
RiDOP: A Rotation-Invariant Detector with Simple Oriented Proposals in Remote Sensing Images
Abstract
1. Introduction
2. Related Works
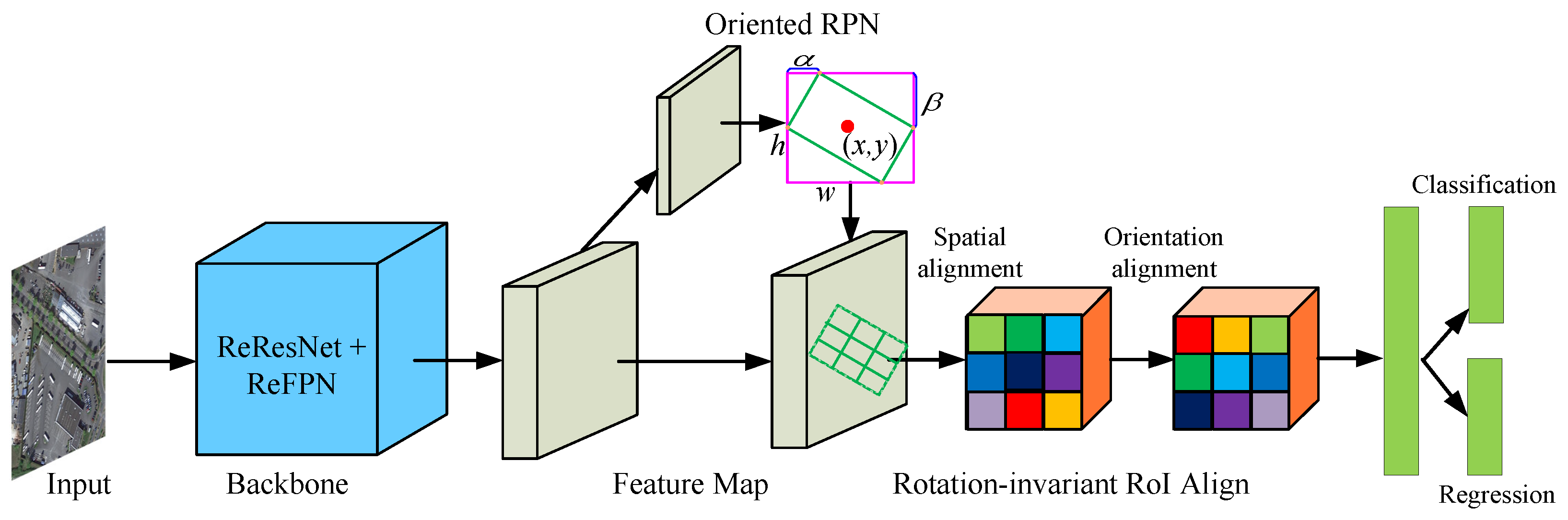
3. Proposed Method
3.1. Oriented Proposal Generation
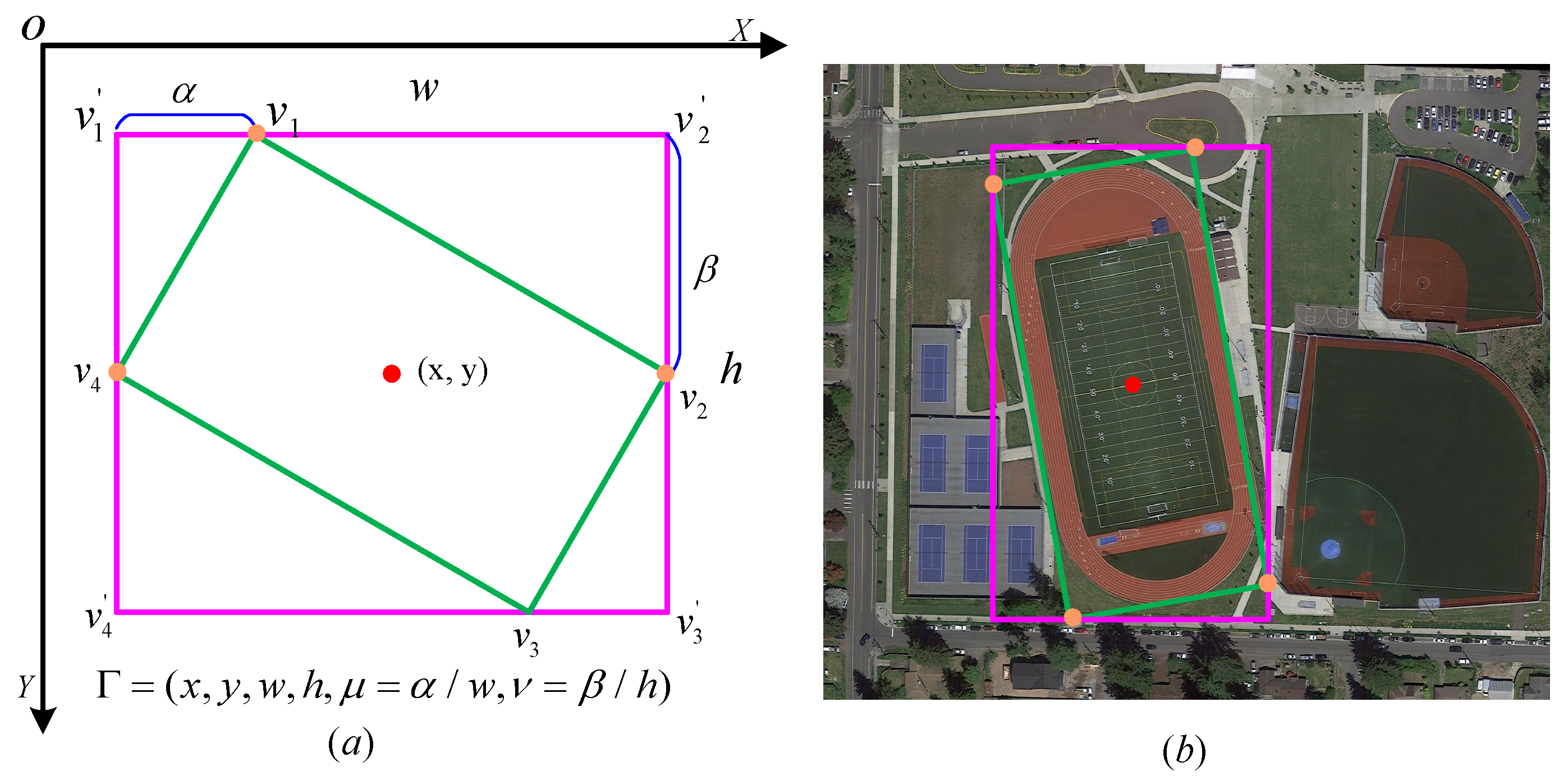
3.2. Oriented Object Representation
3.3. Rotation-Equivariant Backbone Network
3.4. Rotation-Invariant Feature with RiRoI Align
4. Experiments and Discussion
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Peer Comparison

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | MS | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| One-stage: | ||||||||||||||||||
| YOLOV2 [26] | Darknet-19 | - | ||||||||||||||||
| PIoU [32] | DLA-34 | - | ||||||||||||||||
| RSDet [44] | R50-FPN | - | ||||||||||||||||
| O2-DNet* [48] | H104 | - | ||||||||||||||||
| DRN [29] | H104 | ✓ | ||||||||||||||||
| OSSDet [49] | R101-FPN | ✓ | 76.97 | |||||||||||||||
| S2A-Net [11] | R50-FPN | ✓ | ||||||||||||||||
| Two-stage: | ||||||||||||||||||
| RADet [50] | R101-FPN | - | ||||||||||||||||
| CenterMap [45] | R50-FPN | - | ||||||||||||||||
| ReDet [15] | ReR50-ReFPN | - | ||||||||||||||||
| RoI Trans. [5] | R101-FPN | ✓ | ||||||||||||||||
| CenterRot. [51] | R101-FPN | ✓ | ||||||||||||||||
| Gliding Vertex [10] | R101-FPN | ✓ | ||||||||||||||||
| BBAVectors [52] | R101 | ✓ | ||||||||||||||||
| RIE [41] | HRGANet-W48 | ✓ | ||||||||||||||||
| ReDet [15] | Re50-ReFPN | ✓ | ||||||||||||||||
| Our (two-stage): | ||||||||||||||||||
| RiDOP | Re50-ReFPN | - | ||||||||||||||||
| RiDOP | Re50-ReFPN | ✓ | ||||||||||||||||
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2CNN [46] | |||||||||||||||||
| TPR-R2CNN [47] | |||||||||||||||||
| RetinaNet-O [18] | |||||||||||||||||
| FasterRCNN-O [27] | |||||||||||||||||
| ReDet [15] | |||||||||||||||||
| RiDOP (Our) |
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Serge, B.; Luo, J.; Mihai, D.; Marcello, P.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 3974–3983. [Google Scholar]
- Sebastien, R.; Frederic, J. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.; Bai, X.; Yang, W.; Micheal, Y.; Serge, B.; Luo, J.; Mihai, D.; Marcello, P.; et al. Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges. arXiv 2021, arXiv:2102.12219. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8231–8241. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. SCRDet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. arXiv 2022, arXiv:2004.13316. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align Deep Features for Oriented Object Detection. arXiv 2021, arXiv:2008.09397. [Google Scholar] [CrossRef]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–18 October 2021; pp. 3520–3529. [Google Scholar]
