1. Introduction
Computer vision-based technologies are widely used in different applications, for example, in medical, agriculture, security, and conservation research. These achievements are also among the key pieces to many embedded Autonomous Vehicle (AV) applications [
1,
2] in the race toward developing a fully autonomous machine. However, it remains a challenging issue in the research community. Currently, smart vehicles with embedded AV technologies are equipped with multiple types of sensors aiming to gather data in different ranges that can be synchronically interpreted for a clear understanding of the surroundings (i.e., the locations of road users or other obstacles and the relative dynamic interactions between them). Recent machine learning developments have reached impressive achievements in computer vision tasks. A vast amount of research and methods have been developed for multi-sensor data fusion [
3,
4,
5,
6] to synergize the gathered information while omitting redundant data. This allows for storing more knowledge and employing lower amounts of data.
Identifying features in a complex background often targets road users, i.e., people and vehicles, relative to the vehicle’s perspective, whether static or dynamic. Scanning vehicles is dynamic in and of itself, whether they be static or moving, making the spatial representation of a complex environment time-dependent with no absolute static state. Each object’s dynamic level is measured relative to the moving vehicle. Hence, challenges arise from several basic cumulative demands, including an ongoing and continuous sense of the vehicle’s surroundings, dynamic driving abilities that fit different road types (highway, city roads, etc.), the ability to operate in different lighting and environmental conditions, and the real-time ability to detect static and dynamic targets (road users) in changing scenarios.
Lighting conditions affect the acquired data. Natural lighting level (daylight) is a dynamic factor, subject to the effects of the season and the time of day, and the sun’s position and levels of radiation change throughout the day and seasons. The probability of blurring arises around dawn and sunset hours due to the sun’s lower position. Less informative data samplings containing obscured features might occur due to the blurring effect resulting from the diversity of artificial night-time light sources, such as streetlights, vehicles’ headlights, lighted signs, digital advertising screens, and building lights. Light frequencies generated by different types of light origins affect sensors differently. These days, LED lamps commonly used in the public domain in different lighting fixtures emit radiation in the range of visible light to near-infrared wavelengths (depending on the color of the installed LED lamp).
The sensors’ ability to capture informative data is also influenced by weather conditions [
7,
8,
9,
10]. Rain, fog, and haze are masking effects caused by high amounts of water droplets, sand, and dust grains in the air. Cloudy or partially cloudy skies, extreme temperatures, and wet roads differently affect sensing capabilities along with the lighting conditions (natural or artificial lights). Shading, dazzling from objects with high reflectivity, or a shimmering effect might occur when puddles or hot roads are in the scanned scene. These many influences contribute to the high variability found in the acquired data. The additional influence could be exerted by the effect of trees and buildings’ shadows, or for instance, the sudden darkness while driving through tunnels.
Evaluating the contribution of fused data to better perception by Convolutional Neural Networks (CNNs) is performed in relation to well-known CNN object detectors trained with RGB images and considering the suitability of the model’s architecture to operate in real-time with low computational resources. Among the CNN algorithms for image recognition tasks are two-stage-based architectures, e.g., AlexNet, VGG16, GoogLeNet, and ResNet. Region-based CNN (R-CNN) [
11] proposed a bounding-box regression-based approach, later developed into Fast R-CNN [
12], Faster R-CNN [
13], and R-FCN (Region-based Fully Convolutional Network) [
14]. Faster R-CNN uses the region proposal network (RPN) method to classify bounding boxes, followed by finetuning to process the bounding boxes [
15,
16]. One significant drawback of the two-stage architecture is its slow speed detection, resulting in the inability to produce real-time results as required for AV applications. An alternative approach is a one-pass regression of class probabilities and bounding box locations, e.g., Single Shot Multibox Detector (SSD) [
17], Deeply Supervised Object Detector (DSOD) [
18], RetinaNet [
19], EfficientNet [
20], You Only Look Once (YOLO) architecture developed by Redmon et al. [
21], etc. These methods unite target classification and localization into a regression problem, do not require RPN, and directly perform regression to detect targets in the image.
YOLO became a widely used algorithm due to the model’s small size and fast calculation speed. It constructs a backbone for pre-training and a one-stage head to predict classes and bounding box (dense prediction) layers. Subsequent versions described as YOLO V2 [
22], YOLO V3 [
23], YOLO V4 [
24], and YOLO V5 [
25], published in the following years, attempted to improve the low-detection accuracy of the original model and its inefficiency in small target detection. The main developments in YOLO versions were reviewed by Jiang et al. [
26]. YOLO V2 offered better and faster results by improving the inaccuracy positioning, lowering the recall rate, and switching the primary network used for training from GoogLeNet to Darknet-19, simplifying the network’s architecture. In YOLO V3, feature graphs of three scales were adopted using three prior boxes for each position, later divided into three scale feature maps added to a multi-scale detection. However, the feature extraction network used the residual model, which contained 53 convolution layers (Darknet-53) instead of the Darknet-19 used in YOLO V2, enabling it to focus on comparing data. YOLO V4 optimized the speed and accuracy of object detection. Some of its substantial improvements include adding spatial pyramid pooling (SPP) block with an increased receptive field, which separates significant features, MISH activation function, Cross-Stage-Partial-connections (CSP), enhancement by mosaic data augmentation, and Generalized Intersection over Union (GIOU) loss function. YOLO V5 is similar to YOLO V4, but it is based on the PyTorch platform, different from Darknet, which is mainly written in C.
The neural networks fed with RGB and thermal data gained tremendous progress in the last decade with dozens of algorithms, offering a variety of methods for the fusion of image sources in different phases of the learning process [
27,
28,
29,
30,
31]. The fused data might overcome the challenges of accurate detection of dynamic objects in a complex scene captured by dual sensors on moving vehicles. Complex scenes relate to changing environmental conditions in daylight or nightlight. Changing lighting effects causes different reactions to dynamic scenes.
