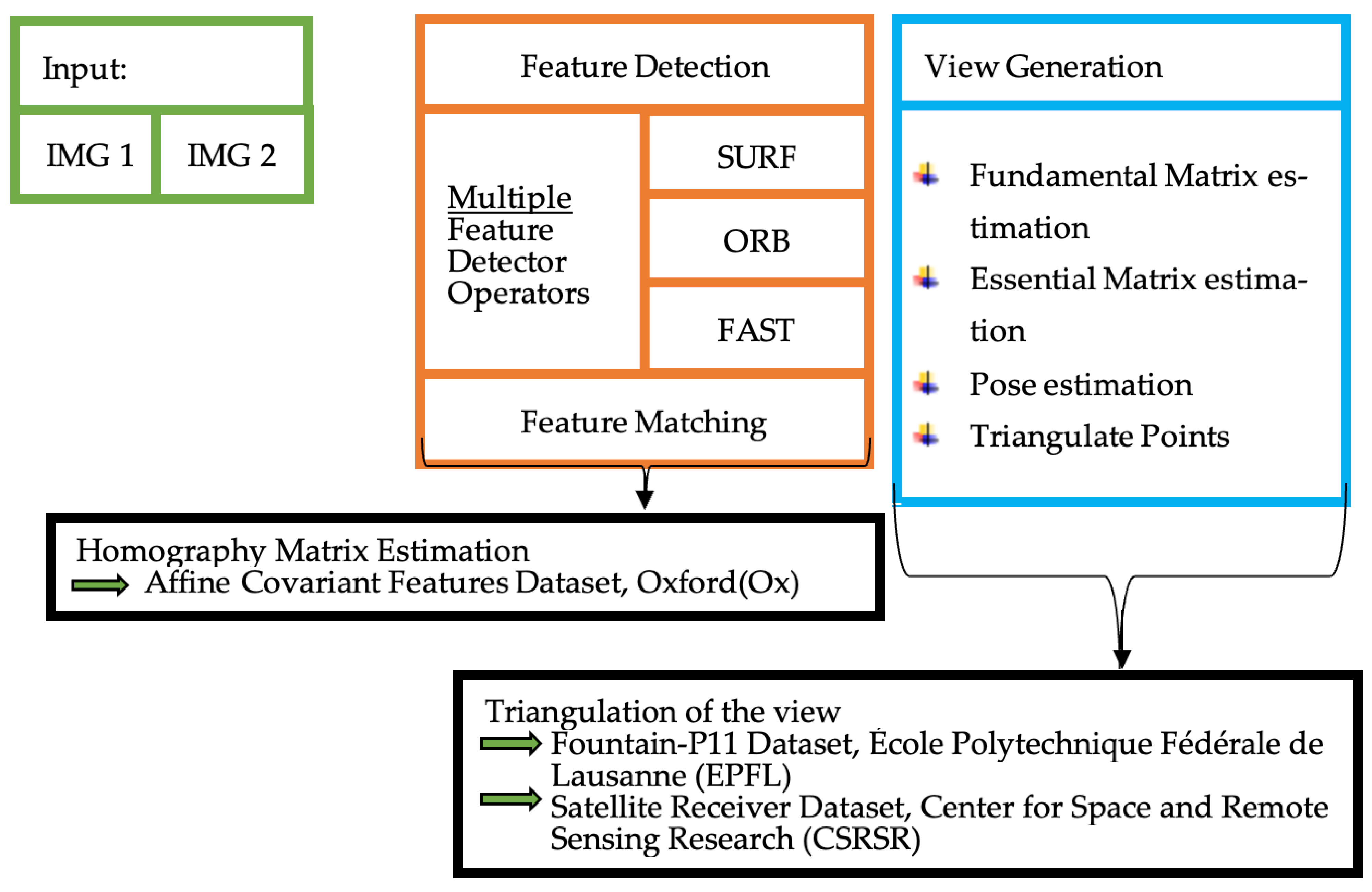
The evaluation is accomplished based on three datasets, two being publicly available and one being a real-world dataset. The results section is divided, for each dataset, into three parts to evaluate each dataset separately and independently.