- Maurice, W.; Gabriele, C. General e(2)-equivariant steerable cnns. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14334–14345. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 2786–2795. [Google Scholar]
- Lu, Y.; Lu, G.; Lin, R.; Li, J.; David, Z. SRGC-Nets: Sparse Repeated Group Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2889–2902. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselinesy. In Proceedings of the International conference on pattern recognition applications and methods, Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Lin, Y.; Goyal, P.; Ross, G.; He, K.; Piotr, D. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Georgia, G.; Ross, G. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Matti, P. Deep learning for generic object detection: A survey. IEEE Geosci. Remote Sens. Lett. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Stephen, L. Reppoints: Point set representation for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–26 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Alexander, C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amesterdom, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ren, S.; He, K.; Ross, G.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Lu, S.; Zhang, W. Cad-net: A context-aware detection network for objects in remote sensing imagery. arXiv 2019, arXiv:1903.00857. [Google Scholar] [CrossRef]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic refinement network for oriented and densely packed object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11204–11213. [Google Scholar]
- Yang, X.; Yan, J. Arbitrary-oriented object detection with circular smooth label. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 677–694. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning High-Precision Bounding Box for Rotated Object Detection via Kullback-Leibler Divergence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Chen, Z.; Chen, K.; Lin, W.; See, J.; Yu, H.; Ke, Y.; Yang, C. PIoU Loss: Towards accurate oriented object detection in complex environments. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 195–211. [Google Scholar]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic anchor learning for arbitrary oriented object detection. In Proceedings of the AAAI Conference on Artificia lIntelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Yang, X.; Hou, L.; Yang, Z.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15814–15824. [Google Scholar]