In a review of real-time detection and localization algorithms for AV conducted by Lu et al. [
32], the authors concluded that since no single sensor can meet all localization requirements for autonomous driving, fusion-based techniques would be the research focus for achieving a cost-efficient self-localization for AV. In addition, they pointed out that future research is required to focus on sensors’ faulty detection and identification techniques and imperfect data modeling approaches to ensure robust and consistent AV localization. Chen et al. [
33] summarized the importance and advantages of visual multi-sensor fusion. In a review of sensing systems for AV environmental perception technologies, a set of open challenges were listed: the lack of a theoretical framework for targeting generic fusion rather than specific fields; ambiguity in associating different sensors’ data; poor robustness; insufficient integration of fusion methods; and the lack of a unified standard specification and evaluation criteria.
Many reviews have been published in recent years on infrared and visible image fusion methods in the context of AV [
6,
28,
30,
34]. The fusion process in the context of neural network architectures may occur in different stages of the learning process: pre-network fusion generates a new single input for the network using by fusing the row data; network-based fusion (or fusion as part of multimodal architecture) is categorized by the phase in which the data is fused [
35]. The early fusion approach uses multiple origins of raw data as input. Data from each origin is separately processed to unite and refine data from the different sensors, followed by a pixel-level fusion layer. The middle (halfway) fusion processes each input layer using parallel convolution-based encoder blocks to extract the valuable data from each source. The extracted features are then fused and forwarded as a single input or additive data (e.g., feature maps, optical flow, density maps, etc.) for the next network block to be interpreted. Li and Wu [
36] proposed fusing feature maps of VIS and IR images that were decomposed using an encoder consisting of a convolutional layer and a dense block prior to reconstructing the fused data with a decoder block. The late fusion (model level) selectively takes place after the network has separately segmented and classified features from each data source based on pre-defined thresholds and the situation in a test.
The main aim of this paper is to evaluate the best method to pre-process the fusion of multi-sensorial data (RGB and thermal cameras) captured using sensors in motion (mounted on AV) that enables CNNs to robustly detect and classify vehicles and pedestrians in complex backgrounds and mixed datasets (daylight and nightlight images).
The developed method includes a pre-processing stage of data fusion combining anomaly detection, enabling the classification of dynamic objects from the complex background. A novel anomaly-based feature extraction process is proposed to overcome the above-mentioned AV challenges in CNN classification tasks. The RGB images are transformed to the intensity, hue, and saturation coordinates, and the improved contrast image is registered to the thermal (IR) image via the affine module to enhance and generalize the RGB images. A global Reed–Xiaoli anomaly detector map (GRXD) from the enhanced RGB data is calculated and normalized to an anomaly image representation. Then both enhanced and anomaly images are integrated with the IR image into a new physical value image representation. The fused images are robustly enriched with texture and feature depth, reducing dependency on lighting or environmental conditions. Such images are used as input for a CNN to extract and classify vehicles and pedestrians in daylight and nightlight images.
The rest of this paper is organized as follows.
Section 2 describes levels of fusion, different methods to decompose the raw images prior to the fusion process, and fusion rules to combine the decomposed images. In addition, the challenges of fusing images from different sensors are described.
Section 3 describes the FLIR dataset and the tested scenarios, as well as the proposed pre-processing of the dual data followed by feature extraction methods (range filter and RXD anomaly detection) and different data fusion techniques. Thereafter, the setting and training of CNN YOLO V5 and the final dataset versions used to train the networks are presented. In
Section 4, the classification results of the trained networks are detailed. Further, in
Section 5, the results and the contribution of the proposed method to reduce network failure in detection and classification tasks are discussed. Finally, the conclusions are presented in
Section 6.
2. Related Works
In image processing, it is common to relate to three levels in which the data can be fused: Pixel-level fusion, also known as low level, where the raw pixel data of both images are fused [
37]; Feature-level (region-based) fusion, which implies that the source images are first separately processed to extract the features of interest based on mutual and distinct characteristics with the extracted features then used in the fusion process; Decision-level (high-level fusion), where each source is initially processed and understood. At this level, the fusion only takes place if the extracted and labeled data meets the predetermined criteria. Most pixel-level fusion methods are based on the multi-scale transform in which original images can be decomposed into components of different scales by means of low-pass and high-pass filters. Multi-scale-transform fusion schemes consist of two key steps: the multi-scale decomposition method and fusion rules. Then, a corresponding inverse multi-scale transform is applied to reconstruct images using coefficients. Pyramid transform [
34] decomposes sub-images via a pyramid structure generated from different scales of spatial frequency (e.g., Laplacian pyramid transform and Steerable decomposition technique). The Wavelet Transform proposed by Mallat [
38] is a fast and efficient method for representing multi-scale uncorrelated coefficients and is widely used in fusing visual and thermal images. Discrete Wavelet Transform (DWT) decomposes the source image signals into a series of sub-images of high and low frequencies at zero scale space representing the detailed coefficients and approximation coefficients. The approximation coefficients can be further decomposed to the next level (to detail and approximation) repeatedly until the desired scale is reached. Regardless of its robustness, the DWT is known to suffer oscillation problems, shift variance, aliasing, and lack of directionality. Stationary Wavelet Transform (SWT) solves the problem of shift-invariance, thus contributing to preserving more detailed information in the decomposition coefficients [
39]. A dual-tree complex Wavelet Transform shows improved performance in computational efficiency, near shift-invariance, and directional selectivity due to a separable filter bank [
40]. Lifting Wavelet Transform has the advantages of adaptive design, irregular sampling, and integral transform over DWT [
41]. Additional techniques include lifting Stationary Wavelet Transform [
42], redundant-lifting non-separable Wavelet multi-directional analysis [
43], spectral graph Wavelet Transforms [
44], quaternion Wavelet Transform, motion-compensated Wavelet Transform, multi-Wavelet, and other fusion methods being applied at the feature level due to their spatial characteristics. Gao et al. [
45] used the non-subsampled contourlet transform (NSCT) for its flexibility and for being fully shift-invariant. The edge-preserving filter technique was combined with the fusion method [
46]. This technique aims to decompose the source image into a smooth-base layer and one or more detail layers. As a result, the spatial consistency of structures is preserved while reducing halo artifacts around the edges.
