semantic segmentation via sub-category exploration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8991–9000. [Google Scholar]
- Shah, D.K. Impervious Surface Probability Distribution Mapping of Kathmandu Valley; University of Salzburg: Salzburg, Austria, 2021. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters |
|---|---|
| Unet | 17,272,577 |
| Unet with CBAM | 17,428,781 |
| Unet with DSC | 3,955,185 |
| SAH-Unet | 4,121,398 |
| Actual Labels | Predicted Labels | |
|---|---|---|
| Impervious | Permeable | |
| Impervious | TP | FN |
| Permeable | FP | TN |
| Set | Model | Mean Accuracy Score | Mean Loss |
|---|---|---|---|
| LinkNet | 0.9153 | 0.0979 | |
| DeepLabv3+ | 0.9237 | 0.0831 | |
| Training set | PAN | 0.9293 | 0.0745 |
| Unet | 0.9352 | 0.0706 | |
| MAnet | 0.9337 | 0.0690 | |
| PSPNet | 0.9089 | 0.0947 | |
| FPN | 0.9262 | 0.0807 | |
| SAH-Unet | 0.9432 | 0.0640 | |
| LinkNet | 0.8543 | 0.1511 | |
| DeepLabv3+ | 0.8714 | 0.1327 | |
| Validation set | PAN | 0.8656 | 0.1400 |
| Unet | 0.8863 | 0.1206 | |
| MAnet | 0.8830 | 0.1209 | |
| PSPNet | 0.8375 | 0.1673 | |
| FPN | 0.8682 | 0.1367 | |
| SAH-Unet | 0.8873 | 0.1169 |
| Model | Accuracy | MIOU | F-Score | Recall | Precision |
|---|---|---|---|---|---|
| LinkNet | 0.8759 | 0.7836 | 0.8726 | 0.8866 | 0.8596 |
| DeepLabv3+ | 0.8974 | 0.8166 | 0.8944 | 0.9096 | 0.8805 |
| PAN | 0.8907 | 0.8062 | 0.8875 | 0.9003 | 0.8756 |
| Unet | 0.9078 | 0.8339 | 0.9041 | 0.9149 | 0.8943 |
| MAnet | 0.9052 | 0.8299 | 0.9020 | 0.9150 | 0.8902 |
| PSPNet | 0.8747 | 0.7799 | 0.8712 | 0.8821 | 0.8609 |
| FPN | 0.8885 | 0.8019 | 0.8859 | 0.9040 | 0.8693 |
| SAH-Unet | 0.9159 | 0.8467 | 0.9117 | 0.9199 | 0.9042 |
| Model | Accuracy | MIOU | F-Score | Recall | Precision |
|---|---|---|---|---|---|
| Unet | 0.9078 | 0.8339 | 0.9041 | 0.9149 | 0.8943 |
| Unet with CBAM | 0.9096 | 0.8386 | 0.9095 | 0.9164 | 0.9003 |
| Unet with MFF | 0.9105 | 0.8391 | 0.9102 | 0.9166 | 0.9009 |
| Unet with DSC | 0.9021 | 0.8320 | 0.9019 | 0.9100 | 0.8895 |
| SAH-Unet | 0.9159 | 0.8467 | 0.9117 | 0.9199 | 0.9042 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, R.; Hou, D.; Chen, Z.; Chen, L. Automatic Extraction of Urban Impervious Surface Based on SAH-Unet. Remote Sens. 2023, 15, 1042. https://doi.org/10.3390/rs15041042
Chang R, Hou D, Chen Z, Chen L. Automatic Extraction of Urban Impervious Surface Based on SAH-Unet. Remote Sensing. 2023; 15(4):1042. https://doi.org/10.3390/rs15041042
Chicago/Turabian StyleChang, Ruichun, Dong Hou, Zhe Chen, and Ling Chen. 2023. "Automatic Extraction of Urban Impervious Surface Based on SAH-Unet" Remote Sensing 15, no. 4: 1042. https://doi.org/10.3390/rs15041042
APA StyleChang, R., Hou, D., Chen, Z., & Chen, L. (2023). Automatic Extraction of Urban Impervious Surface Based on SAH-Unet. Remote Sensing, 15(4), 1042. https://doi.org/10.3390/rs15041042