5.1. Oxford Dataset
The Oxford dataset consists of ground truth (Homography matrix) for every pair. Every case, i.e., illumination (
Figure 2) as explained, consists of five pairs—the reference image with a follow up in the range of img2 to img6. As introduced in
Section 3, all image condition changes are applied to a structured and a textured scene, except Leuven and Ubc (
Table 1). Consequently, the evaluation is group-wise structured. Firstly, bark and boat both with zoom and rotation changes. Then, bike and trees with blur changes, followed by Graf and wall with viewpoint changes. Finally, Leuven with illumination changes and Ubc with JEPG compression. The evaluation includes the RMSE pairwise presented in column bars with the absolute numbers of each group respectively. Further, in table form, the average RMSE appears on one side and the number of features detected on the other side.
The first group focuses on zoom and rotation image condition changes (
Table 1). The bark case is a close-up textured scene with zoom and rotation on level 1, whereas the boat scene is a structured image, which shows a boat as an equal part of a greater scene. This scene has no clear fore- and background with zoom on level 1 and rotation at level 2.
The pairwise RMSE evaluation of H-matrix estimation is shown in
Figure 7. Each column is divided vertically by multi (blue), SURF (orange), ORB (gray) and FAST (yellow) and pairwise horizontally, i.e., I12—reference image 1 with image 2.
The textured scene, bark, seems to be most difficult for FAST even for the first pair: multi (0.445 m), SURF (0.445 m), ORB (0.711 m) and FAST (95.145 m). The multi approach of this study shows good overall performance except for the last pair. Only SURF outperforms our multi approach, except for the first pair. Until pair four (I14) of the boat case, our approach shows outstanding performance. The five (I15) and six (I16) image pairs are handled well only by SURF. The increasing zoom and rotation changes show that FAST struggles the most. However, our approach can balance the struggling operator out. FAST and ORB have higher RMSE values as the combination, multi, would imply. The structured scene (boat) seems to have better results than the textured scene. The structured scene, even with the background, adds enough intensity variety and provides enough individual features to match correctly. The textured scene, on the other hand, lacks individual features; therefore, their corrected match rate is low and RMSE is higher.
The average RMSE evaluation of H-matrix estimation and the average number of features detected for both, bark and boat, are summarized in
Table 2. The orange cell marks out the best average RMSE, whereas the blue cell emphasizes the most features detected for a single operator. SURF realizes on average RMSE of 0.26 m and detects 1003 pt on the bark scene. Our multiple FDO approach achieves 6.55 m (−6.29 m), but detected 2700 pt (+170%). For the boat scene, ORB and FAST performance was unsuitable, where SURF maintained an error under 1 m. SURF realizes an RMSE of 0.14 m and detects 2191 pt. This study of multiple FDO approaches achieves 5.96 m (−5.82 m), but detects 5140 pt (+134%).
The bike scene is a structured close-up with a dominant foreground. The image condition change applied is blur level 1, whereas the trees belong to the textured scene group and the level of blur is in contrast higher, at level 2.
The pairwise RMSE evaluation of H-matrix estimation is shown in
Figure 8. The first three pairs of the bike scene show good overall performance of all FDOs under 1 m. Only SURF and our approach, multi, remain under 1 m, whereas ORB and FAST exceed 1 m. The textured scene of trees seems to retain the error under 1 m, except for one value (I14, FAST 1.292 m). The last pair, I16, shows that only ORB and FAST are able to perform well with 0.845 m and 0.817 m. Our approach is slightly higher with 1.191 m, crossing 1 m line. The blurring effect influences the sharpness of the image, so that strong features become less significant gradually. A scene with an already unclear background seems to be more beneficial than a completely sharp scene (reference image).