The fusion rules set the method to combine the decomposed coefficients, such as coefficient combination (max and weighted averages) in pixel-level fusion. When fusion takes place at the feature level, fusion rules are according to the region level. The most representative method for feature level is based on the salient region, which aims to identify regions more salient than their neighbors. Other fusion rules are sparse representation-based methods that aim to learn an over-complete dictionary from a large amount of high-quality natural images. Each source image is decomposed into overlapping patches using a sliding window strategy. Furthermore, an over-complete dictionary is learned from many high-quality natural images, and sparse coding is performed on each patch to obtain the sparse representation coefficient using the learned over-complete dictionary. The fusion is applied according to the given fusion rule, reconstructing the image according to the fusion coefficients and the learned over-complete dictionary. This method can enhance the fused images to a meaningful and stable representation, reduce visual artifacts, and improve robustness.
The feature-level fusion process aims to identify objects by their regional characteristics. Accurately segmenting the target object’s foreground from its background is a key phase for better object detection. Many algorithms were proposed to segment the information from the visualized data for AV purposes, as well as for medical procedures and early disease detection, smart agriculture, defense and security purposes, and many other fields of research. The color transformation is used in various disciplines in the pre-processing phase of data fusion, before segmentation and classification tasks, to mainly enhance the feature’s border without blurring the featured foreground. Saba et al. [
47] used Laplacian filtering followed by HSV color transformation to enhance the border contrast of images of skin lesions as part of pre-processing before color CNN-based segmentation and detection of melanoma. Afza et al. [
48] used HSI transformation to enrich the contrast of video frames before fusion-based feature selection to target human action recognition. Adeel et al. [
49] applied lab color transformation before multiple feature fusion tasks guided by the canonical correlation analysis (CCA) approach to recognize grape leaf diseases.
In the AV context, the data can sometimes be treated as features, a saliency map, or optical flow extraction. Images captured by sensors in motion contain measured characteristics by time. Therefore, the segmentation of the complex foreground (i.e., object movement in space) from the complex background (also due to unexpected environmental effects) is still considered a challenging task.
Morphological-based approaches, such as texture, color, intensity level, or shape-based methods, for example, can be separately and selectively used on each of the source images to extract the object of interest. An additional approach is to enhance the object’s border and, thus, segment it from its background. Researchers offer various techniques, morphological and statistical, to straighten the object’s boundaries and suppress its background, or a combination of both, for better feature extraction before the fusion process. Following the segmentation task, extracted layers (of pre-processed foreground and background) can be fused using a pixel fusion method based on their regional properties.
The fusion of contradictory signals might cause destructive interference. Therefore, finding the ultimate color coordinate representation yielding the most informative fused data is of great importance, more so when targeting a robust pre-processing for images from different scenarios, lighting, and weather conditions. Mustafa et al. [
31] designed a self-attention mechanism combining multi-contextual and complementary features of IR and RGB images into a compact fused image representation.
However, a prerequisite for successful image fusion arises when using images from different sources: images should be strictly aligned in advance. Data acquisition using multiple sensors for AV is considered a common and acceptable method. Each sensor lens’ parameters and relative position result in different information being captured. Image registration is the process of adjustment between two images captured by a single sensor at different times or by two (or more) sensors from different angles. The registered image is aligned with the same coordinate system as the original image through a transformation of the registered image matrix. Precise and accurate image registration is necessary for accurate object detection [
50,
51,
52,
53,
54].
3. Methodology
3.1. Datasets
The existence of large and varied datasets is a cornerstone for the generic learning process. In many previous works on different aspects of AV, the availability of suitable datasets for training and testing was discussed [
50,
55,
56]. Recently, Ellmauthaler et al. [
53] presented an RGB and IR video database (VLIRVDIF), encouraged by the shortage of publicly available RGB-IR-synchronized dual databases. The authors also proposed a registration method to align the dual sensor data taken in distinct recording locations with varying scene content and lighting conditions. However, the offered dataset was captured by fixed sensors that were pre-calibrated at each location. The targeted dataset of visual and thermal multi-sensors synchronized and annotated real-world video captured from moving vehicles was found to be almost unavailable. In addition, the various scenarios and the changing environmental conditions’ representation makes the datasets even harder to obtain.
In July 2018, FLIR Systems, Inc. released an IR dataset for Advanced Driver Assist Systems (ADAS) [
57]. The dataset contains over 14K images of daylight and nightlight scenarios, acquired via synced RGB and IR cameras mounted on a vehicle while driving in Santa Barbara, California. The captured scenes correspond to urban streets and highways between November and May with clear-to-overcast weather. The IR images were recorded using FLIR Tau2 640 × 512, 13 mm f/1.0 (HFOV 45°, VFOV 37°) and FLIR BlackFly (BFS-U3-51S5C-C) 1280 × 1024, Computer 4–8 mm f/1.4–16-megapixel lens for RGB images. The centerline of the images was approximately located 2 inches apart and collimated to minimize parallax. The dataset was recorded at 30 Hz. Dataset sequences were sampled at 2 frames/sec or 1 frame/sec. Video annotations were performed at 30 frames/sec recording (on IR images). Cars, as well as other vehicles, people, bicycles, and dog classes, were annotated. Since its publication, the FLIR dataset has been used in many research works to detect objects in adverse weather conditions using thermal images either as the main goal or as complementary data for other sensors’ data extraction [
58,
59,
60].
The FLIR-ADAS dual dataset was chosen to train, test, and validate the proposed model. About 2500 diverse images from the FLIR-ADAS dataset were used to train, validate, and test networks for data pre-processing phase evaluation. The RGB image dimensions are 1600 × 1800 × 3 (
Figure 1a) and 1536 × 2048 × 3 (
Figure 1c). All dual IR image sizes are 512 × 640 (
Figure 1b,d).
The dataset included: near and far objects; diverse scene representation, such as main and side urban roads, city junctions, and intercity highways; different conditions under clear daylight, such as sunny sky, cloudy sky, dazzling low sun of twilight hours in front and from behind the camera, object under shadowed area, etc.; and nightlight with low and strong street lighting, and dazzling objects. Examples of diverse scenes are shown in
Figure 2.