- Taco S, C.; Welling, M. Group Equivariant Convolutional Networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2990–2999. [Google Scholar]
- Zhou, Y.; Ye, Q.; Qiu, Q.; Jiao, J. Oriented Response Networks. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4961–4970. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with Aggregating Multi-Layer Features for Partially Occluded Object Detection in Optical Remote Sensing Images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–26 July 2016. [Google Scholar]
- Lin, T.-Y.; Piotr, D.; Ross, G. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, X.; Ma, S.; He, L.; Ru, L.; Wang, C. Learning Rotated Inscribed Ellipse for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 3622. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, Y. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Yang, J.; Liu, Q.; Zhang, K. Stacked hourglass network for robust facial landmark localisation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 July 2020; pp. 79–87. [Google Scholar]
- Qian, W.; Yang, X.; Peng, S.; Guo, Y.; Y, J. Learning Modulated Loss for Rotated Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Wang, J.; Yang, W.; Li, H.; Zhang, H.; Xia, G. Learning center probability map for detecting objects in aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W. R2CNN: Rotational Region CNN for Arbitrarily-Oriented Scene Text Detection. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 3610–3615. [Google Scholar]
- Wu, F.; H, J.; Zhou, J.; Li, H.; Liu, Y.; Sui, X. Improved Oriented Object Detection in Remote Sensing Images Based on a Three-Point Regression Method. Remote Sens. 2021, 13, 4517. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, Y.; Chang, Z.; Li, H.; Wang, H.; Sun, X. Oriented objects as pairs of middle lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Chen, S.; Dai, B.; Tang, J.; Luo, B.; Wang, W.; Lv, K. A Refined Single-Stage Detector With Feature Enhancement and Alignment for Oriented Objects. IEEE J. Sel. Top. Earth Obs. Remote Sens. 2021, 14, 8898–8908. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Q.; Pei, X.; Jiao, L.; Shang, R. RADet: Refine Feature Pyramid Network and Multi-Layer Attention Network for Arbitrary-Oriented Object Detection of Remote Sensing Images. Remote Sens. 2020, 12, 389. [Google Scholar] [CrossRef]