The average RMSE evaluation of H-matrix estimation and the average number of features detected for both, bike and trees, are summarized in
Table 3. SURF can achieve an average RMSE of 0.30 m with 3462 pt of the Bikes scenes. This study’s multiple FDO approach achieves 0.36 m (−0.06 m) while detecting 7907 pt (+128%) more points. The result of the trees case shows that ORB and this study‘s multi-FDO can both achieve 0.52 m (−+0). However, ORB detects 179 pt whereas multi-FDO detects 14,941 pt, +9833% more points.
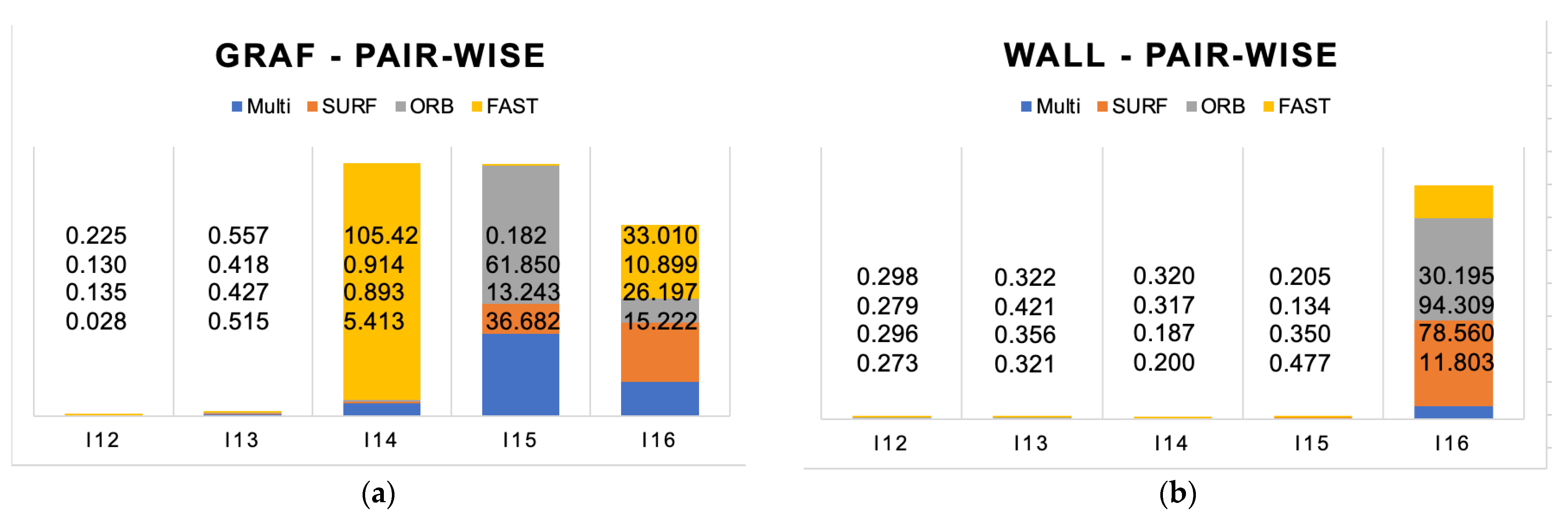
The Graf and wall scenes are both textured scenes with a viewpoint change. The Graf scene is graffiti sprayed onto a flat wall; the viewpoint changes at level 1. The wall scene in contrast is an old-school brick wall as a part of a fence, with a viewpoint change of level 2. The overall performance of the first two pairs is satisfying (
Figure 9). The fourth pair is difficult for our approach and that of FAST. For the fifth pair, FAST performs best; however, for I16, all FDOs are failing. The wall in contrast shows that all FDOs perform for the first four consistently well. The last pair, I16, is the most challenging one for our approach with less than 12 m error best. Viewpoint changes can be considered as the most common challenge in real-world photography. The viewpoint changes with the position changes of the camera, translation, rotation, tilting, etc. The structured Graf scene is therefore much more challenging, even on level 1. The pattern of the graffiti seems to be more challenging than the brick wall, too.