The final dataset contains 1275 unique images of natural luminance conditions (daylight images) and 1170 unique images of artificial lighting conditions (nightlight images) of diverse scenes, comprising various sources of lights and objects of different scales and appearances, as described above. The annotation ratio is 19% pedestrians and 75% cars. The remaining 6%, consisting of bicycles and pets, were ignored due to their low representation. Daylight and nightlight images were grouped into a dataset named Mixed Dataset, containing a total of 2445 images.
3.2. Analysis
Analysis workflow consisted of three steps: pre-processing, processing, and post-processing.
3.2.1. Pre-Processing
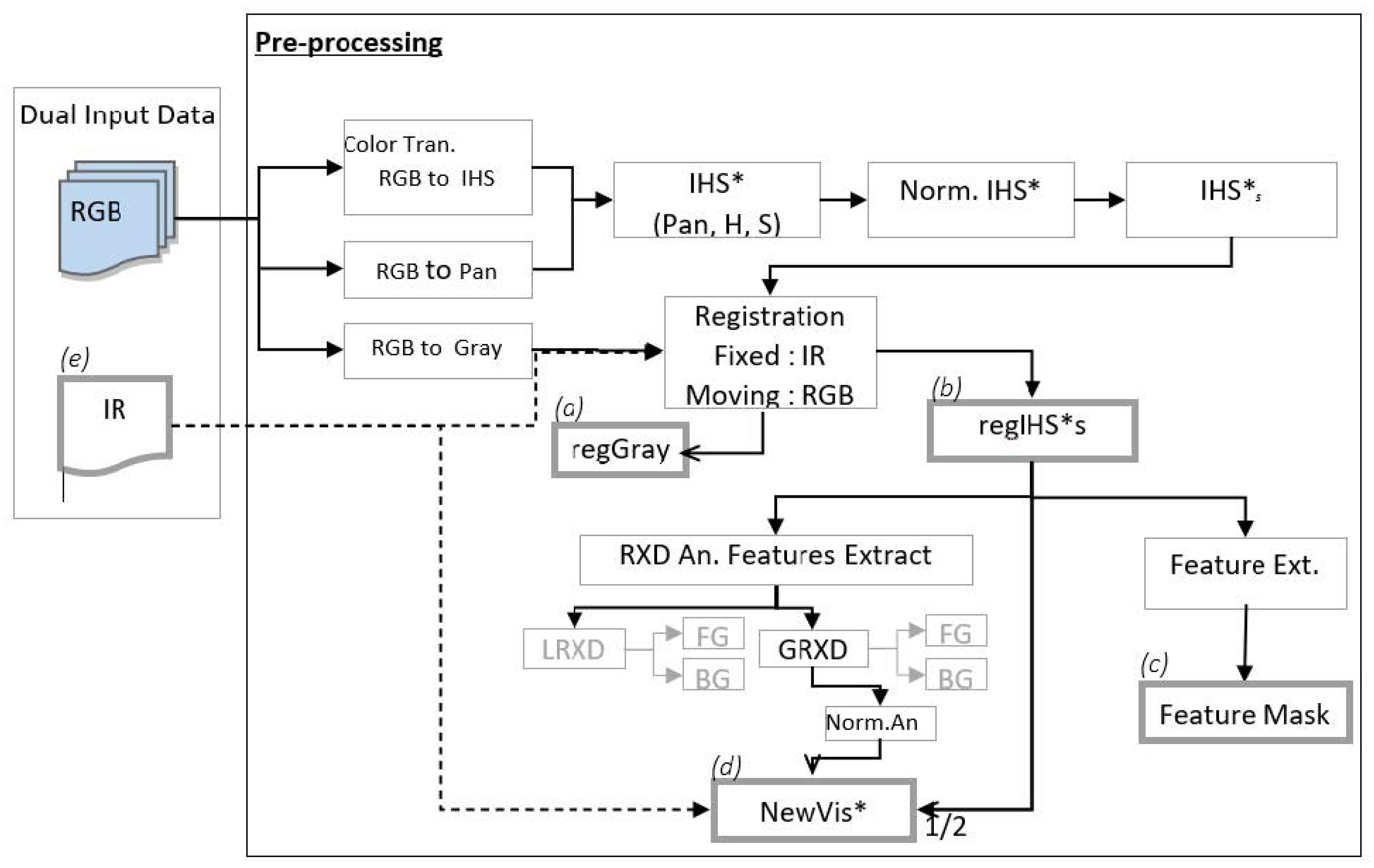
The pre-processing workflow is presented in
Figure 3 and contains the following steps: color transformation for the RGB image data; image registration (applied on RGB data according to IR); anomaly-based feature extraction; new RGB representation/reconstruction; and pixel-level and feature-level based fusion.
The proposed pre-processing workflow is as follows.
Figure 3.
Schema of the proposed pre-processing workflow. Final products of the pre-processing phase are a registered grey representation of an RGB image (a), a registered saturation layer of an IHS image (b), a feature mask based on the (b) layer (c), and a new visual image representation (d) constructed from the integration of (b), RXD-based global anomaly of (b) and IR image (e).
Figure 3.
Schema of the proposed pre-processing workflow. Final products of the pre-processing phase are a registered grey representation of an RGB image (a), a registered saturation layer of an IHS image (b), a feature mask based on the (b) layer (c), and a new visual image representation (d) constructed from the integration of (b), RXD-based global anomaly of (b) and IR image (e).