- Wang, J.; Yang, L.; Li, F. Predicting Arbitrary-Oriented Objects as Points in Remote Sensing Images. Remote Sens. 2021, 13, 3731. [Google Scholar] [CrossRef]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 2150–2159. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 4974–4983. [Google Scholar]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Jie, Z.; Zhang, T.; Yang, J. Learning object-wise semantic representation for detection in remote sensing imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 20–27. [Google Scholar]




| Methods | Backbone | mAP (VOC 07) | mAP (VOC 12) |
|---|---|---|---|
| RoI Trans. [5] | R101-FPN | − | |
| Gliding Vertex. [10] | R101-FPN | − | |
| PIoU [32] | DLA-34 | − | |
| DRN [29] | H-34 | − | |
| R3Det [12] | R101-FPN | − | |
| CenterMap [45] | R101-FPN | − | |
| S2A-Net [11] | R50-FPN | ||
| OR-CNN [13] | R50-FPN | ||
| CenterRot [51] | R50-FPN | ||
| ReDet [15] | Re50-ReFPN | ||
| RiDOP (Our) | Re50-ReFPN |
| Methods | Framework | Backbone | mAP (%) | Param (Mb) | Platform | FPS |
|---|---|---|---|---|---|---|
| Faster RCNN-O [27] | Two-stage | R50 | 158 | Tesla V100 | ||
| RetinaNet-O [18] | One-stage | R50 | 140 | Tesla V100 | ||
| RoI Trans. [5] | Two-stage | R50 | − | 273 | TITAN X | |
| HTC [53] | Two-stage | R50 | 295 | Tesla V100 | ||
| ReDet [15] | Two-stage | ReR50 | 121 | RTX 6000 | ||
| RiDOP (Our) | Two-stage | ReR50 | 71 | RTX 6000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Ni, W.; Qin, Y.; Wu, J.; Zhang, H.; Liu, Q.; Cheng, K.; Bian, H. RiDOP: A Rotation-Invariant Detector with Simple Oriented Proposals in Remote Sensing Images. Remote Sens. 2023, 15, 594. https://doi.org/10.3390/rs15030594
Wei C, Ni W, Qin Y, Wu J, Zhang H, Liu Q, Cheng K, Bian H. RiDOP: A Rotation-Invariant Detector with Simple Oriented Proposals in Remote Sensing Images. Remote Sensing. 2023; 15(3):594. https://doi.org/10.3390/rs15030594
Chicago/Turabian StyleWei, Chongyang, Weiping Ni, Yao Qin, Junzheng Wu, Han Zhang, Qiang Liu, Kenan Cheng, and Hui Bian. 2023. "RiDOP: A Rotation-Invariant Detector with Simple Oriented Proposals in Remote Sensing Images" Remote Sensing 15, no. 3: 594. https://doi.org/10.3390/rs15030594
APA StyleWei, C., Ni, W., Qin, Y., Wu, J., Zhang, H., Liu, Q., Cheng, K., & Bian, H. (2023). RiDOP: A Rotation-Invariant Detector with Simple Oriented Proposals in Remote Sensing Images. Remote Sensing, 15(3), 594. https://doi.org/10.3390/rs15030594