The average RMSE evaluation of H-matrix estimation and the average number of features detected for both, Graf and wall, are summarized in
Table 4. SURF realizes on the Graf scene on average RMSE 8.18 m and detect 1675 pt. This study’s multiple FDO approach achieves 11.57 m (−3.39 m) and detects 3032 pt (+81%) points. For the Wall case, FAST realizes 6.27 m and detects 14′970 pt, whereas this study’s multiple FDO approach achieves 2.62 m (+3.65 m), and detects 18,443 pt (+19%).
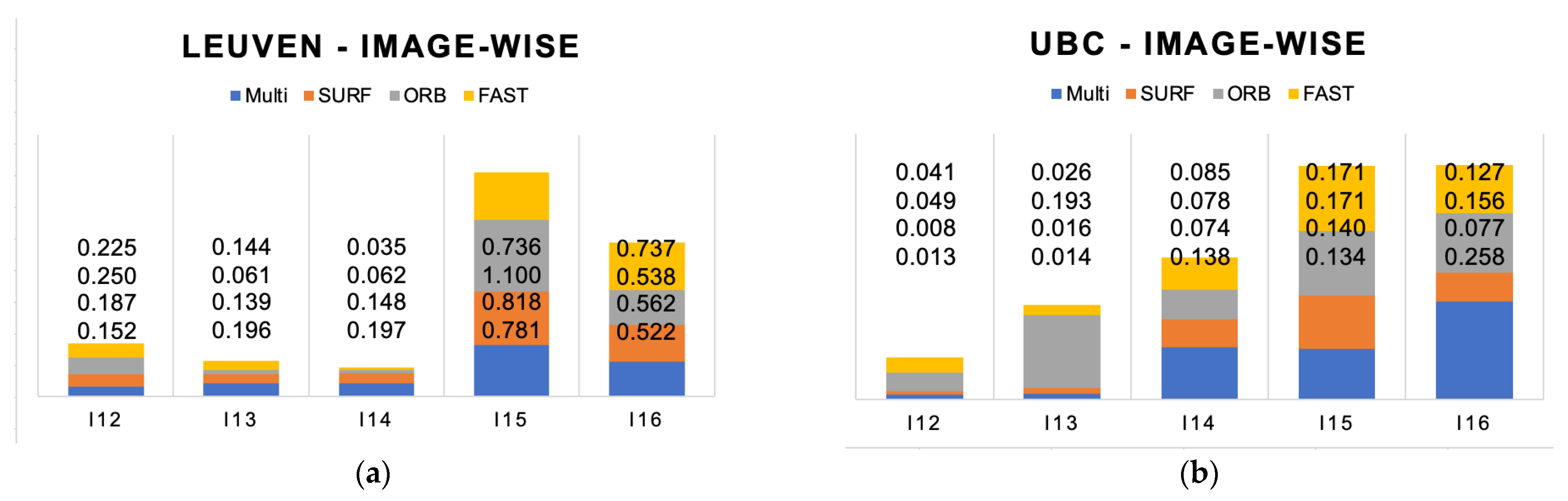
In the last case, the Leuven and Ubc scenes are both structured scenes with different condition changes. The Leuven scene is a close-up with a clear fore- and background, where the illumination changes increasingly pair-by-pair. The Ubc scene is more dominantly scenery with no clear foreground with compression applied increasingly pair-by-pair.
The pairwise RMSE evaluation of H-matrix estimation is shown in
Figure 10. The Leuven case shows that except for one value, all FDOs maintain an error under 1 m. The last two pairs, however, show that illumination can have a greater impact on the result. The compression rate influences the results in a constant manner. All FDOs perform under 0.3 m error. With decreasing illumination, the RMSE rises expectedly. However, the reflection of the car windows and the background make this scene much more difficult, so that the performance was a nice surprise. The JPEG compression, unexpectedly, seems to have much less influence on the RMSE.