Registration
The different methods relate to the type of geometric adjustment to apply to the matrix’s values include: non-reflective similarity, similarity, affine, and projective. In their work, Jana et al. [
64] used affine transformations to learn the distortions caused by camera angle variations. Li et al. [
65] applied an affine transformation to feature-wise edge incorporation as an initial process to EC-CNN for thermal image semantic segmentation. In this work, the transformation matrix was calculated according to fixed points (IR image) and moving points (RGB image), that were manually registered. The dual captured data in the FLIR dataset offers images that were extracted from several recording sessions. Nevertheless, being mounted on a vehicle, the captured images reflect minor shifts in the sensor’s position, resulting in a non registrated images. Since the misregistration is minor (shift of 2–3 pixels) a manual registration approach was proposed. For each recording session, a single t-form for the entire session’s corresponding dual images, was calculated. The residual misregistration (subpixel level) was was further included in that general inaccuracy caused by the vehicles’ inherent shift and treated via data fusion. The coefficients matrix was based on affine translation. The saturation layer of the IHS transformed image was registered to the size and coordinates of IR image. This was performed using a pre-defined t-concord matrix suited to each pair of dual images,. The output layer was named regIHS*s. In addition, the grayscale image of RGB was registered to the IR image. The output was named regGray. These layers will be used in the next steps.
Proposed Anomaly-Based Pre-Process
Anomaly Detection (AD) methods, e.g., BACON [
66] and RXD [
67], are statistical approaches to measuring each pixel’s probability of belonging to the background, assuming a multivariate normal distribution of the background. Guo, Pu, and Cheng [
68] examined several methods to detect anomalies. In the pre-processing phase, using AD for feature extraction can contribute to the generalization of the data. While analyzing RGB images, a global anomaly of daylight images contributes to better foreground segmentation, but anomaly-based foreground extraction of nightlight images tends to extract blurred patches.
The
RXD is a commonly used method for anomaly detection. In this method, no specific data is marked as an anomaly. It relies on the assumption that the image background is multidimensionally distributed. Therefore, the background pixels’ sampling will have a lower probability value, and the anomalies are expected to have a higher value of probability. Based on this assumption, the local anomaly of an image is calculated by Equation (2),
where
RXD(x) stands for the image’s local anomaly, (
x −
μ)
T is the transposed vector of values calculated by subtracting the (
x) pixel in the test from
μ (the mean of
x’s 8-pixel neighborhood) and
∑ is the covariance matrix usually deployed as the image covariance instead of the neighborhood covariance. A global anomaly will be calculated according to Equation (3),
where
X is the pixel under testing (or a vector of the sliding window values) and
μ(G) and
∑G are the mean and covariance of all pixels in the image, respectively. The expression (
X −
μ(G))
T represents the transposed substruction vector. This expression is later multiplied, firstly by the image covariance powered by −1 and secondly by
X −
μ(G). An example of the local and global anomaly of an image is shown in
Figure 6.
Following the pre-process, as detailed earlier (color transform and image registration), the saturation layer of the regIHS*s is used to calculate the image’s global anomaly according to Equation (3). Next, GRXD is normalized between 0 and 1 and further multiplied by 255.
A pseudo-RGB (
NewVis*) image is reconstructed according to Equation (4). Given that
regIHS*s is a registered, color-converted 2D layer of the RGB image,
normAN is the normalized detected global anomaly of
regIHS*s, and
IR is the original IR image.
The NewVis* is calculated by subtracting the normalized anomaly values from half of the transformed RGB layer and adding IR values. This image reconstruction aims to narrow the diversification of digital representation caused by natural differences between daylight and nightlight images, hence creating a generalized RGB representation.
3.2.2. Processing
Image Fusion Methods
The Stationary Wavelet Transform (SWT) algorithm is used for the fusion process as demonstrated in [
69,
70]. SWT decomposes the input signals into scaling and Wavelet coefficients, enabling the preservation of the image texture and edge information while reconstructing the fused signals from the sub-bands back to the image. By being shift-invariant, SWT can effectively reduce distortion caused by the heterogenous data representation of RGB and IR images.
In the SIDWT decomposition phase, each row in the image is separately filtered using high-pass (HP) and low-pass (LP) filters. Next, this image is filtered again along the columns. The output is four sub-bands in the first decomposition level. Three sub-bands (LH, HL, and HH), also known as filter coefficients, contain the horizontal, vertical, and diagonal frequencies’ details along with sub-band LL. The approximation data are transferred onto the next decomposition level. The decompose frequency is increased by a factor of 2(i − 1) on the i
th level of the algorithm, so each n decomposition level will have 3n + 1 sub-bands. In this paper, a SymLet Wavelet (sym2) is applied. Following the pre-processing steps in
Section 3.2, the fusion process is presented in
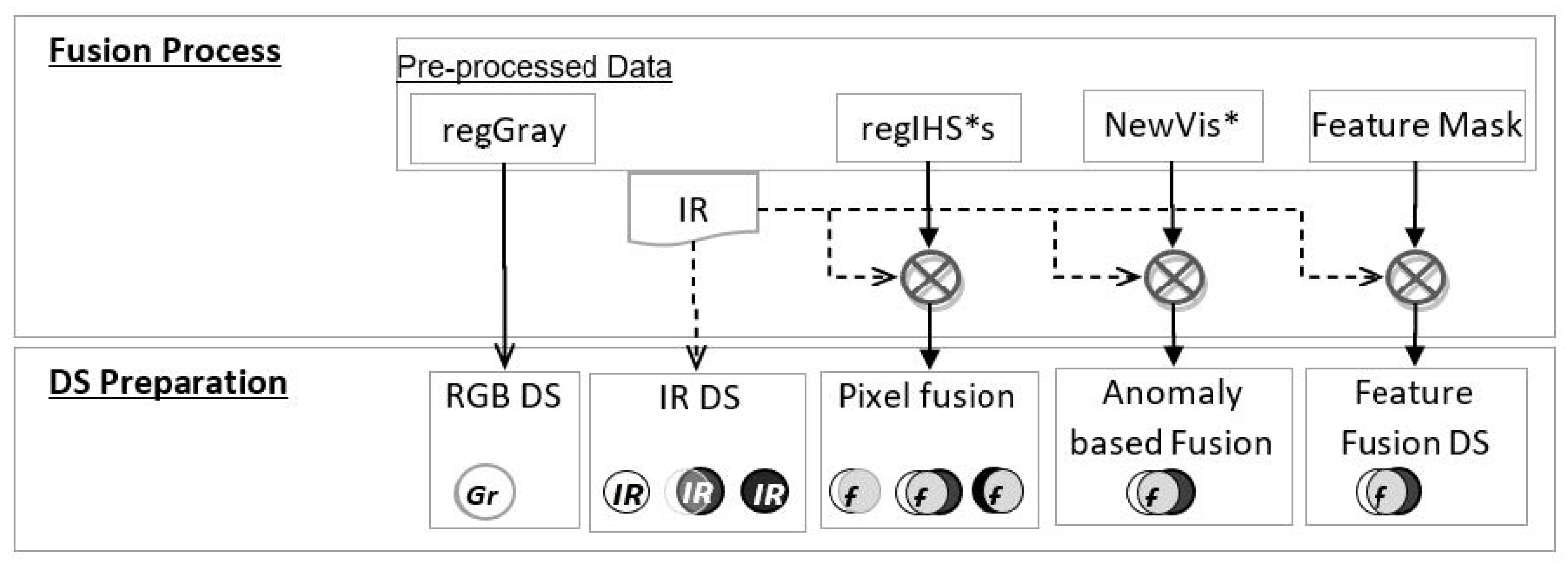
Figure 7.