The average RMSE evaluation of H-matrix estimation and the average number of features detected for both, Leuven and Ubc, are summarized in
Table 5. SURF and multi-FDO can both achieve 0.37 m (−+0) for the Leuven scene. However, SURF detects 3760 pt whereas this study’s multi-FDO detects 10,840 pt (+188%). On the Ubc JPG compression case, SURF realizes 0.062 m and detects 3681 pt. Our multiple FDO approach achieves 0.11 m (−0.048 m), but detects 15,901 pt (+331%).
5.2. EPFL Dataset
This study applies the first two images as input of the EPFL Fountain-P11 dataset. The scene consists of textured and structured components. The scene contains three major elements: first, the brick wall as a background, and the fountain as the main element in the foreground alone. It is attached to the brick wall, together with these two elements dominating the scene. The third element is a wall of homogenous texture with two windows, connected to the brick wall at 90° angle. The evaluation is divided into two parts: first, the feature accumulation (
Table 6) over the individual, and in this study, the proposed multiple FDO, and second, the visible evaluation of the sparse SfM reconstruction (
Figure 6).
The evaluation of the feature accumulation, summarized in
Table 6, shows how the number of features changes during processing. The first and second columns display the initial absolute number of detected features and the fraction that each individual FDO contributes (fraction1 [%]). SURF detects the most features, 18,763, and contributes by far the biggest fraction with 53.57%, whereas FAST detects the smallest number. The third and fourth columns display the final absolute number of points in the point cloud generation process and the fraction each individual FDO contributes (fraction2 [%]). SURF generates the densest point cloud; however, ORB seems to be more stable and gains a fraction. The last two columns (5 and 6) show the actual loss of points for each variation, respectively, and the absolute and the fraction (fraction3 [%]). ORB seems to be more stable while generating ~15% fewer points. FAST generates the fewest points and losses over the process ~28% of the points generated.
The 3D sparse reconstruction of all four options is displayed in
Figure 11. The top row left side shows the FAST results, and the right, the ORB results. Both reconstructed the textured area of the brick wall but barely got the fountain or the second building with a window.
The bottom left displays the SURF result, which got the wall as well as the fountain recognizable. In addition, the window pattern is identifiable as well. The bottom right is the approach proposed in this study, the multiple FDO. It reconstructed the wall, as well as Fountain. Similarly to SURF, the window and the connected wall are recognizably well reconstructed.
5.3. CSRSR Dataset
The study applied the real-world dataset of CSRSR as introduced to reconstruct the antenna and evaluate performance. This is accomplished by the open-source software MicMac and CloudCompare. This study applied MicMac to generate a sparse point cloud to compare the result of the algorithms proposed in this study. The density analysis was made in the open-source software CloudCompare to analyze the point distribution and the location of maxima and minima.