The fusion process is shown below.
Figure 7.
Fusion process schema and the resulting datasets for training, validating, and testing the networks.
Figure 7.
Fusion process schema and the resulting datasets for training, validating, and testing the networks.
Each unique image from the final dataset (2445 images) was processed according to the proposed algorithms described in
Section 3.2, resulting in three types of processes for comparison: dual-RGB (
regIHS*s) and -IR images fused at the pixel level, range-filter-based feature extraction of the pre-processed RGB image (Feature Mask) fused with IR images (as RF Feature Fusion), RXD-based anomaly feature extraction of pseudo-RGB (
NewVis*), and IR image fusion (as RXD Anomaly Feature Fusion). The original IR images dataset (as IR) was also tested for comparison vs. dual data. Examples of feature fusion images are shown in
Figure 8. The created
NewVis* fused with the corresponding IR image.
An additional set of 42 new, diverse images was defined as the Test DS, containing 23 images of nightlight scenes and 19 images captured in daylight. A list of the total datasets used for training the networks is detailed in
Table 1.
Table 2 lists all Test DS variations that were prepared. Ground truth properties of Test DS are detailed in
Appendix A.
The datasets used for network training are shown below.
Table 1.
Mixed set of images (a total of 2445 daylight and nightlight images) was created with each of the listed processes (IR, pixel-level fusion, RXD anomaly-based fusion, and feature fusion). Datasets containing only day images were separately prepared for RGB, IR, and pixel-level images. DSs containing only nightlight images were prepared for IR images and pixel-level fusion images.
Table 1.
Mixed set of images (a total of 2445 daylight and nightlight images) was created with each of the listed processes (IR, pixel-level fusion, RXD anomaly-based fusion, and feature fusion). Datasets containing only day images were separately prepared for RGB, IR, and pixel-level images. DSs containing only nightlight images were prepared for IR images and pixel-level fusion images.
| Dataset | No. of Images | RGB | IR Images | Pixel Level Fusion | RXD Anomaly Fusion | Feature Fusion |
|---|
| Total (Mixed DS) | 2445 | | ✓ | ✓ | ✓ | ✓ |
| Daylight Images DS | 1275 | ✓ | ✓ | ✓ | | |
| Nightlight Images DS | 1170 | | ✓ | ✓ | | |
A list of test datasets is shown below.
Table 2.
Mixed set of images containing a total of 42 images (19 daylight images and 23 nightlight images) was created with each of the listed processes as the Test DS. RGB images were tested only on daylight images.
Table 2.
Mixed set of images containing a total of 42 images (19 daylight images and 23 nightlight images) was created with each of the listed processes as the Test DS. RGB images were tested only on daylight images.
| Dataset | No. of Images | RGB
Images | IR Images | Pixel Level Fusion | RXD Anomaly Fusion | Feature Fusion |
|---|
| Total (Mixed) Test DS | 42 | | ✓ | ✓ | ✓ | ✓ |
| Daylight Images | 19 | ✓ | | | | |
| Nightlight Images | 23 | | | | | |
3.2.3. Post-Processing
The resulting fused sets of images referenced to the original IR images were validated for the most effective process to yield the best physical value as input. Effectiveness in this manner means a robust pre-processing that will reduce the variation between diverse scene image representations while preserving the synergy advantage of the gathered multi-sensor information.
CNN Installation and Network Training
A convolutional neural network (CNN) based on the YOLO V5 architecture (initially trained on the cityscape dataset) was trained to detect and classify four classes: cars, pedestrians, dogs, and bicycles (the last two classes were later ignored due to a low number of annotations). The model was deployed using the Roboflow framework, installed on PyTorch environment version 1.5, Python 3.7, and CUDA 10.2., and was executed with Google Colab, which facilitates a 12 GB NVIDIA Tesla K80 GPU. The YOLO V5 structure is presented in
Figure 9. The input size was set to 640, and the batch size to 16. The training was set to 750 epochs. Data allocation was set to 70% for training, 20% for validation, and the remaining 10% for tests. The initial learning rate was set to 0.01. YOLO V5 was chosen for training for the advantages mentioned in
Section 1, as well as for it being smaller and generally easier to use in production, and the model’s eligible image input types, together with the connectivity offered by the model between its platform and a free storage framework. Another advantage is the free access the model offers for training multiple networks.
At first, the network was separately trained with each of the daylight/nightlight sets: RGB images (daylight dataset only) and IR images, and low-level processed images that were fused at the pixel level for comparison.
Next, the network was trained with the mixed datasets (daylight and nightlight images) of IR images, RXD Anomaly Fusion, feature fusion, and pixel-level fusion. Weights of each trained network were used to detect and classify the suitable Test DS.
Detected objects were marked with bounding boxes (BB) and labeled with suitable label class names. Results were evaluated using a confusion matrix (pixel level) according to the following indicators (Equations (5)–(7)):
where
Td is the number of truly detected pixels divided by
GT, which stands for the total number of ground truth pixels (overlap between YOLO and ground truth), and
in which
OAd is the number of all detected pixels by YOLO divided by
GT.
The IoU (Intersect over Union) indicator is calculated by dividing Td (that is, the number of true detected pixels by YOLO) with the sum of GT and OAd minus Td, reflecting the number of pixels in all marked areas (both in GT and in YOLO, overlapping pixels counts once).
An image is considered successfully classified when gained IoU > 0.5.
The networks’ prediction performances were compared using the
F1 score (Equation (8)):
4. Results
The training results with different datasets were examined for classes (cars and pedestrians) in daylight and nightlight images according to the classification scores (average IoU).
Given the above-mentioned challenges of image complexity, the proposed pre-processing was applied before feature fusion in an attempt to create a feature-based dataset using different threshold ranges for each of the source images. An additional effect that seems to decrease the efficiency of feature fusion according to a level of intensity threshold is the patchiness of the gathered artificial input caused by integrating layers of data, which create artificial edges that might overcome the object’s edges. These limitations ended up in partially segmented, noisy, fused images. Therefore, intensity-based feature fusion was not tested further in this framework.
Table 3 and
Table 4 detail the networks’ scores in classifying the unseen test dataset images, which were processed with the same method each network was trained.
Training the network to detect cars with only daylight images (
Table 3) yields the best result in the pixel-level fusion method (83%), slightly better than the IR dataset (81%) and much better than classifying cars in daylight scenes using RGB unprocessed dataset (68%). Networks trained with only nightlight images (
Table 4) result in a correct classification of 82% using the IR dataset and only 74% when trained on the pixel-level fusion dataset.
Training networks with a mixed dataset (
Table 5) show an improvement in car detection (84% success) compared with training networks using IR daylight images separately. Training with a mixed dataset contributes to the same scores (84%) in all fusion methods that were tested for classifying cars in daylight images. All networks trained with fused mixed datasets show good performance in classifying cars (above 80%) in nightlight images. Pixel-level fusion reached the best score of 84% for correct classification.
None of the methods overperformed the 84%, hinting at the IoU benchmark drawbacks to be discussed further.
Detection and classification of pedestrians, however, is distributed in a wider range of scores and can imply the challenges of this task. Early training attempts using separated datasets for daylight and nightlight images led to low performance in all datasets: the unprocessed IR dataset reached 53%, followed by 47%, and 35% with the pixel-level fusion dataset and unprocessed RGB image, respectively (
Table 3). Training networks with mixed datasets (
Table 6) showed improved results in classifying pedestrians in daylight images. The best scores were reached with the IR dataset (68%), followed by feature fusion-level and anomaly-level fusion methods that also reached relatively high scores (64% and 62%, respectively). The lowest score for classifying pedestrians in daylight images is shown when the network was trained with a mixed dataset at pixel-level fusion (55%).
Training the networks with a mixed DS: pedestrians
Networks trained with mixed DS show the advantage of the proposed anomaly-level fusion method in classifying pedestrians in nightlight scenes (
Table 6). Using the proposed method achieves 81% correct pedestrian classification in nightlight, an improvement compared with the other tested datasets (79%, 78%, and 75% with feature-level fusion, IR, and pixel-level fusion, respectively) and a significant improvement over training with a dataset of nightlight images only, which yielded 71% on IR dataset and 54% using the pixel-level fusion dataset (
Table 4).
An IoU score higher than 0.5 was set as an indication of the network’s success in classifying an image. The number of images each network failed to classify was counted. Results of networks’ failure in classifying objects to the selected categories are summarized in
Table 7 and
Table 8 (detailed tables appear in
Appendix B) according to the dataset type and classification category.
A network trained with a mixed dataset of IR images failed to classify cars in one image. A network trained with pixel-level fusion succeeded in classifying all images as car objects. The feature-level fusion and the anomaly-level fusion images did not use daylight and nightlight images as separate datasets for training; therefore, it is not included in this comparison.
5. Discussion
The results show an advantage for training mixed datasets over separated datasets for daylight and nightlight images. A key factor for this analysis is that none of the methods overperformed (84% IoU) for pedestrian classification. This limit might be caused by the disadvantage of the evaluation method.
The fusion of multiple sensors can yield synergy in fused data by preserving valuable information from each data source. The distinct advantage of the IR sensor is the ability to expose warmer objects (e.g., pedestrians) in a dark scene and its insensitivity to reflected dazzling lights. The IR image is usually flattened relative to RGB images and lacks object depth information.
IoU is a known and acceptable benchmark for measuring neural network performance in segmentation and classification tasks. However, this benchmark has several limitations in performance evaluation. First, IoU is calculated based on the ground truth, and the benchmark score is influenced by the annotation quality. An unmarked object (by an annotator) that is classified by the network is considered an error, while often, these detected objects are correct, so the network classifies better than the annotator. In addition, the proximity of dynamic objects to the scanning sensors and their position (object’s size as a proportion of the image size) may affect the detection scores differently. Naturally, closer objects are marked with a large area (number of pixels for bounding box), and far objects are marked with a smaller bounding box size. A minor shift in a bounding box created by the network, relative to the marked ground truth, may differently affect the measured error ratio on bounding boxes with a small number of pixels (the number of counted pixels in a shifted bounding box area to bounding box size is comparatively high), for which any shift in the bounding box location might slightly reduce the score. Hence, the IoU benchmark was used to evaluate the network’s success in segmentation and classification tasks.
Examination of the contribution of a mixed dataset to the success of the network in classifying cars from daylight images revealed that only three images were detected with IoU scores lower than 50%. The total average for detecting cars in daylight and nightlight is 82.7%, and the distributed averages are 83.7% for daylight and 81.8% for nightlight images. Some of the lowest scores were caused by a greater accuracy of the network in object detection relative to the annotated ground truth, as will be detailed later.