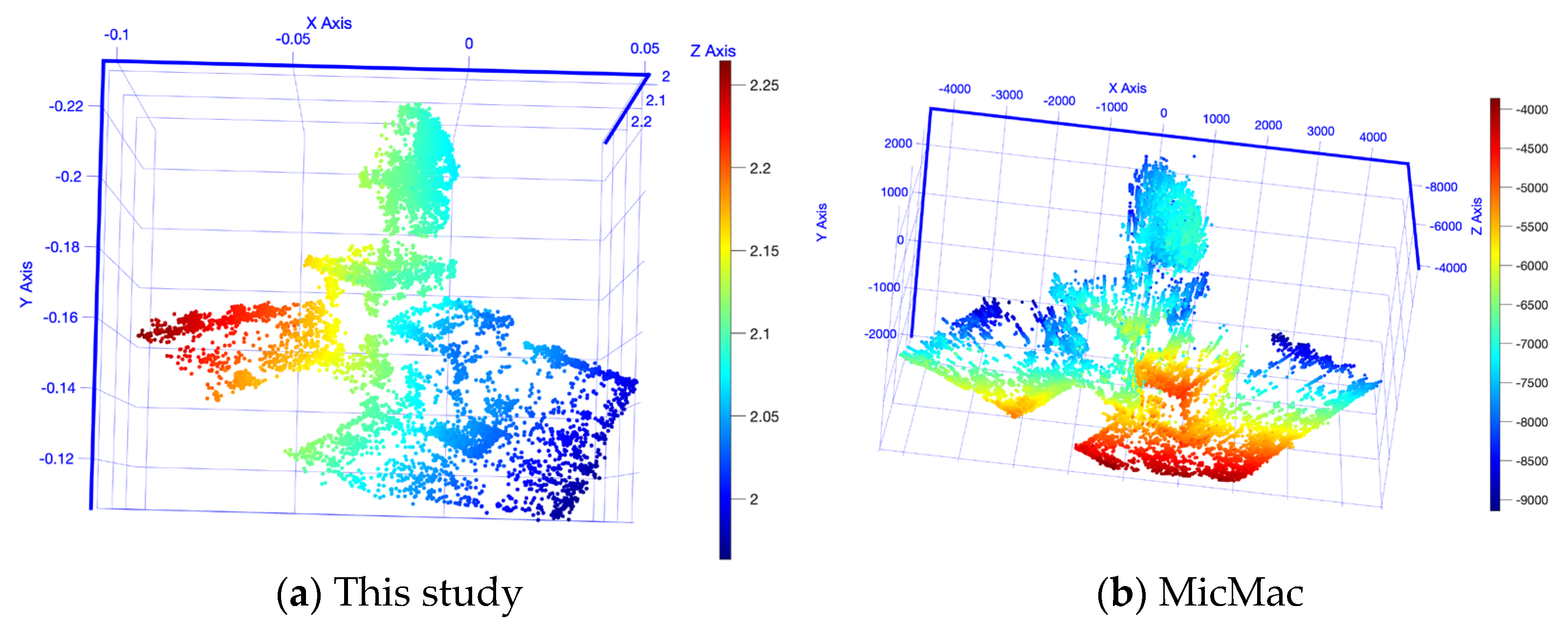
The results of a short baseline 3D reconstruction are shown in
Figure 12, in this study (a) and in MicMac (b). MicMac, as well as the approach proposed in this study, both successfully reconstructed a 3D model. The dish of the antenna and a part of the rooftop are easily recognizable. Nevertheless, the mounting tower is barely recognizable. Some input and output numbers are summarized in
Table 7. This study reconstructed the antenna based on two images only and achieved 4, 378 points. MicMac achieved nearly double that amount with 7803 points. However, MicMac needs a larger number of input images and, as a direct cause, the processing time is larger as well.
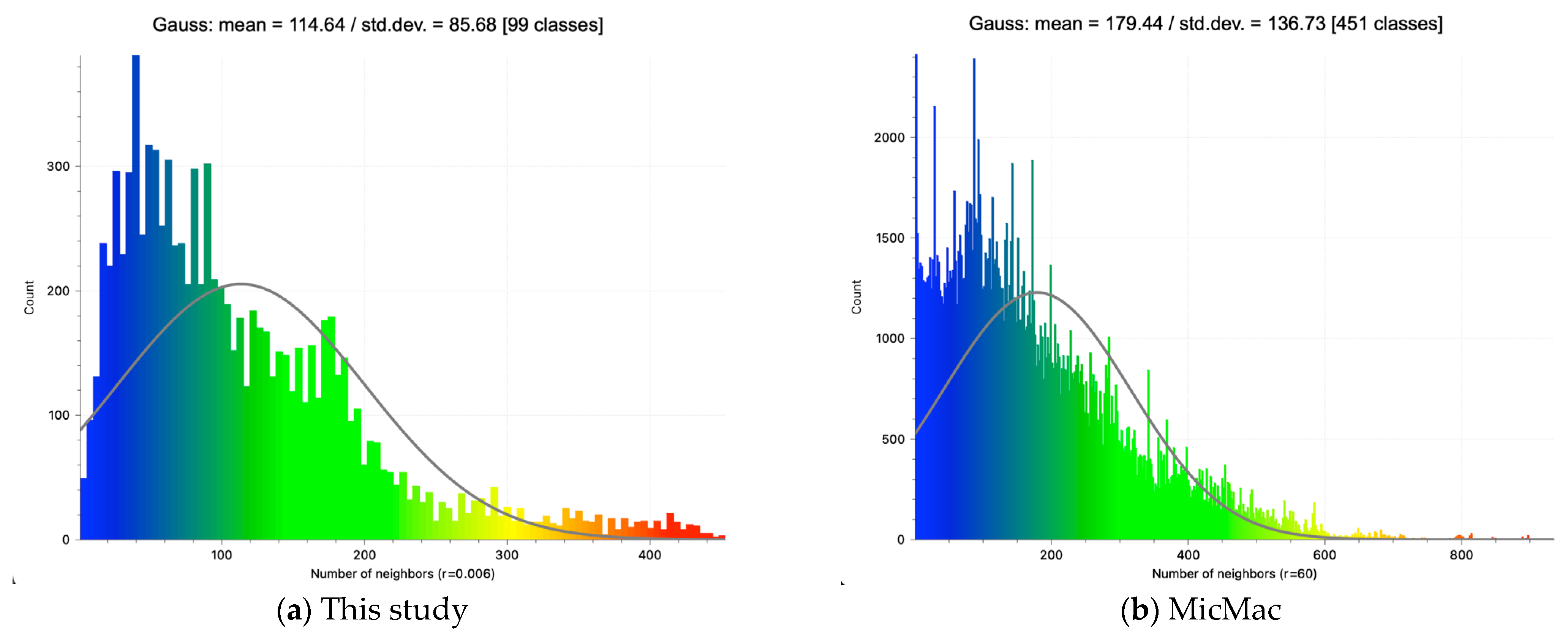
The point density analyses are shown in
Figure 13 with a histogram (Gauss) in
Figure 14. The density analyses show how many neighbors one point within a radius of 0.05 m has. The result generated by MicMac achieves a higher maximum. Most values are located between 0 and 60 neighbors. In contrast, this study reaches a maximum of 50 neighbors per point. The distribution shows every four to five classes a significant local maximum. This can be validated by the plotting. The corner and edges of the roof, as well as the antenna, show areas characterized by higher point density.
The results of the 3D reconstruction shown in
Figure 15 are generated with an increased baseline and camera angle. MicMac, again, generated a denser point cloud than our approach. MicMac generates a point cloud with 203,122 points, whereas our approach has 9666 points. In contrast, MicMac needs many more images (
Table 8) than the approach proposed in this study and as a result, much more time. Interestingly, the reconstruction by MicMac and the approach proposed in this study is off in scale.
This study-generated model is too small with an x-range of −0.1 to 0.05, a y-range of −0.12 to −0.22 and a z-range of 2.2 to 2, whereas the MicMac-generated model is too big with an x-range of −4000 to 4000, a y-range of −2000 to 2000 and a z-range of −4000 to −8000. The 3D model consisting of the antenna with mount, two auxiliary buildings and the actual rooftop are reconstructed recognizably well. The input and output are summarized in
Table 8. This study generated the already-described 3D model with two images and less than 0.15 min. MicMac needed many more images and therefore needed much more time, 202 min.