A network trained on a mixed dataset, processed with anomaly-based fusion, succeeded in the classification of all daylight images. The overlap rate between network detection to the annotated ground truth reached 89%, and the area marked by the network to the annotated ground truth area was 96.5%, meaning a high accuracy level for classifying cars in daylight images. The image in
Figure 10 shows the effect caused by different resolutions in the dual image: part of the ground truth annotation marked on the IR image is out of the frame captured by the RGB image. Fusion enables us to overcome these challenges. Furthermore, unmarked cars in the manual ground truth annotation were detected and correctly classified by the network, leading to an IoU score of 73% for this image, which might be considered a false negative from the IoU score.
A network trained on a mixed dataset of anomaly-level fused images classified cars in all nightlight images of the test dataset. The overlap ratio between the marked area by the network to the annotated ground truth was 91.8%. The networks’ classified area to the annotated ground truth area ratio was 110%. These scores show the network’s high accuracy level, though the error rate is slightly increased. Some of this erroneous rate is due to correct networks’ over-classification of unmarked objects in the annotated ground truth (
Figure 11).
A network trained on a mixed dataset of anomaly-level fused images reached an average IoU of 62.6% in classifying pedestrians in daylight images. The average overlap ratio between the network’s classification area to the annotated ground truth area was 70.1%. The average network’s classified area to the annotated ground truth area was 88.3%.
In some images, few objects were misclassified by the network, yet several images gained low scores due to pedestrian classification based on the correct detection of unmarked ground truth annotation (
Figure 12).
The annotated ground truth area ratio was 111%. Out of two images that scored less than 50% IoU, the first was partially classified by the network, while the second was correctly classified by the network as a missing annotation on ground truth.
An additional drawback of the IoU marker (
Figure 13) arises when classifying small (usually far) objects. A minor shift in the detected bounding box from the annotated ground truth bounding box leads to a substantial reduction in the IoU score, despite correct classification by the network. Image FLIR_07989, for example, was successfully classified by the network but scored only 71%.
Each trained network’s result was separately summed up for daylight and nightlight datasets classification in comparison to the mixed dataset classification to evaluate the contribution of mixed datasets in lowering the network classifications’ failure. This evaluation was conducted based on a trained network with IR images comparing pixel-level fusion images only.
Images containing zero objects from one of the classes (overall GT area = 0) were eliminated due to computation limitations (divided by zero). In the car category, out of 42 images in the test set, four images with no cars were eliminated. The network performance was tested on 38 mixed images, out of which 17 were in daylight, with the remaining 21 in nightlight. In the pedestrian category, eight out of 42 images were discarded (images with zero objects in the pedestrians’ category). In practice, the network’s performances in classifying pedestrians were tested on 34 images, out of which 16 images were in daylight and 18 images were in nightlight.
The network trained with IR images on separate datasets for daylight and nightlight (
Table 5) failed to classify cars in three images in total (8%). A network trained on a mixed dataset decreased the rate of failure in car classification to one image only (3%), an improvement of 5% in the network’s success.
Training the network with separate datasets of IR images for daylight and nightlight (
Table 6) resulted in 32% in pedestrian classification (a total of 11 misclassified images). Training on a mixed dataset decreased the rate of failure of the network to 12%, a total of four out of 34 images.
The network trained with pixel-level fused images on separate datasets for daylight and nightlight failed to classify six images with car objects (16% out of 34 images with car annotations). A network trained on a mixed dataset successfully classified cars in all images with an IoU score higher than 50%, i.e., 0% network failure (
Table 5).
Training the network with separate datasets of pixel-level fused images failed in 56% of pedestrian classifications (a total of 19 misclassified images). Training on a mixed dataset decreased the rate to 24%, a total of eight images out of 34 daylight and nightlight mixed scenes and improved the network’s success by 32% in classifying objects as pedestrians (
Table 6).
6. Conclusions
The pre-processing method intends to handle issues emerging from combining input from multiple types of sensors, such as data registration, values unification, and statistical-based anomaly detection for foreground refinement. By doing so, a reduction in the amount of the gathered data and its variation level caused by differences in sensor types and properties, different lighting and environmental conditions, complex scenes, dynamic objects, etc., was achieved. The unified physical value contributed to the robustness of input data extraction, hence obtaining a better perception of the surroundings under varied environmental states.
We applied the anomaly-level fusion method to suppress the effects of complex dynamic background captured by moving cameras, enabling the model to concentrate on the spatial variation of the moving foreground. With the differences in fusion processes and their contribution to car and pedestrian classification, it can be seen that, due to cars’ flat and smooth textures, all proposed fusion processes yielded a high detection score (80–84%) in classifying a mixed dataset (of daylight and nightlight images) after eliminating the masked effects. Thus, the fusion process, in the context of car detection, makes a major contribution to suppressing masking and background effects.
As for pedestrian detection, a network trained with a mixed dataset of RXD anomaly-level fused images gains the highest average IoU score (75%). The bright appearance of the objects in the IR images contributes to the object’s flattening and, as a result, separately accentuates it from its background. A CNN network trained with RXD anomaly-level fused images classifies pedestrians in nightlight images best (81%) by suppressing the background and masking effects, thus lowering the dependency on accurate registration while maintaining the brightness of pedestrians’ appearances.
Classifying pedestrians from a complex background in daylight images, however, appears to be the most challenging task for the networks, a category that results in the lowest scores in all proposed processes. Enriching the object with texture and depth limits the network’s ability to classify pedestrians as a united, single object; hence, the thermal images achieve the best scores (68%) in pedestrian classification in daylight images. RF feature-level fusion slightly increases the pedestrian’s gradient and adds no texture, while fusing with the IR image yields 64%, slightly lower than IR images and the best out of the examined fusion processes. The authors concluded that as the fusion process expresses a greater range of details from the visual image, the network’s IoU scores in classifying pedestrians in daylight images decrease.
This understanding reinforces the benefits of expressing the color image as a physical value that can contribute to the robustness of the network in training mixed datasets (daylight and nightlight images) by moderating the range of detail enrichment and preserving and neutralizing the masking and background effects in nightlight images.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