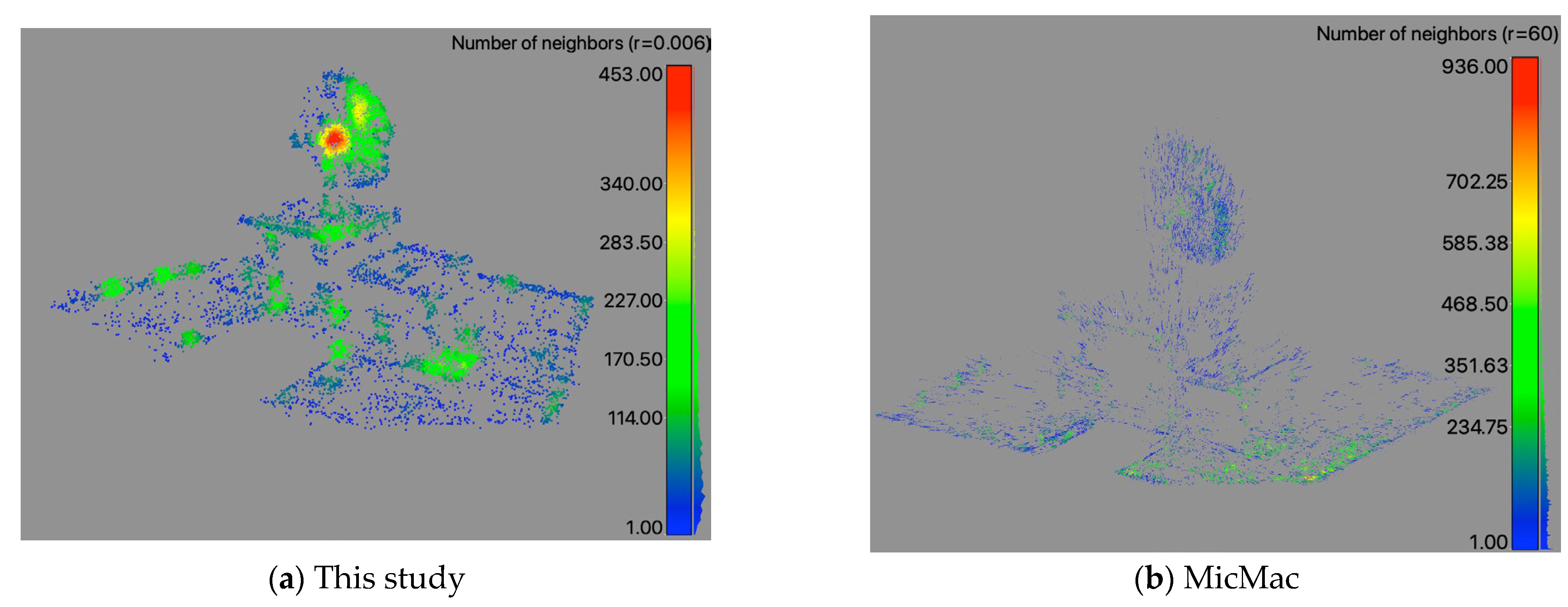
The visible point density (
Figure 16) is analyzed with a histogram (Gauss) (
Figure 17). This study’s point density radius is 0.006 m with a range of 0 to 453 divided into 99 classes (histogram). The graphic (
Figure 16a) shows that the edges and corners, as well as the antenna, are locations of increased density with a mean value of 114.64 and a standard deviation of 85.86. In contrast, the MicMac result shows within a radius of 60 m with a range of 0 to 936 divided into 451 classes. The graphic (
Figure 16b) shows that the edges and the corner on the right-hand side are locations of higher density with a mean value of 179.44 and a standard deviation of 114.64 (
Figure 17).
The influence of the combined feature detector operators is visible over the different reconstruction models and its comparison to the MicMac models is presented. The edges are locations of higher point density. The main proportion of the points is located within the first half of the spectrum. However, our study achieves a small, but clearly visible proportion within the higher point density spectrum of the histogram. The reconstruction is achieved with only two images, while MicMac needs many more images to reconstruct the point cloud.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}